利用NumPy核心知识点优化TensorFlow模型训练过程
利用NumPy核心知识点优化TensorFlow模型训练过程
NumPy是Python科学计算的基础库,掌握它的高效操作可以显著提升TensorFlow模型的训练效率。本文详细探讨如何将NumPy的核心优势应用于TensorFlow模型训练的各个环节。
1. 数据预处理优化
高效向量化操作
NumPy的向量化操作比Python循环快数十倍,在数据预处理阶段尤为重要:
# 低效方式
processed_data = []
for i in range(len(raw_data)):processed_data.append(raw_data[i] / 255.0 - 0.5)# NumPy高效方式
processed_data = raw_data / 255.0 - 0.5 # 向量化操作,速度提升10-100倍
批量数据标准化
使用NumPy进行高效的标准化处理:
# 标准化数据集
def standardize(data):mean = np.mean(data, axis=0)std = np.std(data, axis=0)return (data - mean) / (std + 1e-8) # 添加小值避免除零错误# 应用于TensorFlow数据管道
standardized_data = tf.py_function(lambda x: standardize(x.numpy()), [dataset], tf.float32
)
2. 数据加载与增强
内存映射优化大数据集
当处理超过RAM容量的数据集时,使用NumPy的内存映射功能:
# 使用内存映射读取大型数据集
large_dataset = np.memmap('large_data.dat', dtype='float32', mode='r', shape=(1000000, 784))# 创建TensorFlow数据集
dataset = tf.data.Dataset.from_tensor_slices(large_dataset)
高效数据增强
利用NumPy实现自定义数据增强,然后整合到TensorFlow数据管道:
def numpy_augment(images):# 随机旋转angles = np.random.uniform(-30, 30, size=images.shape[0])augmented = np.array([rotate(img, angle) for img, angle in zip(images, angles)])# 随机缩放和平移可以类似实现return augmented.astype(np.float32)# 整合到TensorFlow
augmented_data = tf.py_function(numpy_augment, [batch_images], tf.float32)
3. 模型初始化优化
实现高级初始化方法
使用NumPy实现TensorFlow中不内置的权重初始化方法:
def orthogonal_initializer(shape):"""正交初始化,有助于深层网络的训练"""flat_shape = (shape[0], np.prod(shape[1:]))a = np.random.normal(0.0, 1.0, flat_shape)u, _, v = np.linalg.svd(a, full_matrices=False)q = u if u.shape == flat_shape else vq = q.reshape(shape)return q.astype(np.float32)# 在TensorFlow模型中使用
weights = tf.Variable(orthogonal_initializer([784, 256]))
特定分布初始化
根据模型特点定制权重分布:
def custom_init(shape, dtype=np.float32):# 例如:基于Gamma分布的初始化return np.random.gamma(0.1, 0.1, size=shape).astype(dtype)layer = tf.keras.layers.Dense(units=128,kernel_initializer=lambda shape, dtype: tf.convert_to_tensor(custom_init(shape)),bias_initializer='zeros'
)
4. 模型分析与调试
权重和梯度分析
使用NumPy分析模型权重分布和梯度状况:
# 分析权重分布
def analyze_weights(model):stats = {}for layer in model.layers:if hasattr(layer, 'kernel'):w = layer.kernel.numpy()stats[layer.name] = {'mean': np.mean(w),'std': np.std(w),'min': np.min(w),'max': np.max(w),'zeros': np.sum(w == 0) / w.size,'histogram': np.histogram(w, bins=20)}return stats
特征可视化与分析
使用NumPy的SVD分解分析特征表示:
def analyze_feature_space(activations):# 假设activations是某层的输出 [batch_size, features]act_np = activations.numpy()# 计算主成分U, S, V = np.linalg.svd(act_np, full_matrices=False)# 计算特征的解释方差比explained_var_ratio = (S ** 2) / np.sum(S ** 2)return {'singular_values': S,'explained_variance_ratio': explained_var_ratio,'principal_directions': V}
5. 自定义训练循环优化
实现混合精度计算
结合NumPy和TensorFlow实现自定义混合精度训练:
def mixed_precision_step(model, inputs, labels, optimizer):# 将输入转换为float16进行前向传播inputs_fp16 = tf.cast(inputs, tf.float16)with tf.GradientTape() as tape:predictions = model(inputs_fp16, training=True)loss = loss_fn(labels, predictions)# 使用NumPy识别并处理梯度爆炸grads = tape.gradient(loss, model.trainable_variables)grads_np = [g.numpy() for g in grads if g is not None]# 检测无效梯度(NaN或Inf)has_nan = any(np.isnan(np.sum(g)) for g in grads_np)has_inf = any(np.isinf(np.sum(g)) for g in grads_np)if not has_nan and not has_inf:optimizer.apply_gradients(zip(grads, model.trainable_variables))return losselse:print("警告:检测到NaN或Inf梯度,跳过此步骤")return None
实现高级梯度操作
利用NumPy实现TensorFlow中不易实现的梯度处理:
def custom_gradient_processing(grads):# 转换为NumPy数组进行处理grads_np = [g.numpy() if g is not None else None for g in grads]# 实现特殊的梯度裁剪 - 例如按百分位数裁剪processed_grads = []for g in grads_np:if g is not None:# 计算95%分位数作为裁剪阈值threshold = np.percentile(np.abs(g), 95)clipped = np.clip(g, -threshold, threshold)processed_grads.append(tf.convert_to_tensor(clipped))else:processed_grads.append(None)return processed_grads
6. 性能优化与监控
基于NumPy的性能分析
使用NumPy分析训练过程中的性能瓶颈:
class PerformanceMonitor:def __init__(self):self.times = {}def time_operation(self, name, operation, *args, **kwargs):start = time.time()result = operation(*args, **kwargs)end = time.time()if name not in self.times:self.times[name] = []self.times[name].append(end - start)return resultdef summarize(self):summary = {}for name, times in self.times.items():times_array = np.array(times)summary[name] = {'mean': np.mean(times_array),'std': np.std(times_array),'median': np.median(times_array),'min': np.min(times_array),'max': np.max(times_array)}return summary
内存使用优化
利用NumPy的内存视图减少数据复制:
def optimize_memory_usage(large_array):# 创建共享内存视图而非复制chunks = []chunk_size = len(large_array) // 10for i in range(10):start = i * chunk_sizeend = (i + 1) * chunk_size if i < 9 else len(large_array)# 使用视图而非复制chunk = large_array[start:end].view()chunks.append(chunk)return chunks
7. 实用技巧与最佳实践
数据类型优化
合理选择NumPy和TensorFlow之间的数据类型:
# 确保NumPy和TensorFlow使用相同的数据类型以减少转换开销
x_train = x_train.astype(np.float32) # TensorFlow默认使用float32# 对于仅整数索引,使用int32而非默认的int64
indices = np.arange(1000, dtype=np.int32) # 与TensorFlow匹配
预计算和缓存优化
对不变的操作结果进行预计算:
# 预计算并缓存频繁使用的变换矩阵
def generate_transformation_matrices(n_transforms=100):# 预计算旋转矩阵angles = np.linspace(0, 360, n_transforms)rotation_matrices = []for angle in angles:theta = np.radians(angle)c, s = np.cos(theta), np.sin(theta)R = np.array([[c, -s], [s, c]], dtype=np.float32)rotation_matrices.append(R)return np.array(rotation_matrices)# 在训练前计算一次,然后重复使用
CACHED_TRANSFORMS = generate_transformation_matrices()
结论
将NumPy的高效向量化操作、内存管理和数学功能与TensorFlow结合,可以显著提升模型训练过程的效率和灵活性。关键是理解两者之间的界面,最小化数据转换开销,并利用NumPy强大的数组操作能力补充TensorFlow的功能。
成功的优化策略应该基于性能分析,针对具体瓶颈应用相应的NumPy技术,同时避免过度优化导致代码可读性和可维护性下降。通过精通NumPy和TensorFlow的协同工作方式,您可以构建既高效又灵活的深度学习训练流程。
相关文章:

利用NumPy核心知识点优化TensorFlow模型训练过程
利用NumPy核心知识点优化TensorFlow模型训练过程 NumPy是Python科学计算的基础库,掌握它的高效操作可以显著提升TensorFlow模型的训练效率。本文详细探讨如何将NumPy的核心优势应用于TensorFlow模型训练的各个环节。 1. 数据预处理优化 高效向量化操作 NumPy的向…...

初识数据结构——Java集合框架解析:List与ArrayList的完美结合
📚 Java集合框架解析:List与ArrayList的完美结合 🌟 前言:为什么我们需要List和ArrayList? 在日常开发中,我们经常需要处理一组数据。想象一下,如果你要管理一个班级的学生名单,或…...
)
TDengine 从入门到精通(2万字长文)
目录 第一章:走进 TDengine 的世界 TDengine 是个啥? TDengine 的硬核特性 性能炸裂 分布式架构,天生可扩展 SQL 用起来贼顺手 写入方式花样多 内置缓存,省心又省力 TDengine 能干啥? 智能制造 能源管理 物联网平台 工业大数据 第二章:上手 TDengine:安装与…...
)
DevOps 与持续集成(CI/CD)
1. DevOps 概述 DevOps(Development + Operations)是一种软件开发方法,强调开发(Dev)与运维(Ops)协作,通过自动化工具提高软件交付效率。其目标是: ✅ 提高部署速度 —— 频繁发布新版本 ✅ 减少人为错误 —— 通过自动化降低运维风险 ✅ 增强可观测性 —— 监控和日…...

[特殊字符] 使用 Handsontable 构建一个支持 Excel 公式计算的动态表格
在 Web 应用中,处理表格数据并提供 Excel 级的功能(如公式计算、数据导入导出)一直是个挑战。今天,我将带你使用 React Handsontable 搭建一个强大的 Excel 风格表格,支持 公式计算、Excel 文件导入导出,并…...

uniapp微信小程序引入vant组件库
1、首先要有uniapp项目,根据vant官方文档使用yarn或npm安装依赖: 1、 yarn init 或 npm init2、 # 通过 npm 安装npm i vant/weapp -S --production# 通过 yarn 安装yarn add vant/weapp --production# 安装 0.x 版本npm i vant-weapp -S --production …...

贪心进阶学习笔记
反悔贪心 贪心是指直接选择局部最优解,不需要考虑之后的影响。 而反悔贪心是在贪心上面加了一个“反悔”的操作,于是又可以撤销之前的“鲁莽行动”,让整个的选择稍微变得“理智一些”。 于是,我个人理解,反悔贪心是…...

Java 大视界 -- Java 大数据在航天遥测数据分析中的技术突破与应用(177)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

架构师面试(二十七):单链表
问题 今天的问题对于架构师来说会相对容易许多。今天出一个【数据结构与算法】相关的题目,醒醒脑。 给一张【单链表】,该单链表有100个节点元素(当然,事先我们是不知道100这个数目的),要获取倒数第8个元素…...
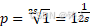
从扩展黎曼泽塔函数构造物质和时空的结构-15
回来考虑泽塔函数, 我们知道, 也就是在平面直角坐标系上反正切函数在x上的变化率,那么不难看出, 就是在s维空间上的“广义”反正切函数在单位p上的变化率,而泽塔函数,就是这些变化率的全乘积, 因…...

数据库访问工具 dbVisitor v6.0.0 发布
dbVisitor 是一款轻量小巧、功能完备的 Java 数据库 ORM 工具,它的前身是 HasorDB,历经 8 年迭代后正式更名为 dbVisitor 并开始独立发展4。以下是关于 dbVisitor v6.0.0 发布的相关信息: 发布说明 在 Maven Central 上可查询到 dbVisitor …...

01背包问题详解 具体样例模拟版
01背包 有 N 件物品和一个容量是 V 的背包。每件物品只能使用一次。 第 i 件物品的体积是 v i v_i vi,价值是 w i w_i wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。 输出最大价值。 输入格式 …...
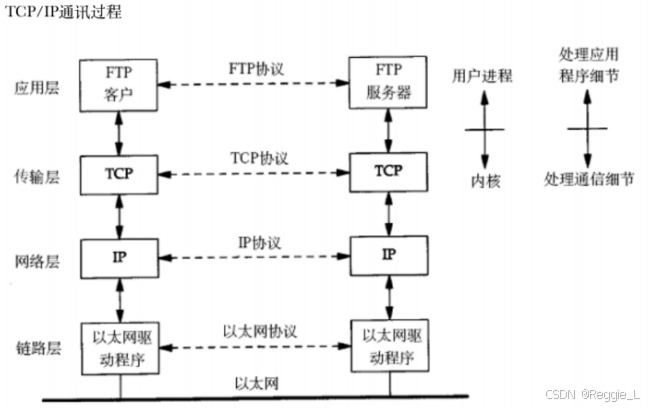
网络初识 - Java
网络发展史: 单机时代(独立模式) -> 局域网时代 -> 广域网时代 -> 移动互联网时代 网络互联:将多台计算机链接再一起,完成数据共享。 数据共享的本质是网络数据传输,即计算机之间通过网络来传输数…...

zk基础—5.Curator的使用与剖析一
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curator实现分布式Barrier 6.基于Curator实现分布式计数器 7.基于Curator实现zk的节点和子节点监听机制 8.基于Curator创…...

大模型快速 ASGI 服务器uvicorn
基础概念类 1. 什么是 Uvicorn,它的作用是什么? 答案:Uvicorn 是一个基于 Python 的快速 ASGI(异步服务器网关接口)服务器。它的主要作用是作为 Web 应用程序的服务器,负责接收客户端的请求,并…...
每日一题(小白)回溯篇4
深度优先搜索题:找到最长的路径,计算这样的路径有多少条(使用回溯) 分析题意可以得知,每次向前后左右走一步,直至走完16步就算一条走通路径。要求条件是不能超出4*4的范围,不能重复之前的路径。…...

消息队列基础概念及选型,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息
前言 是时候总结下消息队列相关知识点啦!我搓搓搓搓 本文包括消息队列基础概念介绍,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息 参考资料: Kafka常见问题总结 | JavaGuide RocketMQ常见问题总结 | JavaGuide …...

基于STM32与应变片的协作机械臂力反馈控制系统设计与实现---3.3 机械结构改装
3.3 机械臂结构改装设计与实施 一、改装需求分析 1.1 改装类型分级 改装级别涉及范围典型改动周期成本I级(小型)末端执行器工具快换装置1-3天$500-2000II级(中型)关节模块电机/减速器升级1-2周$2000-8000III级(大型)本体结构材质/拓扑优化1-3月$8000+1.2 关键参数变更评…...

k8s进阶之路:本地集群环境搭建
概述 文章将带领大家搭建一个 master 节点,两个 node 节点的 k8s 集群,容器基于 docker,k8s 版本 v1.32。 一、系统安装 安装之前请大家使用虚拟机将 ubuntu24.04 系统安装完毕,我是基于 mac m1 的系统进行安装的,所…...
)
云服务器实战:用 Nginx 搭建高性能 API 网关与反向代理服务(附完整配置流程)
在如今的 Web 系统架构中,“接口统一出口”已成为必备设计模式——无论是前后端分离、微服务架构,还是多端接入(Web、小程序、App),一个稳定、高性能、可扩展的 API 网关至关重要。 而 Nginx,作为轻量级高…...
C++ STL 详解 ——list 的深度解析与实践指南
在 C 的标准模板库(STL)中,list作为一种重要的序列式容器,以其独特的双向链表结构和丰富的操作功能,在许多编程场景下发挥着关键作用。深入理解list的特性与使用方法,能帮助开发者编写出更高效、灵活的代码…...

按键切换LCD显示后,显示总在第二阶段,而不在第一阶段的问题
这是一个密码锁的程序,当在输入密码后,原本是要重置密码,但是程序总是在输入密码正确后总是跳转置设置第二个密码,而第一个密码总是跳过。 不断修改后, 解决方法 将if语句换成switch语句,这样就可以分离程序…...
护网蓝初面试题
《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247486065&idx2&snb30ade8200e842743339d428f414475e&chksmc0e4732df793fa3bf39…...

C++11: 智能指针
C11: 智能指针 (一)智能指针原理1.RAll2.智能指针 (二)C11 智能指针1. auto_ptr2. unique_ptr3. shared_ptr4. weak_ptr (三)shared_ptr中存在的问题std::shared_ptr的循环引用 (四)删除器(五&a…...

去中心化预测市场
去中心化预测市场 核心概念 预测市场类型: 类别型市场:二元结果(YES/NO),例如“BTC在2024年突破10万美元?” 多选型市场:多个选项(如总统候选人),赔付基于…...
从零实现本地大模型RAG部署
1. RAG概念 RAG(Retrieval-Augmented Generation)即检索增强生成,是一种结合信息检索与大型语言模型(大模型)的技术。从外部知识库(如文档、数据库或网页)中实时检索相关信息,并将其…...

使用 Python 连接 PostgreSQL 数据库,从 `mimic - III` 数据库中筛选数据并导出特定的数据图表
要使用 Python 连接 PostgreSQL 数据库,从 mimic - III 数据库中筛选数据并导出特定的数据图表,你可以按照以下步骤操作: 安装所需的库:psycopg2 用于连接 PostgreSQL 数据库,pandas 用于数据处理,matplot…...

【Linux系统篇】:探索文件系统原理--硬件磁盘、文件系统与链接的“三体宇宙”
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:Linux篇–CSDN博客 文章目录 一.认识硬件--磁盘物理存储结构1.存储介质类型2.物理存储单元3…...
Tracing the thoughts of a large language model 简单理解
Tracing the thoughts of a large language model 这篇论文通过电路追踪方法(Circuit Tracing)揭示了大型语言模型Claude 3.5 Haiku的内部机制,其核心原理可归纳为以下几个方面: 1. 方法论核心:归因图与替换模型 替换模型(Replacement Model) 使用跨层转码器(CLT)将原…...
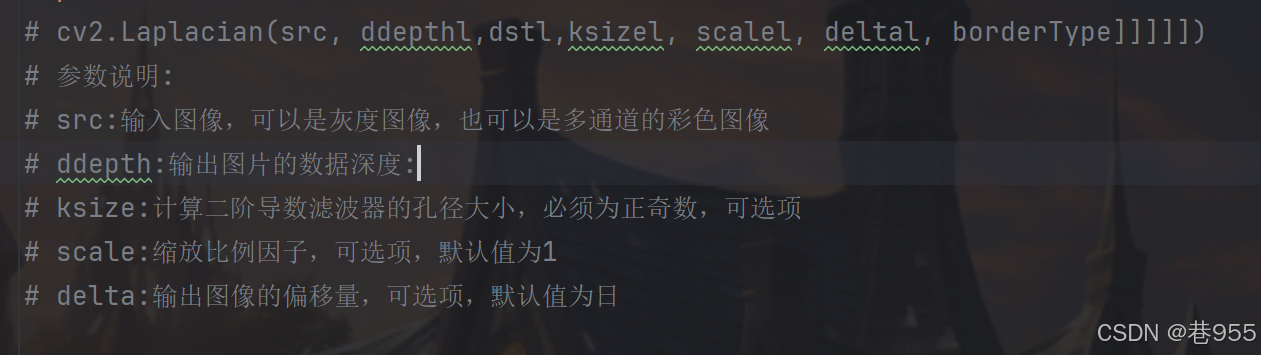
OpenCV边缘检测技术详解:原理、实现与应用
概述 边缘检测是计算机视觉和图像处理中最基本也是最重要的技术之一,它通过检测图像中亮度或颜色急剧变化的区域来识别物体的边界。边缘通常对应着场景中物体的物理边界、表面方向的变化或深度不连续处。 分类 OpenCV提供了多种边缘检测算法,下面我们介…...