Python爬虫第2节-网页基础和爬虫基本原理
目录
一、网页基础
1.1 网页的组成
1.2 网页的结构
1.3 节点树及节点间的关系
1.4 选择器
二、爬虫的基本原理
2.1 爬虫概述
2.2 能抓怎样的数据
2.3 JavaScript 渲染页面
一、网页基础
使用浏览器访问网站时,我们会看到各式各样的页面。你是否思考过,网页为何会呈现出这样的形态呢?在本节中,我们将深入了解网页的基本组成、结构以及节点等方面的内容。
1.1 网页的组成
网页一般由HTML、CSS和JavaScript这三部分组成。打个比方,如果把网页看作人,HTML就相当于人的骨架,CSS如同皮肤,JavaScript则类似肌肉。只有这三部分协同工作,才能打造出一个完整的网页。下面,我们来分别讲讲这三部分各自的功能。
(1)HTML
HTML,全称Hyper Text Markup Language,也就是超文本标记语言,专门用来描述网页。网页里有文字、按钮、图片、视频等各种复杂的元素,而HTML就是这些元素的基础架构。不同的元素用不同的标签来表示,像图片用img标签,视频用video标签,段落用p标签。为了安排这些元素的位置,常使用div标签进行嵌套组合。各种标签通过不同的排列和嵌套,最终搭建成网页的框架。
以Chrome浏览器为例,打开百度后,右键点击页面,选择“检查”选项(也可以直接按F12键),就能打开开发者模式。在Elements选项卡中,我们可以看到网页的源代码。网页就是由各种各样的标签嵌套组合而成,这些标签所定义的节点元素相互嵌套,层层组合,形成复杂的层级关系,从而构建出网页架构。

(2)CSS
HTML确定了网页的结构,但是光有HTML,页面布局会很单调,只是简单地排列节点元素,不够美观。为了让网页更好看,就需要用到CSS。
CSS的全称是Cascading Style Sheets,即层叠样式表。所谓“层叠”,就是当HTML引用多个样式文件,且这些样式出现冲突时,浏览器会按照特定顺序来处理。而“样式”指的是网页中文字的大小、颜色,元素之间的间距、排列方式等格式。
CSS是目前网页排版唯一的样式标准,借助它,网页会变得更加美观。比如这段代码“#head wrapper.s-ps-islite.s-p-top{position: absolute;bottom:40px;width:100%;height: 181px;}”,大括号前面的部分是CSS选择器,它的作用是先找到id为head wrapper且class为s-ps-islite的节点,再从这个节点里找到class为s-p-top的节点。大括号里面的内容是样式规则,像position规定元素采用绝对布局,bottom设定元素的下边距为40像素,width让元素宽度占满父元素,height指定元素的高度。通常,我们会把整个网页的样式规则统一写在后缀为.css的CSS文件里。在HTML文件中,只要用link标签引入这个CSS文件,网页就能变得美观又优雅。
(3)JavaScript
JavaScript简称JS,是一种脚本语言。HTML和CSS配合,只能给用户展示静态信息,缺乏互动性。而网页上的下载进度条、提示框、轮播图等具有交互性和动画效果的部分,通常都是JavaScript的功劳。JavaScript的出现,改变了用户与网页信息的关系,不再只是单纯的浏览和显示,而是实现了实时、动态且可交互的页面功能。
JavaScript一般保存在后缀为.js的单独文件里。在HTML文件中,通过script标签就可以引入JavaScript文件,比如“<script src="jquery-2.1.0.js"></script>”。
总的来说,HTML决定了网页的内容和结构,CSS负责网页的布局,JavaScript则定义了网页的行为。
1.2 网页的结构
我们先通过一个例子来感受 HTML 的基本结构。新建一个后缀为.html 的文本文件(名称可自行设定),内容如下:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>This is a Demo</title>
</head>
<body><div id="container"><div class="wrapper"><h2 class="title">Hello World</h2><p class="text">Hello,this is a paragraph.</p></div></div>
</body>
</html>上面是一个最简单的HTML示例。代码最开始的DOCTYPE声明确定了文档的类型,整个代码最外面用html标签包裹,并且有对应的结束标签来表示代码块的结束。在html标签里面,有head标签和body标签,它们分别对应网页的头部和主体部分,这两个标签也都有各自的结束标签。
在head标签里,定义了一些页面的设置和引用内容。例如,“<meta charset="UTF-8">”把网页的编码设置成了UTF - 8;title标签定义的标题会显示在浏览器的选项卡上,不会在网页正文中显示。
body标签里的内容会显示在网页的正文中。div标签用于划分网页中的区域,其中有一个div的id属性是container,id属性在网页里是唯一的,通过这个id能定位到对应的区域。在这个id为container的div里面,还有一个class属性为wrapper的div标签,class属性也是常用的,经常和CSS一起使用来设置样式。除此之外,代码里还有代表二级标题的h2标签和代表段落的p标签,它们也都有各自的class属性。
把这段代码保存为文件后,在浏览器里打开它,你会发现浏览器的选项卡上显示着“This is a Demo”,这是head标签里title标签定义的内容。而网页的正文是由body标签内的各个元素生成的,页面上会显示出二级标题和段落。
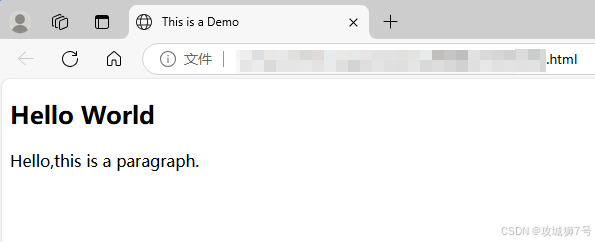
这个示例展示了网页的常见结构,也就是说,标准的网页结构是在html标签里嵌套head标签和body标签,head标签用来定义网页的设置和引用,body标签用来定义网页的正文内容。
1.3 节点树及节点间的关系
在 HTML 中,所有由标签定义的内容都是节点,它们共同构成了一个 HTML DOM 树。
DOM 是 W3C(万维网联盟)的标准,英文全称是 Document Object Model,即文档对象模型,它定义了访问 HTML 和 XML 文档的标准:W3C 文档对象模型(DOM)是中立于平台和语言的接口,允许程序和脚本动态地访问和更新文档的内容、结构和样式。
W3C DOM 标准分为 3 个不同部分:
- 核心 DOM:针对任何结构化文档的标准模型。
- XML DOM:针对 XML 文档的标准模型。
- HTML DOM:针对 HTML 文档的标准模型。
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
- 整个文档是一个文档节点。
- 每个 HTML 元素是元素节点。
- HTML 元素内的文本是文本节点。
- 每个 HTML 属性是属性节点。
- 注释是注释节点。
HTML DOM 将 HTML 文档视为树结构,这种结构称为节点树。通过 HTML DOM,树中的所有节点都可以通过 JavaScript 访问,所有 HTML 节点元素都可以被修改、创建或删除。
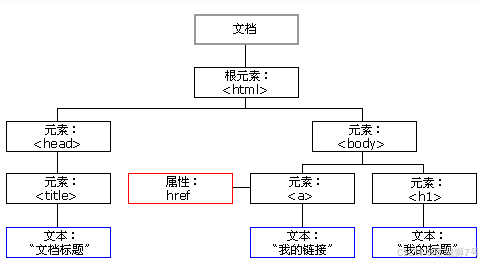
节点树中的节点之间存在层级关系,我们常用父(parent)、子(child)和兄弟(sibling)等术语来描述这些关系。父节点拥有子节点,同级的子节点被称为兄弟节点。在节点树中,顶端节点是根(root)。除根节点外,每个节点都有父节点,同时可以拥有任意数量的子节点或兄弟节点。

1.4 选择器
我们都清楚,网页是由一个个节点构成的。CSS选择器能够依据不同节点设置不同的样式规则,那要怎么找到这些节点呢?
在CSS里,我们借助CSS选择器来定位节点。举个例子,如果一个div节点的id是container,就可以写成#container,这里“#”开头就表示按id来选,后面跟着的就是id的名字;要是想选class为wrapper的节点,就用.wrapper,“.”开头代表按class选,后面跟着的是class的名字;也能按照标签名来筛选,比如选二级标题就用h2。这是最常用的三种选法,分别是按id、class、标签名来选,得记住它们的写法。
CSS选择器还能进行嵌套选择。选择器之间用空格隔开,就表示有嵌套关系。比如#container.wrapper p,意思就是先选id为container的节点,再从里面选class为wrapper的节点,最后从这个节点里选p节点;要是选择器之间没加空格,就表示是并列关系。像div#container.wrapper p.text,就是先选id为container的div节点,接着从里面选class为wrapper的节点,再从这个节点里选class为text的p节点。
CSS 选择器的筛选功能十分强大,此外,它还有一些其他语法规则,具体如下表所示:


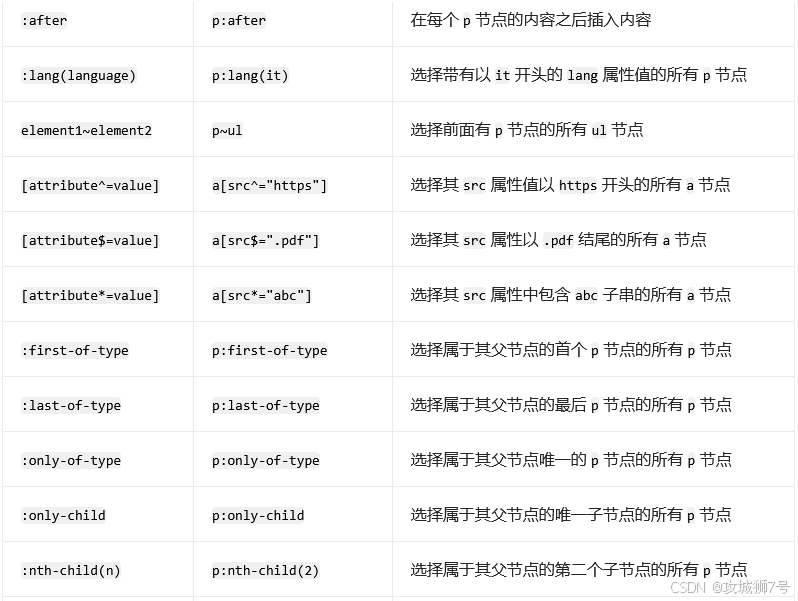
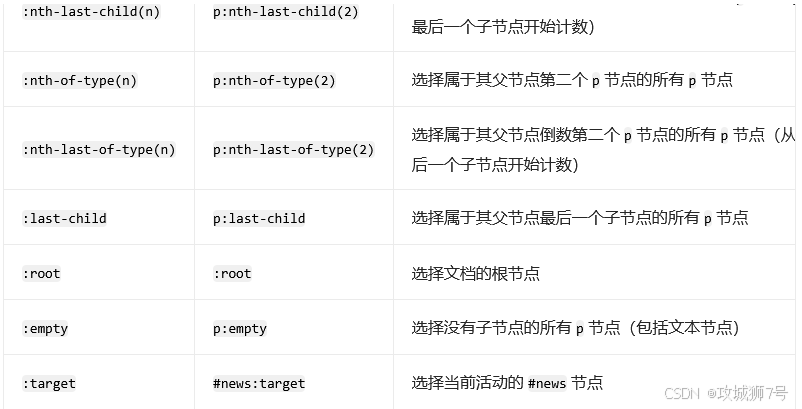

完整的选择器参考表:
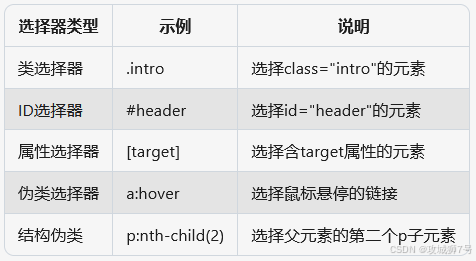
此外,XPath 也是一种常用的选择器,后面会详细介绍。本节介绍了网页的基本结构和节点间的关系,这些知识有助于我们更清晰地解析和提取网页内容。
二、爬虫的基本原理
咱们可以把互联网当作一张巨大的网,而爬虫,也就是网络爬虫,就像是在这张网上爬来爬去的蜘蛛。把网上的一个个节点当作网页,当爬虫访问一个网页时,就如同蜘蛛爬到了对应的节点,进而获取网页的信息。节点之间的连线,就好比网页与网页之间的链接。蜘蛛爬到一个节点后,能顺着连线爬到下一个节点。同样,爬虫通过一个网页,就能获取到后续的网页,如此一来,便能爬遍整个网上的节点,抓取网站的数据。
2.1 爬虫概述
简单来说,爬虫是一种自动化程序,专门用来获取网页信息,再对信息进行提取和保存。下面为你简单介绍一下:
(1)获取网页
爬虫要做的第一件事,就是获取网页,确切地说是获取网页的源代码。因为源代码里包含着网页的一些有用信息,拿到源代码后,就能从中提取出我们需要的信息。
之前我们讲过请求和响应的概念,向网站服务器发送请求,服务器返回的响应体就是网页的源代码。这里的关键,是要构造好请求,发送给服务器,然后接收响应并进行解析。当然,没人会手动去截取网页源码,Python提供了urllib、requests等库,来帮我们完成这项工作。使用这些库,就能发起HTTP请求,请求和响应都能用库中提供的数据结构来表示。得到响应后,解析数据结构里的Body部分,就能获取网页源代码,这样就通过程序实现了获取网页的过程。
(2)提取信息
拿到网页源代码后,接下来就要对源代码进行分析,从中提取出我们需要的数据。最常用的方法是用正则表达式提取,但编写正则表达式比较复杂,还容易出错。由于网页结构有一定的规律,我们还可以借助一些基于网页节点属性、CSS选择器或XPath的库,比如BeautifulSoup、pyquery、lxml等。这些库能快速、高效地提取网页信息,像节点的属性、文本值等。提取信息是爬虫很重要的一个环节,它能让杂乱无章的数据变得有条理,方便我们后续对数据进行处理和分析。
(3)保存数据
提取完信息后,一般要把数据保存起来,方便后续使用。保存数据的方式有很多种,可以保存为TXT文本或者JSON文本,也能保存到数据库里,比如MySQL和MongoDB。还能借助SFTP,把数据保存到远程服务器上。
(4)自动化程序
爬虫是自动化程序,能代替人完成很多操作。虽说手工也能提取信息,但要是数据量很大,或者需要快速获取大量数据,那就得借助程序了。爬虫在抓取数据的过程中,能进行异常处理、错误重试等操作,保证爬取工作持续、高效地进行。
2.2 能抓怎样的数据
在网页上,我们能看到各种各样的信息。最常见的就是常规网页,这类网页对应的是HTML代码,所以HTML源代码是我们最常抓取的内容。另外,有些网页返回的不是HTML代码,而是JSON字符串,很多API接口就是这样。这种格式的数据传输和解析都很方便,同样可以抓取,而且提取数据也更轻松。网页上还有图片、视频、音频等二进制数据,利用爬虫,能把这些数据抓取下来,并保存成对应的文件名。此外,像CSS、JavaScript和配置文件等各种扩展名的文件,只要在浏览器中能访问到,爬虫也能抓取。上面提到的这些内容,都有各自对应的URL,并且基于HTTP或HTTPS协议,只要是这类数据,爬虫都能抓取。
2.3 JavaScript 渲染页面
有时,使用 urllib 或 requests 抓取网页时,得到的源代码与浏览器中看到的不一致,这是常见问题。如今,网页越来越多地采用 Ajax、前端模块化工具构建,很多网页由 JavaScript 渲染而成,原始的 HTML 代码可能只是一个空壳。例如:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>This is a Demo</title>
</head>
<body><div id="container"></div>
</body>
<script src="app.js"></script>
</html>在这个HTML页面里,body节点下仅有一个id为container的节点。但值得留意的是,在body节点后面引入了app.js文件,整个网站页面的渲染工作都由它负责。
当我们在浏览器中打开这个页面时,浏览器首先会加载HTML内容。随后,浏览器检测到页面引入了app.js文件,便会向服务器发起对该文件的请求。获取到app.js文件后,浏览器就会执行其中的JavaScript代码。这些代码会对HTML中的节点进行修改,添加相应内容,经过这一系列操作,最终形成我们看到的完整页面。
然而,当我们使用urllib或requests等库向服务器请求页面时,这些库仅仅能获取到HTML代码,并不会自动加载JavaScript文件。这就导致我们无法看到和浏览器中一样的页面内容,也就解释了为什么通过这些库获取的源代码,和浏览器中实际显示的不一样。
由此可见,使用常规的HTTP请求库获取的源代码,可能与浏览器显示的页面源代码存在差异。针对这种情况,我们有两种解决办法。一是分析网站的后台Ajax接口;二是借助Selenium、Splash等库,模拟JavaScript在浏览器中的渲染过程。后续,我们会对采集JavaScript渲染网页的方法展开详细介绍。
在本节中,我们了解了爬虫的部分基本原理,掌握这些知识,能帮助我们在后续编写爬虫程序时,进展得更加顺利 。
参考学习书籍:Python 3网络爬虫开发实战
相关文章:
Python爬虫第2节-网页基础和爬虫基本原理
目录 一、网页基础 1.1 网页的组成 1.2 网页的结构 1.3 节点树及节点间的关系 1.4 选择器 二、爬虫的基本原理 2.1 爬虫概述 2.2 能抓怎样的数据 2.3 JavaScript 渲染页面 一、网页基础 使用浏览器访问网站时,我们会看到各式各样的页面。你是否思考过&…...

阿里巴巴langengine二次开发大模型平台
阿里巴巴LangEngine开源了!支撑亿级网关规模的高可用Java原生AI应用开发框架 - Leepy - 博客园 阿里国际AI应用搭建平台建设之路(上) - 框架篇 基于java二次开发 目前Spring ai、spring ai alibaba 都是java版本的二次基础能力 重要的是前端工作流 如何与 服务端的…...

深度学习中的 Batch 机制:从理论到实践的全方位解析
一、Batch 的起源与核心概念 1.1 批量的中文译名解析 Batch 在深度学习领域标准翻译为"批量"或"批次",指代一次性输入神经网络进行处理的样本集合。这一概念源自统计学中的批量处理思想,在计算机视觉先驱者Yann LeCun于1989年提出…...

【网络协议】三次握手与四次挥手
例如我们使用MobaXterm登录服务器的时候,基于TCP协议的之间是如何进行通信的? 使用工具:wireshark抓取传输层TCP协议 三次握手 mobaxterm:登录服务器触发三次握手 wireshark过滤分析 ip.addr 192.168.3.239 192.168.3.239登录…...

请求被中止: 未能创建 SSL/TLS 安全通道。
需要安装vs2019社区办,下载VisualStudioSetup.exe后,报无法从"https://aka,ms/vs/16/release/channel"下载通道清单错误,接着打开%temp%目录下的最新日志,发现日志里报: [27d4:000f][2025-04-04T21:15:43] …...
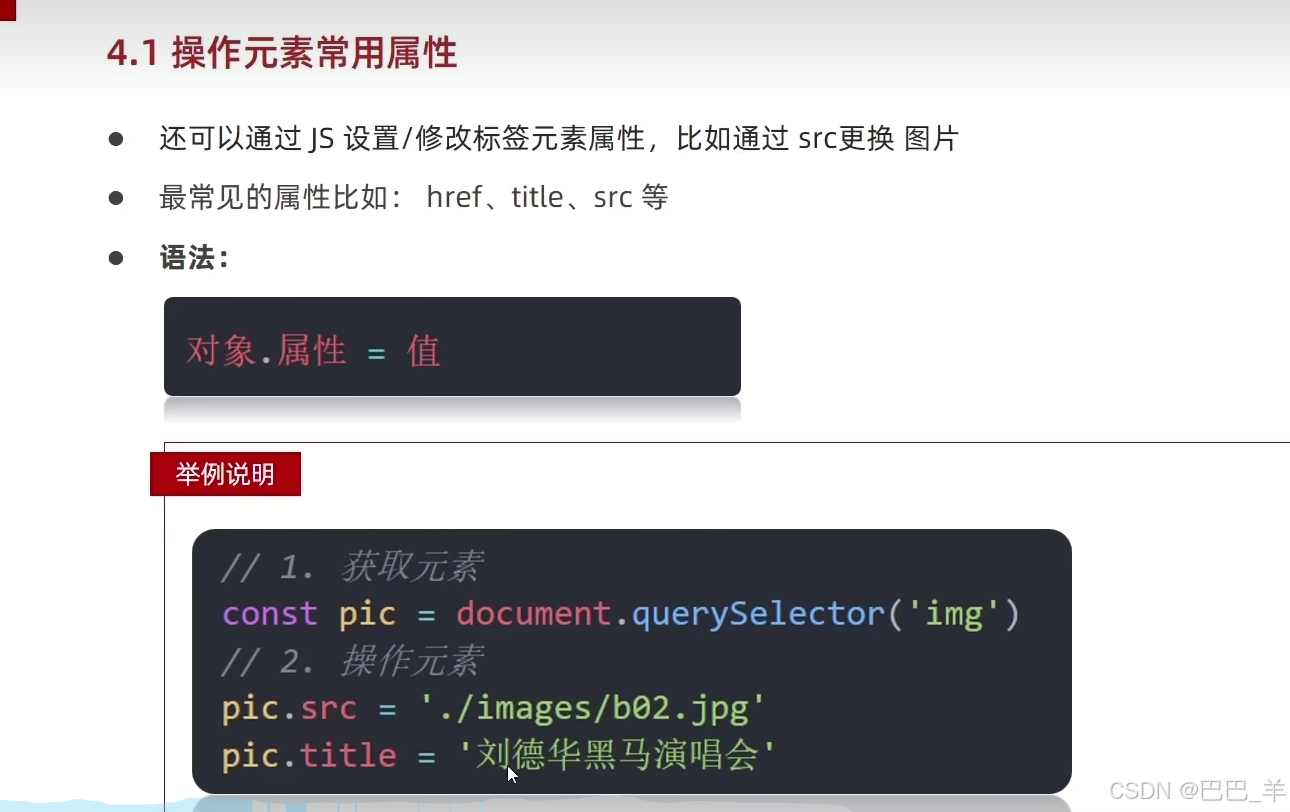
JS API
const变量优先 即对象、数组等引用类型数据可以用const声明 API作用和分类 DOM (ducument object model) 操作网页内容即HTML标签的 树状模型 HTML中标签 JS中对象 最大对象 document 其次大 html 以此类推 获取DOM对象 CSS 中 使用选择器 JS 中 选多个 时代的眼泪 修…...

“一路有你”公益行携手《东方星动》走进湖南岳阳岑川镇中心小学
2025年4月2日,“一路有你”公益行携手《东方星动》走进湖南岳阳岑川镇,一场充满爱与温暖的捐赠仪式在岑川镇中心小学隆重举行。这是一场跨越千里的爱心捐赠,也是一场别开生面的国防教育,更是一场赋能提质的文化盛宴。 岑川镇地处湘…...

vue组件开发:什么是VUE组件?
什么是VUE组件 在我们实际开发过程中你也许会发现有很多代码是重复的,它们可能是一个按钮、一个表单、一个列表等等,其中最为显著的应该是列表。 以CSDN的首页为例: 上述截图中的文章列表可能会在多处出现,比如此截图是精选博客…...
仿小红书社交源码+及时通讯聊天软件APP源码
多端支持,数据互通 本程序支持H5、小程序、安卓、iOS四端运行,共用同一套后台管理系统,确保数据同步,用户可在不同设备上无缝切换,实现真正的多端互通。 技术架构 前端技术:Vue2、uni-app、HTML、CSS、Jav…...

Libevent TCP开发指南
一、概念 Libevent 提供了高效的 TCP 网络编程接口,使开发者能够轻松构建高性能的 TCP 服务器和客户端。本指南将详细介绍如何使用 Libevent 进行 TCP 网络开发。 核心组件 事件基 (event_base) - 事件处理的核心结构 事件 (event) - 表示单个事件 缓冲区事件 (bufferevent)…...

Objective-C语言的集合
Objective-C语言的集合 引言 Objective-C是一种面向对象的编程语言,主要用于苹果的macOS和iOS系统应用程序的开发。作为C语言的一个超集,Objective-C继承了C语言的优雅,同时又添加了许多强大的特性,使其适合于大型项目的开发。在…...

网络安全与防护策略
随着互联网的普及与信息化程度的不断加深,网络安全问题已成为全球关注的焦点。从个人用户到大规模的企业系统,网络安全威胁的不断演变和升级已成为每个人和组织不可忽视的挑战。无论是恶意软件、钓鱼攻击,还是数据泄露、拒绝服务攻击…...

OpenCV:计算机视觉的强大开源库
文章目录 引言一、什么是OpenCV?1.OpenCV的核心特点 二、OpenCV的主要功能模块1. 核心功能(Core Functionality)2. 图像处理(Image Processing)3. 特征检测与描述(Features2D)4. 目标检测&#…...

Java基础:面向对象进阶(二)
01-static static修饰成员方法 static注意事项(3种) static应用知识:代码块 static应用知识:单列模式 02-面向对象三大特征之二:继承 什么是继承? 使用继承有啥好处? 权限修饰符 单继承、Object类 方法重…...

【MVP 和 MVVM 相比 MVC 有哪些优化点?】
MVP 和 MVVM 相比 MVC 的优化及原因 1. MVC 的痛点 在传统 MVC 模式中: 视图(View)和模型(Model)直接交互:View 可能直接监听 Model 的变化(如观察者模式),导致耦合。…...

ttkbootstrap 实现日期选择器, 开始和结束时间
ttkbootstrap 实现日期选择器, 开始和结束时间 1. 展示 2. 打印 3. 源码 from datetime import datetime import ttkbootstrap as ttkclass DateTimeEntryStart(ttk.Frame):def __init__(self, masterNone, **kwargs):super().__init__(master, **kwargs)self.dat…...
Vulnhub-PrinkysPalacev3
Vulnhub-PrinkysPalacev3 1、主机发现 arp-scan -l 扫描同网段 2、端口扫描 nmap -sS -sV 192.168.66.185 nmap -sS -A -T4 -p- 192.168.66.185 nmap --scriptvuln 192.168.66.185 PORT STATE SERVICE VERSION 21/tcp open ftp vsftpd 2.0.8 or later 5555/tcp o…...

matlab从pytorch中导入LeNet-5网络框架
文章目录 一、Pytorch的LeNet-5网络准备二、保存用于导入matlab的model三、导入matlab四、用matlab训练这个导入的网络 这里演示从pytorch的LeNet-5网络导入到matlab中进行训练用。 一、Pytorch的LeNet-5网络准备 根据LeNet-5的结构图,我们可以写如下结构 import…...

淘宝商品数据爬取与分析
淘宝商品数据爬取与分析是一个涉及网络爬虫技术和数据分析方法的过程,以下是其主要步骤: 数据爬取 确定爬取目标:明确要爬取的淘宝商品类别、具体商品名称或关键词等,例如想要分析智能手机市场,就以 “智能手机” 为…...
Spring Boot向Vue发送消息通过WebSocket实现通信
注意:如果后端有contextPath,如/app,那么前端访问的url就是ip:port/app/ws 后端实现步骤 添加Spring Boot WebSocket依赖配置WebSocket端点和消息代理创建控制器,使用SimpMessagingTemplate发送消息 前端实现步骤 安装sockjs-…...

Django4.0的快速查询以及分页
1. filter 方法 filter 是 Django ORM 中最常用的查询方法之一。它用来根据给定的条件过滤查询集并返回满足条件的对象。 articles Article.objects.all() # 使用 SearchFilter 进行搜索 search_param request.query_params.get(search, None) author_id request.query_pa…...

LangChain/Eliza框架在使用场景上的异同,Eliza通过配置实现功能扩展的例子
LangChain与Eliza框架的异同分析 一、相同点 模块化架构设计 两者均采用模块化设计,支持灵活扩展和功能组合。LangChain通过Chains、Agents等组件实现多步骤任务编排,Eliza通过插件系统和信任引擎实现智能体功能的动态扩展。模块化特性降低…...
事件流(SSE)推送)
用spring-webmvc包实现AI(Deepseek)事件流(SSE)推送
前后端: Spring Boot Angular spring-webmvc-5.2.2包 代码片段如下: 控制层: GetMapping(value "/realtime/page/ai/sse", produces MediaType.TEXT_EVENT_STREAM_VALUE)ApiOperation(value "获取告警记录进行AI分析…...

MusicMint ,AI音乐生成工具
MusicMint是什么 MusicMint 是一款强大的人工智能音乐创作工具,旨在帮助用户轻松制作个性化的音乐作品。借助先进的 AI 技术,用户只需输入简短的描述或选择心仪的音乐风格,便能迅速生成独特的歌曲。该平台支持多种音乐风格,包括流…...

嵌入式学习笔记——SPI协议
SPI协议详解 SPI协议概述SPI接口信号介绍SPI通信模式SPI的通信流程SPI的优缺点优点缺点 SPI在STM32上的实现SPI引脚配置SPI初始化代码(STM32F10x)SPI主设备发送和接收数据SPI从设备数据处理 总结 SPI协议概述 SPI(Serial Peripheral Interfa…...
网络编程—Socket套接字(UDP)
上篇文章: 网络编程—网络概念https://blog.csdn.net/sniper_fandc/article/details/146923380?fromshareblogdetail&sharetypeblogdetail&sharerId146923380&sharereferPC&sharesourcesniper_fandc&sharefromfrom_link 目录 1 概念 2 Soc…...
视频设备轨迹回放平台EasyCVR综合智能化,搭建运动场体育赛事直播方案
一、背景 随着5G技术的发展,体育赛事直播迎来了新的高峰。无论是NBA、西甲、英超、德甲、意甲、中超还是CBA等热门赛事,都是值得记录和回放的精彩瞬间。对于体育迷来说,选择观看的平台众多,但是作为运营者,搭建一套体…...

AIGC实战——CycleGAN详解与实现
AIGC实战——CycleGAN详解与实现 0. 前言1. CycleGAN 基本原理2. CycleGAN 模型分析3. 实现 CycleGAN小结系列链接 0. 前言 CycleGAN 是一种用于图像转换的生成对抗网络(Generative Adversarial Network, GAN),可以在不需要配对数据的情况下将一种风格的图像转换成…...
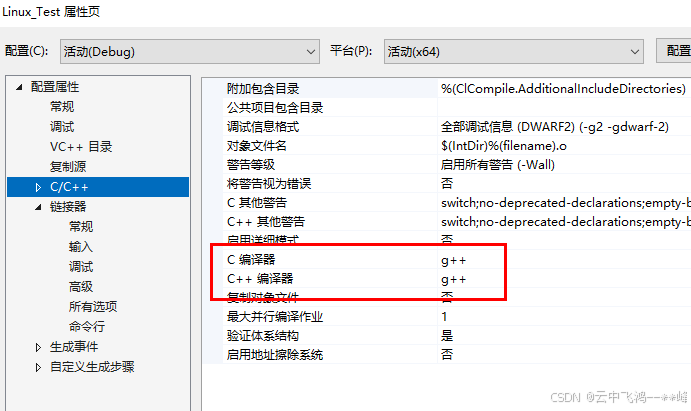
VS2022远程调试Linux程序
一、 1、VS2022安装参考 VS Studio2022安装教程(保姆级教程)_visual studio 2022-CSDN博客 注意:勾选的时候,要勾选下方的选项,才能调试Linux环境下运行的程序! 2、VS2022远程调试Linux程序测试 原文参…...

345-java人事档案管理系统的设计与实现
345-java人事档案管理系统的设计与实现 项目概述 本项目为基于Java语言的人事档案管理系统,旨在帮助企事业单位高效管理员工档案信息,实现档案的电子化、自动化管理。系统涵盖了员工信息的录入、查询、修改、删除等功能,同时具备权限控制和…...