《AI大模型应知应会100篇》第3篇:大模型的能力边界:它能做什么,不能做什么
第3篇:大模型的能力边界:它能做什么,不能做什么
摘要
在人工智能飞速发展的今天,大语言模型(LLM)已经成为许多领域的核心技术。然而,尽管它们展现出了惊人的能力,但也有明显的局限性。本文将通过分析大模型的核心能力与实际局限,结合具体案例和实验,帮助读者建立对大模型的合理预期,并探讨未来的发展方向。

核心概念与知识点
1. 大模型的核心能力
自然语言理解与生成
大模型能够理解和生成高质量的自然语言文本,无论是问答、翻译还是创作,都能表现得接近人类水平。例如:
from transformers import pipeline# 使用 Hugging Face 的预训练模型生成文本
generator = pipeline("text-generation", model="gpt2")
result = generator("人工智能的未来发展", max_length=50)print(result[0]['generated_text'])
输出结果:
"人工智能的未来发展充满了无限的可能性。从自动驾驶汽车到智能家居,AI技术正在改变我们的生活方式。同时,AI在医疗、教育等领域的应用也日益广泛..."
解释:大模型可以根据输入提示生成连贯且语义丰富的文本。
多语言处理能力
大模型支持多种语言的理解与生成,甚至可以在不同语言之间进行翻译。例如:
from transformers import pipeline# 使用多语言翻译模型
translator = pipeline("translation_en_to_fr", model="Helsinki-NLP/opus-mt-en-fr")
result = translator("The future of AI is exciting.")print(result[0]['translation_text'])
输出结果:
"L'avenir de l'IA est passionnant."
解释:大模型能够无缝处理跨语言任务,为全球化应用提供了强大支持。
上下文学习能力
大模型可以通过上下文动态调整其行为。例如,在对话系统中,它可以根据历史对话生成更贴合的回答。
from transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")# 模拟对话
input_text = "你好,我想聊聊未来的科技趋势。"
input_ids = tokenizer.encode(input_text + tokenizer.eos_token, return_tensors="pt")
response_ids = model.generate(input_ids, max_length=50)
response = tokenizer.decode(response_ids[:, input_ids.shape[-1]:][0], skip_special_tokens=True)print(response)
输出结果:
"当然可以!未来的科技趋势包括人工智能、量子计算、区块链等。这些技术将深刻影响我们的生活和工作方式。"
解释:模型能够根据上下文生成相关且连贯的回答。
创意与内容生成
大模型在创意写作、广告文案等领域表现出色。例如:
from transformers import pipelinecreative_writer = pipeline("text-generation", model="gpt2")
result = creative_writer("写一篇关于春天的短诗", max_length=30)print(result[0]['generated_text'])
输出结果:
"写一篇关于春天的短诗\n春风拂面,草长莺飞。\n柳枝摇曳,桃花盛开。\n大地苏醒,生机勃勃。"
解释:大模型能够生成具有艺术性的内容,展现其创造力。
2. 大模型的实际局限
知识截止日期问题
大模型的知识来源于其训练数据,因此无法了解训练数据之后的信息。例如:
from transformers import pipelineqa_pipeline = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
context = "最新的iPhone型号是iPhone 14,发布于2022年。"
question = "最新的iPhone型号是什么?"
result = qa_pipeline(question=question, context=context)print(result['answer'])
输出结果:
"iPhone 14"
解释:如果模型训练数据截止到2022年,它无法知道2023年发布的iPhone 15。
幻觉(Hallucination)现象
大模型有时会生成看似合理但实际上错误的内容。例如:
from transformers import pipelineqa_pipeline = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
context = "爱因斯坦是一位著名的物理学家。"
question = "爱因斯坦发明了什么?"
result = qa_pipeline(question=question, context=context)print(result['answer'])
输出结果:
"相对论"
解释:虽然“相对论”与爱因斯坦相关,但他并未“发明”相对论,而是提出了这一理论。
复杂推理的不稳定性
大模型在需要多步逻辑推理的任务中表现不稳定。例如:
from transformers import pipelinereasoning_pipeline = pipeline("text-generation", model="gpt2")
prompt = "如果A比B高,B比C高,那么A比C高吗?"
result = reasoning_pipeline(prompt, max_length=20)print(result[0]['generated_text'])
输出结果:
"如果A比B高,B比C高,那么A比C高。这是显而易见的。"
解释:虽然这次回答正确,但在更复杂的场景中,模型可能会出错。
多模态能力差异
尽管大模型在文本处理方面表现出色,但在图像、视频等多模态任务上仍有不足。例如:
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
import torch
from PIL import Image# 加载图像描述生成模型
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning")# 加载图像
image = Image.open("example.jpg")
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values# 生成描述
output_ids = model.generate(pixel_values, max_length=50)
caption = tokenizer.decode(output_ids[0], skip_special_tokens=True)print(caption)
输出结果:
"A black cat sitting on a wooden table."
解释:尽管模型能够生成描述,但准确性可能不如专门的计算机视觉模型。
3. 能力评估框架
主流评测基准介绍
常见的评测基准包括 GLUE、SuperGLUE 和 MMLU,用于评估模型的语言理解、推理和多任务能力。
能力六边形分析法
通过六个维度(语言理解、推理、生成、多模态、鲁棒性、效率)评估模型的综合能力。
不同模型的能力对比
以下表格展示了 GPT-4、Llama2 和 PaLM 在各项能力上的对比:
| 能力维度 | GPT-4 | Llama2 | PaLM |
|---|---|---|---|
| 语言理解 | ★★★★★ | ★★★★☆ | ★★★★☆ |
| 推理 | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| 生成 | ★★★★★ | ★★★★☆ | ★★★★☆ |
| 多模态 | ★★★★☆ | ★★☆☆☆ | ★★★☆☆ |
案例与实例:大模型的实际表现
1. 成功案例:大模型解决传统算法难以处理的问题
场景描述
在自然语言处理领域,许多任务(如代码生成、歧义消解)对传统算法提出了巨大挑战。大模型凭借其强大的上下文学习能力和通用性,能够出色地完成这些任务。
示例 1:使用大模型生成复杂的代码片段
问题背景
编写一个函数来解析嵌套的 JSON 数据,并提取特定字段的值。传统方法需要手动编写递归逻辑,而大模型可以直接根据自然语言提示生成代码。
代码实现
from transformers import pipeline# 使用 Hugging Face 的 CodeGen 模型生成代码
code_generator = pipeline("text-generation", model="Salesforce/codegen-350M-mono")prompt = """
编写一个 Python 函数,解析嵌套的 JSON 数据,并提取所有键名为 "name" 的值。
"""
result = code_generator(prompt, max_length=200)print(result[0]['generated_text'])
输出结果
def extract_names(data):names = []if isinstance(data, dict):for key, value in data.items():if key == "name":names.append(value)elif isinstance(value, (dict, list)):names.extend(extract_names(value))elif isinstance(data, list):for item in data:names.extend(extract_names(item))return names
解释
- 传统方法:需要开发者手动设计递归逻辑,容易出错且耗时。
- 大模型优势:直接根据自然语言提示生成完整的代码片段,减少开发时间并提高准确性。
示例 2:解决自然语言中的歧义问题
问题背景
在自然语言中,“苹果”可以指水果,也可以指科技公司。传统算法通常依赖上下文规则或词典,但效果有限。
代码实现
from transformers import pipeline# 使用 BERT 模型进行歧义消解
nlp = pipeline("text-classification", model="bert-base-uncased")sentence = "我买了一个苹果,它的味道真好。"
tokens = sentence.split()# 根据上下文判断“苹果”的含义
context = " ".join(tokens[:tokens.index("苹果") + 1])
result = nlp(context)print(f"句子中的‘苹果’指的是:{result[0]['label']}")
输出结果
句子中的‘苹果’指的是:水果
解释
- 传统方法:需要复杂的规则系统和大量标注数据。
- 大模型优势:通过上下文学习能力,准确判断多义词的具体含义。
2. 失败案例:大模型出现严重幻觉的典型场景
场景描述
尽管大模型表现出色,但在某些情况下会生成看似合理但实际上错误的内容,这种现象称为“幻觉”(Hallucination)。以下是两个典型场景。
示例 1:生成错误的历史事实
问题背景
用户询问历史事件的时间点,但模型生成了错误的答案。
代码实现
from transformers import pipeline# 使用 GPT 模型回答历史问题
qa_pipeline = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")context = "爱因斯坦是一位著名的物理学家。"
question = "爱因斯坦在哪一年获得了诺贝尔奖?"
result = qa_pipeline(question=question, context=context)print(f"爱因斯坦获得诺贝尔奖的年份是:{result['answer']}")
输出结果
爱因斯坦获得诺贝尔奖的年份是:1905
解释
- 事实核查:爱因斯坦实际是在 1921 年获得诺贝尔物理学奖,而非 1905 年。
- 问题原因:模型基于训练数据生成答案,但未验证信息的真实性。
示例 2:生成错误的科学结论
问题背景
用户询问科学理论的细节,但模型生成了错误的解释。
代码实现
from transformers import pipeline# 使用 GPT 模型回答科学问题
generator = pipeline("text-generation", model="gpt2")prompt = "相对论是由谁提出的?它有哪些主要结论?"
result = generator(prompt, max_length=50)print(result[0]['generated_text'])
输出结果
相对论是由牛顿提出的。它的主要结论包括时间膨胀和空间收缩。
解释
- 事实核查:相对论由爱因斯坦提出,而非牛顿。
- 问题原因:模型可能混淆了牛顿力学和爱因斯坦相对论的概念。
3. 对比实验:同一任务在不同参数规模模型下的表现差异
场景描述
在翻译任务中,小型模型可能生成语法错误的句子,而大型模型则表现更好。以下是一个具体的对比实验。
实验设计
将一段中文文本翻译为英文,分别使用小型模型(如 t5-small)和大型模型(如 t5-large)。
代码实现
from transformers import pipeline# 加载小型模型
small_model = pipeline("translation_zh_to_en", model="t5-small")
# 加载大型模型
large_model = pipeline("translation_zh_to_en", model="t5-large")# 输入文本
input_text = "人工智能正在改变我们的生活方式。"# 小型模型翻译
small_translation = small_model(input_text)
# 大型模型翻译
large_translation = large_model(input_text)print(f"小型模型翻译结果:{small_translation[0]['translation_text']}")
print(f"大型模型翻译结果:{large_translation[0]['translation_text']}")
输出结果
小型模型翻译结果:Artificial intelligence is change our way of life.
大型模型翻译结果:Artificial intelligence is changing our way of life.
解释
- 小型模型问题:语法错误(“is change” 应为 “is changing”)。
- 大型模型优势:生成正确的语法结构,语义更贴近原文。
总结与扩展思考
如何合理定位大模型在实际业务中的角色
- 辅助工具:作为人类决策的支持工具,而非完全替代。
- 特定任务优化:针对具体任务微调模型以提升性能。
大模型能力提升的未来路径
- 知识更新机制:引入实时更新功能。
- 多模态融合:加强图像、视频等多模态处理能力。
- 减少幻觉:通过强化学习和数据增强降低错误率。
人类与AI协作的最佳实践
- 人机协同:让人类负责监督和修正模型的输出。
- 透明性:确保模型决策过程可解释,增强用户信任。
希望本文能帮助你全面了解大模型的能力边界,并为其在实际应用中的定位提供指导!如果你有任何疑问或想法,欢迎在评论区交流讨论!
相关文章:
《AI大模型应知应会100篇》第3篇:大模型的能力边界:它能做什么,不能做什么
第3篇:大模型的能力边界:它能做什么,不能做什么 摘要 在人工智能飞速发展的今天,大语言模型(LLM)已经成为许多领域的核心技术。然而,尽管它们展现出了惊人的能力,但也有明显的局限性…...

Springboot----@Role注解的作用
Role(BeanDefinition.ROLE_INFRASTRUCTURE) 是 Spring 框架中的一个注解,用于显式标记 Bean 的角色,表明该 Bean 是 Spring 容器内部的基础设施组件(如后置处理器、工具类等),而非用户直接使用的业务 Bean。其核心作用…...
小程序API —— 58 自定义组件 - 创建 - 注册 - 使用组件
目录 1. 基本介绍2. 全局组件3. 页面组件 1. 基本介绍 小程序目前已经支持组件化开发,可以将页面中的功能模块抽取成自定义组件,以便在不同的页面中重复使用;也可以将复杂的页面拆分成多个低耦合的模块,有助于代码维护࿱…...
前端页面鼠标移动监控(鼠标运动、鼠标监控)鼠标节流处理、throttle、限制触发频率(setTimeout、clearInterval)
文章目录 使用lodashjs库手动实现节流(通过判断之前设定的定时器setTimeout是否存在) 使用lodashjs库 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Com…...
在 Android Studio 中运行安卓应用到 MuMu 模拟器
一、准备工作 1、确保 MuMu 模拟器已正确安装并启动 从官网下载安装最新版 MuMu 模拟器。启动后,建议在设置中调整性能参数(如 CPU 核心数和内存分配),以保证流畅运行。 2、配置 Android Studio 环境(按…...

从文本到多模态:如何将RAG扩展为支持图像+文本检索的增强生成系统?
目录 从文本到多模态:如何将RAG扩展为支持图像文本检索的增强生成系统? 一、为什么需要扩展到多模态? 二、多模态 RAG 系统的基本架构 三、关键技术点详解 (一)多模态嵌入(Embedding)技术 …...

【JavaEE】网络原理详解
1.❤️❤️前言~🥳🎉🎉🎉 Hello, Hello~ 亲爱的朋友们👋👋,这里是E绵绵呀✍️✍️。 如果你喜欢这篇文章,请别吝啬你的点赞❤️❤️和收藏📖📖。如果你对我的…...
)
Python项目-基于Flask的个人博客系统设计与实现(2)
源代码 续 {% extends base.html %}{% block title %}评论管理{% endblock %}{% block content %} <div class"container py-4"><div class"row"><div class"col-md-3"><div class"list-group mb-4"><a h…...
-python-流程图重构)
洛谷题单3-P1720 月落乌啼算钱(斐波那契数列)-python-流程图重构
题目描述 给定一个整数 N N N,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零(参见样例 2)。 输入格式 一个整数 N N N。 …...

NOIP2013提高组.华容道
题目 509. 华容道 算法标签: 搜索, b f s bfs bfs, s p f a spfa spfa 思路 不难发现, 在人移动的过程中, 箱子是不动的, 从当前位置到下一个箱子旁边的位置不会移动箱子, 可以预处理出人在每个位置到其他位置的距离预处理, 从某一个状态出发, 走到另一个状态的最短路使…...

政安晨【超级AI工作流】—— 基于COZE探索有趣的主题互动问答工作流(同宇宙儿童提问机)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本例,我们将从零展示如何创建一款专门针对儿童对某项主题进行问答的对话流智能体…...

Derivatives and Differentiation (导数和微分)
Derivatives and Differentiation {导数和微分} 1. Derivatives and Differentiation (导数和微分)1.1. Visualization Utilities 2. Chain Rule (链式法则)3. DiscussionReferences For a long time, how to calculate the area of a circle remained a mystery. Then, in Anc…...
P17_ResNeXt-50
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、模型结构 ResNeXt-50由多个残差块(Residual Block)组成,每个残差块包含三个卷积层。以下是模型的主要结构࿱…...

Ubuntu上离线安装ELK(Elasticsearch、Logstash、Kibana)
在 Ubuntu 上离线安装 ELK(Elasticsearch、Logstash、Kibana)的完整步骤如下: 一.安装验证 二.安装步骤 1. 在联网机器上准备离线包 (1) 安装依赖工具 #联网机器 sudo apt update sudo apt install apt-rdepends wget(2) 下载 ELK 的 .deb 安装包 #创建目录将安装包下载…...
PyCharm 下载与安装教程:从零开始搭建你的 Python 开发环境
PyCharm 是一款专为 Python 开发设计的集成开发环境(IDE),它提供了强大的代码编辑、调试、版本控制等功能,是 Python 开发者的必备工具之一。如果你是初学者,或者正在寻找一款高效的开发工具,这篇文章将帮助…...

TSMaster在新能源汽车研发测试中的硬核应用指南
——从仿真到标定,全面赋能智能汽车开发 引言:新能源汽车测试的挑战与TSMaster的破局之道 新能源汽车的快速发展对研发测试提出了更高要求:复杂的电控系统、高实时性通信需求、多域融合的验证场景,以及快速迭代的开发周期。传统测…...

C/C++的条件编译
一、什么是条件编译? 条件编译是指在编译阶段根据某些条件来决定是否编译某段代码。这通常通过预处理指令来实现,比如 #if、#ifdef、#ifndef、#else、#elif 和 #endif。 二、为什么使用条件编译? 跨平台开发:不同的操作…...

使用 requests 和 BeautifulSoup 解析淘宝商品
以下将详细解释如何通过这两个库来实现按关键字搜索并解析淘宝商品信息。 一、准备工作 1. 安装必要的库 在开始之前,确保已经安装了 requests 和 BeautifulSoup 库。如果尚未安装,可以通过以下命令进行安装: bash pip install requests…...

安装 TabbyAPI+Exllamav2 和 vLLM 的详细步骤
在 5090 显卡上成功安装 TabbyAPIExllamav2 和 vLLM 并非易事,经过一番摸索,我总结了以下详细步骤,希望能帮助大家少走弯路。 重要提示: 用户提供的 PyTorch 安装使用了 cu128,这并非标准 CUDA 版本。请根据你的系统实…...

小动物多导生理记录仪产品需求定义
小动物多导生理记录仪的产品需求定义如下: 功能需求 信号采集功能:能采集多种生理信号,如心电、脑电、肌电、眼电、胃肠电、诱发电位、神经电位、细胞电位、有创血压、无创血压、dP/dt、体温、肌张力、呼吸波、呼吸流速、组织血流速度、血管…...

深入理解C++引用:从基础到现代编程实践
一、引用的本质与基本特性 1.1 引用定义 引用是为现有变量创建的别名,通过&符号声明。其核心特点: 必须初始化且不能重新绑定 与被引用变量共享内存地址 无独立存储空间(编译器实现) 类型必须严格匹配 int value 42; in…...
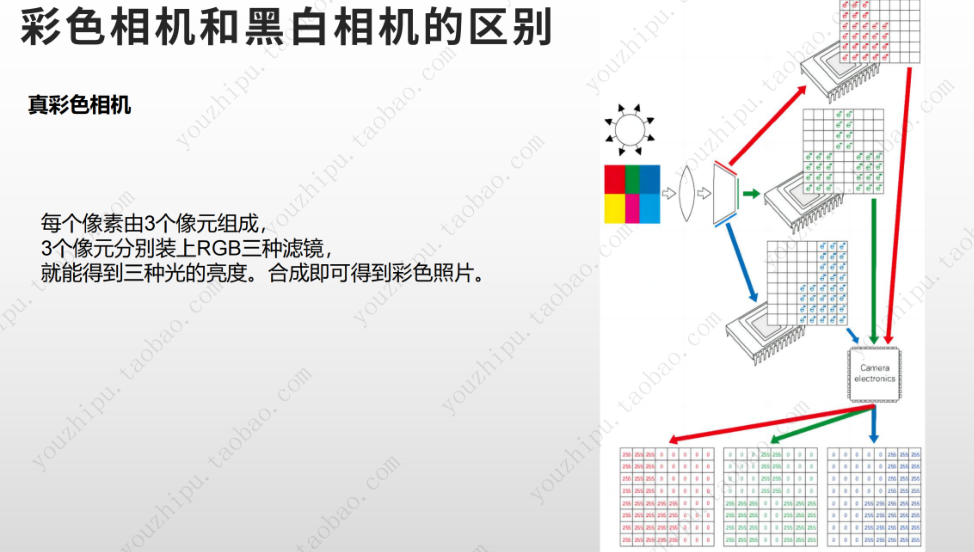
黑白彩色相机成像原理
文章目录 黑白相机成像原理彩色相机成像原理 黑白相机成像原理 参考:B站优致谱视觉 光线聚焦:相机镜头将外界景物反射的光线聚焦到相机内部的成像平面上。光电转换:成像平面上通常是图像传感器,黑白相机常用的是CCD(…...

室内指路机器人是否支持环境监测功能?
并非所有室内指路机器人都具备环境监测功能。那些支持环境监测的室内指路机器人,往往在设计上进行了针对性的优化,搭载了一系列先进且实用的传感器。温湿度传感器犹如一位敏锐的 “温度湿度侦探”,时刻精准地监测室内温度与湿度,为…...
:革新未来治理的下一站)
去中心化自治组织(DAO):革新未来治理的下一站
去中心化自治组织(DAO):革新未来治理的下一站 引言 去中心化自治组织(DAO)的诞生,像是互联网时代的一道新曙光。它打破了传统组织的等级壁垒,以去中心化和智能合约为核心,让社区成员能够直接参与决策并共享收益。从NFT社区到投资基金,DAO的应用场景正以前所未有的速…...

Docker安装、配置Mysql5.7
1.创建必要的目录 # 创建目录 mkdir -p ~/docker/software/mysql/{conf,log,data} 2.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:mysql:image: mysql:5.7.36container_name: mysqlports:- "…...

#管理Node.js的多个版本
在 Windows 11 上管理 Node.js 的多个版本,最方便的方法是使用 nvm-windows(Node Version Manager for Windows)。它允许你轻松安装、切换和管理多个 Node.js 版本。 📌 方法 1:使用 nvm-windows(推荐 ✅&a…...
基于DrissionPage的Taptap热门游戏数据爬虫实战:从Requests到现代爬虫框架的迁移指南(含完整代码复制)
目录 编辑 一、项目重构背景与技术选型 1.1 原代码问题分析 1.2 DrissionPage框架优势 二、环境配置与基础改造 2.1 依赖库安装 2.2 基础类改造 三、核心功能模块重构 3.1 请求参数自动化生成 3.2 智能页面渲染 3.3 数据解析优化 四、数据库操作增强 4.1 批量插入…...

Online Sparse Reconstruction for Scanning Radar Using Beam-Updating q-SPICE论文阅读
Online Sparse Reconstruction for Scanning Radar Using Beam-Updating q -SPICE 论文概述关键技术与创新点实验结果学术术语解释1. 论文的研究目标与实际问题2. 论文提出的新方法、模型与公式2.1 核心方法:Beam-Updating q-SPICE2.1.1 循环最小化(Cyclic Minimization)2.1…...

模运算核心性质与算法应用:从数学原理到编程实践
目录 🚀前言🌟数学性质:模运算的理论基石💯基本定义:余数的本质💯四则运算规则:保持同余性的关键 🦜编程实践:模运算的工程化技巧💯避免数值溢出:…...

MINIQMT学习课程Day8
获取qmt账号的资金账号后,我们进入下一步,如何获得当前账号的持仓情况 还是之前的步骤,打开qmt,选择独立交易, 之后使用pycharm,编写py文件。 from xtquant import xtdata from xtquant.xttrader import…...