【Python爬虫高级技巧】BeautifulSoup高级教程:数据抓取、性能调优、反爬策略,全方位提升爬虫技能!
大家好,我是唐叔!上期我们聊了 BeautifulSoup的基础用法 ,今天带来进阶篇。我将分享爬虫老司机总结的BeautifulSoup高阶技巧,以及那些官方文档里不会告诉你的实战经验!
文章目录
- 一、BeautifulSoup性能优化技巧
- 1. 解析器选择玄机
- 2. 加速查找的秘诀
- 二、复杂HTML处理技巧
- 1. 处理动态属性
- 2. 嵌套数据提取
- 三、反爬对抗实战方案
- 1. 伪装浏览器头
- 2. 处理CloudFlare防护
- 3. 随机延迟策略
- 四、企业级实战案例:电商价格监控
- 需求分析
- 完整实现
- 五、BeautifulSoup的局限性
- 什么时候不该用BeautifulSoup?
- 替代方案对比
- 六、唐叔的爬虫心法
- 七、资源推荐
一、BeautifulSoup性能优化技巧
1. 解析器选择玄机
# 测试不同解析器速度(100KB HTML文档)
import timeit
html = open("page.html").read()print("html.parser:", timeit.timeit(lambda: BeautifulSoup(html, 'html.parser'), number=100))
print("lxml: ", timeit.timeit(lambda: BeautifulSoup(html, 'lxml'), number=100))
print("html5lib: ", timeit.timeit(lambda: BeautifulSoup(html, 'html5lib'), number=100))
实测结论:
- lxml比html.parser快约3-5倍
- html5lib比lxml慢约10倍
- 黄金法则:稳定性要求高用html5lib,速度优先用lxml
2. 加速查找的秘诀
# 低效写法(逐层查找)
soup.find('div').find('ul').find_all('li')# 高效写法(CSS选择器一次性定位)
soup.select('div > ul > li')
性能对比:
| 方法 | 10次查找耗时(ms) |
|---|---|
| 链式find | 45 |
| CSS选择器 | 12 |
二、复杂HTML处理技巧
1. 处理动态属性
# 查找包含data-开头的属性
soup.find_all(attrs={"data-": True})# 正则匹配属性值
import re
soup.find_all(attrs={"class": re.compile("btn-.*")})
2. 嵌套数据提取
目标:提取作者信息和出版日期
<div class="book"><span>作者:<em>唐叔</em></span><p>出版:2023-06</p>
</div>
代码:
# 传统写法
author = soup.find(class_="book").em.text
date = soup.find(class_="book").p.text.split(":")[1]# 更健壮的写法
book = soup.find(class_="book")
author = book.find(text=re.compile("作者:")).find_next("em").text
date = book.find(text=re.compile("出版:")).split(":")[1]
三、反爬对抗实战方案
1. 伪装浏览器头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'https://www.google.com/'
}
2. 处理CloudFlare防护
# 需要配合cloudscraper库
import cloudscraper
scraper = cloudscraper.create_scraper()
html = scraper.get("https://受保护网站.com").text
soup = BeautifulSoup(html, 'lxml')
3. 随机延迟策略
import random
import timedef random_delay():time.sleep(random.uniform(0.5, 3.0))
四、企业级实战案例:电商价格监控
需求分析
- 定时抓取某电商平台商品价格
- 处理JavaScript渲染内容
- 绕过反爬机制
- 异常监控和报警
完整实现
import requests
from bs4 import BeautifulSoup
import random
import time
from datetime import datetimedef monitor_price(url):try:# 1. 伪装请求headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)','Accept-Encoding': 'gzip'}proxies = {'http': 'http://10.10.1.10:3128','https': 'http://10.10.1.10:1080'}# 2. 随机延迟time.sleep(random.randint(1, 5))# 3. 获取页面response = requests.get(url, headers=headers, proxies=proxies, timeout=10)response.raise_for_status()# 4. 解析价格soup = BeautifulSoup(response.text, 'lxml')price = soup.find('span', class_='price').text.strip()name = soup.find('h1', id='product-name').text.strip()# 5. 数据存储log = f"{datetime.now()},{name},{price}\n"with open('price_log.csv', 'a') as f:f.write(log)return float(price.replace('¥', ''))except Exception as e:# 6. 异常处理send_alert_email(f"监控异常: {str(e)}")return Nonedef send_alert_email(message):# 实现邮件发送逻辑pass
关键技巧:
- 使用随机User-Agent轮换(可准备UA池)
- 代理IP池应对IP封锁
- 完善的异常处理机制
- 请求间隔随机化
五、BeautifulSoup的局限性
什么时候不该用BeautifulSoup?
- 页面完全由JavaScript渲染 → 考虑Selenium/Puppeteer
- 需要处理大量异步请求 → 直接分析API接口
- 超大规模数据抓取 → Scrapy框架更合适
替代方案对比
| 场景 | 推荐工具 | 优势 |
|---|---|---|
| 简单静态页 | BeautifulSoup | 轻量易用 |
| 复杂动态页 | Selenium | 能执行JS |
| API接口 | Requests | 直接高效 |
| 大型项目 | Scrapy | 完整框架 |
六、唐叔的爬虫心法
- 二八法则:80%的网站用BeautifulSoup+Requests就能搞定,不必过度设计
- 伦理边界:设置合理的爬取频率,尊重robots.txt
- 数据思维:先分析网站结构再写代码,事半功倍
- 持续进化:定期更新反爬策略,像维护产品一样维护爬虫
终极忠告:
“最厉害的爬虫工程师不是会绕过所有反爬,而是能让爬虫像真实用户一样优雅地获取数据”
七、资源推荐
- 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- CSS选择器备忘单:https://www.w3schools.com/cssref/css_selectors.asp
- 反爬对抗库:
- fake-useragent:UA伪装
- requests-html:JS渲染
- scrapy-splash:高级渲染
如果觉得有用,别忘了点赞关注!关于爬虫工程化的更多实践,我们下期再见!
唐叔说:“技术人要学会把经验转化为可复用的方法论,这才是真正的成长。希望这篇能帮你少走弯路!”
【爬虫】往期文章推荐:
- 【Python爬虫必看】requests库常用操作详解 ,附实战案例
- 【Python爬虫高级技巧】requests库高级用法 - 代理SSL流式一网打尽
- 【Python爬虫必看】Python爬虫必学BeautifulSoup:5分钟上手,小白也能高效抓取豆瓣网页数据!
更多内容可以关注《唐叔学Python》专栏。
相关文章:

【Python爬虫高级技巧】BeautifulSoup高级教程:数据抓取、性能调优、反爬策略,全方位提升爬虫技能!
大家好,我是唐叔!上期我们聊了 BeautifulSoup的基础用法 ,今天带来进阶篇。我将分享爬虫老司机总结的BeautifulSoup高阶技巧,以及那些官方文档里不会告诉你的实战经验! 文章目录 一、BeautifulSoup性能优化技巧1. 解析…...

复古未来主义屏幕辉光像素化显示器反乌托邦效果PS(PSD)设计模板样机 Analog Retro-Futuristic Monitor Effect
这款模拟复古未来主义显示器效果直接取材于 90 年代赛博朋克电影中的黑客巢穴,将粗糙的屏幕辉光和像素化的魅力强势回归。它精准地模仿了老式阴极射线管显示器,能将任何图像变成故障频出的监控画面或高风险的指挥中心用户界面。和……在一起 2 个完全可编…...
集成Redis的完整启用及配置详解,包含代码示例、注释说明和表格总结)
Spring Boot + MySQL + MyBatis(注解和XML配置两种方式)集成Redis的完整启用及配置详解,包含代码示例、注释说明和表格总结
以下是 Spring Boot MySQL MyBatis(注解和XML配置两种方式)集成Redis的完整启用及配置详解,包含代码示例、注释说明和表格总结: 1. 添加依赖 在pom.xml中添加Spring Boot对MySQL、MyBatis和Redis的支持依赖: <d…...

Webpack vs Vite:现代前端构建工具的巅峰对决与选型指南
构建工具的进化革命当雪碧瓶上的水珠折射出前端工程的变迁史,Webpack与Vite的决战已然成为现代前端开发的分水岭。这场始于打包理念的革命,正在重塑整个前端生态的底层逻辑。本文将从原理架构、性能表现、开发体验三个维度,结合真实项目数据对…...

2023-2024总结记录
概括经历 这一年算是一个人生节点,2023年花了一整年的时间在准备考研,基本上等于一个人奋战,我不怎么去图书馆,只呆在无人的实验室,还好有对象陪我,不然可能要抑郁了。作息上还是很随意,什么时…...

技术驱动革新,强力巨彩LED软模组助力创意显示
随着LED显示技术的不断突破,LED软模组因其独特的柔性特质和个性化显示效果,正逐渐成为各类应用场景的新宠。强力巨彩软模组R3.0H系列具备独特的可塑造型能力与技术创新,为商业展示、数字艺术、建筑装饰等领域开辟全新视觉表达空间。 LED…...

Spring 核心技术解析【纯干货版】- XVIII:Spring 网络模块 Spring-WebSocket 模块精讲
在现代 Web 开发中,实时通信已成为提升用户体验的关键技术之一。传统的 HTTP 轮询方式存在较高的延迟和带宽开销,而 WebSocket 作为一种全双工通信协议,能够在客户端和服务器之间建立持久连接,实现高效的双向数据传输。 Spring 框…...

Spark,HDFS概述
HDFS组成构架: 注: NameNode(nn):就是 Master,它是一个主管、管理者。 (1) 管理 HDFS 的名称空间; (2) 配置副本策略。记录某些文件应该保持几个副本; (3) 管理数据块(…...

【数据结构】图论进阶:生成树、生成森林与权值网络的终极解析
图的基本概念 导读一、图中的树与森林1.1 生成树与生成森林1.1.1 生成树1.1.2 生成森林1.1.3 生成树、生成森林与连通分量结点的关系边的关系 1.2 有向图中的树与森林1.2.1 有向树与有向森林1.2.2 生产有向树与生成有向森林1.2.3 有向树与生成有向树的区别1.2.4 有向森林与生成…...

C和C++(list)的链表初步
链表是构建其他复杂数据结构的基础,如栈、队列、图和哈希表等。通过对链表进行适当的扩展和修改,可以实现这些数据结构的功能。想学算法,数据结构,不会链表是万万不行的。这篇笔记是一名小白在学习时整理的。 C语言 链表部分 …...

深入浅出 TypeScript 泛型:类型安全的艺术与实践
文章目录 一、泛型的核心概念1.1 类型参数:代码中的类型变量1.2 类型推断:让代码保持简洁 二、泛型的四大应用场景2.1 泛型函数:打造通用工具库2.2 泛型接口:定义灵活的数据结构2.3 泛型类:构建类型安全的容器2.4 泛型…...

【KWDB创作者计划】_KaiwuDB 2.1.0 单节点裸机部署
大家好,这里是 DBA学习之路,专注于提升数据库运维效率。 目录 前言KWDB 介绍安装准备环境信息配置要求操作系统软件依赖端口要求安装包下载 部署 KWDB简单实用连接数据库创建数据库创建用户创建时序表 前言 今天无意间在墨天轮看到一个征文活动 征文大赛…...

洛谷题单3-P5720 【深基4.例4】一尺之棰-python-流程图重构
题目描述 《庄子》中说到,“一尺之棰,日取其半,万世不竭”。第一天有一根长度为 a a a 的木棍,从第二天开始,每天都要将这根木棍锯掉一半(每次除 2 2 2,向下取整)。第几天的时候木…...
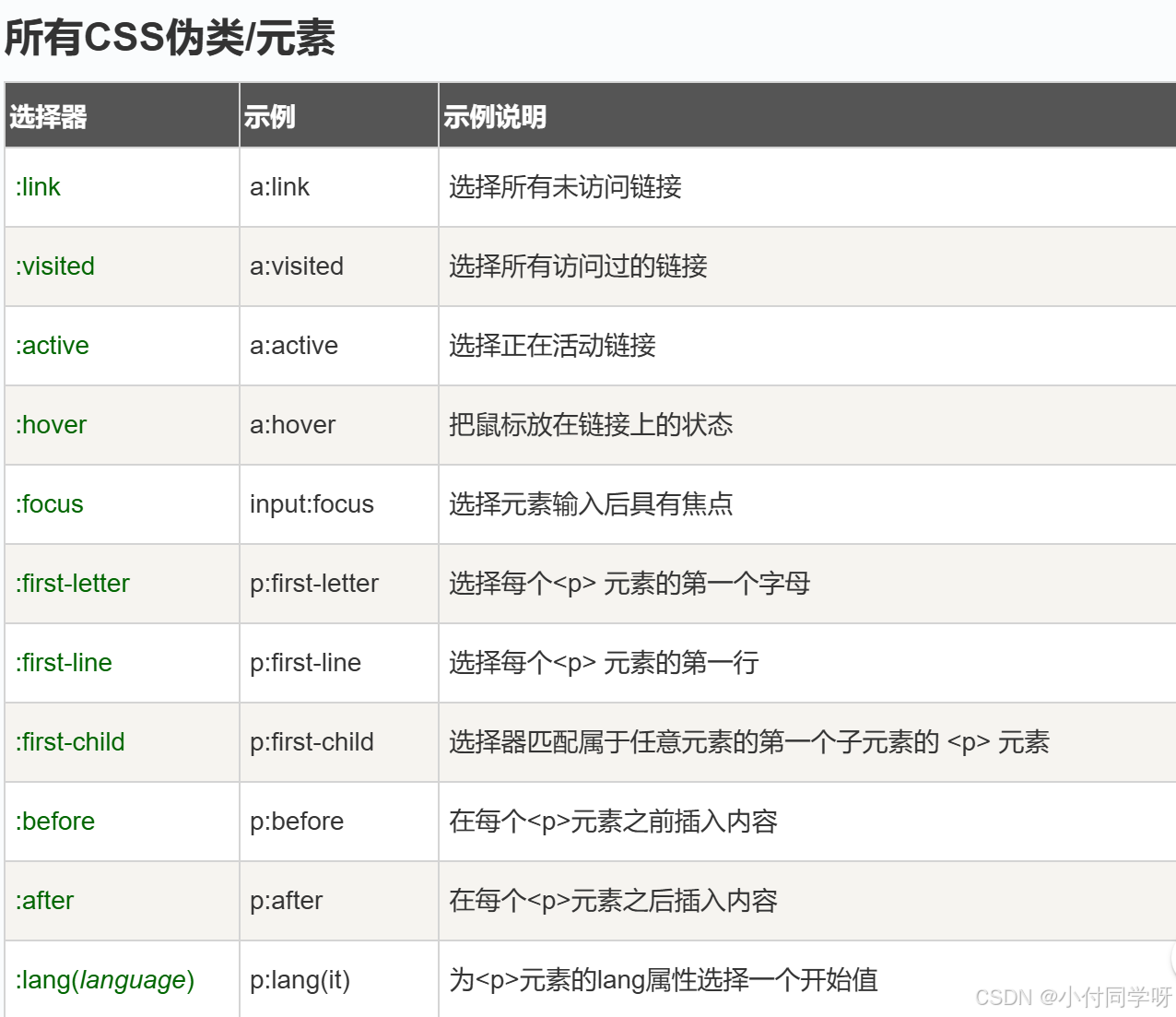
前端快速入门学习3——CSS介绍与选择器
1.概述 CSS全名是cascading style sheets,中文名层叠样式表。 用于定义网页样式和布局的样式表语言。 通过 CSS,你可以指定页面中各个元素的颜色、字体、大小、间距、边框、背景等样式,从而实现更精确的页面设计。 HTML与CSS的关系:HTML相当…...

Redash:一个开源的数据查询与可视化工具
Redash 是一款免费开源的数据可视化与协作工具,可以帮助用户快速连接数据源、编写查询、生成图表并构建交互式仪表盘。它简化了数据探索和共享的过程,尤其适合需要团队协作的数据分析场景。 数据源 Redash 支持各种 SQL、NoSQL、大数据和 API 数据源&am…...

嵌入式Linux驱动—— 1 GPIO配置
目录 1.GPIO操作 1.1 IO命名 1.2 GPIO 时钟使能(CCM) 1.3 IO 复用(IOMUXC) 1.4 IO 配置 1.5 GPIO 配置 1.GPIO操作 GPIO操作主要是以下流程: 使能某组GPIO模块(GPIO1、2、...)&#…...
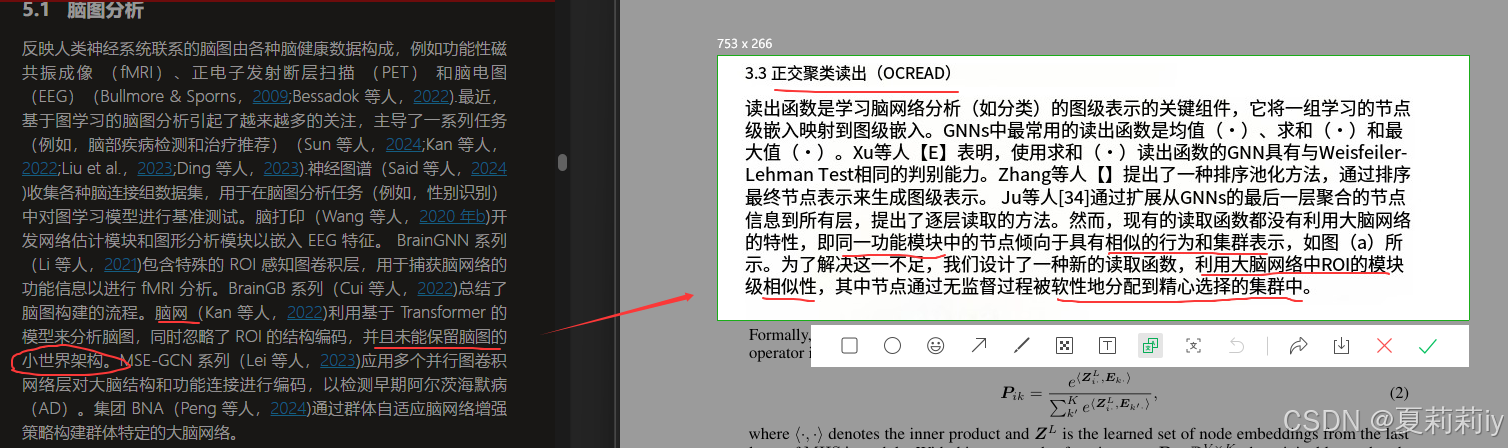
[ICLR 2025]Biologically Plausible Brain Graph Transformer
论文网址:Biologically Plausible Brain Graph Transformer 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 …...

SpringBoot+MyBatis Plus+PageHelper+vue+mysql 实现用户信息增删改查功能
静态资源展示 (1)静态资源下载 (2)下载后文件放到resources/static 目录下 (3) main函数启动项目访问对应文件,http://127.0.0.1:8080/user-list.html 数据库添加表和数据 SET FOREIGN_KEY_CHECKS0;-- --------…...

企业常用Linux服务搭建
1.需要两台centos 7服务器,一台部署DNS服务器,另一台部署ftp和Samba服务器。 2. 部署DNS 服务器 #!/bin/bash# 更新系统 echo "更新系统..." sudo yum update -y# 安装 BIND 和相关工具 echo "安装 BIND 和相关工具..." sudo y…...
Qwen-7B-Chat 本地化部署使用
通义千问 简介 通义千问是阿里云推出的超大规模语言模型,以下是其优缺点: 优点 强大的基础能力:具备语义理解与抽取、闲聊、上下文对话、生成与创作、知识与百科、代码、逻辑与推理、计算、角色扮演等多种能力。可以续写小说、编写邮件、解…...
QGIS获取建筑矢量图-Able Software R2V
1.QGIS截图 说明:加载天地图矢量图层,然后进行截图。 2.Able Software R2V 说明:Able Software R2V 是一款将光栅图像(如扫描图纸、航拍照片)自动转换为矢量图形(如DXF格式)的软件&a…...

CSS:换行与不换行
一、CSS 不允许换行 在 CSS 中,有几种方法可以控制文本不换行: 1. 使用 white-space 属性 .no-wrap {white-space: nowrap; } white-space: nowrap; 会强制文本在一行显示,不换行。 2. 使用 overflow 和 text-overflow 通常与 white-sp…...

【MiniMind】不能全局用 `pip install --upgrade pip`
Q:WARNING: Running pip as the ‘root’ user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.…...

form实现pdf文件转换成jpg文件
说明: 我希望将pdf文件转换成jpg文件 请去下载并安装 Ghostscript,gs10050w64.exe 配置环境变量:D:\Program Files\gs\gs10.05.0\bin 本地pdf路径:C:\Users\wangrusheng\Documents\name.pdf 输出文件目录:C:\Users\wan…...
STM32单片机入门学习——第13节: [6-1] TIM定时中断
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.04 STM32开发板学习——第13节: [6-1] TIM定时中断 前言开发板说明引用解答和科普一…...

量子纠错码实战:从Shor码到表面码
引言:量子纠错的必要性 量子比特的脆弱性导致其易受退相干和噪声影响,单量子门错误率通常在10⁻~10⁻量级。量子纠错码(QEC)通过冗余编码测量校正的机制,将逻辑量子比特的错误率降低到可容忍水平。本文从首个量子纠错…...
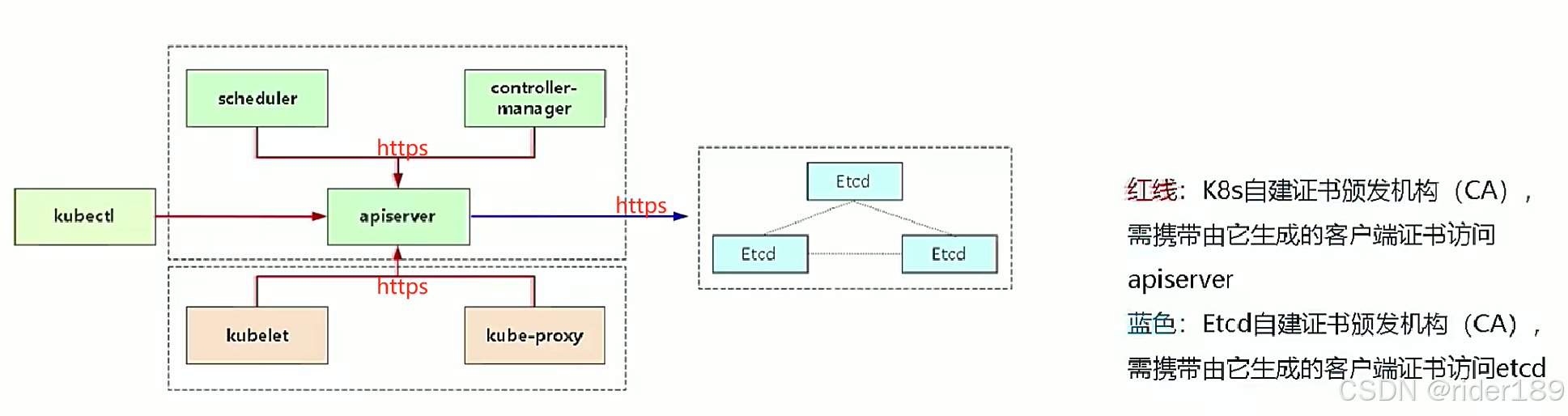
【2】搭建k8s集群系列(二进制)之安装etcd数据库集群
一、etcd服务架构 Etcd 是一个分布式键值存储系统,Kubernetes 使用 Etcd 进行数据存储,所以先 准备一个 Etcd 数据库,为解决 Etcd 单点故障,应采用集群方式部署,这里使用 3 台组建集群,可容忍 1 台机器故障…...
Linux常用命令详解:从基础到进阶
目录 一、引言 二、文件处理相关命令 (一)grep指令 (二)zip/unzip指令 编辑 (三)tar指令 (四)find指令 三、系统管理相关命令 (一)shutdown指…...

【Docker】使用Docker快速部署n8n和unclecode/crawl4ai
Docker部署自动化工具n8n和crawl4ai详细教程 前言 本文将详细介绍如何使用 Docker 来部署和运行自动化工作流工具 n8n 以及 crawl4ai。这两个工具对于需要进行自动化工作流程的开发者来说都非常有用。 一、环境准备 在开始之前,请确保您的系统已经安装了&#x…...

数据库权限获取
1. into outfile(手写) 1.1. 利用条件 • web 目录具有写入权限,能够使用单引号 • 知道网站绝对路径(根目录,或则是根目录往下的目录都行) • secure_file_priv 没有具体值(在 mysql/my.ini 中查看) 1.2. secure_file_priv 介绍 secure_file_priv 是用来限制 loa…...