LLM Agents的历史、现状与未来趋势
引言
大型语言模型(Large Language Model, LLM)近年在人工智能领域掀起革命,它们具备了出色的语言理解与生成能力。然而,单纯的LLM更像是被动的“回答者”,只能根据输入给出回复。为了让LLM真正“行动”起来,人们引入了**Agent(代理或智能体)**的概念。简单来说,LLM Agent就是以大型语言模型为“大脑”的智能体:它能够感知环境、规划行动、调用工具,试图自主地完成复杂任务。
LLM Agent这个概念结合了代理(Agent)技术与LLM模型能力。一方面,传统AI代理指的是能在环境中感知和行动的智能系统,包括早期的机器人代理或软件代理;另一方面,LLM提供了强大的通用智能和语言交互接口。将两者结合,诞生了基于LLM的智能体——它以自然语言为媒介,与人或环境交互,既能思考(推理)又能行动。这种新型智能体有望自动完成例如网络搜索、代码编写、任务规划等需要多步骤推理与操作的任务,因而备受关注。
本篇博客旨在系统梳理LLM Agents的历史演进、当前现状以及未来发展趋势。我们将兼顾学术深度和通俗讲解,既为研究人员提供参考脉络,也为初学者揭开LLM智能体的神秘面纱。从起源与关键转折点讲起,介绍当前主流的架构与能力、生态系统和挑战,再展望未来的发展方向,包括多模态融合、自主学习、可控性和安全性等。最后,我们将重点介绍开源社区中几个具有代表性的项目(MetaGPT、AutoGen、MCP),并推荐其他一些优秀的开源项目及其应用案例。希望通过本篇内容,读者能对LLM Agents有一个全面而清晰的认识。
起源与发展历程
早期AI代理的探索
“智能体”(Agent)并非LLM时代的新事物。早在人工智能的发展早期,研究者就提出了各种形式的代理模型。经典的定义是:智能体是能在某种环境中自主感知和行动的智能系统。在不同年代,“环境”和“智能”的含义有所不同:从物理机器人在现实环境中行动,到软件代理在虚拟环境中对话,都属于广义的Agent范畴。
上世纪60年代的ELIZA可以看作最早的文本代理之一。ELIZA是1966年出现的一个基于模式匹配的对话系统,可以模拟心理治疗师与人交谈。虽然ELIZA并没有真正的“理解”,更称不上“大型语言模型”,但它证明了基于文本交互的代理的可能性。随后几十年,AI领域还出现了各类基于规则或学习的代理。例如,强化学习领域曾涌现出基于LSTM的DQN代理,能通过大量训练在特定领域完成任务。然而,这些早期代理要么规则死板、缺乏通用性,要么训练成本高、适用范围窄,并没有体现出通用智能。可以说,在LLM出现之前,Agent研究虽然重要,但局限于较小的应用场景,缺乏“通用大脑”。
大型语言模型时代的兴起
2017年Transformer架构的提出引领了深度学习的突破,随后OpenAI的GPT系列等大型语言模型横空出世,展现出惊人的语言能力。特别是GPT-3(2020年)和后来的ChatGPT(基于GPT-3.5和GPT-4,在2022-2023年推出)的成功,标志着通用语言智能的发展进入新纪元。LLM能够在零样本或少样本条件下完成问答、写作、翻译、代码生成等众多任务。这让人们开始思考:能否让LLM不仅被动回答,而且主动执行更复杂的任务? 换言之,如果把LLM当作智能体的大脑,让它拥有决策和行动能力,会怎样?
最初的尝试往往从简单的场景入手。例如,在问答系统中引入工具使用的想法:当LLM遇到数学计算时,是否可以调用计算器?当它需要最新资讯时,能否调用搜索引擎?于是,研究者开始给LLM配备“工具”,让它决定何时调用外部API或程序来辅助完成任务。这被视为LLM向Agent转变的萌芽。此外,人们也尝试让LLM产生日志式的思考过程。比如Prompt中要求模型“先思考再给答案”,引出了*Chain-of-Thought (CoT,链式思维)*的提示技巧,让模型列出推理步骤。这些尝试为后来更复杂的LLM Agent奠定了基础:需要让模型学会自主规划步骤,并与外界交互。
一个标志性转折点是2022年提出的ReAct范式。ReAct是“Reasoning and Acting”的缩写,它提供了一种巧妙的提示方法:让LLM的输出交替包含“思考”(Reasoning,即模型的中间推理内容)和“行动”(Act,即模型决定采取的操作)。例如,模型可以先输出“我需要查询百科全书来获取相关信息”,然后作为行动去执行这个查询,再把结果反馈回来继续推理。通过在Prompt中示范这种交替的思维链+行动指令格式,LLM可以在一次对话中反复思考和操作,直到得到答案。ReAct被认为是LLM Agents的重要里程碑——它将推理(内在思考)和行动(外部交互)结合为统一框架,使得模型能够一边“思考”,一边“试探性地采取行动”。相比只会给最终答案的传统用法,ReAct赋予LLM一种代理的雏形:有了内在状态和与环境交互的循环。
自主代理的浪潮:AutoGPT和BabyAGI
进入2023年,随着ChatGPT的爆火,公众对通用AI代理的兴趣被彻底点燃。这一年春季,开源社区出现了两个现象级项目:AutoGPT和BabyAGI。它们标志着“自主的LLM代理”浪潮的开始,引发了广泛关注和跟风开发。
-
AutoGPT(自动GPT):由一位开发者Torantulina在2023年3月首次发布在GitHub上,定位为“让GPT-4自主管理任务的实验性开源项目”。AutoGPT的核心思路是在没有人工干预的情况下,让LLM自主循环:它会根据一个高层目标,不断生成下一步行动(包括可能的子任务)、执行行动、获取反馈,再调整策略,直至目标完成。举个简单例子,如果让AutoGPT以“提高个人理财”为目标,它可能自己列出任务清单(查询投资方法、分析支出等),然后逐一执行。AutoGPT配备了浏览器、文件读写、代码执行等插件,因此它在循环中可以上网搜索信息、运行Python脚本、保存/加载结果等。这个项目展示了LLM自动连贯执行任务的潜力。一时间,“让我来告诉ChatGPT干完这件事”的畅想变成了现实雏形,AutoGPT的GitHub星标飙升,掀起了全民讨论自主AI代理的热潮。不过,AutoGPT也暴露出诸多问题:例如经常生成无效方案或陷入循环,效率低下,以及对稍复杂任务仍显力不从心。但不可否认,它让大众第一次直观感受到LLM Agent的雏形与可能性。
-
BabyAGI:几乎与AutoGPT同时出现的另一个网红项目,由创业者Yohei Nakajima提出。与AutoGPT复杂的插件体系相比,BabyAGI理念更简洁——它实现了一个最小可行的自主代理框架。BabyAGI的主体是一个循环:从初始目标出发,模型会生成要执行的任务列表;每次取出最高优先级的任务,由LLM尝试完成;得到结果后,再由LLM根据剩余目标生成新的任务并调整优先级队列,如此往复。这个过程模仿人类进行项目管理的方式:不断生成-执行-调整。因为实现简单,BabyAGI被众多开发者 fork 并魔改,衍生出各种版本。虽然BabyAGI本身功能有限,但它证明了使用LLM可以搭建一个自我驱动的任务管理循环,被视为自主代理的另一个基础范例。
AutoGPT和BabyAGI的出现是LLM Agents发展史上的重要节点:它们将之前学术界的概念以开源项目形式带入公众视野。大量开发者参与测试这些自主代理,积累了经验,也暴露了问题。这些项目的火爆促使人们思考如何改进代理的可靠性和复杂任务处理能力。一时间,各种以“GPT-Agent”命名的项目层出不穷,例如具有网页界面的AgentGPT,主打长程任务的GodMode等。尽管大多停留在实验玩具阶段,但技术在快速迭代,人们对“AI可以自我调度完成任务”这一前景充满期待。
多智能体协作与记忆涌现
随着单个LLM智能体框架的发展,研究者很快将目光投向多智能体协作和长时记忆两个方向,希望突破单Agent的能力瓶颈。
多智能体协作指的是让多个LLM Agent同时存在,彼此交流协同完成任务。灵感来源很直观:在人类社会中,复杂工作往往需要团队合作,那么多个AI代理是否也能像团队那样配合?早期的有趣探索之一是角色扮演对话:让两个ChatGPT分别充当不同角色进行对话求解问题。例如一个扮演提问者,一个扮演专家,他们通过多轮问答找出答案。这种“双Agent角色扮演”在社区里很流行,被称为CAMEL方法(因为最初的论文/项目提出者将其形象地比喻为两峰驼Camel,代表AI用户和AI助手两个峰)。CAMEL展示了多代理协作解决问题的潜力——通过扮演不同角色、交流信息,LLM可以突破单一身份的限制。
进一步的,多代理不局限于两个。“AI 社会”的概念应运而生:多个智能体各有身份、拥有各自的记忆和目标,在模拟环境中持续交互,产生复杂行为。斯坦福大学在2023年提出的Generative Agents就是一项引人注目的工作:研究者在虚拟小镇中模拟了25个角色各异的代理,这些代理由LLM驱动,有着类似The Sims游戏中的日常行为,它们可以聊天、认识新朋友、记忆每天的经历,并根据记忆调整后续行动。比如,一个代理被设置为早上7点闹钟响就起床,然后去咖啡馆,遇到另一代理打招呼、闲聊,稍晚还会计划一个晚会邀请朋友们。这项研究展示了LLM驱动的代理在社交互动和记忆方面的惊人表现:多个代理之间的对话和协作让整个系统表现出类似社会的动态。这虽然是模拟环境,但启发了对未来拥有社交能力的AI代理的想象。
长时记忆是另一个关键挑战领域。传统LLM受限于固定的提示窗口(context window),难以记住长远的历史。这对一个持续运行的Agent来说显然不够——想象一个助手Agent,昨天刚和你讨论过计划,今天却“失忆”要重头再来,这是不可接受的。因此,研究者尝试赋予LLM Agent某种形式的记忆机制。例如,前面提到的Generative Agents为每个代理维护了一个记忆数据库,里面存储事件的摘要,代理会定期“回顾”记忆、更新自我认知。又如2023年出现的Reflexion方法,思路是在Agent完成一次任务后,让它对过程进行反思(例如检查哪里出错、有没有更好方法),然后把有用的经验写入自身的“长远记忆”(可以是追加在prompt里,也可以存入外部知识库)。下次遇到类似情境时,Agent先查阅自己的反思记录,从而避免重蹈覆辙。Reflexion被形象地称为让Agent具有“自我反馈循环”,相当于一种语言层面的强化学习:不是更新模型参数,而是更新模型的文字记忆。这样的机制提高了Agent连贯完成任务的成功率,也是迈向自主学习的重要一步。
2023年下半年开始,更多关于LLM Agent的新思想不断涌现。例如,为了提升决策规划能力,有研究引入树状思维(Tree of Thoughts),让模型同时展开多个思路进行搜索,再筛选最优方案。为了减少胡乱调用工具的情况,OpenAI等引入了函数调用接口,要求模型输出结构化的函数名和参数,从而安全地调用外部API,让Agent行为更加可控。大型科技公司也加入了Agent研究:Microsoft提出“HuggingGPT”,用ChatGPT作为总控代理,协调调用上百种专业模型(如图像识别、语音识别模型)去完成多模态任务;**Google推出“SayCan”**将LLM与机器人动作结合,让语言模型指导机器人完成现实操作。可以看到,LLM Agents领域在2023年呈现出百花齐放的局面,从个人助理到多Agent团队,从虚拟对话到实体机器人,各种各样的尝试相互交织。即便许多项目还不成熟,但整个方向的发展速度和关注度都在迅速提升。
走向成熟:近况概述
进入2024年至2025年,LLM Agents的研究与应用逐渐走向成熟和理性。一方面,早期过高的期待开始冷却,社区认识到让AI完全自主解决任意复杂任务仍有很长的路。但另一方面,框架化、模块化的解决方案不断涌现,人们在实践中总结经验,迭代出更稳健、更高效的Agent架构。
几个值得一提的里程碑包括:
-
OpenAI官方支持工具调用:OpenAI的GPT-4 API在2023年中加入了函数调用功能,并推出了ChatGPT插件生态。这实际上把Agent的一种能力直接集成到了主流LLM服务中——开发者可以为ChatGPT提供插件,让它按需要调用,如浏览网页、查询数据库、控制家电等。用户在与ChatGPT对话时,代理行为会自动发生(例如它决定调用某插件时,返回结果融入对话)。这一举措让Agent概念走出了纯研究圈子,进入大众产品应用。
-
学术研究系统化:2023年底到2024年,出现了多篇关于LLM Agent的综述和评测论文,开始系统总结这一领域的方法与挑战。例如,一些论文分类了Agent的典型工作流程:反思型(有自我反馈回路)、工具型(侧重调用工具)、规划型(侧重任务分解),还有多智能体协作型。社区也构建了初步的基准测试(Benchmark)来评估Agent解决复杂任务的能力,比如看它们在代码生成、任务管理上的成功率和效率。这样的研究为Agent技术的标准化和改进指明了方向。
-
多种开源框架面世:在开源社区,除了早期的AutoGPT等,后来者如LangChain、Langroid、AgentVerse、GPT Engineer、Camel等层出不穷。这些框架各有侧重:LangChain提供了强大的链式调用和记忆管理工具,被广泛用来实现自定义Agent;Camel强调多Agent角色互動;AgentVerse提供了构建复杂环境中代理的方法;GPT Engineer致力于让AI自动读写和修改代码项目…… 如今开发者已经有丰富的开源库可以选择来搭建自己的LLM Agent,而不必完全从零开始。
-
工业界的试水:不少公司开始将LLM Agent用于实际产品或业务流程中。例如,微软在Office Copilot中引入一些自动任务执行功能;一些初创公司开发AI助手,可以替用户执行跨应用的操作(发送邮件、安排日程等)。虽说还处于早期,但商业应用的尝试正在推进,反馈又反过来推动技术完善。
相关文章:

LLM Agents的历史、现状与未来趋势
引言 大型语言模型(Large Language Model, LLM)近年在人工智能领域掀起革命,它们具备了出色的语言理解与生成能力。然而,单纯的LLM更像是被动的“回答者”,只能根据输入给出回复。为了让LLM真正“行动”起来ÿ…...
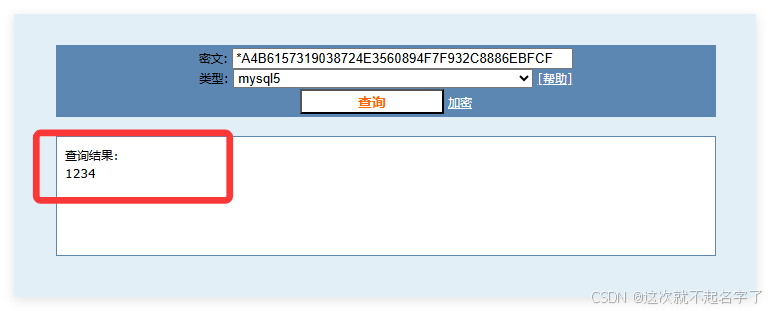
忘记mysql的root用户密码(已解决)
1、打开数据库可视化界面(比如MySQL workbench) 2、执行select host,user,authentication_string from mysql.user; 3、把‘authentication_string’下面的字段 复制到MD5在线解密网页中(比如md5在线解密)...

【Pandas】pandas DataFrame set_flags
Pandas2.2 DataFrame Attributes and underlying data 方法描述DataFrame.index用于获取 DataFrame 的行索引DataFrame.columns用于获取 DataFrame 的列标签DataFrame.dtypes用于获取 DataFrame 中每一列的数据类型DataFrame.info([verbose, buf, max_cols, …])用于提供 Dat…...

Vue3.2 项目打包成 Electron 桌面应用
本文将详细介绍如何将基于 Vue3.2 的项目打包成 Electron 桌面应用。通过结合 Electron 和 Vue CLI 工具链,可以轻松实现跨平台桌面应用的开发与发布。 1. 项目结构说明 项目主要分为以下几个部分: electron/main.js:Electron 主进程文件。…...

git stash pop 后反悔操作
当使用 git stash pop 应用并删除某个存储(stash)后,如果想撤销该操作(即恢复工作目录到 pop 前的状态,并重新将存储放回存储栈),可以按以下步骤操作: 1 强制丢弃所有未提交的更改&…...

Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结
以下是 Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结: 核心 Bean 列表及详细说明 1. MongoClient 类型:com.mongodb.client.MongoClient作用: MongoDB 客户端核心接口,负责与 MongoDB 服务器建立连接、…...

TypeScript面试题集合【初级、中级、高级】
初级面试题 什么是TypeScript? TypeScript是JavaScript的超集,由Microsoft开发,它添加了可选的静态类型和基于类的面向对象编程。TypeScript旨在解决JavaScript的某些局限性,比如缺乏静态类型和基于类的面向对象编程,…...
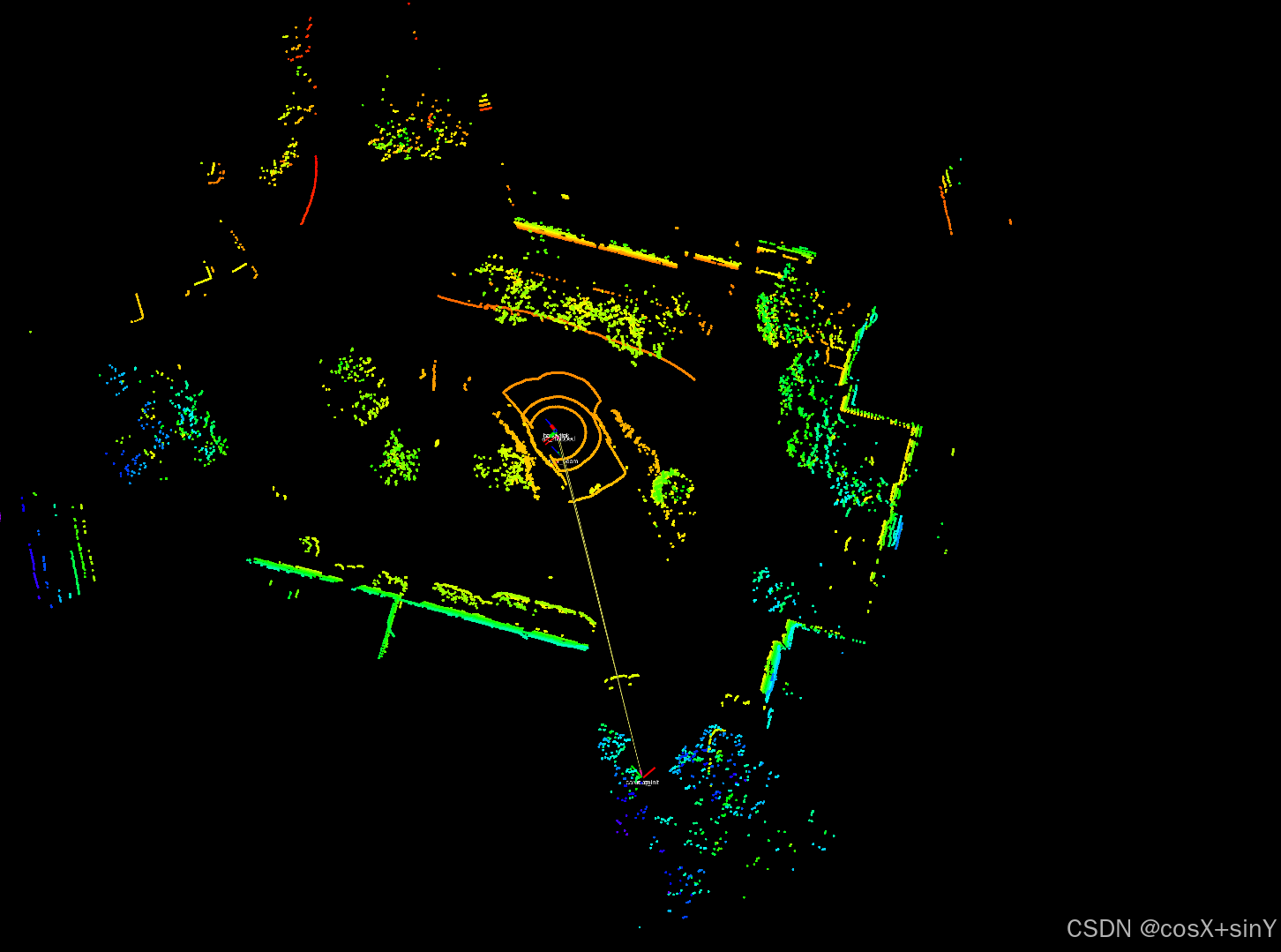
ubuntu 20.04 编译和运行SC-LeGo-LOAM
1.搭建文件目录和clone代码 mkdir -p SC-LeGo-LOAM/src cd SC-LeGo-LOAM/src git clone https://github.com/AbangLZU/SC-LeGO-LOAM.git cd .. 2.修改代码 需要注意的是原作者使用的是Ouster OS-64雷达,需要更改utility.h文件中适配自己的雷达类型,而…...
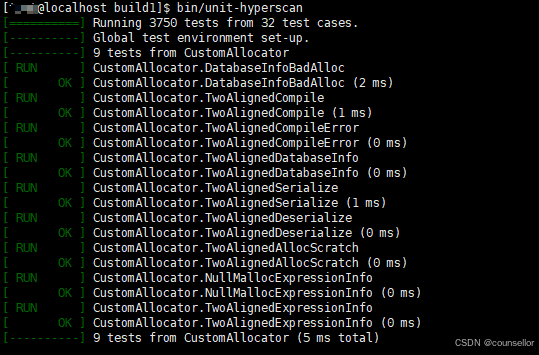
CentOS 7安装hyperscan
0x00 前言 HyperScan是一款由Intel开发的高性能正则表达式匹配库,专为需要快速处理大量数据流的应用场景而设计。它支持多平台运行,包括Linux、Windows和macOS等操作系统,并针对x86架构进行了优化,以提供卓越的性能表现。HyperSc…...

Quartz MisFire补偿机制 任务补偿 任务延迟 错过触发策略
介绍 在 Quartz 中,MisFire(错过触发)是指触发器错过了预定的触发时间,通常是由于系统延迟、任务执行时间过长或者调度器本身未能及时执行任务等原因。这种情况可能会导致任务无法按预期的时间执行。为了应对这些问题,…...

AI训练存储架构革命:存储选型白皮书与万卡集群实战解析
一、引言 在人工智能技术持续高速发展的当下,AI 训练任务对存储系统的依赖愈发关键,而存储系统的选型也变得更为复杂。不同的 AI 训练场景,如机器学习与大模型训练,在模型特性、GPU 使用数量以及数据量带宽等方面的差异ÿ…...

谢志辉和他的《韵之队诗集》:探寻生活与梦想交织的诗意世界
大家好,我是谢志辉,一个扎根在文字世界,默默耕耘的写作者。写作于我而言,早已不是简单的爱好,而是生命中不可或缺的一部分。无数个寂静的夜晚,当世界陷入沉睡,我独自坐在书桌前,伴着…...
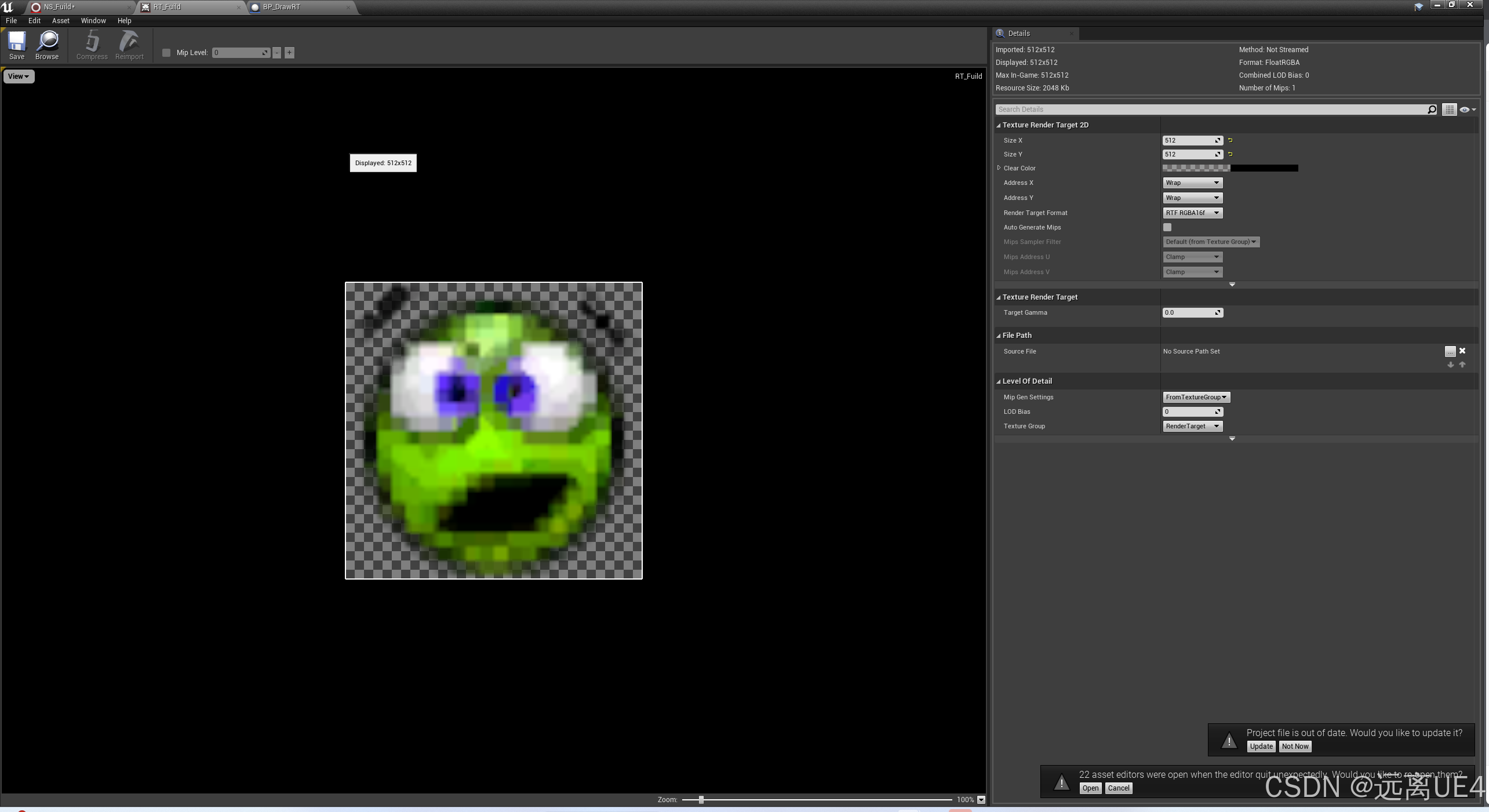
UE5 Simulation Stage
首先将Grid2D创建出来,然后设置值,Grid2D类似于在Niagara系统中的RenderTarget2D,可以进行绘制,那么设置大小为512 * 512 开启Niagara粒子中的Simulation Stage 然后开始编写我们的自定义模块 模块很简单,TS就是Textur…...

Swift 解 LeetCode 250:搞懂同值子树,用递归写出权限系统检查器
文章目录 前言问题描述简单说:痛点分析:到底难在哪?1. 子树的概念搞不清楚2. 要不要“递归”?递归从哪开始?3. 怎么“边遍历边判断”?这套路不熟 后序遍历 全局计数器遍历过程解释一下:和实际场…...

怎样使用Python编写的Telegram聊天机器人
怎样使用Python编写的Telegram聊天机器人 代码直接运行可用 以下是对这段代码的详细解释: 1. 导入必要的库 import loggingfrom telegram import Update from telegram.ext import ApplicationBuilder, ContextTypes, CommandHandler, filters, MessageHandler import log…...

Elixir语言的移动应用安全
Elixir语言的移动应用安全解析 引言 在当今的数字化时代,移动应用已经成为我们日常生活中不可或缺的一部分。从购物、社交到在线银行,几乎每一个生活领域都与移动应用紧密相连。然而,随着应用的普及,安全问题也随之而来。如何确…...

动态估算gas和gasPrice
目录 一、什么是动态估算? 二、动态估算 Gas(代码示例) ✅ 使用 Ethers.js 估算 gasLimit: 💡 发送交易时加一点 buffer: 三、动态估算 gasPrice / maxFee ✅ 获取当前 baseFee(用 provider): ✅ 搭配交易一起发送: 四、完整组合:动态估算 Gas + EIP-1559 费用…...

数据清洗
map阶段:按行读入内容,对内容进行检查,如果字段的个数少于等于11,就删除这条日志(不保留)去除日志中字段个数小于等于11的日志内容。 <偏移量,第一行的内容> → <通过刷选之后的第一行…...
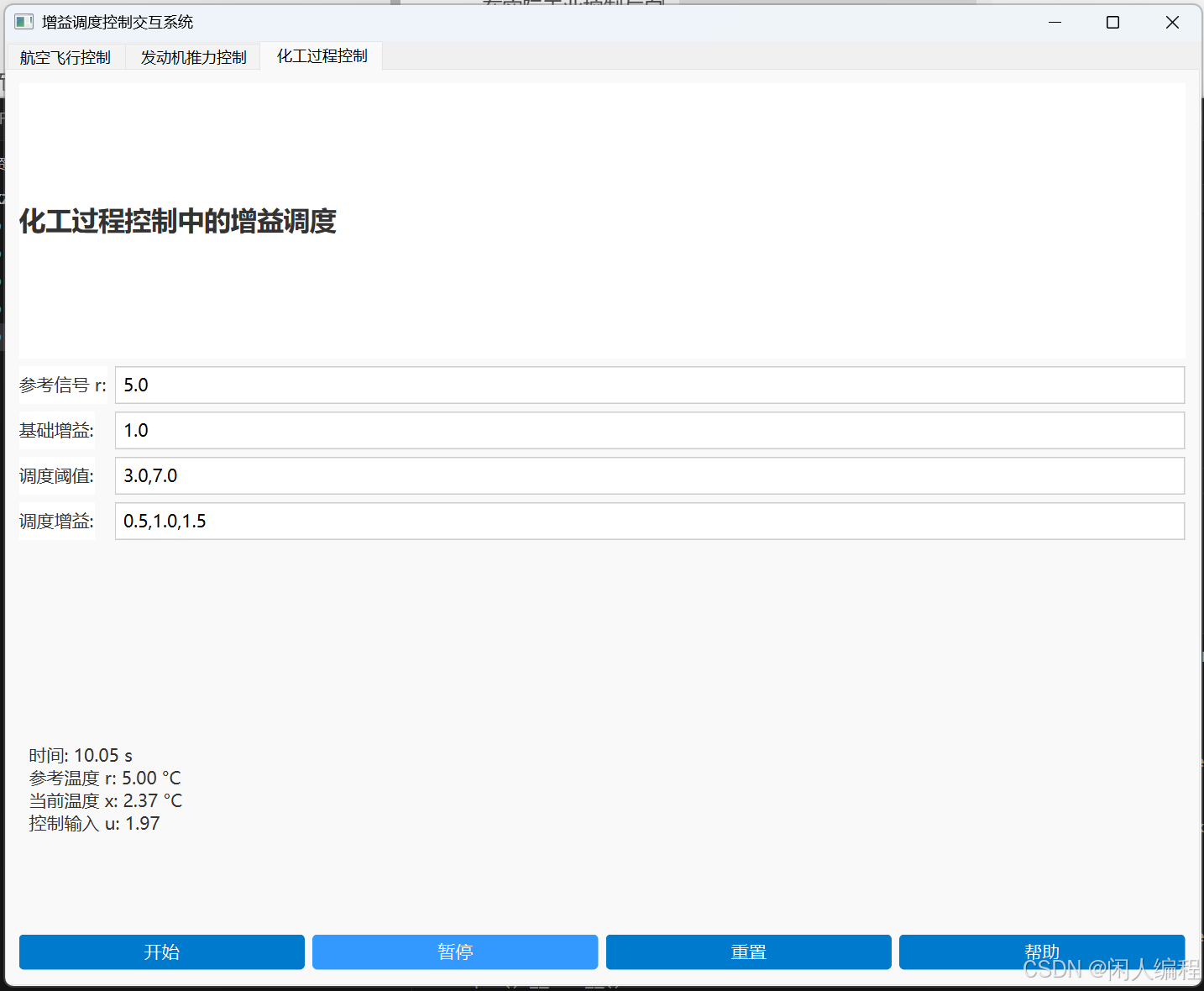
增益调度控制 —— 理论、案例与交互式 GUI 实现
目录 增益调度控制 —— 理论、案例与交互式 GUI 实现一、引言二、增益调度控制的基本原理三、数学模型与公式推导四、增益调度控制的优势与局限4.1 优势4.2 局限五、典型案例分析5.1 案例一:航空飞行控制中的增益调度5.2 案例二:发动机推力控制中的增益调度5.3 案例三:化工…...
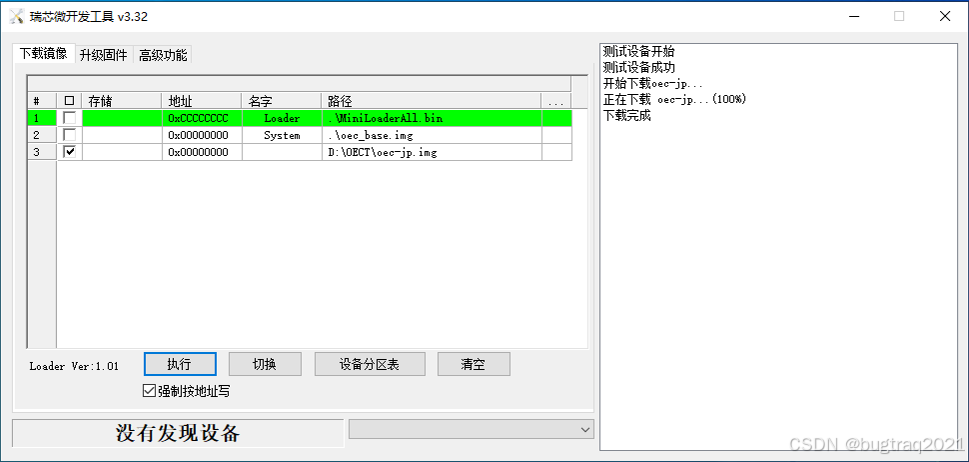
关于OEC/OEC-turbo刷机问题的一些解决方法(2)——可能是终极解决方法了
前面写了两篇关于OEC/OEC-turbo刷机问题的文章了,从刷机过程、刷机中遇到的问题,以及遇到最多但始终无法有效解决的下载boot失败的问题的剖析,最近确实也做了一些工作,虽然没有最终解决,但也算是这系列文章里面阶段性的…...

前后端接口参数详解与 Mock 配置指南【大模型总结】
前后端接口参数详解与 Mock 配置指南 一、前端请求参数类型及 Mock 处理 1.1 URL 路径参数 (Path Parameters) 场景示例: GET /api/users/{userId}/orders/{orderId}Mock.js 处理: Mock.mock(/\/api\/users\/(\d)\/orders\/(\d)/, get, (options) &g…...
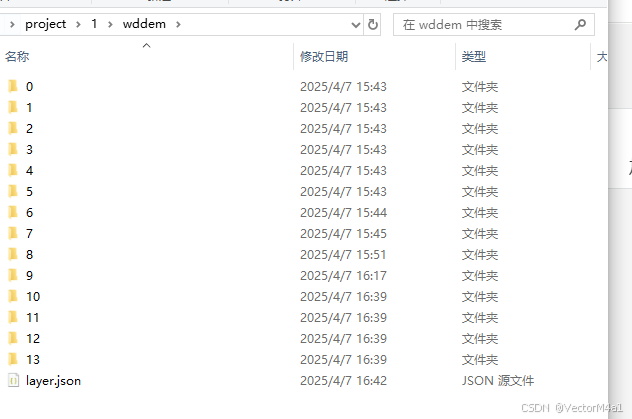
瓦片数据合并方法
影像数据 假如有两份影像数据 1.全球底层影像0-5级别如下: 2.局部高清影像数据级别9-14如下: 合并方法 将9-14文件夹复制到全球底层0-5的目录下 如下: 然后合并xml文件 使得Tileset设置到最高级(包含所有级别)&…...

第16届蓝桥杯单片机模拟试题Ⅰ
试题 代码 sys.h #ifndef __SYS_H__ #define __SYS_H__#include <STC15F2K60S2.H> //onewire.c float getT(); //sys.c extern unsigned char UI; extern bit touch_mode; extern float jiaozhun; extern float canshu; extern float temper; void init74hc138(unsigned…...
mac 卸载流氓软件安全助手
之前个人电脑在公司使用过一段时间,为了使用网线联网安装了公司指定的 联软上网助手,谁知安装容易卸载难,后来找运维来卸载,输入管理员密码后,也无反应,最后不了了之了,这个毒瘤软件长期在后台驻…...

EM算法到底是什么东东
EM(Expectation-Maximization期望最大化)算法是机器学习中非常重要的一类算法,广泛应用于聚类、缺失数据建模、隐变量模型学习等场景,比如高斯混合模型(GMM)就是经典应用。 🐤 第一步ÿ…...

⭐算法OJ⭐滑动窗口最大值【双端队列(deque)】Sliding Window Maximum
文章目录 双端队列(deque)详解基本特性常用操作1. 构造和初始化2. 元素访问3. 修改操作4. 容量操作 性能特点时间复杂度:空间复杂度: 滑动窗口最大值题目描述方法思路解决代码 双端队列(deque)详解 双端队列(deque,全称double-ended queue)是…...

oracle 快速创建表结构
在 Oracle 中快速创建表结构(仅复制表结构,不复制数据)可以通过以下方法实现,适用于需要快速复制表定义或生成空表的场景 1. 使用 CREATE TABLE AS SELECT (CTAS) 方法 -- 复制源表的全部列和数据类型,但不复制数据 C…...

沧州铁狮子
又名“镇海吼”,是中国现存年代最久、形体最大的铸铁狮子,具有深厚的历史文化底蕴和独特的艺术价值。以下是关于沧州铁狮子的详细介绍: 历史背景 • 铸造年代:沧州铁狮子铸造于后周广顺三年(953年)&#…...
Python•判断循环
ʕ⸝⸝⸝˙Ⱉ˙ʔ ♡ 判断🍰常用的判断符号(比较运算符)andor括号notin 和 not inif-elif-else循环🍭计数循环 forrange()函数简易倒计时enumerate()函数zip()函数遍历列表遍历元组遍历字符串遍历字典条件循环 while提前跳转 continue跳出循环 break能量站😚判断🍰 …...

【力扣hot100题】(060)分割回文串
每次需要判断回文串,这点比之前几题回溯题目复杂一些。 还有我怎么又多写了循环…… class Solution { public:vector<vector<string>> result;string s;bool palindromic(string s){for(int i0;i<s.size()/2;i) if(s[i]!s[s.size()-1-i]) return …...