股票日数据使用_未复权日数据生成前复权日周月季年数据
目录
前置:
准备
代码:数据库交互部分
代码:生成前复权 日、周、月、季、年数据
前置:
1 未复权日数据获取,请查看 https://blog.csdn.net/m0_37967652/article/details/146435589 数据库使用PostgreSQL。更新日数据可以查看 https://blog.csdn.net/m0_37967652/article/details/146988667 将日数据更新到最新
2 权息数据,下载 t_exdividend.sql 文件
通过网盘分享的文件:t_exdividend.sql
链接: https://pan.baidu.com/s/17B1EiHcEYByfWSICqX1KNQ?pwd=4abg 提取码: 4abg
在命令行 postgresql安装目录的bin目录下执行
psql -U postgres -h 127.0.0.1 -p 5432 -d db_stock -f E:/temp005/t_exdividend.sql
E:/temp005/t_exdividend.sql 改成自己的文件目录
准备
1 从通达信中获取当前A股股票代码,存储到txt文件,一行一个股票代码
2 准备一个空目录,创建 day month quarter week year 目录

3 安装包
pip install pandas
pip install psycopg2
代码:数据库交互部分
这部分代码存储到 utils包目录下的 postgresql_utils01.py文件中
import psycopg2
import pandas as pddef connect_db():try:conn = psycopg2.connect(database='db_stock',user='postgres',password='',host='127.0.0.1',port=5432)except Exception as e:print(f'connection failed。{e}')else:return connpassdef query_multi_stock_daily(ticker_list:list)->list:ticker_list_str = '\',\''.join(ticker_list)ticker_list_str = '\''+ticker_list_str+'\''sql_str = f"select ticker,tradeDate,openPrice,highestPrice,lowestPrice,closePrice,turnoverVol,turnoverValue,dealAmount,turnoverRate,negMarketValue,marketValue,chgPct,PE,PE1,PB,isOpen,vwap from t_stock_daily where ticker in ({ticker_list_str});"conn = connect_db()cur = conn.cursor()cur.execute(sql_str)res = cur.fetchall()cur.close()conn.close()return resdef query_multi_exdiv(ticker_list:list)->list:ticker_list_str = '\',\''.join(ticker_list)ticker_list_str = '\'' + ticker_list_str + '\''sql_str = f"select ticker,exDate,perShareTransRadio,perCashDiv,allotmentRatio,allotmentPrice from t_exdividend where ticker in ({ticker_list_str});"conn = connect_db()cur = conn.cursor()cur.execute(sql_str)res = cur.fetchall()cur.close()conn.close()return res代码:生成前复权 日、周、月、季、年数据
from concurrent.futures import ThreadPoolExecutor
import os
import pandas as pd
from utils import postgresql_utils01
'''
股票日数据使用
'''
def output_daiy_caculate(thread_num:int,stock_ticker_list:list):pre_dir =r'E:/temp006/'# 每10个处理下print(f'thread {thread_num}, {len(stock_ticker_list)}')try:interval = len(stock_ticker_list) // 10for i in range(0, interval + 1):if (i + 1) * 10 >= len(stock_ticker_list):node_ticker_list = stock_ticker_list[i * 10:]else:node_ticker_list = stock_ticker_list[i * 10:(i + 1) * 10]daily_res = postgresql_utils01.query_multi_stock_daily(node_ticker_list)exdiv_res = postgresql_utils01.query_multi_exdiv(node_ticker_list)df_d_dict = {}df_ex_dict = {}for one in daily_res:ticker = one[0]df = pd.DataFrame(data={'tradeDate': one[1],'openPrice': one[2],'highestPrice': one[3],'lowestPrice': one[4],'closePrice': one[5],'turnoverVol': one[6],'turnoverValue': one[7],'dealAmount': one[8],'turnoverRate': one[9],'negMarketValue': one[10],'marketValue': one[11],'chgPct': one[12],'PE': one[13],'PE1': one[14],'PB': one[15],'isOpen': one[16],'vwap': one[17]})df_d_dict[ticker] = dfpassfor one in exdiv_res:ticker = one[0]df = pd.DataFrame(data={'exDate': one[1],'perShareTransRadio': one[2],'perCashDiv': one[3],'allotmentRatio': one[4],'allotmentPrice': one[5]})df_ex_dict[ticker] = dfpassfin_df_dict = {}for ticker, daily in df_d_dict.items():daily = daily.loc[daily['isOpen'] == 1].copy()daily['o_date'] = pd.to_datetime(daily['tradeDate'])daily.sort_values(by='o_date', ascending=True, inplace=True)if ticker not in df_ex_dict:fin_df_dict[ticker] = dailycontinueex = df_ex_dict[ticker]ex['a'] = 1 / (1 + ex['perShareTransRadio'] + ex['allotmentRatio'])ex['b'] = (ex['allotmentRatio'] * ex['allotmentPrice'] - ex['perCashDiv']) / (1 + ex['perShareTransRadio'] + ex['allotmentRatio'])ex['o_date'] = pd.to_datetime(ex['exDate'])ex.sort_values(by='o_date', ascending=True, inplace=True)for i, row in ex.iterrows():exDate = row['exDate']daily.loc[daily['o_date'] < exDate, 'closePrice'] = daily['closePrice'] * row['a'] + row['b']daily.loc[daily['o_date'] < exDate, 'openPrice'] = daily['openPrice'] * row['a'] + row['b']daily.loc[daily['o_date'] < exDate, 'highestPrice'] = daily['highestPrice'] * row['a'] + row['b']daily.loc[daily['o_date'] < exDate, 'lowestPrice'] = daily['lowestPrice'] * row['a'] + row['b']fin_df_dict[ticker] = dailypassother_cols = ['tradeDate', 'openPrice', 'highestPrice', 'lowestPrice', 'closePrice', 'turnoverVol','turnoverValue', 'dealAmount', 'turnoverRate', 'negMarketValue', 'marketValue']for ticker, df in fin_df_dict.items():d_path = pre_dir + 'day' + os.path.sep + ticker + '.csv'df.to_csv(d_path, encoding='utf-8', index=False)# 开始计算并导出week month quarter year 数据week_group = df.resample('W-FRI', on='o_date')month_group = df.resample('ME', on='o_date')quarter_group = df.resample('QE', on='o_date')year_group = df.resample('YE', on='o_date')w_df = week_group.last()w_df['openPrice'] = week_group.first()['openPrice']w_df['lowestPrice'] = week_group.min()['lowestPrice']w_df['highestPrice'] = week_group.max()['highestPrice']w_df['turnoverVol'] = week_group.sum()['turnoverVol']w_df['turnoverValue'] = week_group.sum()['turnoverValue']w_df['dealAmount'] = week_group.sum()['dealAmount']w_df['turnoverRate'] = week_group.sum()['turnoverRate']m_df = month_group.last()m_df['openPrice'] = month_group.first()['openPrice']m_df['lowestPrice'] = month_group.min()['lowestPrice']m_df['highestPrice'] = month_group.max()['highestPrice']m_df['turnoverVol'] = month_group.sum()['turnoverVol']m_df['turnoverValue'] = month_group.sum()['turnoverValue']m_df['dealAmount'] = month_group.sum()['dealAmount']m_df['turnoverRate'] = month_group.sum()['turnoverRate']q_df = quarter_group.last()q_df['openPrice'] = quarter_group.first()['openPrice']q_df['lowestPrice'] = quarter_group.min()['lowestPrice']q_df['highestPrice'] = quarter_group.max()['highestPrice']q_df['turnoverVol'] = quarter_group.sum()['turnoverVol']q_df['turnoverValue'] = quarter_group.sum()['turnoverValue']q_df['dealAmount'] = quarter_group.sum()['dealAmount']q_df['turnoverRate'] = quarter_group.sum()['turnoverRate']y_df = year_group.last()y_df['openPrice'] = year_group.first()['openPrice']y_df['lowestPrice'] = year_group.min()['lowestPrice']y_df['highestPrice'] = year_group.max()['highestPrice']y_df['turnoverVol'] = year_group.sum()['turnoverVol']y_df['turnoverValue'] = year_group.sum()['turnoverValue']y_df['dealAmount'] = year_group.sum()['dealAmount']y_df['turnoverRate'] = year_group.sum()['turnoverRate']w_df = w_df.loc[:, other_cols].copy()m_df = m_df.loc[:, other_cols].copy()q_df = q_df.loc[:, other_cols].copy()y_df = y_df.loc[:, other_cols].copy()w_df.to_csv(pre_dir + 'week' + os.path.sep + ticker + '.csv', encoding='utf-8')m_df.to_csv(pre_dir + 'month' + os.path.sep + ticker + '.csv', encoding='utf-8')q_df.to_csv(pre_dir + 'quarter' + os.path.sep + ticker + '.csv', encoding='utf-8')y_df.to_csv(pre_dir + 'year' + os.path.sep + ticker + '.csv', encoding='utf-8')passpassexcept Exception as e:print(f"{thread_num} error {e}")finally:print(f"{thread_num} finished")print(f'{thread_num} ending...')passdef start_execute():with open('./stock_ticker.txt',mode='r',encoding='utf-8') as fr:contents = fr.read()stock_ticker_list = contents.split('\n')print(len(stock_ticker_list))thread_count = 5interval = len(stock_ticker_list)//thread_countif interval == 0:thread_count = 1params_list = []thread_num_list = []for i in range(0,thread_count):if i == thread_count-1:pre_list = stock_ticker_list[i*interval:]else:pre_list = stock_ticker_list[i*interval:i*interval+interval]thread_num_list.append(i)params_list.append(pre_list)with ThreadPoolExecutor() as executor:executor.map(output_daiy_caculate, thread_num_list,params_list)print('线程池任务分配完毕')passif __name__ == '__main__':start_execute()pass相关文章:
股票日数据使用_未复权日数据生成前复权日周月季年数据
目录 前置: 准备 代码:数据库交互部分 代码:生成前复权 日、周、月、季、年数据 前置: 1 未复权日数据获取,请查看 https://blog.csdn.net/m0_37967652/article/details/146435589 数据库使用PostgreSQL。更新日…...

Java程序设计第1章:概述
一、Hello World 1.代码: public class HelloWorld {public static void main(String[] args){System.out.println("Hello World!");} } 2.运行结果: Hello World! 二、输出姓名、学号、班级 1.题目: 编写一个Application&a…...
【LeetCode Solutions】LeetCode 146 ~ 150 题解
CONTENTS LeetCode 146. LRU 缓存(中等)LeetCode 147. 对链表进行插入排序(中等)LeetCode 148. 排序链表(中等)LeetCode 149. 直线上最多的点数(困难)LeetCode 150. 逆波兰表达式求值…...

《 如何更高效地学习》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:个人谈心 🌍文章目入 一、明确学习目标二、制定学习计划三、选择合适的学习方法(一)主动学习(二)分散学习(三&#…...

常用中间件合集
简介 在游戏或者web服务器开发过程中 难免会使用一些中间件 正所谓有现成的 就没必要重复造轮子了 以下大概介绍下常用的中间件nginx etcd nats docker k8s nginx 简介 Nginx是一个 轻量级/高性能的反向代理Web服务器,他实现非常高效的反向代理、负载平衡,他可以处理2-3万…...

分布式数据一致性场景与方案处理分析|得物技术
一、引言 在经典的CAP理论中一致性是指分布式或多副本系统中数据在任一时刻均保持逻辑与物理状态的统一,这是确保业务逻辑正确性和系统可靠性的核心要素。在单体应用单一数据库中可以直接通过本地事务(ACID)保证数据的强一致性。 然而随着微服务架构的普及和业务场…...
JAVA:使用 Curator 进行 ZooKeeper 操作的技术指南
1、简述 Apache Curator 是一个基于 ZooKeeper 的 Java 客户端库,它极大地简化了使用 ZooKeeper 的开发工作。Curator 提供了高层次的 API,封装了很多复杂的 ZooKeeper 操作,例如连接管理、分布式锁、Leader 选举等。 在分布式系统中&#…...
)
C++ - 宏基础(简单常量替换宏、函数样式的宏、多行宏、预定义宏、字符串化宏、连接宏、可变参数日志宏)
宏概述 在编程中,宏(Macro)是一种预处理器指令 宏可以让程序员在源代码中定义一段值或代码的别名,在编译程序之前,预处理器会查找这些宏,并将其替换为相应的值或代码 C 宏 在 C 中,宏可以通过…...
Linux中的调试器gdb与冯·诺伊曼体系
一、Linux中的调试器:gdb 1.1安装与版本查看 可以使用yum进行安装: yum install -y gdb 版本查看:使用指令 gdb --version 1.2调试的先决条件:release版本与debug版本的切换 debug版本:含有调试信息 release版本…...
STM32 + keil5 跑马灯
硬件清单 1. STM32F407VET6 2. STLINK V2下载器(带线) 环境配置 1. 安装ST-LINK 2. 安装并配置 keil5 https://blog.csdn.net/qq_36535414/article/details/108947292 https://blog.csdn.net/weixin_43732386/article/details/117375266 3. 接线并下载 点击"LOAD“&a…...

Ruby语言的代码重构
Ruby语言的代码重构:探索清晰、可维护与高效的代码 引言 在软件开发的过程中,代码的质量直接影响到项目的可维护性、扩展性和整体性能。随着时间的推移,系统的需求变化,代码可能会变得混乱和难以理解,因此࿰…...

leetcode 数组总结篇
基础理论 数组:下标时从 0 开始的,地址是连续的,不能删除,只能覆盖;数组的实现:vector动态数组 常用操作 头文件 #include <iostream> #include <vector> #include <cstdint> // IN…...

盲盒小程序开发平台搭建:打造个性化、高互动性的娱乐消费新体验
在数字化浪潮席卷消费市场的今天,盲盒小程序以其独特的趣味性和互动性,迅速成为了年轻人追捧的娱乐消费新宠。盲盒小程序不仅为用户带来了拆盒的惊喜和刺激,更为商家提供了创新的营销手段。为了满足市场对盲盒小程序日益增长的需求࿰…...

DuckDB系列教程:如何分析Parquet文件
Parquet 是一种强大的、基于列的存储格式,适用于实现更快捷和更高效的数据分析。您可以使用 DuckDB 这种内存型分析数据库来处理 Parquet 文件并运行查询以对其进行分析。 在这篇文章中,我们将逐步介绍如何使用 DuckDB 对存储在 Parquet 文件中的餐厅订单…...

深入解析:使用Python爬取Bilibili视频
深入解析:使用Python爬取Bilibili视频 引言 Bilibili,作为中国领先的年轻人文化社区,拥有海量的视频资源。对于想要下载Bilibili视频的用户来说,手动下载不仅费时费力,而且效率低下。本文将介绍如何使用Python编写一…...
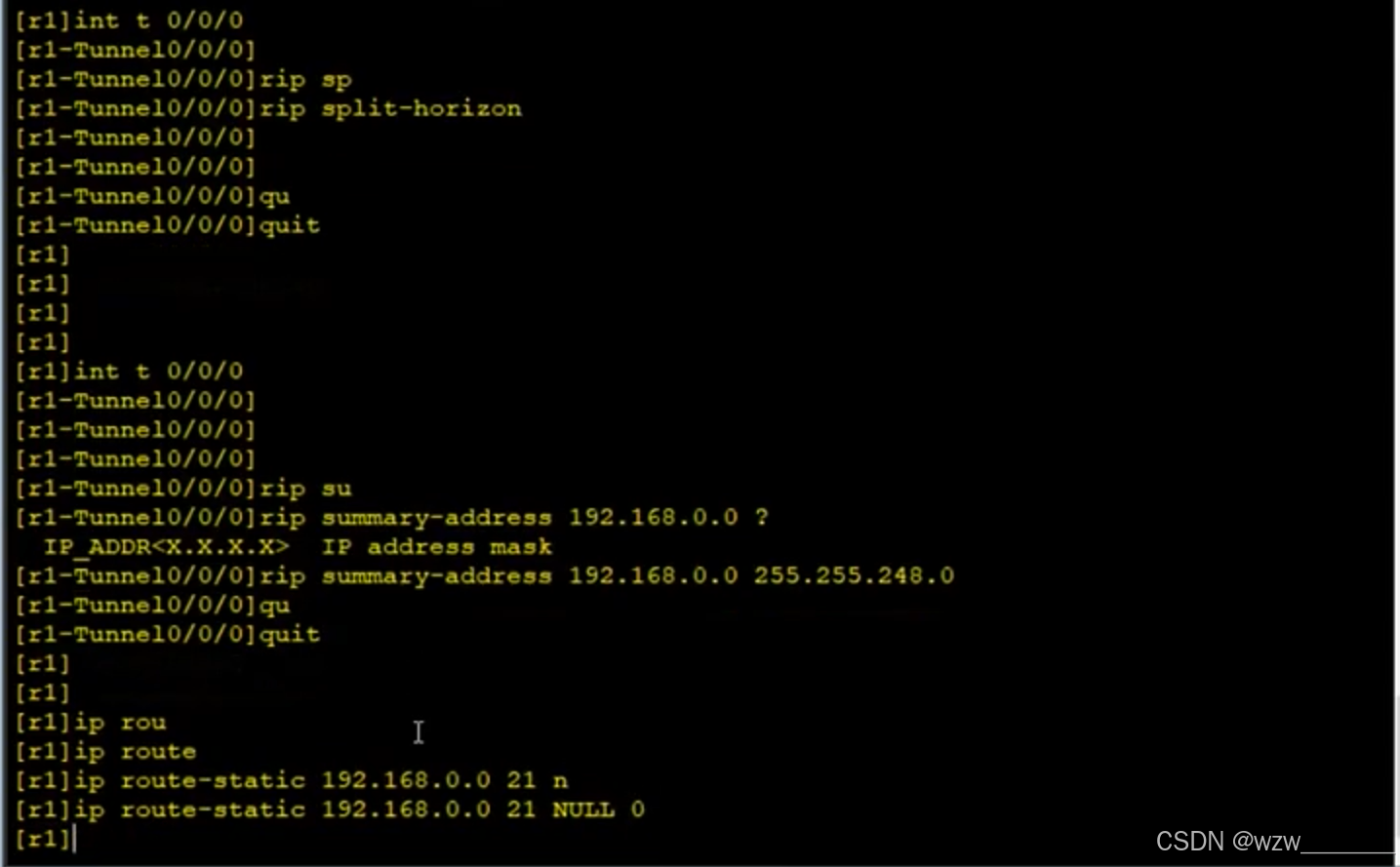
GRE,MGRE
GRE:静态过程,有局限性 R1 : [r1]interface Tunnel 0/0/0 --- 创建一个虚拟的隧道接口 [r1-Tunnel0/0/0]ip address 192.168.3.1 24 --- 给隧道接口分配一个 IP 地址 [r1-Tunnel0/0/0]tunnel-protocol gre --- 定义接口的封装方式 [r1-Tun…...
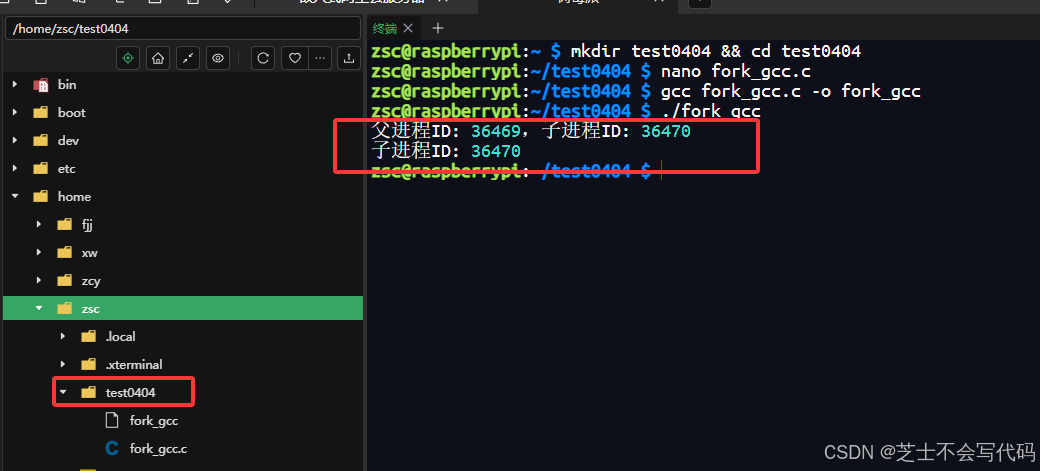
【linux学习】linux系统调用编程
目录 一、任务、进程和线程 1.1任务 1.2进程 1.3线程 1.4线程和进程的关系 1.5 在linux系统下进程操作 二、Linux虚拟内存管理与stm32的真实物理内存区别 2.1 Linux虚拟内存管理 2.2 STM32的真实物理内存映射 2.3区别 三、 Linux系统调用函数 fork()、wait()、exec(…...

Azure Speech 赋能,为智能硬件注入 AI 语音 “新灵魂”
在人工智能技术飞速发展的今天,智能硬件正逐步渗透到人们生活的方方面面。AI玩具、AI眼镜、AI鼠标等创新产品不仅提升了用户体验,更带来了前所未有的交互方式。领驭科技凭借微软Azure Speech的强大技术能力,为硬件厂商提供一站式AI语音解决方…...

力扣DAY35 | 热100 | LRU缓存
前言 中等 ⚪ 这个题原本打算用双链表最小堆做,发现无解。没想到双向链表。 题目 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int …...

Python 助力人工智能与机器学习的深度融合
技术革新的 “源动力” 在当今数字化时代,人工智能(AI)与机器学习(ML)无疑是最具影响力的技术领域,它们如同强大的引擎,推动着各个行业的变革与发展。Python 凭借其简洁易读的语法、丰富的库和…...

ARXML文件解析-1
目录 1 摘要2 ARXML文件2.1 作用及典型应用场景2.2 ARXML文件的结构树2.3 TAG(XML元素)2.4 ARXML文件关键元素解析2.4.1 XML声明与处理指令2.4.2 XML注释2.4.3 XML声明与根元素4.4.3.1 xmlns(默认命名空间)4.4.3.2 xmlns:xsi&…...

SignalR给特定User发送消息
1、背景 官网上SignalR的demo很详细,但是有个特别的问题,就是没有详细阐述如何给指定的用户发送消息。 2、解决思路 网上整体解决思路有三个: 1、最简单的方案,客户端连接SignalR的Hub时,只是简单的连接,…...

React: hook相当于函数吗?
一、Hook 是一个函数,但不仅仅是函数 函数的本质 Hook 确实是一个 JavaScript 函数,例如 useState、useEffect 或自定义 Hook 都是函数。它们可以接受参数(如初始状态值或依赖项数组),并返回结果(如状态值和…...

Ubuntu 安装 VLC
最近项目中需要用VLC查看NVR下子设备的RTSP流,特此记录,便于日后查阅。 1、安装snap $ sudo apt update $ sudo apt install snapd 2、安装vlc $ sudo snap install vlc 3、可能遇到的问题 snap beta install on ubuntu 22.04 failing to start Qt: Se…...

【数据分享】2002-2023中国湖泊水位变化数据集(免费获取)
湖泊水位变化是研究水资源动态、生态系统演变和气候变化影响的重要指标。湖泊水位的升降不仅反映了降水、蒸发和入流水量的变化,还与人类活动、气候波动及地质过程密切相关。因此,高精度、长时间序列的湖泊水位数据对于水资源管理、洪水预测以及生态环境…...

UBUNTU编译datalink
参考文档 datalink 语雀 下载 git clone https://gitee.com/liyang9512/datalink 源码打包 mvn -Prelease-datalink -Dmaven.test.skiptrue clean install -U 启动准备 # unzip ./distribution/target/datalink-server-1.0.0.tar.gz tar -xvf ./distribution/target/da…...
免费送源码:Java+SSM+Android Studio 基于Android Studio游戏搜索app的设计与实现 计算机毕业设计原创定制
摘要 本文旨在探讨基于SSM框架和Android Studio的游戏搜索App的设计与实现。首先,我们详细介绍了SSM框架,这是一种经典的Java Web开发框架,由Spring、SpringMVC和MyBatis三个开源项目整合而成,为开发企业级应用提供了高效、灵活、…...
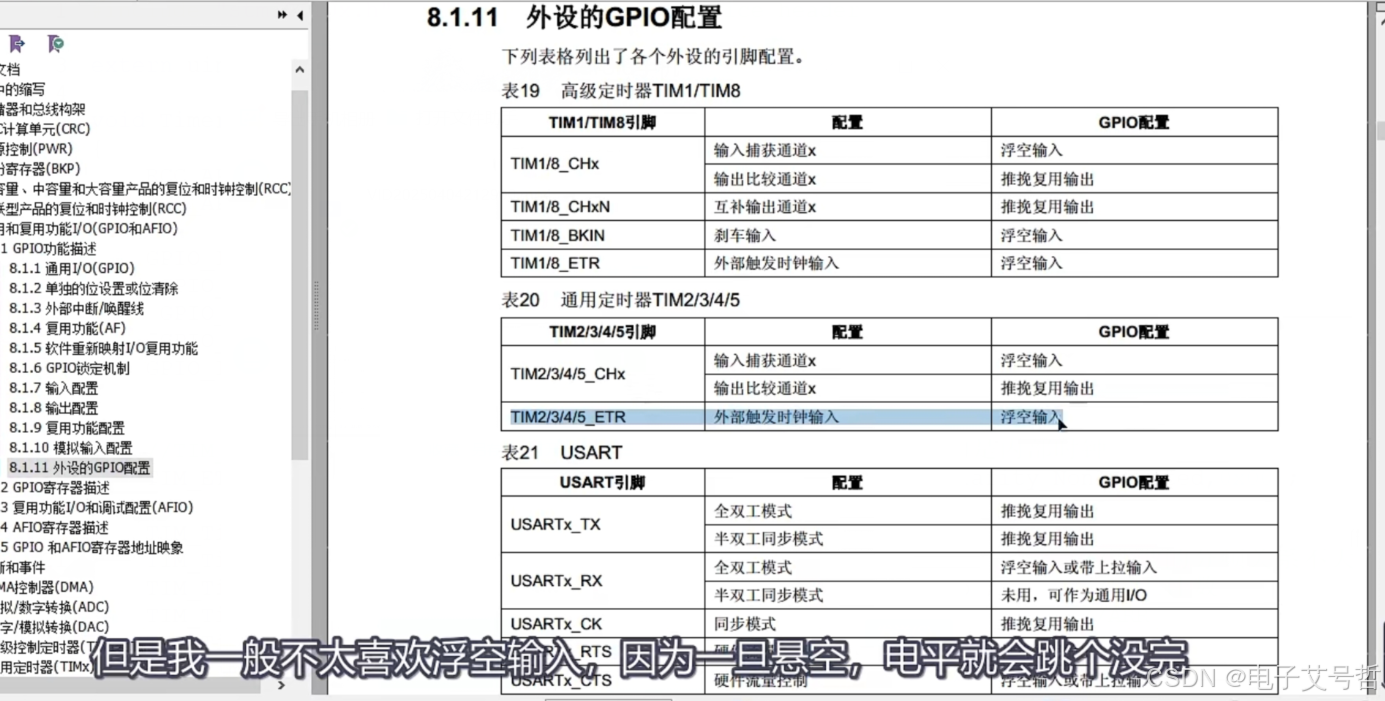
STM32单片机入门学习——第14节: [6-2] 定时器定时中断定时器外部时钟
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.04 STM32开发板学习——第14节: [6-2] 定时器定时中断&定时器外部时钟 前言开发…...

2025-04-03 Latex学习1——本地配置Latex + VScode环境
文章目录 1 安装 Latex2 安装 VScode3 配置环境3.1 汉化 VScode3.2 安装 latex 插件3.3 配置解释 4 编译示例5 加快你的编译5.1 取消压缩5.2 使用 PDF 代替图片 6 参考文章 1 安装 Latex 本文配置环境: Windows11 打开清华大学开源软件镜像站:https://mi…...

【CF】Day24——Codeforces Round 994 (Div. 2) D
D. Shift Esc 题目: 思路: 典DP的变种 如果这一题没有这个变换操作,那么是一个很典型的二维dp,每一个格子我们都选择上面和左边中的最小值即可 而这题由于可以变换,那我们就要考虑变换操作,首先一个显然…...