唯一ID生成器设计方案
《亿级流量系统架构设计与实战》总结
1. 唯一ID的核心需求
• 全局唯一性:分布式系统中所有节点生成的ID不可重复。
• 趋势递增性(可选):ID按时间或序列递增,优化数据库写入性能。
• 高可用性:服务需7×24小时可用,支持故障自动恢复。
• 高性能:单节点QPS需达到数万至百万级别。
• 可扩展性:支持水平扩展以应对业务增长。
2. 单机递增方案
2.1 Redis INCR命令
• 原理:利用Redis原子操作INCR或INCRBY生成单调递增ID。
• 实现:
# 生成ID
redis-cli INCR my_counter
• 技术细节:
• 集群模式:通过Redis Cluster分片存储多个计数器(如user_id:1, order_id:2)。
• 持久化:开启AOF或RDB确保重启后ID不丢失。
• 优点:简单高效,延迟低(毫秒级)。
• 缺点:
• 依赖Redis集群,增加系统复杂度。
• 高并发下可能成为瓶颈(需维护长连接池)。
• 适用场景:低并发系统或作为其他方案的兜底。
2.2 数据库自增主键
• 原理:利用关系型数据库(如MySQL)的自增主键特性。
• 实现:
ALTER TABLE user AUTO_INCREMENT = 1000;
INSERT INTO user (name) VALUES ('Alice');
• 技术细节:
• 分库分表友好性:可通过MOD运算拆分表(如user_id % 1024)。
• 主从延迟:主从同步可能导致短暂ID不连续。
• 优点:绝对有序,天然事务支持。
• 缺点:
• 扩展性差,需预分配ID段或频繁修改表结构。
• 高并发写入易成为性能瓶颈。
• 适用场景:传统单体应用或低并发场景。
3. 分布式递增方案
3.1 Snowflake算法
• 核心组成:
long id = ((timestamp - twepoch) << timestampLeftOffset) | (datacenterId << datacenterIdShift)| (machineId << machineIdShift)| sequence;
• 参数说明:
• timestamp:毫秒级时间戳(41位,支持约69年)。
• datacenterId:数据中心ID(5位,支持32个机房)。
• machineId:工作机器ID(5位,支持32台机器)。
• sequence:序列号(12位,同一毫秒内支持4096个ID)。
• 技术实现:
• 时钟回拨问题:记录历史时间戳,若发生回拨则抛出异常等待时钟同步。
• 位分配优化:根据业务需求调整各字段位数(如延长timestamp到42位)。
• 优点:
• 分布式生成,性能高(单机QPS可达百万)。
• ID趋势递增,利于数据库写入。
• 缺点:
• 依赖机器时钟,时钟回拨可能导致ID重复。
• 需手动分配datacenterId和machineId。
• 适用场景:高并发、需趋势递增的场景(如订单号、消息ID)。
3.2 Leaf(美团分布式ID生成服务)
• Leaf-segment方案:
• 原理:预分配ID号段(如1000~1999),客户端批量拉取号段。
• 架构:
Client → Leaf Server(号段分配) → DB(存储号段状态)
• 优化:支持号段预加载(如提前拉取下一个号段)。
• Leaf-snowflake方案:
• 原理:基于Snowflake算法,通过ZooKeeper选举Master节点分配machineId。
• 架构:
Client → Leaf Server(Snowflake节点) ← ZooKeeper(协调)
• 技术细节:
• 号段分配:支持号段长度动态调整(如从1000调整为10000)。
• 时钟回拨检测:Leaf-snowflake集成Snowflake的时钟回拨处理逻辑。
• 优点:
• 高可用,支持号段和Snowflake双模式切换。
• 支持号段/雪花模式混合部署。
• 缺点:
• 依赖外部存储(如DB/ZooKeeper)。
• 需部署中间件服务。
• 适用场景:中大规模分布式系统,需兼顾灵活性和高可用性。
4. 其他方案
4.1 UUID
• 原理:基于MAC地址、时间戳和随机数生成128位唯一标识。
• 实现:
UUID.randomUUID().toString() // 输出类似 "123e4567-e89b-12d3-a456-426614174000"
• 优点:本地生成,无依赖。
• 缺点:
• 无序导致数据库索引性能下降。
• 存储空间大(16字节)。
• 适用场景:离线系统或对顺序无要求的场景。
4.2 Redis Hash/Redisson
• 原理:利用Redis的Hash数据结构生成ID。
• 实现:
HSET my_hash field 1
HINCRBY my_hash field 1
• 优点:支持原子递增,可扩展多个Hash实例。
• 缺点:需维护Redis集群,性能低于原生INCR。
5. 方案对比与选型建议
| 方案 | 全局唯一性 | 趋势递增 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|
| Redis INCR | ✔️ | ✔️ | 高 | 中 | 低并发系统 |
| 数据库自增 | ✔️ | ✔️ | 低 | 高 | 传统单体应用 |
| Snowflake | ✔️ | ✔️ | 极高 | 中 | 高并发、需趋势递增的场景 |
| Leaf-segment | ✔️ | ❌ | 高 | 高 | 中大规模分布式系统 |
| Leaf-snowflake | ✔️ | ✔️ | 极高 | 高 | 需混合部署的复杂系统 |
6. 架构图示
6.1 Snowflake算法架构
Client → Time Service(获取时间戳)↓Machine ID(通过配置或ZooKeeper分配)↓Sequence Generator(本地计数器)↓
ID合成器 → [timestamp << 22] | [machineId << 17] | [sequence]
6.2 Leaf分布式服务架构
Client → Leaf Client SDK → Leaf Server(HTTP/RPC接口)↑ ↓└─── ZooKeeper(协调Master选举) ────┘
7. 最佳实践
- 时钟回拨防御:
• 记录历史时间戳,若检测到回拨则抛出异常等待时钟同步。
• 使用NTP服务校准时钟,减少回拨概率。 - 分库分表友好:
• ID高位分配分片字段(如末尾N位表示分片号)。 - 预生成ID池:
• 对高并发场景预加载ID池(如提前生成10万ID缓存在本地)。
通过以上方案对比和技术实现细节,可根据业务场景选择最适合的唯一ID生成策略。对于大多数互联网业务,推荐使用Leaf-snowflake或Snowflake算法,兼顾性能与可用性。
相关文章:

唯一ID生成器设计方案
《亿级流量系统架构设计与实战》总结 1. 唯一ID的核心需求 • 全局唯一性:分布式系统中所有节点生成的ID不可重复。 • 趋势递增性(可选):ID按时间或序列递增,优化数据库写入性能。 • 高可用性:服务需72…...
将极坐标(magnitude 和 angle)转换为笛卡尔坐标(x 和 y)函数polarToCart())
OpenCV 图形API(16)将极坐标(magnitude 和 angle)转换为笛卡尔坐标(x 和 y)函数polarToCart()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 计算二维向量的 x 和 y 坐标。 polarToCart 函数根据 magnitude 和 angle 的对应元素表示的每个二维向量,计算其笛卡尔坐标:…...

在 Ubuntu24.04 LTS 上 Docker Compose 部署基于 Dify 重构二开的开源项目 Dify-Plus
一、安装环境信息说明 硬件资源(GB 和 GiB 的主要区别在于它们的换算基数不同,GB 使用十进制,GiB 使用二进制,导致相同数值下 GiB 表示的容量略大于 GB;换算关系:1 GiB ≈ 1.07374 GB ;1 GB ≈ …...

安装和配置Docker
其他版本的安装方式可直接参考官方网站,推荐通过官方网站提供的方式安装Dockers,下面只是个演示的示例,仅供参考 Install | Docker Docs 安装 Docker 的前置准备 1.虚拟机配置: 推荐配置 内存:4GB(最低…...

Ansible YAML 基础语法与关键词 的详细指南
以下是 Ansible YAML 基础语法与关键词 的详细指南,帮助你快速掌握 Playbook 编写规范和核心概念: 目录 一、Ansible Playbook 基础结构1. YAML 文件基础 二、核心关键词1. Play 定义2. Task 定义3. Handler 定义4. 变量(Variables࿰…...

NO.64十六届蓝桥杯备战|基础算法-简单贪心|货仓选址|最大子段和|纪念品分组|排座椅|矩阵消除(C++)
贪⼼算法是两极分化很严重的算法。简单的问题会让你觉得理所应当,难⼀点的问题会让你怀疑⼈⽣ 什么是贪⼼算法? 贪⼼算法,或者说是贪⼼策略:企图⽤局部最优找出全局最优。 把解决问题的过程分成若⼲步;解决每⼀步时…...
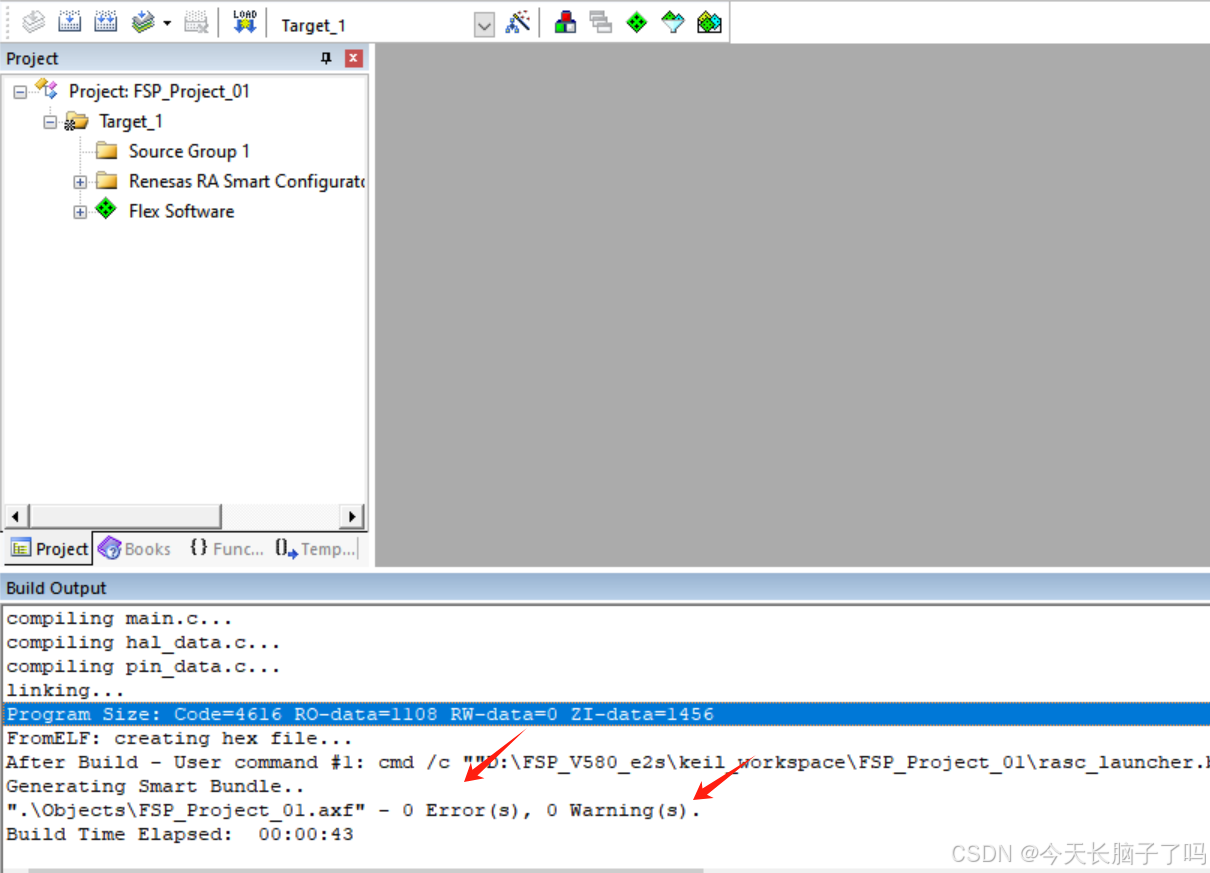
瑞萨RA4M2使用心得-KEIL5的第一次编译
目录 前言 环境: 开发板:RA-Eco-RA4M2-100PIN-V1.0 IDE:keil5.35 一、软件的下载 编辑瑞萨的芯片,除了keil5 外还需要一个软件:RASC 路径:Releases renesas/fsp (github.com) 向下找到: …...

java根据集合中对象的属性值大小生成排名
1:根据对象属性降序排列 public static <T extends Comparable<? super T>> LinkedHashMap<T, Integer> calculateRanking(List<ProductPerformanceInfoVO> dataList, Function<ProductPerformanceInfoVO, T> keyExtractor) {Linked…...
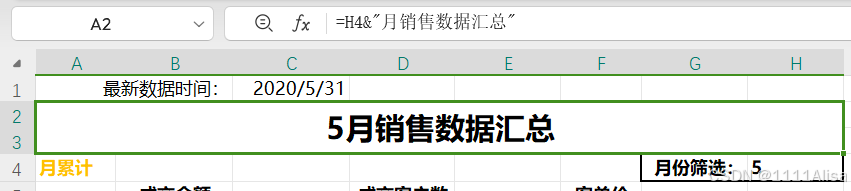
数据分析-Excel-学习笔记
Day1 复现报表聚合函数:日期联动快速定位区域SUMIF函数SUMIFS函数环比、同比计算IFERROR函数混合引用单元格格式总结汇报 拿到一个Excel表格,首先要看这个表格个构成(包含了哪些数据),几行几列,每一列的名称…...
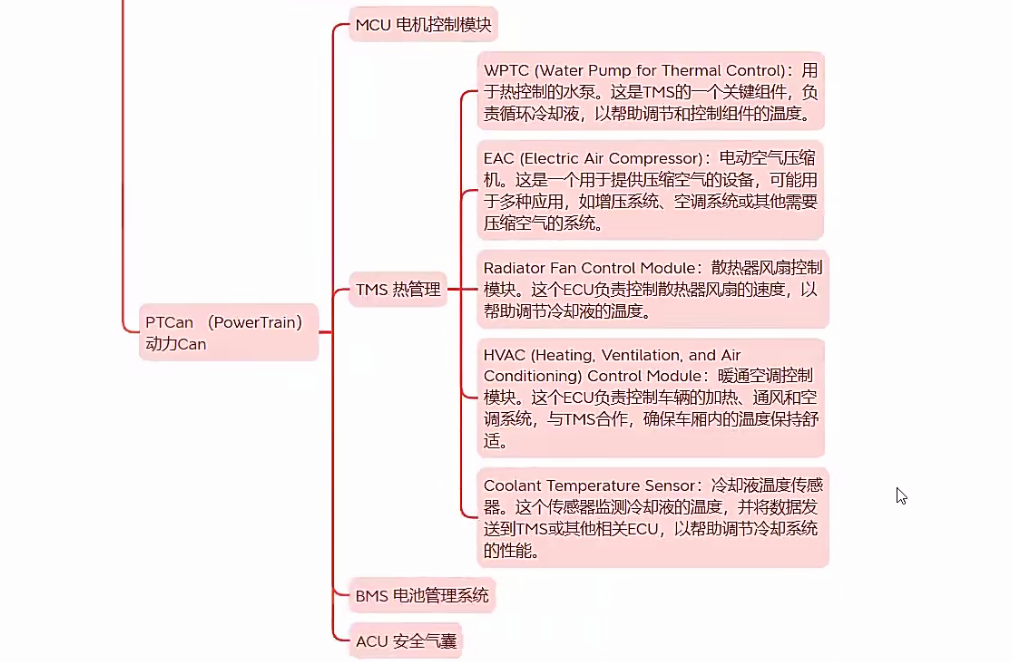
整车CAN网络和CANoe
车载网络中主要包含有Can网络,Lin网络,FlexRay,Most,以太网。 500kbps:500波特率,表示的数据传输的速度。表示的是最大的网速传输速度。也就是每秒 500kb BodyCan车身Can InfoCan娱乐信息Can 车身CAN主要连接的是ESB电动安全带 ADB自适应远光灯等 PTCan动力Can 底盘Can...

ChatGPT 的新图像生成器非常擅长伪造收据
本月,ChatGPT 推出了一种新的图像生成器,作为其 4o 模型的一部分,该模型在生成图像内的文本方面做得更好。 人们已经在利用它来生成假的餐厅收据,这可能会为欺诈者使用的已经很广泛的 AI 深度伪造工具包添加另一种工具。 多产的…...

JS页面尺寸事件
元素位置 在这里插入图片描述 父元素带有定位时输出相对于父亲元素的距离值...

SpringBoot的日志框架
目录 默认日志框架 日志配置 更换日志框架 排除默认Logback 引入目标日志框架 添加配置文件 logback.xml SpringBoot的核心设计宗旨是约定大于配置,很多框架功能都给你默认加载和配置完成供你使用,但这就要求使用者对框架有一定的理解和改造能力,比如这个日志框架,是其…...

网络协议之基础介绍
写在前面 本文看下网络协议相关基础内容。 1:为什么要有网络协议 为了实现世界各地的不同主机的互联互通。 2:协议的三要素 协议存在的目的就是立规矩,无规矩不成方圆嘛!但是这个规矩也不是想怎么立就怎么立的,也…...
)
【学Rust写CAD】34 精确 Alpha 混合函数(argb.rs补充方法)
源码 #[inline]pub fn over_exact(self, dst: Argb) -> Argb {let a 255 - self.alpha32();let t dst.rb() * a 0x80_00_80;let mut rb (t ((t >> 8) & Argb::MASK)) >> 8;rb & Argb::MASK;rb self.rb();// saturaterb | 0x1000100 - ((rb >&…...

利用NumPy核心知识点优化TensorFlow模型训练过程
利用NumPy核心知识点优化TensorFlow模型训练过程 NumPy是Python科学计算的基础库,掌握它的高效操作可以显著提升TensorFlow模型的训练效率。本文详细探讨如何将NumPy的核心优势应用于TensorFlow模型训练的各个环节。 1. 数据预处理优化 高效向量化操作 NumPy的向…...

初识数据结构——Java集合框架解析:List与ArrayList的完美结合
📚 Java集合框架解析:List与ArrayList的完美结合 🌟 前言:为什么我们需要List和ArrayList? 在日常开发中,我们经常需要处理一组数据。想象一下,如果你要管理一个班级的学生名单,或…...
)
TDengine 从入门到精通(2万字长文)
目录 第一章:走进 TDengine 的世界 TDengine 是个啥? TDengine 的硬核特性 性能炸裂 分布式架构,天生可扩展 SQL 用起来贼顺手 写入方式花样多 内置缓存,省心又省力 TDengine 能干啥? 智能制造 能源管理 物联网平台 工业大数据 第二章:上手 TDengine:安装与…...
)
DevOps 与持续集成(CI/CD)
1. DevOps 概述 DevOps(Development + Operations)是一种软件开发方法,强调开发(Dev)与运维(Ops)协作,通过自动化工具提高软件交付效率。其目标是: ✅ 提高部署速度 —— 频繁发布新版本 ✅ 减少人为错误 —— 通过自动化降低运维风险 ✅ 增强可观测性 —— 监控和日…...

[特殊字符] 使用 Handsontable 构建一个支持 Excel 公式计算的动态表格
在 Web 应用中,处理表格数据并提供 Excel 级的功能(如公式计算、数据导入导出)一直是个挑战。今天,我将带你使用 React Handsontable 搭建一个强大的 Excel 风格表格,支持 公式计算、Excel 文件导入导出,并…...

uniapp微信小程序引入vant组件库
1、首先要有uniapp项目,根据vant官方文档使用yarn或npm安装依赖: 1、 yarn init 或 npm init2、 # 通过 npm 安装npm i vant/weapp -S --production# 通过 yarn 安装yarn add vant/weapp --production# 安装 0.x 版本npm i vant-weapp -S --production …...

贪心进阶学习笔记
反悔贪心 贪心是指直接选择局部最优解,不需要考虑之后的影响。 而反悔贪心是在贪心上面加了一个“反悔”的操作,于是又可以撤销之前的“鲁莽行动”,让整个的选择稍微变得“理智一些”。 于是,我个人理解,反悔贪心是…...

Java 大视界 -- Java 大数据在航天遥测数据分析中的技术突破与应用(177)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

架构师面试(二十七):单链表
问题 今天的问题对于架构师来说会相对容易许多。今天出一个【数据结构与算法】相关的题目,醒醒脑。 给一张【单链表】,该单链表有100个节点元素(当然,事先我们是不知道100这个数目的),要获取倒数第8个元素…...
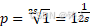
从扩展黎曼泽塔函数构造物质和时空的结构-15
回来考虑泽塔函数, 我们知道, 也就是在平面直角坐标系上反正切函数在x上的变化率,那么不难看出, 就是在s维空间上的“广义”反正切函数在单位p上的变化率,而泽塔函数,就是这些变化率的全乘积, 因…...

数据库访问工具 dbVisitor v6.0.0 发布
dbVisitor 是一款轻量小巧、功能完备的 Java 数据库 ORM 工具,它的前身是 HasorDB,历经 8 年迭代后正式更名为 dbVisitor 并开始独立发展4。以下是关于 dbVisitor v6.0.0 发布的相关信息: 发布说明 在 Maven Central 上可查询到 dbVisitor …...

01背包问题详解 具体样例模拟版
01背包 有 N 件物品和一个容量是 V 的背包。每件物品只能使用一次。 第 i 件物品的体积是 v i v_i vi,价值是 w i w_i wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。 输出最大价值。 输入格式 …...
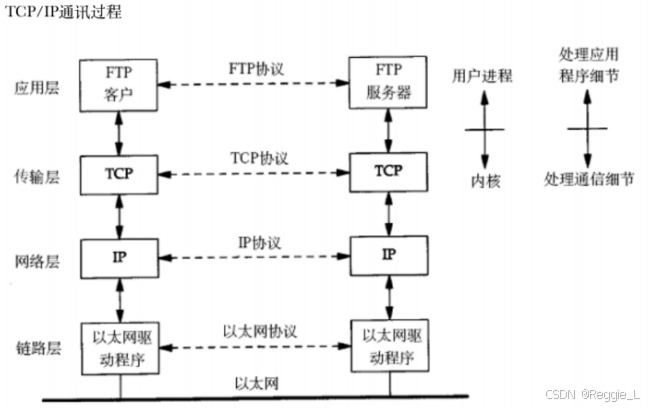
网络初识 - Java
网络发展史: 单机时代(独立模式) -> 局域网时代 -> 广域网时代 -> 移动互联网时代 网络互联:将多台计算机链接再一起,完成数据共享。 数据共享的本质是网络数据传输,即计算机之间通过网络来传输数…...

zk基础—5.Curator的使用与剖析一
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curator实现分布式Barrier 6.基于Curator实现分布式计数器 7.基于Curator实现zk的节点和子节点监听机制 8.基于Curator创…...

大模型快速 ASGI 服务器uvicorn
基础概念类 1. 什么是 Uvicorn,它的作用是什么? 答案:Uvicorn 是一个基于 Python 的快速 ASGI(异步服务器网关接口)服务器。它的主要作用是作为 Web 应用程序的服务器,负责接收客户端的请求,并…...