SQL语句(三)—— DQL
目录
基本语法
一、基础查询
1、查询多个字段
2、字段设置别名
3、去除重复记录
4、示例代码
二、条件查询
1、语法
2、条件列表常用的运算符
3、示例代码
三、分组查询
(一)聚合函数
1、介绍
2、常见的聚合函数
3、语法
4、示例代码
(二)分组查询
1、语法
2、where 与 having 区别
3、注意事项
4、示例代码
四、排序查询
1、语法
2、排序方式
3、注意事项
4、示例代码
五、分页查询
1、语法
2、注意事项
3、示例代码
六、DQL语言的实战应用
(一)执行顺序
(二)各个字句的作用
(三)实际书写代码的思路
DQL 英文全称是Data Query Language,即数据查询语言,用来查询数据库中表的记录。
在一个正常的业务系统中,查询操作的频次是要远高于增删改的。
当我们去访问企业官网、电商网站,在这些网站中我们所看到的数据,实际都是需要从数据库中查询并展示的。而且在查询的过程中,可能还会涉及到条件、排序、分页等操作。
基本语法
DQL 查询语句,语法结构如下:
select字段列表
from表名列表
where条件列表
group by分组字段列表
having分组后条件列表
order by排序字段列表
limit分页参数我们在讲解这部分内容的时候,会将上面的完整语法进行拆分,分为以下几个部分.
① 基本查询 (不带任何条件);② 条件查询 (WHERE);③ 聚合函数 (count、max、min、avg、sum);④ 分组查询 (group by);⑤ 排序查询 (order by);⑥ 分页查询 (limit)
一、基础查询
1、查询多个字段
在基本查询的DQL语句中,不带任何的查询条件,查询的语法如下:
select 字段1, 字段2, 字段3 ... from 表名 ;
select * from 表名 ;
注意:* 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
2、字段设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] ... from 表名;
select 字段1 [ 别名1 ] , 字段2 [ 别名2 ] ... from 表名;
注意:关键字 as 可以省略,方括号表示可以不添加。
3、去除重复记录
select distinct 字段列表 from 表名;
select 的意思是选择,在这里选择对应的字段的意思就是,选到了什么字段,什么字段就显示出来,那一列就显示出来,没有被选择到的就不显示出来。
from 的意思是来自,后面接表名,也就是说明数据来源于哪个表。
4、示例代码
(1)查询指定字段 name, workno, age 并返回
select name,workno,age from emp;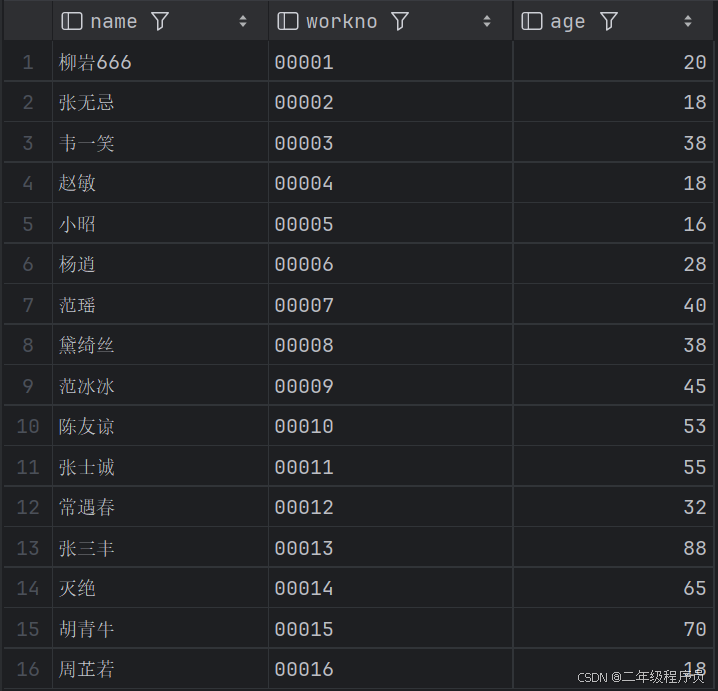
(2)查询返回所有字段
select id ,workno,name,gender,age,idcard,workaddress,entrydate from emp;
select * from emp;(3)查询所有人员的工作地址、起别名
select workaddress as '工作地址' from emp;
-- as可以省略
select workaddress '工作地址' from emp;(4)查询公司员工的上班地址有哪些(不要重复)
select distinct workaddress '工作地址' from emp;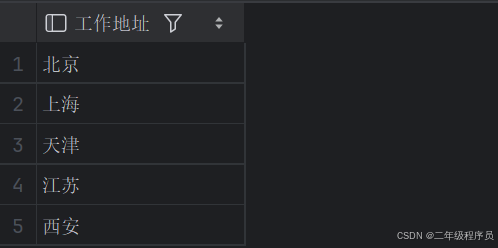
二、条件查询
1、语法
select 字段列表 from 表名 where 条件列表 ;
2、条件列表常用的运算符
(1)常用的比较运算符如下:
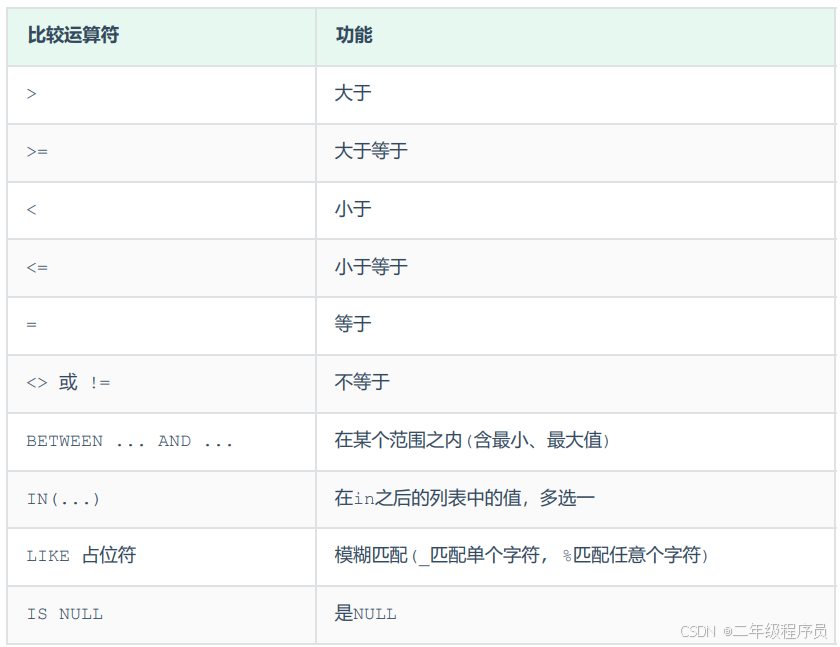
(2)常用的逻辑运算符如下:
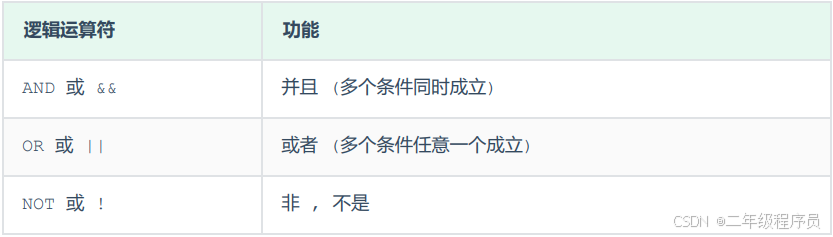
3、示例代码
(1)查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;(2)查询性别为女且年龄小于25岁的员工信息
select * from emp where gender = '女' and age < 25;(3)查询姓名为两个字的员工信息
select * from emp where name like '__';
--like后面有两条_,说明匹配两个任意字符
(4)查询身份证号最后一位是X的员工信息
select * from emp where idcard like '%X';
--%可以表示任意字符,'%X只要保证最后一位是X就行了'
select * from emp where idcard like '_________________X';
三、分组查询
(一)聚合函数
1、介绍
聚合函数即将一列数据作为一个整体,进行纵向计算 。select 的作用就是选择要展现的列,其后面可以接字段与聚合函数。
select 后面接字段就是正常输出一列;而接聚合函数,就是对这一列进行相应的处理,再展示出来,其行数会做出相应的调整。
直接引用表中原始字段,未经过聚合函数处理,这列则被称为非聚合列。而经过聚合函数处理的列,则称为聚合列。
聚合函数可以单独使用,但是如当与非聚合列一起出现时,必须通过 group by 明确分组规则,否则会导致语法错误。
2、常见的聚合函数
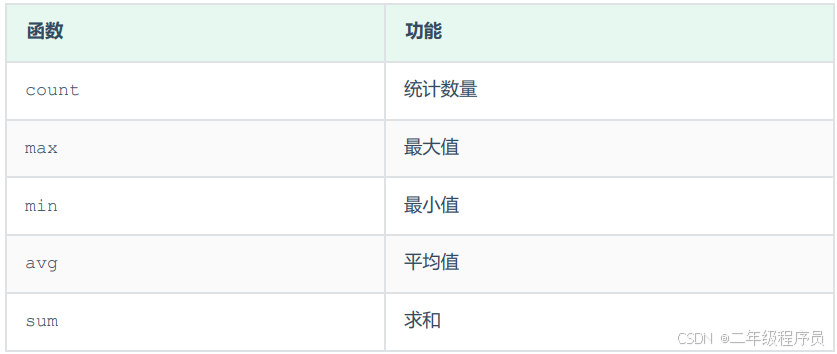
3、语法
select 聚合函数(字段列表) from 表名 ;
注意:NULL值是不参与所有聚合函数运算的
4、示例代码
(1)统计该企业员工数量
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数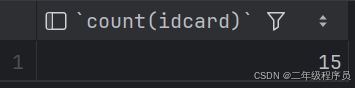
(2)统计该企业员工的最大年龄
select max(age) from emp;(3)统计西安地区员工的年龄之和
select sum(age) from emp where workaddress = '西安';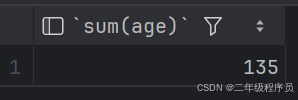
(二)分组查询
1、语法
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
2、where 与 having 区别
(1)执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
(2)判断条件不同:where不能对聚合函数进行判断,而having可以。
3、注意事项
(1)分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。[重点]
例如,我根据性别 gender 分组,分组结为男与女,所以此时就会得到得到男与女两组,即男女两行;但这两行并没有数据,仅知道一行存放男性的数据、一行存放女性的数据。
此时使用聚合函数max(age),就会在这两行呈现对应数据,即男性的最大年龄与女性的最大年龄;再接gender字段,则在两行中分别填放男、女;
但如果接 workplace 字段,性别男或性别女会对应多个工作地址,系统根本不知道显示哪个。所以 select 的后面只能接作为分组依据的字段或聚合函数。
(2)执行顺序
where > group by> 聚合函数 > having
(3)支持多字段分组,具体语法为:group by columnA,columnB
4、示例代码
(1)根据性别分组 , 统计男性员工和女性员工的数量
select gender, count(*) from emp group by gender ;(2)查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
select workaddress, count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3;
(3)统计各个工作地址上班的男性及女性员工的数量
select workaddress, gender, count(*) '数量' from emp group by gender , workaddress ;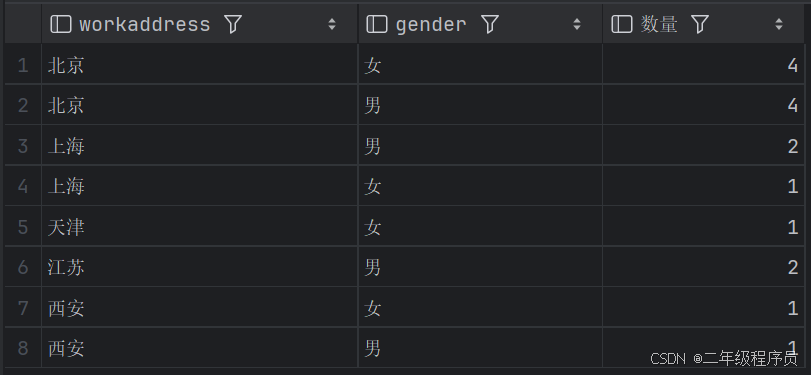
四、排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
1、语法
select 字段列表 from 表名 order by 字段1 排序方式1 , 字段2 排序方式2 ;
2、排序方式
asc:升序(默认值)
desc:降序
3、注意事项
(1)如果是升序,可以不指定排序方式ASC,因为默认升序;
(2)如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序 ;
4、示例代码
(1)根据年龄对公司的员工进行升序排序
select * from emp order by age asc;
select * from emp order by age;(2)根据入职时间, 对员工进行降序排序
select * from emp order by entrydate desc;
(3)根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
select * from emp order by age asc , entrydate desc;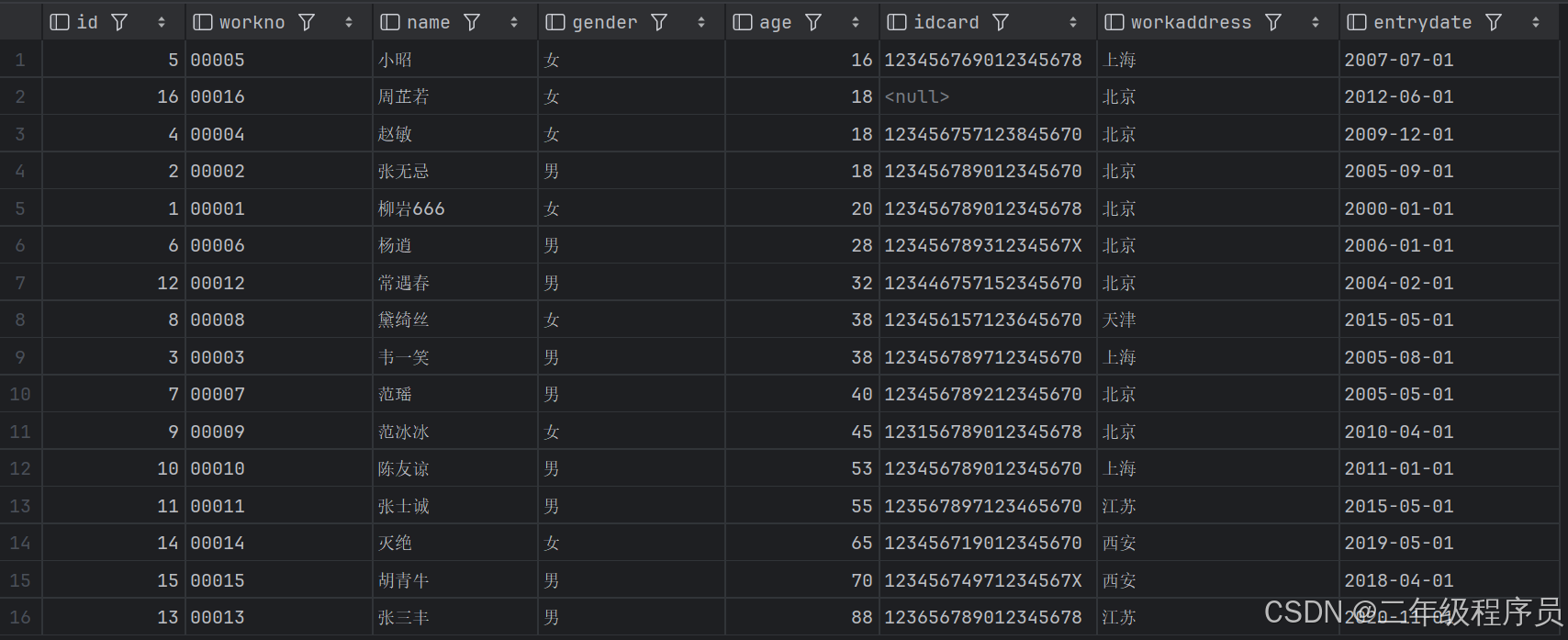
五、分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,我们在网站中看到的各种各样的分页条,后台都需要借助于数据库的分页操作。
1、语法
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
2、注意事项
(1)起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
(2)分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
(3)如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
3、示例代码
(1)查询第1页员工数据, 每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10;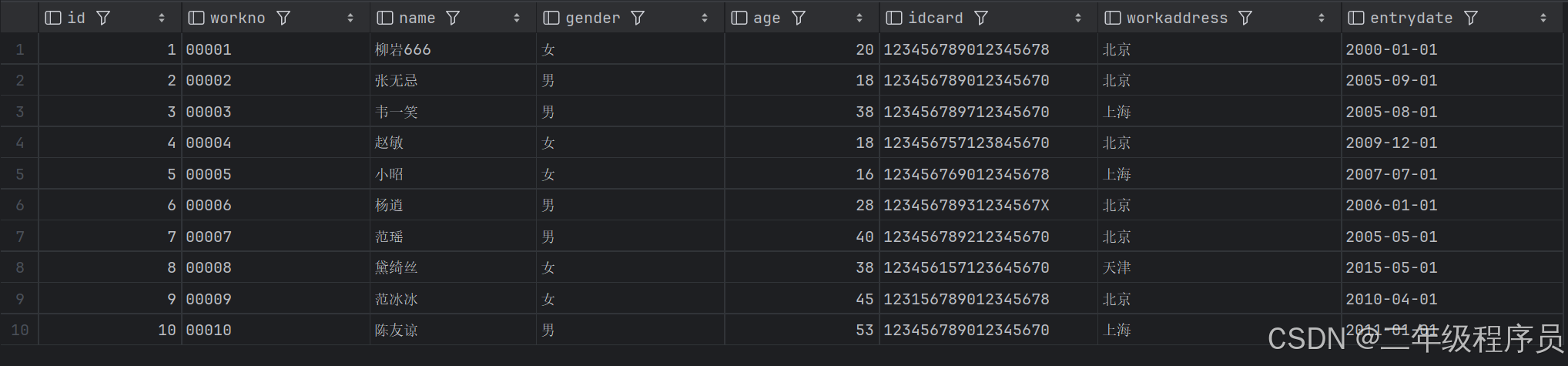
(2)查询第2页员工数据, 每页展示10条记录,即起始索引 = (页码-1) * 页展示记录数
select * from emp limit 10,10;
六、DQL语言的实战应用
(一)执行顺序
在讲解DQL语句的具体语法之前,我们已经讲解了DQL语句的完整语法,及编写顺序,现在我们要来说明的是DQL语句在执行时的执行顺序,也就是先执行哪一部分,后执行哪一部分。

(二)各个字句的作用
① from:指定要查询的表。
② where:筛选满足条件的行。
③ group by:按照指定列对结果进行分组。
④ having:分组后,筛选满足条件的行。
⑤ select:选择要返回的列。
⑥ order by:对结果进行排序。
所以说一条语句执行的完整过程是:
from 先决定查询哪个表,where 筛选满足条件的行,group by再对指定的列进行分组,没有参与分组的列可以忽略了,因为根本select不出来,接着having 对分组后的结果进行二次筛选,筛选满足条件的行;
在前置操作完成后,select 就可以选择需要输出的列;
order by可以对输出的结果进行相应的排序,如果需要分页,则可以使用limit。
(三)实际书写代码的思路
题目:编写一个SQL查询,找出入职日期在2022年之后,所在部门员工平均工资超过5200的部门,统计这些部门的员工数量,最后按照员工数量从多到少排序。以下是表的具体内容:
-- 创建员工表
create table 员工 (员工编号 int primary key,员工姓名 varchar(50),部门 varchar(50),工资 decimal(10, 2),入职日期 date
);-- 插入示例数据
insert into 员工表 (员工编号, 员工姓名, 部门, 工资, 入职日期)
values (1, '爱丽丝', '人力资源部', 5000, '2022-01-01'),(2, '鲍勃', '信息技术部', 6000, '2022-03-15'),(3, '查理', '人力资源部', 5500, '2022-05-20'),(4, '大卫', '信息技术部', 7000, '2022-07-10'),(5, '伊芙', '财务部', 4500, '2022-09-05');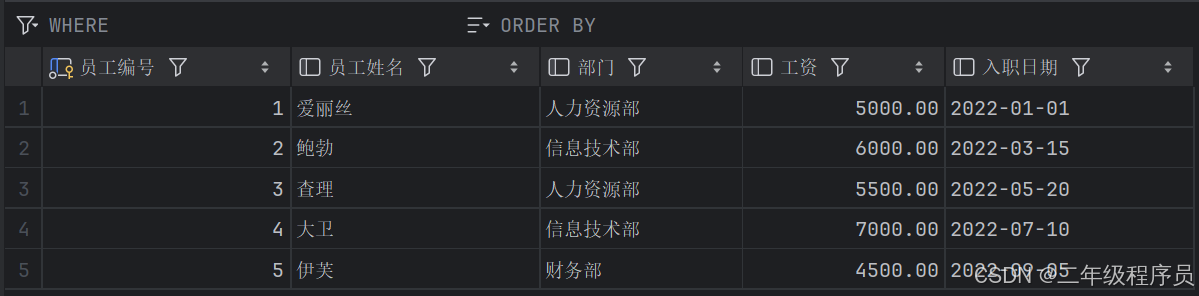
写代码的思路其实就是“代码的书写顺序”,语句的书写顺序符合的是人的思路,语句的执行顺序符合的是计算机的逻辑。【重点】
我们可以把书写代码的过程分为三部分:分组之前、分组、分组之后。
分组之前:第一步要知道,需要输出哪几列,从哪个表得到数据,即 select 与 from。根据“统计这些部门的员工数量”,可以知道,我们需要输出的有两列:部门、数量;数量需要使用聚合函数 count。接着,找出分组之前的筛选条件(where),是“入职日期在 2022 年之后”。
分组:然后要确定分组条件(group by)。我们已经知道了,输出的两列是部门与数量,因为输出的列除了聚合函数以外,就是分组条件,所以分组条件是部门。
分组之后:确定分组后的筛选条件(having)与排序规则(order by)。接着由“所在部门员工平均工资超过5200的部门”可知,在分组之后,我们还要根据平均工资 5200 进行相应的筛选;最后根据员工数量的多少进行排序。
三步之后,即可得到以下代码:
select department,count(employee_id)
fromemployees
where hire_date >= '2022-01-01'
group by department
having avg(salary) > 5200
order by count(employee_id) desc;以上即为数据查询语言 DQL 的所有内容,我们首先对整体语句拆分,作逐个击破;然后对其整体的执行过程与书写思路作讲解,从而能在日常代码书写中,将语句写出。
相关文章:
SQL语句(三)—— DQL
目录 基本语法 一、基础查询 1、查询多个字段 2、字段设置别名 3、去除重复记录 4、示例代码 二、条件查询 1、语法 2、条件列表常用的运算符 3、示例代码 三、分组查询 (一)聚合函数 1、介绍 2、常见的聚合函数 3、语法 4、示例代码 &…...

#python项目生成exe相关了解
在 Windows 上将 Python 项目 生成 EXE 可执行文件,主要使用 pyinstaller。以下是完整步骤: 📌 1. 安装 PyInstaller pip install pyinstaller如果已安装,可执行以下命令检查版本: pyinstaller --versionὌ…...

Opencv计算机视觉编程攻略-第九节 描述和匹配兴趣点
一般而言,如果一个物体在一幅图像中被检测到关键点,那么同一个物体在其他图像中也会检测到同一个关键点。图像匹配是关键点的常用功能之一,它的作用包括关联同一场景的两幅图像、检测图像中事物的发生地点等等。 1.局部模板匹配 凭单个像素就…...

JSON-lib考古现场:在2025年打开赛博古董店的奇妙冒险
各位在代码海洋里捡贝壳的探险家们!今天我们要打开一个尘封的Java古董箱——JSON-lib!这货可是2003年的老宝贝,比在座很多程序员的工龄还大!准备好穿越回Web 1.0时代,感受XML统治时期的余晖了吗? …...

Android: Handler 的用法详解
Android 中 Handler 的用法详解 Handler 是 Android 中用于线程间通信的重要机制,主要用于在不同线程之间发送和处理消息。以下是 Handler 的全面用法指南: 一、Handler 的基本原理 Handler 基于消息队列(MessageQueue)和循环器(Looper)工作,…...
汇编学习之《push , pop指令》
学习本章前线了解ESP, EBP 指令 汇编学习之《指针寄存器&大小端学习》-CSDN博客 栈的特点: 好比一个垂直容器,可以陆续放入物体,但是先放的物体通常会被后面放的物体压着,只有等上面后放的物品拿出来后,才能…...

Python循环控制语句
1. 循环类型概述 Python提供两种主要的循环结构: while循环 - 在条件为真时重复执行for循环 - 遍历序列中的元素 2. while循环 基本语法 while 条件表达式:循环体代码示例 count 0 while count < 5:print(f"这是第{count1}次循环")count 13. f…...
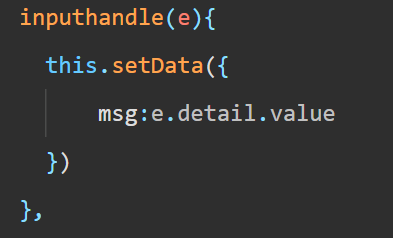
微信小程序(下)
目录 在事件处理函数中为 data 中的数据赋值 事件传参 bindinput 的语法格式 实现文本框和 data 之间的数据同步 条件渲染 结合 使用 wx:if hidden wx:if与 hidden 的对比 wx:for 手动指定索引和当前项的变量名 wx:key 的使用 WXSS 和 CSS 的关系 什么是 rpx 尺寸…...

【零基础入门unity游戏开发——2D篇】2D 游戏场景地形编辑器——TileMap的使用介绍
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

vector的介绍与代码演示
由于以后我们写OJ题时会经常使用到vector,所以我们必不可缺的是熟悉它的各个接口。来为我们未来作铺垫。 首先,我们了解一下: https://cplusplus.com/reference/vector/ vector的概念: 1. vector是表示可变大小数组的序列容器…...

ubuntu 22.04 解决LXC 报错CGroupV1 host system
解决CGroupV1 host system 报错 echo "cgroupv1 environment" sed -i s/^GRUB_CMDLINE_LINUX.*/GRUB_CMDLINE_LINUX_DEFAULT"quiet splash systemd.unified_cgroup_hierarchy0" / /etc/default/grub update-grub reboot 下载oracle 7 Linux 容器测试 l…...

JavaEE初阶复习(JVM篇)
JVM Java虚拟机 jdk java开发工具包 jre java运行时环境 jvm java虚拟机(解释执行 java 字节码) java作为一个半解释,半编译的语言,可以做到跨平台. java 通过javac把.java文件>.class文件(字节码文件) 字节码文件, 包含的就是java字节码, jvm把字节码进行翻译转化为…...
MINIQMT学习课程Day9
获取qmt账号的持仓情况后,我们进入下一步,如何获得当前账号的委托状况 还是之前的步骤,打开qmt,选择独立交易, 之后使用pycharm,编写py文件 导入包: from xtquant import xtdata from xtqua…...

动态规划似包非包系列一>组合总和IIV
目录 题目分析:状态表示:状态转移方程:初始化填表顺序返回值:代码呈现: 题目分析: 状态表示: 状态转移方程: 初始化填表顺序返回值: 代码呈现: class Soluti…...

Java 二叉树非递归遍历核心实现
非递归遍历的核心是用栈模拟递归的调用过程,通过手动维护栈来替代系统栈,实现前序、中序和后序遍历。以下是三种遍历的代码实现与关键逻辑分析: 一、二叉树遍历 1.1、前序遍历(根 → 左 → 右) 核心逻辑:…...

JavaScript性能优化实践:从微观加速到系统级策略
JavaScript性能优化实践:从微观加速到系统级策略 引言:性能优化的"时空折叠"思维 在JavaScript的世界里,性能优化如同在时间与空间的维度中折叠代码。本文将通过"时空折叠"的隐喻,从代码执行效率(时间维度)和内存占用(空间维度)两大核心,结合现代…...

《P1029 [NOIP 2001 普及组] 最大公约数和最小公倍数问题》
题目描述 输入两个正整数 x0,y0,求出满足下列条件的 P,Q 的个数: P,Q 是正整数。 要求 P,Q 以 x0 为最大公约数,以 y0 为最小公倍数。 试求:满足条件的所有可能的 P,Q 的个数。 输入格式 一行两个正整数 x0,y0。…...

【力扣hot100题】(052)课程表
什么人一学期要上2000节课啊jpg 看了非常久都没思路,主要是数据结构还没复习到图论,根本没思路怎么储存一个图…… 唯一记得的就是两种存储方法,一种是二维数组法,记录每一条边的有无,一种是只记录有的边,…...

SpringBoot配置文件多环境开发
目录 一、设置临时属性的几种方法 1.启动jar包时,设置临时属性 2.idea配置临时属性 3.启动类中创建数组指定临时属性 二、多环境开发 1.包含模式 2.分组模式 三、配置文件的优先级 1.bootstrap 文件优先: 2.特定配置文件优先 3.文件夹位置优…...

RSA和ECC在密钥长度相同的情况下哪个更安全?
现在常见的SSL证书,如:iTrustSSL都支持RSA和ECC的加密算法,正常情况下RAS和ECC算法该如何选择呢?实际上在密钥长度相同的情况下,ECC(椭圆曲线密码学)通常比RSA(Rivest-Shamir-Adle…...

Dive into Deep Learning - 2.4. Calculus (微积分)
Dive into Deep Learning - 2.4. Calculus {微积分} 1. Derivatives and Differentiation (导数和微分)1.1. Visualization Utilities 2. Chain Rule (链式法则)3. DiscussionReferences 2.4. Calculus https://d2l.ai/chapter_preliminaries/calculus.html For a long time, …...
)
【备考高项】附录:合同法全文(428条全)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 第一章 一般规定第二章 合同的订立第三章 合同的效力第四章 合同的履行第五章 合同的变更和转让第六章 合同的权利义务终止第七章 违约责任第八章 其他规定第九章 买卖合同第十章 供用电、水、气、热力合同第十…...

Ubuntu安装Podman教程
1、先修改apt源为阿里源加速 备份原文件: sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup 修改源配置: vim sources.list删除里面全部内容后,粘贴阿里源: deb http://mirrors.aliyun.com/ubuntu/ focal main re…...
9.进程信号
信号量 信号量是什么? 本质是一个计数器,通常用来表示公共资源中,资源数量多少的问题。 公共资源:可以被多个进程同时访问的资源。 访问没有保护的公共资源会导致数据不一致问题 什么是数据不一致问题 由于公共资源…...

python爬虫:小程序逆向(需要的工具前期准备)
前置知识点 1. wxapkg文件 如何查看小程序包文件 打开wechat的设置: .wxapkg概述 .wxapkg是小程序的包文件格式,且其具有独特的结构和加密方式。它不仅包含了小程序的源代码,还包括了图像和其他资源文件,这些内容在普通的文件…...
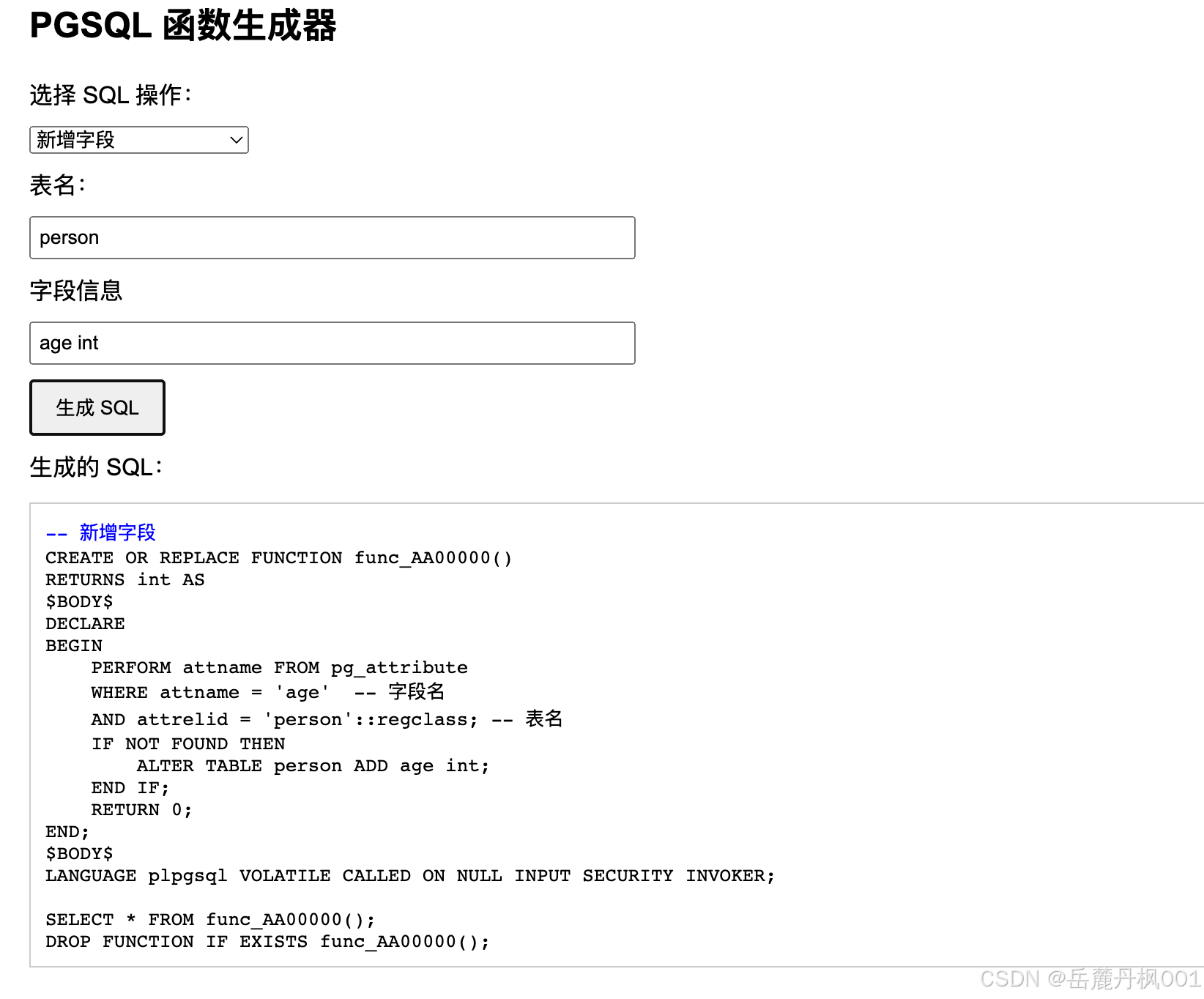
PGSQL 对象创建函数生成工具
文章目录 代码结果 代码 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>PGSQL 函数生成器</tit…...
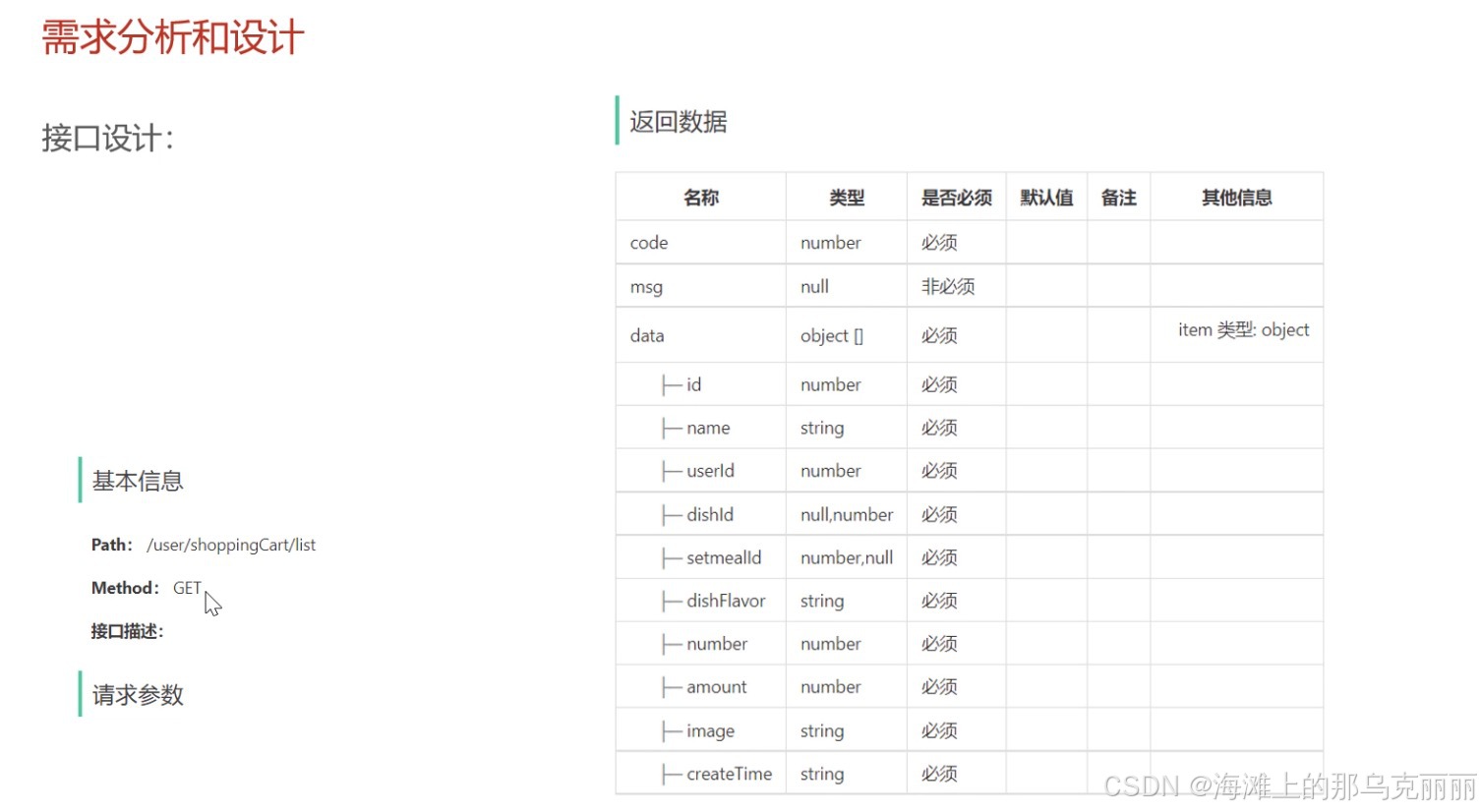
查询当前用户的购物车和清空购物车
业务需求: 在小程序用户端购物车页面能查到当前用户的所有菜品或者套餐 代码实现 controller层 GetMapping("/list")public Result<List<ShoppingCart>> list(){List<ShoppingCart> list shoppingCartService.shopShoppingCart();r…...
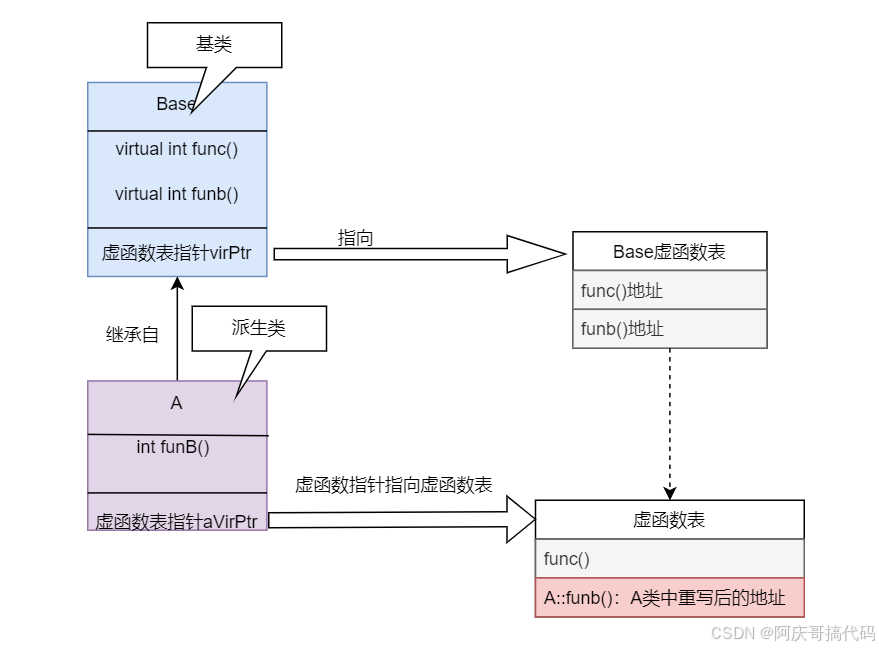
八、重学C++—动态多态(运行期)
上一章节: 七、重学C—静态多态(编译期)-CSDN博客https://blog.csdn.net/weixin_36323170/article/details/146999362?spm1001.2014.3001.5502 本章节代码: cpp/dynamicPolymorphic.cpp CuiQingCheng/cppstudy - 码云 - 开源中…...

react redux的学习,多个reducer
redux系列文章目录 第一章 简单学习redux,单个reducer 前言 前面我们学习到的是单reducer的使用;要知道redux是个很强大的状态存储库,可以支持多个reducer的使用。 combineReducers combineReducers是Redux中的一个辅助函数,主要用于…...

饮食助力进行性核上性麻痹患者,提升生活质量
进行性核上性麻痹是一种少见的神经系统变性疾病,患者会出现姿势不稳、眼球运动障碍等症状。合理的饮食对于维持患者身体机能、延缓病情发展有重要意义。 高蛋白质食物是饮食结构的重要部分。像瘦肉、去皮禽肉、鱼类、豆类及其制品,还有低脂奶制品等&…...