OFP--2018

文章目录
- Abstract
- Introduction
- Related Work
- 2D object detection
- 3D object detection from LiDAR
- 3D object detection from images
- Integral images
- 3D Object Detection Architecture
- Feature extraction
- Orthographic feature transform
- Fast average pooling with integral images
- Topdown network
- Confidence map prediction
- Localization and bounding box estimation
- Non-maximum suppression
- Conclusions
paper
Abstract
事实证明,从单眼图像中检测3D物体是一项极具挑战性的任务,目前领先的系统的性能甚至还达不到基于激光雷达的同类系统的10%。对这种性能差距的一种解释是,现有的系统完全受基于透视图像的表示的支配,其中物体的外观和规模随着深度和有意义的距离而急剧变化,很难推断。在这项工作中,我们认为对3D世界进行推理的能力是3D物体检测任务的基本要素。为此**,我们引入了正交特征变换,它使我们能够通过将基于图像的特征映射到正交三维空间来逃避图像域**。这使我们能够在一个尺度一致且物体之间的距离有意义的领域中,对场景的空间配置进行整体推理。我们将这种转换作为端到端深度学习架构的一部分,并在KITTI 3D对象基准上实现了最先进的性能。
Introduction
任何自主智能体的成功都取决于其检测和定位周围环境中物体的能力。预测、避免和路径规划都依赖于对场景中其他实体的3D位置和尺寸的稳健估计。这使得3D边界盒检测成为计算机视觉和机器人技术中的一个重要问题,特别是在自动驾驶的背景下。迄今为止,三维目标探测的方法主要是利用丰富的LiDAR点云[37,33,15,27,5,6,22,1],而缺乏LiDAR绝对深度信息的纯图像方法的性能明显落后。考虑到现有激光雷达设备的高成本、远距离激光雷达点云的稀疏性以及对传感器冗余的需求,从单眼图像中精确检测3D目标仍然是一个重要的研究目标。
为此,我们提出了一种新的3D目标检测算法,该算法以单眼RGB图像作为输入,产生高质量的3D边界框,在具有挑战性的KITTI基准[8]上实现了单眼方法中最先进的性能。
在许多意义上,图像是一种极具挑战性的形式。透视投影意味着单个物体的比例随着与相机的距离而变化很大;它的外观可以根据不同的视角发生巨大变化;而且3D世界中的距离无法直接推断。这些因素对单目三维目标检测系统提出了巨大的挑战。一种更加无害的表示是许多基于激光雷达的方法中常用的正射影鸟瞰图[37,33,1]。在这种表示下,尺度是均匀的;外表在很大程度上与观点无关;物体之间的距离是有意义的。因此,我们所看到的关键是,尽可能多的推理应该在这个正字法空间中进行,而不是直接在基于像素的图像域上进行。这一点对我们所提出的系统的成功至关重要。然而,目前尚不清楚如何仅从单目图像构建这样的表示。因此,我们引入了正交特征变换(OFT):一种将从透视RGB图像中提取的一组特征映射到正交鸟瞰特征映射的可微分变换。至关重要的是,我们不依赖任何明确的深度概念:相反,我们的系统建立了一个内部表示,能够确定图像中的哪些特征与鸟瞰图上的每个位置相关。我们应用深度卷积神经网络,即自顶向下网络,来局部推理场景的三维结构。我们的主要工作贡献如下:1。我们引入了正交特征变换(OFT),它将基于透视图像的特征映射为正交鸟瞰图,利用积分图像高效地实现快速平均池化。2. 我们描述了一种用于从单目RGB图像预测3D边界框的深度学习架构。3. 我们强调了在3D中对目标检测任务进行推理的重要性。
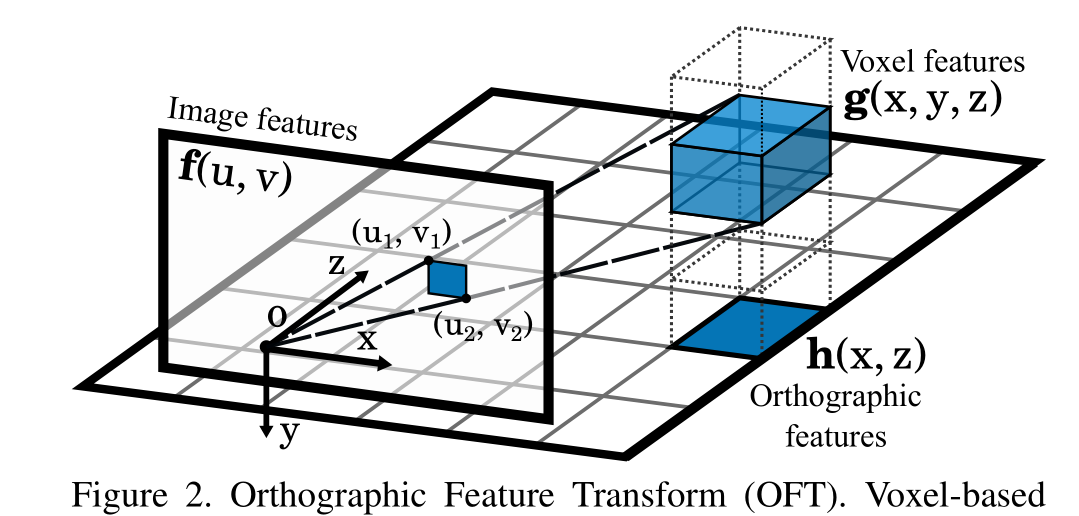
正交特征变换(OFT)。基于体素的特征g(x, y, z)是通过在投影体素区域上累积基于图像的特征f(u, v)而生成的。体素特征沿着垂直方向折叠,得到平面特征h(x, z)。
Related Work
2D object detection
检测图像中的2D边界框是一个被广泛研究的问题,最近的方法即使在最强大的数据集上也能表现出色[30,7,19]。现有方法大致可分为两大类:直接预测目标绑定盒的单级检测器如YOLO[28]、SSD[20]和RetinaNet[18],以及增加中间区域提议阶段的两级检测器如Faster R- CNN[29]和FPN[17]。迄今为止,绝大多数3D物体检测方法都采用了后一种方法,部分原因是难以从3D空间中固定大小的区域映射到图像空间中可变大小的区域。我们通过OFT变换克服了这一限制,使我们能够利用单级架构的速度和精度优势。
3D object detection from LiDAR
三维目标检测对于自动驾驶具有重要意义,目前已经提出了大量基于激光雷达的检测方法,并取得了相当大的成功。大多数变化源于激光雷达点云的编码方式。Qi et al.[27]的挫败点网络和Du et al.[6]的工作直接对点云本身进行操作,考虑了位于图像上由2D边界框定义的挫败范围内的点子集。Minemura等人[22]和Li等人[16]将点云投影到图像平面上,并对生成的RGB-D图像应用faster - rcnn风格的架构。其他方法,如TopNet[33]、BirdNet[1]和Yu et al.[37],将点云离散成一些鸟瞰图(BEV)表示,该表示编码诸如返回强度或地平面以上点的平均高度等特征。这种表示非常有吸引力,因为它没有展示任何在RGB-D图像中引入的透视伪影,例如,我们工作的主要重点是在那里,因此开发一个隐式的图像模拟这些鸟瞰图。另一个有趣的研究方向是传感器融合方法,如AVOD[15]和MV3D[5],它们利用地平面上的3D物体建议来聚合基于图像和鸟瞰的特征:这一操作与我们的正射影特征变换密切相关。
3D object detection from images
同时,由于缺乏绝对深度信息,从图像中获取三维边界框是一个非常具有挑战性的问题。许多方法从使用上述标准检测器提取的2D绑定框开始,在此基础上,它们要么直接回归每个区域的3D姿态参数[14,26,24,23],要么将3D模板拟合到图像中[2,35,36,38]。也许与我们的工作最密切相关的是Mono3D[3],它通过3D边界框提案密集地跨越3D空间,然后使用各种基于图像的特征对每个提案进行评分。其他探索世界空间中密集3D方案的作品有3DOP[4]和Pham and Jeon[25],它们依赖于使用立体几何对深度的明确估计。上述所有工作的一个主要限制是每个区域建议或边界框都是独立处理的,排除了关于场景3D配置的任何联合推理。我们的方法执行与[3]相似的特征聚合步骤,但在保留其空间配置的同时,对结果建议应用二次卷积网络。
Integral images
自从Viola和Jones b[32]的开创性工作引入积分图像以来,积分图像已经从根本上与目标检测联系在一起。它们已成为许多当代三维目标检测方法的重要组成部分,包括AVOD[15]、MV3D[5]、Mono3D[3]和3DOP[4]。然而,在所有这些情况下,积分图像不会反向传播梯度或构成完全端到端深度学习架构的一部分。据我们所知,之前唯一这样做的工作是Kasagi等人的[13],他们结合了卷积层和平均池化层来降低计算成本。
3D Object Detection Architecture

体系结构概述。前端ResNet特征提取器生成基于图像的特征,这些特征通过我们提出的正字法特征变换映射到正字法表示。自上而下的网络在鸟瞰空间中处理这些特征,并在地平面上的每个位置预测置信度评分S、位置偏移量∆pos、尺寸偏移量∆dim和角度矢量∆ang。
系统的概述如图3所示。该算法主要由五个部分组成:1。前端ResNet[10]特征提取器,从输入图像中提取多尺度特征映射。2. 非正射影特征变换,将每个尺度的基于图像的特征映射转换为正射影鸟瞰图表示。3. 一个自上而下的网络,由一系列ResNet残差单元组成,以一种与图像中观察到的视角效果不变的方式处理鸟瞰特征图。4. 一组输出头,它为每个对象类和地平面上的每个位置生成置信度评分、位置偏移、尺寸偏移和方向矢量。5. 非最大抑制和解码阶段,识别置信图中的峰值并生成离散边界框预测。
Feature extraction
我们架构的第一个元素是一个卷积特征提取器,它从原始输入图像中生成多尺度二维特征映射的层次结构。这些特征编码图像中低层结构的信息,这些信息构成了自顶向下网络用来构建场景隐式3D表示的基本组件。前端网络还负责根据图像特征的大小推断环深度信息,因为该架构的后续阶段旨在消除按比例变化。
Orthographic feature transform
为了在没有透视效果的情况下推断3D世界,我们必须首先将从图像空间中提取的特征映射应用到世界空间中的正交特征映射,我们称之为正交特征变换(OFT)。OFT的目标是用前端特征提取器提取的基于图像的特征映射f(u, v)∈Rn中的相关n维特征填充3D体素特征映射g(x, y, z)∈Rn。体素图是在一个均匀间隔的三维晶格G上定义的,该晶格固定在相机下方距离为y0的地平面上,尺寸为W, H, D,体素大小为r。对于给定的体素网格位置(x, y, z)∈G,我们通过在图像特征图f的面积上积累特征来获得体素特征G (x, y, z),该图像特征图f对应于体素的2D投影。一般来说,每个体素都是一个大小为r的立方体,在图像平面上投射到六边形区域。我们用一个矩形边界框来近似它的左上角和右下角分别是(u1,v1)和(u2,v2)它们由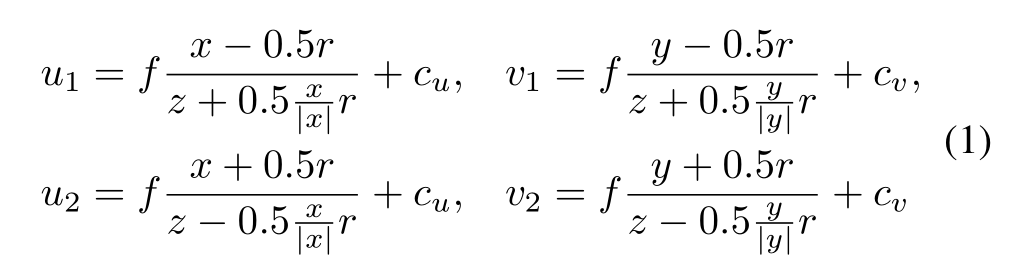
式中f为相机焦距,(cu,cv)为原理点。
然后,我们可以通过对图像特征图f中投影体素的边界框进行平均池化,将特征分配到体素特征图g中的适当位置: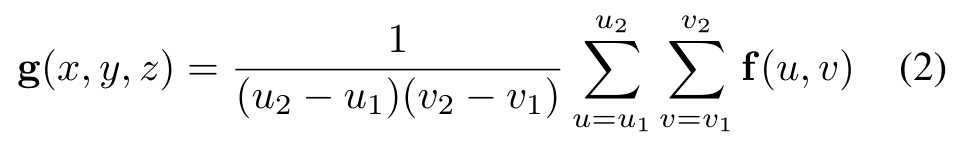
所得到的体素特征图g已经提供了一个场景的表示,它不受每个视角投影的影响。然而,在大体素网格上运行的深度神经网络通常是非常占用内存的。鉴于我们感兴趣的主要是美联社——皱纹如自主驾驶大多数对象固定在2 d地平面,我们可以通过崩溃使问题更容易处理3 d立体像素特征映射到一个第三,二维表示我们词拼写功能映射h (x, z),地图正字法的特性是通过总结体素特征沿纵轴与一组学习乘法后体重矩阵W (y)∈Rn×n:

在转换成最终的正射影特征图之前转换成中间体素表示的优点是保留了场景的垂直结构信息。这被证明是必不可少的下游任务,如估计高度和垂直位置的对象边界框。
Fast average pooling with integral images
上述方法的一个主要挑战是需要在非常多的区域上聚合特征。例如,一个典型的体素网格设置产生大约150k个边界框,这远远超过了Faster R-CNN[29]架构使用的~ 2k个感兴趣的区域。为了方便在如此大量的区域上进行池化,我们使用了基于积分图像[32]的快速平均池化操作。一个积分图像,或者在这种情况下,积分特征映射F,是使用递归关系从一个输入特征映射F构造出来的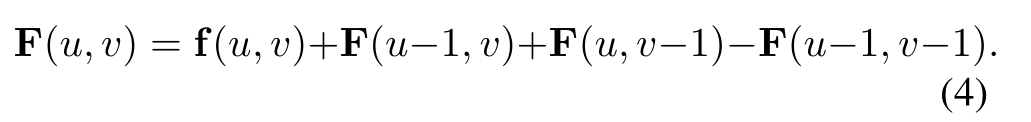
给定积分特征映射F,由边界框坐标(u1,v1)和(u2,v2)定义的区域(见式1)对应的输出特征g(x, y, z)为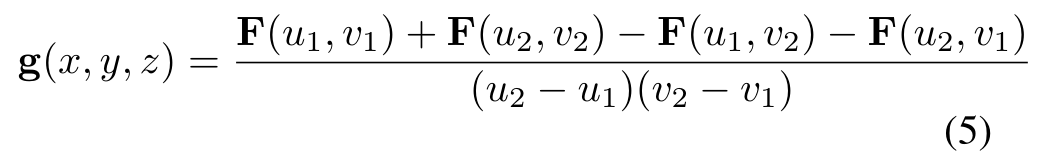
这种池化操作的复杂性与单个区域的大小无关,这使得它非常适合我们的应用程序,在我们的应用程序中,区域的大小和形状取决于体素是离相机近还是远。它在原始特征图f方面也是完全可区分的,因此可以用作端到端深度学习框架的一部分。
Topdown network
这项工作的一个重要贡献是强调了三维推理对复杂三维场景中物体识别和检测的重要性。在我们的体系结构中,这个重构组件是由一个子网络执行的,我们称之为自顶向下网络。这是一个简单的卷积网络,具有resnet风格的跳过连接,它在前面描述的OFT阶段生成的2D特征图h上运行。由于自顶向下网络的滤波器是卷积的,所以所有的处理对特征在地平面上的位置是不变的。这意味着,距离相机较远的特征图与距离较近的特征图得到完全相同的处理,尽管对应的图像区域要小得多。我们的目标是,最终的特征表示将因此捕获纯粹关于场景的底层3D结构的信息,而不是它的2D投影。
Confidence map prediction
在2D和3D方法中,检测通常被视为分类问题,使用交叉熵损失来识别图像中包含物体的区域。然而,在我们的应用中,我们发现采用Huang等人的置信图回归方法更为有效。置信图S(x, z)是一个平滑函数,它表示存在以位置(x, y0,z)为中心的有边界框的物体的概率,其中y0是相机到地平面的距离。给定一组N个具有边界框中心的基础真值对象pi = 【xi yi zi】T,i =1,…, N,我们将地面真值置信映射计算为每个目标中心周围宽度为σ的光滑高斯区域。位置(x, z)的置信度由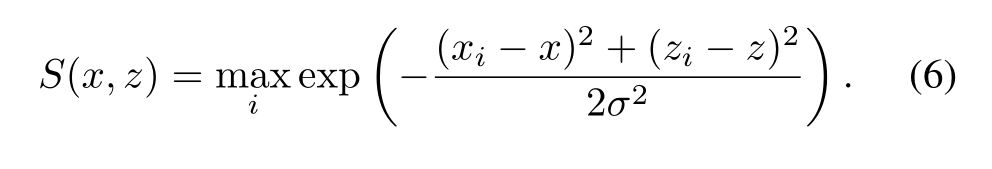
我们的网络的置信度图预测头是通过1损失来训练的,以回归到正字法网格h上每个位置的地面真实置信度。一个有充分记录的挑战是,正(高置信度)位置比负位置少得多,这导致损失的负分量主导优化[31,18]。为了克服这个问题,我们将对应于负位置(我们将其定义为S(x, z) < 0.05的位置)的损失按10 × 2的常数系数进行缩放。
Localization and bounding box estimation
置信图S将每个对象位置的粗略近似值编码为置信分数中的峰值,从而给出精确到特征图分辨率r的位置估计。为了更精确地定位每个目标,我们附加了一个额外的网络输出头,它预测从地平面(x, y0,z)上的网格单元位置到相应地真目标pi中心的相对偏移量∆pos: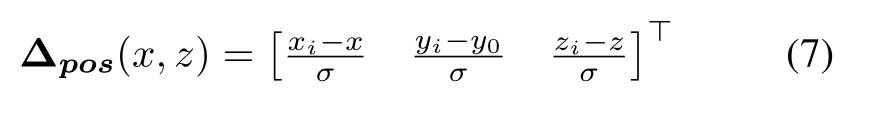
我们使用与3.4节中描述的相同的比例因子σ将位置偏移归一化到一个合理的范围内。如果对象的边界框的任何部分与给定的网格单元相交,则将ground truth对象实例i分配给网格位置(x, z)。不与任何地面真值对象相交的单元在训练期间被忽略。除了定位每个对象之外,我们还必须确定每个边界框的大小和方向。因此,我们引入两个进一步的网络输出。第一个是维头,它预测具有维数di = 【wi hi li】的指定地面真值对象i之间的对数尺度偏移量∆dim。平均维数d¯= [w¯ h¯ l]遍历给定类的所有对象。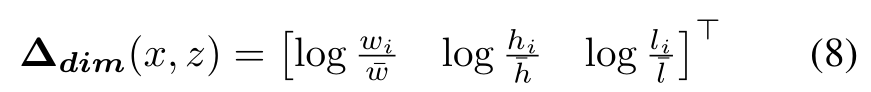
第二个,方向头,预测物体方向θi关于y轴的正弦和余弦:

请注意,由于我们是在正射影鸟瞰空间中操作,因此我们能够直接预测y轴方向θ,而不像其他作品(例如[23])预测所谓的观察角度α,以考虑透视和相对视点的影响。位置偏移量∆pos,尺寸偏移量∆dim和方向矢量∆ang使用1损失进行训练。
Non-maximum suppression
与其他目标检测算法类似,我们采用非最大抑制(NMS)阶段来获得最终的离散目标预测集。在传统的目标检测设置中,这一步可能是昂贵的,因为它需要O(N2)个边界框重叠计算。这是复合的事实,成对的三维盒子不一定是轴对齐的,这使得重叠的计算比2D的情况下更加困难。幸运的是,使用置信图代替锚盒分类的另一个好处是,我们可以在更传统的图像处理意义上应用NMS,即在二维置信图S上搜索局部最大值。在这里,正射影鸟瞰图再次被证明是无价的:在3D世界中,两个物体不可能占据相同的体积,这意味着置信度图上的峰值是自然分离的。为了减轻预测中噪声的影响,我们首先采用宽度为σNMS的高斯核平滑置信映射。如果S (xi,zi)≥S (xi +m, zi +n)∀m, n∈{-1,0,1}。(10)在产生的峰值位置中,任何置信度S(xi,yi)小于给定阈值t的位置都被消除。这将产生最终的预测对象实例集,其边界框中心pi、维度di和方向θi分别由公式7、8和9中的关系反转给出。
Conclusions
在这项工作中,我们提出了一种新的单眼3D物体检测方法,基于直觉,在鸟瞰域中操作可以减轻图像中许多不理想的属性,这些属性使得难以提供世界的3D配置。我们提出了一种简单的正射影特征转换方法,将基于图像的特征转换为鸟瞰图,并描述了如何利用积分图像有效地实现它。然后将其纳入深度学习管道的一部分,其中我们特别强调了以深度2D卷积网络形式应用于提取的鸟瞰图特征的空间推理的重要性。最后,我们通过实验验证了我们的假设,即在自上而下的空间中推理确实取得了更好的结果,并在KITTI 3D对象基准上展示了最先进的性能。
相关文章:
OFP--2018
文章目录 AbstractIntroductionRelated Work2D object detection3D object detection from LiDAR3D object detection from imagesIntegral images 3D Object Detection ArchitectureFeature extractionOrthographic feature transformFast average pooling with integral imag…...

libevent DNS开发
一、DNS功能 Libevent的DNS功能提供异步解析与服务器搭建能力,其核心设计分为阻塞式解析与事件驱动异步解析两套机制。 阻塞式解析(同步) 功能定位 通过evutil_getaddrinfo()提供可移植的阻塞式域名解析,兼容无标准getaddrinfo()接口的系统(如旧版…...
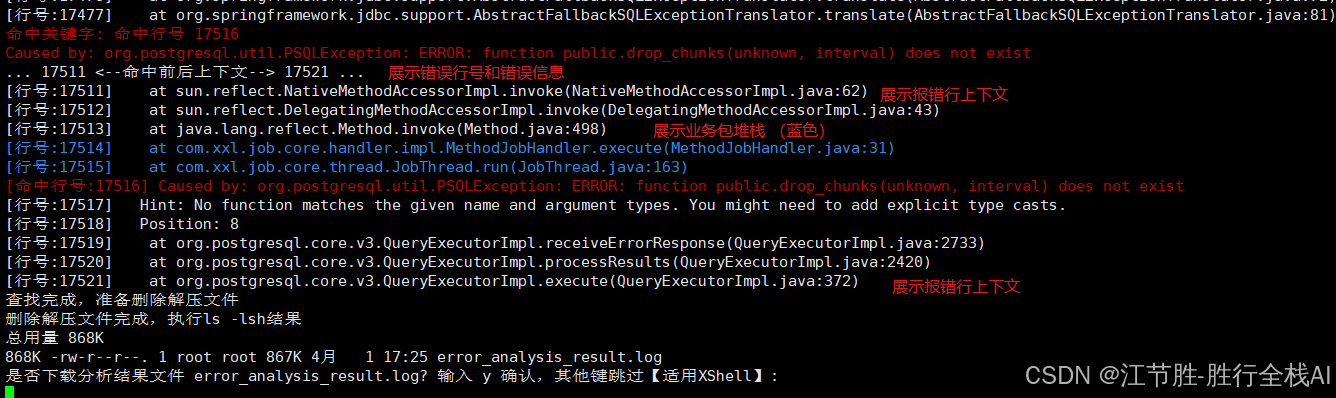
CentOS-查询实时报错日志-查询前1天业务报错gz压缩日志
最新版本更新 https://code.jiangjiesheng.cn/article/364?fromcsdn 推荐 《高并发 & 微服务 & 性能调优实战案例100讲 源码下载》 1. 查询实时报错日志 物理路径(带*的放在靠后,或者不用*) cd /home/logs/java-gz-log-dir &am…...
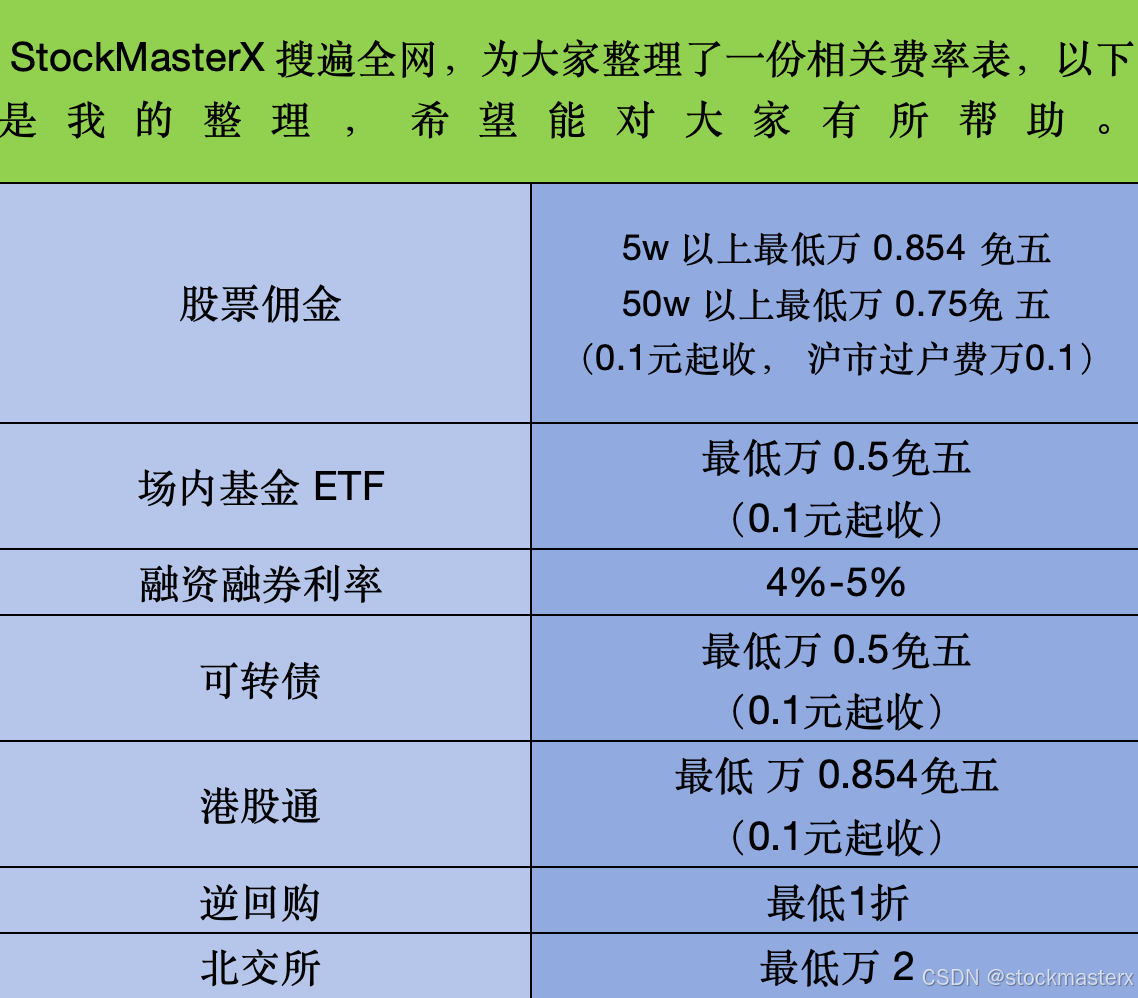
ETF 场内基金是什么?佣金最低又是多少呢?
嘿,朋友们,大家好啊,我是StockMasterX,今天咱们就坐下来慢慢聊聊这个话题,ETF 场内基金到底是个啥东西,它的佣金最低能到多少,真的是个值得深挖的问题。 说起ETF,我还记得刚入行那会…...

[论文阅读]PMC-LLaMA: Towards Building Open-source Language Models for Medicine
PMC-LLaMA:构建医学开源语言模型 摘要 最近,大语言模型在自然语言理解方面展现了非凡的能力。尽管在日常交流和问答场景下表现很好,但是由于缺乏特定领域的知识,这些模型在需要精确度的领域经常表现不佳,例如医学应用…...

26考研——线性表(2)
408答疑 文章目录 一、线性表的定义和基本操作二、线性表的顺序表示三、 线性表的链式表示四、 顺序表和链表的比较五、参考资料鲍鱼科技课件26王道考研书 六、总结顺序表总结顺序表特点深入掌握顺序表的管理方式 单链表总结双循环链表总结 一、线性表的定义和基本操作 文章链…...

写.NET可以指定运行SUB MAIN吗?调用任意一个里面的类时,如何先执行某段初始化代码?
VB.NET 写.NET可以指定运行SUB MAIN吗?调用任意一个里面的类时,如何先执行某段初始化代码? 分享 1. 在 VB.NET 中指定运行 Sub Main 在 VB.NET 里,你能够指定 Sub Main 作为程序的入口点。下面为你介绍两种实现方式: 方式一:在项目属性…...
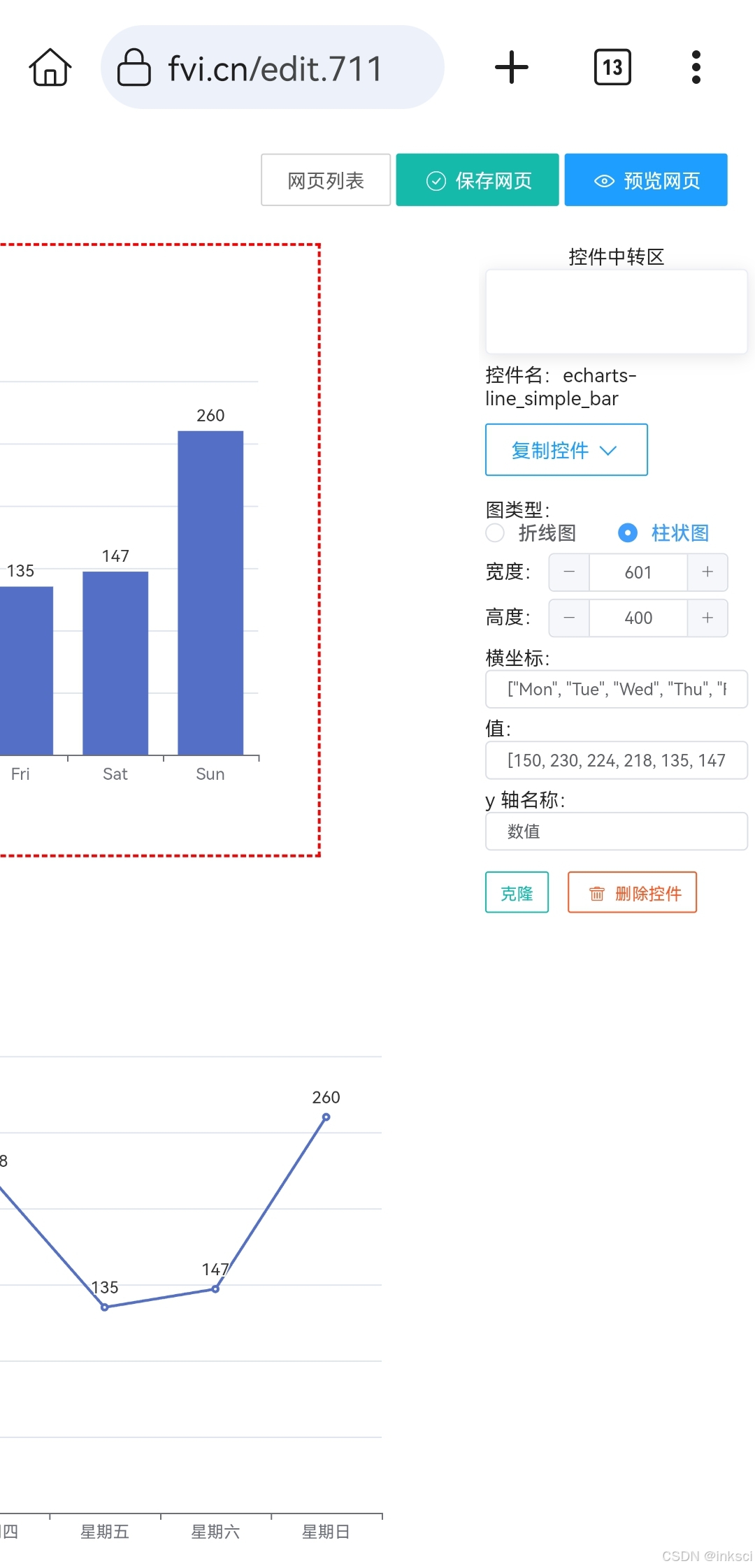
低代码开发平台:飞帆画 echarts 柱状图
https://fvi.cn/711 柱状图这个控件是由折线图的控件改过来的,在配置中,单选框选择柱状图就行了。...
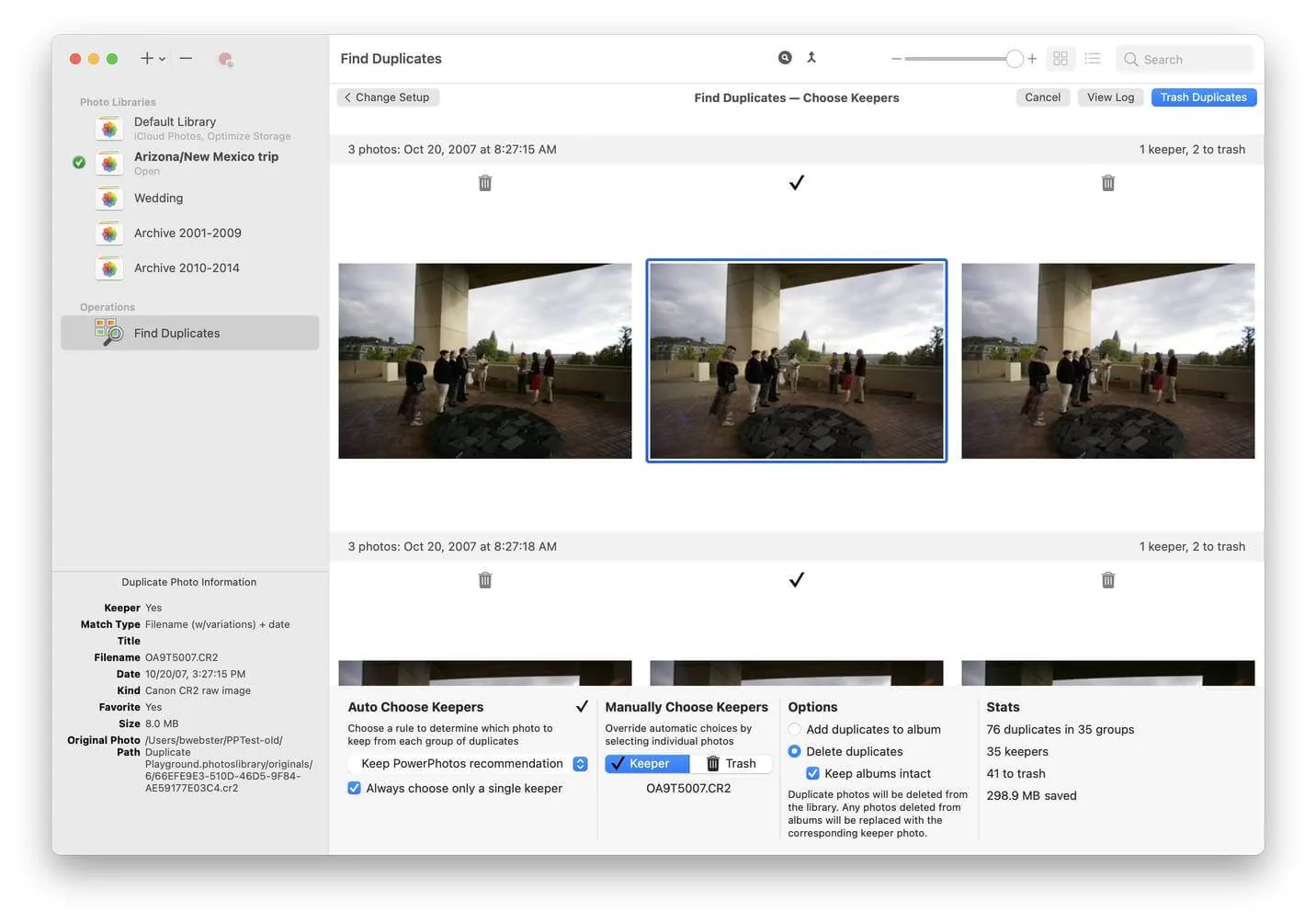
PowerPhotos:拯救你的Mac照片库,告别苹果原生应用的局限
如果你用Mac管理照片,大概率被苹果原生「照片」应用折磨过——无法真正并行操作多个图库。每次切换图库都要关闭重启,想合并照片得手动导出导入,重复文件更是无处可逃…… 直到我发现了 PowerPhotos,这款专为Mac设计的照片库管理…...

如何在Springboot的Mapper中轻松添加新的SQL语句呀?
在如今的软件开发界,Spring Boot可是非常受欢迎的框架哦,尤其是在微服务和RESTful API的构建上,真的是让人爱不释手!今天,我们就来聊聊如何为Spring Boot项目中的Mapper添加新的SQL语句吧!说起来࿰…...
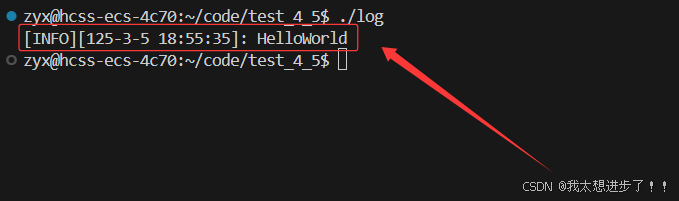
Linux 下 日志系统搭建全攻略
目录 一、引言 二、日志系统基础 日志级别 日志输出格式 三、创建日志所需函数 认识可变参数 编辑 获取时间的函数 小结 四、创建日志 一、引言 在 Linux 环境中开发 C/C 程序时,日志系统是不可或缺的一部分。它不仅有助于调试程序、排查问题ÿ…...
Linux系统安装Postgre和Postgis教程
卸载 如果之前没装过可以忽略这一步 卸载前记得备份数据库数据(如果还需要的话)!!! 一、删除 Docker 安装的 PostgreSQL/PostGIS 1. 停止并删除容器 # 查看所有容器 docker ps -a | grep postgres# 停止并删除容器(替换为实际…...

LXC 导入多Linux系统
前提要求 ubuntu下安装lxd 参考Rockylinux下安装lxd 参考LXC 源替换参考LXC 容器端口发布参考LXC webui 管理<...

6547网:蓝桥STEMA考试 Scratch 试卷(2025年3月)
『STEMA考试是蓝桥青少教育理念的一部分,旨在培养学生的知识广度和独立思考能力。考试内容主要考察学生的未来STEM素养、计算思维能力和创意编程实践能力。』 一、选择题 第一题 运行下列哪个程序后,飞机会向左移动? ( ) A. …...
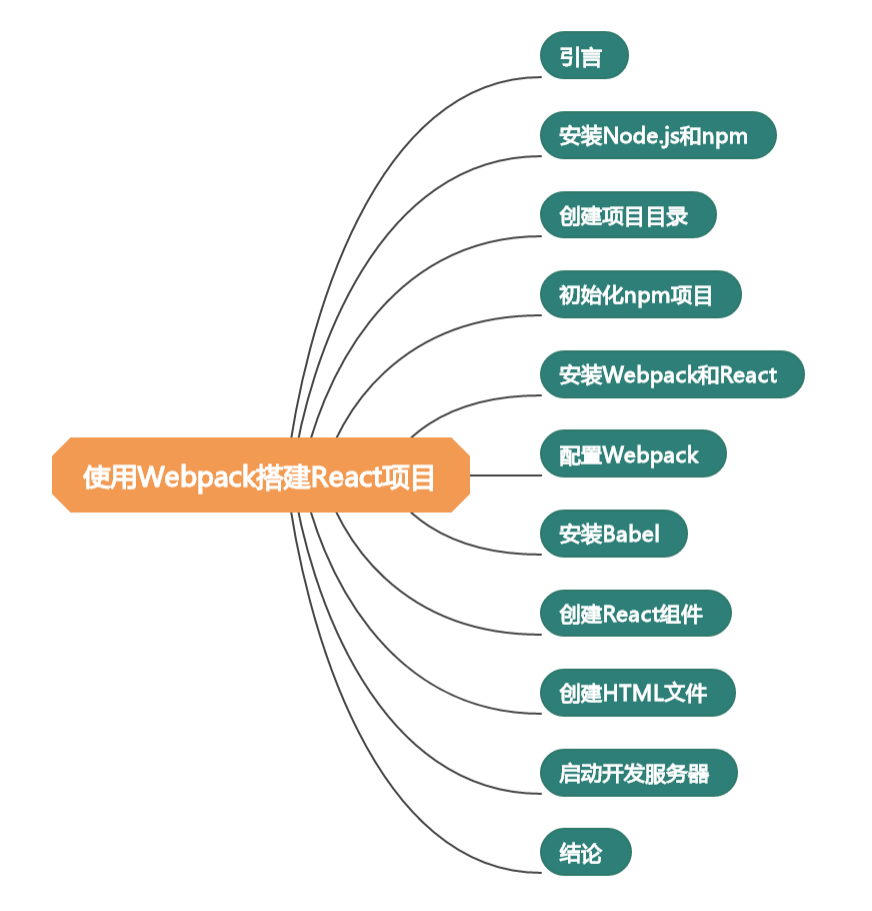
使用Webpack搭建React项目:从零开始
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...
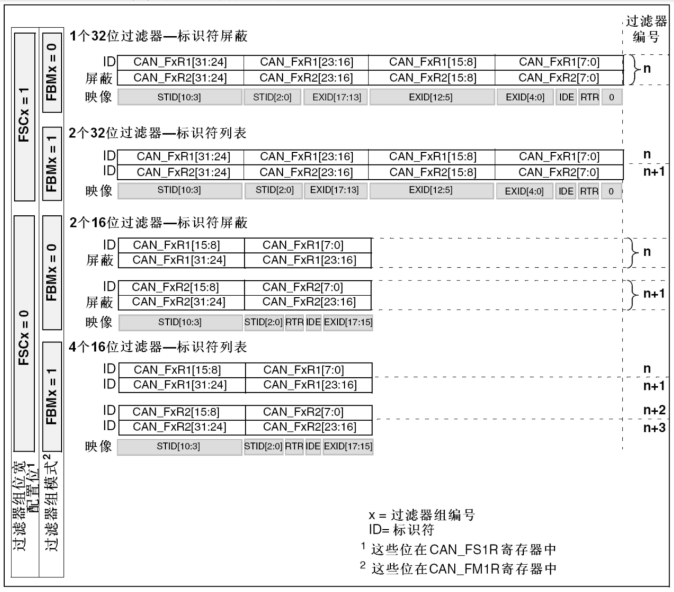
STM32提高篇: CAN通讯
STM32提高篇: CAN通讯 一.CAN通讯介绍1.物理层2.协议层二.STM32CAN外设1.CAN控制器的3种工作模式2.CAN控制器的3种测试模式3.功能框图三.CAN的寄存器介绍1.环回静默模式测试2.双击互发测试四.CAN的HAL代码解读一.CAN通讯介绍 CAN(Controller Area Network 控制器局域网,简称…...
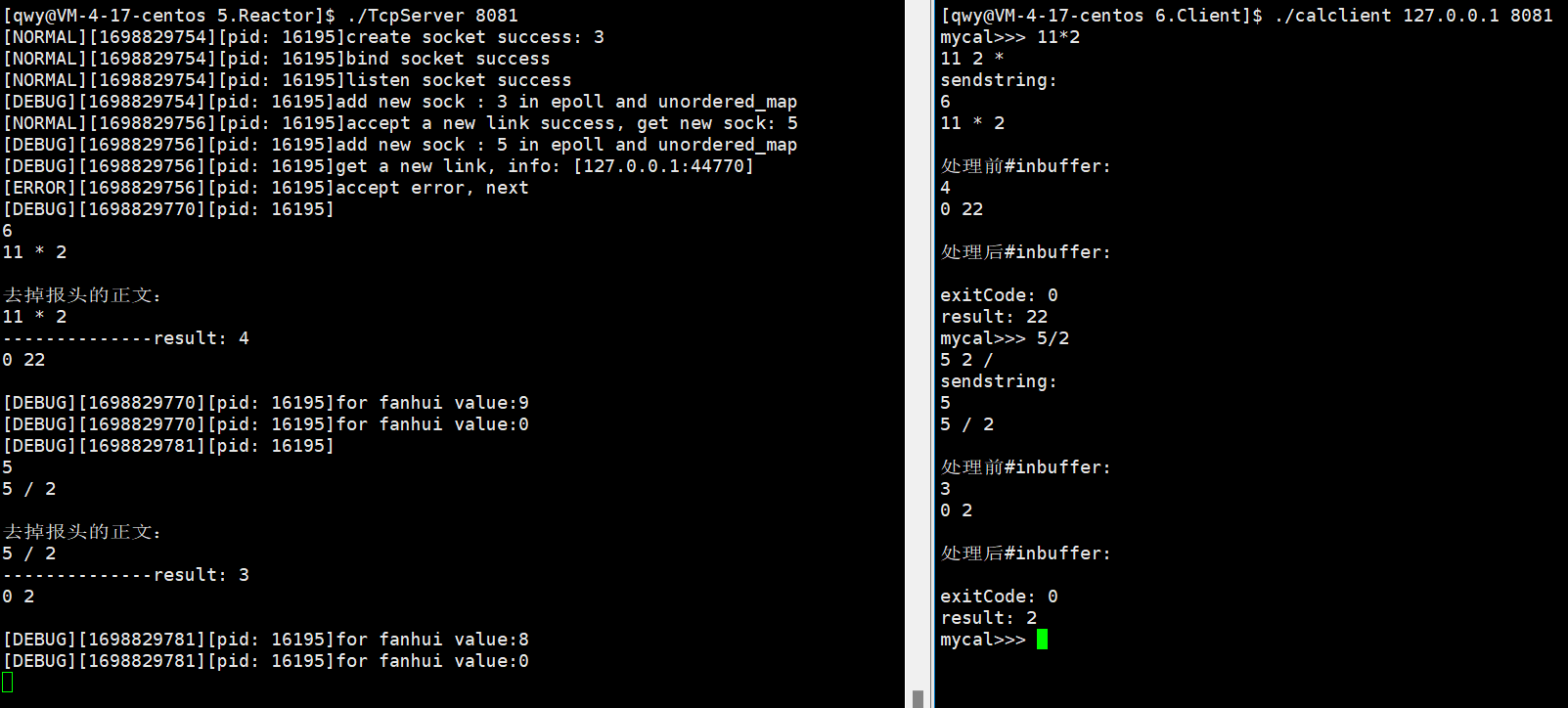
25.Reactor
预备知识 std::bind template <class Fn, class... Args>/* unspecified */ bind (Fn&& fn, Args&&... args);解释: std::bind(&TcpServer::Accepter, this, std::placeholders::_1) 这段代码使用了 C11 中的 std::bind 函数࿰…...
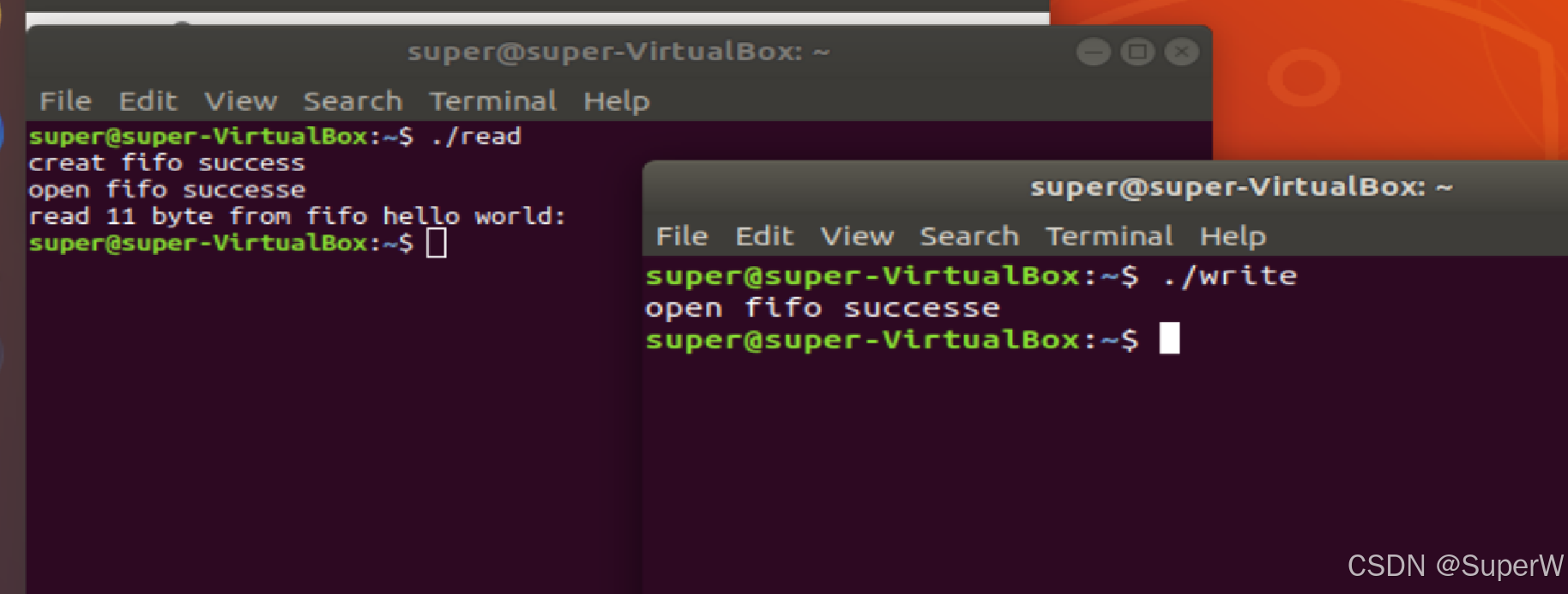
Linux进程间通信——有名管道
一.概念 函数形式:int mkfifo(const char \*filename,mode_t mode); 功能:创建管道文件 参数:管道文件文件名\路径,权限,创建的文件权限仍然和umask有关系。 返回值:创建成功返回0,创建失败返回…...

Axure RP9.0教程: 查询条件隐藏与显示(综合了动态面板状态切换及展开收缩效果实现)
文章目录 引言I 原型显示/隐藏搜索框思路步骤详细操作II 若依 ruoyi 显示/隐藏搜索框 & 显示隐藏列自定义设置显示隐藏列显示/隐藏搜索框引言 数据筛选有大量的查询条件时,可以选择查询隐藏效果。 I 原型显示/隐藏搜索框 综合了动态面板状态切换及展开收缩效果实现 思…...
与反铁电液晶(AFLC))
铁电液晶(FLC)与反铁电液晶(AFLC)
### **铁电液晶(FLC)与反铁电液晶(AFLC)的原理、区别及应用** --- ## **1. 基本原理** ### **(1)铁电液晶(Ferroelectric Liquid Crystal, FLC)** - **分子结构**: …...

【漫话机器学习系列】183.非参数方法(Non-parametric Methods)
非参数方法(Non-parametric Methods)详解 概述 非参数方法是一类在统计学和机器学习中广泛应用的技术,它的特点是不对特征值和目标值之间的关系做具体的假设。与传统的参数方法(如线性回归、逻辑回归等)不同…...
智能驾驶中预测模块简介
1.轨迹预测的定义 轨迹预测是自动驾驶系统“感知-预测-规控”流程中的核心环节,位于感知与规划模块之间,起到承上启下的作用。感知系统负责检测道路环境中的动态和静态元素,包括车辆、行人、自行车、交通标志、车道线等,而预测模…...
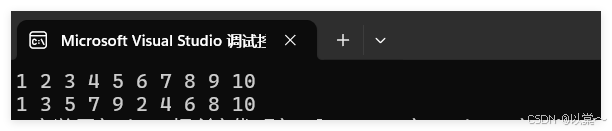
剑指offer经典题型(一)
本期我们将开始进行剑指offer中经典题型的学习。 数组相关 题目1:在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输…...
ctfshow VIP题目限免 版本控制泄露源码2
根据题目提示是版本控制泄露源码 版本控制(Version Control)是一种在软件开发和其他领域中广泛使用的技术,用于管理文件或项目的变更历史。 主流的版本控制工具: Git:目前最流行的分布式版本控制系统。SVN&am…...

蓝牙跳频扩频技术的作用:提升抗干扰能力与通信可靠性的核心机制
在无线通信技术领域,蓝牙(Bluetooth)以其短距离、低功耗和高兼容性成为连接电子设备的首选方案。其核心技术之一 ——跳频扩频(Frequency Hopping Spread Spectrum, FHSS),是蓝牙在2.4 GHz ISM频段复杂电磁…...

Kafka 如何保证消息可靠性?
Kafka 保证消息可靠性主要通过以下几个机制来实现,从生产者到消费者的整个链路上都设计了相应的保障措施: 1. 生产者(Producer)端的可靠性 ✅ a. acks 参数(确认机制) acks0:生产者不等待任何…...

ngx_ssl_init
定义在 src\event\ngx_event_openssl.c ngx_int_t ngx_ssl_init(ngx_log_t *log) { #if OPENSSL_VERSION_NUMBER > 0x10100003Lif (OPENSSL_init_ssl(OPENSSL_INIT_LOAD_CONFIG, NULL) 0) {ngx_ssl_error(NGX_LOG_ALERT, log, 0, "OPENSSL_init_ssl() failed")…...

docker swarm常用命令
1、初始化Swarm集群 用于初始化一个Swarm集群,并将当前节点设置为Manager节点。 用法:docker swarm init --advertise-addr <Manager节点IP> # docker swarm init --advertise-addr 192.168.1.100 这会将当前节点初始化为Swarm集群的管理节点&…...

硬盘加密安全
硬盘加密性能需求核心指标与优化策略 1. 核心性能指标 读写速度影响: 硬盘加密需平衡安全性与数据吞吐效率。以BitLocker为例,其对4K随机写入性能的影响最高可达45%2,但在现代CPU(支持AES-NI指令集)下…...

推荐系统(二十二):基于MaskNet和WideDeep的商品推荐CTR模型实现
在上一篇文章《推荐系统(二十一):基于MaskNet的商品推荐CTR模型实现》中,笔者基于 MaskNet 构建了一个简单的模型。笔者所经历的工业级实践证明,将 MaskNet 和 Wide&Deep 结合应用,可以取得不错的效果&…...