深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用
- 策略学习(Policy-Based Reinforcement Learning)
- 一、策略函数
- 1.1 策略函数输出的例子
- 二、使用神经网络来近似策略函数:Policy Network ,策略网络
- 2.1 策略网络运行的例子
- 2.2需要的几个概念
- 2.3神经网络近似策略函数
- 三、策略学习的主要思想
- 3.1 目标函数的定义
- 3.2策略梯度算法
- 3.2策略梯度的推导
- 3.3策略梯度的两个公式推导
- 四、策略梯度算法的的步骤分解
- 4.1 动作空间离散的情况
- 4.2使用蒙特卡洛近似来计算策略梯度
- 步骤解释
- 4.3 总结策略梯度算法
- 五、动作价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)
- 5.1 方法一:reinforce
- 解释
- 5.2 方法二:使用神经网络近似
策略学习(Policy-Based Reinforcement Learning)
我们可以用一个神经网络来近似一个策略函数,叫做Policy Network。可以用来控制agent的动作。
一、策略函数
π ( a ∣ s ) \pi (a|s) π(a∣s),他是一个概率密度函数。
- 策略函数的输入是状态
- 输出是一个概率分布,给每个动作 a a a一个概率值
1.1 策略函数输出的例子
我们可以举一个超级玛丽的例子,把当前的状态 s s s作为输入,输出三个动作 a l e f t , r i g h t , j u m p a_{left,right,jump} aleft,right,jump的概率。是一个三维向量。
π ( l e f t ∣ s ) = 0.2 \pi(left|s) = 0.2 π(left∣s)=0.2
π ( r i g h t ∣ s ) = 0.8 \pi(right|s) = 0.8 π(right∣s)=0.8
π ( j u m p ∣ s ) = 0.7 \pi(jump|s) = 0.7 π(jump∣s)=0.7
有了概率agent会进行一次随机抽样,三个动作都会被抽到,但是概率越大,被抽到的概率越大。这里会有一个误区,认为agent只会随机抽到概率最大的动作。
二、使用神经网络来近似策略函数:Policy Network ,策略网络
和价值学习一样,我们无法直接得到策略函数,但我们可以使用深度学习中的神经网络通过不断迭代来近似得到。
π ( a ∣ s , θ ) → π ( a ∣ s ) \pi(a|s,\theta) \rightarrow \pi(a|s) π(a∣s,θ)→π(a∣s)
θ \theta θ是神经网络的参数,可以通过梯度下降来更新。
2.1 策略网络运行的例子
还是超级玛丽的游戏作为例子。
- 我们首先对游戏的画面进行采样,得到某一帧的画面作为状态 s t s_t st
- 我们对这一帧画面进行卷积、特征提取,得到一个特征向量
- 我们将这个特征向量作为输入,通过神经网络后再进行softmax得到三个动作 a l e f t , r i g h t , j u m p a_{left,right,jump} aleft,right,jump的概率。
- agent会对得到的概率进行采样,得到一个动作 a t a_t at。
2.2需要的几个概念
- 回报 U t U_t Ut(Discounted Return)
U t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ⋅ ⋅ ⋅ U_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \gamma^3 R_{t+3} +··· Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋅⋅⋅
回报依赖从 T T T时刻开始的所有的动作和所有的状态,是所有奖励的折扣和, γ \gamma γ是折扣系数。
2. 动作价值函数 Q π Q_{\pi} Qπ(Action Value Function)
Q π ( s t , a t ) = E [ U t ∣ s t , a t ] Q_{\pi}(s_t,a_t) = \mathbb{E}[U_t|s_t,a_t] Qπ(st,at)=E[Ut∣st,at]
Q π Q_{\pi} Qπ仅仅依赖当前时刻的状态和动作和策略函数 π \pi π,动作价值函数可以评价在状态 s t s_t st下,执行动作 a t a_t at的回报是多少。它可以评估动作的好坏。
3. 状态价值函数 V π V_{\pi} Vπ(State Value Function)
V π ( s t ) = E A [ Q π ( s t , A ) ] V_{\pi}(s_t) = \mathbb{E}_A[Q_{\pi(s_t,A)}] Vπ(st)=EA[Qπ(st,A)]
V π V_{\pi} Vπ是 Q π Q_{\pi} Qπ的期望, V π V_{\pi} Vπ仅仅依赖当前时刻的状态和策略函数 π \pi π,它可以评估状态的好坏。,它越大,说明当前环境的胜算越大。
如果给定状态 s t s_t st, V π ( s t ∣ A ) V_{\pi}(s_t|A) Vπ(st∣A)可以评估策略 π \pi π的好坏/
如果A是离散的变量,那么我们可以将上述的公式展开:
V π ( s t ) = ∑ a π ( a ∣ s t ) Q π ( s t , a ) V_{\pi}(s_t) = \sum_{a} \pi(a|s_t) Q_{\pi}(s_t,a) Vπ(st)=a∑π(a∣st)Qπ(st,a)
2.3神经网络近似策略函数
我们使用神经网络来近似策略函数,神经网络的输入是状态,输出是动作的概率。
V π ( s t ) = V π ( s ; θ ) = ∑ a π ( a ∣ s ; θ ) Q π ( s , a ) V_{\pi}(s_t) = V_{\pi}(s;{\theta}) = \sum_{a} \pi(a|s;{\theta}) Q_{\pi}(s,a) Vπ(st)=Vπ(s;θ)=a∑π(a∣s;θ)Qπ(s,a)
其中,{\theta}是神经网络的参数。
三、策略学习的主要思想
由状态价值函数可以知道,给定环境 s s s,我们就可以评估一个策略函数 π \pi π的好坏。 V ( s ; θ ) V(s;{\theta}) V(s;θ)的值越大,策略函数就越好,我们可以改变参数 θ \theta θ来使得 V ( s ; θ ) V(s;{\theta}) V(s;θ)的值变大。
3.1 目标函数的定义
由以上思想,我们可以定义要更新的目标函数:
J ( θ ) = E S [ V π ( s t ; θ ) ] J(\theta) = \mathbb{E}_S[V_{\pi}(s_t;{\theta})] J(θ)=ES[Vπ(st;θ)]
我们将状态 S S S作为随机变量使用期望消去,这样我们定义的目标函数就只剩下 θ {\theta} θ
J ( θ ) J(\theta) J(θ)越大,我们的策略函数就越好
3.2策略梯度算法
大概思想:
- 首先我们从环境中采样得到一个状态 s t s_t st
- 我们可以根据这个状态带入到 V ( s ; θ ) V(s;{\theta}) V(s;θ)中,计算他的梯度
- 进行梯度上升: θ = θ + β ∂ V ( s ; θ ) ∂ θ \theta = \theta + \beta \frac{\partial V(s;\theta)}{\partial \theta} θ=θ+β∂θ∂V(s;θ)
$\beta 就是学习率它是一个随机梯度,随机性来源于 就是学习率 它是一个随机梯度,随机性来源于 就是学习率它是一个随机梯度,随机性来源于s$
∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\theta)}{\partial \theta} ∂θ∂V(s;θ)被称为策略梯度。
3.2策略梯度的推导
∂ V ( s ; θ ) ∂ θ = ∂ ∑ a π ( a ∣ s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ⋅ Q π ( s , a ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \begin{split} \frac{\partial V(s;\theta)}{\partial \theta} &=\frac{ \partial {\sum_{a}\pi(a|s;\theta)}} {\partial \theta } \\ &=\sum_{a} \frac{\partial \pi(a|s;\theta) \cdot Q_{\pi}(s,a)}{\partial \theta}\\ &=\sum_{a} \frac{\partial \pi(a|s;\theta)}{\partial \theta} \cdot Q_{\pi}(s,a)\\ \end{split} ∂θ∂V(s;θ)=∂θ∂∑aπ(a∣s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
如果动作 A A A是离散的,直接带入就能把策略梯度算出来,但是实际运用中并不会直接使用这个公式,而是使用策略梯度的蒙特卡洛近似。
3.3策略梯度的两个公式推导
∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) = ∑ a π ( a ∣ s ; θ ) ⋅ ∂ log π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \begin{split} \frac{\partial V(s;\theta)}{\partial \theta} &=\sum_{a} \frac{\partial \pi(a|s;\theta)}{\partial \theta} \cdot Q_{\pi}(s,a)\\ &= \sum_a \pi(a|s;\theta) \cdot \frac{\partial \log \pi(a|s;\theta)}{\partial \theta} \cdot Q_\pi(s, a) \end{split} ∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)=a∑π(a∣s;θ)⋅∂θ∂logπ(a∣s;θ)⋅Qπ(s,a)
这一步从上往下不好推导,我们可以从下往上推导:
∂ log [ π ( θ ) ] ∂ θ = 1 π ( θ ) ⋅ ∂ π ( θ ) ∂ θ \frac{\partial \log[\pi(\theta)]}{\partial \theta} = \frac{1}{\pi(\theta)} \cdot \frac{\partial \pi(\theta)}{\partial \theta} ∂θ∂log[π(θ)]=π(θ)1⋅∂θ∂π(θ)
⇒ π ( θ ) ⋅ ∂ log [ π ( θ ) ] ∂ θ = π ( θ ) ⋅ 1 π ( θ ) ⋅ ∂ π ( θ ) ∂ θ = ∂ π ( θ ) ∂ θ \Rightarrow \pi(\theta) \cdot \frac{\partial \log[\pi(\theta)]}{\partial \theta} = \pi(\theta) \cdot \frac{1}{\pi(\theta)} \cdot \frac{\partial \pi(\theta)}{\partial \theta} = \frac{\partial \pi(\theta)}{\partial \theta} ⇒π(θ)⋅∂θ∂log[π(θ)]=π(θ)⋅π(θ)1⋅∂θ∂π(θ)=∂θ∂π(θ)
这样我们就推导
π ( θ ) ⋅ ∂ log [ π ( θ ) ] ∂ θ = ∂ π ( θ ) ∂ θ \pi(\theta) \cdot \frac{\partial \log[\pi(\theta)]}{\partial \theta} = \frac{\partial \pi(\theta)}{\partial \theta} π(θ)⋅∂θ∂log[π(θ)]=∂θ∂π(θ)
我们接第一个推导继续推导
∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) = ∑ a π ( a ∣ s ; θ ) ⋅ ∂ log π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) = E A ∼ π ( ∙ ∣ s ; θ ) [ ∂ log π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] \begin{split} \frac{\partial V(s;\theta)}{\partial \theta} &= \sum_a \frac{\partial \pi(a|s;\theta)}{\partial \theta} \cdot Q_\pi(s, a)\\ &= \sum_a \pi(a|s;\theta) \cdot \frac{\partial \log \pi(a|s;\theta)}{\partial \theta} \cdot Q_\pi(s, a)\\ &= \mathbb{E}_{A \sim \pi(\bullet|s;\theta)} \left[ \frac{\partial \log \pi(A|s;\theta)}{\partial \theta} \cdot Q_\pi(s, A) \right] \end{split} ∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)=a∑π(a∣s;θ)⋅∂θ∂logπ(a∣s;θ)⋅Qπ(s,a)=EA∼π(∙∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
实际上,下面中形式是等价的。
∂ V ( s ; θ ) ∂ θ = ∑ a ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \frac{\partial V(s;\theta)}{\partial \theta} = \sum_{a} \frac{\partial \pi(a|s;\theta)}{\partial \theta} \cdot Q_{\pi}(s,a) ∂θ∂V(s;θ)=a∑∂θ∂π(a∣s;θ)⋅Qπ(s,a)
上面的公式对离散的动作空间适用,比如我们的超级玛丽游戏,我们只有三个动作。
∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ∙ ∣ s ; θ ) [ ∂ log π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] \frac{\partial V(s;\theta)}{\partial \theta} = \mathbb{E}_{A \sim \pi(\bullet|s;\theta)} \left[ \frac{\partial \log \pi(A|s;\theta)}{\partial \theta} \cdot Q_\pi(s, A) \right] ∂θ∂V(s;θ)=EA∼π(∙∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
上面的公式对连续的动作空间使用,比如说对动作空间是零到一之间的所有实数,我们就用蒙特卡洛近似的公式。
四、策略梯度算法的的步骤分解
4.1 动作空间离散的情况
首先我们对于每一个 a ∈ A a \in \mathcal{A} a∈A都带入到策略梯度公式中,记为 f ( a , θ ) \mathbf{f}(a, \theta) f(a,θ)
f ( a , θ ) = ∂ π ( a ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ) \mathbf{f}(a, \theta) = \frac{\partial \pi(a|s;\theta)}{\partial \theta} \cdot Q_\pi(s, a) f(a,θ)=∂θ∂π(a∣s;θ)⋅Qπ(s,a)
计算出每个离散值的 f ( a , θ ) \mathbf{f}(a, \theta) f(a,θ),我们可以将他们累加起来,得到策略梯度公式
∂ V ( s ; θ ) ∂ θ = f ( "left" , θ ) + f ( "right" , θ ) + f ( "up" , θ ) \frac{\partial V(s;\theta)}{\partial \theta} = \mathbf{f}(\text{"left"}, \theta) + \mathbf{f}(\text{"right"}, \theta) + \mathbf{f}(\text{"up"}, \theta) ∂θ∂V(s;θ)=f("left",θ)+f("right",θ)+f("up",θ)
但是如果动作空间是连续的,那么将会由无穷多个动作,这时在进行累加就比较困难,如果我们选择积分的话,由于策略函数是一个神经网络,那么我们无法直接计算出策略梯度,所以我们需要使用蒙特卡洛方法来计算。
4.2使用蒙特卡洛近似来计算策略梯度
蒙特卡洛方法的基本思想是通过大量随机抽样来近似期望值。对于强化学习中的价值函数估计,蒙特卡洛方法通过多次抽样,用随机样本来近似期望来更新模型。
公式 2:
∂ V ( s ; θ ) ∂ θ = E A ∼ π ( ⋅ ∣ s ; θ ) [ ∂ log π ( A ∣ s ; θ ) ∂ θ ⋅ Q π ( s , A ) ] \frac{\partial V(s;\theta)}{\partial \theta} = \mathbb{E}_{A \sim \pi(\cdot|s;\theta)} \left[ \frac{\partial \log \pi(A|s;\theta)}{\partial \theta} \cdot Q_\pi(s, A) \right] ∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)]
这个公式表示状态价值函数 V ( s ; θ ) V(s;\theta) V(s;θ) 关于参数 θ \theta θ 的梯度可以通过期望来计算。期望是在动作 A A A 根据策略 π ( ⋅ ∣ s ; θ ) \pi(\cdot|s;\theta) π(⋅∣s;θ) 采样的情况下计算的,其中 Q π ( s , A ) Q_\pi(s, A) Qπ(s,A) 是在状态 s s s 下采取动作 A A A 的期望回报。
步骤解释
-
随机采样动作:
- 根据概率密度函数 π ( ⋅ ∣ s ; θ ) \pi(\cdot|s;\theta) π(⋅∣s;θ) 随机采样一个动作 a ^ \hat{a} a^。这意味着从策略定义的动作分布中抽取一个动作。
-
计算 g ( a ^ , θ ) g(\hat{a}, \theta) g(a^,θ):
- 计算 g ( a ^ , θ ) = ∂ log π ( a ^ ∣ s ; θ ) ∂ θ ⋅ Q π ( s , a ^ ) g(\hat{a}, \theta) = \frac{\partial \log \pi(\hat{a}|s;\theta)}{\partial \theta} \cdot Q_\pi(s, \hat{a}) g(a^,θ)=∂θ∂logπ(a^∣s;θ)⋅Qπ(s,a^)。这里, ∂ log π ( a ^ ∣ s ; θ ) ∂ θ \frac{\partial \log \pi(\hat{a}|s;\theta)}{\partial \theta} ∂θ∂logπ(a^∣s;θ) 是策略的对数关于参数 θ \theta θ 的梯度, Q π ( s , a ^ ) Q_\pi(s, \hat{a}) Qπ(s,a^) 是在状态 s s s 下采取动作 a ^ \hat{a} a^ 的期望回报。
-
使用 g ( a ^ , θ ) g(\hat{a}, \theta) g(a^,θ) 作为策略梯度的近似:
- 使用 g ( a ^ , θ ) g(\hat{a}, \theta) g(a^,θ) 作为策略梯度 ∂ V ( s ; θ ) ∂ θ \frac{\partial V(s;\theta)}{\partial \theta} ∂θ∂V(s;θ) 的近似。这意味着通过单个动作的采样和计算得到的 g ( a ^ , θ ) g(\hat{a}, \theta) g(a^,θ) 可以用来估计整个策略梯度。
这种方法对于离散的也是适用的。
4.3 总结策略梯度算法
-
观察状态 s t s_t st:
- 在时间步 t t t,观察或接收环境的当前状态 s t s_t st。
-
根据策略 π ( ⋅ ∣ s t ; θ t ) \pi(\cdot | s_t; \theta_t) π(⋅∣st;θt) 随机采样动作 a t a_t at:
- 根据当前策略 π \pi π(由参数 θ t \theta_t θt 定义)在状态 s t s_t st 下的概率分布,随机选择一个动作 a t a_t at。
-
计算 q t ≈ Q π ( s t , a t ) q_t \approx Q_\pi(s_t, a_t) qt≈Qπ(st,at)(某种估计):
- 计算或估计在状态 s t s_t st 下采取动作 a t a_t at 的期望回报 Q π ( s t , a t ) Q_\pi(s_t, a_t) Qπ(st,at)。这里 q t q_t qt 是这个期望回报的估计值。
-
对策略网络求导:
- 计算策略网络关于参数 θ \theta θ 的梯度 d θ , t d_{\theta,t} dθ,t,即 ∂ log π ( a t ∣ s t , θ ) ∂ θ \frac{\partial \log \pi(a_t | s_t, \theta)}{\partial \theta} ∂θ∂logπ(at∣st,θ) 在 θ = θ t \theta = \theta_t θ=θt 时的值。这个梯度表示策略参数如何影响选择特定动作 a t a_t at 的概率。
-
(近似)策略梯度:
- 计算策略梯度的近似值 g ( a t , θ t ) = q t ⋅ d θ , t g(a_t, \theta_t) = q_t \cdot d_{\theta,t} g(at,θt)=qt⋅dθ,t。这里, q t q_t qt 是步骤3中计算的期望回报的估计值, d θ , t d_{\theta,t} dθ,t 是步骤4中计算的梯度。
-
更新策略网络:
- 使用梯度上升方法更新策略网络的参数 θ \theta θ。更新公式为 θ t + 1 = θ t + β ⋅ g ( a t , θ t ) \theta_{t+1} = \theta_t + \beta \cdot g(a_t, \theta_t) θt+1=θt+β⋅g(at,θt),其中 β \beta β 是学习率,控制更新步长的大小。
五、动作价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)
其实我们一直没有说明动作价值函数 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at)是什么,该如何得到。
我们并不知道 Q π ( s t , a t ) Q_{\pi}(s_t,a_t) Qπ(st,at),并没有办法计算这个函数值,但是我们可以近似得到这个函数的值 q t ≈ Q π ( s t , a t ) q_t \approx Q_\pi(s_t, a_t) qt≈Qπ(st,at),我们有两个方法来近似 q t q_t qt
5.1 方法一:reinforce
REINFORCE算法的核心思想是通过采样来估计策略梯度,并使用这个估计值来更新策略参数。
-
生成轨迹:
- 玩完一局游戏并生成轨迹: s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … , s T , a T , r T s_1, a_1, r_1, s_2, a_2, r_2, \ldots, s_T, a_T, r_T s1,a1,r1,s2,a2,r2,…,sT,aT,rT。这里, s t s_t st 是时间步 t t t 的状态, a t a_t at 是时间步 t t t 的动作, r t r_t rt 是时间步 t t t 的奖励, T T T 是游戏的总时间步数。
-
计算折扣回报:
- 计算折扣回报 u t = ∑ k = t T γ k − t r k u_t = \sum_{k=t}^T \gamma^{k-t} r_k ut=∑k=tTγk−trk,对于所有 t t t。这里, γ \gamma γ 是折扣因子,用于权衡未来奖励的重要性。
-
近似动作价值函数:
- 由于 Q π ( s t , a t ) = E [ U t ] Q_\pi(s_t, a_t) = \mathbb{E}[U_t] Qπ(st,at)=E[Ut],我们可以使用 u t u_t ut 来近似 Q π ( s t , a t ) Q_\pi(s_t, a_t) Qπ(st,at)。即 q t = u t q_t = u_t qt=ut。
解释
- 轨迹生成:通过与环境交互生成完整的轨迹,记录每个时间步的状态、动作和奖励。
- 折扣回报:计算从当前时间步 t t t 到游戏结束的所有未来奖励的加权和,权重由折扣因子 γ \gamma γ 决定。
- 近似动作价值:使用折扣回报 u t u_t ut 作为动作价值函数 Q π ( s t , a t ) Q_\pi(s_t, a_t) Qπ(st,at) 的估计值 q t q_t qt。
这种方法的优点是简单且易于实现,但可能存在高方差的问题,因为折扣回报 u t u_t ut 可能对单个样本的波动非常敏感。为了降低方差,可以使用基线方法或优势函数等技术进行改进。
5.2 方法二:使用神经网络近似
这个方法比较复杂,我会放到下一期进行讲解。
相关文章:

深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用 策略学习(Policy-Based Reinforcement Learning)一、策略函数1.1 策略函数输出的例子 二、使用神经网络来近似策略函数:Policy Network ,策略网络2.1 策略网络运行的例子2.2需要的几个概念2.3神经网络近似…...
ModuleNotFoundError: No module named ‘pandas‘
在使用Python绘制散点图表的时候,运行程序报错,如图: 报错显示Python 环境中可能没有安装 pandas 库,执行pip list命令查看,果然没有安装pandas 库,如图: 执行命令:python -m pip in…...

配环境的经验
pip install -e . 该命令用于以“编辑模式”(也称为开发模式)安装当前目录下的 Python 包,比如包含有 setup.py、setup.cfg 或 pyproject.toml 文件的项目-e 是 --editable 的简写。以编辑模式安装时,pip 会在你的 Python 环境中创…...

解决 Kubernetes 中容器 `CrashLoopBackOff` 问题的实战经验
在 Kubernetes 集群中,容器状态为 CrashLoopBackOff 通常意味着容器启动失败,并且 Kubernetes 正在不断尝试重启它。这种状态表明容器内可能存在严重错误,如应用异常、依赖服务不可用、配置错误等。本文将分享一次实际排障过程,并…...

hive/doris查询表的创建和更新时间
hive查询表的创建和更新时间: SELECT d.NAME AS database_name, t.TBL_NAME AS table_name, FROM_UNIXTIME(t.CREATE_TIME) AS create_time, FROM_UNIXTIME(tp.PARAM_VALUE) AS last_ddl_time FROM metastore.TBLS t JOIN metastore.DBS d ON t.DB_ID d.DB_ID JOIN…...

springboot中使用async实现异步编程
目录 1.说明 2.实现原理 3.示例 4.总结 1.说明 Async 是 Spring 框架提供的一个注解,用于标记方法为异步执行。被标记的方法将在调用时立即返回,而实际的方法执行将在单独的线程中进行。 Async 注解有一个可选属性:指定要使用的特定线程…...

【教程】MacBook 安装 VSCode 并连接远程服务器
目录 需求步骤问题处理 需求 在 Mac 上安装 VSCode,并连接跳板机和服务器。 步骤 Step1:从VSCode官网(https://code.visualstudio.com/download)下载安装包: Step2:下载完成之后,直接双击就能…...

初识 Three.js:开启你的 Web 3D 世界 ✨
3D 技术已经不再是游戏引擎的专属,随着浏览器技术的发展,我们完全可以在网页上实现令人惊艳的 3D 效果。而 Three.js,作为 WebGL 的封装库,让 Web 3D 的大门向更多开发者敞开了。 这是我开启这个 Three.js 专栏的第一篇文章&…...

基于大模型的病态窦房结综合征预测及治疗方案研究报告
目录 一、引言 1.1 研究背景与目的 1.2 研究意义 二、病态窦房结综合征概述 2.1 定义与病因 2.2 临床表现与分型 2.3 诊断方法 三、大模型在病态窦房结综合征预测中的应用 3.1 大模型介绍 3.2 数据收集与预处理 3.3 模型训练与优化 四、术前预测与准备 4.1 风险预…...

在 Ubuntu 下通过 Docker 部署 PSQL 服务器的详细技术博客
今天,需要部署一个密码管理器,突然要用到PSQL的服务器,所以就把部署的过程记录下来。 鉴于最近囊中羞涩,故此次部署实验使用三丰云的免费服务器配置,配置是为1 核 CPU、1G 内存和 5M 带宽,足够了。 以下是…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Account Kit(3)
1.问题描述: PC场景,青少年模式系统API不支持吗? 解决方案: PC场景,青少年模式系统API不支持,另外文档上的几个API也不支持。 2.问题描述: 华为一键登录 Beta7本地运行到手机可以拿到匿名手…...

地图与图层操作
地图文档本质上就是存储在磁盘上的地图,包括地理数据、图名、图例等一系列要素,当完成地图制作、图层要素标注及符号显示设置后,可以将其作为图层文件保存到磁盘中,在一个图层文件中,包括了定义如何在地图上描述地理数…...

starrocks split函数和trino split函数差异性
在trino419和starrocks3.2.8中分别执行下面这两条sql,出来的结果是不一样的 select split(,,,)[1] as t1 select coalesce(split(,,&#...
_33)
LeetCode算法题(Go语言实现)_33
题目 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 一、代码实现 func maxDepth(root *TreeNode) int {// 递归法(后序遍历)if root nil {return 0}leftDepth : maxDepth(r…...

go程序启动工具——cobra
以下是将“为什么很多 Go 程序启动都是用 Cobra”的内容转换为 Markdown 格式的文档: 为什么很多 Go 程序启动都是用 Cobra 在 Go 编程生态中,Cobra 是一个非常流行的命令行工具库,许多 Go 程序选择使用它来构建启动逻辑和命令行接口&#…...

Unet网络的Pytorch实现和matlab实现
文章目录 一、Unet网络简介1.1 输入图像1.2 编码器部分(Contracting Path)1.3 解码器部分(Expanding Path)1.4 最后一层(输出)1.5 跳跃连接(Skip Connections) 二、Unet网络的Pytorc…...
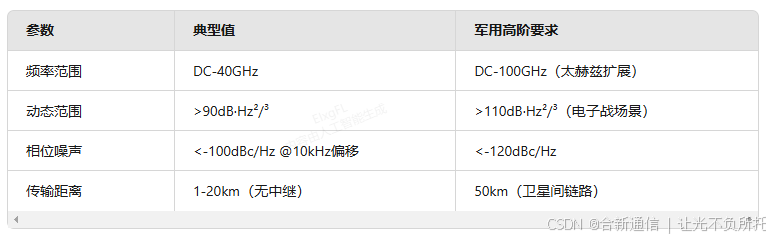
【合新通信】相控阵雷达RFoF方案的应用
一、相控阵雷达为何需要RFoF? 核心需求驱动 分布式部署:相控阵雷达(AESA/PESA)的T/R模块需分散布局(如舰载雷达阵面、卫星载荷),传统同轴电缆导致重量和损耗剧增。高频段挑战:X/Ku/…...

关于点卷积
🧠 什么是点卷积? 点卷积(Pointwise Convolution) 是一种特殊类型的卷积操作,其基本特点是卷积核的大小为 1 1 1 \times 1 11。与传统的卷积操作(如 3 3 3 \times 3 33 或 5 5 5 \times 5 55 卷积核…...
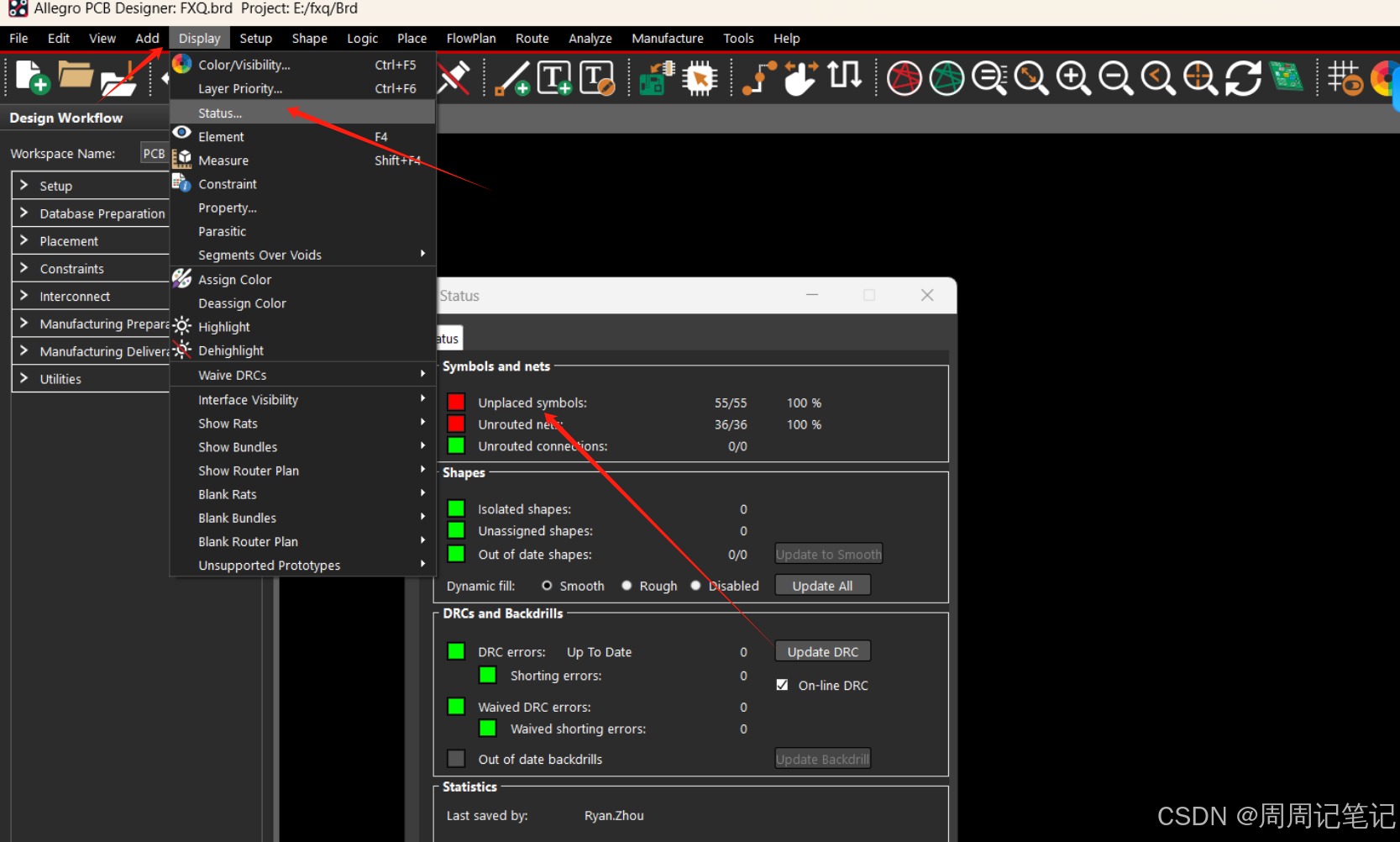
原理图输出网表及调入
一、输出网表操作步骤 (1)选中.dsn文件,选者N或进入tools下拉列表选择Creat Netlists (2)导出网表后的文件 二、网表的导入 (1)执行菜单命令“File-Import-Logic/netlist”,将原理…...

python基础12 模块/库的引用
在软件的设计中,经常提及到解耦的概念,即模块和模块之间的功能尽可能独立,减少不必要的关联。所以在实际项目中,我们经常会将一个工程拆解成很多不同的功能模块,以实现更优的设计并满足团队开发的要求。 有了模块的概…...

TDengine JAVA 语言连接器
简介 本节简介 TDengine 最重要且使用最多的连接器, 本节内容是以教科书式方式列出对外提供的接口及功能及使用过程中要注意的技术细节,大家可以收藏起来做为今后开发 TDengine 的参考资料。 taos-jdbcdriver 是 TDengine 的官方 Java 语言连接器,Java…...

【NLP 55、实践 ⑬ LoRA完成NER任务】
目录 一、数据文件 二、模型配置文件 config.py 三、数据加载文件 loader.py 1.导入文件和类的定义 2.初始化 3.数据加载方法 代码运行流程 4.文本编码 / 解码方法 ① encode_sentence(): ② decode(): 代码运行流程 ③ padding(): 代码…...
【蓝桥杯】Python大学A组第十五届省赛
1.填空题 1.1.拼正方形 问题描述 小蓝正在玩拼图游戏,他有个的方块和个的方块,他需要从中挑出一些来拼出一个正方形。 比如用个和个的方块可以拼出一个的正方形;用个的方块可以拼出一个的正方形。 请问小蓝能拼成的最大的正方形的边长为多少。 import math # 2*2的个数 a =…...

小球反弹(蓝桥杯C语言)
有一长方形,长为 343720343720 单位长度,宽为 233333233333 单位长度。在其内部左上角顶点有一小球 (无视其体积),其初速度如图所示且保持运动速率不变,分解到长宽两个方向上的速率之比为 dx:dy15:17dx:dy15:17。小球碰到长方形的…...

Redis底层数据结构?编码与底层数据结构的映射?
Redis底层数据结构 一、简单动态字符串(SDS) 结构: struct sdshdr {int len; // 已使用字节长度 int free; // 未使用字节长度 char buf[]; // 字节数组(兼容C字符串) };特点: 二进制安全&#…...

linux环境下的硬盘分区格式化工具介绍 fdisk,gdisk,parted,cfdisk,cgdisk,sfdisk,gparted 笔记250407
linux环境下的硬盘分区格式化工具介绍 fdisk,gdisk,parted,cfdisk,cgdisk,sfdisk,gparted 笔记250407 以下是 Linux 系统中常用的 硬盘分区与格式化工具,涵盖命令行和图形界面工具,按功能分类整理: 一、分区管理工具 1. 命令行工具 工具功能…...

HarmonyOS-ArkUI Ability进阶系列-UIAbility与各类Context
UIAbility及相关类关系 一个模块编译的时候会出一个HAP包, 每一个HAP包在运行时都对应一个AbilityStage。 AbilityStage持有一个AbilityStageContext一个APP, 有时候会有很多个HAP包, 至少一个。 一个APP运行时,对应的是我们的App…...

前端入门之CSS
CSS: HTML负责定义页面结构;JS负责处理页面逻辑和点击事件;CSS负责用于描述 HTML 元素的显示方式,通过 CSS 可以控制颜色、字体、布局等。 核心语法: 选择器: 类选择器主要用于选中需要添加样式的 HTML 元素。主要分为:类选择器(.class-name { ... })、标签选择器(…...

JavaScript逆向WebSocket协议解析与动态数据抓取
在JavaScript逆向工程中,WebSocket协议的解析和动态数据抓取是关键技能。本文将结合Fiddler、Charles Proxy和APIfox工具,详细讲解如何解析WebSocket协议并抓取动态数据。 一、WebSocket协议解析 (一)WebSocket协议的基本概念 …...

剑指Offer(数据结构与算法面试题精讲)C++版——day4
剑指Offer(数据结构与算法面试题精讲)C版——day4 题目一:和为k的子数组题目二:0和1个数相同的子数组题目三:左右两边子数组的和相等 题目一:和为k的子数组 结合前面着重阐述的双指针法这一经典的算法技巧&…...