消息队列基础概念及选型,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息
前言
是时候总结下消息队列相关知识点啦!我搓搓搓搓
本文包括消息队列基础概念介绍,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息
参考资料:
Kafka常见问题总结 | JavaGuide
RocketMQ常见问题总结 | JavaGuide
【原创】消息队列的消费语义和投递语义 - 孤独烟 - 博客园
Kafka事务是怎么实现的?Kafka事务消息原理详解(文末送书)-CSDN博客
Kafka/RocketMQ事务消息对比 - 简书
1. 什么是消息队列
消息队列可以看作是存放消息的容器,常用于分布式系统中,在消息的生产者和消费者之间引入一个缓冲区
它的作用主要由三点概括,分别是
- 解耦:生产者和消费者之间没有直接的调用关系,新增或者修改模块对其它模块的影响较小
- 异步:生产者无需等待消息消费完成就即刻返回,减少用户请求的响应时间
- 削峰:在高并发场景,消息队列可以缓存消息,平滑高峰流量,防止系统过载
2. 消息队列有什么常见应用场景
日志处理:将日志发送到消息队列,由日志处理系统进行消费,进行实时分析和监控
电商系统:订单的创建、支付、发货等步骤可以由消息队列进行异步处理和解耦
任务调度:任务调度系统可以将任务发布在消息队列中,由多个不同的节点并行处理
数据同步:消息队列可以将变更的数据同步到不同的存储系统中
3. 常见的消息队列如何选型
常见的消息队列有几种:RabbitMQ、Kafka、RocketMQ
从延时来看,RabbitMQ是基于Erlang开发的,延时最低,能达到微秒级别,其它都是毫秒级别
从吞吐量来看,Kafka和RocketMQ吞吐量最高,达十万、百万级,RabbitMQ只有万级
从定制开发难度来看,RocketMQ是由Java开发的,对于大型公司可以有人手进行定制化开发,而能对RabbitMQ进行定制化开发的较少,但是RabbitMQ社区活跃,能够解决开发上的bug
从业务场景来看,RocketMQ基本上经受住了大型企业场景的考验比如双十一,Kafka适用于大数据场景实时分析和日志采集等业务
总结,如果是数据量没有那么大,可以选择功能完备、社区活跃的RabbitMQ,如果有大数据量的金融互联网场景,对可靠性和吞吐量要求都很高,推荐选择RocketMQ,如果是日志采集和大数据实时分析的场景,则推荐使用Kafka
4. 消息队列有什么模型
JMS是一种Java消息服务的API规范,它定义了两种消息模型:队列模型和发布/订阅模型
队列模型又叫点对点模型,指的是生产者往队列里发送消息,一个消息只能被一个消费者消费,一个队列的多个消费者之间是竞争关系
发布/订阅模型又叫主题模型,指生产者往Topic发送消息,所有订阅了该Topic的消费者都能消费到
Kafka和RocketMQ就是基于发布/订阅模型实现的
AMQP是另一种消息服务的协议,它定义了几种消息模型,通过引入exchange完成对消息的路由,支持direct exchange、fanout exchange、topic exchange
RabbitMQ就是基于AMQP协议实现的
5. 如何保证消息不丢失
消息不丢失需要从生产消息、存储消息、消费消息三个方面去保证
5.1 生产消息
在生产者侧,需要处理好生产消息的异常处理,如果写入失败需要有重试、告警等机制
5.2 存储消息
在存储消息上,Broker需要在刷盘之后再给生产者应答
在RocketMQ中,可以配置同步刷盘,主从架构下配置同步复制(也叫同步双写)
在Kafka中,默认acks=1,表示消息被leader副本接受后就会返回成功,设置acks=all,那么在所有的ISR(In-Sync Replicas)接受后才算成功,相关的其它参数有:
replication.factor:分区的副本数,可设置为>=3
min.insync.replicas:消息发送成功需要至少写入的副本数,设置为>1
unclean.leader.election.enable:leader副本故障后的选举机制,false表示不从非ISR节点中选leader,设置为false
5.3 消费消息
消费者在真正完成业务逻辑时再返回成功给Broker
在RocketMQ中,完成消费逻辑后再返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS,否则返回ConsumeConcurrentlyStatus.RECONSUME_LATER
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;public class RocketMQConsumer {public static void main(String[] args) throws Exception {// 实例化消费者,并指定消费者组名DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("example_consumer_group");// 指定NameServer地址consumer.setNamesrvAddr("localhost:9876");// 订阅一个或多个Topic,以及Tag来过滤需要消费的消息consumer.subscribe("TopicTest", "*");// 注册消息监听器consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {for (MessageExt msg : msgs) {try {// 处理消息的业务逻辑System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), new String(msg.getBody()));} catch (Exception e) {// 处理异常,这里可以根据业务需求进行重试或其他处理e.printStackTrace();// 消费失败,返回RECONSUME_LATER,消息会重新投递return ConsumeConcurrentlyStatus.RECONSUME_LATER;}}// 消费成功,返回CONSUME_SUCCESSreturn ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});// 启动消费者实例consumer.start();System.out.printf("Consumer Started.%n");}
}
在Kafka中,需要设置enable.auto.commit=false,然后在代码中手动提交offset
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {// 配置消费者属性Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("enable.auto.commit", "false");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 创建Kafka消费者实例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题String topic = "test-topic";consumer.subscribe(Collections.singletonList(topic));try {while (true) {// 拉取消息ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>();for (ConsumerRecord<String, String> record : records) {try {// 处理消息的业务逻辑System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());// 记录需要提交的偏移量TopicPartition partition = new TopicPartition(record.topic(), record.partition());OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1);offsetsToCommit.put(partition, offsetAndMetadata);} catch (Exception e) {// 处理异常,这里可以根据业务需求进行重试或其他处理e.printStackTrace();}}// 手动同步提交偏移量if (!offsetsToCommit.isEmpty()) {consumer.commitSync(offsetsToCommit);}}} finally {// 关闭消费者consumer.close();}}
}
6. 如何解决重复消费
解决重复消费比较粗鲁的办法就是保证一条消息只能被消费一次,但是如果消费者挂了未提交offset,那么为了保证消息可靠性,消息就会被重复消费
所以重点是要让消费者的处理具有幂等性,即多次处理同一条消息得到的结果是一样的
具体做法有引入全局唯一的ID,对已经消费过的消息进行去重
7. 如何保证消息的有序性
简单粗暴的方法是:单一生产者和单一消费者,即消息只由单个生产者发往单个队列,再由单个消费者消费,存在性能瓶颈
在支持分区键(Partition Key)的系统比如Kafka和RocketMQ中,可以在发送消息的时候指定key
在Kafka中在发送消息时指定key,如果需要严格顺序的话,可以指定max.in.flight.requests.per.connection=1,该参数表示在得到响应前可以发送的消息数,参数值越大吞吐量越大,设置为1会降低吞吐量
在RocketMQ中可以通过继承MessageQueueSelector实现
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.MessageQueueSelector;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageQueue;import java.util.List;public class RocketMQPartitionKeyProducer {public static void main(String[] args) throws MQClientException {DefaultMQProducer producer = new DefaultMQProducer("partition_key_producer_group");producer.setNamesrvAddr("localhost:9876");producer.start();String topic = "partition_key_topic";// 模拟不同的 Partition KeyString[] partitionKeys = {"key1", "key2", "key1", "key2"};for (int i = 0; i < partitionKeys.length; i++) {String partitionKey = partitionKeys[i];Message msg = new Message(topic, "TAG", ("Message " + i).getBytes());try {SendResult sendResult = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {String key = (String) arg;int index = Math.abs(key.hashCode()) % mqs.size();return mqs.get(index);}}, partitionKey);System.out.printf("%s%n", sendResult);} catch (Exception e) {e.printStackTrace();}}producer.shutdown();}
}
8. 推拉模式有什么区别,怎么选择
推模式和拉模式的选择一般出现在Broker和消费者之间,而生产者和Broker之间一般使用推模式而不是Broker去拉取消息,否则大量的生产者还需要去维护消息可靠性
推模式的好处是Broker在接收到消息后能够迅速地推送给消费者进行消费,适用于对实时性要求比较高的场景,坏处是消费者消费能力不够强时容易过载,需要Broker去维护消费者的状态去调整推送速率,对Broker要求比较高
拉模式的好处是对Broker没什么要求,可以稳定地控制消息消费的速率,防止消费者过载,并且适合批量地拉取消息,坏处是消息容易延迟,或者是长时间轮询没有消息可消费
RocketMQ和Kafka都使用了拉模式,它们都利用长轮询对拉模式做了优化,也就是在消费者拉取的时候把请求给hold住,然后等待消息到来再把消息发送出去
9. 如何解决消息堆积
消息堆积问题有两个原因,一个是生产太快,一个是消费太慢
生产太快的问题可以对生产端做限流和降级,以及只保留关键消息,丢弃非关键消息,或者延迟处理
消费太慢的问题需要去定位bug,提升消费者的消费能力,包括优化消费的逻辑,增加消费者的线程数量,对消费者进行垂直扩容(增加单个消费者的CPU/内存),或者水平扩容(增加消费者副本数)
10. Kafka的事务消息是什么,怎么实现
Kafka的事务消息保证一系列消息要么完全发送成功,要么完全发送失败,即一系列消息操作的原子性
实现的方式是,Kafka使用事务协调器负责事务的启动、提交和终止,为确保精确一次(exactly once)的投递语义,会为每个Producer维护一个pid,为<pid, topic, partition>维护一个递增的seq从而保证消息按顺序被正确接收,在消费者侧,需要设置read_committed=true保证只消费已提交的消息
具体实践如下
生产者配置acks=all确认消息成功发送、transaction_id设置事务id、enable.idempotence=true确保投递精确一次
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;public class KafkaTransactionalProducer {public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.ACKS_CONFIG, "all");props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional-id");props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");KafkaProducer<String, String> producer = new KafkaProducer<>(props);producer.initTransactions();try {producer.beginTransaction();ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", "key", "value");producer.send(record);producer.commitTransaction();} catch (Exception e) {producer.abortTransaction();e.printStackTrace();} finally {producer.close();}}
}
消费者配置read_committed=true确保只消费已提交的消息,auto.offset.reset=earliest确保启动时从最早的消息开始消费
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaTransactionalConsumer {public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("test_topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (var record : records) {System.out.printf("Received message: key = %s, value = %s%n", record.key(), record.value());}}}
}
11. RocketMQ的事务消息是什么
RocketMQ的事务消息和Kafka的不同,Kafka实现的是多条消息的原子性,RocketMQ实现的是分布式事务,也就是消息存储和本地事务处在同一个事务
RocketMQ是利用事务消息+事务回查机制实现分布式事务的
- 生产者发送“半消息”到MQ
- MQ响应
- 生产者执行本地事务
- 生产者根据本地事务执行状态向MQ发送commit/rollback,若是commit,半消息变为正式消息,消费者可见,若是rollback,则丢弃该半消息
- 如果因为网络抖动等原因,MQ没收到第四步,则通知生产者事务回查
- 生产者查询事务状态
- 生产者根据回查的事务状态,通知MQ进行commit/rollback
相关文章:

消息队列基础概念及选型,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息
前言 是时候总结下消息队列相关知识点啦!我搓搓搓搓 本文包括消息队列基础概念介绍,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息 参考资料: Kafka常见问题总结 | JavaGuide RocketMQ常见问题总结 | JavaGuide …...

基于STM32与应变片的协作机械臂力反馈控制系统设计与实现---3.3 机械结构改装
3.3 机械臂结构改装设计与实施 一、改装需求分析 1.1 改装类型分级 改装级别涉及范围典型改动周期成本I级(小型)末端执行器工具快换装置1-3天$500-2000II级(中型)关节模块电机/减速器升级1-2周$2000-8000III级(大型)本体结构材质/拓扑优化1-3月$8000+1.2 关键参数变更评…...

k8s进阶之路:本地集群环境搭建
概述 文章将带领大家搭建一个 master 节点,两个 node 节点的 k8s 集群,容器基于 docker,k8s 版本 v1.32。 一、系统安装 安装之前请大家使用虚拟机将 ubuntu24.04 系统安装完毕,我是基于 mac m1 的系统进行安装的,所…...
)
云服务器实战:用 Nginx 搭建高性能 API 网关与反向代理服务(附完整配置流程)
在如今的 Web 系统架构中,“接口统一出口”已成为必备设计模式——无论是前后端分离、微服务架构,还是多端接入(Web、小程序、App),一个稳定、高性能、可扩展的 API 网关至关重要。 而 Nginx,作为轻量级高…...
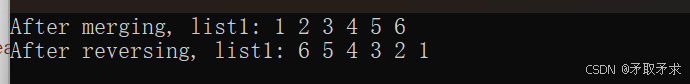
C++ STL 详解 ——list 的深度解析与实践指南
在 C 的标准模板库(STL)中,list作为一种重要的序列式容器,以其独特的双向链表结构和丰富的操作功能,在许多编程场景下发挥着关键作用。深入理解list的特性与使用方法,能帮助开发者编写出更高效、灵活的代码…...

按键切换LCD显示后,显示总在第二阶段,而不在第一阶段的问题
这是一个密码锁的程序,当在输入密码后,原本是要重置密码,但是程序总是在输入密码正确后总是跳转置设置第二个密码,而第一个密码总是跳过。 不断修改后, 解决方法 将if语句换成switch语句,这样就可以分离程序…...
护网蓝初面试题
《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247486065&idx2&snb30ade8200e842743339d428f414475e&chksmc0e4732df793fa3bf39…...

C++11: 智能指针
C11: 智能指针 (一)智能指针原理1.RAll2.智能指针 (二)C11 智能指针1. auto_ptr2. unique_ptr3. shared_ptr4. weak_ptr (三)shared_ptr中存在的问题std::shared_ptr的循环引用 (四)删除器(五&a…...

去中心化预测市场
去中心化预测市场 核心概念 预测市场类型: 类别型市场:二元结果(YES/NO),例如“BTC在2024年突破10万美元?” 多选型市场:多个选项(如总统候选人),赔付基于…...
从零实现本地大模型RAG部署
1. RAG概念 RAG(Retrieval-Augmented Generation)即检索增强生成,是一种结合信息检索与大型语言模型(大模型)的技术。从外部知识库(如文档、数据库或网页)中实时检索相关信息,并将其…...

使用 Python 连接 PostgreSQL 数据库,从 `mimic - III` 数据库中筛选数据并导出特定的数据图表
要使用 Python 连接 PostgreSQL 数据库,从 mimic - III 数据库中筛选数据并导出特定的数据图表,你可以按照以下步骤操作: 安装所需的库:psycopg2 用于连接 PostgreSQL 数据库,pandas 用于数据处理,matplot…...

【Linux系统篇】:探索文件系统原理--硬件磁盘、文件系统与链接的“三体宇宙”
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:Linux篇–CSDN博客 文章目录 一.认识硬件--磁盘物理存储结构1.存储介质类型2.物理存储单元3…...
Tracing the thoughts of a large language model 简单理解
Tracing the thoughts of a large language model 这篇论文通过电路追踪方法(Circuit Tracing)揭示了大型语言模型Claude 3.5 Haiku的内部机制,其核心原理可归纳为以下几个方面: 1. 方法论核心:归因图与替换模型 替换模型(Replacement Model) 使用跨层转码器(CLT)将原…...
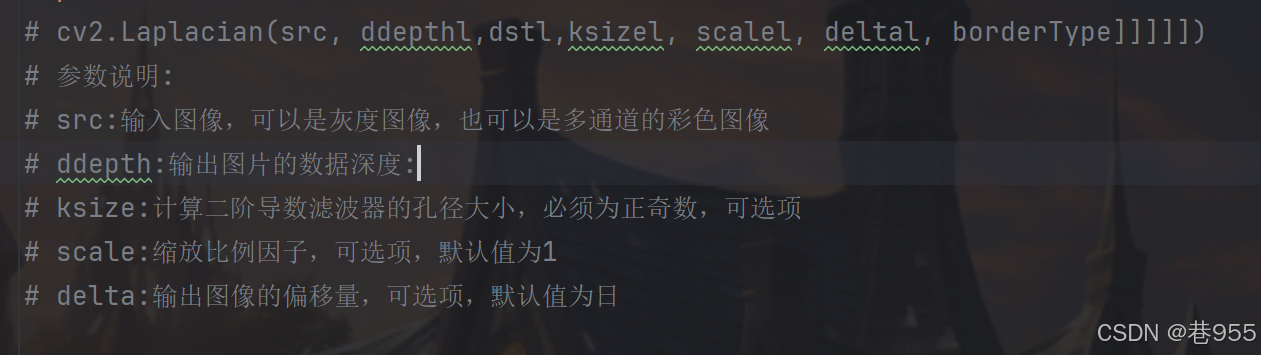
OpenCV边缘检测技术详解:原理、实现与应用
概述 边缘检测是计算机视觉和图像处理中最基本也是最重要的技术之一,它通过检测图像中亮度或颜色急剧变化的区域来识别物体的边界。边缘通常对应着场景中物体的物理边界、表面方向的变化或深度不连续处。 分类 OpenCV提供了多种边缘检测算法,下面我们介…...
)
Java学习——day22(Java反射基础入门)
文章目录 1.反射的定义2. 认识反射的关键API2.1 Class2.2 Field2.3 Method2.4 Constructor 3. 示例代码讲解与分析4. 编写反射示例代码的步骤4.1 定义测试类4.2 编写主程序,使用反射获取信息4.3 通过反射创建对象并调用方法 5. 总结6.今日生词 Java反射笔记 1.反射的…...
BN 层做预测的时候, 方差均值怎么算
✅ 一、Batch Normalization(BN)回顾 BN 层在训练和推理阶段的行为是不一样的,核心区别就在于: 训练时用 mini-batch 里的均值方差,预测时用全局的“滑动平均”均值方差。 🧪 二、训练阶段(Trai…...

JS 其他事件类型
页面加载 事件 window.addEvent() window.addEventListener(load,function(){const btn document.querySelector(button)btn.addEventListener(click,function(){alert(按钮)})})也可以给其他标签加该事件 HTML加载事件 找html标签 也可以给页面直接赋值...
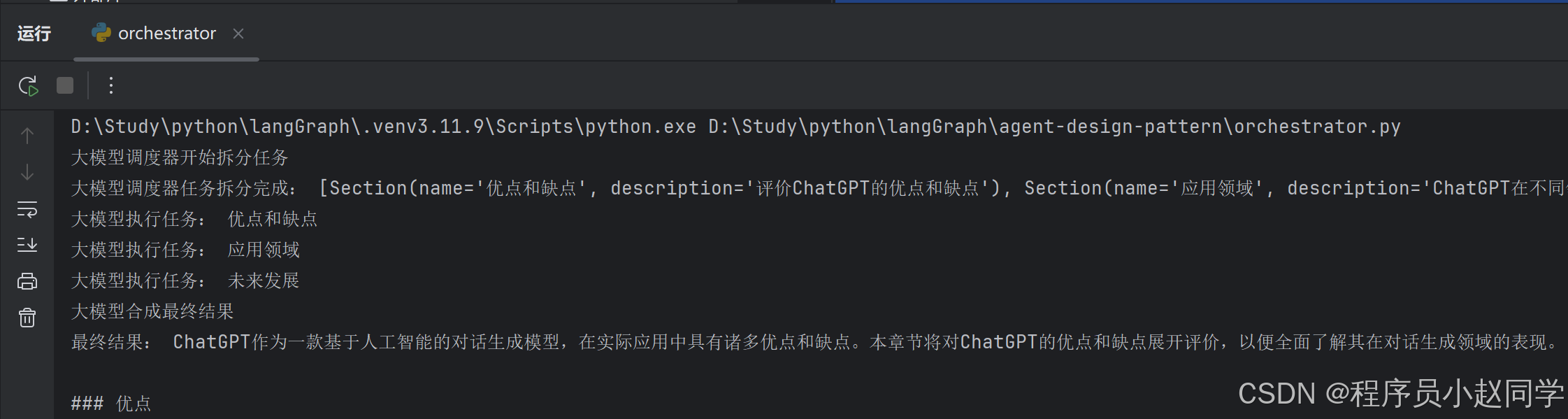
AI Agent设计模式五:Orchestrator
概念 :中央任务调度中枢 ✅ 优点:全局资源协调,确保任务执行顺序❌ 缺点:单点故障风险,可能成为性能瓶颈 import operator import osfrom langchain.schema import SystemMessage, HumanMessage from langchain_opena…...

在Hive中,将数据从一个表查询并插入到另一个表
1. 确认目标表结构 确保目标表已存在且结构与查询结果匹配。若不存在,需先创建: CREATE TABLE target_table ( id INT, name STRING ) PARTITIONED BY (dt STRING) STORED AS ORC; 2. 选择插入方式 覆盖插入(替换现有数据࿰…...
)
Android Fresco 框架缓存模块源码深度剖析(二)
Android Fresco 框架缓存模块源码深度剖析 一、引言 本人掘金号,欢迎点击关注:https://juejin.cn/user/4406498335701950 在 Android 应用开发中,图片加载和处理是常见且重要的功能。频繁的图片加载不仅会消耗大量的网络流量,还…...

MySQL基础 [三] - 数据类型
目录 数据类型分类 编辑 数值类型 tinyint bit 浮点类型 float decimal 字符串类型 char varchar varchar和char的比较和选择 日期和时间类型 enum和set enum类型 set类型 enum和set的类型查找 数据类型分类 数值类型 tinyint TINYINT[(M)] [UNSIGNED]是 …...
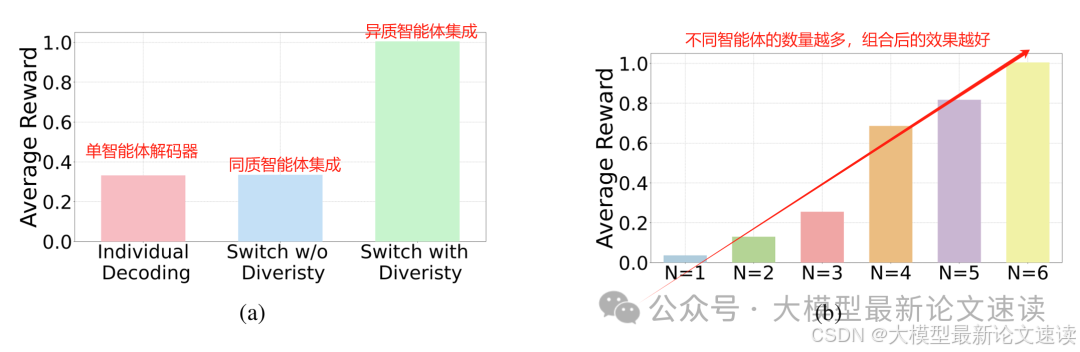
不用训练,集成多个大模型产生更优秀的输出
论文标题 Collab: Controlled Decoding using Mixture of Agents for LLM Alignment 论文地址 https://arxiv.org/pdf/2503.21720 作者背景 JP摩根,马里兰大学帕克分校,普林斯顿大学 动机 大模型对齐(alignment)的主要目的…...
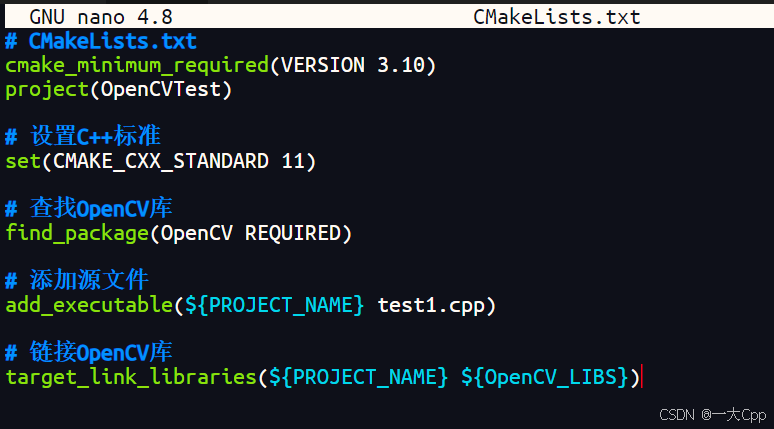
随笔1 认识编译命令
1.认识编译命令 1.1 解释gcc编译命令: gcc test1.cpp -o test1 pkg-config --cflags --libs opencv 命令解析: gcc:GNU C/C 编译器,用于编译C/C代码。 test1.cpp:源代码文件。 -o test1:指定输出的可执行文件名为t…...

【数据结构】并查集应用
修改数组 题目:检查ai是否出现过,出现过就不断1,使成为第一个没有出现过的。这样得到一个不重复数组。 祖先是该数字能使用的最小数字,当使用完后,祖先把这个格子占了,下次再来,就得使用后一个…...

python基础-16-处理csv文件和json数据
文章目录 【README】【16】处理csv文件和json数据【16.1】csv模块【16.1.1】reader对象【16.1.2】在for循环中, 从reader对象读取数据【16.1.3】writer对象【16.1.5】DictReader与DictWriter对象 【16.4】json模块【16.4.1】使用loads()函数读取json字符串并转为jso…...

MySQL Explain 分析 SQL 执行计划
MySQL Explain 分析 SQL 执行计划 在优化 SQL 查询性能时,了解查询的执行计划至关重要。MySQL 提供的 EXPLAIN 工具能够帮助我们深入了解查询语句的执行过程、索引使用情况以及潜在的性能瓶颈。本文将详细介绍如何使用 EXPLAIN 分析 SQL 执行计划,并探讨…...

Hyperlane 框架路由功能详解:静态与动态路由全掌握
Hyperlane 框架路由功能详解:静态与动态路由全掌握 Hyperlane 框架提供了强大而灵活的路由功能,支持静态路由和动态路由两种模式,让开发者能够轻松构建各种复杂的 Web 应用。本文将详细介绍这两种路由的使用方法。 静态路由:简单…...

理解进程和线程的概念
在操作系统中,进程和线程都是执行的基本单位,但它们在性质和管理方面有所不同 进程 定义: 进程是一个正在运行的程序的实例,是操作系统资源分配的基本单位。特点: 独立性:每个进程有其独立的内存空间、数据栈和其他辅助数据。重…...
铰链损失函数 Hinge Loss和Keras 实现
一、说明 在为了了解 Keras 深度学习框架的来龙去脉,本文介绍铰链损失函数,然后使用 Keras 实现它们以进行练习并了解它们的行为方式。在这篇博客中,您将首先找到两个损失函数的简要介绍,以确保您在我们继续实现它们之前直观地理解…...

瑞数信息发布《BOTS自动化威胁报告》,揭示AI时代网络安全新挑战
近日,瑞数信息正式发布《BOTS自动化威胁报告》,力求通过全景式观察和安全威胁的深度分析,为企业在AI时代下抵御自动化攻击提供安全防护策略,从而降低网络安全事件带来的影响,进一步增强业务韧性和可持续性。 威胁一&am…...