zk基础—2.架构原理和使用场景二
大纲
1.zk的使用场景
2.zk主要会被用于那些系统
3.为什么在分布式系统架构中需要使用zk集群
4.zk分布式系统具有哪些特点
5.zk集群机器的三种角色
6.客户端与zk之间的长连接和会话
7.zk的数据模型znode和节点类型
8.zk最核心的Watcher监听回调机制
9.ZAB协议的主从同步机制和崩溃恢复机制
10.ZAB协议流程之集群启动-数据同步-崩溃恢复
11.采用2PC两阶段提交思想的ZAB消息广播流程
12.zk到底是强一致性还是最终一致性
13.ZAB协议下两种可能存在的数据不一致问题
14.崩溃恢复时新Leader和Follower的数据同步
15.ZAB协议会如何处理需要丢弃的消息的
16.zk的Observer节点的作用
17.zk适合小集群部署 + 读多写少场景的原因
18.zk特性的总结
12.zk到底是强一致性还是最终一致性
(1)强一致性
(2)最终一致性
(3)顺序一致性
(1)强一致性
只要写入一条数据,无论从zk哪台机器上都可以马上读取到这条数据。强一致性的写入操作卡住时,直到Leader和全部Follower都进行了Commit,才能让写入操作返回,才能认为写入成功。所以只要写入成功,无论从哪个zk机器查询都能查到,这就是强一致性。很明显,ZAB协议机制下的zk不是强一致性。
(2)最终一致性
写入一条数据,方法返回写入成功。此时马上去其他zk机器上查有可能是查不到的,可能会出现短暂时间的数据不一致。但是过一会儿,一定会让其他机器同步到这条数据,最终一定可以查到写入的数据。
在ZAB协议中:当过半Follower对Proposal提议返回ACK时,Leader就会发送Commit消息给所有Follower。只要Follower或者Leader进行了Commit,那么这个数据就会被客户端读取到。
那么就有可能出现:有的Follower已经Commit了,但有的Follower还没有Commit。某个客户端连接到某个Follower时可以读取到刚刚Commit的数据,但有的客户端连接到另一个Follower时却没法读取到还没有Commit的数据。
所以zk不是强一致性的。Leader不会保证一条数据被全部Follower都Commit后,才让客户端读取到。在Commit的过程中,可能会出现在不同的Follower上读取到的数据是不一致的情况。但完成Commit后,最终一定会让客户端读取到一致的数据。
(3)顺序一致性
zk官方给自己的定义是顺序一致性,当然也属于最终一致性。但zk的顺序一致性比最终一致性更好一点,因为Leader会保证所有的Proposal提议同步到Follower时是按顺序进行同步的。
如果要求zk是强一致性,那么可以手动调用zk的sync()方法。
13.ZAB协议下两种可能存在的数据不一致问题
(1)Leader还没发送Commit消息就崩溃
(2)Leader还没广播Proposal提议就崩溃
(1)Leader还没发送Commit消息就崩溃
Leader收到了过半的Follower的ACK,接着Leader自己Commit了,但还没来得及发送Commit消息给所有Follower自己却宕机了。此时相当于Leader的数据跟所有Follower是不一致的,所以得保证全部Follower最终都完成Commit。
因此Leader崩溃后,就会选举一个拥有最大ZXID的Follower作为Leader,这个Leader会检查事务日志。如果发现自己事务日志里有一个还没进行提交的Proposal提议,那么旧说明旧Leader没来得及发送Commit消息就崩溃了。此时它作为新Leader会为这个Proposal提议向Follower发送Commit消息,从而保证旧Leader提交的事务最终可以被提交到所有Follower中。
同理,如果Leader收到过半Follower的ACK响应后,在发送Commit消息的过程中,出现Leader宕机或者Leader和Follower的网络问题。那么Follower只要与它能找到的Leader(新选举的ZXID最大的Follower或者原来的Leader)进行数据同步,就可以保证新数据在该Follower中完成Commit。
(2)Leader还没广播Proposal提议就崩溃
Leader没来得及发送Proposal提议给所有Follower的时候就宕机了,此时Leader上的这个请求应该是要被丢弃的。
对于这种情况:如果旧Leader日志里有一个事务Proposal提议,它重启后跟新Leader同步,发现这个事务Proposal提议其实是不应该存在的,那么就会直接丢弃。
14.崩溃恢复时新Leader和Follower的数据同步
(1)先发送Proposal提议再发送Commit消息
(2)Commit操作会把数据写入到内存中的znode
(3)通过已同步Follower列表判断数据可用
(4)选择ZXID最大的Follower作为新Leader的原因
(1)先发送Proposal提议再发送Commit消息
新选举出一个Leader后,其他Follower就会跟它进行数据同步。Leader会给每个Follower准备一个队列,然后把所有的Proposal提议都发送给Follower,并紧接着会发送Commit消息给那个Follower。
(2)Commit操作会把数据写入到内存中的znode
Commit操作就是把这条数据加入内存中的znode树形数据结构里,这样客户端就能访问到该数据,当然也会去通知监听这个znode的客户端。而收到Proposal提议时,会将数据以事务日志的形式顺序写入到磁盘。
(3)通过已同步Follower列表判断数据可用
如果一个Follower跟新Leader完成数据同步后,就会加入新Leader的已同步Follower列表中。当这个已同步Follower列表中有过半的Follower时,那么新Leader就可以对外继续提供服务了。
(4)选择ZXID最大的Follower作为新Leader的原因
在选举新Leader时,会挑选拥有最大ZXID的那个Follower作为新Leader。比如5个机器,1Leader + 4个Follower。1个Leader把Proposal发送给4个Follower,其中3个Follower(过半)都收到了Proposal返回ACK了,但是第四个Follower没收到Proposal。此时Leader执行Commit后挂了,Commit消息没法发送给其他Follower。这时剩余4个Follower,只要其中3个投票某一个当Leader,那它就可成为Leader。假设收到Proposal的那3个Follower都投票给没收到Proposal的Follower,那么这条数据就会永久丢失,所以需要选择一个拥有最大ZXID的Follower作为新Leader。
15.ZAB协议会如何处理需要丢弃的消息的
(1)ZAB协议根据epoch处理需要丢弃的消息
(2)ZAB协议的简单总结
(1)ZAB协议根据epoch处理需要丢弃的消息
每一个事务的ZXID是64位的,高32位是Leader的epoch(表示选举轮次),低32位是自增长的序列号。
如果一个Leader刚把一个Proposal提议写入本地磁盘日志,还没来得及广播Proposal提议给全部Follower就崩溃了。那么当新Leader选举出来后,事务的epoch会自增长一位。然后当旧Leader重启后重新加入集群成为Follower时,会发现自己比新Leader多出一条Proposal提议,但该Proposal提议的epoch比新Leader的epoch低,所以会丢弃这条数据。
(2)ZAB协议的简单总结
一.启动时:过半机器选举Leader + 数据同步
二.对外提供服务时:2PC + 过半写机制,顺序一致性(最终一致性)
三.崩溃恢复时:重新选举Leader + 针对两种数据不一致的情况进行处理
16.zk的Observer节点的作用
(1)对于写请求
(2)对于读请求
Observer节点不参与Leader选举,不参与广播提议时过半Follower进行ACK的环节,只处理客户端读请求和同步数据。
(1)对于写请求
由于Leader在进行数据同步时,Observer不会参与到过半写机制里。所以zk集群无论多少台机器,只能是由一个Leader进行写。Leader单机写入最多每秒上万QPS,这是没法扩展的。
因此zk是适合写少的场景。Redis的写QPS可以达10万,zk的写QPS才上万。虽然Redis和zk都是内存级的,而且对写请求的处理都是单线程处理的。但是由于Redis没有过半写机制,所以它的写性能更高。
(2)对于读请求
Follower通常会有2个或4个,这样处理读请求时就可以达到每秒几万QPS。如果引入更多的Follower,那么在过半写机制中会有更多的Follower参与。这会影响Leader写的效率,因此就有了Observer。
所以为了进一步提升zk集群对读请求的处理能力,可以引入Observer节点。由于它只同步数据提供读服务,所以可以无限扩展节点而不影响写效率。
17.zk适合小集群部署 + 读多写少场景的原因
(1)zk集群通常采用三五台机器小集群部署
(2)zk集群适合读多写少的场景
(1)zk集群通常采用三五台机器小集群部署
假设有1个Leader + 20个Follower,总共21台机器。此时由于Follower要参与到ZAB的写请求的过半ACK,所以一个写请求要等至少10个Follower返回ACK才能发送Commit消息。Leader发送Commit消息后才能告诉客户端写请求成功,所以性能会比较差。所以ZAB协议决定了zk集群通常采用1个Leader + 2个Follower的小集群。
(2)zk集群适合读多写少的场景
zk集群的写请求的处理能力是无法扩展的。如果读请求量大,可以加Observer机器。因此zk只适合读多写少的场景,所以zk主要是用来处理分布式系统的一些协调工作。
18.zk特性的总结
(1)集群模式部署
(2)主从架构
(3)内存数据模型
(4)顺序一致性
(5)高性能
(6)高可用
(7)高并发
(1)集群模式部署
一般奇数节点部署,不能超过一半的机器挂掉。因为5台机器可以挂2台,6台机器也最多只能挂2台。所以5台和6台效果一致,所以奇数节点可以减少机器开销。而且zk集群是小集群部署,适用于读多写少的场景。
(2)主从架构
Leader、Follower、Observer。
(3)内存数据模型
znode,多种节点类型,支持Watcher机制实现监听回调通知。
(4)顺序一致性
消息按顺序同步,但是最终才会一致,不是强一致。ZXID的高32位epoch,低32位是自增长的序列号。
(5)高性能
2PC中的过半写机制,纯内存的数据结构,znode。ZAB协议:2PC、过半ACK + 写事务日志,Commit + 写内存数据。
(6)高可用
Follower宕机没影响,Leader宕机有数据不一致问题。新选举的Leader会自动处理,正常运行。但是在恢复模式期间,可能有一小段时间是没法写入zk的。客户端跟zk进行TCP长连接,通过心跳机制维持Session。
(7)高并发
单机Leader写,Observer节点可以线性扩展读QPS。
相关文章:

zk基础—2.架构原理和使用场景二
大纲 1.zk的使用场景 2.zk主要会被用于那些系统 3.为什么在分布式系统架构中需要使用zk集群 4.zk分布式系统具有哪些特点 5.zk集群机器的三种角色 6.客户端与zk之间的长连接和会话 7.zk的数据模型znode和节点类型 8.zk最核心的Watcher监听回调机制 9.ZAB协议的主从同步…...
AI 数理逻辑基础之统计学基本原理(上)
目录 文章目录 目录统计学统计学基本概念描述性统计数据可视化图表工具 汇总统计统计数据的分布情况:中位数、众数、平均值统计数据的离散程度:极差、方差、标准差、离散系数 相关分析Pearson 线性关系相关系数Spearman 单调关系相关系数 回归分析回归模…...

积分赛——读取实时时间
设计要求 调用DS1302芯片驱动程序,读取DS1302中的实时时分秒数据,并显示在数码管上。 23时59分59秒 通过串口发送时间作为定时时间,定时时间到则蜂鸣器响2s后静音。 串口发送格式:“12:35:66”。 备注&…...

12.青龙面板自动化我的生活
安装 docker方式 docker run -dit \ -v /root/ql:/ql/data \ -p 5700:5700 \ -e ENABLE_HANGUPtrue \ -e ENABLE_WEB_PANELtrue \ --name qinglong \ --hostname qinglong \ --restart always \ whyour/qinglongk8s方式 https://truecharts.org/charts/stable/qinglong/ he…...
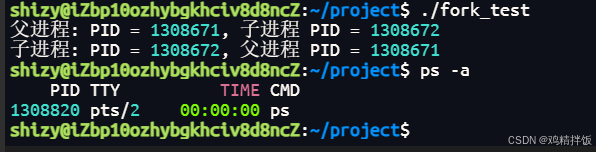
进程和线程的概念及Linux操作
文章目录 一、进程与线程1、进程2、线程3、查看进程与线程 二、Linux的“虚拟内存管理”,它与stm32中的 真实物理内存(内存映射)有什么区别?三、Linux系统调用函数 fork()、wait()、exec() 等1、fork()函数…...

uniapp中uploadFile的用法
基本语法 uni.uploadFile(OBJECT)OBJECT 是一个包含上传相关配置的对象,常见参数如下: 参数类型必填说明urlString是开发者服务器地址。filePathString是要上传文件资源的本地路径。nameString是文件对应的 key,开发者在服务端可以通过这个 …...
详细步骤)
VirtualBox 配置双网卡(NAT + 桥接)详细步骤
在 VirtualBox 中为 CentOS 虚拟机配置双网卡(NAT 桥接),使其既能访问外网(NAT),又能与宿主机(Windows 10)或局域网通信(桥接)。 步骤 1:关闭虚…...
APang网联科技项目报告【服务器篇】
APang网联科技:连接未来,智能领航 公司简介 APang网联科技成立于 [2005年],总部位于 [广东深圳],是一家集网络技术研发、系统集成、项目实施与运维服务为一体的高新技术企业。我们致力于为客户提供全方位、定制化的网络部署解决…...

[MySQL初阶]MySQL表的操作
MySQL表的操作 1. 创建表2. 查看表结构3. 修改表(修改表的属性而非表的数据)4. 删除表 1. 创建表 语法: CREATE TABLE table_name (field1 datatype,field2 datatype,field3 datatype ) character set 字符集 collate 校验规则 engine 存储…...
AI助力高效PPT制作:从内容生成到设计优化
随着人工智能技术的不断发展,AI在各个领域的应用日益普及,尤其是在文档和演示文稿的创建过程中。PowerPoint(PPT)作为最常用的演示工具之一,借助AI的技术手段,可以极大地提高制作效率并提升最终呈现效果。在…...

《双影奇境》手机版上线?ToDesk用跨平台技术实现「全设备云电脑3A游戏」
《双影奇境》是由Hazelight Studios研发发行的一款双人合作冒险类游戏,玩家们在游戏中将扮演米欧和佐伊两位风格迥异的女作家,剧情讲述的是她们被骗进入一台意在窃取创意的机器后便陷入了自己创作的故事之中,并且必须相互依靠,努力…...
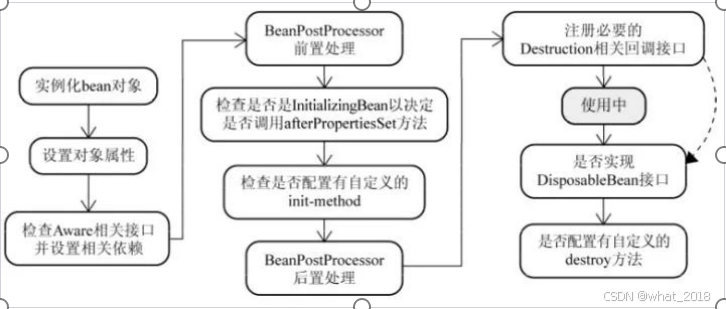
spring IOC 反射 bean生命周期
目录 反射 反射三种方式 获取反射中的Class对象 通过反射创建类对象 通过反射获取类属性、方法、构造器 IOC 概念 原理 实现方式 基于 XML 配置 基于注解配置 IOC优点 IOC的初始化过程 1. 资源定位 3. Bean 定义注册 4. BeanFactory 后置处理 5. Bean 后置处理…...

Pytorch中预置数据集的加载方式
Pytorch中数据集加载方式 数据类型PyTorch 模块是否预置数据集图像/视频torchvision.datasets✅ 是音频torchaudio.datasets✅ 是文本torchtext.datasets✅ 是(需安装)自定义数据torch.utils.data❌ 否(需手动实现)多模态/第三…...

ARM-----数据处理、异常处理、模式切换
实列一: 1. 异常向量表 area reset, code, readonly code32 entry area reset, code, readonly:定义一个名为reset的代码区域,只读。 code32:指示编译器生成32位ARM指令。 entry:标记程序的入口点。 2. 程序入口…...

[2013][note]通过石墨烯调谐用于开关、传感的动态可重构Fano超——
前言 类型 太赫兹 + 超材料 太赫兹 + 超材料 太赫兹+超材料 期刊 S C I E N T I F I C R...
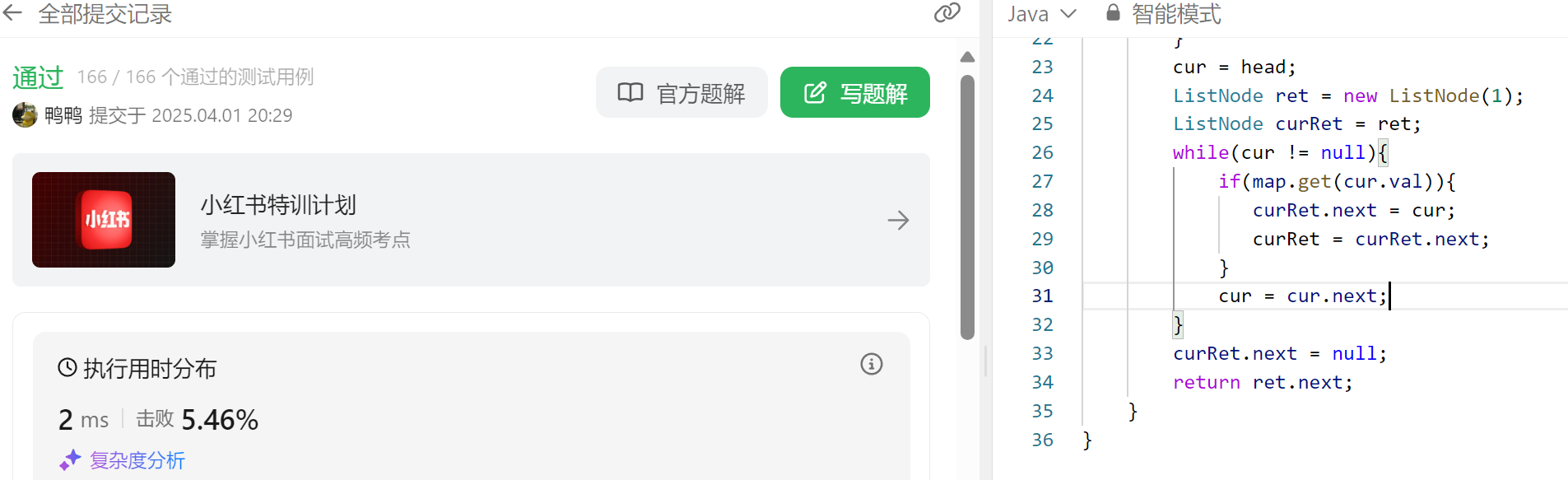
d202541
目录 一、分隔链表 二、旋转链表 三、删除链表中重复的数字 一、分隔链表 用两个list存一下小于和大于等于 x的节点 最后串起来就行 public ListNode partition(ListNode head, int x) {ListNode ret new ListNode(1);ListNode cur ret;List<ListNode> small new A…...

YOLOv12 从预训练迈向自主训练,第一步数据准备
视频讲解: YOLOv12 从预训练迈向自主训练,第一步数据准备 前面复现过yolov12,使用pre-trained的模型进行过测试,今天来讲下如何训练自己的模型,第一步先准备数据和训练格式 https://gitcode.com/open-source-toolkit/…...

【UVM学习笔记】更加灵活的UVM—通信
系列文章目录 【UVM学习笔记】UVM基础—一文告诉你UVM的组成部分 【UVM学习笔记】UVM中的“类” 文章目录 系列文章目录前言一、TLM是什么?二、put操作2.1、建立PORT和EXPORT的连接2.2 IMP组件 三、get操作四、transport端口五、nonblocking端口六、analysis端口七…...
NSSCTF [HGAME 2023 week1]simple_shellcode
3488.[HGAME 2023 week1]simple_shellcode 手写read函数shellcode和orw [HGAME 2023 week1]simple_shellcode (1) motalymotaly-VMware-Virtual-Platform:~/桌面$ file vuln vuln: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpret…...

前端面试题之CSS中的box属性
前几天在面试中遇到面试官问了一个关于box的属性面试题,平时都是直接AI没有仔细去看过。来说说CSS中的常用box属性: 1. box-sizing box-sizing 属性定义了元素的宽度和高度是否包括内边距(padding)和边框(border&…...

数据集(Dataset)和数据加载器(DataLoader)-pytroch学习3
pytorch网站学习 处理数据样本的代码往往会变得很乱、难以维护;理想情况下,我们希望把数据部分的代码和模型训练部分分开写,这样更容易阅读、也更好维护。 简单说:数据和模型最好“分工明确”,不要写在一起。 PyTor…...

数据结构|排序算法(一)快速排序
一、排序概念 排序是数据结构中的一个重要概念,它是指将一组数据元素按照特定的顺序进行排列的过程,默认是从小到大排序。 常见的八大排序算法: 插入排序、希尔排序、冒泡排序、快速排序、选择排序、堆排序、归并排序、基数排序 二、快速…...

文件或目录损坏且无法读取:数据恢复的实战指南
在数字化时代,数据的重要性不言而喻。然而,在日常使用电脑、移动硬盘、U盘等存储设备时,我们难免会遇到“文件或目录损坏且无法读取”的提示。这一提示如同晴天霹雳,让无数用户心急如焚,尤其是当这些文件中存储着重要的…...
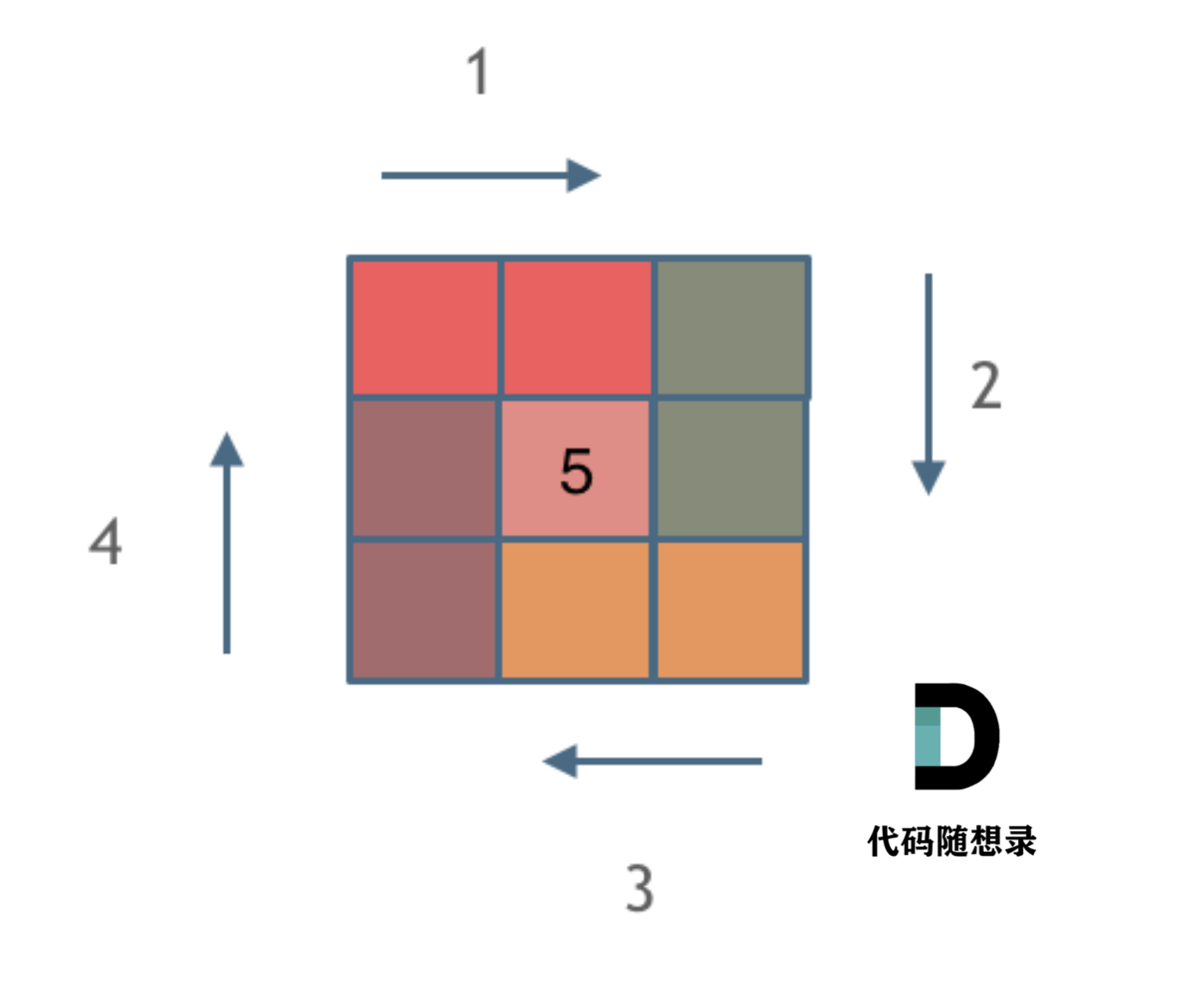
leetcode数组-螺旋矩阵Ⅱ
题目 题目链接:https://leetcode.cn/problems/spiral-matrix-ii/ 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 输入:n 3 输出:[[1,2,3],[8,9,4],[7…...
小刚说C语言刷题——第14讲 逻辑运算符
当我们需要将一个表达式取反,或者要判断两个表达式组成的大的表达式的结果时,要用到逻辑运算符。 1.逻辑运算符的分类 (1)逻辑非(!) !a,当a为真时,!a为假。当a为假时,!a为真。 例…...

WPS宏开发手册——Excel实战
目录 系列文章5、Excel实战使用for循环给10*10的表格填充行列之和使用for循环将10*10表格中的偶数值提取到另一个sheet页使用for循环给写一个99乘法表按市场成员名称分类(即市场成员A、B、C...),统计月内不同时间段表1和表2的乘积之和&#x…...

Buildroot与Yocto介绍比对
Buildroot 和 Yocto 是嵌入式 Linux 领域最常用的两大系统构建工具,它们在功能定位、使用方法和适用场景上有显著差异。以下从专业角度对两者进行对比分析: 一、Buildroot 核心功能与特点 1. 功能定位 轻量级系统构建工具:专注于快速生成精…...

前端加密方式 AES对称加密 RSA非对称加密 以及 MD5哈希算法详解
在前端开发中,MD5 并不是用于加密解密的算法,而是一个不可逆的哈希算法(即生成固定长度的摘要,但无法逆向解密)。如果你需要实现加密解密功能,应该使用对称加密算法(如 AES)或非对称…...
)
32--当网络接口变成“夜店门口“:802.1X协议深度解码(理论纯享版本)
当网络接口变成"夜店门口":802.1X协议深度解码 引言:网口的"保安队长"上岗记 如果把企业网络比作高端会所,那么802.1X协议就是门口那个拿着金属探测器的黑超保安。它会对着每个想进场的设备说:“请出示您的会…...

MAUI开发第一个app的需求解析:登录+版本更新,用于喂给AI
vscode中MAUI框架已经搭好,用MAUI+c#webapi+orcl数据库开发一个app, 功能是两个界面一个登录界面,登录注册常用功能,另一个主窗体,功能先空着,显示“主要功能窗体”。 这是一个全新的功能,需要重零开始涉及所有数据表 登录后检查是否有新版本程序,自动更新功能。 1.用户…...