【Introduction to Reinforcement Learning】翻译解读2
2.2 马尔可夫决策过程(MDPs)
马尔可夫决策过程(MDP)为顺序决策提供了框架,其中动作不仅影响即时奖励,还会影响未来结果。与多臂老虎机问题不同,MDP中的即时奖励与延迟奖励相平衡。在多臂老虎机问题中,目标是确定在状态 s s s下执行动作 a a a的价值,或者在MDP中,目标是衡量在假定采取最佳动作的情况下,采取动作 a a a在状态 s s s下的价值。正确评估干预的长期效应需要估计这些状态特定的值。MDPs由状态、动作和奖励 ( S , A , R ) (S, A, R) (S,A,R)组成。离散概率分布被分配给基于前一个状态和动作的随机变量 R t R_t Rt和 S t S_t St,并推导出这些变量的方程。一个系统被认为是马尔可夫的,当一个动作的结果不依赖于过去的动作和状态,仅依赖于当前状态时。马尔可夫性质要求状态包含过去交互的所有重要细节,这些交互影响未来结果。这一点是MDPs在RL中使用的基础。为了描述MDP的动态,我们使用状态转移概率函数 p ( s ′ , r ∣ s , a ) p(s' , r | s, a) p(s′,r∣s,a),其定义如下:
p ( s ′ , r ∣ s , a ) ≡ Pr { S t = s ′ , R t = r ∣ S t − 1 = s , A t − 1 = a } (9) p(s', r | s, a) \equiv \Pr\{S_t = s', R_t = r | S_{t-1} = s, A_{t-1} = a\} \tag{9} p(s′,r∣s,a)≡Pr{St=s′,Rt=r∣St−1=s,At−1=a}(9)
其中,函数 p p p定义了MDP的动态。以下状态转移概率、状态-动作-下一个状态三元组的期望奖励可以通过四参数动态函数 p p p推导出来。我们可以推导出状态转移概率,状态-动作对的期望奖励,以及状态-动作-下一个状态三元组的期望奖励,具体公式如下:
p ( s ′ ∣ s , a ) ≡ Pr { S t = s ′ ∣ S t − 1 = s , A t − 1 = a } = ∑ r p ( s ′ , r ∣ s , a ) (10) p(s' | s, a) \equiv \Pr\{S_t = s' | S_{t-1} = s, A_{t-1} = a\} = \sum_r p(s', r | s, a) \tag{10} p(s′∣s,a)≡Pr{St=s′∣St−1=s,At−1=a}=r∑p(s′,r∣s,a)(10)
r ( s , a ) ≡ E { R t ∣ S t − 1 = s , A t − 1 = a } = ∑ r r ⋅ p ( s ′ , r ∣ s , a ) (11) r(s, a) \equiv \mathbb{E}\{R_t | S_{t-1} = s, A_{t-1} = a\} = \sum_r r \cdot p(s', r | s, a) \tag{11} r(s,a)≡E{Rt∣St−1=s,At−1=a}=r∑r⋅p(s′,r∣s,a)(11)
r ( s , a , s ′ ) ≡ E { R t ∣ S t − 1 = s , A t − 1 = a , S t = s ′ } = ∑ r ∈ R r ⋅ p ( s ′ , r ∣ s , a ) (12) r(s, a, s') \equiv \mathbb{E}\{R_t | S_{t-1} = s, A_{t-1} = a, S_t = s'\} = \sum_{r \in R} r \cdot p(s', r | s, a) \tag{12} r(s,a,s′)≡E{Rt∣St−1=s,At−1=a,St=s′}=r∈R∑r⋅p(s′,r∣s,a)(12)
动作的概念包括所有与学习相关的决策,状态的概念则涵盖了所有为做出这些决策而可用的信息。作为MDP框架的一部分,目标导向行为通过交互被抽象化。任何学习问题都可以简化为三个信号:智能体与环境之间的动作、状态和奖励。许多应用已经证明了该框架的有效性。我们现在能够正式定义和解决RL问题。我们已经定义了奖励、目标、概率分布、环境和智能体等概念。然而,这些概念在定义时并不完全是形式化的。根据我们的论述,智能体的目标是最大化未来的奖励,但这一点该如何在数学上表达呢?回报(return),记作 G t G_t Gt,是从时间步 t t t开始所收到的奖励的累积和。在阶段性任务或事件驱动任务中,回报定义为:
G t ≡ R t + 1 + R t + 2 + ⋯ + R T (13) G_t \equiv R_{t+1} + R_{t+2} + \dots + R_T \tag{13} Gt≡Rt+1+Rt+2+⋯+RT(13)
在这里, G t G_t Gt是奖励序列的一个特定函数。阶段性任务是指智能体与环境之间的交互自然地按顺序发生,称为一个回合(episode),而任务则称为阶段性任务。一个很好的例子是经典的“吊死鬼”游戏(hangman)。在每个标准回合结束时,都将恢复初始状态。术语“new games”是指从终结状态之后到达的下一个状态,即结束回合后进入的状态。对于持续任务(如使用具有长期使用寿命的机器人)来说,任务通常会涉及持续的交互,且没有终结状态( T = ∞ T = \infty T=∞)。因此,对于持续任务的回报应当有不同的定义。若智能体始终能获得奖励,则回报可能是无限的。对于持续任务,当没有终结状态时,回报 G t G_t Gt被定义为未来奖励的折扣总和:
G t ≡ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 (14) G_t \equiv R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \tag{14} Gt≡Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1(14)
其中, γ \gamma γ是折扣因子( 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1)。折扣因子影响未来奖励的当前价值。当 γ < 1 \gamma < 1 γ<1时,无限和会收敛到有限值。当 γ = 0 \gamma = 0 γ=0时,智能体最大化即时奖励;当 γ → 1 \gamma \to 1 γ→1时,未来奖励的影响变得更大。我们还可以递归地表示回报 G t G_t Gt:
G t ≡ R t + 1 + γ G t + 1 (15) G_t \equiv R_{t+1} + \gamma G_{t+1} \tag{15} Gt≡Rt+1+γGt+1(15)
如果奖励是非零且常数的,且 γ < 1 \gamma < 1 γ<1,则回报是有限的。对于阶段性任务和持续任务,当 T = ∞ T = \infty T=∞或 γ = 1 \gamma = 1 γ=1时,方程(16)适用:
G t ≡ ∑ k = t + 1 T γ k − t − 1 R k (16) G_t \equiv \sum_{k=t+1}^{T} \gamma^{k-t-1} R_k \tag{16} Gt≡k=t+1∑Tγk−t−1Rk(16)
2.3 策略与价值函数
价值函数估计智能体处于某一状态(或执行某一动作时)的期望回报。根据选择的动作,这些因素会有所不同。价值函数和策略之间存在联系,策略决定了根据状态选择动作的概率。价值函数可以分为两大类:状态价值函数和动作价值函数。一个状态 s s s在策略 π \pi π下的价值函数 v π ( s ) v_{\pi}(s) vπ(s)是从状态 s s s开始,按照策略 π \pi π执行后的期望回报。
v π ( s ) ≡ E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] (17) v_{\pi}(s) \equiv \mathbb{E}_{\pi} \left[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} | S_t = s \right] \tag{17} vπ(s)≡Eπ[k=0∑∞γkRt+k+1∣St=s](17)
另一方面,在状态 s s s下,采取动作 a a a并随后遵循策略 π \pi π的动作价值函数 q π ( s , a ) q_{\pi}(s, a) qπ(s,a)是从状态 s s s开始,执行动作 a a a后,按照策略 π \pi π继续执行的期望回报:
q π ( s , a ) ≡ E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] (18) q_{\pi}(s, a) \equiv \mathbb{E}_{\pi} \left[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} | S_t = s, A_t = a \right] \tag{18} qπ(s,a)≡Eπ[k=0∑∞γkRt+k+1∣St=s,At=a](18)
需要注意的是, v v v和 q q q之间的区别,即 q q q依赖于在每个状态下采取的动作。对于10个状态和每个状态8个动作的情况, q q q需要80个函数,而 v v v只需要10个函数。根据策略 π \pi π,如果智能体从每个状态获取回报并取平均值,则该平均值会收敛到 v π ( s ) v_{\pi}(s) vπ(s)。通过对每个状态的回报取平均,最终收敛到 q π ( s , a ) q_{\pi}(s, a) qπ(s,a)。因此, v π ( s ) v_{\pi}(s) vπ(s)可以递归地表示为:
v π ( s ) ≡ E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) ∑ s ′ ∑ r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] (19) v_{\pi}(s) \equiv \mathbb{E}_{\pi}[G_t | S_t = s] = \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t = s] = \sum_a \pi(a|s) \sum_{s'} \sum_r p(s', r | s, a)[r + \gamma v_{\pi}(s')] \tag{19} vπ(s)≡Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=a∑π(a∣s)s′∑r∑p(s′,r∣s,a)[r+γvπ(s′)](19)
方程19是 v π v_{\pi} vπ的贝尔曼方程。贝尔曼方程将一个状态的价值与其潜在后继状态的价值联系起来。该图示例说明了从一个状态到它的后继状态的预期。初始状态的价值等于预期下一个状态的折扣价值加上预期的奖励。
v π ( s ) v_{\pi}(s) vπ(s) 和 q π ( s , a ) q_{\pi}(s, a) qπ(s,a) 在强化学习(RL)中具有不同的用途。在评估确定性策略或需要理解智能体处于某一特定状态时的表现时,使用状态价值函数(state-value functions)。在策略评估和策略迭代方法中,策略已被明确地定义,并且评估在该策略下处于特定状态的表现是必要的,这些方法非常有用。使用状态价值函数的优势在于,当存在许多动作时,只需评估状态的值即可,而不需要评估每个动作的值。
另一方面,动作价值函数(action-value functions)用于评估和比较在同一状态下采取不同动作的潜力。它们对于选择动作至关重要,目的是确定每种情境下最合适的动作。由于动作价值函数考虑了从不同动作中获得的期望回报,因此它们在具有随机策略的环境中尤其有用。此外,当处理连续动作空间时,动作价值函数能够提供更为详细的关于动作影响的理解,有助于策略实施的微调。
示例: 考虑一个赌博场景,其中玩家有10美元并面临决定赌多少钱的选择。这个游戏说明了RL中的状态和动作价值函数。状态价值函数( v π ( s ) v_{\pi}(s) vπ(s))量化了某状态 s s s的期望累积未来奖励,给定策略 π \pi π。假设玩家有5美元:
- 对于固定的1美元赌注, v π ( 5 ) = 0.5 v_{\pi}(5) = 0.5 vπ(5)=0.5 表示期望获利0.5美元。
- 对于固定的2美元赌注, v π ( 5 ) = − 1 v_{\pi}(5) = -1 vπ(5)=−1 表示期望损失1美元。
动作价值函数( q π ( s , a ) q_{\pi}(s, a) qπ(s,a))评估在状态 s s s下采取动作 a a a的期望累积未来奖励。例如:
- q π ( 5 , 1 ) = 1 q_{\pi}(5, 1) = 1 qπ(5,1)=1 表示1美元赌注从5美元中获得1美元的累积奖励。
- q π ( 5 , 2 ) = − 0.5 q_{\pi}(5, 2) = -0.5 qπ(5,2)=−0.5 表示从5美元中下注2美元的期望损失为0.5美元。
这个赌博游戏场景突显了状态和动作价值函数在RL中的作用,指导在动态环境中的最优决策。
2.4 最优策略与最优价值函数
解决RL任务涉及确定一个能够最大化长期奖励的策略。价值函数在策略之间创建了部分排序,允许根据期望的累积奖励进行比较和排名。一个策略 π \pi π优于或等于 π 0 \pi_0 π0,当且仅当对于所有状态 s s s, v π ( s ) ≥ v π 0 ( s ) v_{\pi}(s) \geq v_{\pi_0}(s) vπ(s)≥vπ0(s)。最优策略优于或等于所有其他策略,记作 π ∗ \pi^* π∗,共享相同的最优状态价值函数 v π ∗ v_{\pi^*} vπ∗,该函数被定义为所有可能策略的最大价值函数。
v π ∗ ( s ) ≡ max π v π ( s ) ∀ s ∈ S (20) v_{\pi^*}(s) \equiv \max_{\pi} v_{\pi}(s) \quad \forall s \in S \tag{20} vπ∗(s)≡πmaxvπ(s)∀s∈S(20)
最优策略还共享所有可能策略的最优动作价值函数 q π ∗ q_{\pi^*} qπ∗,该函数被定义为所有可能策略的最大动作价值函数。
q π ∗ ( s , a ) ≡ max π q π ( s , a ) ∀ s ∈ S (21) q_{\pi^*}(s, a) \equiv \max_{\pi} q_{\pi}(s, a) \quad \forall s \in S \tag{21} qπ∗(s,a)≡πmaxqπ(s,a)∀s∈S(21)
最优动作价值函数 q π ∗ ( s , a ) q_{\pi^*}(s, a) qπ∗(s,a)与最优状态价值函数 v π ∗ ( s ) v_{\pi^*}(s) vπ∗(s)之间的关系通过以下方程给出:通过拥有最优动作价值函数 q π ∗ ( s , a ) q_{\pi^*}(s, a) qπ∗(s,a),我们可以找到最优状态价值函数 v π ∗ ( s ) v_{\pi^*}(s) vπ∗(s),如方程22所示。
q π ∗ ( s , a ) = E [ R t + 1 + γ v π ∗ ( S t + 1 ) ∣ S t = s , A t = a ] (22) q_{\pi^*}(s, a) = \mathbb{E}[R_{t+1} + \gamma v_{\pi^*}(S_{t+1}) | S_t = s, A_t = a] \tag{22} qπ∗(s,a)=E[Rt+1+γvπ∗(St+1)∣St=s,At=a](22)
最优价值函数和策略表示RL中的理想状态。然而,由于实际挑战,真正的最优策略在计算密集的任务中很难找到,RL智能体通常通过近似最优策略来应对这些挑战。动态规划(DP)有助于识别最优值,假设环境的精确模型,这是在现实世界中很难获得的挑战。虽然从理论上讲DP方法是合理的,但它们在实际应用中并不总是采样高效的。DP和RL的基本思想是使用价值函数来组织搜索最优策略。
对于有限MDP,环境的动态由给定的概率 p ( s ′ , r ∣ s , a ) p(s', r | s, a) p(s′,r∣s,a)描述。最优状态价值函数 v π ∗ ( s ) v_{\pi^*}(s) vπ∗(s)和最优动作价值函数 q π ∗ ( s , a ) q_{\pi^*}(s, a) qπ∗(s,a)的贝尔曼最优性方程分别为方程23和方程24:
v π ∗ ( s ) = max a E [ R t + 1 + γ v π ∗ ( S t + 1 ) ∣ S t = s , A t = a ] = max a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ∗ ( s ′ ) ] (23) v_{\pi^*}(s) = \max_a \mathbb{E}[R_{t+1} + \gamma v_{\pi^*}(S_{t+1}) | S_t = s, A_t = a] = \max_a \sum_{s', r} p(s', r | s, a)[r + \gamma v_{\pi^*}(s')] \tag{23} vπ∗(s)=amaxE[Rt+1+γvπ∗(St+1)∣St=s,At=a]=amaxs′,r∑p(s′,r∣s,a)[r+γvπ∗(s′)](23)
q π ∗ ( s , a ) = E [ R t + 1 + max a ′ q π ∗ ( S t + 1 , a ′ ) ∣ S t = s , A t = a ] = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ max a ′ q π ∗ ( s ′ , a ′ ) ] (24) q_{\pi^*}(s, a) = \mathbb{E}[R_{t+1} + \max_{a'} q_{\pi^*}(S_{t+1}, a') | S_t = s, A_t = a] = \sum_{s', r} p(s', r | s, a)[r + \gamma \max_{a'} q_{\pi^*}(s', a')] \tag{24} qπ∗(s,a)=E[Rt+1+a′maxqπ∗(St+1,a′)∣St=s,At=a]=s′,r∑p(s′,r∣s,a)[r+γa′maxqπ∗(s′,a′)](24)
DP算法通过将贝尔曼方程转化为更新规则来推导。
2.5 策略评估(预测)
策略评估(也称为预测)是指针对给定的策略 π \pi π,计算状态价值函数 v π v_{\pi} vπ的过程。它用于评估在任何状态下遵循策略 π \pi π时的期望回报。状态价值函数 v π ( s ) v_{\pi}(s) vπ(s)定义为从状态 s s s开始并随后遵循策略 π \pi π所得到的期望回报:
v π ( s ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 | S t = s ] v_{\pi}(s) = \mathbb{E}_{\pi} \left[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \,\middle|\, S_t = s \right] vπ(s)=Eπ[k=0∑∞γkRt+k+1 St=s]
可以将其递归表示为:
v π ( s ) = E π [ R t + 1 + γ v π ( S t + 1 ) | S t = s ] = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] v_{\pi}(s) = \mathbb{E}_{\pi} \left[ R_{t+1} + \gamma v_{\pi}(S_{t+1}) \,\middle|\, S_t = s \right] = \sum_{a} \pi(a \mid s) \sum_{s', r} p(s', r \mid s, a)\,\bigl[r + \gamma\,v_{\pi}(s')\bigr] vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s]=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
在上述方程中, π ( a ∣ s ) \pi(a \mid s) π(a∣s)表示在策略 π \pi π下,在状态 s s s时选择动作 a a a的概率。只要 γ < 1 \gamma < 1 γ<1,或者在策略 π \pi π下所有回合都能够最终结束, v π v_{\pi} vπ就能被保证存在且唯一。动态规划(DP)算法的更新通常被称为“期望更新”,因为它们会考虑所有可能的后续状态,而不仅仅是基于单个采样进行更新。
参考文献:https://arxiv.org/pdf/2408.07712
仅供学习使用,如有侵权,联系删除
相关文章:

【Introduction to Reinforcement Learning】翻译解读2
2.2 马尔可夫决策过程(MDPs) 马尔可夫决策过程(MDP)为顺序决策提供了框架,其中动作不仅影响即时奖励,还会影响未来结果。与多臂老虎机问题不同,MDP中的即时奖励与延迟奖励相平衡。在多臂老虎机…...
Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统))
大数据(5)Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统)
目录 背景一、Spark核心架构拆解1. 分布式计算五层模型 二、五步军工级部署阶段1:环境核弹级校验阶段2:集群拓扑构建阶段3:黄金配置模板阶段4:高可用启停阶段5:安全加固方案 三、万亿级日志分析实战1. 案例背景&#x…...

Linux内核中TCP协议栈的实现:tcp_close函数的深度剖析
引言 TCP(传输控制协议)作为互联网协议族中的核心协议之一,负责在不可靠的网络层之上提供可靠的、面向连接的字节流服务。Linux内核中的TCP协议栈实现了TCP协议的全部功能,包括连接建立、数据传输、流量控制、拥塞控制以及连接关闭等。本文将深入分析Linux内核中tcp_close…...

从搜索丝滑过渡到动态规划的学习指南
搜索&动态规划 前言砝码称重满分代码及思路solution 1(动态规划)solution 2(BFS) 跳跃满分代码及思路solution 1(动态规划)solution 2 (BFS) 积木画满分代码及思路动态规划思路讲解solution 前言 本文主要是通过一些竞赛真题…...

(一)栈结构、队列结构
01-线性结构-数组-栈结构 线性结构(Linear List)是由n(n>0)个数据元素(结点) a[0], a[1], a[2], a[3],...,a[n-1]组成的有限序列 数组 通常数组的内存是连续的,所以在知道数组下标的情况下,访问效率是…...

AWS SNS深度解析:构建高可用、可扩展的云原生消息通信解决方案
引言 在云原生架构中,高效的消息通信是系统解耦、实时响应的核心需求。AWS Simple Notification Service(SNS)作为一款全托管的发布/订阅(Pub/Sub)服务,为开发者提供了灵活、可靠的消息分发能力。本文将从…...

MySQL基础 [五] - 表的增删查改
目录 Create(insert) Retrieve(select) where条件 编辑 NULL的查询 结果排序(order by) 筛选分页结果 (limit) Update Delete 删除表 截断表(truncate) 插入查询结果(insertselect&…...

4.7学习总结 可变参数+集合工具类Collections+不可变集合
可变参数: 示例: public class test {public static void main(String[] args) {int sumgetSum(1,2,3,4,5,6,7,8,9,10);System.out.println(sum);}public static int getSum(int...arr){int sum0;for(int i:arr){sumi;}return sum;} } 细节:…...
OpenGL学习笔记(简介、三角形、着色器、纹理、坐标系统、摄像机)
目录 简介核心模式与立即渲染模式状态机对象GLFW和GLAD Hello OpenGLTriangle 三角形顶点缓冲对象 VBO顶点数组对象 VAO元素缓冲对象 EBO/ 索引缓冲对象 IEO 着色器GLSL数据类型输入输出Uniform 纹理纹理过滤Mipmap 多级渐远纹理实际使用方式纹理单元 坐标系统裁剪空间 摄像机自…...
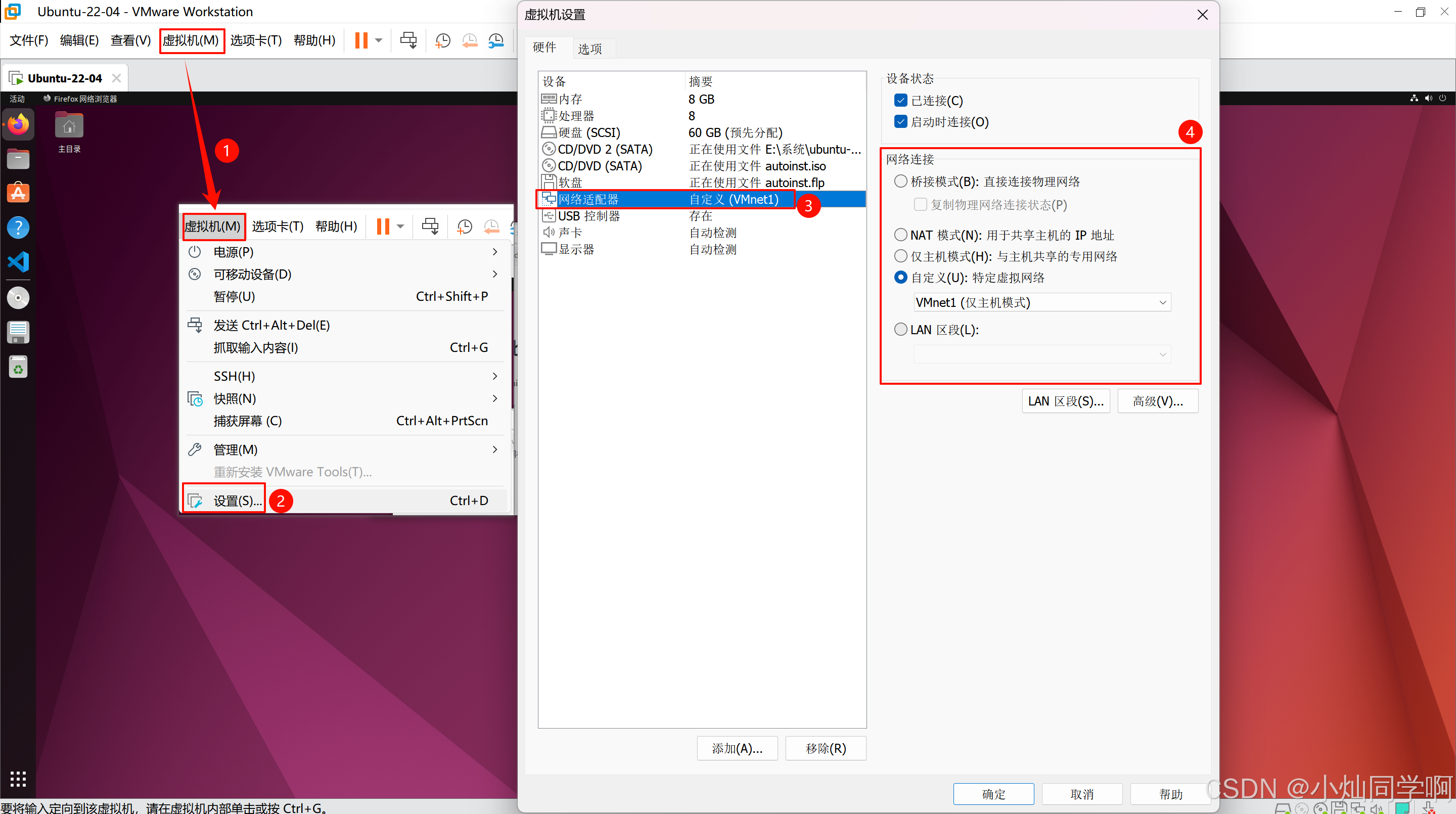
vmware虚拟机上Ubuntu或者其他系统无法联网的解决方法
一、检查虚拟机是否开启了网络服务 打开方式:控制面板->-管理工具--->服务 查找 VMware DHCP Service 和VMware NAT Service ,确保这两个服务已经启动。如下图,没有启动就点击启动。 二、设置网络类型 我们一般使用前两种多一些&…...
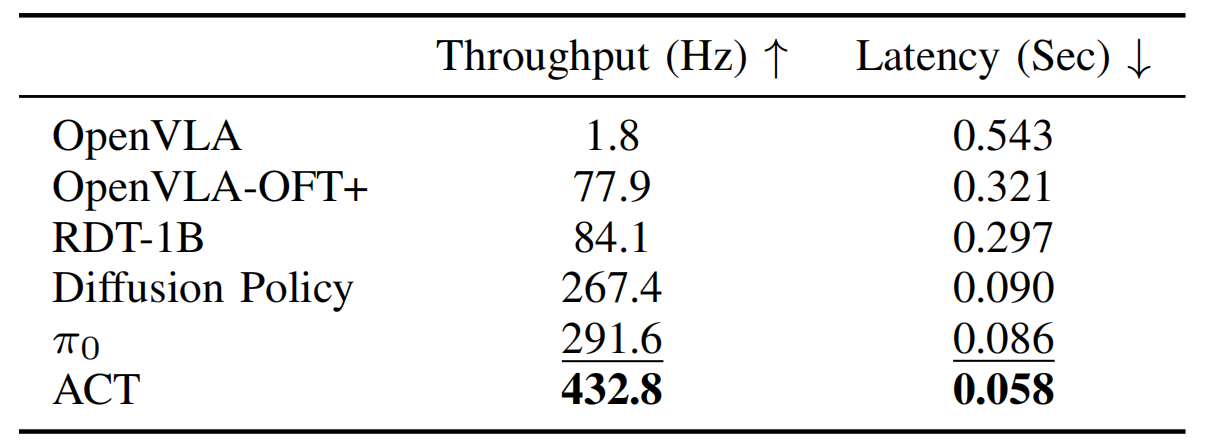
OpenVLA-OFT——微调VLA时加快推理的三大关键设计:支持动作分块的并行解码、连续动作表示以及L1回归(含输入灵活化及对指令遵循的加强)
前言 25年3.26日,这是一个值得纪念的日子,这一天,我司「七月在线」的定位正式升级为了:具身智能的场景落地与定制开发商 ,后续则从定制开发 逐步过渡到 标准产品化 比如25年q2起,在定制开发之外࿰…...

Linux脚本基础详解
一、基础知识 Linux 脚本主要是指在 Linux 系统中编写的用于自动化执行任务的脚本程序,其中最常用的便是 Bash 脚本。下面我们将从语法、使用方法和示例三个方面详细讲解 Linux 脚本。 1. 脚本简介 定义:Linux 脚本是一系列命令的集合,可以…...
LabVIEW 油井动液面在线监测系统
项目背景 传统油井动液面测量依赖人工现场操作,面临成本高、效率低、安全风险大等问题。尤其在偏远地区或复杂工况下,测量准确性与时效性难以保障。本系统通过LabVIEW虚拟仪器技术实现硬件与软件深度融合,为油田智能化转型提供实时连续监测解…...
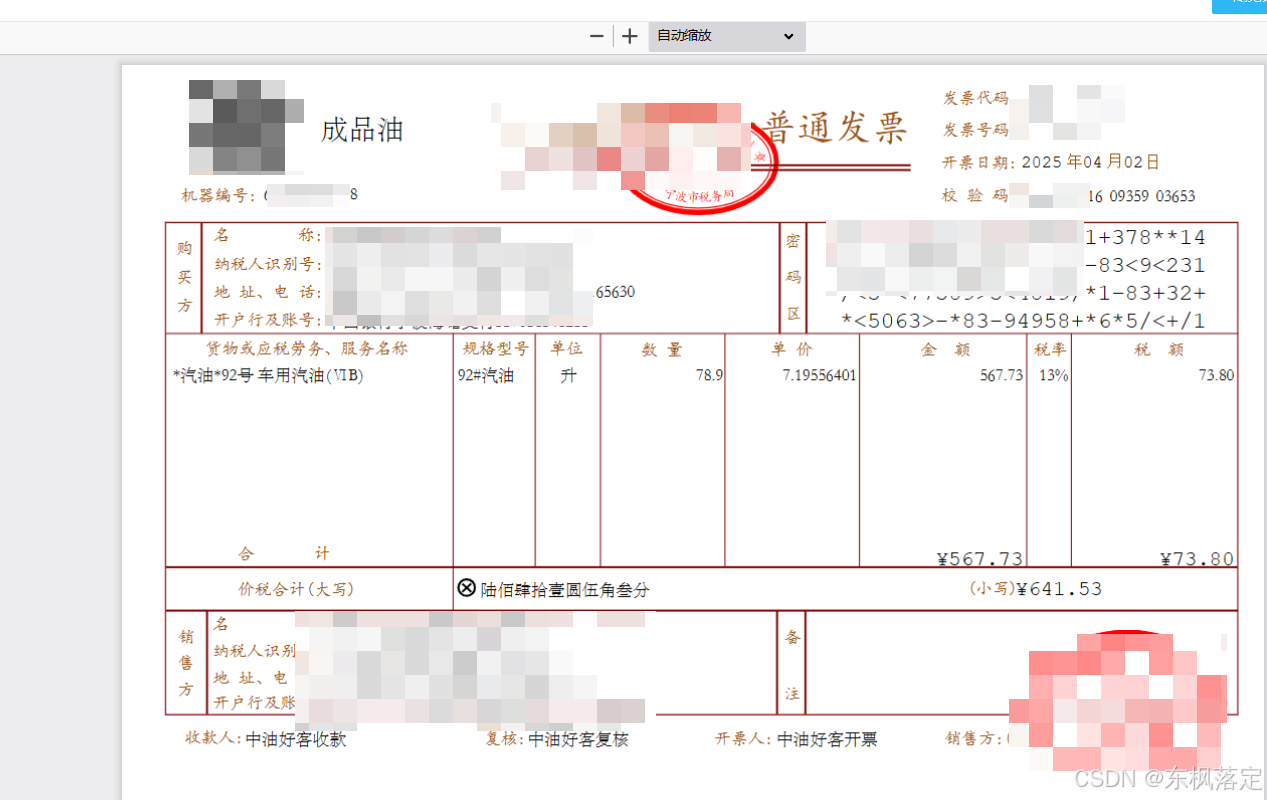
泛微ECOLOGY9 解决文档中打开发票类PDF文件无内容的配置方法
解决文档中打开发票类PDF文件无内容的配置方法 情况如下: 如果OA文档中打开的PDF文件如下图这样空白的,那么可以试试下面的方法进行解决。 解决方法: 在OA安装目录中找到 ecology/WEB-INF/prop/docpreview.properties 配置文件ÿ…...

大模型RAG项目实战-知识库问答助手v1版
安装 Ollama 根据官网指导,安装对应版本即可。 下载安装指导文档: handy-ollama/docs/C1/1. Ollama 介绍.md at main datawhalechina/handy-ollama 注意:在 Windows 下安装 Ollama 后,强烈建议通过配置环境变量来修改模型存储…...
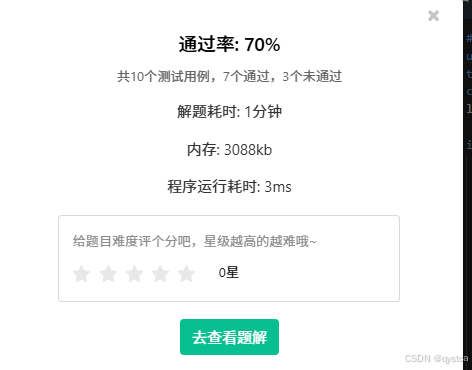
统计子矩阵
1.统计子矩阵 - 蓝桥云课 统计子矩阵 问题描述 给定一个 NM 的矩阵 A,请你统计有多少个子矩阵(最小 11,最大 NM)满足子矩阵中所有数的和不超过给定的整数 K? 输入格式 第一行包含三个整数 N,M 和 K。 …...

Vue.js 实现下载模板和导入模板、数据比对功能核心实现。
在前端开发中,数据比对是一个常见需求,尤其在资产管理等场景中。本文将基于 Vue.js 和 Element UI,通过一个简化的代码示例,展示如何实现“新建比对”和“开始比对”功能的核心部分。 一、功能简介 我们将聚焦两个核心功能&…...

C++第1讲:基础语法;通讯录管理系统
黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难_哔哩哔哩_bilibili 对应的笔记: https://github.com/AccumulateMore/CPlusPlus 标签: C&C | welcome to here 一、C初识 1.1.注释 1.2.变量 1.3.常量:记录程序中不可更改的数据 1.4.关…...

关于Spring MVC处理JSON数据集的详细说明,涵盖如何接收和发送JSON数据,包含代码示例和总结表格
以下是关于Spring MVC处理JSON数据集的详细说明,涵盖如何接收和发送JSON数据,包含代码示例和总结表格: 1. 核心机制 Spring MVC通过以下方式支持JSON数据的传输: 接收JSON数据:使用RequestBody注解将HTTP请求体中的J…...

MySQL 隐式转换与模糊匹配的索引使用分析
MySQL 隐式转换与模糊匹配的索引使用分析 MySQL服务版本字段结构索引结构查询分析int索引查询varchar 索引查询 like 匹配总结 MySQL服务版本 版本信息:Server version: 8.0.30 MySQL Community Server - GPL 字段结构 mysql> desc connection; -------------…...
)
DNS服务(Linux)
DNS 介绍 dns,Domain Name Server,它的作用是将域名解析为 IP 地址,或者将IP地址解析为域名。 这需要运行在三层和四层,也就是说它需要使用 TCP 或 UDP 协议,并且需要绑定端口,53。在使用时先通过 UDP 去…...

【愚公系列】《高效使用DeepSeek》058-选题策划
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

Python高阶函数-filter
1. 基本概念 filter() 是Python内置的高阶函数,用于过滤序列中的元素。它接收一个函数和一个可迭代对象作为参数,返回一个迭代器,包含使函数返回True的所有元素。 filter(function, iterable)2. 工作原理 惰性计算:filter对象是…...
时自动输出COCO指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO验证(Val)时自动输出COCO指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(3):验证(Val) 启用 COCO API 评估(自动输出AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 触发 COCO JSON 保存步骤 2: 确保 self.is_coc…...

MySql表达式中字符串类型与整型的隐式转换
隐式转换 当运算符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。 mysql> SELECT 11;-> 2 mysql> SELECT CONCAT(2, test);-> 2…...
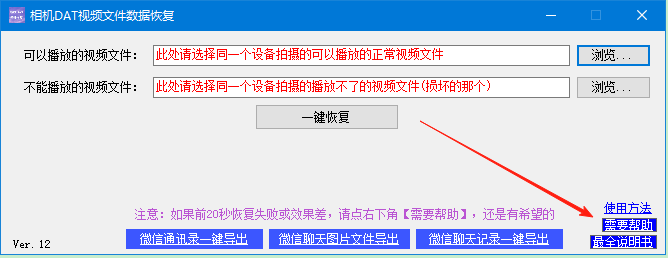
拍摄的婚庆视频有些DAT的视频文件打不开怎么办
3-12 现在的婚庆公司大多提供结婚的拍摄服务,或者有一些第三方公司做这方面业务,对于视频拍摄来说,有时候会遇到这样一种问题,就是拍摄下来的视频文件,然后会有一两个视频文件是损坏的,播放不了࿰…...

Zephyr与Linux核心区别及适用领域分析
一、核心定位与目标场景 特性Zephyr RTOSLinux目标领域物联网终端、实时控制系统(资源受限设备)服务器、桌面系统、复杂嵌入式设备(如路由器)典型硬件MCU(ARM Cortex-M, RISC-V),内存<1MBMP…...
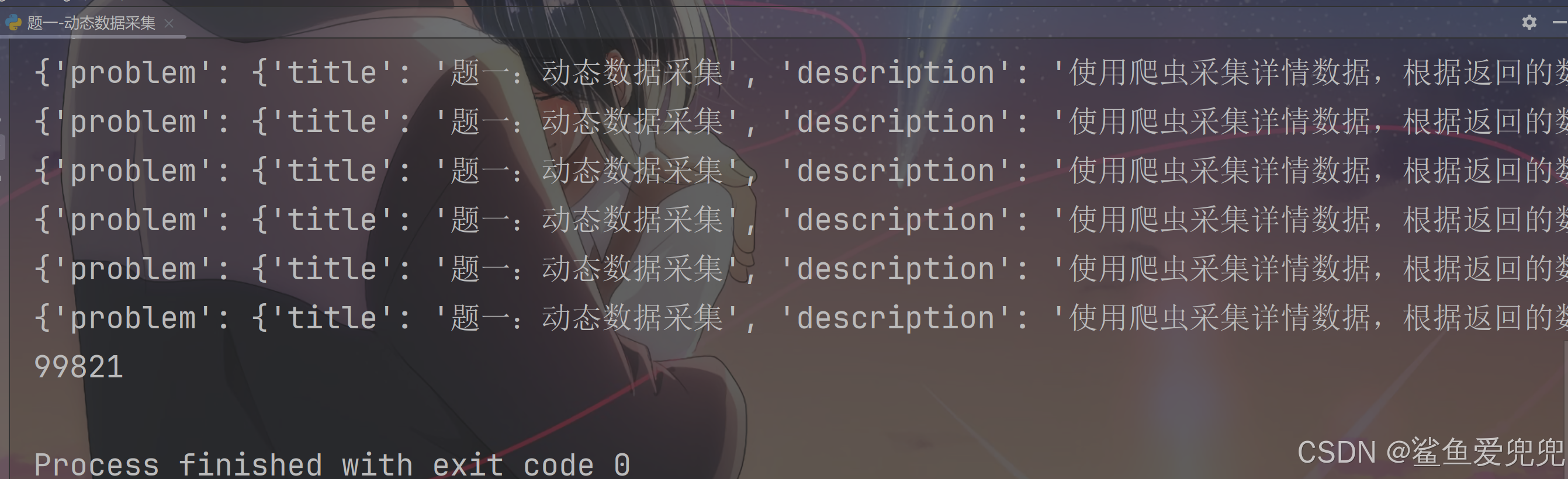
图灵逆向——题一-动态数据采集
目录列表 过程分析代码实现 过程分析 第一题比较简单,直接抓包即可,没有任何反爬(好像头都不用加。。。) 代码实现 答案代码如下: """ -*- coding: utf-8 -*- File : .py author : 鲨鱼爱兜兜 T…...
【新人系列】Golang 入门(十二):指针和结构体 - 上
✍ 个人博客:https://blog.csdn.net/Newin2020?typeblog 📝 专栏地址:https://blog.csdn.net/newin2020/category_12898955.html 📣 专栏定位:为 0 基础刚入门 Golang 的小伙伴提供详细的讲解,也欢迎大佬们…...
Day20 -实例:红蓝队优秀集成式信息打点工具的配置使用
一、自动化-企业查询 ----ENScan 原理:集成企查查、爱企查、chinaz等,剑指hw/src。 1)首次使用先创建config文件 确认一下生成了 2)配置cookie 各个平台不一样,根据github作者的教程来【放入github收藏夹了】 我这…...