【数据结构】图论存储革新:十字链表双链设计高效解决有向图入度查询难题
十字链表
- 导读
- 一、邻接表的优缺点
- 二、十字链表
- 2.1 结点结构
- 2.2 原理解释
- 2.2.1 顶点表
- 2.2.2 边结点
- 2.2.3 十字链表
- 三、存储结构
- 四、算法评价
- 4.1 时间复杂度
- 4.2 空间复杂度
- 五、优势与劣势
- 5.1 优势
- 5.2 劣势
- 5.3 特点
- 结语

导读
大家好,很高兴又和大家见面啦!!!
在图的链式存储探索中,我们曾解析邻接表的灵活性与局限——它虽以链表动态管理边集,却难解有向图入度查询的效率困局。
如何让存储结构在空间与时间上实现双重突破?
本文将聚焦一种革新设计——十字链表,它通过顶点表双向关联出边与入边,以共享边节点的巧思,实现出入度的高效统管。
从结构定义到代码落地,层层拆解这一“双向链表”如何为有向图赋予全新生命力!
一、邻接表的优缺点
邻接表作为图的链式存储结构,通过顺序存储的顶点表能够快速的访问各个顶点的信息,通过链式存储的边表,能够动态的对边集进行增加与删除操作;
相比于邻接矩阵的利用空间换时间,邻接表通过链表存储边的信息,大大降低了空间的消耗。
顶点表中的每个结点都可以通过边表头指针域来管理边的信息。对于有向图而言,邻接表则是能够通过出边表快速获取顶点的出度信息;
但是,在有向图中,除了出度还有入度。当我们需要获取一个顶点x的入度信息时,我们只能够消耗大量的时间遍历整个邻接表,通过判断其他顶点的出边表中是否存在弧头尾为x的结点,以此来获取顶点x的入度信息。
如果说我们能够在顶点表中同时管理出度和入度的信息,那么邻接表的这个短板是不是就被解决了呢?
通过顶点表同时管理出度与入度信息的数据结构就是我们今天要介绍的十字链表;
二、十字链表
十字链表(Orthogonal List)是有向图的一种链式存储结构,它的是实现与邻接表一样,通过顺序表存储顶点信息,通过链表存储弧的信息。
2.1 结点结构
在十字链表中,存储顶点信息的顺序表我们同样将其称之为顶点表。与邻接表不同的是,十字链表顶点表不仅能够管理结点的出度,还能够管理结点的入度。
十字链表中的顶点表的各个顶点结点有3个域:
- data域:用于存放顶点数据信息
- firstin域:指向以该顶点为弧头的第一条弧(入度)
- firstout域:指向以该顶点为弧尾的第一条弧(出度)
在十字链表中,管理边的链表有两个:
- 出边链表(邻接表):用于存放顶点的出边信息
- 入边链表(逆邻接表):用于存放顶点的入度信息
链表中的每一个结点都由五部分组成:
- tailvex域:存放弧尾的顶点编号
- headvex域:存放弧头的顶点编号
- hlink域:存放弧头相同的下一条弧
- tlink域:存放弧尾相同的下一条弧
- info域:存放该弧的相关信息

十字链表的图看上去似乎密密麻麻的箭头,无法正确的辨别到底谁是谁。接下来我们就来理解以下十字链表的原理;
2.2 原理解释
2.2.1 顶点表
十字链表通过顶点表存储顶点信息并且管理出边表和入边表。
- 出边表就是邻接表:以该顶点为弧尾,其它顶点为弧头的弧对应的边结点所组成的链表
- 如弧 < a , b > <a, b> <a,b>就是顶点a的邻接表中的边结点
- 我们可以通过指向出边表的指针
firstout找到以该顶点为弧尾的所有弧;
- 入边表就是逆邻接表:以其它顶点为弧尾,该顶点为弧头的弧对应的边结点所组成的链表
- 如弧 < a , b > <a, b> <a,b> 就是顶点b的逆邻接表中的边结点
- 我们可以通过指向入边表的指针
firstin找到以该顶点为弧头的所有弧;
2.2.2 边结点
在十字链表中,出边表和入边表中的结点是共用的,也就是说同一个结点会同时存在于两个边表中,因此我们这里主要分析边结点的作用;
在边结点中,通过弧尾顶点域和弧头顶点与存储对应顶点的编号信息:
tailvex: 记录弧尾的编号信息;headvex: 记录弧头的编号信息;
通过记录的编号信息,我们就可以在顶点表中找到该顶点的信息,这样我们就能够确定当前边结点所对应的弧;
边结点中的头链域hlink所指向的是由所有弧中弧头结点相同的弧对应的边结点所组成的链表;
这里比较绕,我们通过图示来理解:
在上示的有向图中,有4条弧 E = { < a , b > , < b , c > , < c , b > , < d , c > } E = \{<a, b>, <b, c>, <c, b>, <d, c>\} E={<a,b>,<b,c>,<c,b>,<d,c>},如果我们将弧头相同的弧放入一个链表中,那么我们就可以得到两个头链表:
- < a , b > , < c , b > <a, b>, <c, b> <a,b>,<c,b> 这两条弧的弧头相同,都是以顶点 b b b 为弧头,因此这两条弧对应的边结点在同一个头链表中;
- < b , c > , < d , c > <b, c>, <d, c> <b,c>,<d,c> 这两条弧的弧头相同,都是以顶点 c c c 为弧头,因此这两条弧对应的边结点在同一个头链表中;
同理,尾链域tlink所指向的是由所有弧中弧尾结点相同的弧对应的边结点所组成的链表;
边结点中的信息域info存储的是该结点对应的弧的信息,比如该弧的权值。
因此如果我们是通过十字链表存储一张有向网,那么我们就需要通过该域记录每条弧的权值;
若我们存储的是普通的有向图,我们是可以省略info域的。
2.2.3 十字链表
十字链表是由顶点表和所有的边结点相互关联所形成的一张交叉链表:
- 顶点表中将各顶点分为两个链表:
- 出边表:由该顶点为弧尾的边结点组成的链表
- 入边表:由该顶点为弧头的边结点组成的链表
- 边结点又通过头链域和尾链域自动分成了两个链表:
- 头链表:由弧头编号相同的顶点所组成的链表
- 尾链表:由弧尾编号相同的顶点所组成的链表
十字链表中的所有边结点不管是按照出入边的方式进行分类还是按照弧头弧尾的方式进行分类,同一个结点一定会同时归属于两个链表中,这里我们以弧 < a , b > <a, b> <a,b> 为例:
- 按出边与入边的方式分类:
- < a , b > → 结点 b 的入边 ↓ 结点 a 的出边 <a, b> → 结点b的入边 \\ \hspace{1em}\downarrow \\结点a的出边 <a,b>→结点b的入边↓结点a的出边
- 按照弧头弧尾的方式进行分类:
- < a , b > → 以结点 b 为弧头 ↓ 以结点 a 为弧尾 <a, b> → 以结点b为弧头\\ \hspace{1em}\downarrow \\以结点a为弧尾 <a,b>→以结点b为弧头↓以结点a为弧尾
可以看到,不管是那种分类方式,对于弧 < a , b > <a, b> <a,b> 而言,它都是同时存在于两个链表中,并且这两个链表我们可以认为其在逻辑上十字相交。

右上角的出边表与入边表组成的链表矩阵中,我们可以看到每一个结点所处的位置正好是对应两个链表的十字交点,因此这种存储结构称为十字链表。
三、存储结构
十字链表的存储结构与邻接表一样,都是需要定义两种结点类型;
与邻接表不同的是两种结点的结构上有所区别:
#define MAXSIZE 5
typedef char VexType;
typedef int ArcType;
//边结点
typedef struct ArcNode {int tailvex; // 弧尾顶点编号int headvex; // 弧头顶点编号struct ArcNode* hlink; // 头链表指针struct ArcNode* tlink; // 尾链表指针ArcType info; // 边信息(权值),可以省略
}ArcNode;
//顶点结点
typedef struct VexNode {VexType data; // 顶点信息ArcNode* firstin; // 入边表(逆邻接表)ArcNode* firstout; // 出边表(邻接表)
}VexNode;
//十字链表
typedef struct Orthogonal_List {VexNode vex_list[MAXSIZE]; // 顶点表int vex_num; // 当前顶点数两int arc_num; // 当前弧的数量
}OLGraph;
整个结构的定义并不困哪,我们只需要在邻接表的基础上稍作修改即可,这里就不再展开;
这里需要注意,如果当前的有向图就是一张普通的有向图,那么我们就可以在边结点中省去信息域info;
在顶点表中,我们也可以通过增加两个变量分别记录该顶点的出度与入度,这个就看个人习惯了。
四、算法评价
对十字链表的算法评价我们同样以十字链表的遍历进行评价;
4.1 时间复杂度
当我们对一个十字链表进行遍历时,实际上就是在遍历顶点表的基础上,分别对每个顶点的邻接表和逆邻接表进行遍历;
对于有向图,所有顶点的入度之和、出度之和与边的总数满足以下关系:
∑ v ∈ V deg − ( v ) = ∑ v ∈ V deg + ( v ) = ∣ E ∣ \sum_{v \in V} \deg^{-}(v) = \sum_{v \in V} \deg^{+}(v) = |E| v∈V∑deg−(v)=v∈V∑deg+(v)=∣E∣
其中
- deg − ( v ) \deg^{-}(v) deg−(v):顶点 v v v 的入度(指向 v v v 的边数)。
- deg + ( v ) \deg^{+}(v) deg+(v):顶点 v v v 的出度(从 v v v 出发的边数)。
- ∣ E ∣ |E| ∣E∣:图的边的总数。
因此当我们要遍历整个有向图时,我们只需要遍历顶点以及所有顶点的入度或者所有顶点的出度即可,对应的时间复杂度为: T ( N ) = O ( ∣ V ∣ + ∣ E ∣ ) T(N) = O(|V| + |E|) T(N)=O(∣V∣+∣E∣)
4.2 空间复杂度
在十字链表中,我们只需要给每个顶点申请一个结点空间,给每条弧申请一个结点空间即可,因此其所对应的空间复杂度应该是: T ( N ) = O ( ∣ V ∣ + ∣ E ∣ ) T(N) = O(|V| + |E|) T(N)=O(∣V∣+∣E∣)
五、优势与劣势
5.1 优势
在十字链表中,因为我们通过顶点表同时管理了一个结点的出度与入度,因此相比于邻接表,十字链表大大提高了查找顶点入度的效率;
在十字链表中,出边表和入边表共享着所有的边结点,避免了管理出边表与入边表时的双重存储,大大节省了内存空间
由于十字链表在存储边结点时采用的是链表的形式,因此支持动态的弧的插入与删除;
当我们遇到需要同时处理出入与入度的问题时,我们就可以通过十字链表来快速实现;
5.2 劣势
十字链表的存储对象被限制在了有向图,该数据结构能且仅能存储有向图,无法实现无向图的存储;
由于十字链表需要同时管理结点的出度与入度,因此我们在实现的过程中,其代码量会十分的庞大;
5.3 特点
十字链表相当于将邻接表中无法管理入度的不足以及邻接矩阵中空间消耗过大的不足同时完善了,因此十字链表十分适合进行有向稀疏图的存储;
十字链表与邻接表一样,因为对有向边采用的是链表进行的存储,因此一张图所对应的十字链表并不是唯一的,但是一个十字链表表示的一定是一张确定的有向图;
结语
十字链表以顶点表为枢纽,通过出边与入边链表的交叉绑定,攻克了邻接表处理有向图入度的效率短板。其“一节点双归属”的设计,既保留了链表的动态扩展性,又避免了邻接矩阵的空间冗余,成为稀疏有向图的优选方案。
无向图中一条边需被两个顶点共享,如何避免重复存储?下一篇将揭秘邻接多重表的精妙设计,看它如何以“边节点共享”破局!
🔍 本文是否让你对链式存储的迭代有了新认知?点赞❤️支持原创深度解析!
📁 收藏随时回溯技术细节,转发🔗与团队探讨方案优化。
💬 评论区畅聊你的存储设计心得,或抛出疑惑共同探讨!
🔔 关注不迷路,下篇《邻接多重表:无向图存储的优雅解法》即将上线!
🚀 你的每一次互动,都是技术深水区探索的助力!
相关文章:
【数据结构】图论存储革新:十字链表双链设计高效解决有向图入度查询难题
十字链表 导读一、邻接表的优缺点二、十字链表2.1 结点结构2.2 原理解释2.2.1 顶点表2.2.2 边结点2.2.3 十字链表 三、存储结构四、算法评价4.1 时间复杂度4.2 空间复杂度 五、优势与劣势5.1 优势5.2 劣势5.3 特点 结语 导读 大家好,很高兴又和大家见面啦ÿ…...

聊一聊没有接口文档时如何开展测试
目录 一、前期准备与信息收集 二、使用抓包工具分析接口 三、逆向工程构造测试用例 四、安全测试 五、 模糊测试(Fuzz Testing) 六、记录并维护发现的接口信息 七、 推动团队规范流程 其它注意事项 在我们进行接口测试时,总会遇到各种…...
.net6 中实现邮件发送
一、开启邮箱服务 先要开启邮箱的 SMTP 服务,获取授权码,在实现代码发送邮件中充当邮箱密码用。 在邮箱的 设置 > 账号 > POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务中,把 SMTP 服务开启,获取授权码。 二、安装库 安装 …...

vector复制耗时
CPP中的vector对象在传参给子函数时,如果直接传参,会造成复制给形参的额外耗时 如何解决这个问题呢? 这样定义局部函数 const vector <int>&vec可以保证传递vector对象时使用地址传递,并且使用const保证vector不被改变…...

MySQL 数据库操作指南:从数据库创建到数据操作
关键词:MySQL;数据库操作;DDL;DML 一、引言 MySQL 作为广泛应用的关系型数据库管理系统,对于开发人员和数据库管理员而言,熟练掌握其操作至关重要。本文章通过一系列 SQL 示例,详细阐述 MySQL…...
【Linux】命令和权限
目录: 一、shell命令及运行原理 (一)什么是外壳 (二)为什么要有外壳 (三)外壳怎么工作的 二、Linux权限的概念 (一)Linux的文件类型 (二)L…...

22.OpenCV轮廓匹配原理介绍与使用
OpenCV轮廓匹配原理介绍与使用 1. 轮廓匹配的基本概念 轮廓匹配(Contour Matching)是计算机视觉中的一种重要方法,主要用于比较两个轮廓的相似性。它广泛应用于目标识别、形状分析、手势识别等领域。 在 OpenCV 中,轮廓匹配主要…...

深入解析AI绘画技术背后的人工智能
在当今数字艺术领域,AI绘画作为一种新兴艺术形式,正迅速吸引着越来越多的创作者与爱好者。它不仅推动了艺术创作的边界,同时也改变了我们对创作与美的理解。本文将深入探讨AI绘画所依赖的人工智能技术,并分析其背后的原理与应用。…...

Kaggle房价预测
实战 Kaggle 比赛:预测房价 这里李沐老师讲的比较的细致,我根据提供的代码汇总了一下: import hashlib import os import tarfile import zipfile import requests import numpy as np import pandas as pd import torch from matplotlib i…...

browser-use开源程序使 AI 代理可以访问网站,自动完成特定的指定任务,告诉您的计算机该做什么,它就会完成它。
一、软件介绍 文末提供程序和源码下载 browser-use开源程序使 AI 代理可以访问网站,自动完成特定的指定任务,浏览器使用是将AI代理与浏览器连接的最简单方法。告诉您的计算机该做什么,它就会完成它。 二、快速开始 使用 pip (Py…...

java虚拟机---JVM
JVM JVM,也就是 Java 虚拟机,它最主要的作用就是对编译后的 Java 字节码文件逐行解释,翻译成机器码指令,并交给对应的操作系统去执行。 JVM 的其他特性有: JVM 可以自动管理内存,通过垃圾回收器回收不再…...
2025数字中国初赛wp
一,取证与溯源 镜像文件解压密码:44216bed0e6960fa 1.运维人员误删除了一个重要的word文件,请通过数据恢复手段恢复该文件,文件内容即为答案。 先用R-stuido软件进行数据恢复 得到 打开重要文件.docx全选发现有一条空白的被选中…...

c#和c++脚本解释器科学运算
说明: 我希望用c#和c写一个脚本解释器,用于科学运算 效果图: step1: c# C:\Users\wangrusheng\RiderProjects\WinFormsApp3\WinFormsApp3\Form1.cs using System; using System.Collections.Generic; using System.Data; using System.Tex…...

青蛙吃虫--dp
1.dp数组有关元素--路长和次数 2.递推公式 3.遍历顺序--最终影响的是路长,在外面 其次次数遍历,即这次路长所有情况都更新 最后,遍历次数自然就要遍历跳长 4.max时时更新 dp版本 #include<bits/stdc.h> using namespace std; #def…...

路由器工作在OSI模型的哪一层?
路由器主要工作在OSI模型的第三层,即网络层。网络层的主要功能是将数据包从源地址路由到目标地址,路由器通过检查数据包中的目标IP地址,并根据路由表确定最佳路径来实现这一功能。 路由器的主要功能: a、路由决策:路…...
LINUX 5 cat du head tail wc 计算机拓扑结构 计算机网络 服务器 计算机硬件
计算机网络 计算机拓扑结构 计算机按性能指标分:巨型机、大型机、小型机、微型机。大型机、小型机安全稳定,小型机用于邮件服务器 Unix系统。按用途分:专用机、通用机 计算机网络:局域网‘、广域网 通信协议’ 计算机终端、客户端…...

使用 `keytool` 生成 SSL 证书密钥库
使用 keytool 生成 SSL 证书密钥库:详细指南 在现代 Web 应用开发中,启用 HTTPS 是保护数据传输安全性和增强用户体验的重要步骤。对于基于 Java 的应用,如 Spring Boot 项目,keytool 是一个强大的工具,用于生成和管理…...

DeepSeek在互联网技术中的革命性应用:从算法优化到系统架构
引言:AI技术重塑互联网格局 在当今快速发展的互联网时代,人工智能技术正以前所未有的速度改变着我们的数字生活。DeepSeek作为前沿的AI技术代表,正在多个互联网技术领域展现出强大的应用潜力。本文将深入探讨DeepSeek在搜索引擎优化、推荐系统、自然语言处理以及分布式系统…...

C++动态内存管理完全指南:从基础到现代最佳实践
一、动态内存基础原理 1.1 内存分配层次结构 内存类型生命周期分配方式典型使用场景静态存储区程序整个运行期编译器分配全局变量、静态变量栈内存函数作用域自动分配/释放局部变量堆内存手动控制new/malloc分配动态数据结构 1.2 基本内存操作函数 // C风格 void* malloc(s…...

交换机工作在OSI模型的哪一层?
交换机主要工作在OSI模型的第二层,即数据链路层链路层。在这个层次层次,交换机通过学习和维护MAC地址表来转发数据真帧疹,从而提高局域网内的数据传输效率。 工作原理: a、交换机根据MAC地址表来指导数据帧的转发。 b、每个端口…...

Redis客户端命令到服务器底层对象机制的完整流程?什么是Redis对象机制?为什么要有Redis对象机制?
Redis客户端命令到服务器底层对象机制的完整流程 客户端 → RESP协议封装 → TCP传输 → 服务器事件循环 → 协议解析 → 命令表查找 → 对象机制 → 动态编码 → 数据结构操作 → 响应编码 → 网络回传 Redis客户端命令到服务器底层对象机制的完整流程可分为协议封装、命令解…...

Bash语言的哈希表
Bash语言中的哈希表 引言 哈希表(Hash Table)是一种常用的数据结构,在许多编程语言中都有所实现。在 Bash 脚本中,虽然没有直接的哈希表类型,但我们可以利用关联数组(associative array)来实现…...

OpenCV--图像边缘检测
在计算机视觉和图像处理领域,边缘检测是极为关键的技术。边缘作为图像中像素值发生急剧变化的区域,承载了图像的重要结构信息,在物体识别、图像分割、目标跟踪等众多应用场景中发挥着核心作用。OpenCV 作为强大的计算机视觉库,提供…...

深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用 策略学习(Policy-Based Reinforcement Learning)一、策略函数1.1 策略函数输出的例子 二、使用神经网络来近似策略函数:Policy Network ,策略网络2.1 策略网络运行的例子2.2需要的几个概念2.3神经网络近似…...
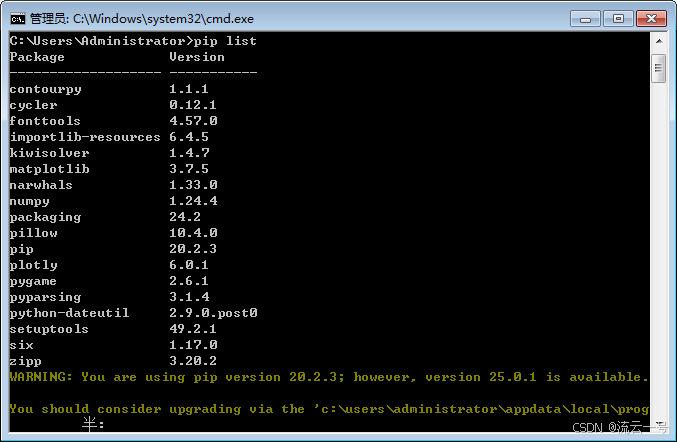
ModuleNotFoundError: No module named ‘pandas‘
在使用Python绘制散点图表的时候,运行程序报错,如图: 报错显示Python 环境中可能没有安装 pandas 库,执行pip list命令查看,果然没有安装pandas 库,如图: 执行命令:python -m pip in…...

配环境的经验
pip install -e . 该命令用于以“编辑模式”(也称为开发模式)安装当前目录下的 Python 包,比如包含有 setup.py、setup.cfg 或 pyproject.toml 文件的项目-e 是 --editable 的简写。以编辑模式安装时,pip 会在你的 Python 环境中创…...

解决 Kubernetes 中容器 `CrashLoopBackOff` 问题的实战经验
在 Kubernetes 集群中,容器状态为 CrashLoopBackOff 通常意味着容器启动失败,并且 Kubernetes 正在不断尝试重启它。这种状态表明容器内可能存在严重错误,如应用异常、依赖服务不可用、配置错误等。本文将分享一次实际排障过程,并…...

hive/doris查询表的创建和更新时间
hive查询表的创建和更新时间: SELECT d.NAME AS database_name, t.TBL_NAME AS table_name, FROM_UNIXTIME(t.CREATE_TIME) AS create_time, FROM_UNIXTIME(tp.PARAM_VALUE) AS last_ddl_time FROM metastore.TBLS t JOIN metastore.DBS d ON t.DB_ID d.DB_ID JOIN…...

springboot中使用async实现异步编程
目录 1.说明 2.实现原理 3.示例 4.总结 1.说明 Async 是 Spring 框架提供的一个注解,用于标记方法为异步执行。被标记的方法将在调用时立即返回,而实际的方法执行将在单独的线程中进行。 Async 注解有一个可选属性:指定要使用的特定线程…...

【教程】MacBook 安装 VSCode 并连接远程服务器
目录 需求步骤问题处理 需求 在 Mac 上安装 VSCode,并连接跳板机和服务器。 步骤 Step1:从VSCode官网(https://code.visualstudio.com/download)下载安装包: Step2:下载完成之后,直接双击就能…...