Python高阶函数-sorted(深度解析从原理到实战)

一、sorted()函数概述
sorted()是Python内置的高阶函数,用于对可迭代对象进行排序操作。与列表的sort()方法不同,sorted()会返回一个新的已排序列表,而不改变原数据。
基本语法
sorted(iterable, *, key=None, reverse=False)
二、核心参数详解
1. iterable(必需参数)
任何可迭代对象(列表、元组、字符串、字典等)
2. key(关键参数)
- 接受一个函数作为参数
- 该函数会被应用到每个元素上,根据函数返回值进行排序
- 默认值为
None,表示直接比较元素本身
3. reverse(排序方向)
- 布尔值参数
False表示升序(默认)True表示降序
三、底层实现原理
sorted()内部使用TimSort算法(一种混合了归并排序和插入排序的稳定算法):
- 时间复杂度:O(n log n)
- 空间复杂度:O(n)
- 稳定性:保持相等元素的原始顺序
# 伪代码展示基本逻辑
def sorted(iterable, key=None, reverse=False):# 1. 获取可迭代对象的元素列表elements = list(iterable)# 2. 如果有key函数,应用转换if key is not None:decorated = [(key(x), i, x) for i, x in enumerate(elements)]else:decorated = elements# 3. 执行TimSort排序decorated.sort()# 4. 还原原始数据(保持稳定性)if key is not None:result = [x for (k, i, x) in decorated]else:result = decorated# 5. 处理排序方向if reverse:result.reverse()return result
四、高级使用技巧
1. 复杂对象排序
students = [{'name': 'Alice', 'age': 20, 'score': 85},{'name': 'Bob', 'age': 19, 'score': 92},{'name': 'Charlie', 'age': 21, 'score': 78}
]# 按分数降序排序
sorted_students = sorted(students, key=lambda x: x['score'], reverse=True)
2. 多条件排序
# 先按年龄升序,年龄相同按分数降序
sorted_students = sorted(students,key=lambda x: (x['age'], -x['score']))
3. 使用operator模块
from operator import itemgetter, attrgetter# 等价于 lambda x: x['score']
sorted_students = sorted(students, key=itemgetter('score'))# 类对象排序
class Student: ...
sorted_students = sorted(students, key=attrgetter('age'))
4. 自定义排序规则
def custom_sort(x):# 奇偶数优先排序:奇数在前,数值小的在前return (x % 2 == 0, x)nums = [3, 1, 4, 2]
sorted_nums = sorted(nums, key=custom_sort) # [1, 3, 2, 4]
五、性能优化建议
- 避免在key函数中进行复杂计算:key函数会被频繁调用,应保持简单高效
- 考虑使用生成器:对于大数据集,可以先用生成器预处理
- 预编译key函数:对于重复使用的key函数,可以预编译或缓存结果
- 考虑稳定性需求:当需要保持相等元素的原始顺序时,sorted()是更好的选择
六、与sort()方法的对比
| 特性 | sorted() | list.sort() |
|---|---|---|
| 返回值 | 新列表 | None(原地修改) |
| 原始数据 | 不改变 | 直接修改 |
| 适用对象 | 任何可迭代对象 | 仅列表 |
| 链式操作 | 支持 | 不支持 |
| 内存使用 | 更高(需要副本) | 更低 |
七、实际应用案例
1. 日志文件按时间排序
log_lines = ["2023-01-15 ERROR: Disk full","2023-01-10 INFO: System started","2023-01-12 WARNING: Memory low"
]sorted_logs = sorted(log_lines, key=lambda x: x.split()[0])
2. 文件名自然排序
import refiles = ["file1.txt", "file10.txt", "file2.txt"]
sorted_files = sorted(files, key=lambda x: int(re.search(r'\d+', x).group()))
3. 多语言字符串排序
import locale
locale.setlocale(locale.LC_COLLATE, 'fr_FR.UTF-8')words = ['été', 'hôtel', 'arbre']
sorted_words = sorted(words, key=locale.strxfrm)
八、常见问题解答
Q1: sorted()如何处理None值?
A: 在Python中,None不能与其他值比较。解决方案:
sorted_list = sorted(mixed_list, key=lambda x: (x is None, x))
Q2: 如何实现自定义排序类?
class CustomOrder:_order = ['high', 'medium', 'low']def __init__(self, value):self.value = valuedef __lt__(self, other):return self._order.index(self.value) < self._order.index(other.value)sorted_items = sorted([CustomOrder(x) for x in ['low', 'high', 'medium']])
Q3: 超大文件如何高效排序?
使用外部排序(分块读取+归并):
def external_sort(file_path):# 分块读取并排序chunks = []with open(file_path) as f:while True:chunk = list(itertools.islice(f, 10000)) # 每次读1万行if not chunk:breakchunk.sort()chunks.append(chunk)# 多路归并return list(heapq.merge(*chunks))
九、总结
sorted()作为Python的核心高阶函数,其强大之处在于:
- 灵活的参数设计(特别是key函数)
- 稳定的排序算法
- 广泛的应用场景
- 优秀的性能表现
掌握sorted()的高级用法,可以让你写出更Pythonic、更高效的排序代码。建议在实际项目中多实践各种排序场景,深入理解其底层原理。
扩展阅读:Python官方文档中关于排序指南的详细说明
相关文章:
Python高阶函数-sorted(深度解析从原理到实战)
一、sorted()函数概述 sorted()是Python内置的高阶函数,用于对可迭代对象进行排序操作。与列表的sort()方法不同,sorted()会返回一个新的已排序列表,而不改变原数据。 基本语法 sorted(iterable, *, keyNone, reverseFalse)二、核心参数详…...

Vue3实战三、Axios封装结合mock数据、Vite跨域及环境变量配置
目录 Axios封装、调用mock接口、Vite跨域及环境变量配置封装Axios对象调用mock接口数据第一步、安装axios,处理一部请求第二步、创建request.ts文件第三步、本地模拟mock数据接口第四步、测试axiosmock接口是否可以调用第五步、自行扩展 axios 返回的数据类型 axios…...

机器学习(神经网络基础篇)——个人理解篇5(梯度下降中遇到的问题)
在神经网络训练中,计算参数的梯度是关键步骤。numerical_gradient 方法旨在通过数值微分(中心差分法)计算损失函数对网络参数的梯度。然而,该方法的实现存在一个关键问题,导致梯度计算错误。 1、错误代码示例…...

sklearn的Pipeline
Pipeline类 介绍:Pipeline 可以将多个数据处理步骤和机器学习模型组合成一个序列,其中每个步骤都是一个变换器(Transformer)或者估计器(Estimator),并且Pipeline中的最后一个必须为估计器,其它的必须为变换器,如果Pipeline中的估计器为为分类器则整个Pipeline就作为分…...
【Linux】虚拟机设置静态IP
主播我今天下午学了几节微服务课,上课的时候,直接把手机拿走了去上课(电脑连的我手机的热点),虚拟机没关,晚上主播我回来继续学,电脑连上热点之后,发现虚拟机连接不上了,…...

职坐标解析自动驾驶技术发展新趋势
内容概要 作为智能交通革命的核心驱动力,自动驾驶技术正以惊人的速度重塑出行生态。2023年,行业在多传感器融合与AI算法优化两大领域实现突破性进展:激光雷达、摄像头与毫米波雷达的协同精度提升至厘米级,而深度学习模型的实时决…...

js算法基础-01
文章目录 1、双指针2、快慢指针3、滑动指针4、哈希表5、汇总区间6、栈7、进制求和8、数学9、动态规划 js算法基础, 每个重要逻辑思路,做一下列举 1、双指针 有序数组合并:一般思路就是合并、排序,当然效率略低题目1:nums1中取前m个…...

了解 DeepSeek R1
了解DeepSeek R1 R1探索纯强化学习是否可以在没有监督微调的情况下学会推理的能力。 ‘Aha’ Moment 这种现象有点类似于人类在解决问题时突然意识到的方式,以下是它的工作原理: 初始尝试:模型对解决问题进行初始尝试识别:识别…...
局域网:电脑或移动设备作为主机实现局域网访问
电脑作为主机 1. 启用电脑的网络发现、SMB功能 2. 将访问设备开启WIFI或热点,用此电脑连接;或多台设备连接到同一WIFI 3. 此电脑打开命令行窗口,查看电脑本地的IP地址 Win系统:输入"ipconfig",回车后如图 4.…...
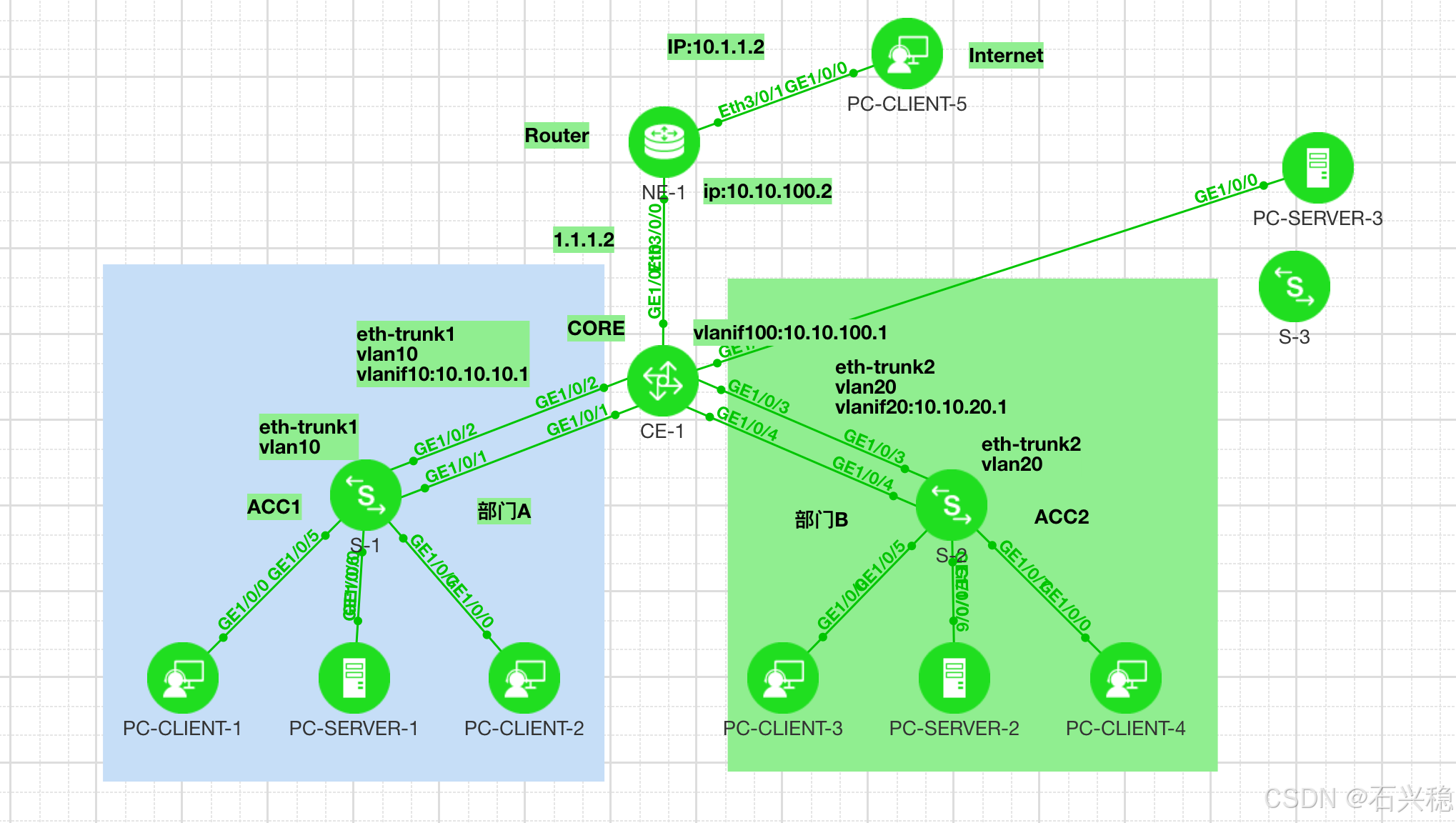
小型园区组网图
1. 在小型园区中,S5735-L-V2通常部署在网络的接入层,S8700-4通常部署在网络的核心,出口路由器一般选用AR系列路由器。 2. 接入交换机与核心交换机通过Eth-Trunk组网保证可靠性。 3. 每个部门业务划分到一个VLAN中,部门间的业务在C…...
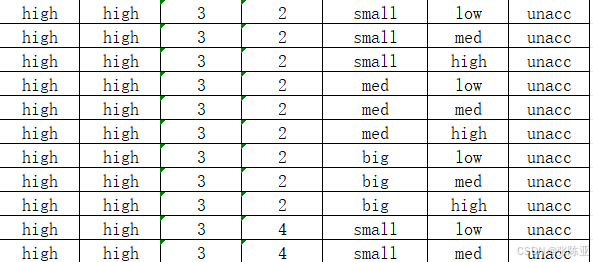
数据分享:汽车测评数据
说明:如需数据可以直接到文章最后关注获取。 1.数据背景 Car Evaluation汽车测评数据集是一个经典的机器学习数据集,最初由 Marko Bohanec 和 Blaz Zupan 创建,并在 1997 年发表于论文 "Classifier learning from examples: Common …...

python小整数池和字符串贮存
在Python中,**小整数池**是一种优化机制,用于减少内存使用和加速小整数的创建。 ### 小整数池的工作原理 - **范围**:Python会预先创建并缓存-5到256之间的整数对象。这些对象在解释器启动时就已经创建,并且会一直驻留在内存中。…...
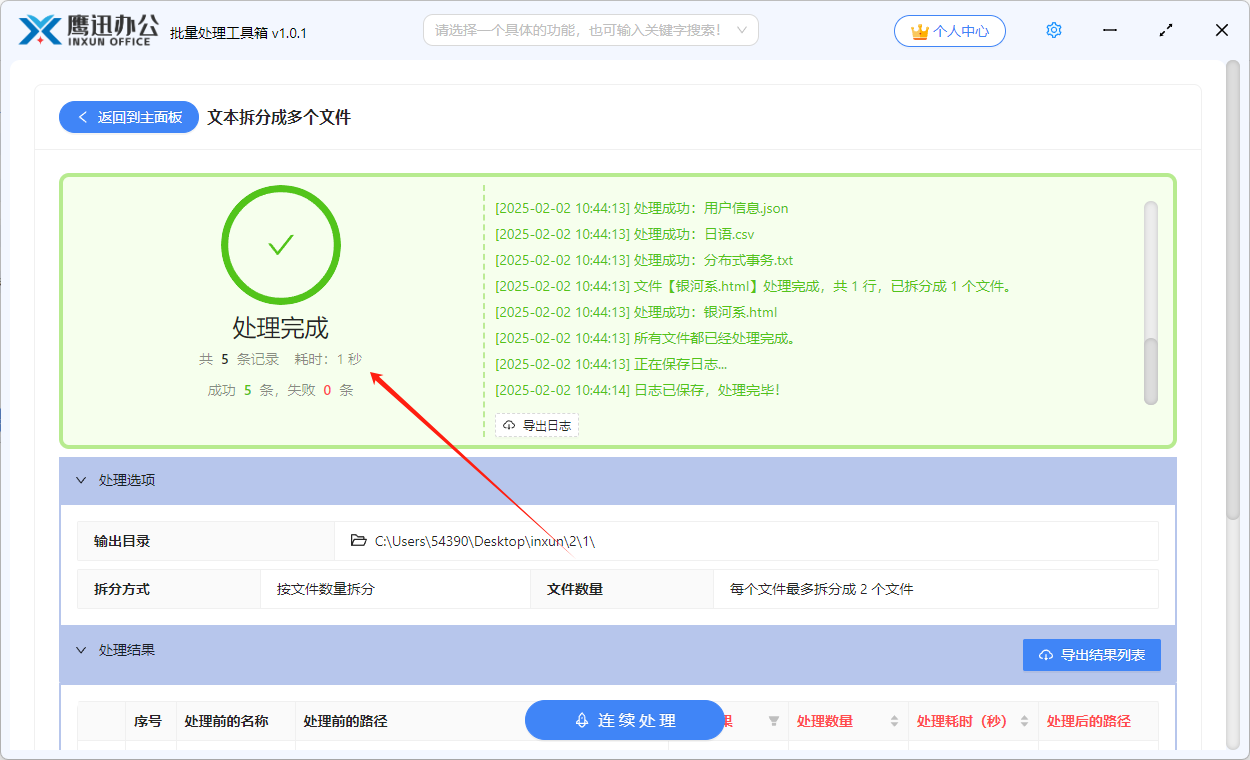
批量将 txt/html/json/xml/csv 等文本拆分成多个文件
我们的文本文件太大的时候,我们通常需要对文本文件进行拆分,比如按多少行一个文件将一个大的文本文件拆分成多个小的文本文件。这样我们在打开或者传输的时候都比较方便。今天就给大家介绍一种同时对多个文本文件进行批量拆分的方法,可以快速…...
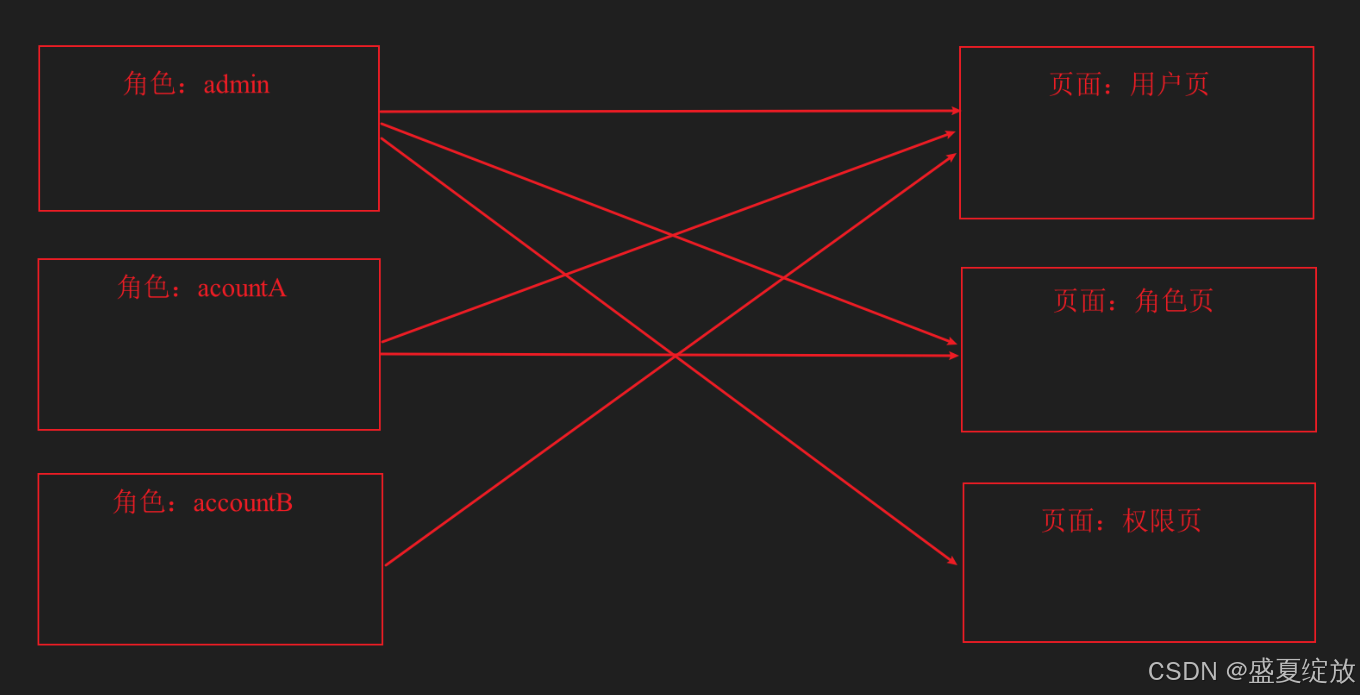
Vue3 路由权限管理:基于角色的路由生成与访问控制
Vue3 路由权限管理:基于角色的路由生成与访问控制 一、核心概念 1.1 大致流程思路: 用户在登录完成的时候,后端给出一个此登录用户对应的角色名字,此时可以将这个用户的角色存起来(vuex/pinia)中,在设置路由时的met…...

LLM Agents的历史、现状与未来趋势
引言 大型语言模型(Large Language Model, LLM)近年在人工智能领域掀起革命,它们具备了出色的语言理解与生成能力。然而,单纯的LLM更像是被动的“回答者”,只能根据输入给出回复。为了让LLM真正“行动”起来ÿ…...
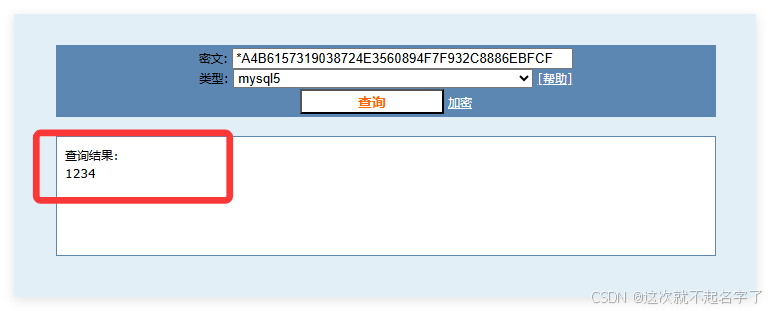
忘记mysql的root用户密码(已解决)
1、打开数据库可视化界面(比如MySQL workbench) 2、执行select host,user,authentication_string from mysql.user; 3、把‘authentication_string’下面的字段 复制到MD5在线解密网页中(比如md5在线解密)...

【Pandas】pandas DataFrame set_flags
Pandas2.2 DataFrame Attributes and underlying data 方法描述DataFrame.index用于获取 DataFrame 的行索引DataFrame.columns用于获取 DataFrame 的列标签DataFrame.dtypes用于获取 DataFrame 中每一列的数据类型DataFrame.info([verbose, buf, max_cols, …])用于提供 Dat…...

Vue3.2 项目打包成 Electron 桌面应用
本文将详细介绍如何将基于 Vue3.2 的项目打包成 Electron 桌面应用。通过结合 Electron 和 Vue CLI 工具链,可以轻松实现跨平台桌面应用的开发与发布。 1. 项目结构说明 项目主要分为以下几个部分: electron/main.js:Electron 主进程文件。…...

git stash pop 后反悔操作
当使用 git stash pop 应用并删除某个存储(stash)后,如果想撤销该操作(即恢复工作目录到 pop 前的状态,并重新将存储放回存储栈),可以按以下步骤操作: 1 强制丢弃所有未提交的更改&…...

Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结
以下是 Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结: 核心 Bean 列表及详细说明 1. MongoClient 类型:com.mongodb.client.MongoClient作用: MongoDB 客户端核心接口,负责与 MongoDB 服务器建立连接、…...

TypeScript面试题集合【初级、中级、高级】
初级面试题 什么是TypeScript? TypeScript是JavaScript的超集,由Microsoft开发,它添加了可选的静态类型和基于类的面向对象编程。TypeScript旨在解决JavaScript的某些局限性,比如缺乏静态类型和基于类的面向对象编程,…...
ubuntu 20.04 编译和运行SC-LeGo-LOAM
1.搭建文件目录和clone代码 mkdir -p SC-LeGo-LOAM/src cd SC-LeGo-LOAM/src git clone https://github.com/AbangLZU/SC-LeGO-LOAM.git cd .. 2.修改代码 需要注意的是原作者使用的是Ouster OS-64雷达,需要更改utility.h文件中适配自己的雷达类型,而…...
CentOS 7安装hyperscan
0x00 前言 HyperScan是一款由Intel开发的高性能正则表达式匹配库,专为需要快速处理大量数据流的应用场景而设计。它支持多平台运行,包括Linux、Windows和macOS等操作系统,并针对x86架构进行了优化,以提供卓越的性能表现。HyperSc…...

Quartz MisFire补偿机制 任务补偿 任务延迟 错过触发策略
介绍 在 Quartz 中,MisFire(错过触发)是指触发器错过了预定的触发时间,通常是由于系统延迟、任务执行时间过长或者调度器本身未能及时执行任务等原因。这种情况可能会导致任务无法按预期的时间执行。为了应对这些问题,…...

AI训练存储架构革命:存储选型白皮书与万卡集群实战解析
一、引言 在人工智能技术持续高速发展的当下,AI 训练任务对存储系统的依赖愈发关键,而存储系统的选型也变得更为复杂。不同的 AI 训练场景,如机器学习与大模型训练,在模型特性、GPU 使用数量以及数据量带宽等方面的差异ÿ…...

谢志辉和他的《韵之队诗集》:探寻生活与梦想交织的诗意世界
大家好,我是谢志辉,一个扎根在文字世界,默默耕耘的写作者。写作于我而言,早已不是简单的爱好,而是生命中不可或缺的一部分。无数个寂静的夜晚,当世界陷入沉睡,我独自坐在书桌前,伴着…...
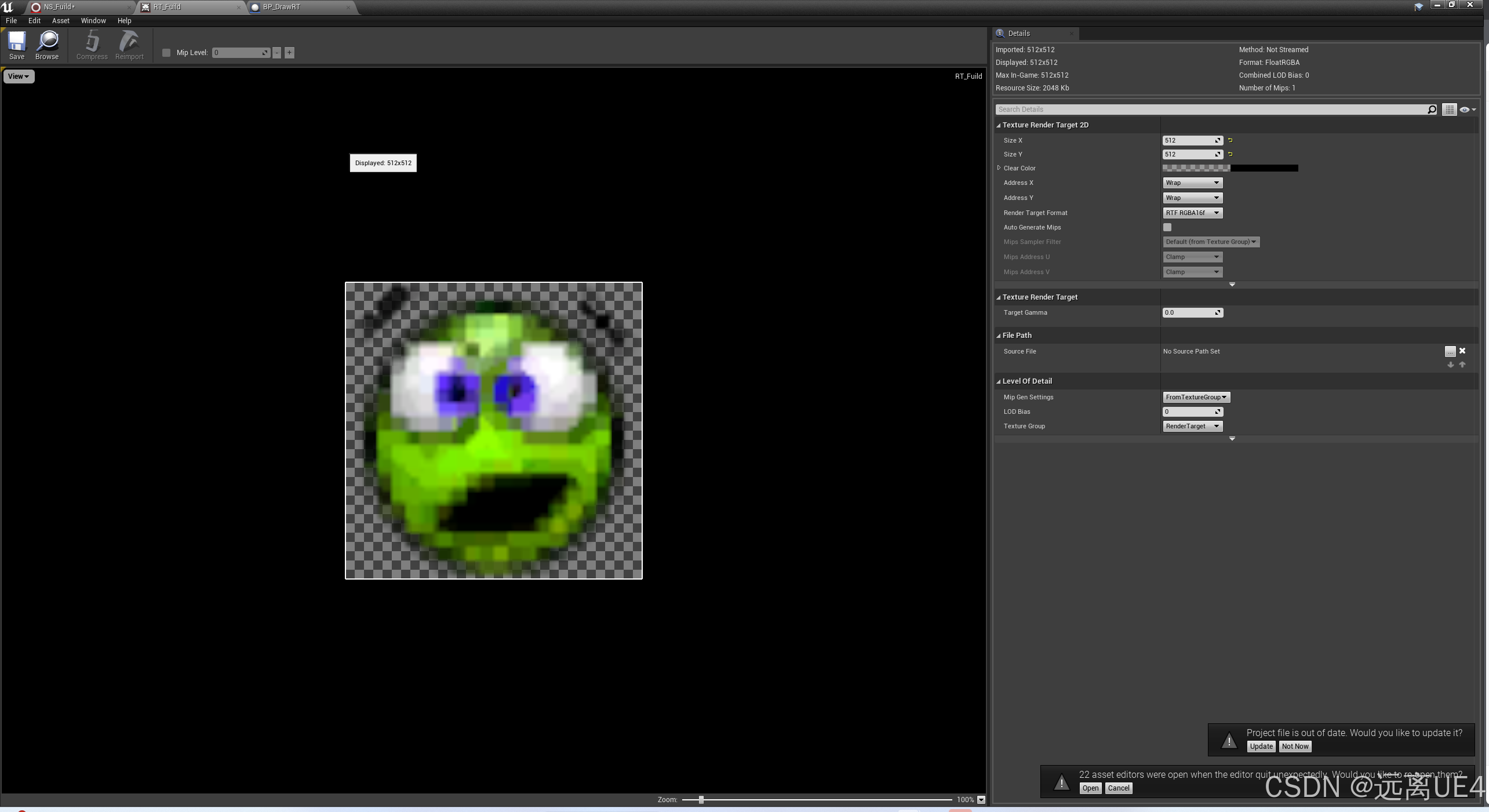
UE5 Simulation Stage
首先将Grid2D创建出来,然后设置值,Grid2D类似于在Niagara系统中的RenderTarget2D,可以进行绘制,那么设置大小为512 * 512 开启Niagara粒子中的Simulation Stage 然后开始编写我们的自定义模块 模块很简单,TS就是Textur…...

Swift 解 LeetCode 250:搞懂同值子树,用递归写出权限系统检查器
文章目录 前言问题描述简单说:痛点分析:到底难在哪?1. 子树的概念搞不清楚2. 要不要“递归”?递归从哪开始?3. 怎么“边遍历边判断”?这套路不熟 后序遍历 全局计数器遍历过程解释一下:和实际场…...

怎样使用Python编写的Telegram聊天机器人
怎样使用Python编写的Telegram聊天机器人 代码直接运行可用 以下是对这段代码的详细解释: 1. 导入必要的库 import loggingfrom telegram import Update from telegram.ext import ApplicationBuilder, ContextTypes, CommandHandler, filters, MessageHandler import log…...

Elixir语言的移动应用安全
Elixir语言的移动应用安全解析 引言 在当今的数字化时代,移动应用已经成为我们日常生活中不可或缺的一部分。从购物、社交到在线银行,几乎每一个生活领域都与移动应用紧密相连。然而,随着应用的普及,安全问题也随之而来。如何确…...