Python爬虫第5节-urllib的异常处理、链接解析及 Robots 协议分析
目录
一、处理异常
1.1 URLError
1.2 HTTPError
二、解析链接
2.1 urlparse()
2.2 urlunparse()
2.3 urlsplit()
2.4 urlunsplit()
2.5 urljoin()
2.6 urlencode()
2.7 parse_qs()
2.8 parse_qsl()
2.9 quote()
2.10 unquote()
三、分析网站Robots协议
3.1 Robots协议
3.2 爬虫名称
3.3 robotparser
一、处理异常
上一节,我们学习了如何发送网络请求。但在实际使用中,网络情况往往不稳定,很容易出现异常。要是对这些异常不管不顾,程序就可能报错,甚至直接终止运行。所以,对异常进行处理是很有必要的。
在Python的urllib库中,`error`模块专门定义了`request`模块在运行时可能产生的各种异常。也就是说,当`request`模块执行出现问题时,就会抛出`error`模块里预先定义好的异常 。
1.1 URLError
`URLError`类包含在urllib库的`error`模块里,它从`OSError`类继承而来,是`error`模块里处理异常的基础类。只要是`request`模块运行过程中产生的异常,都可以通过捕获`URLError`类来处理。`URLError`类有个`reason`属性,借助它能够获取到报错的具体原因。
下面通过实例来看:
from urllib import request, error
try:response = request.urlopen('https://cuiqingcai.com/index.htm')
except error.URLError as e:print(e.reason)我们尝试打开一个不存在的页面,正常情况下应该会报错。但通过捕获`URLError`这个异常,运行结果如下:
Not Found
程序没直接报错,而是输出了上面那些内容。这么做,一方面能防止程序因异常而终止运行,另一方面也实现了对异常的有效处理。
1.2 HTTPError
`HTTPError`隶属于`URLError`子类,主要用来处理HTTP请求时出现的错误,像认证请求失败这类问题。它包含3个属性:
- `code`:给出HTTP状态码,比如404意味着网页找不到,500代表服务器内部出错。
- `reason`:和父类功能相同,都是为了给出错误的成因。
- `headers`:返回请求头信息。
下面通过几个实例来了解:
from urllib import request, error
try:response = request.urlopen('https://cuiqingcai.com/index.htm')
except error.HTTPError as e:print(e.reason, e.code, e.headers, sep='\n')运行结果如下:
Not Found
404
Server:nginx/1.4.6(Ubuntu)
Date:Wed,03 Aug 2016 08:54:22 GMT
Content-Type:text/html;charset=UTF-8
Transfer-Encoding:chunked
Connection:close
X-Powered-By:PHP/5.5.9-1ubuntu4.14
Vary: Cookie
Expires:wed,11 Jan 1984 05:00:00 GMT
Cache-Control:no-cache,must-revalidate,max-age=0
Pragma:no-cache
Link:<https://cuiqingcai.com/wp-json/>;rel="https://api.w.org/"
同样是访问该网址,这里捕获了`HTTPError`异常,并输出了`reason`、`code`和`headers`属性。由于`URLError`是`HTTPError`的父类,因此可以先捕获子类错误,再捕获父类错误。
上述代码更优的写法如下:
from urllib import request, error
try:response = request.urlopen('https://cuiqingcai.com/index.htm')
except error.HTTPError as e:print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:print(e.reason)
else:print('Request Successfully')按照这种方式,程序会优先捕获`HTTPError`异常,借此获取错误状态码、错误原因、请求头`headers`等信息。要是捕获的不是`HTTPError`异常,程序就会捕获`URLError`异常,并输出对应的错误原因。最后,借助`else`语句来处理程序正常运行时的逻辑,这算得上是一种比较好的异常处理办法。
需要注意,`reason`属性返回的内容并非总是字符串,有时也可能是一个对象。
看下面的实例:
import socket
import urllib.request
import urllib.error
try:response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:print(type(e.reason))if isinstance(e.reason, socket.timeout):print('TIME OUT')这里我们直接设置超时时间,强制抛出`timeout`异常。运行结果如下:
<class'socket.timeout'>
TIME OUT
从运行结果能看到,`reason`属性返回的是`socket.timeout`类。基于这一点,我们可以借助`isinstance()`方法来判断它的类型,从而对异常进行更细致的分析。
至此我们了解了`error`模块的使用方法。在编写程序时,合理地捕获异常,不仅能更准确地判断异常类型,还能增强程序的稳定性,减少错误发生。
二、解析链接
前面讲过,urllib库包含`parse`模块。这个模块制定了处理URL的标准接口,能实现URL各部分的提取、整合,以及链接的转换。`parse`模块支持处理多种协议的URL,像`file`、`fp`、`gopher` ,还有日常常用的`http`、`https`,以及`imap`、`mailto`等。接下来这节,会介绍`parse`模块里一些常用方法,帮助大家体会这些方法在处理URL时有多方便。
2.1 urlparse()
该方法可实现URL的识别和分段。先通过实例来看:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)这里利用`urlparse()`方法对一个URL进行了解析。首先输出解析结果的类型,然后输出结果。运行结果如下:
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
运行后能看到,`urlparse()`方法返回的结果是`ParseResult`类型对象,这个对象包含6个部分,分别为`scheme`、`netloc`、`path`、`params`、`query`和`fragment`。
以`http://www.baidu.com/index.html;user?id=5#comment`这个URL为例,`urlparse()`方法把它拆成了6个部分。仔细观察会发现,解析URL时存在特定分隔符:`://`前面的内容是`scheme`,代表协议类型;第一个`/`前面的是`netloc`,也就是域名,`/`后面的则是`path`,即访问路径;分号`;`前面的是`params`,用来表示参数;问号`?`后面是`query`查询条件,常见于GET类型URL;井号`#`后面是锚点,能直接定位到页面内部特定位置。
由此可知,标准URL格式为`scheme://netloc/path;params?query#fragment`,只要是标准URL,都能通过`urlparse()`方法进行拆分。
除了上述基本解析方式,`urlparse()`方法还有其他配置。下面来看它的API用法:`urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)`,该方法有3个参数:
- `urlstring`:这是必须填写的参数,就是需要解析的URL。
- `scheme`:默认协议类型(如`http`、`https`)。当URL中没有协议信息时,就会将此参数值作为默认协议 。
-`allow_fragments`:指的是是否忽略`fragment`。要是把它设成`False`,`fragment`部分就会被忽略,它会被当成`path`、`parameters`或者`query`的一部分来解析,`fragment`部分就没内容了。
通过实例来看:
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)运行结果如下:
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html', params='user', query='id=5', fragment='comment')
能看到,给的URL开头没有`scheme`信息,但指定了默认的`scheme`参数后,返回结果里的`scheme`就是`https`。
要是URL本身带有`scheme`,比如这样的代码:
result = urlparse("http://www.baidu.com/index.html;user?id=5#comment", scheme='https')运行结果会是:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
这说明,`scheme`参数只有在URL里没有`scheme`信息时才起作用。要是URL里有`scheme`信息,就会把解析出来的`scheme`返回。
`allow_fragments`这个参数决定是否忽略`fragment`。如果把它设成`False`,`fragment`部分就不单独算了,会把它当成`path`、`parameters`或者`query`的一部分,`fragment`部分就没内容了。
下面通过实例来看:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)
```
运行结果如下:
```
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment', fragment='')假设URL中不包含`params`和`query`,再通过实例看一下:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result)运行结果如下:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html#comment', params='', query='', fragment='')
可以发现,当URL中不包含`params`和`query`时,`fragment`便会被解析为`path`的一部分。
返回结果`ParseResult`实际上是一个元组,我们既可以用索引顺序来获取,也可以用属性名获取。示例如下:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result.scheme, result[0], result.netloc, result[1], sep='\n')这里分别用索引和属性名获取了`scheme`和`netloc`,其运行结果如下:
http
http
www.baidu.com
www.baidu.com
可以发现,二者结果一致,两种方法都能成功获取。
2.2 urlunparse()
有了`urlparse()`,相应地就有了它的反向方法`urlunparse()`。它接受的参数是一个可迭代对象,但它的长度必须是6,否则会抛出参数数量不足或过多的问题。先通过实例来看:
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))这里参数`data`使用了列表类型。当然,也可以用其他类型,比如元组或者特定的数据结构。运行结果如下:
http://www.baidu.com/index.html;user?a=6#comment
这样就成功实现了URL的构造。
2.3 urlsplit()
这个方法和`urlparse()`方法非常相似,只不过它不再单独解析`params`这一部分,只返回5个结果。上面例子中的`params`会合并到`path`中。示例如下:
from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result)运行结果如下:
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.html;user', query='id=5', fragment='comment')
可以发现,返回结果是`SplitResult`,它其实也是一个元组类型,既可以用属性获取值,也可以用索引来获取。示例如下:
from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result.scheme, result[0])运行结果如下:
http
http
2.4 urlunsplit()
与`urlunparse()`类似,它也是将链接各个部分组合成完整链接的方法,传入的参数也是一个可迭代对象,例如列表、元组等,唯一的区别是长度必须为5。示例如下:
from urllib.parse import urlunsplit
data = ['http', 'www.baidu.com', 'index.html', 'a=6', 'comment']
print(urlunsplit(data))运行结果如下:
http://www.baidu.com/index.html?a=6#comment
2.5 urljoin()
使用`urlunparse()`和`urlunsplit()`方法,能实现链接的合并。不过,使用这两个方法时,需要有一个特定长度的对象,并且链接的各个部分必须清晰区分开来。
除了上述两种方法,`urljoin()`也能用来生成链接。使用`urljoin()`方法时,第一个参数是`base_url`(基础链接),第二个参数是新链接。这个方法会分析`base_url`中的`scheme`(协议)、`netloc`(域名)和`path`(路径),若新链接中缺少这些部分,它会用`base_url`中的对应部分进行补充,最后返回生成的链接。
下面通过几个实例来看:
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', "https://cuiqingcai.com/index.php"))
print(urljoin('http://www.baidu.com', "?category=2#comment"))
print(urljoin('www.baidu.com', "?category=2#comment"))
print(urljoin('www.baidu.com#comment', "?category=2"))
运行结果如下:
http://www.baidu.com/FAQ.html
https://cuiqingcai.com/FAQ.html
https://cuiqingcai.com/FAQ.html
https://cuiqingcai.com/FAQ.html?question=2
https://cuiqingcai.com/index.php
http://www.baidu.com?category=2#comment
www.baidu.com?category=2#comment
www.baidu.com?category=2
可以发现,`base_url`提供了`scheme`、`netloc`和`path`三项内容。如果这三项在新的链接里不存在,就予以补充;如果新的链接存在,就使用新链接的部分。而`base_url`中的`params`、`query`和`fragment`不起作用。
通过`urljoin()`方法,我们可以轻松实现链接的解析、拼合与生成。
2.6 urlencode()
这里再介绍一个常用方法——`urlencode()`,它在构造GET请求参数时非常有用。示例如下:
from urllib.parse import urlencode
params = {'name': 'germey', 'age': 22}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)这里首先声明了一个字典来表示参数,然后调用`urlencode()`方法将其序列化为GET请求参数。运行结果如下:
http://www.baidu.com?name=germey&age=22
可以看到,参数成功地由字典类型转化为GET请求参数。这个方法非常常用。有时为了更方便地构造参数,我们会事先用字典来表示。要转化为URL的参数时,只需调用该方法即可。
2.7 parse_qs()
有了序列化,必然就有反序列化。如果我们有一串GET请求参数,利用`parse_qs()`方法,就可以将它转回字典。示例如下:
from urllib.parse import parse_qs
query = 'name=germey&age=22'
print(parse_qs(query))运行结果如下:
{'name': ['germey'], 'age': ['22']}
可以看到,这样就成功转回为字典类型了。
2.8 parse_qsl()
另外,还有一个`parse_qsl()`方法,它用于将参数转化为元组组成的列表。示例如下:
from urllib.parse import parse_qsl
query = 'name=germey&age=22'
print(parse_qsl(query))运行结果如下:
[('name', 'germey'), ('age', '22')]
可以看到,运行结果是一个列表,而列表中的每一个元素都是一个元组,元组的第一个内容是参数名,第二个内容是参数值。
2.9 quote()
该方法可以将内容转化为URL编码的格式。URL中带有中文参数时,有时可能会导致乱码问题,此时用这个方法可以将中文字符转化为URL编码。示例如下:
from urllib.parse import quote
keyword = '壁纸'
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url) 这里我们声明了一个中文的搜索文字,然后用`quote()`方法对其进行URL编码,最后得到的结果如下:
https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8
2.10 unquote()
有了`quote()`方法,当然还有`unquote()`方法,它可以进行URL解码。示例如下:
from urllib.parse import unquote
url = 'https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))这是上面得到的URL编码后的结果,这里利用`unquote()`方法还原,结果如下:
https://www.baidu.com/s?wd=壁纸
可以看到,利用`unquote()`方法可以方便地实现解码。
本节中,我们介绍了`parse`模块的一些常用URL处理方法。有了这些方法,我们可以方便地实现URL的解析和构造,建议熟练掌握。
三、分析网站Robots协议
借助urllib库的`robotparser`模块,我们能对网站的Robots协议展开分析。在这一节,我们就来简要认识一下这个模块的使用方法。
3.1 Robots协议
Robots协议又叫爬虫协议、机器人协议,其正式名称是网络爬虫排除标准(Robots Exclusion Protocol)。该协议的作用是告知爬虫和搜索引擎,网站中哪些页面能被抓取,哪些不能被抓取。Robots协议一般以`robots.txt`文本文件的形式存在,并且通常放置在网站的根目录下。
当搜索爬虫访问某个网站时,会首先查看该网站根目录下有没有`robots.txt`文件。要是有这个文件,搜索爬虫就会依据文件里规定的爬取范围进行页面抓取;要是没找到这个文件,搜索爬虫就会访问网站所有可直接访问的页面 。
下面我们看一个`robots.txt`的样例:
User-agent: *
Disallow: /
Allow: /public/这样设置后,所有搜索爬虫就只能爬取`public`目录了。把上面这些内容保存成`robots.txt`文件,放到网站根目录下,和网站入口文件(像`index.php`、`index.html`、`index.jsp`这类)放在一块儿。
`User-agent`用来表示搜索爬虫的名称,设置成`*`就意味着这个协议对所有搜索爬虫都有效。例如设置成:
User-agent: Baiduspider这就说明设置的规则只对百度爬虫起作用。要是有多个`User-agent`记录,那对应的多个爬虫的爬取行为都会受到限制,不过至少得有一条`User-agent`记录。
`Disallow`用来指定不允许抓取的目录,比如设置成`/`,就表示所有页面都不能抓取。
`Allow`一般和`Disallow`搭配使用,很少单独用,它的作用是排除一些限制。这里设置成`/public/`,意思就是除了`public`目录可以抓取,其他页面都不允许抓取。
下面再看几个例子:
- 禁止所有爬虫访问任何目录,代码这么写:
User-agent: *
Disallow: /- 允许所有爬虫访问任何目录,代码是这样:
User-agent: *
Disallow:直接把`robots.txt`文件留空也是可以的。
- 禁止所有爬虫访问网站的某些目录,代码如下:
User-agent: *
Disallow: /private/
Disallow: /tmp/- 只允许某一个爬虫访问,代码这么设置:
User-agent: WebCrawler
Disallow:
User-agent: *
Disallow: /这些都是`robots.txt`文件常见的写法。
3.2 爬虫名称
大家或许会好奇,爬虫的名字是怎么来的?为啥要叫这些名字呢?其实,爬虫名都是有固定规范的。比如百度的爬虫,就叫`BaiduSpider`。下面这张表,列举了一些常见搜索爬虫的名字,以及它们对应的网站 。

3.3 robotparser
认识Robots协议后,就能借助`robotparser`模块解析`robots.txt`文件了。`robotparser`模块里有个`RobotFileParser`类,通过它可以依据某网站的`robots.txt`文件,判断某个爬虫有没有权限爬取该网站的网页。
这个类使用起来很容易,在创建对象时,只要在构造方法中传入`robots.txt`文件的链接就行。它的声明是`urllib.robotparser.RobotFileParser(url='')`。
要是创建对象时没传入链接,默认链接为空,后续也能使用`seturl()`方法来设置链接。
下面讲讲这个类常用的几个方法:
- `seturl()`:专门用来设置`robots.txt`文件的链接。要是创建`RobotFileParser`对象时已经传入了链接,就没必要再用这个方法设置了。
- `read()`:能读取`robots.txt`文件并进行分析。要注意,这个方法会执行读取和分析操作,如果不调用它,后续的爬取权限判断都会返回`False`,所以务必调用这个方法。该方法不会返回具体内容,但会完成文件读取操作。
- `parse()`:用于解析`robots.txt`文件,向它传入`robots.txt`文件的某些行内容,它会按照`robots.txt`的语法规则对这些内容进行分析。
- `can_fetch()`:使用时需传入两个参数,第一个是`User - agent`,第二个是待抓取的URL。这个方法会判断搜索引擎能否抓取该URL,返回结果为`True`或`False`。
- `mtime()`:返回上次抓取和分析`robots.txt`文件的时间。对于长时间进行分析和抓取操作的搜索爬虫而言,定期检查并抓取最新的`robots.txt`文件十分重要,这个方法就能派上用场。
- `modified()`:同样对长时间分析和抓取的搜索爬虫很有用,它会把当前时间设置为上次抓取和分析`robots.txt`文件的时间。
下面我们用实例来看一下:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.seturl('http://www.jianshu.com/robots.txt')
rp.read()
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*', 'http://www.jianshu.com/search?q=python&page=1&type=collections'))这里以简书为例,首先创建`RobotFileParser`对象,然后通过`seturl()`方法设置了`robots.txt`的链接。当然,不用这个方法的话,可以在声明时直接用如下方法设置:
rp = RobotFileParser('http://www.jianshu.com/robots.txt')接着利用`can_fetch()`方法判断了网页是否可以被抓取。运行结果如下:
True
False
这里同样可以使用`parse()`方法执行读取和分析,示例如下:
from urllib.robotparser import RobotFileParser
from urllib.request import urlopen
rp = RobotFileParser()
rp.parse(urlopen('http://www.jianshu.com/robots.txt').read().decode('utf-8').split('\n'))
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*', 'http://www.jianshu.com/search?q=python&page=1&type=collections'))运行结果一样:
True
False
到这里,我们介绍了`robotparser`模块的基本使用方法,还举了一些例子。借助这个模块,我们能轻松判断出哪些页面能被抓取,哪些页面不能被抓取。
参考学习书籍:Python 3网络爬虫开发实战
相关文章:
Python爬虫第5节-urllib的异常处理、链接解析及 Robots 协议分析
目录 一、处理异常 1.1 URLError 1.2 HTTPError 二、解析链接 2.1 urlparse() 2.2 urlunparse() 2.3 urlsplit() 2.4 urlunsplit() 2.5 urljoin() 2.6 urlencode() 2.7 parse_qs() 2.8 parse_qsl() 2.9 quote() 2.10 unquote() 三、分析网站Robots协议 3.1 R…...

26届Java暑期实习面经,腾讯视频一面
短链接的生成原理 如何解决短链接生成的哈希冲突问题 如何加快从短链接到原链接的重定向过程 TCP 和 UDP 协议 如何理解 TCP 是面向连接的 为什么 TCP 的握手是 3 次 IO 模式 是否有真正写过一个底层的 Socket 通信 MySQL 的事务隔离级别 MVCC 机制 什么叫服务的并行 为什么能基…...

Kafka负载均衡挑战解决
本文为 How We Solve Load Balancing Challenges in Apache Kafka 阅读笔记 kafka通过利用分区来在多个队列中分配消息来实现并行性。然而每条消息都有不同的处理负载,也具有不同的消费速率,这样就有可能负载不均衡,从而使得瓶颈、延迟问题和…...

前端性能优化的全方位方案【待进一步结合项目】
以下是前端性能优化的全方位方案,结合代码配置和最佳实践,涵盖从代码编写到部署的全流程优化: 一、代码层面优化 1. HTML结构优化 <!-- 语义化标签减少嵌套 --> <header><nav>...</nav> </header> <main&…...
2025年第二期PMP考试中文报名时间定了!
近日,官方发布了《关于2025年6月15日PMI认证考试的报名通知》。根据通知,中国大陆地区2025年第二期PMI认证考试将于6月15日举行,中文报名将于4月17日正式开始。 一、报名安排 为缓解报名高峰期的网络拥堵,本次考试将采取分地区、…...
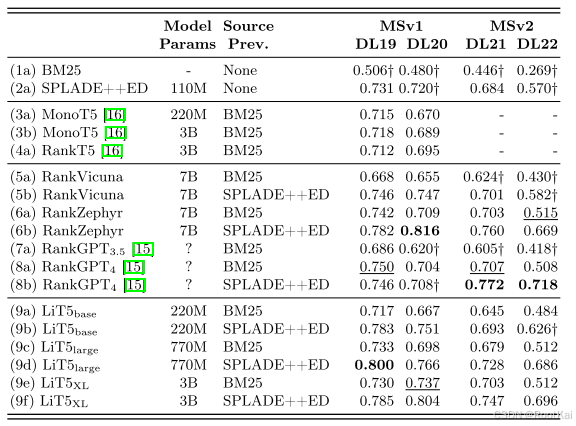
LiT and Lean: Distilling Listwise Rerankers intoEncoder-Decoder Models
文章:ECIR 2025会议 一、动机 背景:利用LLMs强大的能力,将一个查询(query)和一组候选段落作为输入,整体考虑这些段落的相关性,并对它们进行排序。 先前的研究基础上进行扩展 [14,15],…...

【Java面试系列】Spring Boot微服务架构下的分布式事务处理与Seata框架实现原理详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Boot微服务架构下的分布式事务处理与Seata框架实现原理详解 - 3-5年Java开发必备知识 1. 引言 在微服务架构中,分布式事务处理是一个不可避免的挑战。随着业务复杂度的提升,单体应用逐渐演变为微服务架构,而分布式事…...

源码分析之Leaflet图层控制控件Control.Layers实现原理
概述 本文将介绍Leaflet库中最后一个组件,即图层控制组件 Control.Layers。 源码实现 export var Layers Control.extend({options: {collapsed: true,position: "topright",autoZIndex: true,hideSingleBase: false,sortLayers: false,sortFunction:…...

嵌入式软硬件开发,常见通信总线
嵌入式通信总线分类与应用指南 一、片上/板级通信接口(内部互联) I2C总线 核心特性 同步半双工传输,SCL时钟线SDA数据线7/10位地址寻址,支持多主多从架构标准模式100kbps,高速模式3.4Mbps,超高速模式5Mbps…...

[ERROR] Some problems were encountered while processing the POMs
记录一次maven的错误 问题复现: 我在ruoyi-vue-plus项目的ruoyi-modules中新建了一个子项目ruoyi-network-telphonem,然后某一次编译的时候提示SysTenantServiceImpl找不到无参的构造函数,检查了很久都没发现问题,于是我想着删掉本地maven仓…...

Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行?
环境: Ubuntu 20.04 LTS 问题描述: Ubuntu 服务器上运行相关命令,关闭终端就停止服务,怎么才能启动后在后台运行? bash docker/entrypoint.sh解决方案: bash docker/entrypoint.sh 脚本在后台运行&…...

前端工具方法整理
文章目录 1.在数组中找到匹配项,然后创建新对象2.对象转JSON字符串3.JSON字符串转JSON对象4.有个响应式对象,然后想清空所有属性5.判断参数不为空6.格式化字符串7.解析数组内容用逗号拼接 1.在数组中找到匹配项,然后创建新对象 const modifi…...
关于Deepseek本地AI知识文档库被联网访问方法的探索
背景: 根据前面的文章,我们使用了anythingLLM搭建了本地知识库,这个虽然基本可以用了,但是你只能在anythingLLM的界面里面进行提问,自能自己用,那么能否让其他人也可以使用我们搭建的本地知识库呢根据我的…...

一个简单的跨平台Python GUI自动化 AutoPy
象一下,你坐在电脑前,手指轻轻一点,鼠标自己动了起来,键盘仿佛被无形的手操控,屏幕上的任务自动完成——这一切不需要你费力,只靠几行代码就能实现。这就是AutoPy的魅力,一个简单却强大的跨平台…...

面试题汇总06-场景题线上问题排查难点亮点
面试题汇总06-场景题&线上问题排查&难点亮点 【一】场景题【1】订单到期关闭如何实现【2】每天100w次登录请求,4C8G机器如何做JVM调优?(1)问题描述和分析(2)堆内存设置(3)垃圾收集器选择(4)各区大小设置(5)添加必要的日志【3】如果你的业务量突然提升100倍…...

【嵌入式系统设计师】知识点:第4章 嵌入式系统软件基础知识
提示:“软考通关秘籍” 专栏围绕软考展开,全面涵盖了如嵌入式系统设计师、数据库系统工程师、信息系统管理工程师等多个软考方向的知识点。从计算机体系结构、存储系统等基础知识,到程序语言概述、算法、数据库技术(包括关系数据库、非关系型数据库、SQL 语言、数据仓库等)…...

基于RDK X3的“校史通“机器人:SLAM导航+智能交互,让校史馆活起来!
视频标题: 【校史馆の新晋顶流】RDK X3机器人:导览员看了直呼内卷 视频文案: 跑得贼稳团队用RDK X3整了个大活——给校史馆造了个"社牛"机器人! 基于RDK X3开发板实现智能导航与语音交互SLAM技术让机器人自主避障不…...

春芽儿智能跳绳:以创新技术引领运动健康新潮流
在全球运动健康产业蓬勃发展的浪潮中,智能健身器材正成为连接科技与生活的重要纽带。据《中国体育用品产业发展报告》显示,2023年中国智能运动装备市场规模突破千亿元,其中跳绳类目因兼具大众普及性与技术升级空间,年均增速超30%。…...

复活之我会二分
文章目录 整数二分模板模板1:满足条件的第一个数模板2:满足条件的最后一个数 浮点数二分模板一、Building an Aquarium思路分析具体代码 二、Tracking Segments思路分析具体代码 三、Wooden Toy Festival思路分析具体代码 四、路标设置思路分析具体代码 …...

NOA是什么?国内自动驾驶技术的现状是怎么样的?
国内自动驾驶技术的现状如何? 汽车的NOA指的是“Navigate on Autopilot”,即导航辅助驾驶或领航辅助驾驶。这是一种高级驾驶辅助系统(ADAS)的功能,它允许车辆在设定好起点和终点后,自动完成行驶、超车、变…...

秒杀系统的性能优化
秒杀任务总体QPS预期是每秒几十万,对tomcat、redis、JVM参数进行优化。 tomcat线程数 4核8G的机器,一般就是开200-300个工作线程,这是个经验值。每秒一个线程处理3-5个请求,200多个线程的QPS可以达到1000左右。线程不能太多&…...

Linux 指令初探:开启终端世界的大门
前言 当我们初次接触 Linux,往往会被一串串在黑底屏幕中跳动的字符震撼甚至吓退。然而,正是这些看似晦涩的命令,构建了服务器、嵌入式系统乃至云计算的世界。 本篇将带你从最基础的 Linux 指令开始,逐步揭开命令行的神秘面纱。从…...

Edge浏览器IE兼容模式设置
一、了解Edge浏览器的IE模式 Microsoft Edge,作为微软推出的新一代浏览器,不仅拥有更快的浏览速度、更强大的安全性能以及更现代的界面设计,还巧妙地解决了与旧网站和应用程序的兼容性问题。通过内置的IE模式,Edge能够模拟IE浏览器…...

文件中魔数
当然可以,来讲几个实际开发中魔数会“救你一命”的场景,帮助你更直观地理解它的作用。 🎯 场景 1:误读取非 SST 文件 假设你有一段代码在扫描一个目录,尝试打开所有 .sst 后缀的文件并加载: cpp 复制 编辑…...

制定大运维管理体系的标准、流程、机制、规范
规划并制定大运维管理体系的标准、流程、机制、规范,对于确保平台的可用性和稳定性至关重要。这一过程涉及从顶层设计到具体执行的全面考量,需要综合考虑业务需求、技术架构、团队能力等多方面因素。以下是一个基本框架,用于指导如何构建有效…...

算法初识-时间复杂度空间复杂度
注:观看Adbul Bari算法视频 算法概念 算法:先验分析,不依托于硬件,无语言限制,逻辑。 程序:后验测试,依托硬件,语言限制,实现。 特点: 输入-0或多个输出-至…...

Python高阶函数-sorted(深度解析从原理到实战)
一、sorted()函数概述 sorted()是Python内置的高阶函数,用于对可迭代对象进行排序操作。与列表的sort()方法不同,sorted()会返回一个新的已排序列表,而不改变原数据。 基本语法 sorted(iterable, *, keyNone, reverseFalse)二、核心参数详…...

Vue3实战三、Axios封装结合mock数据、Vite跨域及环境变量配置
目录 Axios封装、调用mock接口、Vite跨域及环境变量配置封装Axios对象调用mock接口数据第一步、安装axios,处理一部请求第二步、创建request.ts文件第三步、本地模拟mock数据接口第四步、测试axiosmock接口是否可以调用第五步、自行扩展 axios 返回的数据类型 axios…...

机器学习(神经网络基础篇)——个人理解篇5(梯度下降中遇到的问题)
在神经网络训练中,计算参数的梯度是关键步骤。numerical_gradient 方法旨在通过数值微分(中心差分法)计算损失函数对网络参数的梯度。然而,该方法的实现存在一个关键问题,导致梯度计算错误。 1、错误代码示例…...

sklearn的Pipeline
Pipeline类 介绍:Pipeline 可以将多个数据处理步骤和机器学习模型组合成一个序列,其中每个步骤都是一个变换器(Transformer)或者估计器(Estimator),并且Pipeline中的最后一个必须为估计器,其它的必须为变换器,如果Pipeline中的估计器为为分类器则整个Pipeline就作为分…...