了解 DeepSeek R1
了解DeepSeek R1
R1探索纯强化学习是否可以在没有监督微调的情况下学会推理的能力。
‘Aha’ Moment
这种现象有点类似于人类在解决问题时突然意识到的方式,以下是它的工作原理:
- 初始尝试:模型对解决问题进行初始尝试
- 识别:识别潜在的错误或不一致
- 自我纠正:它根据这种识别调整其方法
- 解释:它可以解释为什么新方法更好
这种能力从 RL 训练中自然而然地出现,没有明确编程,展示了学习,而不仅仅是从训练数据中记住一个过程。
训练过程
- DeepSeek-R1-Zero: 纯粹使用强化学习训练的模型。
- DeepSeek-R1: 基于 DeepSeek-R1-Zero 构建并添加监督微调的模型。
| Feature | DeepSeek-R1-Zero | DeepSeek-R1 |
|---|---|---|
| Training Approach | Pure RL | Multi-phase (SFT + RL) |
| Fine-tuning | None | Supervised fine-tuning |
| Reasoning Capability | Emergent | Enhanced |
| AIME Performance | 71.0% | 79.8% |
| Key Characteristics | Strong reasoning but readability issues | Better language consistency and readability |
1. Cold Start Phase(Quality Foundation)
2. Reasoning RL Phase(Capability Building)
此阶段采用基于规则的强化学习,奖励与解决方案的正确性直接相关,无需单独的奖励模型,从而简化了训练过程。
- language consistency reward
- human preferences reward
- answer reward
- format reward
3. Rejection Sampling Phase(Quality Control)
侧重于推理,此阶段整合来自其他领域的数据,以增强模型在编写、角色扮演和其他通用任务方面的能力
4. Diverse RL Phase(Broad Alignment)
最后的 Diverse RL 阶段使用复杂的混合方法处理多种任务类型。对于确定性任务,它采用基于规则的奖励,而主观任务则通过 LLM 反馈进行评估。此阶段旨在通过其创新的混合奖励方法实现人类偏好对齐,将基于规则的系统的精确性与语言模型评估的灵活性相结合。
- rule-base reward : math、code、logical reasoning
- model-reward : upon the DeepSeek-V3
Group Relative Policy Optimization(GRPO)
GRPO 的新颖之处在于它能够 “直接优化以纠正偏好”。这意味着将模型与所需输出对齐的途径更直接、更高效,这与 PPO 等传统强化学习算法形成鲜明对比。下面通过其三个主要组件来分解 GRPO 的工作原理。
1. Group Formation: Creating Multiple Solutions
GRPO 的第一步非常直观 - 它类似于学生通过尝试多种方法解决难题的方式。当给出提示时,它会创建多次尝试来解决同一问题(通常为 4、8 或 16 次不同的尝试)。
2. Preference Learning: Understanding What Makes a Good Solution
这就是 GRPO 最具特色的地方,与其他需要单独奖励模型来预测解决方案可能有多好的 RLHF 方法不同,GRPO 可以使用任何函数或模型来评估解决方案的质量。例如,我们可以使用 length 函数来奖励较短的响应,或使用数学求解器来奖励准确的数学解决方案。
GRPO 不仅给出绝对分数,还对每组内的奖励进行标准化。它使用一个简单但有效的公式来估计群体相对优势:
Advantage = (reward - mean(group_rewards)) / std(group_rewards)
3. Optimization: Learning from Experience
最后一步是 GRPO 教模型根据它从评估一组解决方案中学到的知识进行改进。这种方法被证明比传统方法更稳定,因为:
- 它着眼于多个解决方案,而不是一次只比较两个
- 基于组的规范化有助于防止奖励扩展出现问题
- KL 处罚就像一个安全网,确保模型在学习新事物时不会忘记它已经知道的东西
4. GRPO Algorithm in Pseudocode
Input:
- initial_policy: Starting model to be trained
- reward_function: Function that evaluates outputs
- training_prompts: Set of training examples
- group_size: Number of outputs per prompt (typically 4-16)Algorithm GRPO:
1. For each training iteration:a. Set reference_policy = initial_policy (snapshot current policy)b. For each prompt in batch:i. Generate group_size different outputs using initial_policyii. Compute rewards for each output using reward_functioniii. Normalize rewards within group:normalized_advantage = (reward - mean(rewards)) / std(rewards)iv. Update policy by maximizing the clipped ratio:min(prob_ratio * normalized_advantage, clip(prob_ratio, 1-epsilon, 1+epsilon) * normalized_advantage)- kl_weight * KL(initial_policy || reference_policy)where prob_ratio is current_prob / reference_probOutput: Optimized policy model
Limitations and Challenges of GRPO
- 生成成本:与仅生成一个或两个完成的方法相比,为每个提示生成多个完成 (4-16) 会增加计算要求。
- 批量大小约束:需要一起处理完成组可能会限制有效的批量大小,从而增加训练过程的复杂性,并可能减慢训练速度。
- 奖励函数设计:训练的质量在很大程度上取决于精心设计的奖励函数。设计不佳的奖励可能会导致意外行为或针对错误目标的优化。
- 组大小权衡:选择最佳组大小涉及平衡解决方案的多样性与计算成本。样本太少可能无法提供足够的多样性,而样本太多会增加训练时间和资源需求。
- KL 背离调整:为 KL 背离惩罚找到合适的平衡需要仔细调整 - 太高会导致模型无法有效学习,太低并且可能会偏离其初始能力太远。
相关文章:

了解 DeepSeek R1
了解DeepSeek R1 R1探索纯强化学习是否可以在没有监督微调的情况下学会推理的能力。 ‘Aha’ Moment 这种现象有点类似于人类在解决问题时突然意识到的方式,以下是它的工作原理: 初始尝试:模型对解决问题进行初始尝试识别:识别…...
局域网:电脑或移动设备作为主机实现局域网访问
电脑作为主机 1. 启用电脑的网络发现、SMB功能 2. 将访问设备开启WIFI或热点,用此电脑连接;或多台设备连接到同一WIFI 3. 此电脑打开命令行窗口,查看电脑本地的IP地址 Win系统:输入"ipconfig",回车后如图 4.…...
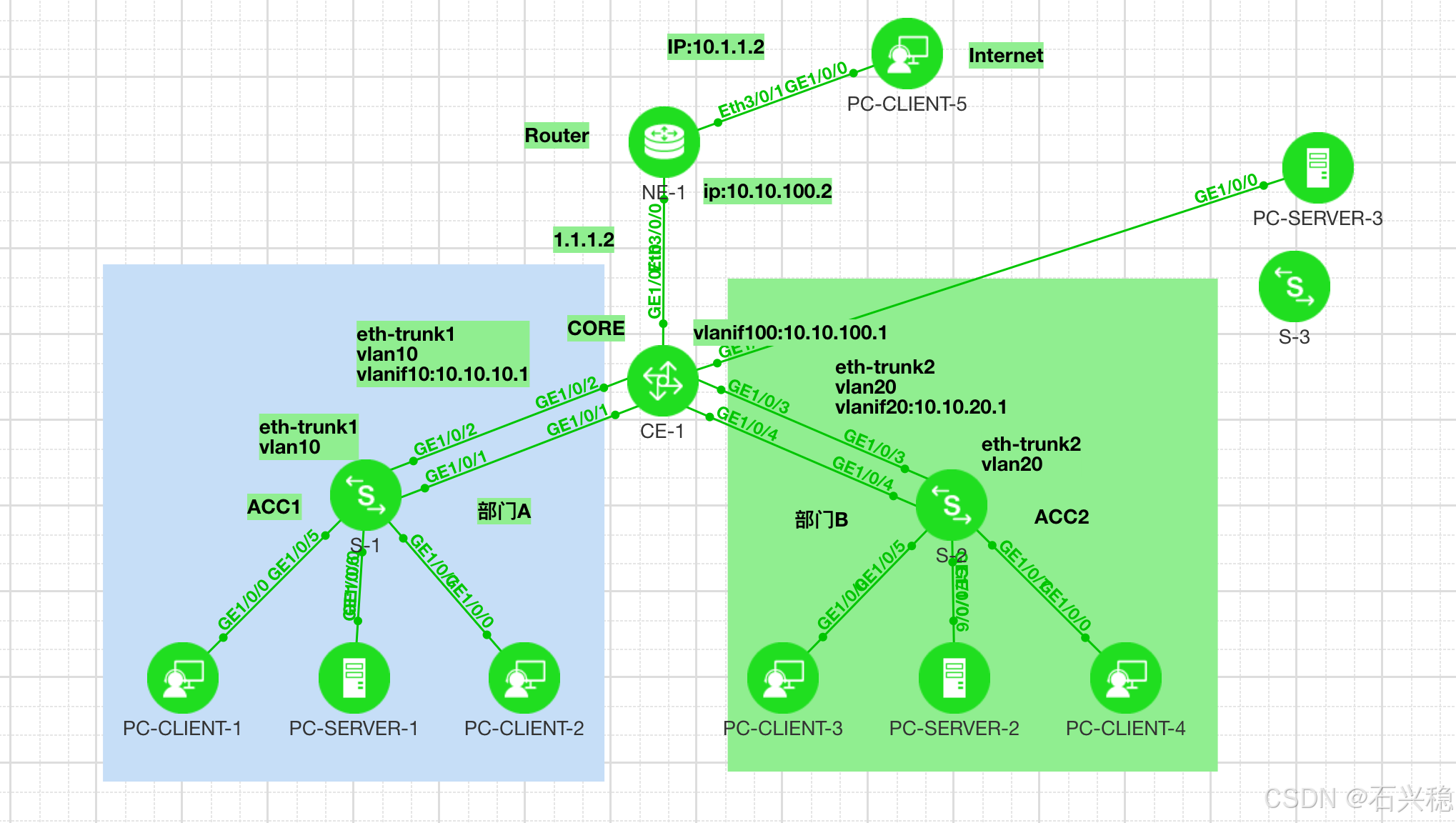
小型园区组网图
1. 在小型园区中,S5735-L-V2通常部署在网络的接入层,S8700-4通常部署在网络的核心,出口路由器一般选用AR系列路由器。 2. 接入交换机与核心交换机通过Eth-Trunk组网保证可靠性。 3. 每个部门业务划分到一个VLAN中,部门间的业务在C…...
数据分享:汽车测评数据
说明:如需数据可以直接到文章最后关注获取。 1.数据背景 Car Evaluation汽车测评数据集是一个经典的机器学习数据集,最初由 Marko Bohanec 和 Blaz Zupan 创建,并在 1997 年发表于论文 "Classifier learning from examples: Common …...

python小整数池和字符串贮存
在Python中,**小整数池**是一种优化机制,用于减少内存使用和加速小整数的创建。 ### 小整数池的工作原理 - **范围**:Python会预先创建并缓存-5到256之间的整数对象。这些对象在解释器启动时就已经创建,并且会一直驻留在内存中。…...
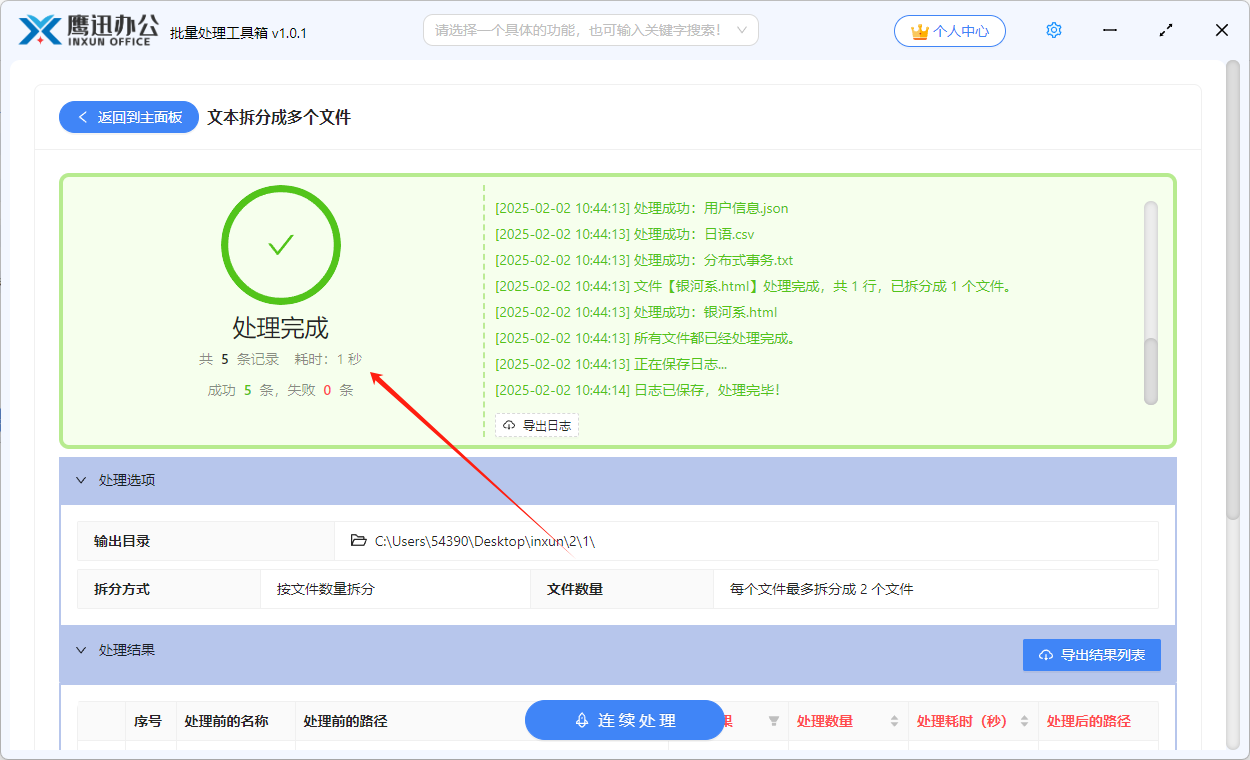
批量将 txt/html/json/xml/csv 等文本拆分成多个文件
我们的文本文件太大的时候,我们通常需要对文本文件进行拆分,比如按多少行一个文件将一个大的文本文件拆分成多个小的文本文件。这样我们在打开或者传输的时候都比较方便。今天就给大家介绍一种同时对多个文本文件进行批量拆分的方法,可以快速…...
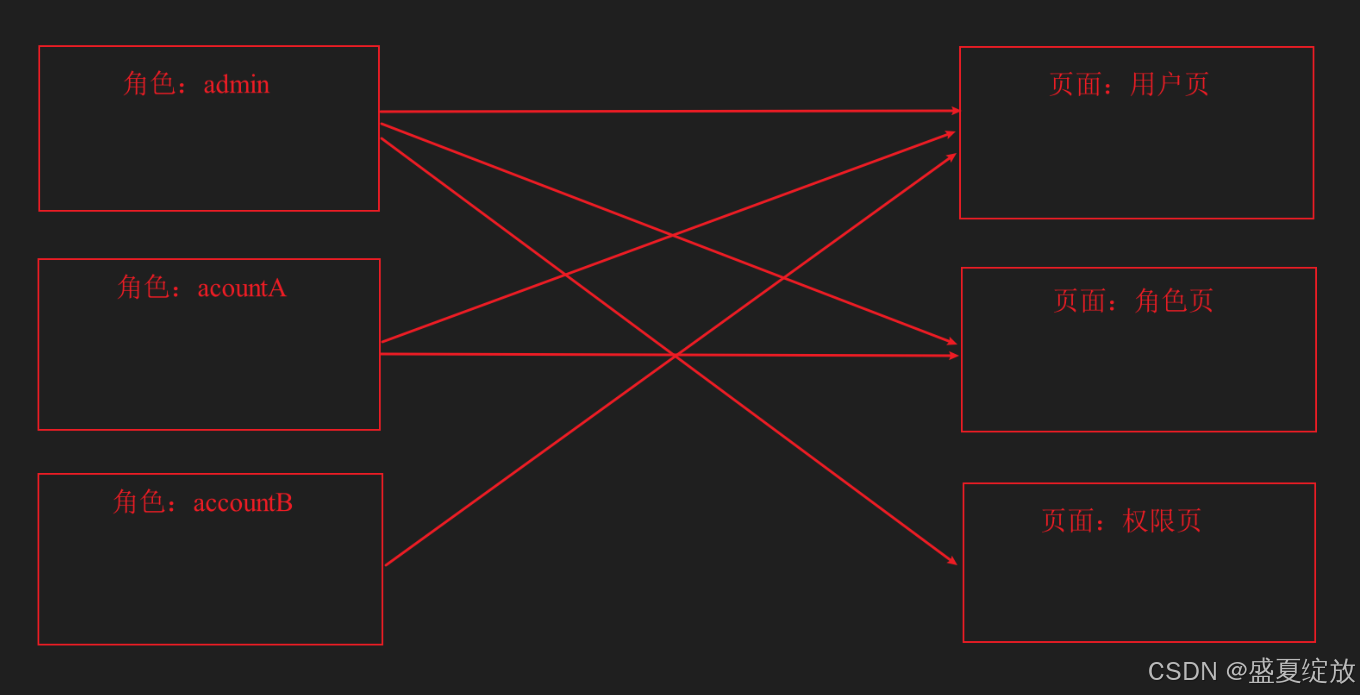
Vue3 路由权限管理:基于角色的路由生成与访问控制
Vue3 路由权限管理:基于角色的路由生成与访问控制 一、核心概念 1.1 大致流程思路: 用户在登录完成的时候,后端给出一个此登录用户对应的角色名字,此时可以将这个用户的角色存起来(vuex/pinia)中,在设置路由时的met…...

LLM Agents的历史、现状与未来趋势
引言 大型语言模型(Large Language Model, LLM)近年在人工智能领域掀起革命,它们具备了出色的语言理解与生成能力。然而,单纯的LLM更像是被动的“回答者”,只能根据输入给出回复。为了让LLM真正“行动”起来ÿ…...
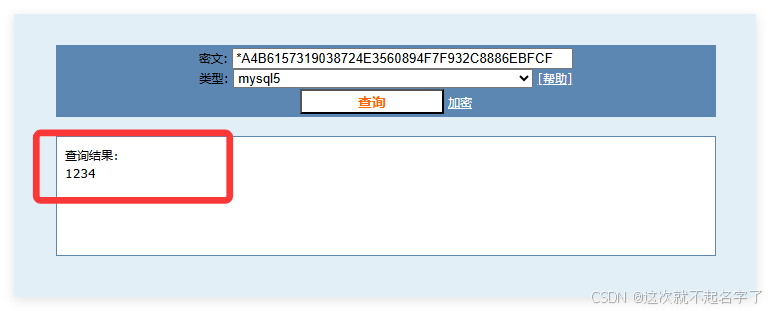
忘记mysql的root用户密码(已解决)
1、打开数据库可视化界面(比如MySQL workbench) 2、执行select host,user,authentication_string from mysql.user; 3、把‘authentication_string’下面的字段 复制到MD5在线解密网页中(比如md5在线解密)...

【Pandas】pandas DataFrame set_flags
Pandas2.2 DataFrame Attributes and underlying data 方法描述DataFrame.index用于获取 DataFrame 的行索引DataFrame.columns用于获取 DataFrame 的列标签DataFrame.dtypes用于获取 DataFrame 中每一列的数据类型DataFrame.info([verbose, buf, max_cols, …])用于提供 Dat…...

Vue3.2 项目打包成 Electron 桌面应用
本文将详细介绍如何将基于 Vue3.2 的项目打包成 Electron 桌面应用。通过结合 Electron 和 Vue CLI 工具链,可以轻松实现跨平台桌面应用的开发与发布。 1. 项目结构说明 项目主要分为以下几个部分: electron/main.js:Electron 主进程文件。…...

git stash pop 后反悔操作
当使用 git stash pop 应用并删除某个存储(stash)后,如果想撤销该操作(即恢复工作目录到 pop 前的状态,并重新将存储放回存储栈),可以按以下步骤操作: 1 强制丢弃所有未提交的更改&…...

Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结
以下是 Spring Boot 集成 MongoDB 时自动创建的核心 Bean 的详细说明及表格总结: 核心 Bean 列表及详细说明 1. MongoClient 类型:com.mongodb.client.MongoClient作用: MongoDB 客户端核心接口,负责与 MongoDB 服务器建立连接、…...

TypeScript面试题集合【初级、中级、高级】
初级面试题 什么是TypeScript? TypeScript是JavaScript的超集,由Microsoft开发,它添加了可选的静态类型和基于类的面向对象编程。TypeScript旨在解决JavaScript的某些局限性,比如缺乏静态类型和基于类的面向对象编程,…...
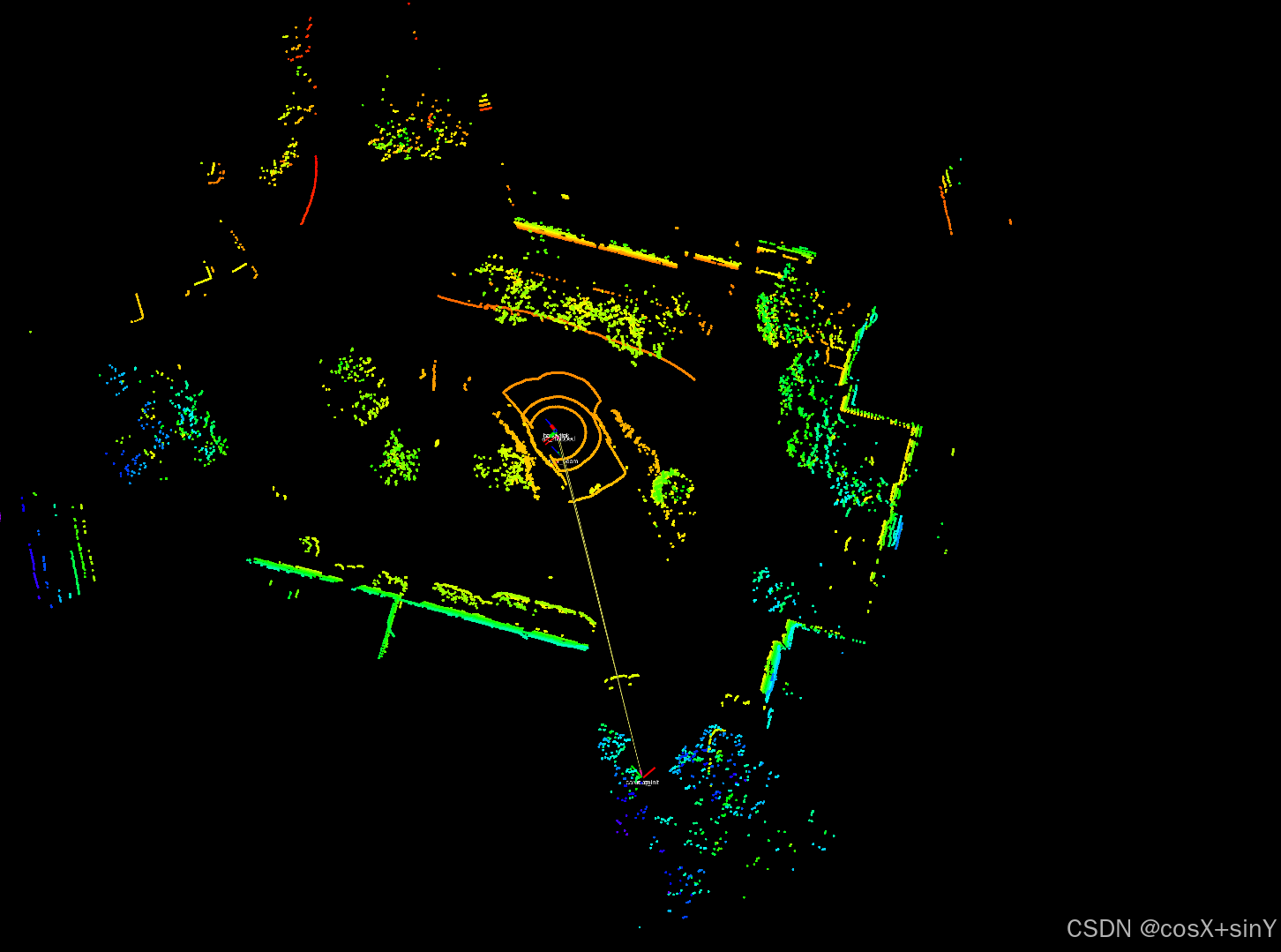
ubuntu 20.04 编译和运行SC-LeGo-LOAM
1.搭建文件目录和clone代码 mkdir -p SC-LeGo-LOAM/src cd SC-LeGo-LOAM/src git clone https://github.com/AbangLZU/SC-LeGO-LOAM.git cd .. 2.修改代码 需要注意的是原作者使用的是Ouster OS-64雷达,需要更改utility.h文件中适配自己的雷达类型,而…...
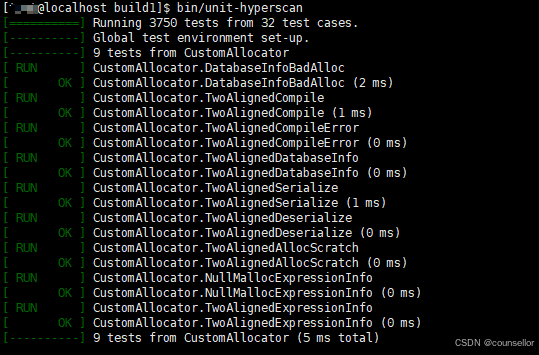
CentOS 7安装hyperscan
0x00 前言 HyperScan是一款由Intel开发的高性能正则表达式匹配库,专为需要快速处理大量数据流的应用场景而设计。它支持多平台运行,包括Linux、Windows和macOS等操作系统,并针对x86架构进行了优化,以提供卓越的性能表现。HyperSc…...

Quartz MisFire补偿机制 任务补偿 任务延迟 错过触发策略
介绍 在 Quartz 中,MisFire(错过触发)是指触发器错过了预定的触发时间,通常是由于系统延迟、任务执行时间过长或者调度器本身未能及时执行任务等原因。这种情况可能会导致任务无法按预期的时间执行。为了应对这些问题,…...

AI训练存储架构革命:存储选型白皮书与万卡集群实战解析
一、引言 在人工智能技术持续高速发展的当下,AI 训练任务对存储系统的依赖愈发关键,而存储系统的选型也变得更为复杂。不同的 AI 训练场景,如机器学习与大模型训练,在模型特性、GPU 使用数量以及数据量带宽等方面的差异ÿ…...

谢志辉和他的《韵之队诗集》:探寻生活与梦想交织的诗意世界
大家好,我是谢志辉,一个扎根在文字世界,默默耕耘的写作者。写作于我而言,早已不是简单的爱好,而是生命中不可或缺的一部分。无数个寂静的夜晚,当世界陷入沉睡,我独自坐在书桌前,伴着…...
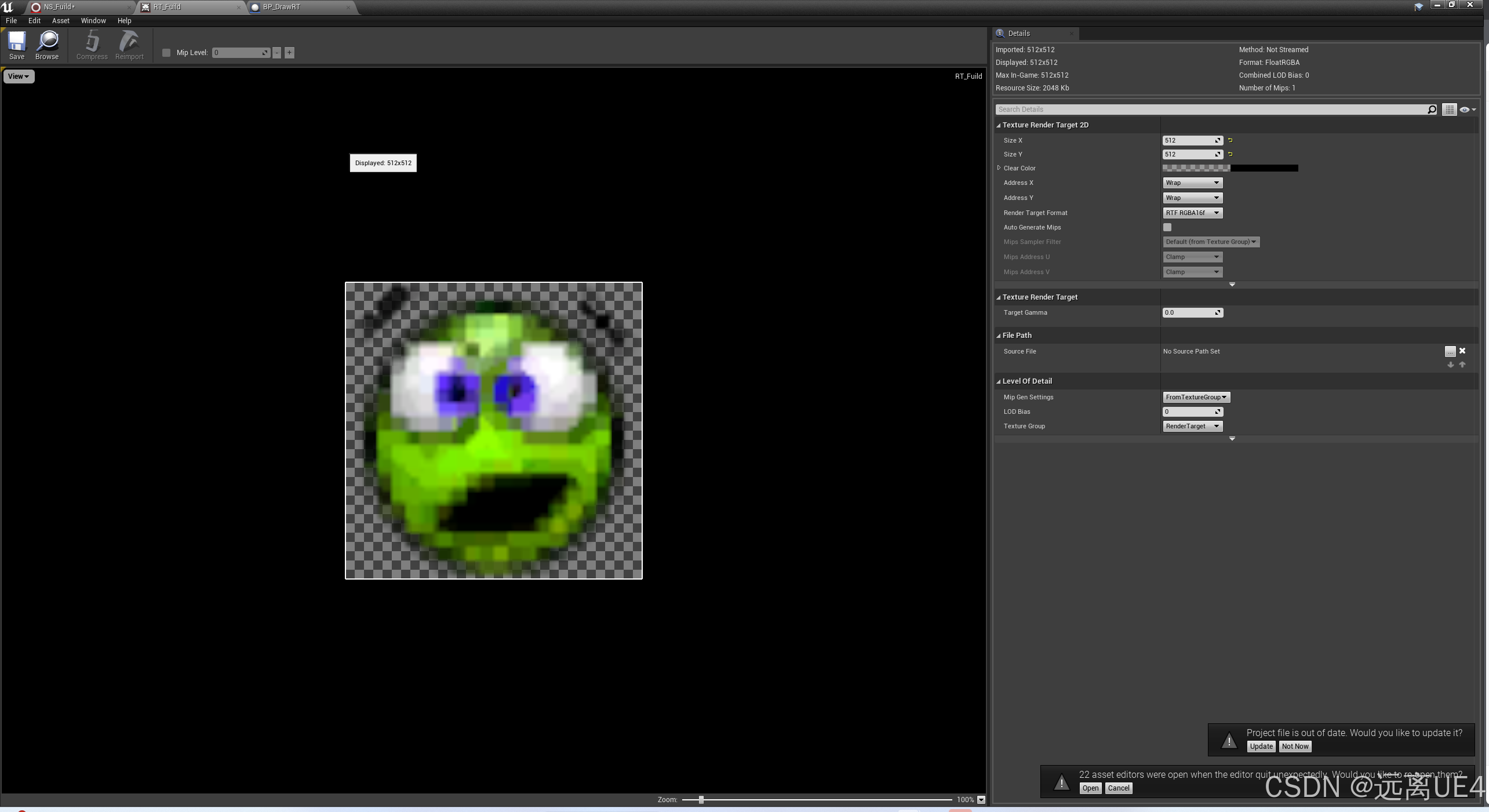
UE5 Simulation Stage
首先将Grid2D创建出来,然后设置值,Grid2D类似于在Niagara系统中的RenderTarget2D,可以进行绘制,那么设置大小为512 * 512 开启Niagara粒子中的Simulation Stage 然后开始编写我们的自定义模块 模块很简单,TS就是Textur…...

Swift 解 LeetCode 250:搞懂同值子树,用递归写出权限系统检查器
文章目录 前言问题描述简单说:痛点分析:到底难在哪?1. 子树的概念搞不清楚2. 要不要“递归”?递归从哪开始?3. 怎么“边遍历边判断”?这套路不熟 后序遍历 全局计数器遍历过程解释一下:和实际场…...

怎样使用Python编写的Telegram聊天机器人
怎样使用Python编写的Telegram聊天机器人 代码直接运行可用 以下是对这段代码的详细解释: 1. 导入必要的库 import loggingfrom telegram import Update from telegram.ext import ApplicationBuilder, ContextTypes, CommandHandler, filters, MessageHandler import log…...

Elixir语言的移动应用安全
Elixir语言的移动应用安全解析 引言 在当今的数字化时代,移动应用已经成为我们日常生活中不可或缺的一部分。从购物、社交到在线银行,几乎每一个生活领域都与移动应用紧密相连。然而,随着应用的普及,安全问题也随之而来。如何确…...

动态估算gas和gasPrice
目录 一、什么是动态估算? 二、动态估算 Gas(代码示例) ✅ 使用 Ethers.js 估算 gasLimit: 💡 发送交易时加一点 buffer: 三、动态估算 gasPrice / maxFee ✅ 获取当前 baseFee(用 provider): ✅ 搭配交易一起发送: 四、完整组合:动态估算 Gas + EIP-1559 费用…...

数据清洗
map阶段:按行读入内容,对内容进行检查,如果字段的个数少于等于11,就删除这条日志(不保留)去除日志中字段个数小于等于11的日志内容。 <偏移量,第一行的内容> → <通过刷选之后的第一行…...
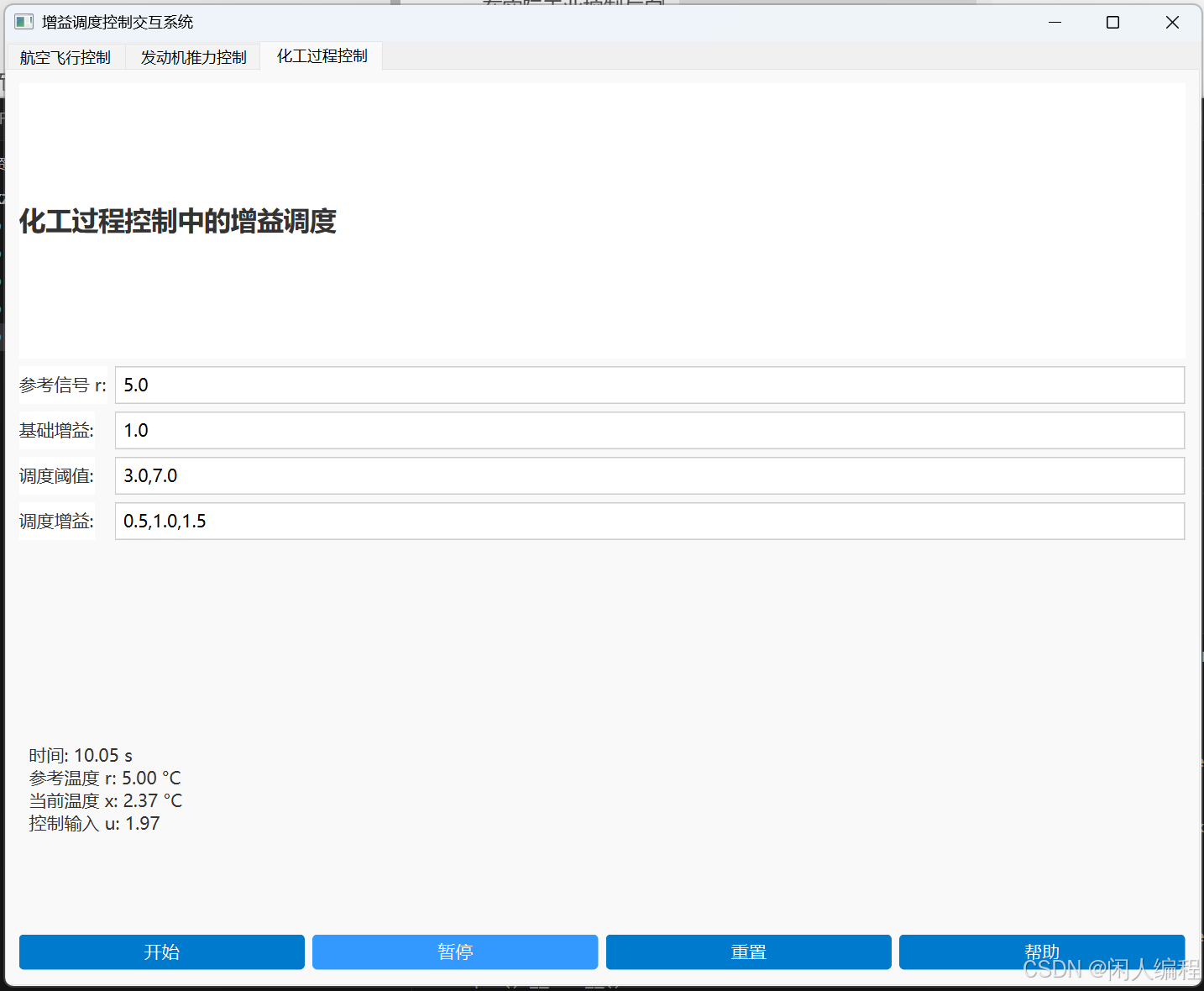
增益调度控制 —— 理论、案例与交互式 GUI 实现
目录 增益调度控制 —— 理论、案例与交互式 GUI 实现一、引言二、增益调度控制的基本原理三、数学模型与公式推导四、增益调度控制的优势与局限4.1 优势4.2 局限五、典型案例分析5.1 案例一:航空飞行控制中的增益调度5.2 案例二:发动机推力控制中的增益调度5.3 案例三:化工…...
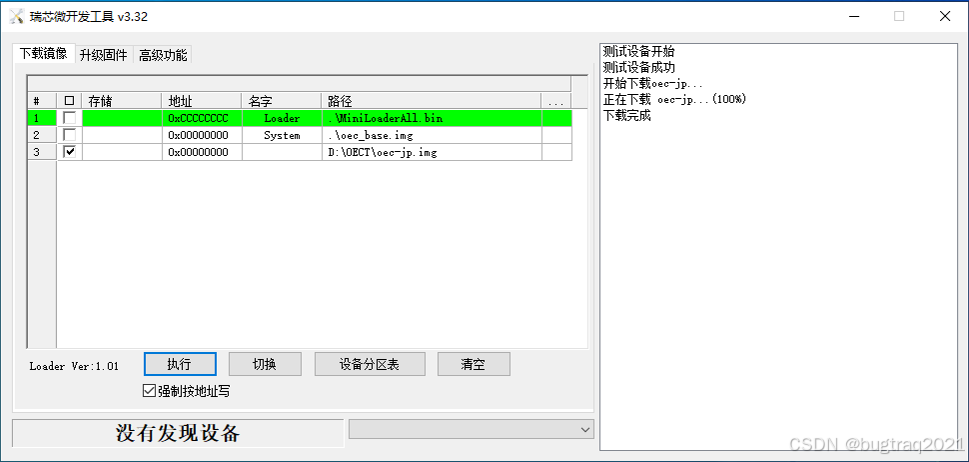
关于OEC/OEC-turbo刷机问题的一些解决方法(2)——可能是终极解决方法了
前面写了两篇关于OEC/OEC-turbo刷机问题的文章了,从刷机过程、刷机中遇到的问题,以及遇到最多但始终无法有效解决的下载boot失败的问题的剖析,最近确实也做了一些工作,虽然没有最终解决,但也算是这系列文章里面阶段性的…...

前后端接口参数详解与 Mock 配置指南【大模型总结】
前后端接口参数详解与 Mock 配置指南 一、前端请求参数类型及 Mock 处理 1.1 URL 路径参数 (Path Parameters) 场景示例: GET /api/users/{userId}/orders/{orderId}Mock.js 处理: Mock.mock(/\/api\/users\/(\d)\/orders\/(\d)/, get, (options) &g…...
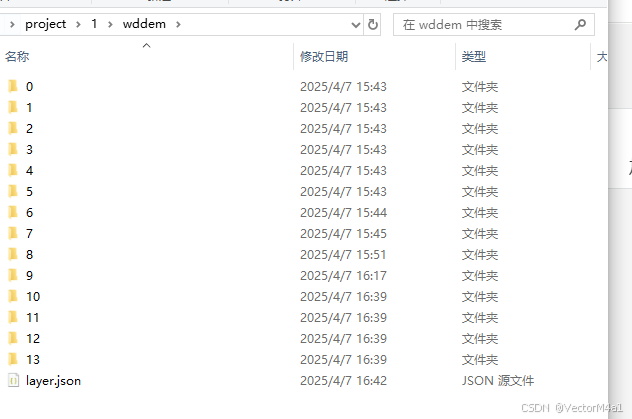
瓦片数据合并方法
影像数据 假如有两份影像数据 1.全球底层影像0-5级别如下: 2.局部高清影像数据级别9-14如下: 合并方法 将9-14文件夹复制到全球底层0-5的目录下 如下: 然后合并xml文件 使得Tileset设置到最高级(包含所有级别)&…...

第16届蓝桥杯单片机模拟试题Ⅰ
试题 代码 sys.h #ifndef __SYS_H__ #define __SYS_H__#include <STC15F2K60S2.H> //onewire.c float getT(); //sys.c extern unsigned char UI; extern bit touch_mode; extern float jiaozhun; extern float canshu; extern float temper; void init74hc138(unsigned…...