从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。
GraphRag的创新
RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。传统的Rag方法在大部分情况下效果都很好,但在处理复杂任务时却面临一些挑战,如多跳推理(multi-hop reasoning)或联系不同信息片段全面回答问题。不适用于摘要、总结性的问题。
GraphRAG将知识图谱技术应用到RAG,利用大模型,同时在知识图谱的基础上使用图社区摘要解决总结性查询任务的问题。
一、数据加载
支持csv和txt的格式。

二、分割文档
分割参数包括分割的每一块的token数、块之间的重叠数。使用 tiktoken 库来对文本进行编码和解码,并基于token进行分割。
使用Tokenizer对输入文本进行编码,得到一个令牌ID列表。根据设定的每个块的最大令牌数(tokensperchunk)和块之间的重叠令牌数(chunkoverlap)来迭代分割文本。在每次迭代中,它会取出一定数量的令牌ID,使用Tokenizer的解码方法将其转换回字符串,形成一个文本块。然后更新起始索引,跳过重叠的令牌,继续分割剩余的文本,直到所有文本都被处理。

补充:
其他的分词方法
tiktoken 是一个用于 OpenAI 模型的快速 BPE(字节对编码)标记器。
BPE 是一种简单的数据压缩算法,它通过迭代地合并最频繁出现的字节对来构建词汇表。
WordPiece:由 Google 开发,用于处理未知词汇和稀有词汇。
在训练数据上统计单词、子词和其他字符序列的出现频率。选择能够最大化训练数据似然的字符序列,将其添加到词汇表中。
SentencePiece:是一个无监督的文本编码器,可以用于子词分词和语言建模。
其他的chunk计算方法

三、形成嵌入向量
1.分割后的文本片段被发送到LLM以生成嵌入向量
2.LLM如何生成嵌入向量
大模型形成的特征作为嵌入向量。
3.生成的向量如何存储
VectorStoreDocument对象,该对象包含文本的ID、文本内容、嵌入向量以及其他属性(如标题)。嵌入之后的向量存储:文本嵌入向量的存储方式取决于是否配置了向量存储(vector store)以及具体的存储配置。如果在策略配置中提供了vector_store部分,那么文本嵌入向量将被存储在向量存储中。如果没有提供vector_store配置,那么嵌入向量将直接存储在内存中的DataFrame里。
azure_ai_search, lancedb
4.有哪些嵌入的大模型,如何选择
bge and nomic embed text
BGE通常是指使用BERT或其变体来生成文本嵌入的方法,适用于文本相似性分析、文档分类、情感分析等。
nomic embed text:支持多种任务,包括分类、检索、聚类、重排序和语义文本相似度(STS)计算。
四、调用大模型生成实体、关系和摘要等
最终生成实体-摘要-社区-社区摘要。
实体和关系
1.在什么数据的基础上生成实体和关系
输入数据是文本,具体来说,是一个包含多个文档的列表,每个文档是一个字典,其中包含文档的ID和文本内容。
2.如何生成实体和关系
定义一个默认的实体类型列表DEFAULT_ENTITY_TYPES,包括组织、人物、地理位置和事件。
实体格式:("entity"<>实体标识<>实体类型<>实体描述)
关系格式:("relationship"<>实体1标识<>实体2标识<>关系描述<>关系强度)
可以选择两种方式来生成实体:
graph_intelligence:使用图智能库提取实体。调用大模型。
![]()
run_extract_entities--GraphExtractor

通过prompt来指导大模型生成实体。

不用大模型可以选择nltk:使用NLTK库提取实体和关系。没有使用大模型。
![]()
3.如何存储生成的结果
提取后的实体保存在一个列表中,每个实体是一个字典,包含实体的名称和其他属性。
如何处理实体歧义和关系重叠问题。
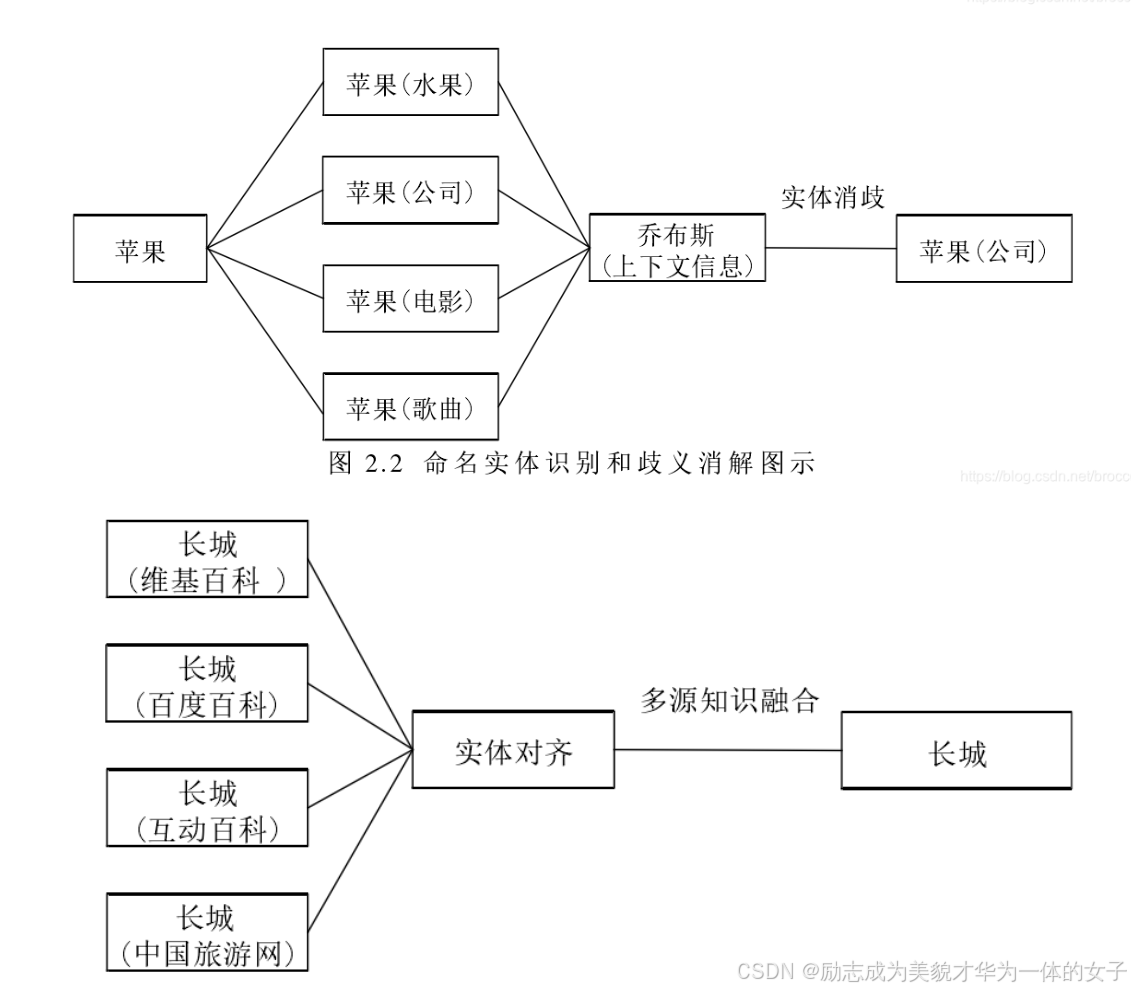
在GraphRag的实体生成过程中实体只有去除相同名称以及循环避免遗漏的处理,没有提醒大模型进行实体消歧和对齐,可以优化prompt。
实体描述
1.输入数据格式和内容
输入数据是一个 DataFrame,其中包含图的字符串表示。

2.如何生成摘要
使用语言模型(LLM)来提取和总结实体图中的实体描述。

3.保存的数据格式
提取后的实体内容保存在SummarizedDescriptionResult对象中,该对象包含两个属性:items和description。
它是一个简单的数据结构,用于封装提取结果。

图社区
社区检测_和_知识图谱嵌入

使用社区检测算法将图划分为模块化社区。
1.在什么数据的基础上生成图社区
在实体数据上
2.生成图社区的过程
社区检测:生成实体社区的层次结构。
networkx库用于图处理,以及 graspologic.partition.hierarchical_leiden 用于社区检测。
社区检测(Community Detection)是一种常用的技术,用于发现图中的紧密相连的节点集合,这些节点集合在内部有较多的连接,而与集合外部的节点连接较少。
首先,需要有一个图(Graph),它由节点(Nodes)和边(Edges)组成。在代码中,这通常是通过 networkx 库来表示的。
import networkx as nx# 创建一个图
G = nx.Graph()# 添加节点和边
G.add_nodes_from([1, 2, 3, 4, 5])
G.add_edges_from([(1, 2), (2, 3), (3, 4), (4, 5), (5, 1)])定义聚类方法,处理聚类结果,聚类算法执行后,会返回一个包含社区信息的字典。这个字典通常以社区级别为键,以包含社区 ID 和节点列表的字典为值。
优化模块度(一个衡量社区质量的指标)来快速识别社区。


节点的度:对于无向图,一个节点的度是指与该节点相连的边的数量。在无向图中,每条边连接两个节点,因此每条边会为两个节点各增加一度。
知识图谱嵌入
使用 Node2Vec 算法生成知识图谱的向量表示。这将使我们能够理解我们的知识图谱的隐含结构,并提供一个额外的向量空间,用于在查询阶段搜索相关概念。
将图数据嵌入到向量空间中,使用 node2vec 算法生成节点的嵌入向量,并返回一个有序的字典,其中包含节点的标识符和它们的嵌入向量。
为什么要把图节点生成嵌入向量:

node2vec是一种随机游走的算法,
node2vec使用了一种灵活的随机游走策略,它结合了两种游走策略:深度优先搜索(DFS)和广度优先搜索(BFS)。这种策略允许算法在探索节点邻域时平衡局部和全局的结构信息。一旦生成了随机游走序列,node2vec使用Skip-Gram模型来学习节点的嵌入。Skip-Gram的目标是给定一个节点(中心节点),预测它的上下文节点。通过优化目标函数(例如,最大化上下文节点的对数概率),使用梯度下降等优化算法更新节点的嵌入向量。
一旦我们完成了知识图谱增强步骤,我们会对 实体 和 关系 表进行发射,之后再进行文本域的文本嵌入。
3.输出结果
社区信息,包括社区级别、社区ID和属于该社区的节点列表。
社区摘要
自下而上地生成每个社区层级及其组成部分的摘要。如果社区 A 是最高层级的社区,我们将获得有关整个知识图谱的报告。如果社区是较低级别的,则我们将获得有关局部集群的报告。
生成社区报告
使用 LLM 生成每个社区的摘要。这将使我们能够了解每个社区中包含的不同信息,并从高层次或低层次的角度提供对知识图谱的范围性理解。这些报告包含管理概述,并引用社区子结构中的关键实体、关系。
总结社区报告
在这一步中,每个_社区报告_会经过 LLM 进行摘要,供简要使用。
社区嵌入
通过生成社区报告、社区报告摘要和社区报告标题的文本嵌入,生成我们社区的向量表示。
五、检索
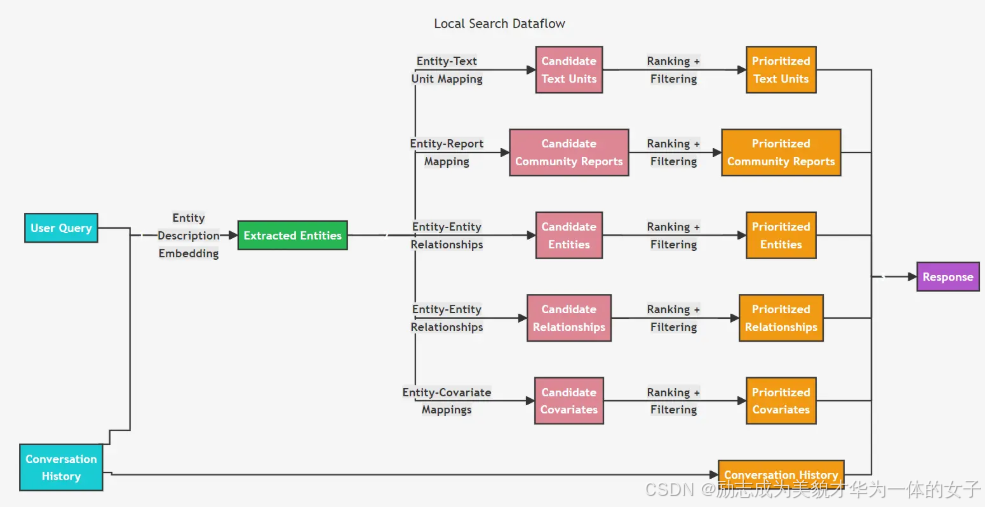
局部检索
适用于需要理解文档中提到的特定实体的问题。
1.将query在存储实体信息的向量库中检索出相关实体。
代码路径:graphrag\query\context_builder\entity_extraction.py
提供了三种查询相关性实体的方法:
map_query_to_entities(默认用的是这个)
通过文本嵌入向量来查找与查询最相关的实体,查询文本嵌入向量(在文本分块后数据库中实际存储的向量)与查询向量的相关性,然后返回对应文本向量的实体。
graphrag\vector_stores\lancedb.py similarity_search_by_text。
其他实现实体检索的方法:
find_nearest_neighbors_by_entity_rank:通过实体的直接关系和排名来查找最相关的实体。
找出与目标实体直接相连的关系。
确定与目标实体有关系的实体名称,并排除掉排除列表中的实体。
从所有实体中检索这些相关实体的列表,并根据实体的排名进行排序。
返回前 k 个实体。
find_nearest_neighbors_by_graph_embeddings
通过图嵌入(graph embeddings)查找与给定实体最相似的实体。
2.将第一步实体相关的chunk信息、社区摘要、实体详情、实体关系、实体Covarites按一定的格式组织作为上下文。对这些候选数据源进行优先排序和过滤, 以适应预定义大小的单一上下文窗口, 用于生成对用户查询的响应。
怎么优先排序?
chunk信息:关系数量:文本单元与实体的关系数量是排序的一个重要因素,这表明代码旨在优先考虑与更多关系相关的文本单元。实体顺序:实体在列表中的顺序也是一个排序因素,这可能意味着先出现的实体可能更重要或更相关。上下文限制:通过max_tokens参数限制了上下文文本的长度,确保不会超出令牌限制。
社区摘要:

关系和协变量上下文:在build_relationship_context和build_covariates_context函数中,关系和协变量可能根据它们与实体的关联强度或其他属性(如权重或排名)进行排序。
3.如果有历史聊天记录想历史聊天记录也作为上下文的一部分。
graphrag\query\context_builder\conversation_history.py在对话系统中存储、管理和格式化对话历史。
4.让LLM根据上下文生成回答(prompt路径为graphrag/query/structured_search/local_search/system_prompt.py)。
如何高效地存储和查询嵌入向量,特别是在大规模知识图谱中。
向量存储的索引策略和数据结构。
全局检索
以 map-reduce 方式搜索所有 AI 生成的社区报告来生成答案。这是一种资源密集型方法,但通常对于需要整体理解数据集的问题能给出很好的响应。因为基准的 RAG 依赖于对数据集中语义相似文本内容的向量搜索。查询中没有任何指示它找到正确信息的内容。LLM 生成的知识图的结构告诉我们整个数据集的结构(因此也是主题)。这使得私有数据集可以被组织成有意义的语义聚类,并进行预摘要。

1.将所有社区摘要shuffle并分块作为上下文,另将历史对话构成的上下文与这些社区摘要块拼接在一起作为上下文。
2.用map机制将前一步的多个上下文让LLM评估它们对于回答用户问题是否有帮助并进行0-100的打分。过滤掉分数为0的上下文。
prompt:graphrag\query\structured_search\global_search\map_system_prompt.py
3.将前一步得到的结果合并且按照分数大小进行降序排序,并将这些信息加入到LLM上下文窗口,让LLM生成最终的回答。
全局搜索的响应质量很大程度上取决于所选的用于获取社区报告的社区层次结构级别。较低层次的层次结构带有其详细报告,往往会产生更详尽的响应,但可能也会增加生成最终响应所需的时间和 LLM 资源,因为需要处理更多的报告。
Global查询的步骤如下(如下图所示)(prompt在graphrag/query/structured_search/global_search/map_system_prompt.py 和 graphrag/query/structured_search/global_search/reduce_system_prompt.py:
写的比较好的笔记:
基于社区发现的GraphRAG思路_graphrag 社区-CSDN博客
相关文章:
从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。 …...

通俗地讲述DDD的设计
通俗地讲述DDD的设计 前言为什么要使用DDDDDD架构分层重构实践关键问题解决方案通过领域事件机制解耦服务依赖:防止逻辑下沉 领域划分电商场景下的领域划分 结语完结撒花,如有需要收藏的看官,顺便也用发财的小手点点赞哈,…...
【Redis】通用命令
使用者通过redis-cli客户端和redis服务器交互,涉及到很多的redis命令,redis的命令非常多,我们需要多练习常用的命令,以及学会使用redis的文档。 一、get和set命令(最核心的命令) Redis中最核心的两个命令&…...

网络安全技术文档
网络安全技术文档 1. 概述 网络安全是指通过技术手段和管理措施,保护网络系统的硬件、软件及其数据不受偶然或恶意破坏、更改、泄露,确保系统连续可靠运行,网络服务不中断。 2. 常见网络威胁 2.1 攻击类型 DDoS攻击:分布式拒…...
微前端随笔
✨ single-spa: js-entry 通过es-module 或 umd 动态插入 js 脚本 ,在主应用中发送请求,来获取子应用的包, 该子应用的包 singleSpa.registerApplication({name: app1,app: () > import(http://localhost:8080/app1.js),active…...

【36期获取股票数据API接口】如何用Python、Java等五种主流语言实例演示获取股票行情api接口之沪深A股当天逐笔大单交易数据及接口API说明文档
在量化分析领域,实时且准确的数据接口是成功的基石。经过多次实际测试,我将已确认可用的数据接口分享给正在从事量化分析的朋友们,希望能够对你们的研究和工作有所帮助,接下来我会用Python、JavaScript(Node.js&…...
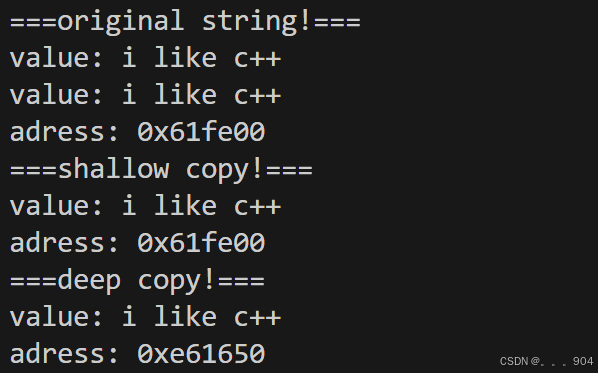
C++中的浅拷贝和深拷贝
浅拷贝只是将变量的值赋予给另外一个变量,在遇到指针类型时,浅拷贝只会把当前指针的值,也就是该指针指向的地址赋予给另外一个指针,二者指向相同的地址; 深拷贝在遇到指针类型时,会先将当前指针指向地址包…...

二叉树与红黑树核心知识点及面试重点
二叉树与红黑树核心知识点及面试重点 一、二叉树 (Binary Tree) 1. 基础概念 定义:每个节点最多有两个子节点(左子节点和右子节点) 术语: 根节点:最顶层的节点 叶子节点:没有子节点的节点 深度…...
)
GitHub 趋势日报 (2025年04月01日)
GitHub 趋势日报 (2025年04月01日) 本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星语言1punkpeye/awesome-mcp-serversA collection of MCP servers.⭐ 3280未指定2th-ch/youtube-musicYouTu…...

Java的SeleniumChromeDriver的常用方法
启动和关闭浏览器: driver.get(url):打开指定的URL。driver.quit():关闭浏览器并结束ChromeDriver会话。 元素定位: driver.findElement(By.id("elementId")):通过元素的ID定位。driver.findElement(By.cl…...

字符串、列表、元组、字典
字符串 双引号或者单引号中的数据,就是字符串 字符串输入 之前在学习input的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中; 注意:input获取的数据,都以字符串的方式进行保存,即…...

【GEE学习笔记】报错解决:“Image.select: Band pattern ‘QA60‘ did not match any bands”
【GEE学习笔记】报错解决:“Image.select: Band pattern ‘QA60’ did not match any bands” 【GEE学习笔记】报错解决:“Image.select: Band pattern ‘QA60’ did not match any bands” 文章目录 【GEE学习笔记】报错解决:“Image.selec…...

AI可以赋能的三农产品、机械与服务
三农赛道涵盖农业、农村和农民相关的产品与服务,涉及农资、农业机械、智能设备、农产品加工及数字化服务等多个领域。随着人工智能(AI)技术的飞速发展,AI正在通过赋能农业的生产、管理、销售等各个环节,推动传统农业向…...

ngx_timezone_update
定义在 src\os\unix\ngx_time.c void ngx_timezone_update(void) { #if (NGX_FREEBSD)if (getenv("TZ")) {return;}putenv("TZUTC");tzset();unsetenv("TZ");tzset();#elif (NGX_LINUX)time_t s;struct tm *t;char buf[4];s tim…...

车载诊断架构 --- 整车重启先后顺序带来的思考
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

GESP C++三级 知识点讲解
C编程三级标准 (一)知识点详述 (1)了解二进制数据编码:原码、反码、补码。 (2)掌握数据的进制转换:二进制、八进制、十进制、十六进制。 (3)掌握位运算:与(&)、或(|)、非(~)、异或(^)、左移(<<)、右移(>>)的基本使用方法及原理。 (4)了解算法的概念与描述&…...

前端 vs 后端:技术分工详解——从用户界面到系统逻辑的全解析
前端(Frontend) 和 后端(Backend) 是软件开发中两个核心概念,分别对应用户直接交互的部分和系统背后的逻辑处理部分。它们共同构成完整的应用程序,但分工不同。 目录 一、前端(Frontend…...

Redis 除了数据类型外的核心功能 的详细说明,包含事务、流水线、发布/订阅、Lua 脚本的完整代码示例和表格总结
以下是 Redis 除了数据类型外的核心功能 的详细说明,包含事务、流水线、发布/订阅、Lua 脚本的完整代码示例和表格总结: 1. Redis 事务(Transactions) 功能描述 事务通过 MULTI 和 EXEC 命令将一组命令打包执行,保证…...

JavaScript智能对话机器人——企业知识库自动化
引言 内部知识管理常面临信息分散、查找困难的问题。本文将使用Node.js和虎跃办公的智能对话API,构建企业级知识问答机器人,支持自然语言查询和自动学习。 核心技术 自然语言处理(NLP)意图识别机器学习模型微调REST API集成 代…...

JS实现AES和DES
目录 目标 概述 DES AES 实战 JS实现DES JS实现AES 目标 了解AES和DES的特点并用JS实现。 概述 DES 翻译过来叫数据加密标准。它有5种加密模式(CTR、OFB、CFB、CBC、ECB),在JS中,不同加密模式语法结构几乎一致,…...

【C++11(下)】—— 我与C++的不解之缘(三十二)
前言 随着 C11 的引入,现代 C 语言在语法层面上变得更加灵活、简洁。其中最受欢迎的新特性之一就是 lambda 表达式(Lambda Expression),它让我们可以在函数内部直接定义匿名函数。配合 std::function 包装器 使用,可以…...
Windows 10/11系统优化工具
家庭或工作电脑使用时间久了,会出现各种各样问题,今天给大家推荐一款专为Windows 10/11系统设计的全能优化工具,该软件集成了超过40项专业级实用程序,可针对系统性能进行深度优化、精准调校、全面清理、加速响应及故障修复。通过系…...

浅谈在HTTP中GET与POST的区别
从 HTTP 报文来看: GET请求方式将请求信息放在 URL 后面,请求信息和 URL 之间以 ?隔开,请求信息的格式为键值对,这种请求方式将请求信息直接暴露在 URL 中,安全性比较低。另外从报文结构上来看,…...

LightRAG实战:轻松构建知识图谱,破解传统RAG多跳推理难题
作者:后端小肥肠 🍊 有疑问可私信或评论区联系我。 🥑 创作不易未经允许严禁转载。 姊妹篇: 2025防失业预警:不会用DeepSeek-RAG建知识库的人正在被淘汰_deepseek-embedding-CSDN博客 从PDF到精准答案:Coze…...

C++多线程编码二
1.lock和try_lock lock是一个函数模板,可以支持多个锁对象同时锁定同一个,如果其中一个锁对象没有锁住,lock函数会把已经锁定的对象解锁并进入阻塞,直到多个锁锁定一个对象。 try_lock也是一个函数模板,尝试对多个锁…...
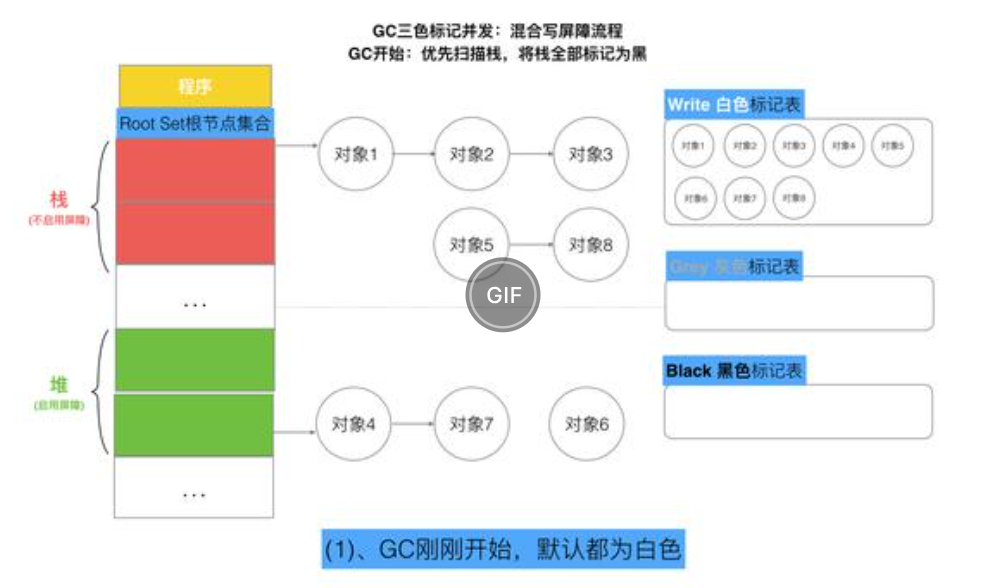
垃圾回收——三色标记法(golang使用)
三色标记法(tricolor mark-and-sweep algorithm)是传统 Mark-Sweep 的一个改进,它是一个并发的 GC 算法,在Golang中被用作垃圾回收的算法,但是也会有一个缺陷,可能程序中的垃圾产生的速度会大于垃圾收集的速度,这样会导…...

Linux学习笔记——零基础详解:什么是Bootloader?U-Boot启动流程全解析!
零基础详解:什么是Bootloader?U-Boot启动流程全解析! 一、什么是Bootloader?📌 举个例子: 二、U-Boot 是什么?三、U-Boot启动过程:分为两个阶段🔹 第一阶段(汇…...

Windows环境下开发pyspark程序
Windows环境下开发pyspark程序 一、环境准备 1.1. Anaconda/Miniconda(Python环境) 如果不怕包的版本管理混乱,可以直接使用已有的Python环境。 需要安装anaconda/miniconda(python3.8版本以上):Anaconda…...
)
thinkphp8.0上传图片到阿里云对象存储(oss)
1、开通oss,并获取accessKeyId、accessKeySecret <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><tit…...
SSM婚纱摄影网的设计
🍅点赞收藏关注 → 添加文档最下方联系方式咨询本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 SS…...