【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解
【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解
文章目录
- 【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解
- 前言
- YOLOV3的模型结构
- YOLOV3模型的基本执行流程
- YOLOV3模型的网络参数
- YOLOV3的核心思想
- 前向传播阶段
- 反向传播阶段
- 总结
前言
YOLOV3是由华盛顿大学的Joseph Redmon等人在《YOLOv3: An Incremental Improvement》【论文地址】中提出的YOLO系列单阶段目标检测模型的升级改进版,核心思想是在YOLOV2基础上,通过引入多项关键技术和模块提升检测性能,即特征金字塔网络(FPN)结构的多尺度特征融合、更深的Darknet-53网络、借鉴了ResNet的残差连接设计、改进的损失函数等使得YOLOV3在保持高速的同时,大幅提升了检测精度。
Joseph Redmon在提出了YOLO三部曲之后,宣布退出计算机视觉研究,后续的YOLO系列是其他人在其基础上的创新改进。
YOLOV3的模型结构
YOLOV3模型的基本执行流程
下图是博主根据原论文绘制了YOLOV3模型流程示意图:
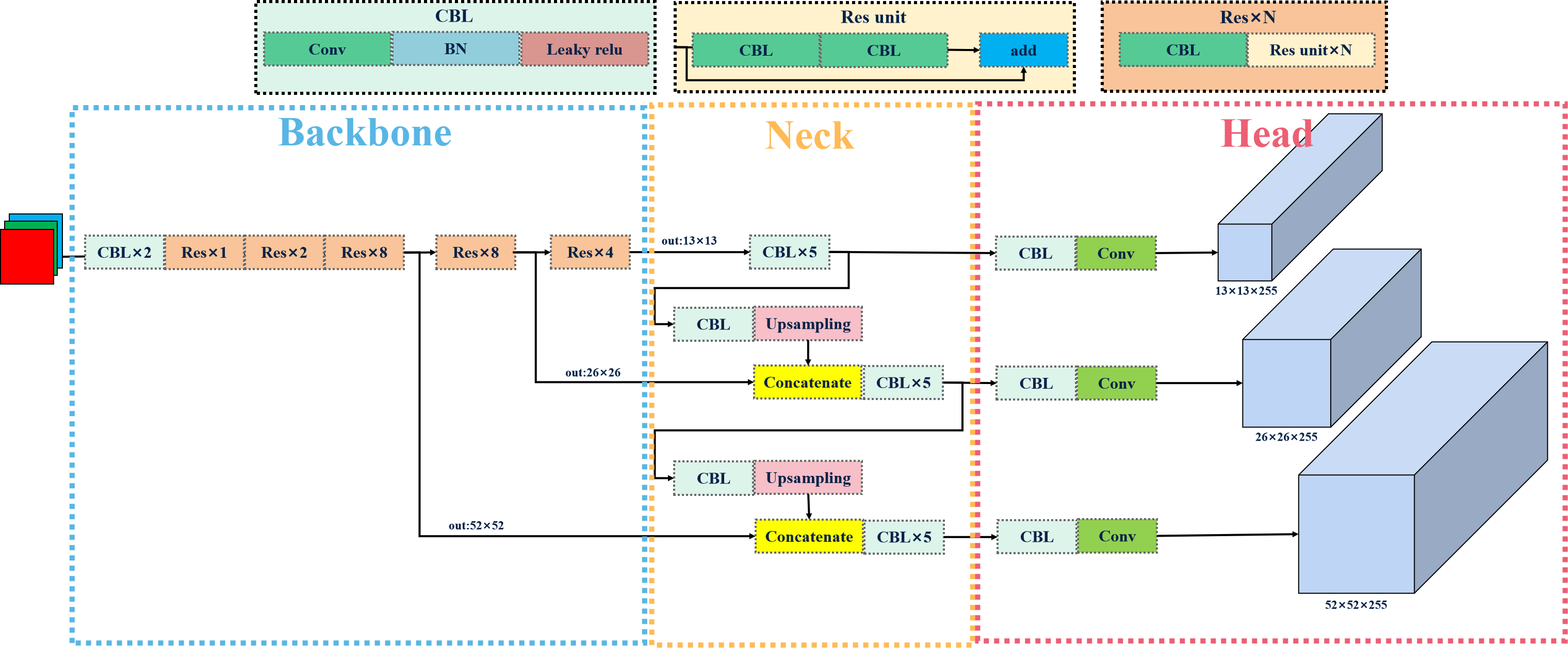
基本流程: 将输入图像调整为固定大小(416x416),使用Darknet-53作为骨干网络来提取图像的特征(包含了检测框位置、大小、置信度以及分类概率),在三个不同尺度特征图划分网格,每个单元网格负责预测一定数量的边界框及其对应的类别概率,分别对应于小、中、大尺寸目标的检测。
YOLOV3模型的网络参数
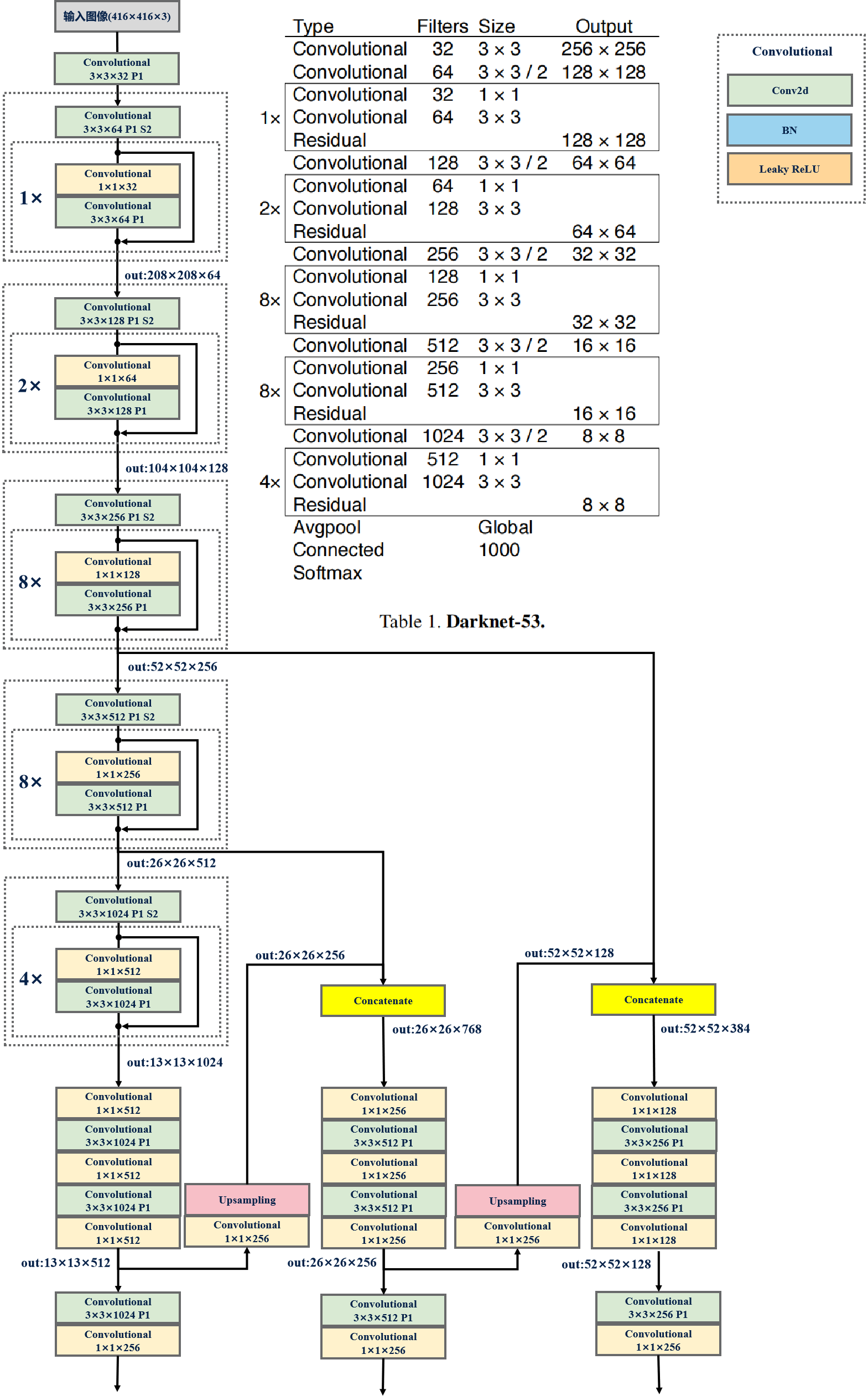
YOLOV3网络参数: YOLOV3采用的Darknet-53结构,由于没有全连接层,模型的输入可以是任意图片大小,不管是416×416还是320×320,因此可以进行多尺度训练。
53是指有53个Convolutional层。
YOLOV3的核心思想
前向传播阶段
特征金字塔(FPN): 包含了从底层到顶层的多个尺度的特征图,每个特征图都融合了不同层次的特征信息,每一层都对应一个特定的尺度范围,利用不同尺度的特征图进行检测,使得模型能够同时处理不同大小的目标【参考】 。

通过以下步骤实现多尺度特征的提取和融合:
- step1(自底向上): 使用基础网络(ResNet等)作为骨干网络(backbone),对输入图像中逐层提取特征,特征图的分辨率逐渐降低,按照输出特征图分辨率大小划分为不同的阶段(stage),相邻俩个阶段的特征图,后一个阶段相对于前一个阶段特征图尺度缩小一半,通道数则增加一倍;
- step2(自顶向下): 后一阶段的高层特征图上采样(up-sampling,通常采用2倍邻近插值算法),使其分辨率尺寸与前一阶段的低层特征图相匹配,;
- step3(横向连接): 将俩个特征图进行通道拼接,完成低层特征图的高分辨率信息与高层特征图的丰富语义信息的融合。
检测头: 基于多尺度特征图来预测目标的位置和类别,作用如下:
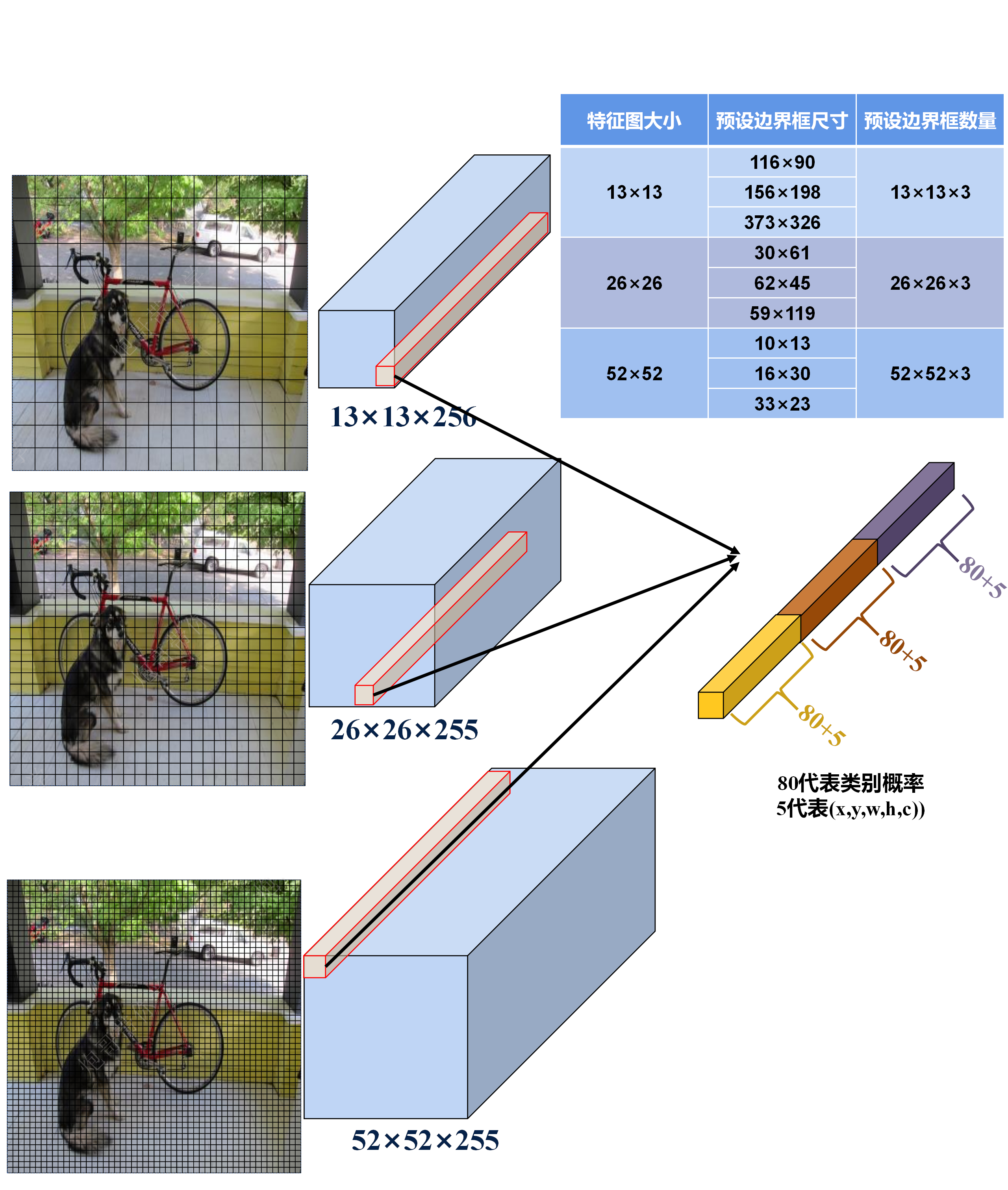
- 多尺度预测: 在三个不同尺度的特征图上分别应用检测头,使得模型可以同时处理小、中、大型目标的检测问题,有效地提高模型对不同尺寸目标的检测能力;
- 边界框预测: 每个检测头基于一组(3个)预选框(anchor boxes)负责预测边界框,预测预选框相对于真实框(ground truth)的偏移和缩放来确定边界框位置,预测框中目标存在的概率以及目标类别的概率来确定边界框的类别。
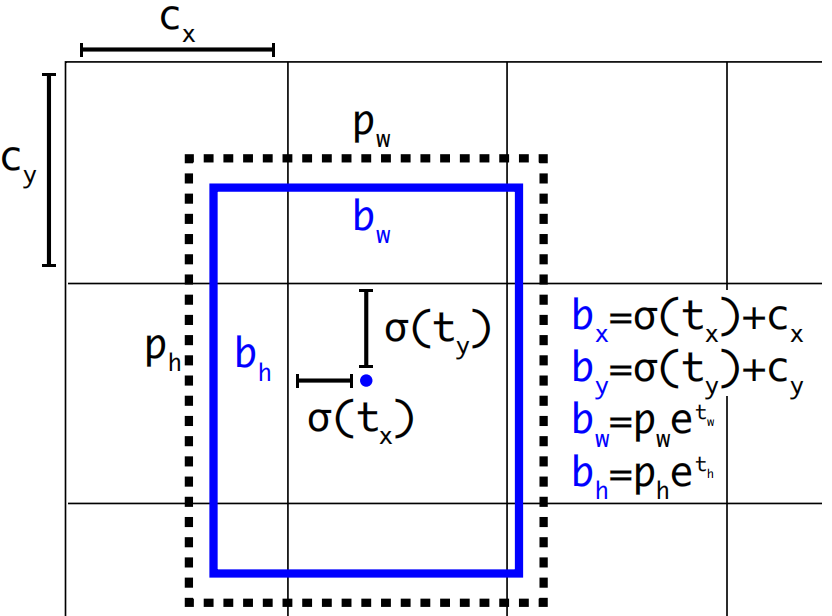
位置预测: YOLOV3延续了YOLOV2的设计,利用预选框来预测边界框相对预选框之间的误差补偿(offsets),预测边界框位置(中心点)在所属网格单元左上角位置进行相对偏移值,预测边界框尺寸基于所对应的预选框宽高进行相对缩放:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{array}{l} {b_x} = \sigma ({t_x}) + {c_x}\\ {b_y} = \sigma ({t_y}) + {c_y}\\ {b_w} = {p_w}{e^{{t_w}}}\\ {b_h} = {p_h}{e^{{t_h}}} \end{array} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
使用sigmoid函数处理偏移值,将边界框中心点约束在所属网格单元中,网格单元的尺度为1,而偏移值在(0,1)范围内,防止过度偏移。
( c x , c y ) ({c_x},{c_y}) (cx,cy)是网格单元的左上角坐标, p w p_w pw和 p h p_h ph是预选框的宽度与高度, e t w e^{{t_w}} etw和 e t h e^{{t_h}} eth则没有过多约束是因为物体的大小是不受限制的。
多尺度训练: 采用不同分辨率的多尺度图像训练(输入图像尺寸动态变化),让模型能够鲁棒地运行在不同尺寸的图像上,提高了模型对不同尺寸目标的泛化能力 。

数据正负样本: 、 预测框分为三 种情况::正样本(positive)、负样本(negative)和忽略样本(ignore)。
-
正样本: 任取一个真实框,计算与其类别相同的全部预测框IOU,IOU最大的预测框作为正样本,正样本IOU可能小于阈值。一个预测框只分配给一个真实框。正样本产生置信度loss、检测框loss以及类别loss,真实框的类别标签是onehot编码,置信度标签为1。
当前真实框已经匹配了一个预测框,那么下一个真实框就在余下的预测框中匹配IOU最大的作为其正样本。
-
忽略样本: 与任意一个真实框IOU大于阈值但没成为正样本的预测框,就是忽略样本。忽略样样本不产生任何loss。
-
负样本: 任取一个真实框,计算与其类别相同的全部预测框IOU,IOU小于阈值的预测框作为负样本。负样本只产生置信度loss、真实框的置信度标签为0。
根据上述标准,下图中以检测狗为例,浅绿色是真实框,绿色是正样本预测框,橙色是忽略样本预测框,红色则是负样本预测框。
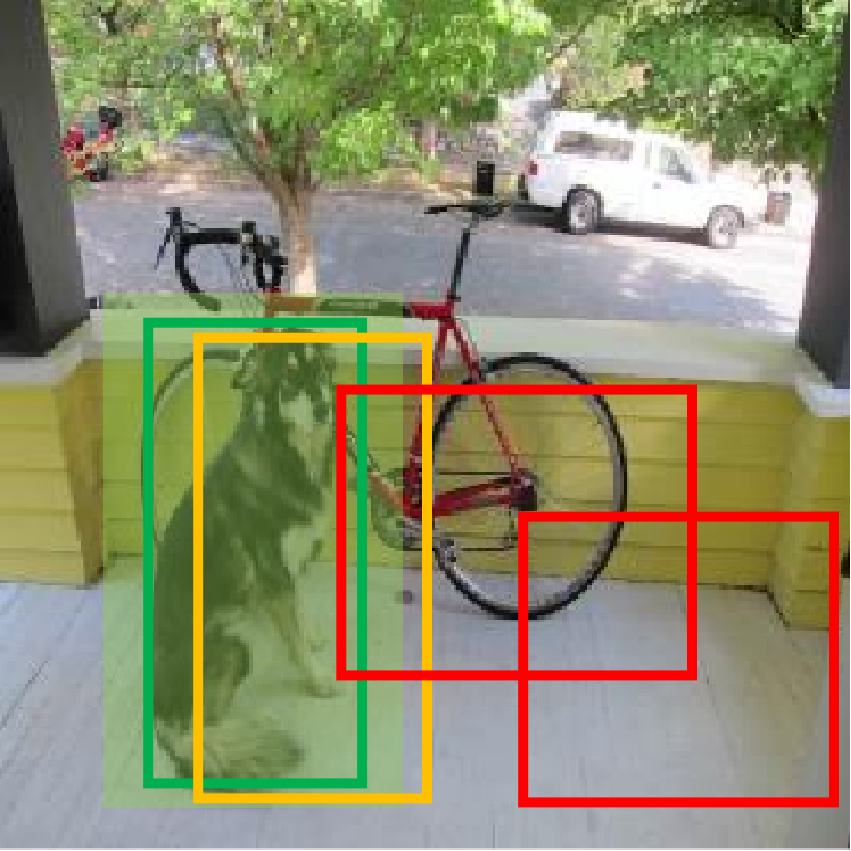
在之前的YOLO版本中,正样本使用真实框与预测框的IOU作为置信度,置信度始终比较小,检测的召回率不高(过滤太多找不全),特别是在学习小物体时,IOU可能更小,导致无法有效学习。YOLOV3将正样本置信度设置为1,因为置信度本身就是二分类问题,即预测框中是不是一个真实物体,标签是1或0更加合理。
反向传播阶段
损失函数: YOLOV3的损失函数公式为:
L o s s = − λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ x ∧ i j log ( x i j ) + ( 1 − x ∧ i j ) log ( 1 − x i j ) + y ∧ i j log ( y i j ) + ( 1 − y ∧ i j ) log ( 1 − y i j ) ] + 1 2 λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i j − w ∧ i j ) 2 + ( h i j − h ∧ i j ) 2 ] − ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ C ∧ i j log ( C i j ) + ( 1 − C ∧ i j ) log ( 1 − C i j ) ] − λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j [ C ∧ i j log ( C i j ) + ( 1 − C ∧ i j ) log ( 1 − C i j ) ] − ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ∑ c ∈ c l a s s e s [ P ∧ i j c log ( P i j c ) + ( 1 − P ∧ i j c ) log ( 1 − P i j c ) ] L{\rm{oss}} = - {\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop x\limits^ \wedge }_{ij}}\log ({x_{ij}}) + (1 - {{\mathop x\limits^ \wedge }_{ij}})\log (1 - {x_{ij}}) + {{\mathop y\limits^ \wedge }_{ij}}\log ({y_{ij}}) + (1 - {{\mathop y\limits^ \wedge }_{ij}})\log (1 - {y_{ij}})} \right]} } + \frac{1}{2}{\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{({w_{ij}} - {{\mathop w\limits^ \wedge }_{ij}})}^2} + {{({h_{ij}} - {{\mathop h\limits^ \wedge }_{ij}})}^2}} \right]} } - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } - {\lambda _{noobj}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{noobj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\sum\limits_{c \in classes} {\left[ {{{\mathop P\limits^ \wedge }_{ijc}}\log ({P_{ijc}}) + (1 - {{\mathop P\limits^ \wedge }_{ijc}})\log (1 - {P_{ijc}})} \right]} } } } Loss=−λcoordi=0∑S2j=0∑B1ijobj[x∧ijlog(xij)+(1−x∧ij)log(1−xij)+y∧ijlog(yij)+(1−y∧ij)log(1−yij)]+21λcoordi=0∑S2j=0∑B1ijobj[(wij−w∧ij)2+(hij−h∧ij)2]−i=0∑S2j=0∑B1ijobj[C∧ijlog(Cij)+(1−C∧ij)log(1−Cij)]−λnoobji=0∑S2j=0∑B1ijnoobj[C∧ijlog(Cij)+(1−C∧ij)log(1−Cij)]−i=0∑S2j=0∑B1ijobjc∈classes∑[P∧ijclog(Pijc)+(1−P∧ijc)log(1−Pijc)]
- ∑ i = 0 S 2 \sum\limits_{{\rm{i}} = 0}^{{S^2}} {} i=0∑S2表示遍历所有网格单元并进行累加;
- ∑ j = 0 B \sum\limits_{{\rm{j}} = 0}^B {} j=0∑B表示遍历所有预测边界框并进行累加。
预测框位置损失: 计算了所有预测框的位置(中心坐标)与真实框的位置的交叉熵误差损失和。
− λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ x ∧ i j log ( x i j ) + ( 1 − x ∧ i j ) log ( 1 − x i j ) + y ∧ i j log ( y i j ) + ( 1 − y ∧ i j ) log ( 1 − y i j ) ] - {\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop x\limits^ \wedge }_{ij}}\log ({x_{ij}}) + (1 - {{\mathop x\limits^ \wedge }_{ij}})\log (1 - {x_{ij}}) + {{\mathop y\limits^ \wedge }_{ij}}\log ({y_{ij}}) + (1 - {{\mathop y\limits^ \wedge }_{ij}})\log (1 - {y_{ij}})} \right]} } −λcoordi=0∑S2j=0∑B1ijobj[x∧ijlog(xij)+(1−x∧ij)log(1−xij)+y∧ijlog(yij)+(1−y∧ij)log(1−yij)]
- ( x ∧ i j , y ∧ i j ) {({{\mathop {{\rm{ }}x}\limits^ \wedge }_{ij}},{{\mathop {{\rm{ y}}}\limits^ \wedge }_{ij}})} (x∧ij,y∧ij)表示真实框的中心点坐标;
- ( x i j , y i j ) {({x_{ij}},{y_{ij}})} (xij,yij)表示预测框的中心点坐标;
- λ c o o r d {\lambda _{coord}} λcoord表示协调系数, λ c o o r d = ( 2 − w i j ∧ h i j ∧ ) {\lambda _{coord}} = (2 - {\mathop w\limits^ \wedge _{ij}}{\mathop h\limits^ \wedge _{ij}}) λcoord=(2−ijw∧ijh∧)协调检测目标不同大小对误差函数的影响:检测目标比较小时增大其对损失函数的影响,相反检测目标比较大时消减其对损失函数的影响;
- 1 i j o b j {1_{ij}^{obj}} 1ijobj表示当前预测框是否预测一个目标物体,如果预测一个目标则为1,否则等于0。
预测框尺度损失: 计算了所有预测框的宽高与真实框的宽高求和平方误差损失和。
1 2 λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i j − w ∧ i j ) 2 + ( h i j − h ∧ i j ) 2 ] \frac{1}{2}{\lambda _{coord}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{({w_{ij}} - {{\mathop w\limits^ \wedge }_{ij}})}^2} + {{({h_{ij}} - {{\mathop h\limits^ \wedge }_{ij}})}^2}} \right]} } 21λcoordi=0∑S2j=0∑B1ijobj[(wij−w∧ij)2+(hij−h∧ij)2]
- ( w ∧ i j , h ∧ i j ) {({{\mathop {{\rm{ }}w}\limits^ \wedge }_{ij}},{{\mathop {{\rm{ h}}}\limits^ \wedge }_{ij}})} (w∧ij,h∧ij)表示真实框的中心点坐标;
- ( w i j , h i j ) {({w_{ij}},{h_{ij}})} (wij,hij)表示预测框的中心点坐标。
预测框置信度损失: 计算了所有预测框的置信度与真实框的置信度的交叉熵误差损失和。
− ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ C ∧ i j log ( C i j ) + ( 1 − C ∧ i j ) log ( 1 − C i j ) ] − λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j [ C ∧ i j log ( C i j ) + ( 1 − C ∧ i j ) log ( 1 − C i j ) ] - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } - {\lambda _{noobj}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{noobj}\left[ {{{\mathop C\limits^ \wedge }_{ij}}\log ({C_{ij}}) + (1 - {{\mathop C\limits^ \wedge }_{ij}})\log (1 - {C_{ij}})} \right]} } −i=0∑S2j=0∑B1ijobj[C∧ijlog(Cij)+(1−C∧ij)log(1−Cij)]−λnoobji=0∑S2j=0∑B1ijnoobj[C∧ijlog(Cij)+(1−C∧ij)log(1−Cij)]
- C ∧ i j {{{\mathop C\limits^ \wedge }_{ij}}} C∧ij表示真实框的置信度,包含检测目标取值为1,否则还是0;
- C i j {{C_{ij}}} Cij表示预测框的置信度;
- λ n o o b j {\lambda _{noobj}} λnoobj表示预测框没有目标的权重系数,通常大部分预测框都不包含检测目标物体,导致模型预测倾向于预测框中没有目标物体,因此必须减少没有目标物体的预测框的损失权重。
预测框类别损失: 计算了所有预测框的类别概率与真实框的类别概率的交叉熵误差损失和。
− ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ∑ c ∈ c l a s s e s [ P ∧ i j c log ( P i j c ) + ( 1 − P ∧ i j c ) log ( 1 − P i j c ) ] - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {1_{ij}^{obj}\sum\limits_{c \in classes} {\left[ {{{\mathop P\limits^ \wedge }_{ijc}}\log ({P_{ijc}}) + (1 - {{\mathop P\limits^ \wedge }_{ijc}})\log (1 - {P_{ijc}})} \right]} } } −i=0∑S2j=0∑B1ijobjc∈classes∑[P∧ijclog(Pijc)+(1−P∧ijc)log(1−Pijc)]
- P ∧ i j c {{{\mathop P\limits^ \wedge }_{ijc}}} P∧ijc表示真实框的类别概率,onehot编码,所属的类别概率为1,其他类概率为0;
- P i j c {{P_{ijc}}} Pijc表示预测框的类别概率。
在YOLOV1和YOLOV2利用softmax来进行概率预测,这种激活函数让所有类别的概率相加等于1,因此只能进行单一分类预测,而在YOLOV3中将softmax修改成sigmoid函数,对不同类别单独进行二分类概率预测,因此进行多标签类别的分类预测。
YOLOV3可以同时是动物和猪俩类(sigmoid函数),而不是动物和猪中选择概括最大的一类(softmax函数)。
总结
尽可能简单、详细的介绍了YOLOV3模型的结构,深入讲解了YOLOV3核心思想。
相关文章:
【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解
【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解 文章目录 【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解前言YOLOV3的模型结构YOLOV3模型的基本执行流程YOLOV3模型的网络参数 YOLOV3的核心思想前向传播阶段反向传播阶段 总结 前言 YOLOV3是由华盛顿…...

【前端扫盲】postman介绍及使用
Postman 是一款专为 API 开发与测试设计的 全流程协作工具,程序员可通过它高效完成接口调试、自动化测试、文档管理等工作。以下是针对程序员的核心功能介绍和应用场景说明: 一、核心功能亮点 接口请求构建与调试 支持所有 HTTP 方法(GET/POS…...
)
每日c/c++题 备战蓝桥杯(全排列问题)
题目描述 按照字典序输出自然数 1 到 n 所有不重复的排列,即 n 的全排列,要求所产生的任一数字序列中不允许出现重复的数字。 输入格式 一个整数 n。 输出格式 由 1∼n 组成的所有不重复的数字序列,每行一个序列。 每个数字保留 5 个场…...
IdeaVim-AceJump
AceJump 是一款专为IntelliJ IDEA平台打造的开源插件,旨在通过简单的快捷键操作帮助用户快速跳转到编辑器中的任何符号位置,如变量名、方法调用或特定的字符串。无论是大型项目还是日常编程,AceJump 都能显著提升你的代码导航速度和效率。…...

BMS电池关键参数及其含义
BMS概述 BMS的定义与功能 BMS,即电池管理系统,是电池系统的核心控制设备,充当着电池的“状态观测器”。它通过传感器采集电池的单体电压、温度、电流等关键参数,并利用电子控制单元(ECU)进行数据处理和分…...

DataFrame行索引操作以及重置索引
一.DataFrame行索引操作 1.1 获取数据 1.1.1 loc 选取数据 df.loc[ ] 只能使用标签索引,不能使用整数索引。 当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭。 传参: 1.如果选择单行或单列,返回的数据类型为 Series…...

DayDreamer: World Models forPhysical Robot Learning
DayDreamer:用于物理机器人学习的世界模型 Philipp Wu* Alejandro Escontrela* Danijar Hafner* Ken Goldberg Pieter Abbeel 加州大学伯克利分校 *贡献相同 摘要:为了在复杂环境中完成任务,机器人需要从经验中学习。深度强化学习是机器人学…...

线性欧拉筛
线性筛:高效求解素数 在数论中,素数的筛选是一个经典的问题。最常见的素数筛选方法是埃拉托斯特尼筛法,其时间复杂度为 O ( n log log n ) O(n\log \log n) O(nloglogn),非常适合求解小范围内的素数。随着问题规模的增大&…...

Flutter vs React Native:跨平台移动开发框架对比
文章目录 前言1. 框架概述什么是 Flutter?什么是 React Native? 2. 性能对比Flutter 的性能表现React Native 的性能表现总结: 3. 开发体验对比3.1 开发效率3.2 UI 组件库 4. 生态系统对比5. 适用场景分析6. 结论:如何选择&#x…...

用matlab搭建一个简单的图像分类网络
文章目录 1、数据集准备2、网络搭建3、训练网络4、测试神经网络5、进行预测6、完整代码 1、数据集准备 首先准备一个包含十个数字文件夹的DigitsData,每个数字文件夹里包含1000张对应这个数字的图片,图片的尺寸都是 28281 像素的,如下图所示…...

AI辅助开发插件
适合Java程序员的AI辅助开发插件,按功能和适用场景分类: 1. 飞算JavaAI • 特点:从需求分析到代码生成的全流程智能引导,支持Maven、Gradle等主流工具,一键生成完整工程代码,包括配置文件、源代码和测试资…...
【AI4CODE】5 Trae 锤一个基于百度Amis的Crud应用
【AI4CODE】目录 【AI4CODE】1 Trae CN 锥安装配置与迁移 【AI4CODE】2 Trae 锤一个 To-Do-List 【AI4CODE】3 Trae 锤一个贪吃蛇的小游戏 【AI4CODE】4 Trae 锤一个数据搬运工的小应用 1 百度 Amis 简介 百度 Amis 是一个低代码前端框架,由百度开源。它通过 J…...

npm webpack打包缓存 导致css引用地址未更新
问题如下: 测试环境配置: publicPath: /chat/,生产环境配置: publicPath: /,css中引用背景图片 background-image: url(/assets/images/calendar/arrow-left.png);先打包测试环境,观察打包后的css文件引用的背景图片地址 可以全…...
ollama导入huggingface下载的大模型并量化
1. 导入GGUF 类型的模型 1.1 先在huggingface 下载需要ollama部署的大模型 1.2 编写modelfile 在ollama 里面输入 ollama show --modelfile <你有的模型名称> eg: ollama show --modelfile qwen2.5:latest修改其中的from 路径为自己的模型下载路径 FROM /Users/lzx/A…...
Java 集合 Map Stream流
目录 集合遍历for each map案例 编辑 这种数组的遍历是【index】编辑map排序【对象里重写compareTo编辑map排序【匿名内部类lambda编辑 stream流编辑 编辑获取: map的键是set集合,获取方法map.keySet() map的值是collection 集合&…...

记录一下零零散散的的东西-ImageNet
ImageNet 是一个非常著名的大型图像识别数据集, 数据集基本信息 内容说明📸 图像数量超过 1400万张图片(包含各类子集)🏷️ 类别数量常用的是 ImageNet-1K(1000类)🧑Ἶ…...

【网络安全实验】PKI(证书服务)配置实验
目录 一、PKI相关概念 1.1 定义与核心功能 1.2 PKI 系统的组成 1.证书颁发机构(CA, Certificate Authority) 2.注册机构(RA, Registration Authority) 3.数字证书 1.3 PKI 的功能 1.4 PKI认证体系: 工作流程 …...
【数据集】多视图文本数据集
多视图文本数据集指的是包含多个不同类型或来源的信息的文本数据集。不同视图可以来源于不同的数据模式(如原始文本、元数据、网络结构等),或者不同的文本表示方法(如 TF-IDF、词嵌入、主题分布等)。这些数据集常用于多…...
学透Spring Boot — 007. 七种配置方式及优先级
Spring Boot 提供很多种方式来加载配置,本文我们会用Tomcat的端口号作为例子,演示Spring Boot 常见的配置方式。 几种配置方式 使用默认配置 新建一个项目什么都不配置,Spring Boot会自动配置Tomcat端口号。 启动日志 TomcatWebServer :…...

元素定位-xpath
xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点。 绝对定位 从根开始找--/(根目录)/html/body/div[2]/div/form/div[5]/button缺…...

【youcans论文精读】弱监督深度检测网络(Weakly Supervised Deep Detection Networks)
欢迎关注『youcans论文精读』系列 本专栏内容和资源同步到 GitHub/youcans 【youcans论文精读】弱监督深度检测网络 WSDDN 0. 弱监督检测的开山之作0.1 论文简介0.2 WSDNN 的步骤0.3 摘要 1. 引言2. 相关工作3. 方法3.1 预训练网络3.2 弱监督深度检测网络3.3 WSDDN训练3.4 空间…...

网络购物谨慎使用手机免密支付功能
在数字经济蓬勃发展的当下,“免密支付”成为许多人消费时的首选支付方式。 “免密支付”的存在有其合理性。在快节奏的现代生活中,时间愈发珍贵,每节省一秒都可能带来更高的效率。以日常通勤为例,上班族乘坐交通工具时,…...

Sentinel[超详细讲解]-4
🚓 主要讲解流控模式的 三种方式中的两种: 直接、链路🚀 1️⃣ 直接模式 🚎 直接模式:对资源本身进行限流,例如对某个接口进行限流,当该接口的访问频率超过设定的阈值时,直接拒绝新的…...

【服务日志链路追踪】
MDCInheritableThreadLocal和spring cloud sleuth 在微服务架构中,日志链路追踪(Logback Distributed Tracing) 是一个关键需求,主要用于跟踪请求在不同服务间的调用链路,便于排查问题。常见的实现方案有两种&#x…...

【行测】判断推理:图形推理
> 作者:დ旧言~ > 座右铭:读不在三更五鼓,功只怕一曝十寒。 > 目标:掌握 图形推理 基本题型,并能运用到例题中。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! …...
用于计算图像或矩阵的平均值函数mean())
OpenCV 图形API(12)用于计算图像或矩阵的平均值函数mean()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 计算矩阵元素的平均值(均值)。 mean函数计算矩阵元素的平均值M,每个通道独立计算,并返回该值。 …...
:DML触发器)
Oracle触发器使用(一):DML触发器
Oracle触发器使用(一):DML触发器 DML触发器条件谓词触发器INSTEAD OF DML触发器复合DML触发器Oracle数据库中的触发器(Trigger)本质上也是PL/SQL代码,触发器可以被Enable或者Disable,但是不能像存储过程那样被直接调用执行。 触发器不能独立存在,而是定义在表、视图、…...

3D模型给可视化大屏带来了哪些创新,都涉及到哪些技术栈。
一、3D 模型给可视化大屏带来的创新 更直观的视觉体验 传统的可视化大屏主要以二维图表和图形的形式展示数据,虽然能够传达一定的信息,但对于复杂的场景和数据关系,往往难以直观地呈现。而 3D 模型可以将数据以三维立体的形式展示出来&#…...

Unity HDRP管线用ShaderGraph还原Lit,方便做拓展;
里面唯一的重点就是判断有无这张复合图,我用的是颜色判断: float Tex TexCol.r*TexCol.g*TexCol.b*TexCol.a; if(Tex 1) { IsOrNot 1; } else { IsOrNot 0; } 其他的正常解码就行,对了法线贴图孔位记得设置成normal,不然的话…...

绝缘升级 安全无忧 金能电力环保绝缘胶垫打造电力安全防护新标杆
在电力安全领域,一块看似普通的胶垫,却是守护工作人员生命安全的“第一道防线”。近年来,随着电网设备升级和环保要求趋严,传统绝缘胶垫有异味、易老化、绝缘性能不足等问题逐渐暴露。为此,金能电力凭借技术创新推出新…...