Linux命令-grep
grep 是一种强大的命令行工具,用于在一个或多个输入文件中搜索与正则表达式匹配的行,并将匹配的行标准输出。
1.基本搜索
参数 说明
-i 忽略大小写进行匹配
-w 只匹配完整的单词
-x 只匹配与整行完全匹配的行
-v 反向匹配,显示不匹配的行
-q 静默模式,不输出任何内容,仅返回状态码
grep -i "pattern" file.txt
grep -w "word" file.txt
grep -x "line" file.txt
grep -v "pattern" file.txt
grep -q "pattern" file.txt
2.输出控制
参数 说明
-n 显示匹配行的行号
-H 显示文件名
-h 不显示文件名
-m n 最多显示 n 行匹配结果
–color 高亮显示匹配部分
grep -n "pattern" file.txt
grep -H "pattern" file.txt
grep -h "pattern" file.txt
grep -m 5 "pattern" file.txt
grep --color "pattern" file.txt
3.文件处理
参数 说明
-r 或 -R 递归搜索目录中的文件
-d action 指定目录的处理方式(read、skip、recurse)
-D action 指定设备文件的处理方式(read、skip)
-s 静默模式,忽略不存在的文件或读取错误
grep -r "pattern" /path/to/directory
grep -d skip "pattern" /path/to/directory
grep -D skip "pattern" /dev/sda
grep -s "pattern" file.txt
4.匹配模式
参数 说明
-e pattern 指定搜索模式,可多次使用
-f file 从文件中读取搜索模式
-E 启用扩展正则表达式
-F 将模式视为固定字符串,而非正则表达式
-G 强制使用基本正则表达式
-P 启用 Perl 兼容正则表达式(PCRE)
grep -e "pattern1" -e "pattern2" file.txt
grep -f patterns.txt file.txt
grep -E "pattern" file.txt
grep -F "pattern" file.txt
grep -G "pattern" file.txt
grep -P "pattern" file.txt
5.上下文显示
参数 说明
-A n 显示匹配行后的 n 行
-B n 显示匹配行前的 n 行
-C n 显示匹配行前后的 n 行
grep -A 2 "pattern" file.txt
grep -B 2 "pattern" file.txt
grep -C 2 "pattern" file.txt
6.统计和计数
参数 说明
-c 显示匹配行的数量
-L 显示没有匹配的文件名
-l 显示匹配的文件名
-o 只显示匹配的部分
-Z 以 NULL 字符分隔文件名(适用于 xargs)
grep -c "pattern" file.txt
grep -L "pattern" file1.txt file2.txt
grep -l "pattern" file1.txt file2.txt
grep -o "pattern" file.txt
grep -Z "pattern" file.txt
7.其他选项
参数 说明
-V 显示版本信息
grep -V-u 强制输出为 UTF-8 编码
grep -u "pattern" file.txt-z 将输入视为 NULL 分隔的行
grep -z "pattern" file.txt
–exclude=glob 排除匹配 glob 的文件
grep --exclude=*.log -r "pattern" /path/to/directory
–include=glob 只搜索匹配 glob 的文件
grep --include=*.txt -r "pattern" /path/to/directory
–files-with-matches 只显示匹配的文件名
grep --files-with-matches "pattern" file.txt
–files-without-match 只显示没有匹配的文件名
grep --files-without-match "pattern" file.txt
–label=label 为输出添加标签
grep --label="my_label" "pattern" file.txt
–binary-files=type 指定二进制文件的处理方式(binary、text、without-match)
grep --binary-files=text "pattern" file.bin
–text 将二进制文件视为文本处理
grep --text "pattern" file.bin
–null-data 将空文件视为匹配
grep --null-data "pattern" file.txt
–max-count=n 最多匹配 n 次后停止
grep --max-count=5 "pattern" file.txt
–line-buffered 使用行缓冲输出
grep --line-buffered "pattern" file.txt
–mmap 使用内存映射读取文件
grep --mmap "pattern" file.txt
–perl-regexp 启用 Perl 兼容正则表达式(同 -P)
grep --perl-regexp "pattern" file.txt
–basic-regexp 强制使用基本正则表达式(同 -G)
grep --basic-regexp "pattern" file.txt
–extended-regexp 启用扩展正则表达式(同 -E)
grep --extended-regexp "pattern" file.txt
–fixed-strings 将模式视为固定字符串(同 -F)
grep --fixed-strings "pattern" file.txt
–auto-call 自动调用 --color 如果输出是终端
grep --auto-color "pattern" file.txt
–color=when 指定何时高亮显示匹配部分(never、always、auto)
grep --color=always "pattern" file.txt
–context[=n] 显示匹配行前后的 n 行(同 -C)
grep --context=2 "pattern" file.txt
–before-context[=n] 显示匹配行前的 n 行(同 -B)
grep --before-context=2 "pattern" file.txt
–after-context[=n] 显示匹配行后的 n 行(同 -A)
grep --after-context=2 "pattern" file.txt
–group-separator=string 指定分隔匹配组的字符串
grep --group-separator="---" -A 2 -B 2 "pattern" file.txt
#该命令会在 file.txt 文件中查找包含 pattern 的行,并显示匹配行前后的上下文行(匹配行前 2 行和后 2 行)。同时,匹配内容之间会以 --- 作为分隔符。
–binary 将文件视为二进制文件
grep --binary "pattern" file.txt
–text 将文件视为文本文件(同 --text)
grep --text "pattern" file.txt
–ignore-case 忽略大小写(同 -i)
grep --ignore-case "pattern" file.txt
–word-regexp 只匹配完整的单词(同 -w)
grep --word-regexp "word" file.txt
–line-regexp 只匹配与整行完全匹配的行(同 -x)
grep --line-regexp "line" file.txt
–invert-match 反向匹配(同 -v)
grep --invert-match "pattern" file.txt
–quiet 静默模式(同 -q)
grep --quiet "pattern" file.txt
–silent 静默模式(同 -q)
grep --silent "pattern" file.txt
–no-messages 静默模式,不显示错误信息
grep --no-messages "pattern" file.txt
–directories=action 指定目录的处理方式(read、skip、recurse)(同 -d)
grep --directories=skip "pattern" /path/to/directory
–devices=action 指定设备文件的处理方式(read、skip)(同 -D)
grep --devices=skip "pattern" /dev/sda
–labels 显示标签
grep --labels "pattern" file.txt
–null 以 NULL 字符分隔输出
grep --null "pattern" file.txt
–null-data 将空文件视为匹配(同 --null-data)
grep --null-data "pattern" file.txt
–only-matching 只显示匹配的部分(同 -o)
grep --only-matching "pattern" file.txt
–file=file 从文件中读取搜索模式(同 -f)
grep --file=patterns.txt file.txt
–fixed-strings 将模式视为固定字符串(同 -F)
grep --fixed-strings "pattern" file.txt
–basic-regexp 强制使用基本正则表达式(同 -G)
grep --basic-regexp "pattern" file.txt
–extended-regexp 启用扩展正则表达式(同 -E)
grep --extended-regexp "pattern" file.txt
–perl-regexp 启用 Perl 兼容正则表达式(同 -P)
grep --perl-regexp "pattern" file.txt
–binary-files=type 指定二进制文件的处理方式(同 --binary-files)
grep --binary-files=text "pattern" file.bin
–mmap 使用内存映射读取文件(同 --mmap)
grep --mmap "pattern" file.txt
–line-buffered 使用行缓冲输出(同 --line-buffered)
grep --line-buffered "pattern" file.txt
–max-count=n 最多匹配 n 次后停止(同 --max-count)
grep --max-count=5 "pattern" file.txt
–color=when 指定何时高亮显示匹配部分(同 --color)
grep --color=always "pattern" file.txt
综合示例
递归搜索目录中的文件并忽略大小写:
grep -ri "pattern" /path/to/directory
显示匹配行的行号和文件名:
grep -Hn "pattern" file.txt
高亮显示匹配部分并限制输出行数:
grep --color -m 5 "pattern" file.txt
递归搜索并显示匹配的文件名:
grep -rl "pattern" /path/to/directory
使用 Perl 兼容正则表达式:
grep -P "\d+" file.txt
grep 命令中与正则表达式相关的参数及其详细说明:
1.基本正则表达式(BRE)
参数 说明
. 匹配任意单个字符(换行符除外)
^ 匹配行首
$ 匹配行尾
[] 匹配字符集合中的任意一个字符
[^] 匹配不在字符集合中的任意一个字符
*匹配前一个字符零次或多次
{n,m} 匹配前一个字符 n 到 m 次
\ 转义特殊字符
grep "a.c" file.txt 匹配 abc、a1c 等
grep "^aa" file.txt 匹配以 aa 开头的行
grep "aa$" file.txt 匹配以 aa 结尾的行
grep "[abc]" file.txt 匹配包含 a、b 或 c 的行
grep "[^abc]" file.txt 匹配不包含 a、b 或 c 的行
grep "go*gle" file.txt 匹配 ggle、google 等
grep "a\{2,4\}" file.txt 匹配 aa、aaa、aaaa
grep "\$10" file.txt 匹配 $10
2.扩展正则表达式(ERE)
参数 说明
-E 或 --extended-regexp 启用扩展正则表达式
grep -E "pattern" file.txt
+匹配前一个字符一次或多次
grep -E "go+gle" file.txt 匹配 gogle、google
? 匹配前一个字符零次或一次
grep -E "colou?r" file.txt 匹配 color、colour
| 逻辑或,匹配多个模式之一
grep -E "error|warn" file.txt匹配error或warn
() 分组表达式
grep -E "(ab)+" file.txt 匹配 ab、abab
{n,m} 匹配前一个字符 n 到 m 次(无需转义)
grep -E "a{2,4}" file.txt 匹配 aa、aaa、aaaa
实际应用示例
匹配 IP 地址:
grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}" log.txt
正则表达式解释
[0-9]{1,3}:匹配 1 到 3 位的数字。
\.:匹配点号(.),因为点号在正则表达式中是一个特殊字符,需要用反斜杠 \ 进行转义。
([0-9]{1,3}\.){3}:匹配三个由数字和点号组成的段(例如 192.168.0.)。
[0-9]{1,3}:匹配最后一段数字(例如 1 或 255)。
匹配类似 192.168.1.1 的 IP 地址。
匹配邮箱地址:
grep -E "[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}" users.csv
正则表达式解释
[a-zA-Z0-9._%+-]+:匹配电子邮件地址的用户名部分,可以包含字母(大小写)、数字、点(.)、下划线(_)、百分号(%)、加号(+)和短横线(-)。
@:匹配电子邮件地址中的 @ 符号。
[a-zA-Z0-9.-]+:匹配电子邮件地址的域名部分,可以包含字母(大小写)、数字、点(.)和短横线(-)。
\.:匹配域名中的点号(.),因为点号在正则表达式中是一个特殊字符,需要用反斜杠 \ 进行转义。
[a-zA-Z]{2,}:匹配顶级域名(如 .com、.org),要求至少包含两个字母。
匹配类似 user@example.com 的邮箱地址。
匹配以特定字符串开头的行:
grep "^example" file.txt
匹配以 example 开头的行。
匹配以特定字符串结尾的行:
grep "example$" file.txt
匹配以 example 结尾的行。
匹配包含任意字符的字符串:
grep "a..a" file.txt
匹配类似 a12a、aBa 的字符串。
相关文章:

Linux命令-grep
grep 是一种强大的命令行工具,用于在一个或多个输入文件中搜索与正则表达式匹配的行,并将匹配的行标准输出。 1.基本搜索 参数 说明 -i 忽略大小写进行匹配 -w 只匹配完整的单词 -x 只匹配与整行完全匹配的行 -v 反向匹配,显示不匹配的行…...

【Cursor】设置语言
Ctrl Shift P 搜索 configure display language选择“中文-简体”...

k8s 1.30 安装ingress-nginx
一、下载 # wget https://mirrors.chenby.cn/https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/cloud/deploy.yaml 二、过滤镜像 修改 三、部署 四、检查: 五、扩充副本数 # kubectl scale --replicas3 deployment/ingr…...
很简单 的 将字幕生成视频的 方法
一、一键将字幕生成视频的 方法 1、下载任性动图 10.7 以上版本 2、设置背景 1)背景大小 拉伸背景到合适大小,或者选择右侧比例 2)、直接空背景,设置背景颜色等详细信息 3)、或者 复制或者突然图片做背景 3、设置文…...

OpenCv(二)——边界填充、阈值处理
目录 一、边界填充 (1)constant边界填充,填充指定宽度的像素 (2)REFLECT镜像边界填充 (3)REFLECT_101镜像边界填充改进 (4) REPLICATE使用最边界的像素值代替 (5)WRAP上下左右边依次替换 二…...
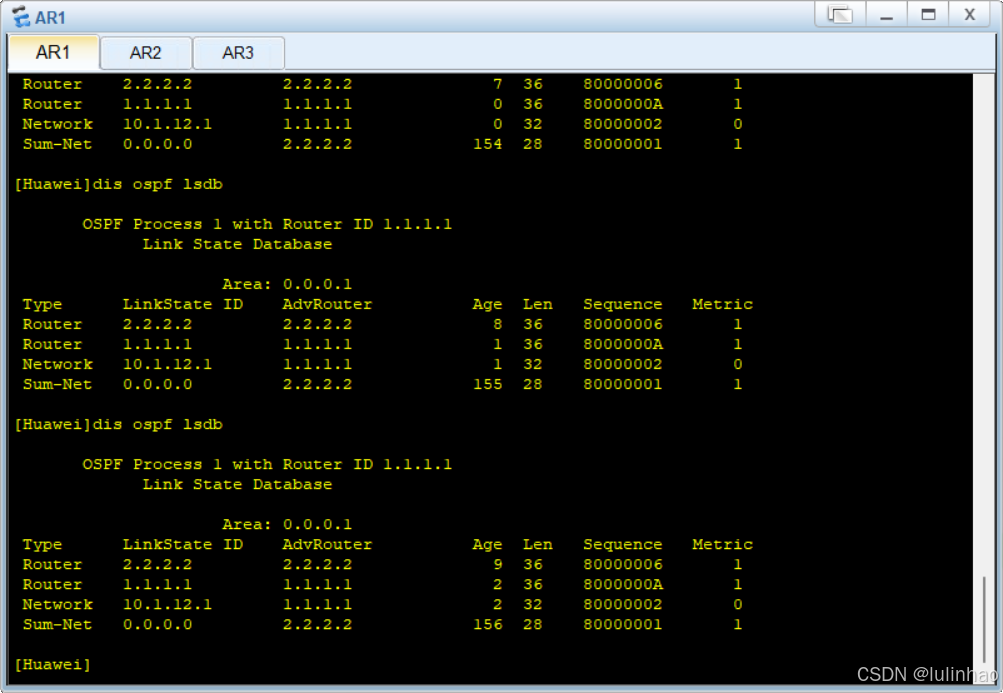
理解OSPF Stub区域和各类LSA特点
之前学习到OSPF特殊区域和各类类型LSA的分析后,一直很混乱,在网上也难找到详细的解释,在看了 HCNP书本内容后,对这块类容理解更加清晰,本次内容,我们使用实验示例,来对OSPF特殊区域和各 类型LSA…...

鸿蒙 ——选择相册图片保存到应用
photoAccessHelper // entry/src/main/ets/utils/file.ets import { fileIo } from kit.CoreFileKit; import { photoAccessHelper } from kit.MediaLibraryKit; import { bundleManager } from kit.AbilityKit;// 应用在本设备内部存储上通用的存放默认长期保存的文件路径&am…...

pat学习笔记
two pointers 双指针 给定一个递增的正整数序列和一个正整数M,求序列中的两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。例如给定序列{1,2,3,4,5,6}和正整数M 8,就存在268和358成立。 容易想到࿱…...

Gson修仙指南:谷歌大法的佛系JSON渡劫手册
各位在代码世界打坐修行的道友们!今天我们要参悟Google出品的JSON心法——Gson!这货就像代码界的扫地僧,表面朴实无华,实则内力深厚,专治各种JSON不服!准备好迎接"万物皆可JSON"的顿悟时刻了吗&a…...

我的世界1.20.1forge模组开发进阶教程——TerraBlender
TerraBlender介绍 从模组开发者的视角来看,TerraBlender为Minecraft生物群系类模组的开发提供了全方位的技术支持,显著降低了开发门槛并提升了模组的质量与扩展性: 跨平台兼容性架构支持Forge/Fabric/Quilt/NeoForge四大主流加载器,开发者无需为不同平台单独适配代码客户端…...

判断HiveQL语句为ALTER TABLE语句的识别函数
写一个C#字符串解析程序代码,逻辑是从前到后一个一个读取字符,遇到匹配空格、Tab和换行符就继续读取下一个字符,遇到大写或小写的字符a,就读取后一个字符并匹配是否为大写或小写的字符l,以此类推,匹配任意字…...

CAN/FD CAN总线配置 最新详解 包含理论+实战(附带源码)
看前须知:本篇文章不会说太多理论性的内容(重点在理论结合实践),顾及实操,应用,一切理论内容支撑都是为了后续实际操作进行铺垫,重点在于读者可以看完文章应用。(也为节约读者时间&a…...

DE2-115分秒计数器
一、模块设计 如若不清楚怎么模块化,请看https://blog.csdn.net/szyugly/article/details/146379170?spm1001.2014.3001.5501 1.1顶层模块 module top_counter(input wire CLOCK_50, // 50MHz时钟input wire KEY0, // 暂停/继续按键out…...

MoE Align Sort在医院AI医疗领域的前景分析(代码版)
MoE Align & Sort技术通过优化混合专家模型(MoE)的路由与计算流程,在医疗数据处理、模型推理效率及多模态任务协同中展现出显著优势,其技术价值与应用意义从以下三方面展开分析: 一、方向分析 1、提升医疗数据处理效率 在医疗场景中,多模态数据(如医学影像、文本…...
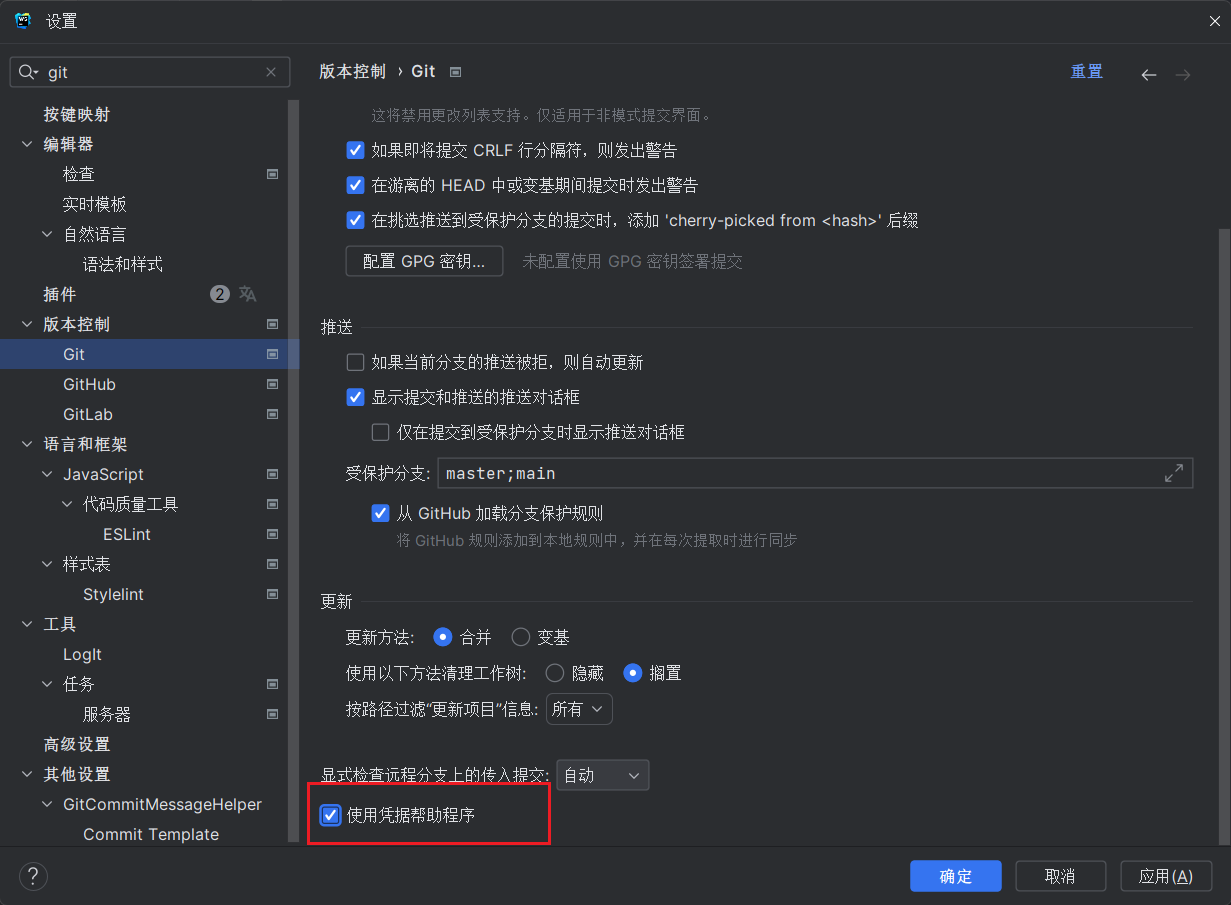
【已解决】Webstorm 每次使用 git pull/push 都要输入令牌/密码登录
解决办法:勾上【使用凭据帮助程序】(英文:Use credential helper)...

阅读分析Linux0.11 /boot/setup.s
目录 第一部分第二部分第三部分 该源文件功能分为三部分: (1)源文件开始部分是通过各种中断指令, 初始化计算机的组成硬件,获得硬件的参数,然后保存到段空间0X9000。该空间原来是保存加载到内存的引导扇区内…...

Cmake:Win10 如何编译 midifile C++应用程序
先从 Microsoft C Build Tools - Visual Studio 下载 1.73GB 安装 "Microsoft C Build Tools“ 下载:midifile 项目 , 将 midifile-master.zip 解压到 D:\Music-soft 参阅: cmake超详细入门教程 CMake是一个跨平台的自动化建构系统,它使用一个名为 CMakeLi…...
)
QEMU源码全解析 —— 块设备虚拟化(14)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(13) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回开始解析VirtioDeviceClass的realize函数virtio_blk_device_realize(),再来回…...
软路由安装指南
1.openwrt下载 : 选择合适的安装包,我用的软路由CPU主板是j3160,属于X86_64架构,所以筛选的时候使用X86_64的安装镜像 openwrt的官方地址可能国内打不开,需要科学上网 openwrt安装镜像下载地址 我准备用U盘引导小主机开机,进而安装openwrt操作系统,所以下载 .img.gz 文…...

机器视觉工程师的专业精度决定职业高度,而专注密度决定成长速度。低质量的合群,不如高质量独处
在机器视觉行业,真正的技术突破往往诞生于深度思考与有效碰撞的辩证统一。建议采用「70%高质量独处30%精准社交」的钻石结构,构建可验证的技术能力护城河。记住:你的专业精度决定职业高度,而专注密度决定成长速度。 作为机器视觉工…...

Oracle 数据库中,并行 DML
在 Oracle 数据库中,PL/SQL 的 BEGIN...END 块默认是串行执行的,但可以通过以下方法实现并行处理,提升大规模数据操作的性能: 并行 DML(Data Manipulation Language) 在 BEGIN...END 块中启用并行 DML&am…...

Spring Boot 集成 Redis中@Cacheable 和 @CachePut 的详细对比,涵盖功能、执行流程、适用场景、参数配置及代码示例
以下是 Cacheable 和 CachePut 的详细对比,涵盖功能、执行流程、适用场景、参数配置及代码示例: 1. 核心对比表格 特性CacheableCachePut作用缓存方法的返回结果,避免重复计算执行方法并更新缓存,不覆盖原有缓存执行流程缓存命中…...
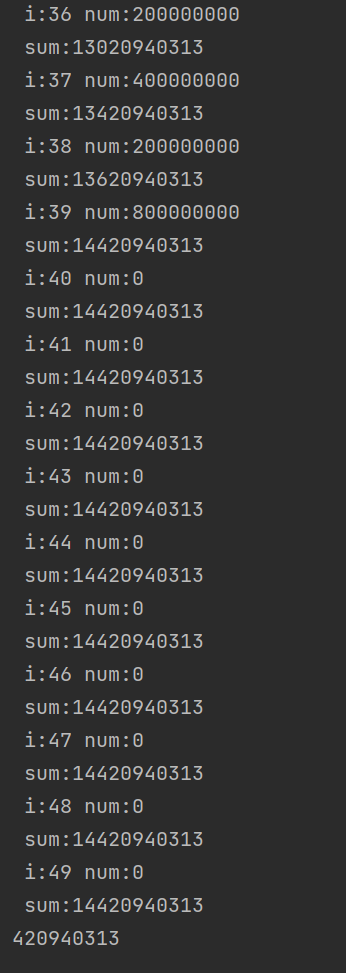
3500 阶乘求和
3500 阶乘求和 ⭐️难度:中等 🌟考点:2023、思维、省赛 📖 📚 import java.util.Scanner;public class Main {public static void main(String[] args) {long sum 0;for(int i1;i<50;i) { // 之后取模都相等su…...

软件工程(应试版)图形工具总结(二)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 教材参考《软件工程导论(第六版)》 七、 层次图(H图)与HIPO图 1、概述 1.1、层次图(Hierarchy Chart / H图) 核心…...

思维链、思维树、思维图与思维森林在医疗AI编程中的应用蓝图
在医疗AI编程中,思维链(Chain of Thought, CoT)、思维树(Tree of Thoughts, ToT)、思维图(可能指知识图谱或逻辑图)以及思维森林(Forest-of-Thought, FoT)等技术框架通过模拟人类认知和推理过程,显著提升了AI在复杂医疗场景中的决策能力和可解释性: 1. 思维链(CoT)…...

SpringBoot异步任务实践指南:提升系统性能的利器
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 引言 在现代Web应用中,高并发场景下的响应速度和资源利用率是系统设计的重要考量。SpringBoot通过简洁的异步任务机制,帮助开发者轻松…...

化工行业如何通过定制化工作流自动化实现25-30%成本优化?
作者:Mihir Jhaveri 编译:李升伟 发布日期:2024年10月30日 在化工生产领域,数字化转型正以颠覆性态势重塑产业格局。通过集成定制化软件、ERP系统、工业物联网(IIoT)传感网络、机器人流程自动化࿰…...

嵌入式硬件篇---嘉立创PCB绘制
文章目录 前言一、PCB绘制简介1.1绘制步骤1.1.1前期准备1.1.2原理图设计1.1.3原理图转PCB1.1.4PCB布局1.1.5布线1.1.6布线优化和丝印1.1.7制版1.2原理1.2.1电气连接原理1.2.2信号传输原理1.2.3电源和接地原理1.3注意事项1.3.1元件封装1.3.2布局规则1.3.3过孔设计1.3.4DRC检查1.…...

CSS Id 和 Class 选择器学习笔记
一、概述 在 CSS 中,id 和 class 选择器是用于为 HTML 元素指定样式的强大工具。它们可以帮助我们精确地控制页面中元素的样式,让页面设计更加灵活和高效。 二、id 选择器 1. 定义和使用 定义:id 选择器用于为具有特定 id 属性的 HTML 元素…...

Linux的 /etc/sysctl.conf 笔记250404
Linux的 /etc/sysctl.conf 笔记250404 /etc/sysctl.conf 是 Linux 系统中用于 永久修改内核运行时参数 的核心配置文件。它通过 sysctl 工具实现参数的持久化存储,确保系统重启后配置依然生效。以下是其详细说明: 📂 备份/etc/sysctl.conf t…...