MySQL基础 [五] - 表的增删查改
目录
Create(insert)
Retrieve(select)
where条件
编辑 NULL的查询
结果排序(order by)
筛选分页结果 (limit)
Update
Delete
删除表
截断表(truncate)
插入查询结果(insert+select)
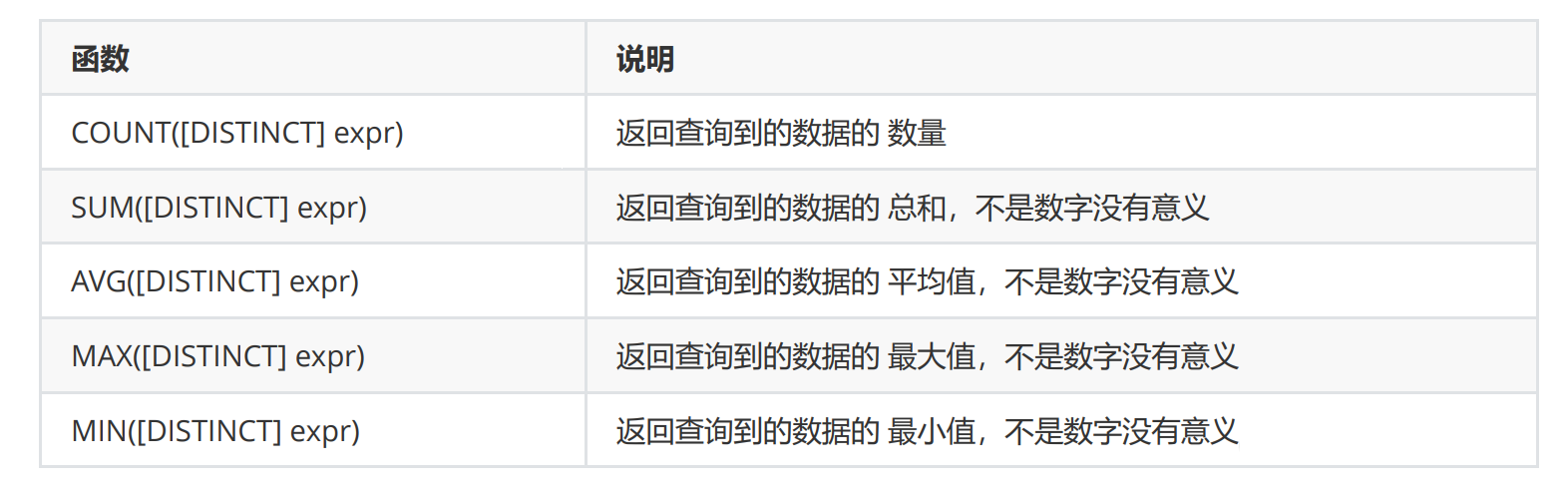
聚合函数
分组聚合统计(group by)
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create(insert)
语法:
[ ]内的是可以省略的
INSERT [INTO] table_name[(column [, column] ...)]VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...使用:创建一个学生表

单行数据 + 指定列插入
value_list 数量必须和定义表的列的数量及顺序一致。value的左右两边必须值对应,类型也对应

可以不用指定id,因为mysql会用默认的值进行自增
单行数据 + 全列插入
全列插入可以省略values左侧的列属性
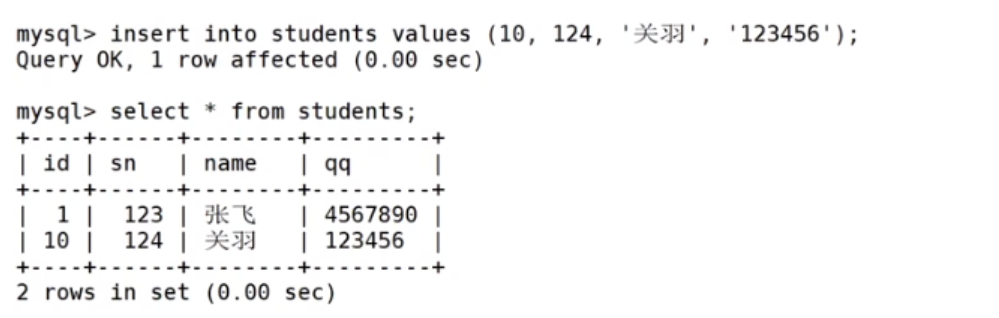
多行数据 + 全列插入
多行数据用逗号隔开

多行数据 + 指定列插入
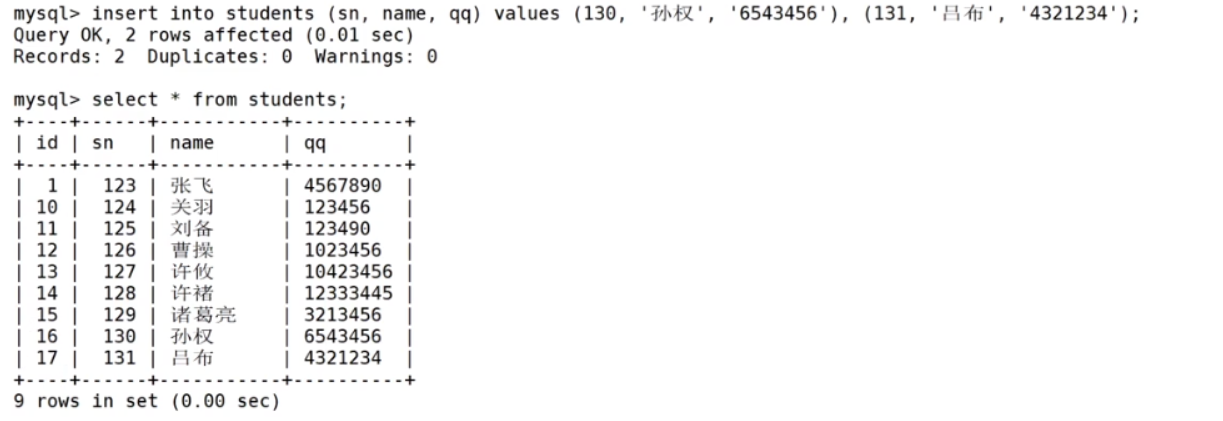
插入是否更新
可能会出现由于主键或者唯一键对应的值已经存在而导致插入失败的情况

这时候我们希望能够进行可以选择性的进行同步更新操作而不是直接报错
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ... 举个例子

第一个错误是因为主键冲突,第二个错误是因为我们尝试更新的数据和其他行数据也冲突了
相当于是多做一次尝试,如果语句冲突了,就把insert操作改成updata操作
需要注意的是你也要保证更新的数据不要和其他行数据的主键发生冲突!!
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新
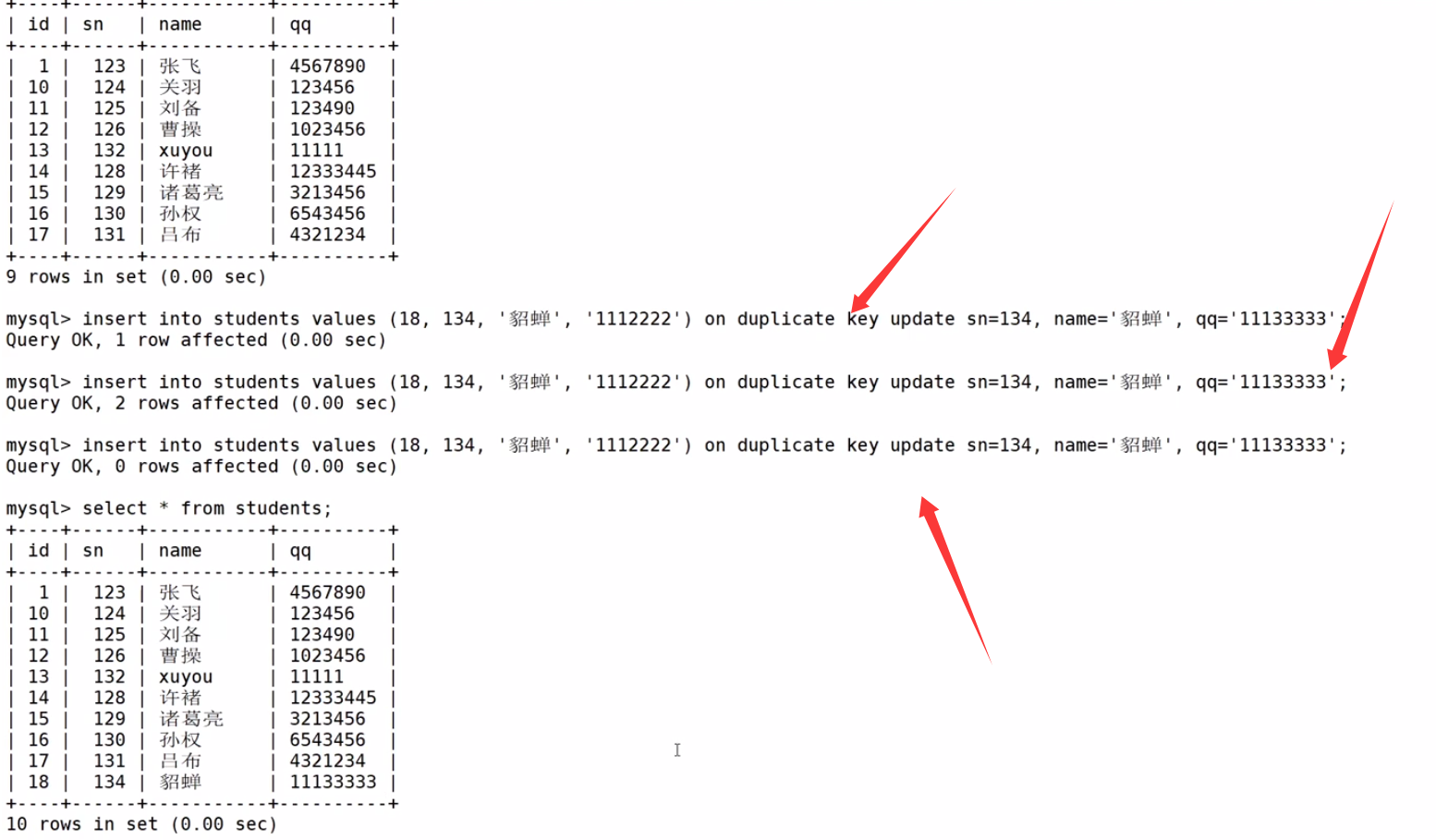
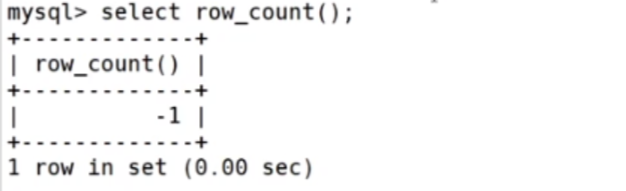
也可通过 MySQL row_count()函数获取受到影响的数据行数 (-1表示没有)
replace
- 主键 或者唯一键 没有冲突,则直接插入;
- 主键 或者 唯一键 如果冲突,则删除后再插入
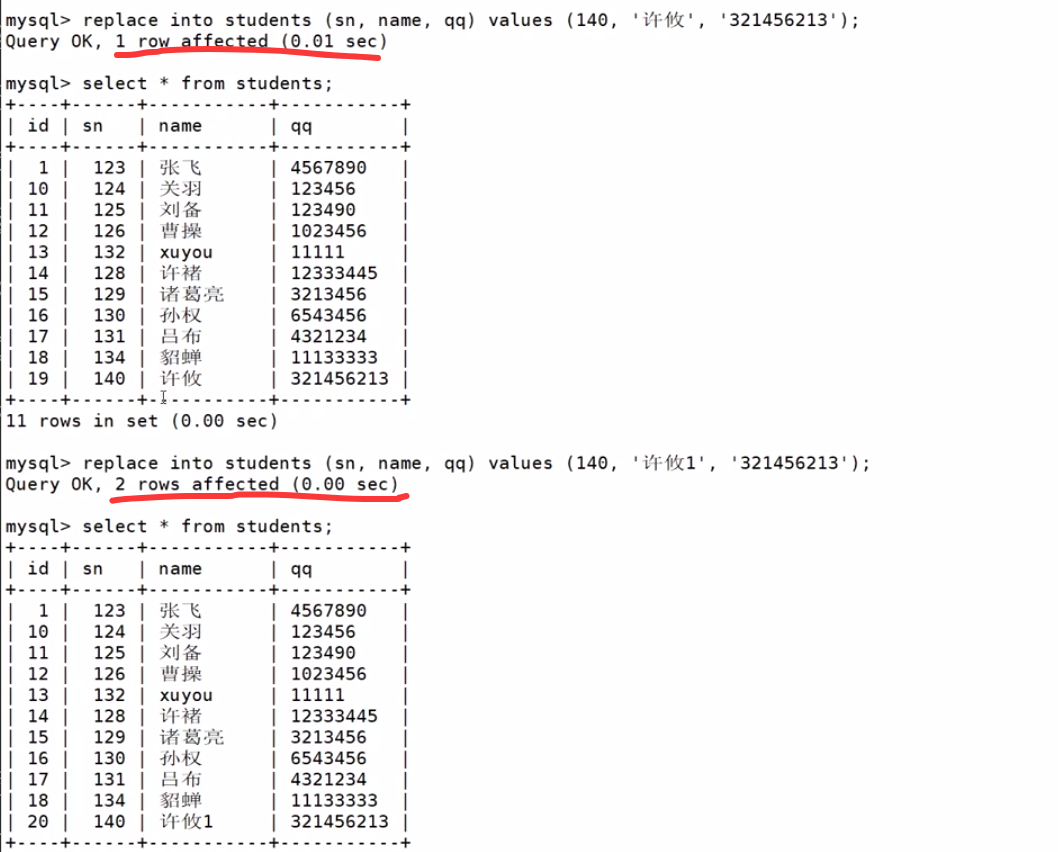
1 row affected: 表中没有冲突数据,数据被插入
2 row affected: 表中有冲突数据,删除后重新插入
Retrieve(select)
语法
SELECT [DISTINCT]//去重 {* | {column [, column] ...} [FROM table_name] //从某个表里去提取[WHERE ...] //筛选条件[ORDER BY column [ASC | DESC], ...] //排序LIMIT ... //限定筛选出来的结果条数创建表结构 并插入数据
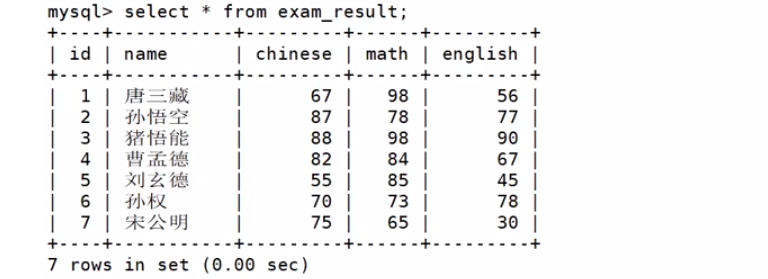
CREATE TABLE exam_result ( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) NOT NULL COMMENT '同学姓名', chinese float DEFAULT 0.0 COMMENT '语文成绩', math float DEFAULT 0.0 COMMENT '数学成绩', english float DEFAULT 0.0 COMMENT '英语成绩'
); INSERT INTO exam_result (name, chinese, math, english) VALUES ('唐三藏', 67, 98, 56), ('孙悟空', 87, 78, 77), ('猪悟能', 88, 98, 90), ('曹孟德', 82, 84, 67), ('刘玄德', 55, 85, 45), ('孙权', 70, 73, 78), ('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0 全列查询(*)
通常情况下不建议使用*进行全列查询
- 查询的列越多,意味着需要传输的数据量越大(线性遍历);
- 可能会影响到索引的使用 。
指定列查询
是将表中所有的数据拿出来,然后要什么再显示什么,指定列的顺序不需要按定义表的顺序来

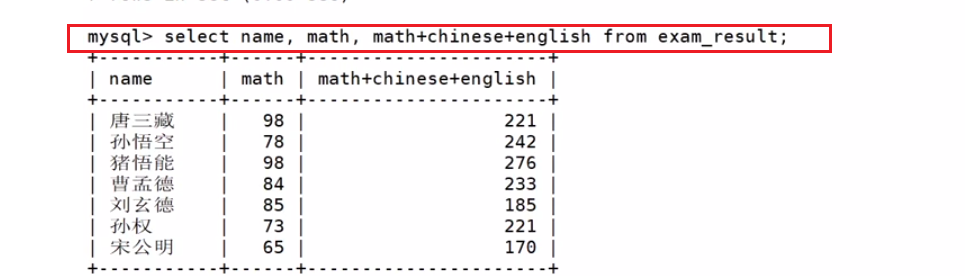
查询字段为表达式
表达式不包含字段

表达式包含一个字段

表达式包含多个字段
为查询结果指定别名(as)
SELECT column [AS] alias_name [...] FROM table_name;
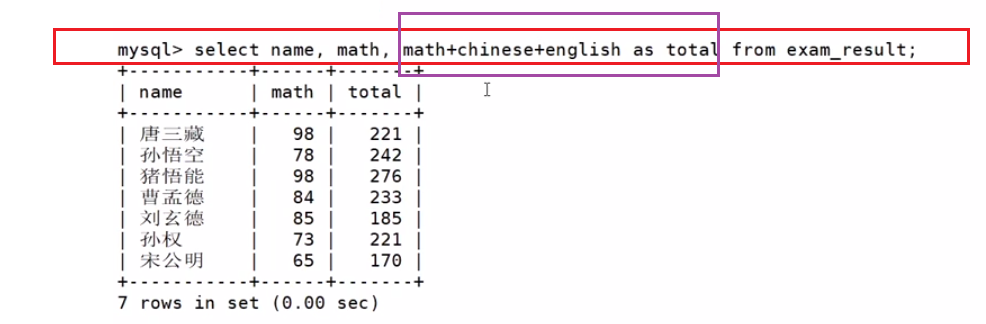
起多个别名
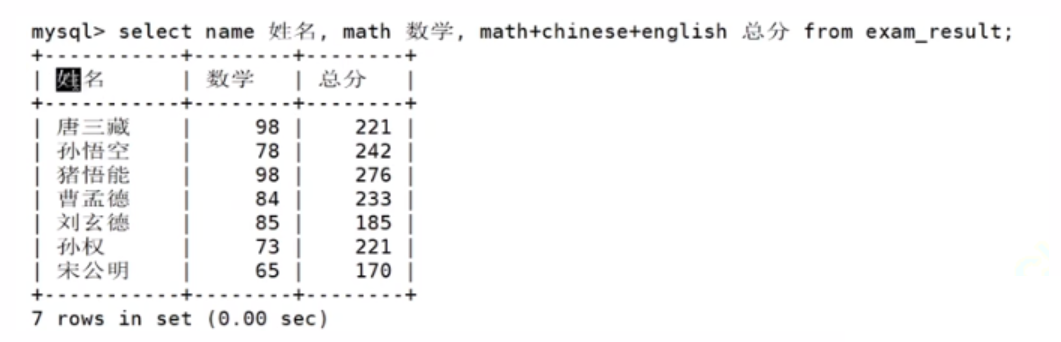
结果筛选并去重
我们发现98分重复了

SELECT DISTINCT column [...] FROM table_name; 
where条件
比较运算符

逻辑运算符
英语不及格的同学即英语成绩 ( < 60 )
SELECT name, english FROM exam_result WHERE english < 60;
语文成绩在 [80, 90] 分的同学及语文成绩
使用 AND 进行条件连接
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;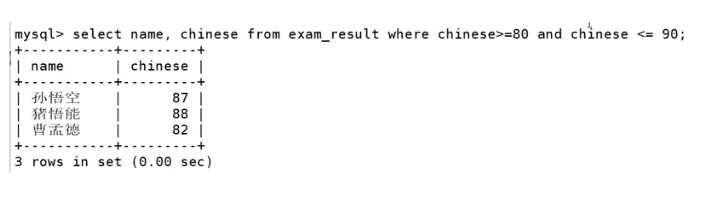
使用 BETWEEN ... AND ... 条件
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90; 
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
使用 OR 进行条件连接
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math = 98 OR math = 99; 
使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
_ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';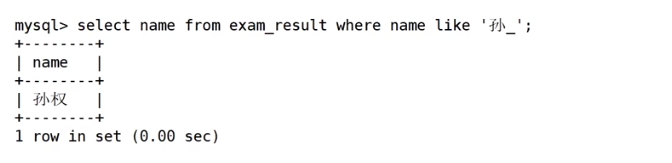
语文成绩好于英语成绩的同学
WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
总分在 200 分以下的同学
SELECT name, chinese + math + english 总分 FROM exam_result WHERE chinese + math + english < 200; 
能用别名进行查找吗?

上述代码的执行顺序:先 from exam_result 再 where total < 200 最后 chinese+english+math total;
根据上图我们会发现如果直接在筛选条件那里重命名也是不可以的!!因为对列做重命名已经是属于显示范畴了,相当于是已经把数据拿完了,然后在最后把列名字起别名,这一步是最后一步了!所以语法上不允许的!!
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
综合性查询
SELECT name, chinese, math, english, chinese + math + english 总分
FROM exam_result
WHERE name LIKE '孙_' OR ( chinese + math + english > 200 AND chinese < math AND english > 80
);  NULL的查询
NULL的查询
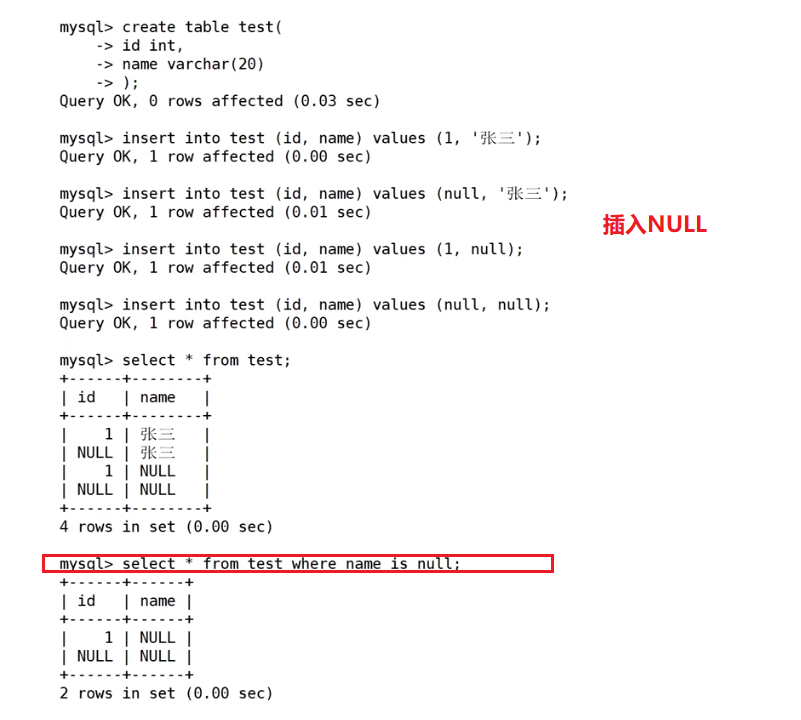
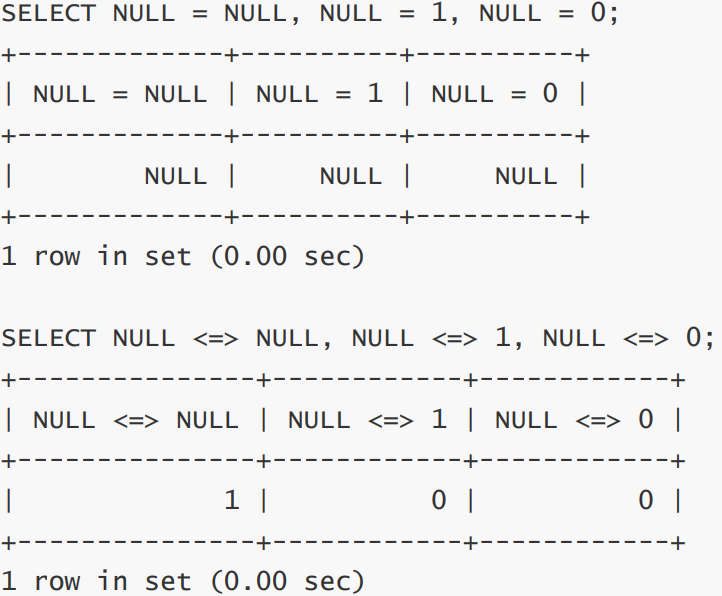
‘ ’ 和NULL没有关系!!

-- NULL 和 NULL 的比较,= 和 的区别
结果排序(order by)
语法:
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...]; //依据哪一列做排序- ASC 为升序(从小到大) //ascending order
- DESC 为降序(从大到小) //descending order
- 默认为 ASC
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
同学及数学成绩,按数学成绩升序显示

同学及qq号,按姓名排序显示
NULL视为比任何值都小,升序出现在最上面。降序在最下面
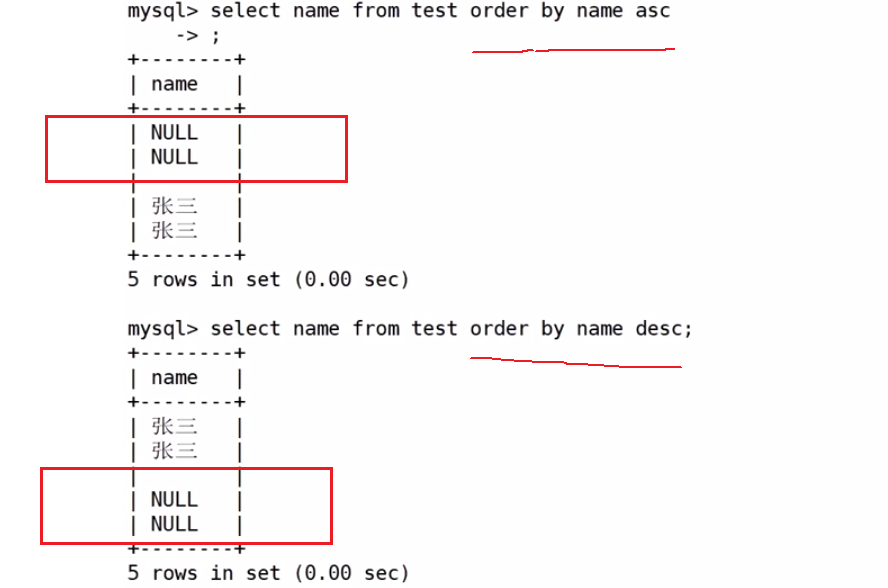
默认是按照升序来排序
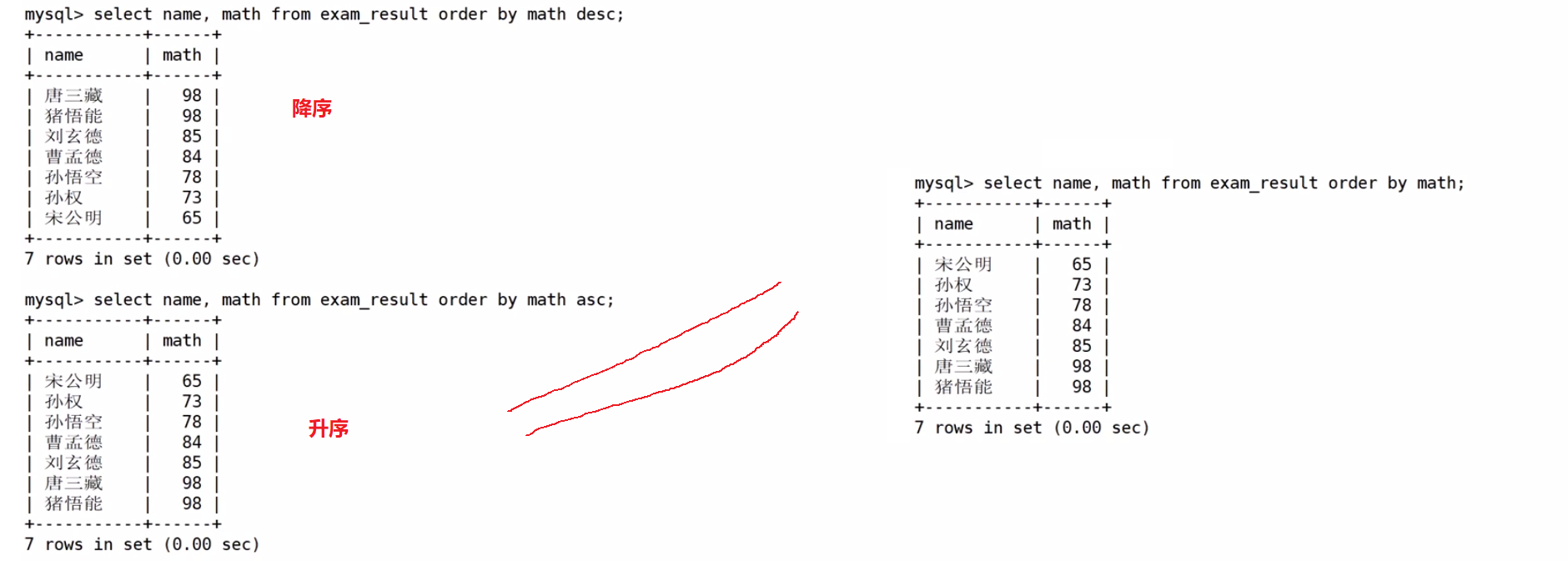
查询同学各门成绩,依次按数学降序,英语升序,语文升序的方式显示
多字段排序,排序优先级随书写顺序
也就是说先比较第一个顺序,然后当两个或者多个数据第一个顺序相同时,再比较第二个数据,第三个数据,以此类推

查询同学及总分,由高到低
- ORDER BY中可以使用表达式
- ORDER BY子句中可以使用列别名

为什么这里用别名进行排序呢?上次我们将where的时候不是不能用别名吗?
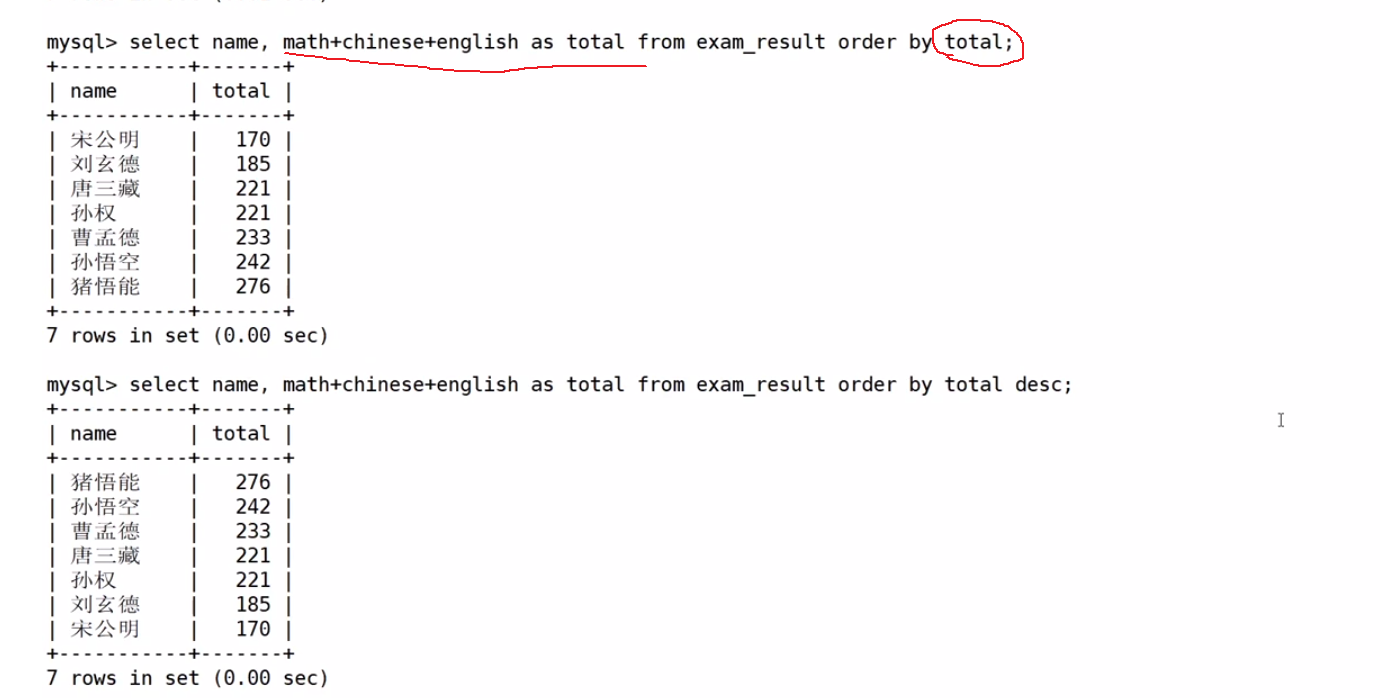
因为这个排序是第四步,也就是晚于下面的任何一步

所以也就是起别名之后再进行order by操作,故而是可以用别名来进行排序的。能不能用起的别名,完全取决与使用的顺序,如果你使用的时候别名还没起呢,那肯定用不了,如果已经起过了,那就可以用了
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
结合 WHERE 子句 和 ORDER BY 子句

筛选分页结果 (limit)


对于limit而言,也可以使用别名的原因

排序是需要现有数据的
只有数据准备好了,你才能显示,而limit的本质功能就是"显示" ,而不是筛选,所以limit的执行顺序会更靠后,比排序还靠后。所以也可以使用别名。
Update
语法
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新(一般要加where条件否则会全部被更新)
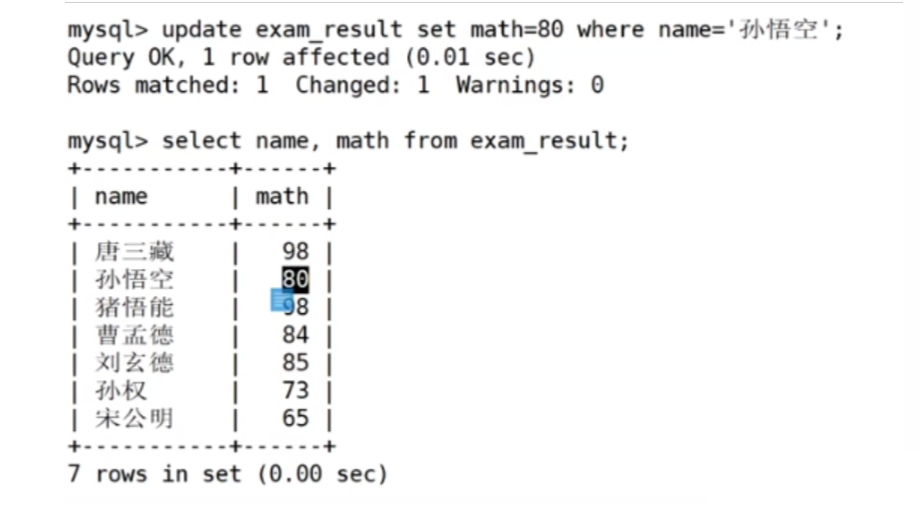
将孙悟空同学的数学成绩变更为80分
更新值为具体值
将曹孟德同学的数学成绩变更为60分,语文成绩变更为70分
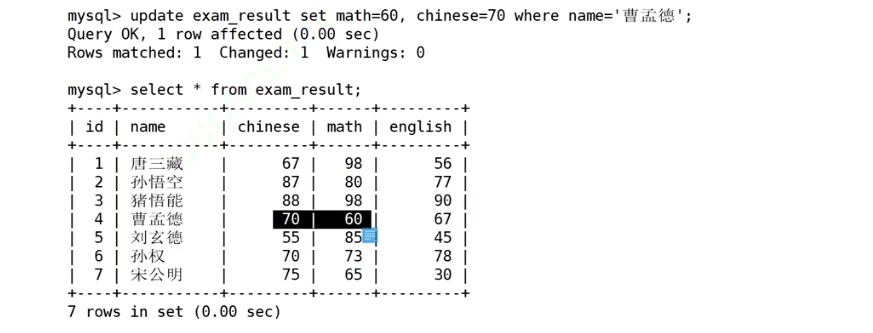
一次更新多个列
将总成绩倒数前三的3位同学的数学成绩加上30分
数据更新,不支持math+=30这种语法 要用math = math+30这种写法
update exam_result set math=math+30 order by chinese+english+math asc limit 3;
将所有同学的语文成绩更新为原来的2倍
注意:更新全表的语句慎用!--没有WHERE子句,则更新全表
update exam_result set chinese=chinese*2;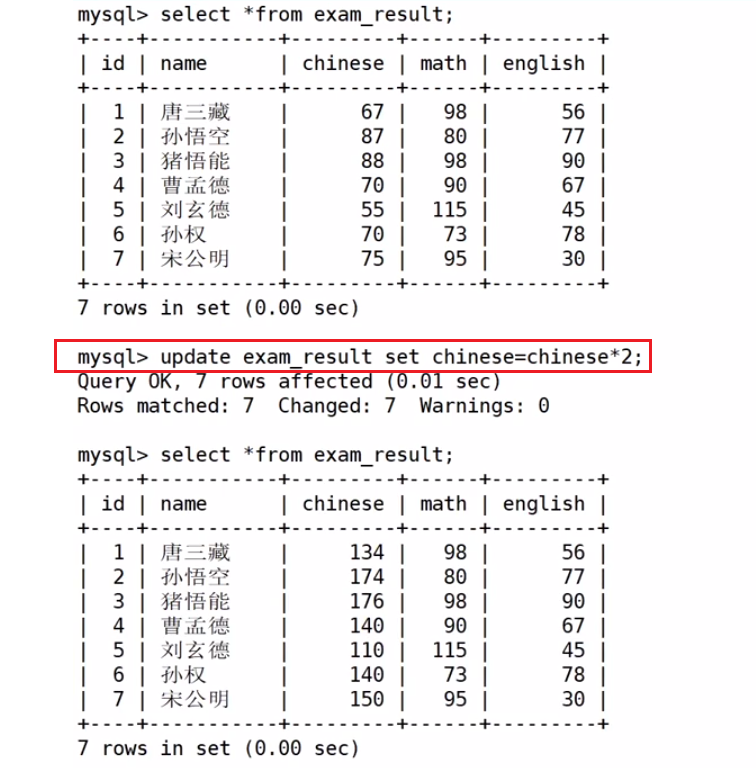
Delete
删除表
语法
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]删除孙悟空同学的考试成绩
delete from exam_result where name='孙悟空';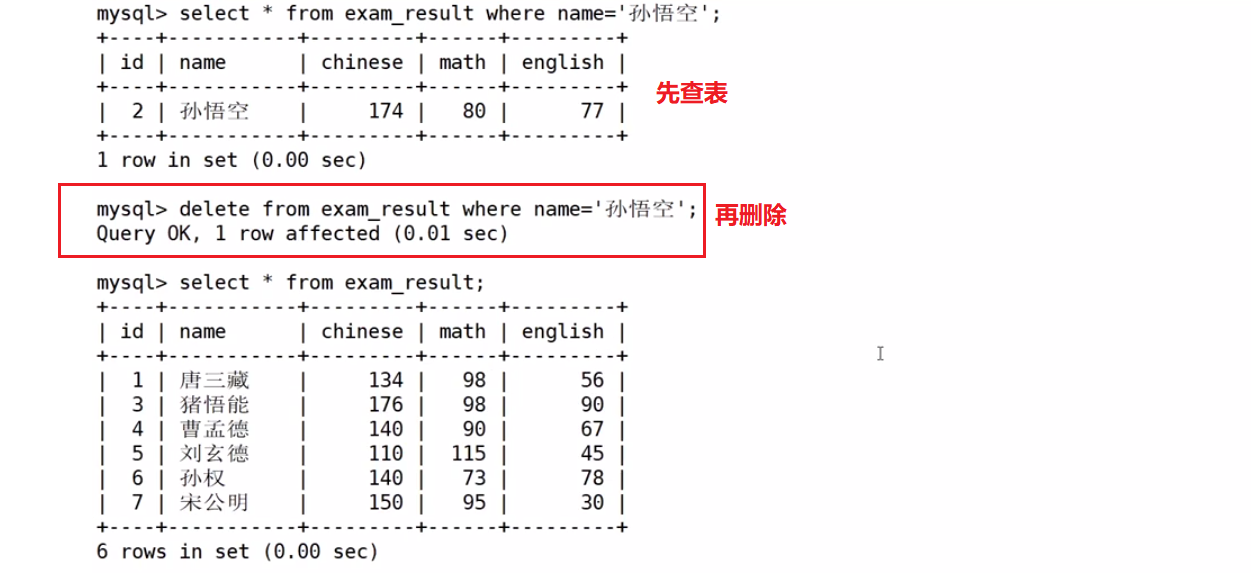
去掉班级的倒数第一名
delete from exam_result order by english+math+chinese asc limit 1;
删除整张表数据
delete只是删表数据,不删表结构。表结构是由alter来管理的
先新建表,并插入一点数据
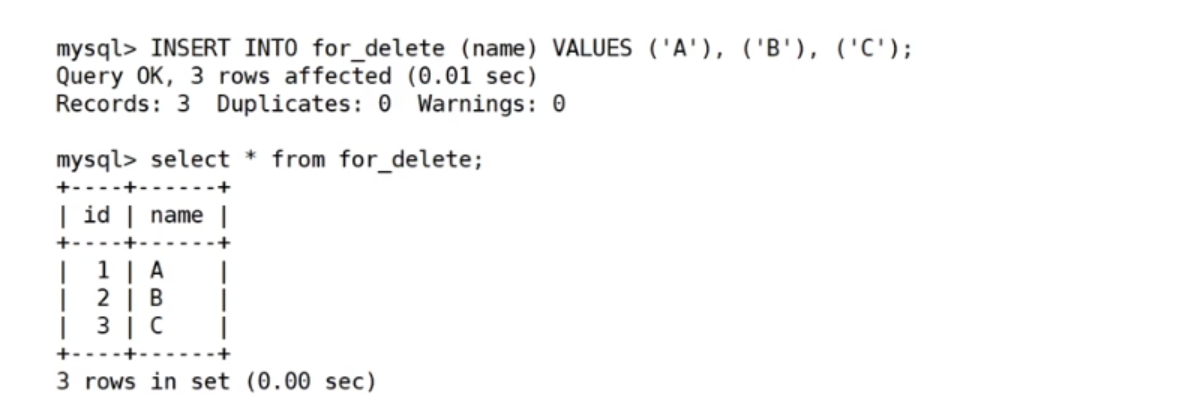
再查表的结构,然后再进行删除操作
 我们会发现我们只是把表数据给删除了,但是表的结构还在!!计数器没有变
我们会发现我们只是把表数据给删除了,但是表的结构还在!!计数器没有变
截断表(truncate)
语法
TRUNCATE [TABLE] table_name我们还按照刚才的例子重新测试下
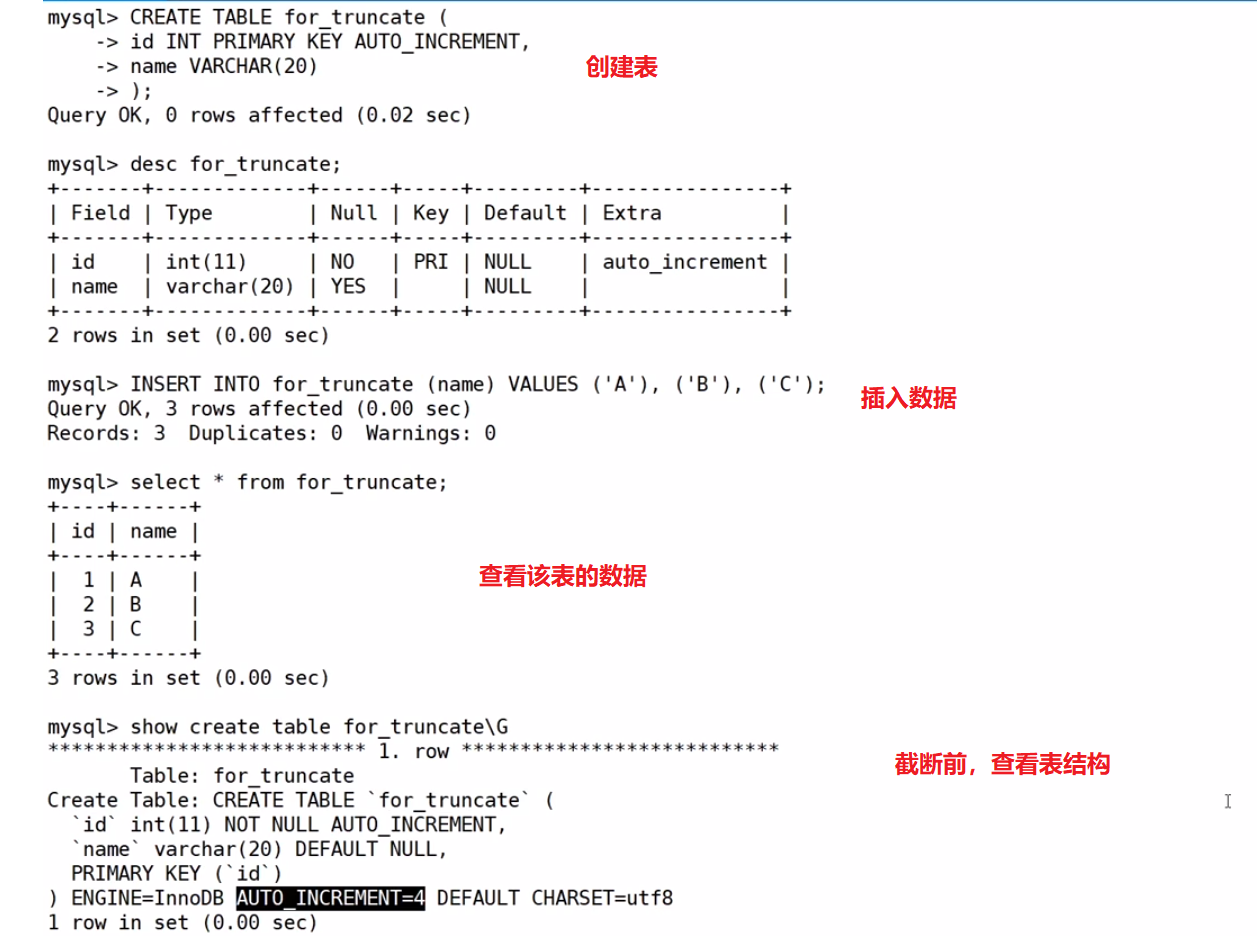
然后开始截断,并再次查看表数据和表结构

注意:这个操作慎用
只能对整表操作,不能像DELETE一样针对部分数据操作;
实际上MySQL 不对数据操作,所以比DELETE更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务(不会被记录到日志里),所以无法回滚
会重置AUTO_INCREMENT项
三种日志:
bin log: 历史上操作过的sql语句优化之后保留下来——方便主从同步、备份、恢复
redo log:确保宕机、断电的时候数据不丢失(因为数据可能在内存中存着)——保证崩溃安全
undo log:做事务回滚、事务的隔离性
插入查询结果(insert+select)
INSERT INTO table_name [(column [, column ...])] SELECT ...
删除表中的重复记录,重复的数据只能有一份
建表
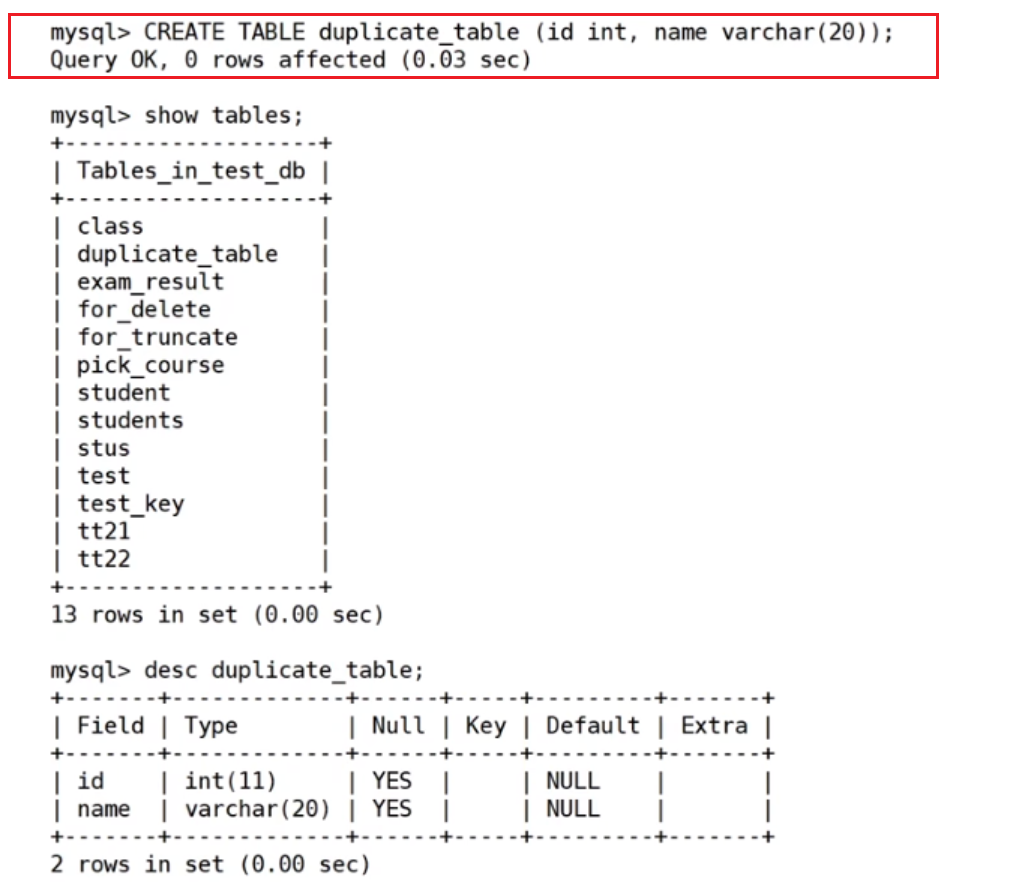 插入测试数据
插入测试数据
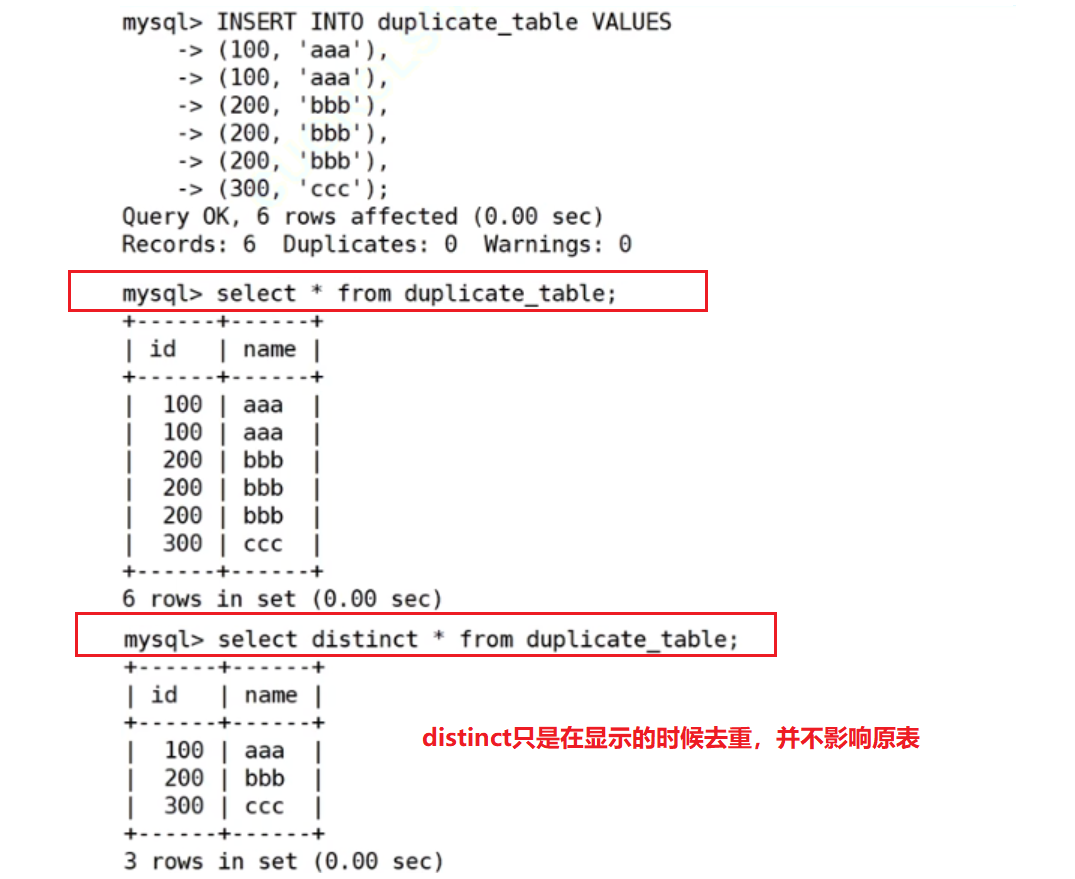
不能用distinct去重,因为它不影响原表的数据,而是修改的显示的数据
但是我们可以将insert和select结合起来用,将distinct筛选出来的数据插入到空表中!!然后再改一下表的名字!!
第一步:create table no_duplicate_table like duplicate_table;建立一张和原表结构相同的空表
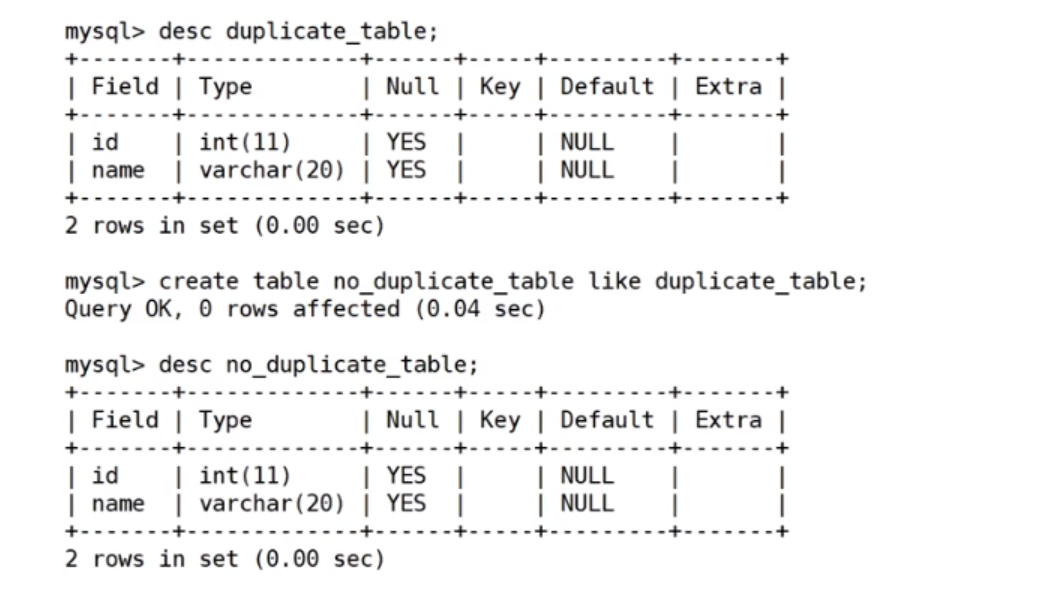
第二步:insert into no_duplicate_table select distinct * from duplicate_table; 查询原表去重后的结果然后插入到新表中

第三步:rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;将原表重命名备份一下,然后再把新表的名字改成原表的名字
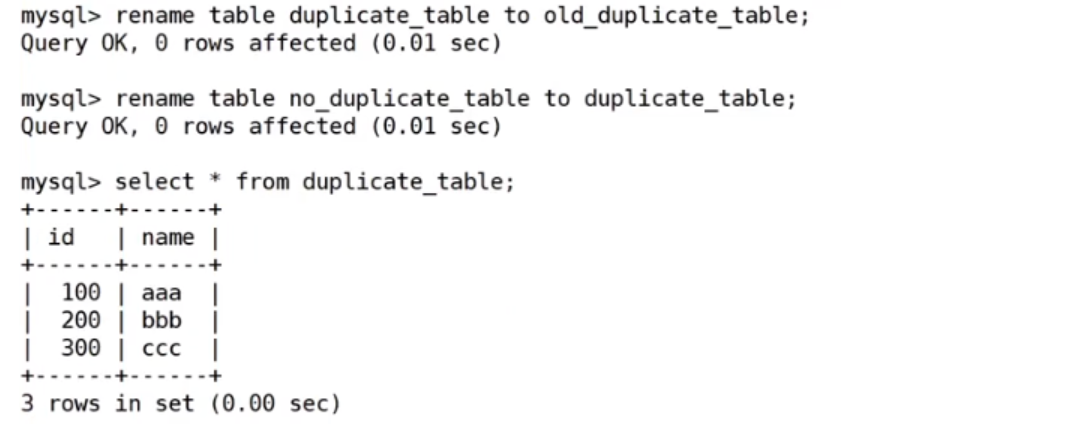
为什么最后是通过rename的方式进行的?
创建一个数据库其实就是创建一个文件夹,创建一张表其实就是创建一个文件,对应的系统调用就是mkdir和touch,而rename背后的也是类似rename这样的系统调用,平时我们用的move指令重命名也是类似的,如果我今天想把一个文件上传到linux下,可能上传得很慢,我想等这个文件上传好之后,把这个文件放到某个目录下,我希望他放入的过程是原子的,所以我们一定不能直接把这个文件直接上传到对应的目录下,因为上传的过程一直在写入,一定不是原子的,所以一般我们喜欢把这个要上传的文件上传到一个临时的目录下,等全都上传完成之后,再把整个文件move到特定的目录下,这个move是原子的。
所以总的来说,用rename单纯就是相等一切都就绪了,然后统一放入、更新、生效等。因为我们的move操作和重命名操作实际上就是在文件系统里就是改这个文件所在的目录里面文件名和inode的映射关系,他相较于冗长地向表中插入和冗长的上传行为比起来非常轻。很有可能我这个目录有很多文件包括正在操作的这个文件正在被外部的网站或者各种语言正在访问,所以我们不能着急动这个表而是应该先把这个表先传到临时目录然后再统一move过去,这是一种比较推荐的做法
聚合函数
统计班级共有多少同学
使用 * 做统计,不受 NULL 影响
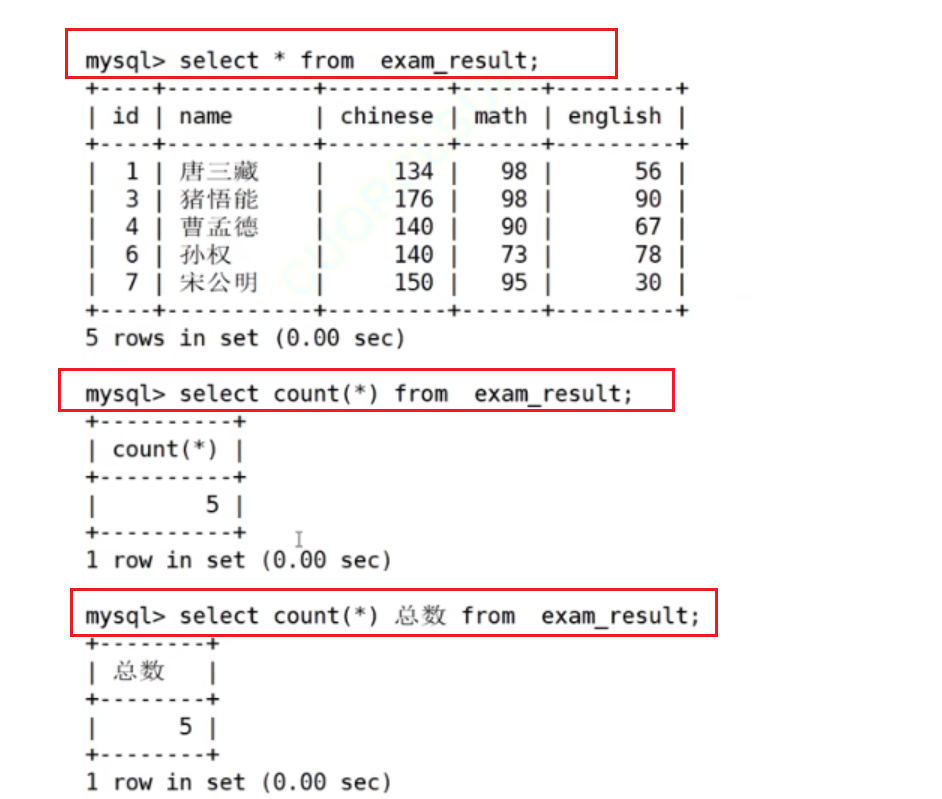
统计本次考试的数学成绩分数个数
NULL 不会计入结果
COUNT(math) 统计的是全部成绩

COUNT(DISTINCT math) 统计的是去重成绩数量

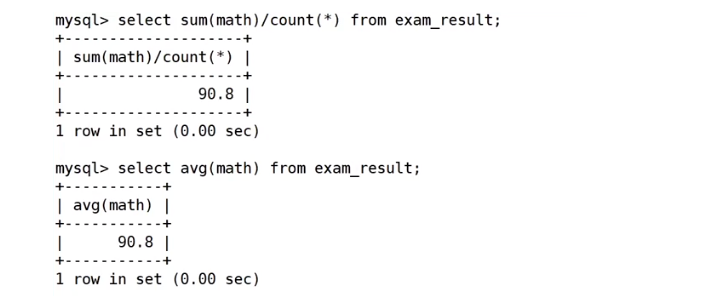
统计数学成绩总分

统计数学的平均分
数学不及格的人有多少

统计平均总分

返回英语最高分
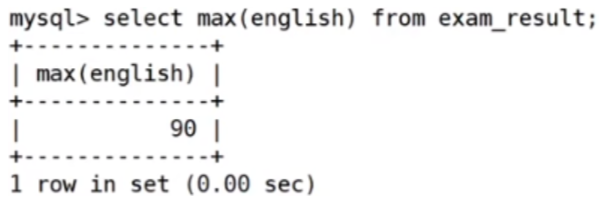
返回 > 70 分以上的数学最低分

聚合函数:1、在应用层上更多的是在未来进行某种程度上的数据统计,是有自己的现实需求的2、大部分聚合都是简单的场景,还有一部分场景需要对信息做完分组之后做聚合
分组聚合统计(group by)
分组的目的是为了方便后面的聚合统计 (比如说分成男生女生然后分别做统计)
在select中使用group by 子句可以对指定列进行分组查询
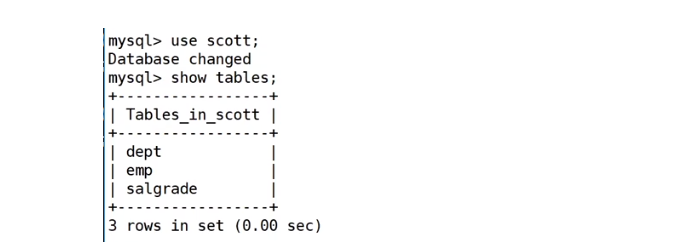
select column1, column2, .. from table group by column;案例:准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
1、EMP员工表
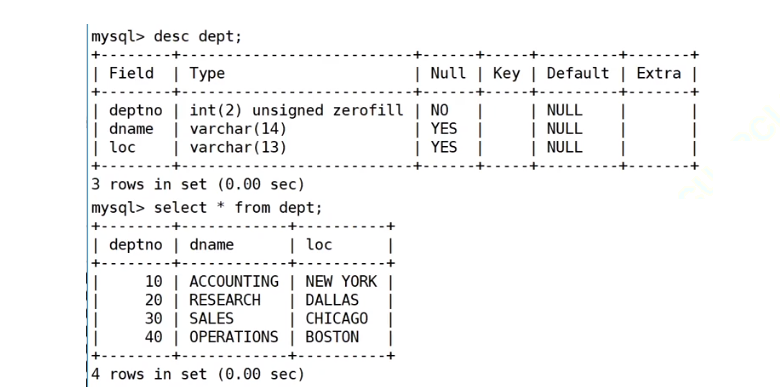
2、DEPT部门表
3、SALGRADE工资等级表
//利用source将该备份文件恢复到数据库中
DROP database IF EXISTS `scott`;//如果曾经有这个名字是数据库就删掉
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;//创建这个数据库USE `scott`;//使用这个数据库DROP TABLE IF EXISTS `dept`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `dept` (//创建部门表`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `emp` (//创建员工表`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',//外键`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'//外键
);DROP TABLE IF EXISTS `salgrade`;//如果有这个名字的部门表叫把他删掉
CREATE TABLE `salgrade` (//薪资表 可以客观反应这个员工在公司的重要程度`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);//插入部门
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');//核算部门
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');//搜索部门
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');//销售部门
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');//运营部门//插入员工
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);//插入不同等级的薪资
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);该数据库的表结构
表emp
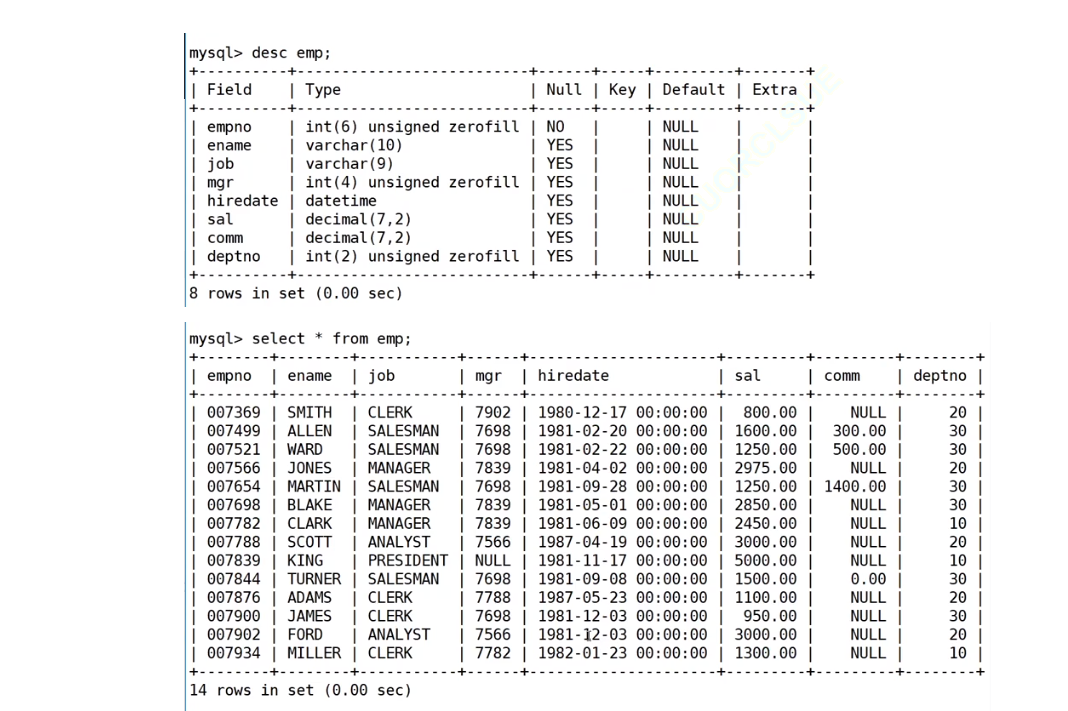
表 dept
表salgrade 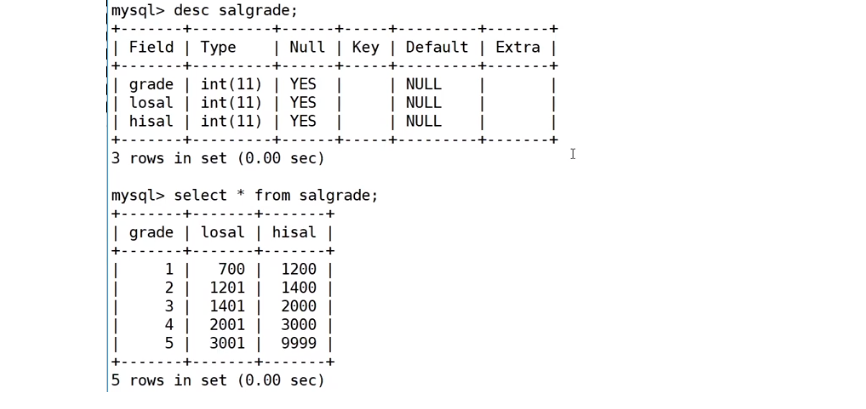
显示每个部分的平均工资和最高工资
select deptno,max(sal) 最高,avg(sal) 平均 from EMP group by deptno; from emp:- 从 emp(员工)表中查询数据
group by deptno:- 按部门编号(deptno)将员工数据分组
- 意味着所有具有相同部门编号的员工会被归类到同一个组
select部分:deptno:显示部门编号max(sal) 最高:计算每个部门的最高工资avg(sal) 平均:计算每个部门的平均工资
这个查询的具体含义是:
- 按部门编号(deptno)将员工表(emp)分组
- 对每个部门计算:
- 最高工资(max(sal))
- 平均工资(avg(sal))

groupby的宏观理解
让我们进行分组聚合统计的。分组指定列名,实际分组是用该列的不同的行数据
比如说你按照deptno进行分组,那它就会把deptno列中,相同的数据成为一组,也就是可以被聚合压缩。
分组,就是把一组按照条件拆成了多个组,然后进行各自组内的统计。
分组也就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对各自的子表进行聚合统计
显示每个部门的每种岗位的平均工资和最低工资
也就是说不仅要按照部门分组,也要按照岗位分组
用,来进行区分不同的组
select deptno,job from EMP group by deptno, job; 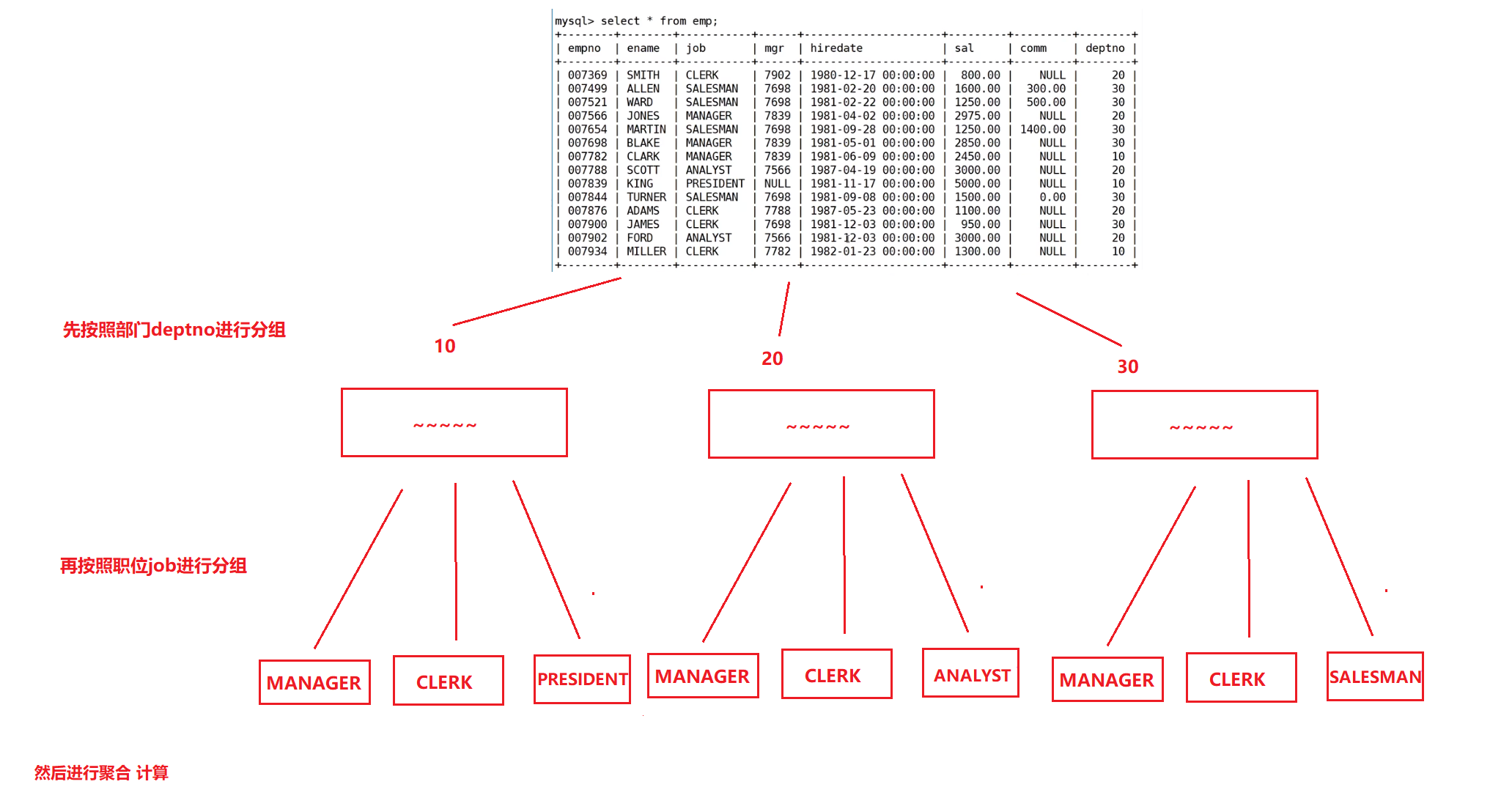
再聚合,也就是进行计算所需要的数据
select deptno,job,avg(sal) 平均,min(sal) 最低 from EMP group by deptno, job; 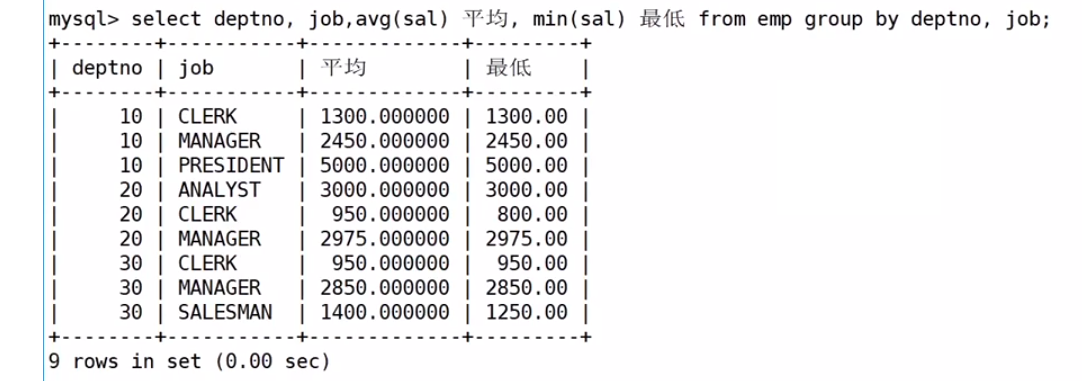
为啥进行员工名字ename分组的时候不行呢?

原因是ename没有在分组条件中出现,不属于分组条件,所以无法进行聚合和压缩。也就是说,select后面要想能出现,必须在group by后进行添加。
显示平均工资低于2000的部门和它的平均工资
第一步,先统计出来每一个部门的平均工资,然后在进行对比,也就是说先把结果聚合出来
select deptno,avg(sal) deptavg from EMP group by deptno;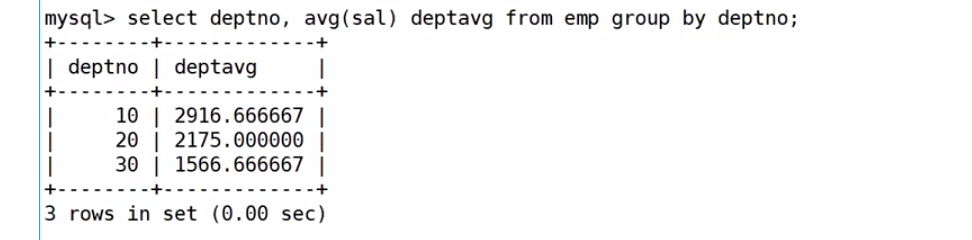
第二步,再进行判断。就是对聚合的结果进行判断
select deptno,avg(sal) deptavg from EMP group by deptno having deptavg<2000;
那怎么对聚合的结果进行判断呢?
having和group by配合使用,对group by结果进行过滤
having经常和group by搭配使用,作用是对聚合后的统计数据进行条件筛选,作用有些像where。
hvaing和where的区别理解是什么呢?

- 执行顺序不同:
- WHERE在分组和聚合函数计算之前执行
- HAVING在分组和聚合函数计算之后执行
- 作用对象不同:
- WHERE作用于表中的列/字段,筛选原始数据
- HAVING作用于分组后的结果集,可以使用聚合函数
不要单纯的认为,只有磁盘上表结构导入到mysql,真实存在的表才叫做表。中间筛选出来的,包括最终结果,全部都是逻辑上的表!“MySQL一切皆表”。也就是说未来只要我们处理好单表的CURD,所有的sql场景我们全部都能用统一的方式进行
面试题:SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
相关文章:
MySQL基础 [五] - 表的增删查改
目录 Create(insert) Retrieve(select) where条件 编辑 NULL的查询 结果排序(order by) 筛选分页结果 (limit) Update Delete 删除表 截断表(truncate) 插入查询结果(insertselect&…...

4.7学习总结 可变参数+集合工具类Collections+不可变集合
可变参数: 示例: public class test {public static void main(String[] args) {int sumgetSum(1,2,3,4,5,6,7,8,9,10);System.out.println(sum);}public static int getSum(int...arr){int sum0;for(int i:arr){sumi;}return sum;} } 细节:…...
OpenGL学习笔记(简介、三角形、着色器、纹理、坐标系统、摄像机)
目录 简介核心模式与立即渲染模式状态机对象GLFW和GLAD Hello OpenGLTriangle 三角形顶点缓冲对象 VBO顶点数组对象 VAO元素缓冲对象 EBO/ 索引缓冲对象 IEO 着色器GLSL数据类型输入输出Uniform 纹理纹理过滤Mipmap 多级渐远纹理实际使用方式纹理单元 坐标系统裁剪空间 摄像机自…...
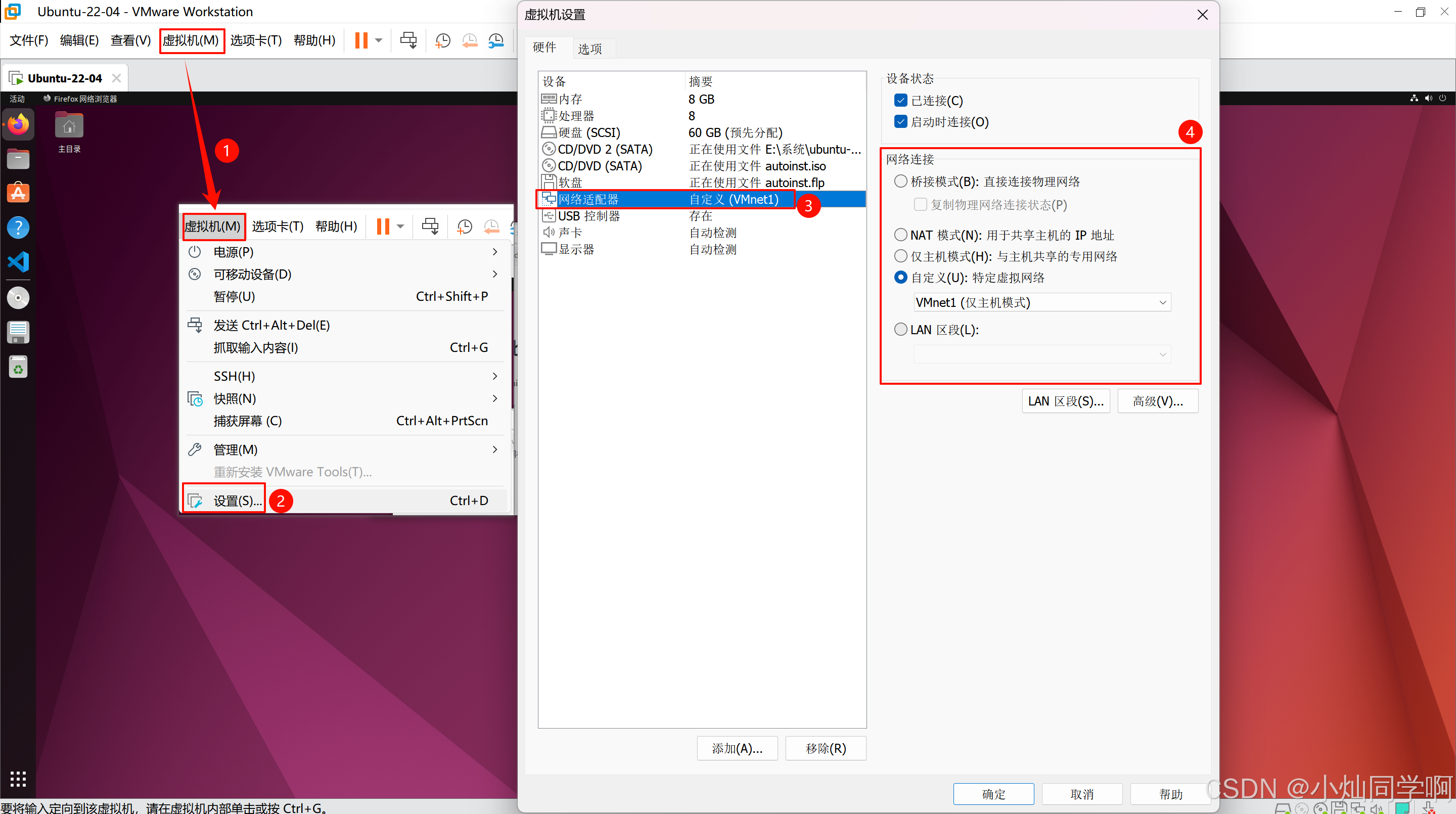
vmware虚拟机上Ubuntu或者其他系统无法联网的解决方法
一、检查虚拟机是否开启了网络服务 打开方式:控制面板->-管理工具--->服务 查找 VMware DHCP Service 和VMware NAT Service ,确保这两个服务已经启动。如下图,没有启动就点击启动。 二、设置网络类型 我们一般使用前两种多一些&…...
OpenVLA-OFT——微调VLA时加快推理的三大关键设计:支持动作分块的并行解码、连续动作表示以及L1回归(含输入灵活化及对指令遵循的加强)
前言 25年3.26日,这是一个值得纪念的日子,这一天,我司「七月在线」的定位正式升级为了:具身智能的场景落地与定制开发商 ,后续则从定制开发 逐步过渡到 标准产品化 比如25年q2起,在定制开发之外࿰…...

Linux脚本基础详解
一、基础知识 Linux 脚本主要是指在 Linux 系统中编写的用于自动化执行任务的脚本程序,其中最常用的便是 Bash 脚本。下面我们将从语法、使用方法和示例三个方面详细讲解 Linux 脚本。 1. 脚本简介 定义:Linux 脚本是一系列命令的集合,可以…...
LabVIEW 油井动液面在线监测系统
项目背景 传统油井动液面测量依赖人工现场操作,面临成本高、效率低、安全风险大等问题。尤其在偏远地区或复杂工况下,测量准确性与时效性难以保障。本系统通过LabVIEW虚拟仪器技术实现硬件与软件深度融合,为油田智能化转型提供实时连续监测解…...
泛微ECOLOGY9 解决文档中打开发票类PDF文件无内容的配置方法
解决文档中打开发票类PDF文件无内容的配置方法 情况如下: 如果OA文档中打开的PDF文件如下图这样空白的,那么可以试试下面的方法进行解决。 解决方法: 在OA安装目录中找到 ecology/WEB-INF/prop/docpreview.properties 配置文件ÿ…...

大模型RAG项目实战-知识库问答助手v1版
安装 Ollama 根据官网指导,安装对应版本即可。 下载安装指导文档: handy-ollama/docs/C1/1. Ollama 介绍.md at main datawhalechina/handy-ollama 注意:在 Windows 下安装 Ollama 后,强烈建议通过配置环境变量来修改模型存储…...
统计子矩阵
1.统计子矩阵 - 蓝桥云课 统计子矩阵 问题描述 给定一个 NM 的矩阵 A,请你统计有多少个子矩阵(最小 11,最大 NM)满足子矩阵中所有数的和不超过给定的整数 K? 输入格式 第一行包含三个整数 N,M 和 K。 …...

Vue.js 实现下载模板和导入模板、数据比对功能核心实现。
在前端开发中,数据比对是一个常见需求,尤其在资产管理等场景中。本文将基于 Vue.js 和 Element UI,通过一个简化的代码示例,展示如何实现“新建比对”和“开始比对”功能的核心部分。 一、功能简介 我们将聚焦两个核心功能&…...

C++第1讲:基础语法;通讯录管理系统
黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难_哔哩哔哩_bilibili 对应的笔记: https://github.com/AccumulateMore/CPlusPlus 标签: C&C | welcome to here 一、C初识 1.1.注释 1.2.变量 1.3.常量:记录程序中不可更改的数据 1.4.关…...

关于Spring MVC处理JSON数据集的详细说明,涵盖如何接收和发送JSON数据,包含代码示例和总结表格
以下是关于Spring MVC处理JSON数据集的详细说明,涵盖如何接收和发送JSON数据,包含代码示例和总结表格: 1. 核心机制 Spring MVC通过以下方式支持JSON数据的传输: 接收JSON数据:使用RequestBody注解将HTTP请求体中的J…...

MySQL 隐式转换与模糊匹配的索引使用分析
MySQL 隐式转换与模糊匹配的索引使用分析 MySQL服务版本字段结构索引结构查询分析int索引查询varchar 索引查询 like 匹配总结 MySQL服务版本 版本信息:Server version: 8.0.30 MySQL Community Server - GPL 字段结构 mysql> desc connection; -------------…...
)
DNS服务(Linux)
DNS 介绍 dns,Domain Name Server,它的作用是将域名解析为 IP 地址,或者将IP地址解析为域名。 这需要运行在三层和四层,也就是说它需要使用 TCP 或 UDP 协议,并且需要绑定端口,53。在使用时先通过 UDP 去…...

【愚公系列】《高效使用DeepSeek》058-选题策划
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

Python高阶函数-filter
1. 基本概念 filter() 是Python内置的高阶函数,用于过滤序列中的元素。它接收一个函数和一个可迭代对象作为参数,返回一个迭代器,包含使函数返回True的所有元素。 filter(function, iterable)2. 工作原理 惰性计算:filter对象是…...
时自动输出COCO指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO验证(Val)时自动输出COCO指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(3):验证(Val) 启用 COCO API 评估(自动输出AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 触发 COCO JSON 保存步骤 2: 确保 self.is_coc…...

MySql表达式中字符串类型与整型的隐式转换
隐式转换 当运算符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。 mysql> SELECT 11;-> 2 mysql> SELECT CONCAT(2, test);-> 2…...
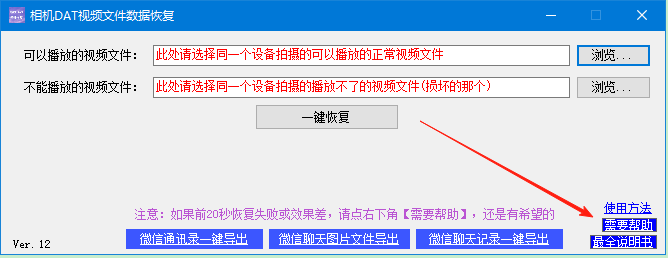
拍摄的婚庆视频有些DAT的视频文件打不开怎么办
3-12 现在的婚庆公司大多提供结婚的拍摄服务,或者有一些第三方公司做这方面业务,对于视频拍摄来说,有时候会遇到这样一种问题,就是拍摄下来的视频文件,然后会有一两个视频文件是损坏的,播放不了࿰…...

Zephyr与Linux核心区别及适用领域分析
一、核心定位与目标场景 特性Zephyr RTOSLinux目标领域物联网终端、实时控制系统(资源受限设备)服务器、桌面系统、复杂嵌入式设备(如路由器)典型硬件MCU(ARM Cortex-M, RISC-V),内存<1MBMP…...
图灵逆向——题一-动态数据采集
目录列表 过程分析代码实现 过程分析 第一题比较简单,直接抓包即可,没有任何反爬(好像头都不用加。。。) 代码实现 答案代码如下: """ -*- coding: utf-8 -*- File : .py author : 鲨鱼爱兜兜 T…...
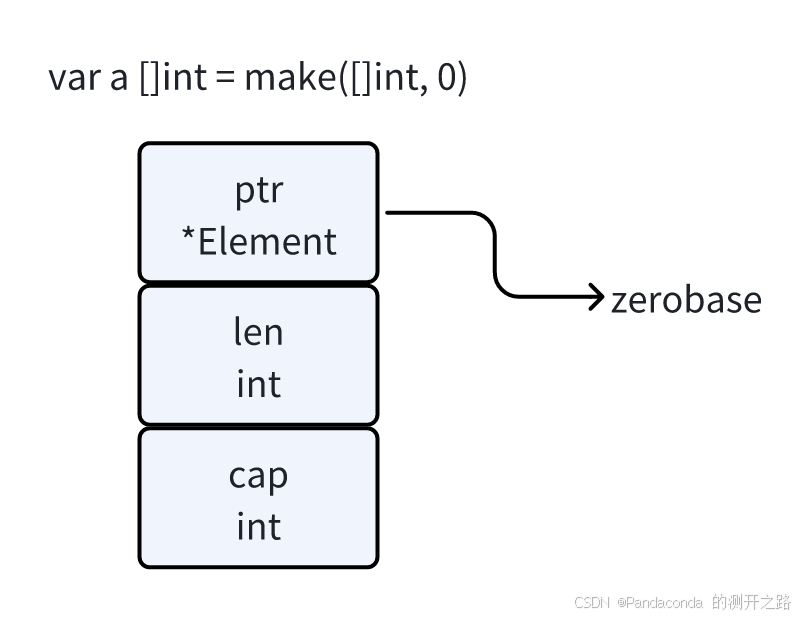
【新人系列】Golang 入门(十二):指针和结构体 - 上
✍ 个人博客:https://blog.csdn.net/Newin2020?typeblog 📝 专栏地址:https://blog.csdn.net/newin2020/category_12898955.html 📣 专栏定位:为 0 基础刚入门 Golang 的小伙伴提供详细的讲解,也欢迎大佬们…...
Day20 -实例:红蓝队优秀集成式信息打点工具的配置使用
一、自动化-企业查询 ----ENScan 原理:集成企查查、爱企查、chinaz等,剑指hw/src。 1)首次使用先创建config文件 确认一下生成了 2)配置cookie 各个平台不一样,根据github作者的教程来【放入github收藏夹了】 我这…...

MySQL学习笔记五
第七章数据过滤 7.1组合WHERE子句 7.1.1AND操作符 输入: SELECT first_name, last_name, salary FROM employees WHERE salary < 4800 AND department_id 60; 输出: 说明:MySQL允许使用多个WHERE子句,可以以AND子句或OR…...

Python爬虫第5节-urllib的异常处理、链接解析及 Robots 协议分析
目录 一、处理异常 1.1 URLError 1.2 HTTPError 二、解析链接 2.1 urlparse() 2.2 urlunparse() 2.3 urlsplit() 2.4 urlunsplit() 2.5 urljoin() 2.6 urlencode() 2.7 parse_qs() 2.8 parse_qsl() 2.9 quote() 2.10 unquote() 三、分析网站Robots协议 3.1 R…...

26届Java暑期实习面经,腾讯视频一面
短链接的生成原理 如何解决短链接生成的哈希冲突问题 如何加快从短链接到原链接的重定向过程 TCP 和 UDP 协议 如何理解 TCP 是面向连接的 为什么 TCP 的握手是 3 次 IO 模式 是否有真正写过一个底层的 Socket 通信 MySQL 的事务隔离级别 MVCC 机制 什么叫服务的并行 为什么能基…...

Kafka负载均衡挑战解决
本文为 How We Solve Load Balancing Challenges in Apache Kafka 阅读笔记 kafka通过利用分区来在多个队列中分配消息来实现并行性。然而每条消息都有不同的处理负载,也具有不同的消费速率,这样就有可能负载不均衡,从而使得瓶颈、延迟问题和…...

前端性能优化的全方位方案【待进一步结合项目】
以下是前端性能优化的全方位方案,结合代码配置和最佳实践,涵盖从代码编写到部署的全流程优化: 一、代码层面优化 1. HTML结构优化 <!-- 语义化标签减少嵌套 --> <header><nav>...</nav> </header> <main&…...
2025年第二期PMP考试中文报名时间定了!
近日,官方发布了《关于2025年6月15日PMI认证考试的报名通知》。根据通知,中国大陆地区2025年第二期PMI认证考试将于6月15日举行,中文报名将于4月17日正式开始。 一、报名安排 为缓解报名高峰期的网络拥堵,本次考试将采取分地区、…...