《AI大模型应知应会100篇》第57篇:LlamaIndex使用指南:构建高效知识库
第57篇:LlamaIndex使用指南:构建高效知识库
摘要
在大语言模型(LLM)驱动的智能应用中,如何高效地管理和利用海量知识数据是开发者面临的核心挑战之一。LlamaIndex(原 GPT Index) 是一个专为构建大模型知识库设计的框架,它提供了从数据摄入、索引构建到查询优化的完整解决方案。
本文将全面介绍 LlamaIndex 的核心功能和技术特点,并通过实战代码示例展示如何构建高效的知识库应用。我们将涵盖从基础架构到高级应用开发的全流程,帮助你快速掌握这一强大的工具!

核心概念与知识点
1. LlamaIndex基础架构【实战部分】
核心概念
LlamaIndex 的核心架构围绕以下几个关键组件展开:
- Documents:原始数据源,如文档、网页、API 数据等。
- Nodes:经过分块和解析后的最小处理单元。
- Indices:索引结构,用于加速检索。
- Retrievers:负责从索引中提取相关节点。
架构设计
LlamaIndex 的工作流程可以分为三个阶段:
- 数据摄入:从多种数据源加载并解析数据。
- 索引构建:将解析后的数据转化为高效的索引结构。
- 查询执行:通过检索器和响应合成器生成最终答案。
最新版本特性
最新版本引入了以下高级功能:
- 高级检索:支持混合检索策略,如向量+关键词组合。
- 响应合成功能:通过多步推理生成更准确的答案。
与LangChain集成
LlamaIndex 可以无缝集成 LangChain,形成优势互补的工作流。例如,使用 LangChain 的链式调用管理复杂业务逻辑,同时利用 LlamaIndex 的高效索引和检索能力。
2. 数据摄入与处理【实战部分】
多源数据加载
LlamaIndex 支持多种数据源的加载,包括本地文档、网页和 API 数据。
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.web import SimpleWebPageReader# 加载本地文档
documents = SimpleDirectoryReader("./data").load_data()# 加载网页内容
web_documents = SimpleWebPageReader().load_data(["https://example.com/page1", "https://example.com/page2"]
)print(f"加载了 {len(documents)} 个本地文档和 {len(web_documents)} 个网页文档。")
文本分块策略
不同的分块方法会影响检索效率和精度。以下是两种常见分块器的实现:
from llama_index.core.node_parser import SentenceSplitter, TokenTextSplitter# 基于句子的分块器
sentence_parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes_sentence = sentence_parser.get_nodes_from_documents(documents)# 基于token的分块器
token_parser = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
nodes_token = token_parser.get_nodes_from_documents(documents)print(f"基于句子的分块数量:{len(nodes_sentence)}")
print(f"基于token的分块数量:{len(nodes_token)}")
自定义解析器
对于专业领域文档(如 PDF 或表格),可以使用自定义解析器提取特定信息。
from llama_index.readers.file import PDFReader# 加载PDF文档
pdf_reader = PDFReader()
pdf_documents = pdf_reader.load_data(file="./research_paper.pdf")print(f"加载了 {len(pdf_documents)} 页PDF内容。")
元数据提取
通过提取元数据(如标题、作者、时间戳等),可以增强节点的检索能力。
from llama_index.core.schema import Document# 添加元数据
document = Document(text="量子计算是一种基于量子力学原理的新型计算方式。",metadata={"title": "量子计算简介", "author": "张三", "date": "2023-01-01"}
)
print(document.metadata)
3. 索引与检索技术【实战部分】
向量索引构建
向量索引是 LlamaIndex 的核心功能之一,适用于大规模文档的高效检索。
from llama_index.core import VectorStoreIndex# 创建向量索引
vector_index = VectorStoreIndex.from_documents(documents)# 保存和加载索引
vector_index.storage_context.persist("./storage")
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
loaded_index = load_index_from_storage(storage_context)
混合检索策略
混合检索结合了向量、关键词和知识图谱等多种方法,能够显著提升检索精度。
from llama_index.core.retrievers import VectorIndexRetriever, BM25Retriever
from llama_index.core.retrievers import EnsembleRetriever# 创建多个检索器
retriever_vector = VectorIndexRetriever(index=vector_index)
retriever_keyword = BM25Retriever.from_documents(documents)# 组合检索器
ensemble_retriever = EnsembleRetriever(retrievers=[retriever_vector, retriever_keyword],weights=[0.6, 0.4]
)# 执行混合检索
nodes = ensemble_retriever.retrieve("量子计算的应用场景有哪些?")
for node in nodes:print(node.text)
上下文压缩
上下文压缩技术通过减少冗余信息,提升大规模文档的检索效率。
from llama_index.core.postprocessor import LongContextReorder# 使用上下文压缩
reordered_nodes = LongContextReorder().postprocess_nodes(nodes)
for node in reordered_nodes:print(node.text)
重排序策略
基于相关性的结果优化方法可以进一步提升检索质量。
from llama_index.core.postprocessor import SimilarityPostprocessor# 应用重排序
similarity_processor = SimilarityPostprocessor(similarity_cutoff=0.8)
filtered_nodes = similarity_processor.postprocess_nodes(reordered_nodes)
for node in filtered_nodes:print(node.text)
4. 高级应用开发【实战部分】
查询引擎定制
通过配置响应合成器,可以实现不同查询模式的灵活切换。
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine# 配置响应合成器
synthesizer = CompactAndRefine(llm=llm,verbose=True,streaming=True
)# 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=ensemble_retriever,response_synthesizer=synthesizer
)# 执行查询
response = query_engine.query("太阳能技术的最新进展是什么?")
print(response)
代理集成
结合工具使用的知识代理可以实现动态任务分解。
from llama_index.agents import ReActAgent# 定义工具
tools = [{"name": "SearchInternet", "func": search_internet},
]# 创建代理
agent = ReActAgent(tools=tools, query_engine=query_engine)# 执行代理
result = agent.run("查找关于太阳能技术的最新研究论文。")
print(result)
流处理
实时响应生成的流式 API 能够提升用户体验。
from llama_index.core.streaming import StreamingResponse# 使用流式响应
streaming_response = StreamingResponse(query_engine.stream_query("解释区块链的基本原理。"))
for chunk in streaming_response:print(chunk, end="")
评估框架
通过评估脚本测试系统的性能并进行优化。
from llama_index.evaluation import QueryResponseEvaluator# 初始化评估器
evaluator = QueryResponseEvaluator()# 测试查询
evaluation_result = evaluator.evaluate(query="什么是人工智能?",response=response,reference="人工智能是模拟人类智能的技术。"
)
print(evaluation_result)
案例与实例:LlamaIndex 实战应用
1. 企业文档库
问题背景:企业需要一个知识库系统,能够处理和检索大规模的 PDF 文档。以下是完整实现,包括数据加载、索引构建和查询优化。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.readers.file import PDFReader
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine# 数据加载:从目录中加载 PDF 文档
pdf_reader = PDFReader()
documents = pdf_reader.load_data(file="./corporate_documents/*.pdf")# 数据分块:将文档分割为小块
from llama_index.core.node_parser import SentenceSplitter
parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = parser.get_nodes_from_documents(documents)# 索引构建:创建向量索引
index = VectorStoreIndex(nodes)# 查询优化:使用向量检索器
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)# 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=retriever)# 执行查询
response = query_engine.query("公司2023年的主要产品有哪些?")
print(response)
输出结果
"根据文档内容,公司2023年的主要产品包括智能客服系统、数据分析平台和区块链解决方案。"
说明
- 数据加载:
PDFReader支持批量加载 PDF 文件。 - 数据分块:通过
SentenceSplitter将文档分割为适合模型处理的小块。 - 索引构建:使用向量索引加速检索。
- 查询优化:通过
VectorIndexRetriever提取最相关的节点。
2. 个人知识助手
问题背景:构建一个支持跨会话上下文管理的个人知识助手,帮助用户高效检索和记忆信息。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import ContextChatEngine# 数据加载:从本地目录加载文档
documents = SimpleDirectoryReader("./personal_knowledge").load_data()# 索引构建:创建向量索引
index = VectorStoreIndex.from_documents(documents)# 初始化记忆模块
memory = ChatMemoryBuffer.from_defaults(token_limit=4096)# 创建上下文感知的聊天引擎
chat_engine = ContextChatEngine(retriever=index.as_retriever(),memory=memory,system_prompt="你是一个个人知识助手,负责回答用户的问题并记住对话历史。",
)# 模拟多轮对话
response1 = chat_engine.chat("什么是量子计算?")
print(response1)response2 = chat_engine.chat("它有哪些应用场景?")
print(response2)# 查看对话历史
print(memory.get())
输出结果
"量子计算是一种基于量子力学原理的新型计算方式,利用量子比特进行并行计算。""量子计算的应用场景包括密码学、药物研发和金融建模等领域。"[{'role': 'assistant', 'content': '量子计算是一种基于量子力学原理的新型计算方式,利用量子比特进行并行计算。'}, {'role': 'assistant', 'content': '量子计算的应用场景包括密码学、药物研发和金融建模等领域。'}]
说明
- 记忆模块:
ChatMemoryBuffer用于存储对话历史,支持跨会话的上下文管理。 - 上下文感知:聊天引擎结合检索器和记忆模块,生成更精准的回答。
- 多轮对话:通过记忆模块,助手能够理解上下文并提供连贯的回答。
3. 研究文献分析器
问题背景:构建一个学术论文智能问答系统,支持关键词检索和引用分析。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.retrievers import BM25Retriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.evaluation import QueryResponseEvaluator# 数据加载:加载学术论文
documents = SimpleDirectoryReader("./research_papers").load_data()# 数据分块:提取段落和元数据
from llama_index.core.node_parser import TokenTextSplitter
parser = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
nodes = parser.get_nodes_from_documents(documents)# 索引构建:创建向量索引
index = VectorStoreIndex(nodes)# 检索器:结合 BM25 和向量检索
bm25_retriever = BM25Retriever.from_documents(documents)
vector_retriever = index.as_retriever(similarity_top_k=5)from llama_index.core.retrievers import EnsembleRetriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, vector_retriever],weights=[0.4, 0.6]
)# 查询引擎:配置响应合成器
synthesizer = CompactAndRefine(verbose=True)
query_engine = RetrieverQueryEngine(retriever=ensemble_retriever,response_synthesizer=synthesizer
)# 执行查询
response = query_engine.query("深度学习在自然语言处理中的最新进展是什么?")
print(response)# 引用分析:评估答案质量
evaluator = QueryResponseEvaluator()
evaluation_result = evaluator.evaluate(query="深度学习在自然语言处理中的最新进展是什么?",response=response,reference="参考文献中提到Transformer架构的改进提升了模型性能。"
)
print(evaluation_result)
输出结果
"最新的进展包括Transformer架构的改进、预训练模型的优化以及多模态融合技术的应用。"EvaluationResult(score=0.85, feedback="回答准确且涵盖了关键点。")
说明
- 关键词检索:
BM25Retriever提供高效的关键词匹配。 - 引用分析:通过
QueryResponseEvaluator评估答案的准确性。 - 混合检索:结合 BM25 和向量检索,提升检索精度。
- 响应合成:通过
CompactAndRefine合成更清晰的答案。
以上三个案例展示了 LlamaIndex 在不同场景中的强大能力:
- 企业文档库:通过向量索引和分块策略,高效处理大规模 PDF 文档。
- 个人知识助手:结合记忆模块,支持跨会话的上下文管理。
- 研究文献分析器:利用混合检索和引用分析,构建学术领域的智能问答系统。
总结与扩展思考
LlamaIndex 凭借其强大的数据处理能力和高效的索引机制,已成为构建大模型知识库的首选框架。未来,随着更多高级功能的推出,LlamaIndex 将进一步降低开发门槛,助力企业快速构建智能化应用系统。
扩展思考:
- 如何选择适合的框架(LlamaIndex vs. LangChain)?
- 大规模知识应用的高可用性和扩展性设计。
- 知识库技术的未来发展趋势与应用前景。
希望本文能为你打开 LlamaIndex 的大门!如果你有任何问题或想法,欢迎在评论区留言交流!
相关文章:
《AI大模型应知应会100篇》第57篇:LlamaIndex使用指南:构建高效知识库
第57篇:LlamaIndex使用指南:构建高效知识库 摘要 在大语言模型(LLM)驱动的智能应用中,如何高效地管理和利用海量知识数据是开发者面临的核心挑战之一。LlamaIndex(原 GPT Index) 是一个专为构建…...

目标检测中COCO评估指标中每个指标的具体含义说明:AP、AR
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

鸿蒙应用元服务开发-Account Kit概述
Account Kit(华为账号服务)提供简单、快速、安全的登录功能,让用户快捷地使用华为账号登录元服务。用户授权后,Account Kit可提供头像、手机号码等信息,帮助元服务更了解用户。Account Kit提供的SampleCode示例工程体现…...
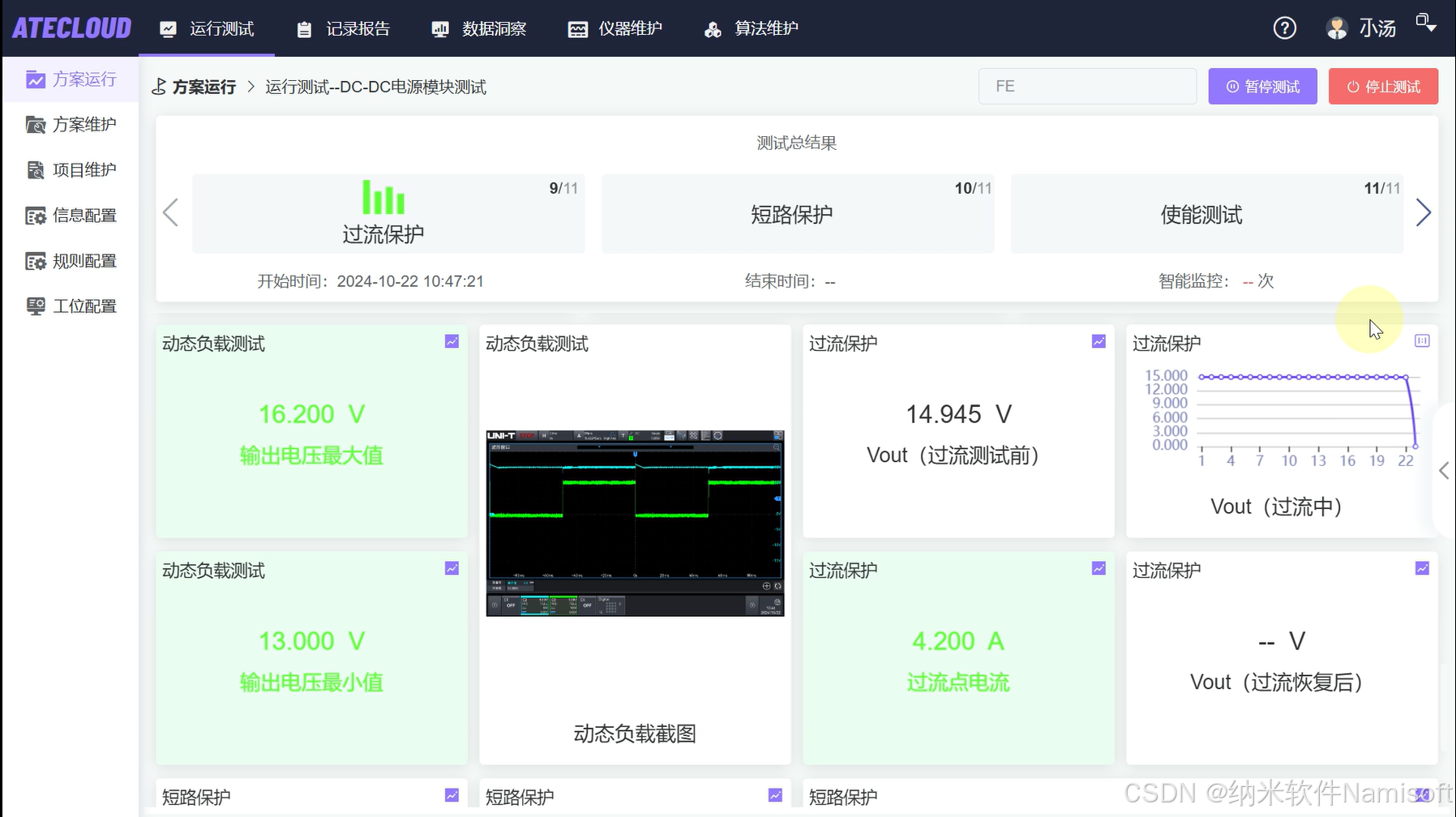
如何利用ATECLOUD测试平台的芯片测试解决方案实现4644芯片的测试?
作为多通道 DC-DC 电源管理芯片的代表产品,4644 凭借 95% 以上的转换效率、1% 的输出精度及多重保护机制,广泛应用于航天航空(卫星电源系统)、医疗设备(MRI 梯度功放)、工业控制(伺服驱动单元&a…...

SpringBoot集成OAuth2.0
文章目录 OAuth 2.0 介绍概念与传统认证方式的对比常见应用场景 OAuth 2.0 原理核心角色授权流程 Spring Boot 集成 OAuth 2.01. 添加依赖2. 配置 OAuth 2.0 客户端3. 配置 Spring Security4. 创建控制器5. 主应用类 代码解释 OAuth 2.0 介绍 概念 OAuth 2.0 是一个开放标准的…...

《继电器:机械骑士的电磁战甲》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 第一章:千年契约的青铜誓言 在电气王国的熔炉深处,电磁铁与簧片的盟约已镌刻千年。电磁铁身披螺旋铜线编织的斗篷,其胸膛中沉睡着一道可召唤磁力的古…...
的作用)
c++中cin.ignore()的作用
在 C 中,cin.ignore() 是用于忽略(丢弃)输入流中的字符的函数,通常用来清除输入缓冲区中的残留内容(如换行符、多余输入等),以避免影响后续的输入操作。 基本用法 cin.ignore(n, delim);n&…...

python如何获取html中附件链接,并下载保存附件
在Python中,要获取HTML中的附件链接并下载保存附件,你通常需要执行以下步骤: 解析HTML内容:使用像BeautifulSoup这样的库来解析HTML并找到包含附件链接的标签(例如<a>标签,它们通常有一个href属性指向…...

【计算机相关学习】R语言
在Python统治数据科学的时代,我意外推开了R语言的大门。这个诞生于统计学家之手的编程语言,像一把精巧的手术刀,改变了我对数据处理的认知边界。 语法里的统计基因令人惊艳。当我第一次用<-符号完成变量赋值时,这个源…...

JavaScript DOM 节点操作
目录 一、DOM 节点 节点类型(Node Types) 二、查找节点 1.查找父节点 1. parentNode 2. parentElement 2.查找子节点 1. childNodes 2. children 3. firstChild / lastChild 4. firstElementChild / lastElementChild 3.查找兄弟节点 1. pre…...
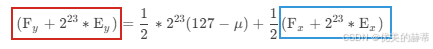
快速求平方根
1. 前置知识 建议首先阅读我的另外一篇文章《雷神之锤 III 竞技场》快速求平方根倒数的计算探究》。建议大家自己看过《雷神之锤 III 竞技场》快速求平方根倒数的计算探究》学会快速求平方根倒数算法后,不看我这篇文章,自己推导一篇快速求平方根的算法&…...

科普:One-Class SVM和SVDD
SVM(支持向量机)算法是用于解决二分类问题的,它在样本空间(高维空间)中找一个最优超平面,使得两类数据点中离超平面最近的点(称为支持向量)到超平面的距离最大。 对于极少数“坏样本…...

Vue 3 中按照某个字段将数组分成多个数组
方法一:使用 reduce 方法 const originalArray [{ id: 1, category: A, name: Item 1 },{ id: 2, category: B, name: Item 2 },{ id: 3, category: A, name: Item 3 },{ id: 4, category: C, name: Item 4 },{ id: 5, category: B, name: Item 5 }, ];const grou…...

冒泡排序笔记
核心思想 通过相邻元素的比较和交换,使较大的元素逐渐“浮”到数组的末尾(像气泡从水底冒到水面一样) 基础冒泡排序 public class BubbleSort{public static void bubbleSort(int[] arr){for(int i 0; i < arr.length - 1; i){//冒泡…...
)
【ABAP】REST/HTTP技术(一)
1、概念 1.1、SAP 如何提供 Http Service 如果要将 SAP 应用程序服务器 (application server)作为 http 服务提供者,需要定义一个类,这个类必须实现 IF_HTTP_EXTENSION 接口。IF_HTTP_EXTENSION 接口只有一个方法 HANDLE_REQUEST。…...

Flutter PopupMenuButton 深度解析:从入门到架构级实战
在移动应用交互设计中,上下文菜单如同隐形的魔法师,在有限屏幕空间中优雅地扩展操作维度。作为Flutter框架中的核心交互组件,PopupMenuButton绝非简单的菜单触发器,其背后蕴含着Material Design的交互哲学、声明式UI的架构智慧以及…...

C语言基础要素(019):输出ASCII码表
计算机以二进制处理信息,但二进制对人类并不友好。比如说我们规定用二进制值 01000001 表示字母’A’,显然通过键盘输入或屏幕阅读此数据而理解它为字母A,是比较困难的。为了有效的使用信息,先驱者们创建了一种称为ASCII码的交换代…...

VSCode开发者工具快捷键
自动生成浏览器文件.html的快捷方式 在文本里输入: ! enter VSCode常用快捷键列表 代码格式化:Shift Alt F向上或向下移动一行:Alt Up 或者 Alt Down快速复制一行代码:Shift Alt Up 或者 Shift Alt Down快速保…...

CI/CD(九) Jenkins共享库与多分支流水线准备
后端构建 零:安装插件 Pipeline: Stage View(阶段视图)、SSH Pipeline Steps(共享库代码中要调用sshCommond命令) 一、上传共享库 二、Jenkins配置共享库 3、新增静态资源与修改配置 如果是docker和k8s启动…...

使用Deployment运行无状态应用
使用Deployment运行无状态应用 文章目录 使用Deployment运行无状态应用[toc]一、工作负载资源与控制器二、ReplicationController、ReplicaSet和Deployment1. ReplicationController(已淘汰)2. ReplicaSet(ReplicationController 的增强版&am…...

pip安装timm依赖失败
在pycharm终端给虚拟环境安装timm库失败( pip install timm),提示你要访问 https://rustup.rs/ 来下载并安装 Rust 和 Cargo 直接不用管,换一条命令 pip install timm0.6.13 成功安装 简单粗暴...

详解隔离级别(4种),分别用表格展示问题出现的过程及解决办法
选择隔离级别的时候,既需要考虑数据的一致性,避免脏数据,又要考虑系统性能的问题。下面我们通过商品抢购的场景来讲述这4种隔离级别的区别 未提交读(read uncommitted) 未提交读是最低的隔离级别,其含义是…...
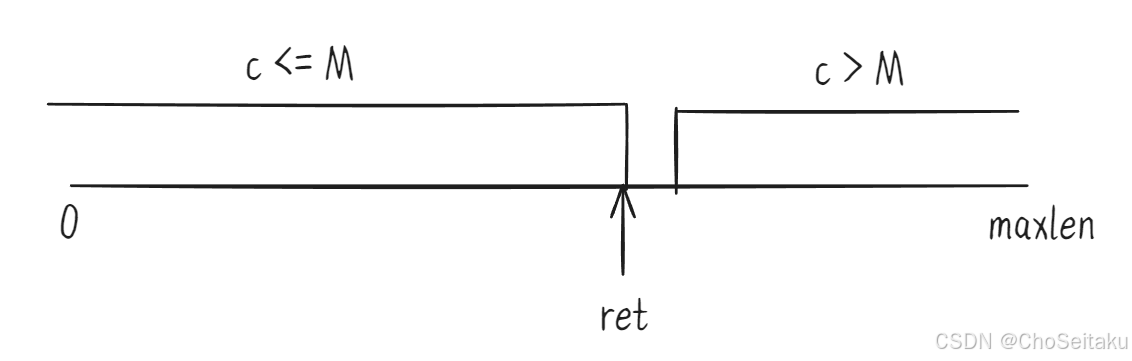
NO.63十六届蓝桥杯备战|基础算法-⼆分答案|木材加工|砍树|跳石头(C++)
⼆分答案可以处理⼤部分「最⼤值最⼩」以及「最⼩值最⼤」的问题。如果「解空间」在从⼩到⼤的「变化」过程中,「判断」答案的结果出现「⼆段性」,此时我们就可以「⼆分」这个「解空间」,通过「判断」,找出最优解。 这个「⼆分答案…...

深层储层弹塑性水力裂缝扩展机理
弹性与弹塑性储层条件下裂缝形态对比 参考: The propagation mechanism of elastoplastic hydraulic fracture in deep reservoir | International Journal of Coal Science & Technology...
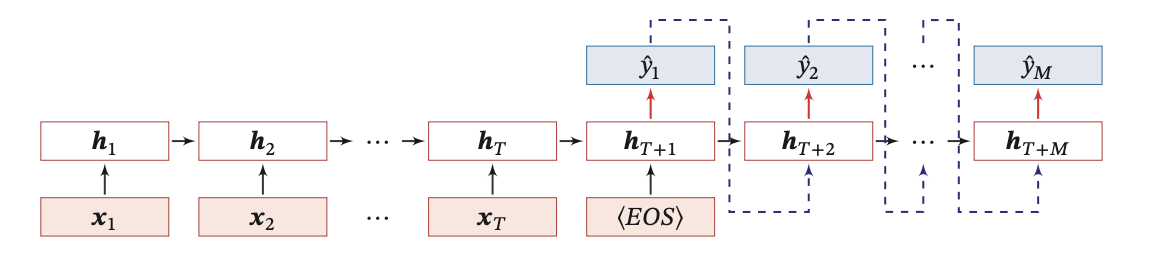
循环神经网络 - 机器学习任务之异步的序列到序列模式
前面我们学习了机器学习任务之同步的序列到序列模式:循环神经网络 - 机器学习任务之同步的序列到序列模式-CSDN博客 本文我们来学习循环神经网络应用中的第三种模式:异步的序列到序列模式! 一、基本概述: 异步的序列到序列模式…...
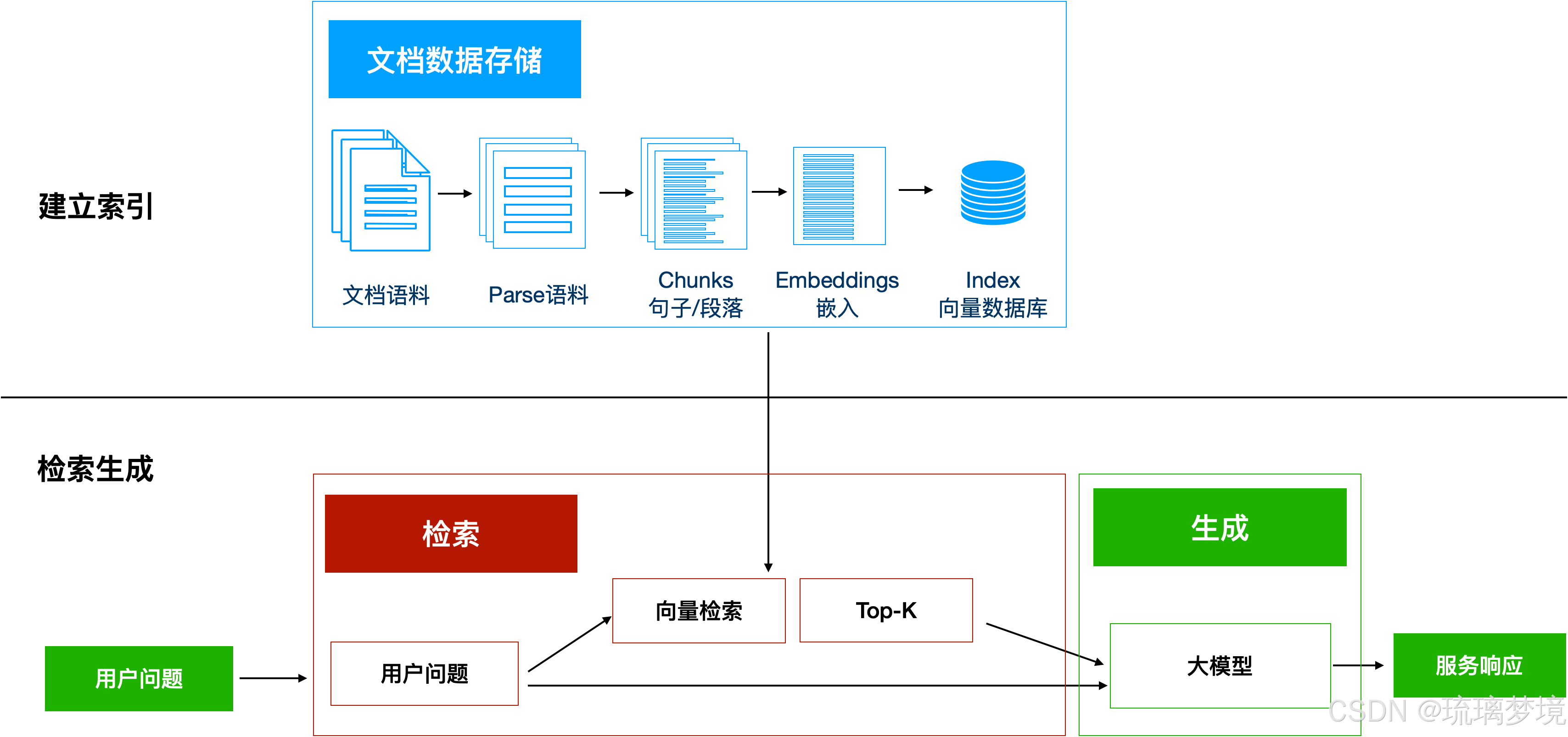
什么是检索增强生成(RAG)
1、什么是检索增强生成(RAG) 1.1 检索增强生成的概念 检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了信息检索和文本生成技术的新型自然语言处理方法。这种方法增强了模型的理解和生成能力。 相较于经典生成…...
MATLAB 控制系统设计与仿真 - 33
状态反馈控制系统 -全维状态观测器的实现 状态观测器的建立解决了受控系统不能测量的状态重构问题,使得状态反馈的工程实现成为可能。 考虑到系统的状态方程表达式,如果{A,B}可控,{A,C}可观,且安装系统的性能指标,可…...

PM2 在 Node.js 项目中的使用与部署指南
一、PM2 简介 PM2 是一个带有负载均衡功能的 Node.js 应用程序的进程管理器。它可以让你的 Node.js 应用程序始终保持运行状态,即使出现错误或服务器重启也能自动恢复。同时,它还提供了诸如日志管理、性能监控等实用功能,极大地简化了 Nod…...
企业管理系统的功能架构设计与实现
一、企业管理系统的核心功能模块 企业管理系统作为现代企业的中枢神经系统,涵盖了多个核心功能模块,以确保企业运营的顺畅与高效。这些功能模块通常包括: 人力资源管理模块:负责员工信息的录入、维护、查询及统计分析,…...

RTOS基础 -- NXP M4小核的RPMsg-lite与端点机制回顾
一、RPMsg-lite与端点机制回顾 在RPMsg协议框架中: Endpoint(端点) 是一个逻辑通信端口,由本地地址(local addr)、远程地址(remote addr)和回调函数组成。每个消息都会发送到特定的…...