Kafka负载均衡挑战解决
本文为 How We Solve Load Balancing Challenges in Apache Kafka 阅读笔记
kafka通过利用分区来在多个队列中分配消息来实现并行性。然而每条消息都有不同的处理负载,也具有不同的消费速率,这样就有可能负载不均衡,从而使得瓶颈、延迟问题和整体系统不稳定,进而导致额外的维护工作或额外的资源分配。
在 Kafka 中,分区器和分配器策略会影响消息分发。
Producer 分区器
- Round-robin:平均分配消息至各分区。
- Sticky partitioning:短时间内固定分配到一个分区,减少 rebalance 影响。
Consumer 分配器
- Range、Round-robin:静态分配分区给消费者。
这些策略都是基于两个主要的假设
- 消费者具有相同的处理能力
- 消息的工作量都相等
挑战
异构硬件
不同的服务器硬件代次的性能不同,从而导致处理速率不同。
消息工作负载不均衡
不同的消息可能需要一组不同的处理步骤。例如,处理消息可能涉及调用第三方 HTTP 终端节点,不同的响应大小或延迟可能会影响处理速率。此外,对于涉及数据库作的应用程序,其数据库查询的延迟可能会根据查询参数而波动,从而导致处理速率不同。
过度配置
在资源分配过程中,系统为应对预期峰值负载而分配了远超实际需求的资源,导致资源利用率低下和成本浪费
假设我们的高吞吐量和低吞吐量的处理速率分别为 20 msg/s 和 10 msg/s(根据表 1 中的数据简化)。使用两个较快的处理器和一个较慢的处理器,我们预计总容量为 20+20+10 = 50 条消息/秒。

但由于轮询均匀分配消息(每台处理器分到约16.67 msg/s),低速处理器无法处理其份额,实际系统仅能处理30 msg/s(10×3),剩余消息堆积,引发延迟。
静态平衡方案
相同pod上部署
可以考虑控制服务部署中使用的硬件类型以缓解问题。
加权负载均衡
如果容量是可预测的,并且大部分时间保持不变,则为不同的使用者分配不同的权重有助于最大限度地利用可用资源。例如,在为性能更好的使用者提供更高的权重后,我们还可以将更多流量路由到这些使用者。
响应式延迟感应
虽然是可以估算负载来通过加权方式来进行负载均衡,然而
- 消息在工作负载中并不统一,因此难以估计计算机容量
- 依赖项(例如网络和第三方连接)不稳定,有时会导致实际处理中的容量发生变化
- 系统若经常添加新功能,会增加额外的维护工作以保持权重更新
为了解决这些问题,我们在系统中实施了延迟感知机制,以动态监控每个分区中的当前延迟,并根据当前流量状况做出相应的响应。
- Log-aware Producer: 利用动态分区逻辑来考虑目标主题的滞后信息
- Log-aware Consumer: 监控当前的滞后,并在必要时自行取消订阅以触发负载的重新平衡。通常,可以采用自定义再平衡策略来调整分区分配。

Log-aware Producer
以下是不应该使用的情况下
- 纯消费类应用 :您的应用不控制消息的生产
- 多消费组:当生成的消息被多个消费组使用时,滞后感知创建器可能会为其他消费组生成不必要的倾斜负载,因为滞后是特定于一个消费组的信息
相同队列长度算法
此算法将每个分区滞后视为处理的队列大小。获取滞后信息后,它会发布适当数量的消息以填充短队列。
这种方法更适合于由于异构硬件而导致的偏斜滞后分布,其中高性能 Pod(机器)在大多数情况下能够更快地处理。
适用场景:
- 硬件异构(部分节点性能强,部分弱)。
- 消息处理时间相对稳定,但节点处理能力差异显著。

def same_queue_length_algorithm(partitions, current_lags): total_messages = 100 # 假设本次需分配100条消息 avg_lag = sum(current_lags) / len(partitions) # 计算平均队列长度 # 计算每个分区应分配的消息量:目标是将Lag降至avg_lag messages_per_partition = [] for partition, lag in zip(partitions, current_lags): if lag < avg_lag: # 低Lag分区:分配更多消息以填充队列 messages = total_messages * (avg_lag - lag) / sum(max(avg_lag - lag, 0) for l in current_lags) else: # 高Lag分区:分配较少消息 messages = 0 # 或按比例减少 messages_per_partition.append(messages) return messages_per_partition
示例:
- 分区Lag:
[10, 30, 50](目标平均Lag = 30) - 分配结果:
- 分区1(Lag=10):分配较多消息(拉长队列至30)。
- 分区3(Lag=50):暂停分配,直到Lag降低。
异常值检测算法
利用统计方法来确定所有分区的高延迟异常值,并暂时停止那些缓慢异常值的消息发送过程。为了满足我们的特定需求,已经提出了 IQR(四分位间距)和 STD(标准差)异常值检测算法

- Slow partition: 由于存在滞后,这些分区的消息发布已停止
- OK partition: 为了提高性能不佳的计算机的性能,当系统尝试将慢速分区提升为良好分区时,会添加观察期。此观察阶段可以通过仅生成一小部分消息并进行观察来优化为“半开”状态。当滞后获取间隔相对较长时,半开是有益的,因为它可以防止使用者在尚未查询更新的滞后数据时延迟等待传入消息的情况
- Good partition: 照常发布并均匀分布到所有 Good Partitions
适用于
- 突发性延迟。比如依赖服务超时
- 动态负载波动大
def outlier_detection_algorithm(partitions, current_lags): # 使用IQR方法检测异常值 q1, q3 = np.percentile(current_lags, [25, 75]) iqr = q3 - q1 upper_bound = q3 + 1.5 * iqr # 定义高延迟阈值 # 分区状态判断 for partition, lag in zip(partitions, current_lags): if lag > upper_bound: partition.state = "Closed" # 停止分配 elif partition.state == "Closed" and lag < q3: partition.state = "Half-Open" # 试探性恢复 elif partition.state == "Half-Open": if lag < q1: partition.state = "Open" # 完全恢复 else: partition.state = "Closed" # 重新关闭 # 仅向Open/Half-Open分区分配消息 open_partitions = [p for p in partitions if p.state != "Closed"] messages_per_partition = distribute_evenly(open_partitions) # 均匀分配 return messages_per_partition
示例:
- 分区Lag:
[10, 12, 15, 100](IQR计算后,100被识别为异常值) - 操作:
- 分区4标记为
Closed,暂停消息分配。 - 其余分区均匀分配消息。
- 分区4标记为
Log-aware Consumer
当多个消费者组订阅同一主题时,生产者基于单一消费者组的延迟调整分区流量,可能导致其他消费者组负载失衡
因此直接在消费者侧引入实现动态负载均衡
主动退订
消费者实例监测自身处理延迟(Lag),若发现某些分区积压严重(如因硬件性能差),可主动退订这些分区,触发 Kafka 的 重平衡(Rebalance)。
在重平衡过程中,通过自定义的分区分配策略(如基于机器性能指标或实时 Lag 数据),将高负载分区重新分配给性能更强的消费者实例。
相关文章:
Kafka负载均衡挑战解决
本文为 How We Solve Load Balancing Challenges in Apache Kafka 阅读笔记 kafka通过利用分区来在多个队列中分配消息来实现并行性。然而每条消息都有不同的处理负载,也具有不同的消费速率,这样就有可能负载不均衡,从而使得瓶颈、延迟问题和…...

前端性能优化的全方位方案【待进一步结合项目】
以下是前端性能优化的全方位方案,结合代码配置和最佳实践,涵盖从代码编写到部署的全流程优化: 一、代码层面优化 1. HTML结构优化 <!-- 语义化标签减少嵌套 --> <header><nav>...</nav> </header> <main&…...
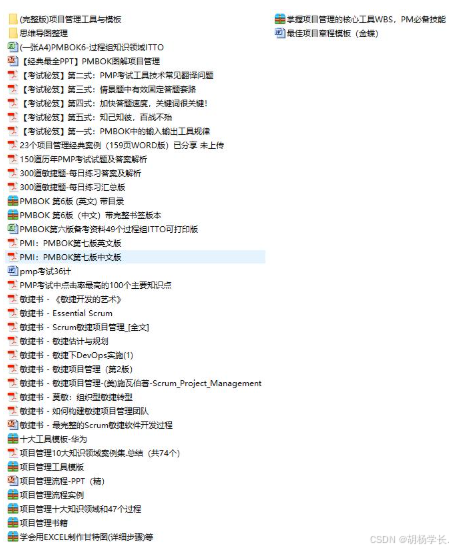
2025年第二期PMP考试中文报名时间定了!
近日,官方发布了《关于2025年6月15日PMI认证考试的报名通知》。根据通知,中国大陆地区2025年第二期PMI认证考试将于6月15日举行,中文报名将于4月17日正式开始。 一、报名安排 为缓解报名高峰期的网络拥堵,本次考试将采取分地区、…...
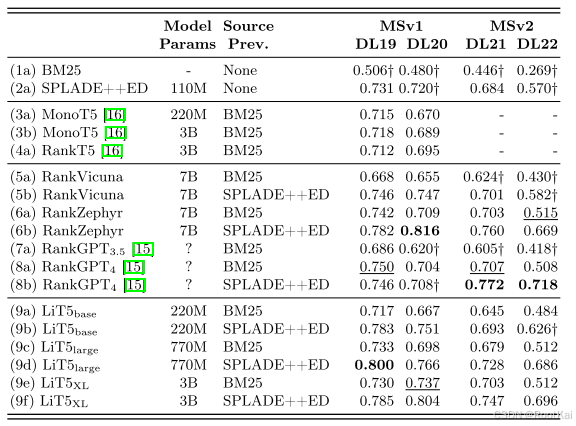
LiT and Lean: Distilling Listwise Rerankers intoEncoder-Decoder Models
文章:ECIR 2025会议 一、动机 背景:利用LLMs强大的能力,将一个查询(query)和一组候选段落作为输入,整体考虑这些段落的相关性,并对它们进行排序。 先前的研究基础上进行扩展 [14,15],…...

【Java面试系列】Spring Boot微服务架构下的分布式事务处理与Seata框架实现原理详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Boot微服务架构下的分布式事务处理与Seata框架实现原理详解 - 3-5年Java开发必备知识 1. 引言 在微服务架构中,分布式事务处理是一个不可避免的挑战。随着业务复杂度的提升,单体应用逐渐演变为微服务架构,而分布式事…...

源码分析之Leaflet图层控制控件Control.Layers实现原理
概述 本文将介绍Leaflet库中最后一个组件,即图层控制组件 Control.Layers。 源码实现 export var Layers Control.extend({options: {collapsed: true,position: "topright",autoZIndex: true,hideSingleBase: false,sortLayers: false,sortFunction:…...

嵌入式软硬件开发,常见通信总线
嵌入式通信总线分类与应用指南 一、片上/板级通信接口(内部互联) I2C总线 核心特性 同步半双工传输,SCL时钟线SDA数据线7/10位地址寻址,支持多主多从架构标准模式100kbps,高速模式3.4Mbps,超高速模式5Mbps…...

[ERROR] Some problems were encountered while processing the POMs
记录一次maven的错误 问题复现: 我在ruoyi-vue-plus项目的ruoyi-modules中新建了一个子项目ruoyi-network-telphonem,然后某一次编译的时候提示SysTenantServiceImpl找不到无参的构造函数,检查了很久都没发现问题,于是我想着删掉本地maven仓…...

Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行?
环境: Ubuntu 20.04 LTS 问题描述: Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行? bash docker/entrypoint.sh解决方案: bash docker/entrypoint.sh 脚本在后台运行&…...

前端工具方法整理
文章目录 1.在数组中找到匹配项,然后创建新对象2.对象转JSON字符串3.JSON字符串转JSON对象4.有个响应式对象,然后想清空所有属性5.判断参数不为空6.格式化字符串7.解析数组内容用逗号拼接 1.在数组中找到匹配项,然后创建新对象 const modifi…...
关于Deepseek本地AI知识文档库被联网访问方法的探索
背景: 根据前面的文章,我们使用了anythingLLM搭建了本地知识库,这个虽然基本可以用了,但是你只能在anythingLLM的界面里面进行提问,自能自己用,那么能否让其他人也可以使用我们搭建的本地知识库呢根据我的…...

一个简单的跨平台Python GUI自动化 AutoPy
象一下,你坐在电脑前,手指轻轻一点,鼠标自己动了起来,键盘仿佛被无形的手操控,屏幕上的任务自动完成——这一切不需要你费力,只靠几行代码就能实现。这就是AutoPy的魅力,一个简单却强大的跨平台…...

面试题汇总06-场景题线上问题排查难点亮点
面试题汇总06-场景题&线上问题排查&难点亮点 【一】场景题【1】订单到期关闭如何实现【2】每天100w次登录请求,4C8G机器如何做JVM调优?(1)问题描述和分析(2)堆内存设置(3)垃圾收集器选择(4)各区大小设置(5)添加必要的日志【3】如果你的业务量突然提升100倍…...

【嵌入式系统设计师】知识点:第4章 嵌入式系统软件基础知识
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

基于RDK X3的“校史通“机器人:SLAM导航+智能交互,让校史馆活起来!
视频标题: 【校史馆の新晋顶流】RDK X3机器人:导览员看了直呼内卷 视频文案: 跑得贼稳团队用RDK X3整了个大活——给校史馆造了个"社牛"机器人! 基于RDK X3开发板实现智能导航与语音交互SLAM技术让机器人自主避障不…...

春芽儿智能跳绳:以创新技术引领运动健康新潮流
在全球运动健康产业蓬勃发展的浪潮中,智能健身器材正成为连接科技与生活的重要纽带。据《中国体育用品产业发展报告》显示,2023年中国智能运动装备市场规模突破千亿元,其中跳绳类目因兼具大众普及性与技术升级空间,年均增速超30%。…...

复活之我会二分
文章目录 整数二分模板模板1:满足条件的第一个数模板2:满足条件的最后一个数 浮点数二分模板一、Building an Aquarium思路分析具体代码 二、Tracking Segments思路分析具体代码 三、Wooden Toy Festival思路分析具体代码 四、路标设置思路分析具体代码 …...

NOA是什么?国内自动驾驶技术的现状是怎么样的?
国内自动驾驶技术的现状如何? 汽车的NOA指的是“Navigate on Autopilot”,即导航辅助驾驶或领航辅助驾驶。这是一种高级驾驶辅助系统(ADAS)的功能,它允许车辆在设定好起点和终点后,自动完成行驶、超车、变…...

秒杀系统的性能优化
秒杀任务总体QPS预期是每秒几十万,对tomcat、redis、JVM参数进行优化。 tomcat线程数 4核8G的机器,一般就是开200-300个工作线程,这是个经验值。每秒一个线程处理3-5个请求,200多个线程的QPS可以达到1000左右。线程不能太多&…...

Linux 指令初探:开启终端世界的大门
前言 当我们初次接触 Linux,往往会被一串串在黑底屏幕中跳动的字符震撼甚至吓退。然而,正是这些看似晦涩的命令,构建了服务器、嵌入式系统乃至云计算的世界。 本篇将带你从最基础的 Linux 指令开始,逐步揭开命令行的神秘面纱。从…...

Edge浏览器IE兼容模式设置
一、了解Edge浏览器的IE模式 Microsoft Edge,作为微软推出的新一代浏览器,不仅拥有更快的浏览速度、更强大的安全性能以及更现代的界面设计,还巧妙地解决了与旧网站和应用程序的兼容性问题。通过内置的IE模式,Edge能够模拟IE浏览器…...

文件中魔数
当然可以,来讲几个实际开发中魔数会“救你一命”的场景,帮助你更直观地理解它的作用。 🎯 场景 1:误读取非 SST 文件 假设你有一段代码在扫描一个目录,尝试打开所有 .sst 后缀的文件并加载: cpp 复制 编辑…...

制定大运维管理体系的标准、流程、机制、规范
规划并制定大运维管理体系的标准、流程、机制、规范,对于确保平台的可用性和稳定性至关重要。这一过程涉及从顶层设计到具体执行的全面考量,需要综合考虑业务需求、技术架构、团队能力等多方面因素。以下是一个基本框架,用于指导如何构建有效…...

算法初识-时间复杂度空间复杂度
注:观看Adbul Bari算法视频 算法概念 算法:先验分析,不依托于硬件,无语言限制,逻辑。 程序:后验测试,依托硬件,语言限制,实现。 特点: 输入-0或多个输出-至…...

Python高阶函数-sorted(深度解析从原理到实战)
一、sorted()函数概述 sorted()是Python内置的高阶函数,用于对可迭代对象进行排序操作。与列表的sort()方法不同,sorted()会返回一个新的已排序列表,而不改变原数据。 基本语法 sorted(iterable, *, keyNone, reverseFalse)二、核心参数详…...

Vue3实战三、Axios封装结合mock数据、Vite跨域及环境变量配置
目录 Axios封装、调用mock接口、Vite跨域及环境变量配置封装Axios对象调用mock接口数据第一步、安装axios,处理一部请求第二步、创建request.ts文件第三步、本地模拟mock数据接口第四步、测试axiosmock接口是否可以调用第五步、自行扩展 axios 返回的数据类型 axios…...

机器学习(神经网络基础篇)——个人理解篇5(梯度下降中遇到的问题)
在神经网络训练中,计算参数的梯度是关键步骤。numerical_gradient 方法旨在通过数值微分(中心差分法)计算损失函数对网络参数的梯度。然而,该方法的实现存在一个关键问题,导致梯度计算错误。 1、错误代码示例…...

sklearn的Pipeline
Pipeline类 介绍:Pipeline 可以将多个数据处理步骤和机器学习模型组合成一个序列,其中每个步骤都是一个变换器(Transformer)或者估计器(Estimator),并且Pipeline中的最后一个必须为估计器,其它的必须为变换器,如果Pipeline中的估计器为为分类器则整个Pipeline就作为分…...
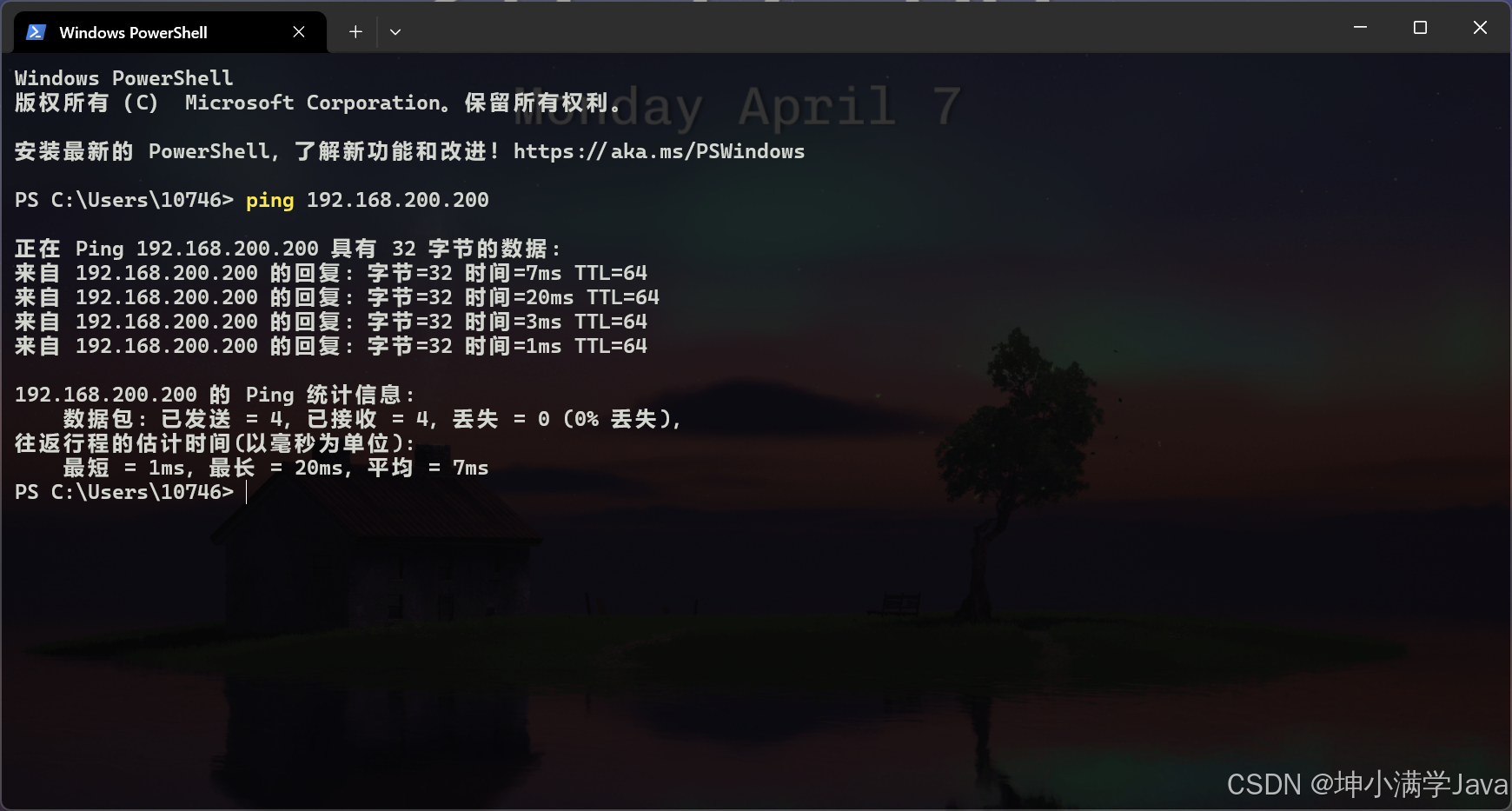
【Linux】虚拟机设置静态IP
主播我今天下午学了几节微服务课,上课的时候,直接把手机拿走了去上课(电脑连的我手机的热点),虚拟机没关,晚上主播我回来继续学,电脑连上热点之后,发现虚拟机连接不上了,…...

职坐标解析自动驾驶技术发展新趋势
内容概要 作为智能交通革命的核心驱动力,自动驾驶技术正以惊人的速度重塑出行生态。2023年,行业在多传感器融合与AI算法优化两大领域实现突破性进展:激光雷达、摄像头与毫米波雷达的协同精度提升至厘米级,而深度学习模型的实时决…...