LLaMA-Factory大模型微调全流程指南
该文档为LLaMA-Factory大模型微调提供了完整的技术指导,涵盖了从环境搭建到模型训练、推理和合并模型的全流程,适用于需要进行大模型预训练和微调的技术人员。
一、docker 容器服务
请参考如下资料制作 docker 容器服务,其中,挂载的目录关系如下:
1、制作 docker 容器服务的资料列表
- 《基于docker的LLaMA-Factory全流程部署指南》
2、挂载目录列表
| 宿主机目录 | 容器目录(如:docker) |
|---|---|
| ./LLaMA-Factory/hf_cache | /root/.cache/huggingface |
| ./LLaMA-Factory/ms_cache | /root/.cache/modelscope |
| ./LLaMA-Factory/om_cache | /root/.cache/openmind |
| ./LLaMA-Factory/data | /app/data |
| ./LLaMA-Factory/output | /app/output |
二、下载模型
前往 ModelScope 下载模型,以 Qwen/Qwen2.5-3B-Instruct 模型举例,获取模型下载地址。
# 执行下面的命令,根据您的实际情况选择不同的下载方式
# 以 modelscope 方式下载(注:宿主机目录 )
# modelscope download --model Qwen/Qwen2.5-3B-Instruct README.md --local_dir ./LLaMA-Factory/ms_cache/Qwen2.5-3B-Instruct
# 以 git 方式下载(注:宿主机目录 )
git clone https://www.modelscope.cn/Qwen/Qwen2.5-3B-Instruct.git ./LLaMA-Factory/ms_cache/Qwen2.5-3B-Instruct
三、准备待微调数据
准备待微调的数据,假设已经创建文件 ./LLaMA-Factory/data/alpaca_zh_test.json(注:宿主机目录 ) 且 已经添加内容如下:
注:该 json 文件编码格式必须为UTF-8,否则,训练的模型输出内容会乱码,在linux环境可以执行file -i ./LLaMA-Factory/data/alpaca_zh_test.json 命令判断文件编码类型。
[{"instruction": "正式礼貌询问","input": "您好,能否请您详细做一下自我介绍呢?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "日常随意询问","input": "嘿,来跟我说说你自己呗","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "好奇探索式询问","input": "我很好奇,你能讲讲自己是个怎样的存在吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "开门见山式询问","input": "介绍下你自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "委婉请求式询问","input": "不知是否方便,能请您做个自我介绍吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "引导式询问","input": "想必你有很多特别之处,能给我讲讲自己吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "友好互动式询问","input": "哈喽,我们认识一下,你能介绍下自己吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌请教式询问","input": "您好,想请教下您能做个自我介绍吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "轻松调侃式询问","input": "嘿,快自报家门啦","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "好奇追问式询问","input": "我对您很好奇,您能详细说说自己吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "简洁命令式询问","input": "做个自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌邀请式询问","input": "您好,诚挚邀请您做个自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "温和建议式询问","input": "要不您给我讲讲自己吧","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "俏皮询问","input": "嘿,小可爱,介绍下自己呗","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "期待式询问","input": "好期待了解您,能做个自我介绍吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "试探式询问","input": "我想了解下您,不知能否做个自我介绍?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "尊重式询问","input": "尊敬的您,能做个自我介绍让我认识下吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "热情询问","input": "哇,好激动,快介绍下你自己呀","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "委婉好奇式询问","input": "有点好奇您的情况,能给我讲讲吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌请求补充式询问","input": "您好,麻烦做个自我介绍,详细些更好哦","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "轻松聊天式询问","input": "咱聊聊,你先介绍下自己呗","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "直截了当初识询问","input": "初次交流,介绍下你自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌询问用途式","input": "您好,能介绍下自己以及您能做什么吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "日常交流式询问","input": "嘿,跟我说说你是干嘛的,顺便介绍下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "正式商务式询问","input": "您好,在开展交流前,烦请您做个自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "友好好奇式询问","input": "你好呀,我很好奇你,能介绍下自己不?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "温和请求式询问","input": "可以请您介绍下自己吗,非常感谢","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "俏皮活泼式询问","input": "哈喽呀,快蹦出你的自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "期待好奇式询问","input": "好期待你介绍自己,快说说吧","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌求知式询问","input": "您好,想学习了解下您,能做个自我介绍吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "轻松调侃好奇式询问","input": "嘿,神秘的你,快揭秘下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "简洁直接式询问","input": "介绍下自己,谢谢","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌邀请详细式询问","input": "您好,邀请您详细介绍下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "温和建议友好式询问","input": "要不你友好地介绍下自己呀","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "俏皮可爱式询问","input": "小可爱,快亮出你的自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "期待热情式询问","input": "超级期待你热情介绍自己,快开始吧","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "试探礼貌式询问","input": "我想进一步认识您,不知能否麻烦您介绍下自己?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "尊重正式式询问","input": "尊敬的您,在交流前请您做个正式自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "热情友好式询问","input": "哇哦,友好地介绍下你自己吧","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "委婉好奇深入式询问","input": "有点好奇您更深入的情况,能详细讲讲自己吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌请求丰富式询问","input": "您好,麻烦丰富地介绍下自己,谢谢","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "轻松聊天深入式询问","input": "咱深入聊聊,你先详细介绍下自己呗","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "直截了当初次交流式询问","input": "初次交流,全面介绍下你自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌询问多方面式","input": "您好,能介绍下自己以及您擅长的方面吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "日常交流深入式询问","input": "嘿,深入跟我说说你是干嘛的,顺便好好介绍下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "正式商务详细式询问","input": "您好,在合作探讨前,烦请您详细做个自我介绍","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "友好好奇全面式询问","input": "你好呀,我很好奇你各方面情况,能全面介绍下自己不?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "温和请求细致式询问","input": "可以请您细致介绍下自己吗,十分感谢","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "俏皮活泼丰富式询问","input": "哈喽呀,快用丰富的方式介绍下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "期待好奇全面式询问","input": "好期待你全面介绍自己,赶紧的","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "礼貌求知深入式询问","input": "您好,想深入学习了解下您,能详细做个自我介绍吗?","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "轻松调侃好奇深入式询问","input": "嘿,神秘的你,快深入揭秘下自己","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"},{"instruction": "简洁直接详细式询问","input": "详细介绍下自己,谢谢","output": "我是人工智能模型小智同学,具备多种能力,不管是知识问答还是内容创作等方面的问题,都可以问我。"}
]
在 ./LLaMA-Factory/data/dataset_info.json (注:宿主机目录 ) 文件里面添加数据集信息,假设已经创建该文件且添加内容如下:
{"alpaca_zh_test": {"file_name": "alpaca_zh_test.json","formatting":"alpaca","columns": {"prompt":"instruction","query": "input","response": "output"}}
}
注:alpaca_zh_test.json 必须跟 dataset_info.json 放在同一个目录下,否则会找不到文件。
四、训练及测试
1、命令行方式
在 ./LLaMA-Factory/data/alpaca_zh_test_train.yaml (注:宿主机目录 ) 文件里面添加用于【模型微调】的配置参数,假设已经创建该文件且添加内容如下:
# ========== 基础训练配置 ==========
# 训练阶段类型:指令监督微调(SFT)
stage: sft
# 启用训练模式(必须开启以启动训练流程)
do_train: true
# 模型权重路径(Hugging Face标识符或本地路径【注:容器目录】,需确保与模板匹配)
model_name_or_path: /root/.cache/modelscope/Qwen2.5-3B-Instruct
# 对话模板(Qwen系列必须使用default模板,否则影响对话格式)
template: default# ========== 数据集配置 ==========
# 数据集配置文件目录【注:容器目录】
dataset_dir: data
# 注册数据集名称(支持多个数据集逗号分隔)
dataset: alpaca_zh_test
# 文本处理最大长度(超过此值触发截断,长文本任务建议8192)
cutoff_len: 2048
# 最大训练样本数(用于限制大规模数据集内存占用)
max_samples: 100000# ========== 训练参数 ==========
# 单卡批次大小(4090显卡建议2到4,根据显存调整)
per_device_train_batch_size: 2
# 梯度累积(等效总批次=2*8=16,显存不足时优先调高此值)
gradient_accumulation_steps: 8
# 训练轮次(建议至少3轮,复杂任务需50+轮)
num_train_epochs: 50
# 初始学习率(LoRA建议0.00005,全参数微调建议0.00001)
learning_rate: 0.00005
# 学习率调度器(稳定收敛首选,对比step需配置warmup)
lr_scheduler_type: cosine
# 梯度裁剪阈值(防止梯度爆炸,常规任务建议0.5-1.0)
max_grad_norm: 1.0
# 优化器类型(优先选torch原生优化器)
optim: adamw_torch
# 首次训练/全新任务时设为false
resume_from_checkpoint: false
# 常规任务建议开启以优化内存
remove_unused_columns: true# ========== LoRA配置 ==========
# 微调策略(LoRA比QLoRA精度更高,4-bit量化选QLoRA),【注:如果是预训练模型,必须选择full】
finetuning_type: lora
# 矩阵分解维度(默认8,效果不足时可升到16)
lora_rank: 8
# 缩放系数(建议为秩的2倍,过高易过拟合)
lora_alpha: 16
# 丢弃率(常规任务设为0,数据量少时可设0.1)
lora_dropout: 0.0
# 作用模块(Qwen模型默认作用于c_attn,attn.c_proj等线性层)
lora_target: all# ========== 硬件加速配置 ==========
# 混合精度训练(A100/V100等支持BF16的显卡必开启)
bf16: true
# 自动启用FlashAttention(长序列任务显存降低30%)
flash_attn: auto
# 数据预处理线程数(建议等于CPU核数)
preprocessing_num_workers: 16
# 分布式训练超时(多卡训练需调高,单位毫秒)
ddp_timeout: 180000000# ========== 日志与模型输出 ==========
# 输出目录【注:容器目录】(含检查点和日志)
output_dir: saves/Qwen2.5-3B-Instruct/lora/train_000000001
# 覆盖已有输出目录
overwrite_output_dir: true
# 日志记录间隔(调试时建议1,常规训练5-10)
logging_steps: 5
# 模型保存间隔(根据存储空间调整,频繁保存影响速度)
save_steps: 100
# 生成损失曲线图(用于监控过拟合/欠拟合)
plot_loss: true# ========== 高级配置 ==========
# 信任远程代码(加载自定义模型结构时必须开启)
trust_remote_code: true
# 新增适配器(多任务训练时设为True防覆盖)
create_new_adapter: false
# 统计处理token数(用于计算训练成本)
include_num_input_tokens_seen: true
在 ./LLaMA-Factory/data/alpaca_zh_test_chat.yaml (注:宿主机目录 ) 文件里面添加用于【模型推理】的配置参数,假设已经创建该文件且添加内容如下:
# 模型权重路径(Hugging Face标识符或本地路径【注:容器目录】,需确保与模板匹配)
model_name_or_path: /root/.cache/modelscope/Qwen2.5-3B-Instruct
# 输出目录【注:容器目录】(含检查点和日志)
adapter_name_or_path: saves/Qwen2.5-3B-Instruct/lora/train_000000001
# 对话模板(Qwen系列必须使用default模板,否则影响对话格式)
template: default
# 推理引擎(huggingface/vllm)
infer_backend: huggingface
# 信任远程代码(加载自定义模型结构时必须开启)
trust_remote_code: true
在 ./LLaMA-Factory/data/alpaca_zh_test_export.yaml (注:宿主机目录 ) 文件里面添加用于【模型合并】的配置参数,假设已经创建该文件且添加内容如下:
# ========== 模型配置 ==========
# 模型权重路径(Hugging Face标识符或本地路径【注:容器目录】,需确保与模板匹配)
model_name_or_path: /root/.cache/modelscope/Qwen2.5-3B-Instruct
# 输出目录【注:容器目录】(含检查点和日志)
adapter_name_or_path: saves/Qwen2.5-3B-Instruct/lora/train_000000001
# 对话模板(Qwen系列必须使用default模板,否则影响对话格式)
template: default
# 信任远程代码(加载自定义模型结构时必须开启)
trust_remote_code: true# ========== 合并输出配置 ==========
# 必须修改:合并模型的输出目录(保存LoRA合并后的完整模型)
export_dir: output/Qwen2.5-3B-Instruct-new
# 单文件最大体积(单位:GB),超过时分割存储(默认值:2)
export_size: 5
# 导出设备类型(显存不足时设为cpu,可用gpu加速导出过程)
export_device: cpu
# 是否导出为旧版格式(兼容老版本推理框架需设为true)
export_legacy_format: false# ========== 导出量化配置 ==========
# 支持的量化位数枚举值:4(INT4)、8(INT8),仅限GPTQ等后训练量化方法使用
# export_quantization_bit: 4
# 量化校准数据集路径(JSON格式),需包含与目标任务匹配的数据分布
# export_quantization_dataset: data/c4_demo.json注:以上三个文件建议跟 ./LLaMA-Factory/data/dataset_info.json 放在同一个目录下。
在宿主机的控制台执行该命令 docker exec -it llamafactory /bin/bash 进入 docker 容器,并且,在 docker 容器执行如下命令:
# 模型微调
llamafactory-cli train /app/data/alpaca_zh_test_train.yaml
# 模型推理
llamafactory-cli chat /app/data/alpaca_zh_test_chat.yaml
# 模型合并
llamafactory-cli export /app/data/alpaca_zh_test_export.yaml
2、WEB方式
请在浏览器中访问 http://localhost:7860/ ,即可访问 LLaMA-Factory 的 WEB 服务。
模型微调:除了用箭头标志的地方需要修改,其他地方建议使用默认值。



模型微调:除了用箭头标志的地方需要修改,其他地方建议使用默认值。


相关文章:
LLaMA-Factory大模型微调全流程指南
该文档为LLaMA-Factory大模型微调提供了完整的技术指导,涵盖了从环境搭建到模型训练、推理和合并模型的全流程,适用于需要进行大模型预训练和微调的技术人员。 一、docker 容器服务 请参考如下资料制作 docker 容器服务,其中,挂…...

为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统
为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统 在芯片半导体行业,严格的合规性要求、复杂的供应链协同及高精度质量管理是核心挑战。全星研发项目管理APQP系统专为高门槛制造业设计,深度融合APQP五大阶段(从设…...

Linux make 检查依赖文件更新的原理
1. 文件的时间戳 make 主要依靠文件的时间戳来判断依赖文件是否有更新。每个文件在文件系统中都有一个时间戳,记录了文件的三种重要时间: 访问时间(Accesstime):文件最后一次被访问的时间。修改时间&…...

vulkanscenegraph显示倾斜模型(5.6)-vsg::RenderGraph的创建
前言 上一章深入分析了vsg::CommandGraph的创建过程及其通过子场景遍历实现Vulkan命令录制的机制。本章将在该基础上,进一步探讨Vulkan命令录制中的核心封装——vsg::RenderGraph。作为渲染流程的关键组件,RenderGraph封装了vkCmdBeginRenderPass和vkCmd…...
深度解析与优化之道)
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道 引言 Python,这门以简洁和优雅著称的编程语言,自诞生以来在 Web 开发、数据分析、人工智能等领域大放异彩。然而,Python 的多线程性能却常被诟病,其核心原因之一便是全局解释器锁(Global Interpreter …...

基于阿里云可观测产品构建企业级告警体系的通用路径与最佳实践
前言 1.1 日常生活中的告警 任何连续稳定运行的生产系统都离不开有效的监控与报警机制。通过监控,我们可以实时掌握系统和业务的运行状态;而报警则帮助我们及时发现并响应监控指标及业务中的异常情况。 在日常生活中,我们也经常遇到各种各样…...
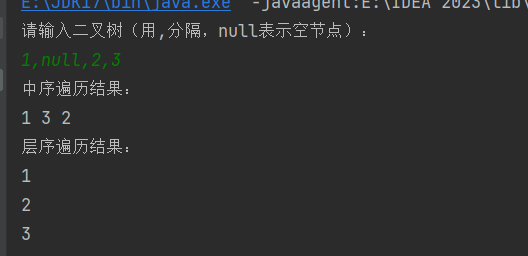
二叉树的ACM板子(自用)
package 二叉树的中序遍历;import java.util.*;// 定义二叉树节点 class TreeNode {int val; // 节点值TreeNode left; // 左子节点TreeNode right; // 右子节点// 构造函数TreeNode(int x) {val x;} }public class DMain {// 构建二叉树(层序遍历方式&…...

架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录 Pre引言案例何谓查询分离?何种场景下使用查询分离?查询分离实现思路1. 如何触发查询分离?方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。方式二:修改业务代码:…...

Qt进阶开发:QFileSystemModel的使用
文章目录 一、QFileSystemModel的基本介绍二、QFileSystemModel的基本使用2.1 在 QTreeView 中使用2.2 在 QListView 中使用2.3 在 QTableView 中使用 三、QFileSystemModel的常用API3.1 设置根目录3.2 过滤文件3.2.1 仅显示文件3.2.2 只显示特定后缀的文件3.2.3 只显示目录 四…...

后端开发常见的面试问题
目录 编程语言 python Linux环境 web框架 数据处理与分析 数据库 图数据库 什么是图数据库?它与传统关系型数据库有什么区别? 图数据库中的节点、边和属性分别代表什么? 常见的图数据库有哪些?它们各自有什么特点&#…...

List结构之非实时榜单实战
像京东、淘宝等电商系统一般都会有热销的商品榜单,比如热销手机榜单,热销电脑榜单,这些都是非实时的榜单。为什么是非实时的呢?因为完全实时的计算和排序对于资源消耗较大,尤其是当涉及大量交易数据时。 一般来说&…...
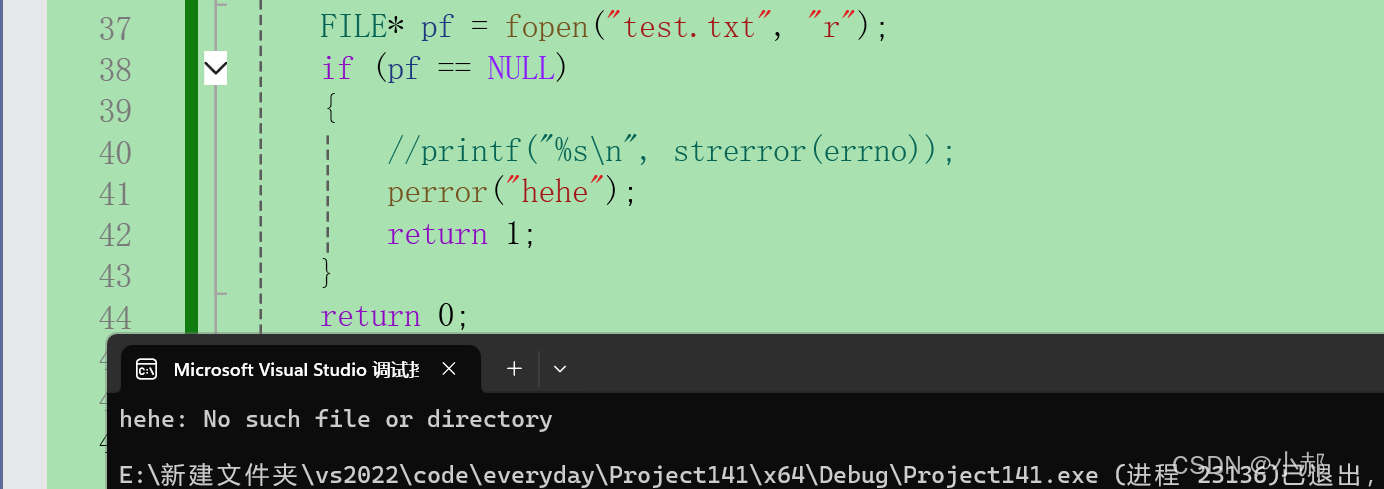
【C语言】字符串处理函数:strtok和strerror
在C语言中,字符串处理是编程的基础之一。本文将详细讲解两个重要的字符串处理函数:strtok和strerror 一、strtok函数 strtok函数用于将字符串分割成多个子串,这些子串由指定的分隔符分隔。其原型定义如下: char *strtok(char *s…...

如何提升后端开发效率:从Spring Boot到微服务架构
在现代软件开发中,后端开发的效率直接决定了项目的成败。随着技术的快速发展,Spring Boot、微服务架构、Docker等工具和技术已经成为提升后端开发效率的核心利器。在这篇文章中,我们将探讨如何通过使用Spring Boot及微服务架构来提升开发效率…...

go语言:开发一个最简单的用户登录界面
1.用deepseek生成前端页面: 1.提问:请你用html帮我设计一个用户登录页面,要求特效采用科技感的背景渲染加粒子流动,用css、div、span标签,并给出最终合并后的代码。 生成的完整代码如下: <!DOCTYPE h…...

基于 .NET 8 + Lucene.Net + 结巴分词实现全文检索与匹配度打分实战指南
文章目录 前言一、技术选型与优势1.1 技术栈介绍1.2 方案优势 二、环境搭建与配置2.1 安装 NuGet 包2.2 初始化核心组件 三、索引创建与文档管理3.1 构建索引3.2 动态更新策略 四、搜索与匹配度排序4.1 执行搜索4.2 自定义评分算法(扩展) 五、高级优化技…...

Docker安装、配置Nacos
1.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:nacos:image: nacos/nacos-server:v2.1.1container_name: nacos2ports:- "8848:8848"- "9848:9848"environment:- MODEstandalone…...
《Maven高级应用:继承聚合设计与私服Nexus实战指南》
一、 Maven的继承和聚合 1.什么是继承 Maven 的依赖传递机制可以一定程度上简化 POM 的配置,但这仅限于存在依赖关系的项目或模块中。当一个项目的多个模块都依赖于相同 jar 包的相同版本,且这些模块之间不存在依赖关系,这就导致同一个依赖…...

重要头文件下的函数
1、<cctype> #include<cctype>加入这个头文件就可以调用以下函数: 1、isalpha(x) 判断x是否为字母 isalpha 2、isdigit(x) 判断x是否为数字 isdigit 3、islower(x) 判断x是否为小写字母 islower 4、isupper(x) 判断x是否为大写字母 isupper 5、isa…...
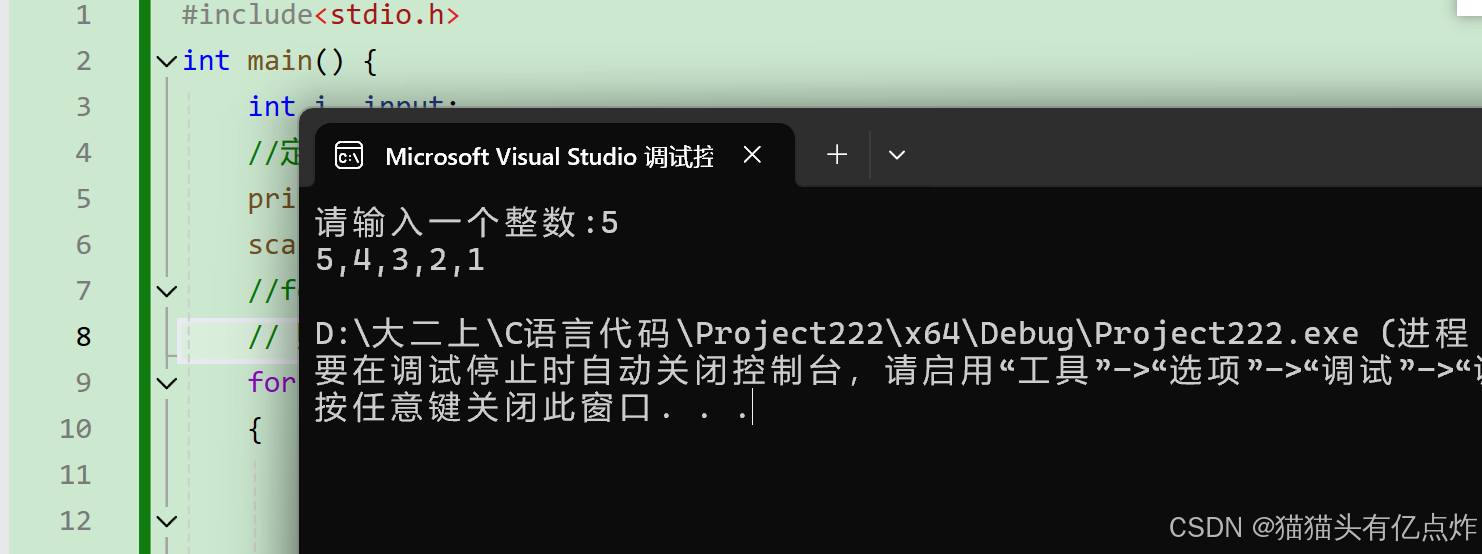
C语言数字分隔题目
一、题目引入 编写一个程序,打印出从用户输入的数字开始,递减到1的序列。要求每次打印一行,数字之间用逗号分隔,最后一个数字后面没有逗号。 二、代码展示 三、运行结果 四、思路分析 1.先用一个for循环对输入的数字进行递减 2.再对for循环里面的数字进行筛选 如果大于1 …...

DigitalOcean 发布 AMD Instinct MI300X GPU 裸金属服务器
DigitalOcean 宣布现已提供 AMD Instinct MI300X GPU,并搭载 ROCm 软件,以支持用户的 AI 任务。 在 DigitalOcean,我们致力于为你的项目提供更多选择。AMD Instinct MI300X 是目前带宽最高的 GPU 之一(5.3 TB/s 的 HBM3 内存带宽&…...
)
CentOS 7 镜像源失效解决方案(2025年)
执行 yum update 报错: yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirror…...

应对高并发的根本挑战:思维转变【大模型总结】
以下是对这篇技术总结的详细解析,以分步说明的形式呈现,帮助理解亿万并发场景下的核心策略与创新思维: 一、应对高并发的根本挑战:思维转变 1. 传统架构的局限 问题:传统系统追求零故障和强一致性,但在海…...

ARM-外部中断,ADC模数转换器
根据您提供的图片,我们可以看到一个S3C2440微控制器的中断处理流程图。这个流程图展示了从中断请求源到CPU的整个中断处理过程。以下是流程图中各个部分与您提供的寄存器之间的关系: 请求源(带sub寄存器): 这些是具体的…...
git克隆数据失败
场景:当新到一家公司,然后接手了上一个同时的电脑,使用git克隆代码一直提示无法访问,如图 原因:即使配置的新的用户信息。但是window记录了上一个同事的登录信息,上一个同事已经被剔除权限,再拉…...
自动化备份全网服务器数据平台
自动化备份全网服务器数据平台 项目背景知识 总体需求 某企业里有一台Web服务器,里面的数据很重要,但是如果硬盘坏了数据就会丢失,现在领导要求把数据做备份,这样Web服务器数据丢失在可以进行恢复。要求如下:1.每天0…...

大模型如何优化数字人的实时交互与情感表达
标题:大模型如何优化数字人的实时交互与情感表达 内容:1.摘要 随着人工智能技术的飞速发展,数字人在多个领域的应用愈发广泛,其实时交互与情感表达能力成为提升用户体验的关键因素。本文旨在探讨大模型如何优化数字人的实时交互与情感表达。通过分析大模…...

AI Agent系列(八) -基于ReAct架构的前端开发助手(DeepSeek)
AI Agent系列【八】 项目目标一、核心功能设计二、技术栈选择三、Python实现3.1 设置基础环境3.2 定义AI前端生成的类3.4 实例化3.5 Flask路由3.6 主程序执行 四、 功能测试 项目目标 开发一个能够协助HTMLJSCSS前端设计的AI Agent,通过在网页中输入相应的问题&am…...

二级索引详解
二级索引详解 二级索引(Secondary Index)是数据库系统中除主键索引外的附加索引结构,用于加速基于非主键列的查询操作。以下是关于二级索引的全面解析: 一、核心概念 特性主键索引 (Primary Index)二级索引 (Secondary Index)唯一性必须唯一可以唯一或非唯一数量每表只有…...
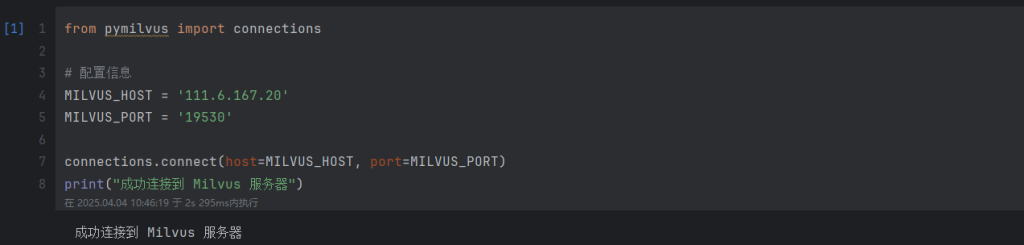
一文学会云服务器配置Milvus向量数据库
服务器准备 首先,我们需要进行服务器的准备,这里准备的是RTX-4090服务器 连接我们已经创建好的服务器,这里可使用MobaXterm进行ssh连接 ssh funhpcIP地址 一键完成Docker配置 注:docker的旧版本不一定被称为docker,doc…...
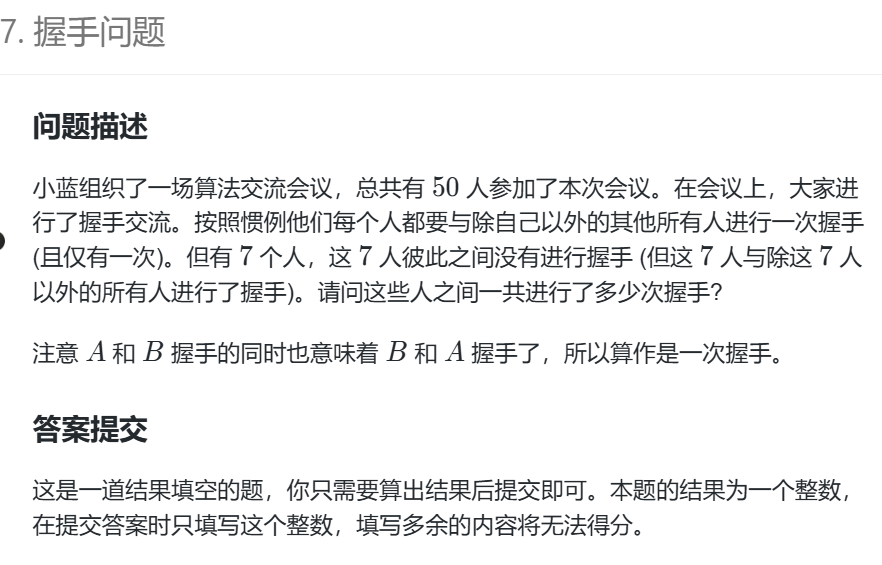
19685 握手问题
19685 握手问题 ⭐️难度:简单 🌟考点:2024、省赛、数学 📖 📚 package test ;import java.util.Scanner; public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);…...