在huggingface上制作小demo
在huggingface上制作小demo
今天好兄弟让我帮他搞一个模型,他有小样本的化学数据,想让我根据这些数据训练一个小模型,他想用这个模型预测一些值
最终我简单训练了一个小模型,起初想把这个模型和GUI界面打包成exe发给他,但是发现打包后3.9GB,太大了吧!!!后来我又找了别的方案,即将训练好的模型以及相关代码、环境配置文件上传到huggingface上,通过hf的界面端直接使用这个模型,接下来我回顾一下整个流程
1.训练模型并写一个简单的GUI
训练数据

模型输入值:substance、N、C、C/N、K、Cellulose、Hemicellulose、Lignin
模型输出值:Alkaliniy400、Alkalinity600
训练代码train.py
由于样本较小,为了减小误差,这里采用5折交叉验证
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import joblib# 定义神经网络模型
class AlkalinityNet(nn.Module):def __init__(self, input_dim):super(AlkalinityNet, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 64),nn.ReLU(),nn.Dropout(0.2),nn.Linear(64, 32),nn.ReLU(),nn.Dropout(0.2),nn.Linear(32, 2) # 输出两个值:400℃ 和 600℃ 碱度)def forward(self, x):return self.model(x)def train_model(model, train_loader, criterion, optimizer, device):model.train()running_loss = 0.0for X_batch, y_batch in train_loader:X_batch = X_batch.to(device)y_batch = y_batch.to(device)optimizer.zero_grad()outputs = model(X_batch)loss = criterion(outputs, y_batch)loss.backward()optimizer.step()running_loss += loss.item() * X_batch.size(0)return running_lossdef evaluate_model(model, val_loader, criterion, device):model.eval()running_loss = 0.0with torch.no_grad():for X_batch, y_batch in val_loader:X_batch = X_batch.to(device)y_batch = y_batch.to(device)outputs = model(X_batch)loss = criterion(outputs, y_batch)running_loss += loss.item() * X_batch.size(0)return running_lossdef main():# 读取 Excel 数据data = pd.read_excel('~/PycharmProjects/Alkalinity/datasets/data.xlsx')# 假设第一列为物质名称,列名为 "Substance"# 数值特征num_features = ["N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"]targets = ["Alkalinity400", "Alkalinity600"]# 提取物质类别和数值特征substances = data["Substance"].values.reshape(-1, 1)X_num = data[num_features].valuesy = data[targets].values.astype(np.float32)# 对物质类别使用 OneHotEncoder 编码encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore')X_cat = encoder.fit_transform(substances)joblib.dump(encoder, 'encoder.pkl')# 对数值特征进行标准化scaler_X = StandardScaler()X_num_scaled = scaler_X.fit_transform(X_num)joblib.dump(scaler_X, 'scaler_X.pkl')# 拼接类别特征和数值特征X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)# 对目标值进行标准化scaler_y = StandardScaler()y_scaled = scaler_y.fit_transform(y)joblib.dump(scaler_y, 'scaler_y.pkl')# 转换为 PyTorch tensorX_tensor = torch.from_numpy(X_combined)y_tensor = torch.from_numpy(y_scaled)# 设置设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 交叉验证设置kf = KFold(n_splits=5, shuffle=True, random_state=42)num_epochs = 100batch_size = 8criterion = nn.MSELoss()fold_losses = []print("开始 5 折交叉验证...")for fold, (train_index, val_index) in enumerate(kf.split(X_tensor), 1):X_train, X_val = X_tensor[train_index], X_tensor[val_index]y_train, y_val = y_tensor[train_index], y_tensor[val_index]train_dataset = TensorDataset(X_train, y_train)val_dataset = TensorDataset(X_val, y_val)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)model = AlkalinityNet(input_dim=X_tensor.shape[1]).to(device)optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in range(num_epochs):train_loss = train_model(model, train_loader, criterion, optimizer, device)val_loss = evaluate_model(model, val_loader, criterion, device)# 这里可以打印每折每轮的损失,也可以选择每隔一定轮数打印一次# print(f"Fold {fold}, Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss/len(train_dataset):.4f}, Val Loss: {val_loss/len(val_dataset):.4f}")avg_val_loss = val_loss / len(val_dataset)print(f"第 {fold} 折验证 Loss: {avg_val_loss:.4f}")fold_losses.append(avg_val_loss)print("5 折交叉验证平均 Loss:", np.mean(fold_losses))# 在全数据集上训练最终模型final_dataset = TensorDataset(X_tensor, y_tensor)final_loader = DataLoader(final_dataset, batch_size=batch_size, shuffle=True)final_model = AlkalinityNet(input_dim=X_tensor.shape[1]).to(device)optimizer = optim.Adam(final_model.parameters(), lr=0.001)print("开始在全数据集上训练最终模型...")for epoch in range(num_epochs):train_loss = train_model(final_model, final_loader, criterion, optimizer, device)# 可打印训练进度# print(f"Epoch {epoch+1}/{num_epochs}, Loss: {train_loss/len(final_dataset):.4f}")# 保存最终模型参数torch.save(final_model.state_dict(), 'final_model.pth')print("最终模型已保存到 final_model.pth")if __name__ == '__main__':main()
推理代码eval.py
import numpy as np
import torch
import torch.nn as nn
import joblib
from sklearn.preprocessing import StandardScaler, OneHotEncoder# 定义与训练时相同的网络结构
class AlkalinityNet(nn.Module):def __init__(self, input_dim):super(AlkalinityNet, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 64),nn.ReLU(),nn.Dropout(0.2),nn.Linear(64, 32),nn.ReLU(),nn.Dropout(0.2),nn.Linear(32, 2))def forward(self, x):return self.model(x)def predict_alkalinity(input_data):"""参数 input_data 为字典,包含以下键值:"Substance": 物质名称,例如 "玉米秸秆""N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"返回预测的 [400℃ 碱度, 600℃ 碱度]"""# 数值特征顺序与训练时一致num_features = ["N", "C", "C/N", "K", "Cellulose", "Hemicellulose", "Lignin"]# 提取物质名称与数值特征substance = np.array([[input_data["Substance"]]])X_num = np.array([input_data[feat] for feat in num_features]).reshape(1, -1).astype(np.float32)# 加载保存的 OneHotEncoder 和 StandardScalerencoder = joblib.load('encoder.pkl')scaler_X = joblib.load('scaler_X.pkl')scaler_y = joblib.load('scaler_y.pkl')X_cat = encoder.transform(substance)X_num_scaled = scaler_X.transform(X_num)# 拼接类别特征和数值特征X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)# 转换为 tensorX_tensor = torch.from_numpy(X_combined)# 加载模型,注意输入维度需与训练时保持一致input_dim = X_combined.shape[1]model = AlkalinityNet(input_dim=input_dim)# 加载模型参数model.load_state_dict(torch.load('final_model.pth', map_location=torch.device('cpu'), weights_only=True))model.eval()with torch.no_grad():y_pred_tensor = model(X_tensor)y_pred_scaled = y_pred_tensor.numpy()# 将预测结果反标准化y_pred = scaler_y.inverse_transform(y_pred_scaled)return y_pred[0]if __name__ == '__main__':# 示例输入,请根据实际物质成分调整数值input_data = {"Substance": "鸡粪","N": 1.0,"C": 40.0,"C/N": 40.0,"K": 2.5,"Cellulose": 29.0,"Hemicellulose": 25.0,"Lignin": 12.0}result = predict_alkalinity(input_data)print("预测 400℃ 碱度:", result[0])print("预测 600℃ 碱度:", result[1])本地推理看看

GUI界面代码app.py
import tkinter as tk
from tkinter import messagebox
import tkinter.font as tkFont
import joblib
import numpy as np
import torch
import torch.nn as nn# 定义与训练时一致的模型结构
class AlkalinityNet(nn.Module):def __init__(self, input_dim):super(AlkalinityNet, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, 64),nn.ReLU(),nn.Dropout(0.2),nn.Linear(64, 32),nn.ReLU(),nn.Dropout(0.2),nn.Linear(32, 2) # 输出 400℃ 和 600℃ 的碱度值)def forward(self, x):return self.model(x)def predict():try:# 获取用户输入的各项数值substance = entry_substance.get()N = float(entry_N.get())C = float(entry_C.get())C_N = float(entry_CN.get())K = float(entry_K.get())cellulose = float(entry_cellulose.get())hemicellulose = float(entry_hemicellulose.get())lignin = float(entry_lignin.get())except ValueError:messagebox.showerror("输入错误", "请确保所有数值项均正确填写")return# 构造输入字典input_data = {"Substance": substance,"N": N,"C": C,"C/N": C_N,"K": K,"Cellulose": cellulose,"Hemicellulose": hemicellulose,"Lignin": lignin}try:# 加载保存的预处理器encoder = joblib.load('encoder.pkl')scaler_X = joblib.load('scaler_X.pkl')scaler_y = joblib.load('scaler_y.pkl')except Exception as e:messagebox.showerror("加载错误", f"加载预处理器失败:{e}")return# 对物质类别特征进行 one-hot 编码substance_arr = np.array([[input_data["Substance"]]])X_cat = encoder.transform(substance_arr)# 数值特征转换与标准化X_num = np.array([[input_data["N"], input_data["C"], input_data["C/N"], input_data["K"],input_data["Cellulose"], input_data["Hemicellulose"], input_data["Lignin"]]], dtype=np.float32)X_num_scaled = scaler_X.transform(X_num)# 拼接特征X_combined = np.hstack([X_cat, X_num_scaled]).astype(np.float32)X_tensor = torch.from_numpy(X_combined)# 加载模型(注意:模型参数文件和输入预处理器需放在同一目录下)input_dim = X_combined.shape[1]model = AlkalinityNet(input_dim=input_dim)try:model.load_state_dict(torch.load('final_model.pth', map_location=torch.device('cpu'), weights_only=True))except Exception as e:messagebox.showerror("加载模型错误", f"加载模型失败:{e}")returnmodel.eval()with torch.no_grad():y_pred_tensor = model(X_tensor)y_pred_scaled = y_pred_tensor.numpy()# 反标准化得到预测值y_pred = scaler_y.inverse_transform(y_pred_scaled)pred_400 = y_pred[0, 0]pred_600 = y_pred[0, 1]# 在界面上显示预测结果label_pred_400.config(text=str(pred_400))label_pred_600.config(text=str(pred_600))# 创建 GUI 主窗口
root = tk.Tk()
root.title("碱度预测模型")# 设置参考尺寸与基础字体大小(可根据需要调整)
REF_WIDTH = 800
REF_HEIGHT = 600
BASE_FONT_SIZE = 18# 用于存放所有需要动态调整字体的控件
widgets_to_update = []# 创建一个默认字体对象,初始大小 BASE_FONT_SIZE
default_font = tkFont.Font(family="SimSun", size=BASE_FONT_SIZE)# 辅助函数:创建标签并加入更新列表(居中显示)
def create_label(text, row, col):lbl = tk.Label(root, text=text, font=default_font, anchor="center")lbl.grid(row=row, column=col, padx=5, pady=5, sticky="nsew")widgets_to_update.append(lbl)return lbl# 辅助函数:创建输入框并加入更新列表(内容居中)
def create_entry(row, col):ent = tk.Entry(root, font=default_font, justify="center")ent.grid(row=row, column=col, padx=5, pady=5, sticky="nsew")widgets_to_update.append(ent)return ent# 定义行列权重,使控件居中扩展
for i in range(11):root.grid_rowconfigure(i, weight=1)
for j in range(2):root.grid_columnconfigure(j, weight=1)# 创建左侧标签
label_substance = create_label("物质", 0, 0)
label_N = create_label("N", 1, 0)
label_C = create_label("C", 2, 0)
label_CN = create_label("C/N", 3, 0)
label_K = create_label("K", 4, 0)
label_cellulose = create_label("纤维素", 5, 0)
label_hemicellulose = create_label("半纤维素", 6, 0)
label_lignin = create_label("木质素", 7, 0)
label_400 = create_label("400摄氏度碱度", 8, 0)
label_600 = create_label("600摄氏度碱度", 9, 0)# 创建右侧输入框
entry_substance = create_entry(0, 1)
entry_N = create_entry(1, 1)
entry_C = create_entry(2, 1)
entry_CN = create_entry(3, 1)
entry_K = create_entry(4, 1)
entry_cellulose = create_entry(5, 1)
entry_hemicellulose = create_entry(6, 1)
entry_lignin = create_entry(7, 1)# 用于显示预测结果的标签(400℃ 和 600℃)
label_pred_400 = create_label("未预测", 8, 1)
label_pred_600 = create_label("未预测", 9, 1)# 预测按钮(也加入更新列表)
predict_button = tk.Button(root, text="预测", font=default_font, command=predict)
predict_button.grid(row=10, column=0, columnspan=2, pady=10)
widgets_to_update.append(predict_button)# 定义一个函数,在窗口大小变化时更新所有控件的字体大小
def on_resize(event):# 根据窗口当前尺寸与参考尺寸计算缩放比例scale_factor = min(event.width / REF_WIDTH, event.height / REF_HEIGHT)new_font_size = max(int(BASE_FONT_SIZE * scale_factor), 8) # 设置最小字体为8# 更新所有控件字体new_font = (default_font.actual("family"), new_font_size)for widget in widgets_to_update:widget.config(font=new_font)# 绑定窗口尺寸变化事件
root.bind("<Configure>", on_resize)root.mainloop()
本地运行看看效果

2.在huggingface上创建Space
点击new space

填写相关信息后点击Create

3.上传模型、代码、环境配置文件
上传你的模型和相应代码、以及requirements.txt
 requirements.txt中直接写需要用到的库
requirements.txt中直接写需要用到的库

上传文件中需要有个名为 app.py的文件,huggingface会根据这个文件创建网页端应用
为了能够让hf分享别人可以访问的public链接,在app.py中添加参数share=True
# Launch the app with shareable link
if __name__ == "__main__":iface.launch(share=True)
为了不让模型自动推理运行,而是让它点击运行时才推理,我们需要将app.py中 live=True设置为False
# Create Gradio interface
iface = gr.Interface(fn=predict,inputs=[gr.Textbox(label="Substance", placeholder="Enter substance"),gr.Number(label="N"),gr.Number(label="C"),gr.Number(label="C/N"),gr.Number(label="K"),gr.Number(label="Cellulose"),gr.Number(label="Hemicellulose"),gr.Number(label="Lignin")],outputs=[gr.Number(label="400℃ Alkalinity"),gr.Number(label="600℃ Alkalinity")],live=False, # Disable live prediction to avoid automatic predictiontitle="Alkalinity Prediction Model",description="Input relevant data and click the 'Predict' button to get predictions."
)
hf会根据环境配置文件下载相关库并根据app.py创建应用
 这样就可以在网页端直接使用模型
这样就可以在网页端直接使用模型
 将左侧输入值填入后,点击submit后模型输出值显示到右侧
将左侧输入值填入后,点击submit后模型输出值显示到右侧

将分享链接分享给好兄弟后,他就可以直接在网页端使用我训练好的简单模型了
相关文章:
在huggingface上制作小demo
在huggingface上制作小demo 今天好兄弟让我帮他搞一个模型,他有小样本的化学数据,想让我根据这些数据训练一个小模型,他想用这个模型预测一些值 最终我简单训练了一个小模型,起初想把这个模型和GUI界面打包成exe发给他࿰…...

集合学习内容总结
集合简介 1、Scala 的集合有三大类:序列 Seq、集Set、映射 Map,所有的集合都扩展自 Iterable 特质。 2、对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包 不可变集合:scala.collect…...
51.评论日记
千万不能再挖了,否则整个华夏文明将被改写。_哔哩哔哩_bilibili 2025年4月7日22:13:42...

SpringCloud第二篇:注册中心Eureka
注册中心的意义 注册中心 管理各种服务功能包括服务的注册、发现、熔断、负载、降级等,比如dubbo admin后台的各种功能。 有了注册中心,调用关系的变化,画几个简图来看一下。(了解源码可求求: 1791743380) 服务A调用服务B 有了注册中心之后&a…...
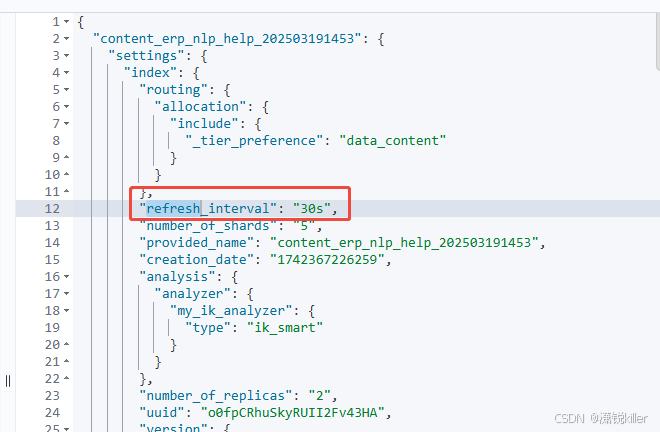
ES 参数调优
1、refresh_interval 控制索引刷新的时间间隔。增大这个值可以减少I/O操作,从而提升写入性能,但会延迟新文档的可见性 查看 GET /content_erp_nlp_help_202503191453/_settings?include_defaultstrue 动态修改:refresh_interval 是一个动态…...

用claude3.7,不到1天写了一个工具小程序(11个工具6个游戏)
一、功能概览和本文核心 本次开发,不是1天干撸,而是在下班后或早起搞的,总体加和计算了一下,大概1天的时间(12个小时),平常下班都是9点的衰仔,好在还有双休,谢天谢地。 …...
【GeoDa使用】空间自相关分析操作
使用 GeoDa 软件进行空间自相关分析 双击打开 GeoDa 软件 选择 .shp 文件 导入文件 空间权重矩阵(*.gal / *.gwt)是进行任何空间分析的前提 构建空间权重矩阵 空间权重矩阵(Spatial Weights Matrix) 是一个用来描述空间对象之间…...

什么是数据
一、数据的本质定义 哲学视角 亚里士多德《形而上学》中"未加工的观察记录"现代认知科学:人类感知系统接收的原始刺激信号(如视网膜光信号、听觉神经电信号)信息论奠基人香农:消除不确定性的度量载体 …...

C++基于rapidjson的Json与结构体互相转换
简介 使用rapidjson库进行封装,实现了使用C对结构体数据和json字符串进行互相转换的功能。最短只需要使用两行代码即可无痛完成结构体数据转换为Json字符串。 支持std::string、数组、POD数据(int,float,double等)、std::vector、嵌套结构体…...

OpenStack Yoga版安装笔记(十七)安全组笔记
一、安全组与iptables的关系 OpenStack的安全组(Security Group)默认是通过Linux的iptables实现的。以下是其主要实现原理和机制: 安全组与iptables的关系 OpenStack的安全组规则通过iptables的规则链实现。每条安全组规则会被转换为相应的i…...

通义万相2.1 图生视频:为AI绘梦插上翅膀,开启ALGC算力领域新纪元
通义万相2.1图生视频大模型 通义万相2.1图生视频技术架构万相2.1的功能特点性能优势与其他工具的集成方案 蓝耘平台部署万相2.1核心目标典型应用场景未来发展方向 通义万相2.1ALGC实战应用操作说明功能测试 为什么选择蓝耘智算蓝耘智算平台的优势如何通过API调用万相2.1 写在最…...

Debezium日常分享系列之:Debezium3.1版本之增量快照
Debezium日常分享系列之:Debezium3.1版本之增量快照 按需快照触发一次临时增量快照触发临时阻塞快照增量快照增量快照过程如何 Debezium 解决具有相同主键的记录之间的冲突快照窗口触发增量快照使用附加条件运行临时增量快照使用 Kafka 信号通道触发增量快照临时增量…...

聊聊Spring AI的RedisVectorStore
序 本文主要研究一下Spring AI的RedisVectorStore 示例 pom.xml <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-redis</artifactId> </dependency>配置 spring:ai:vectorstore:…...
(4))
Diffusion Policy Visuomotor Policy Learning via Action Diffusion官方项目解读(二)(4)
运行官方代码库中提供的Colab代码:vision-based environment(二)(4) 十六、函数unnormalize_data,继承自torch.utils.data.Dataset十六.1 def __init__()十六.2 def __len__ ()十六.3 def __getitem__()总体…...
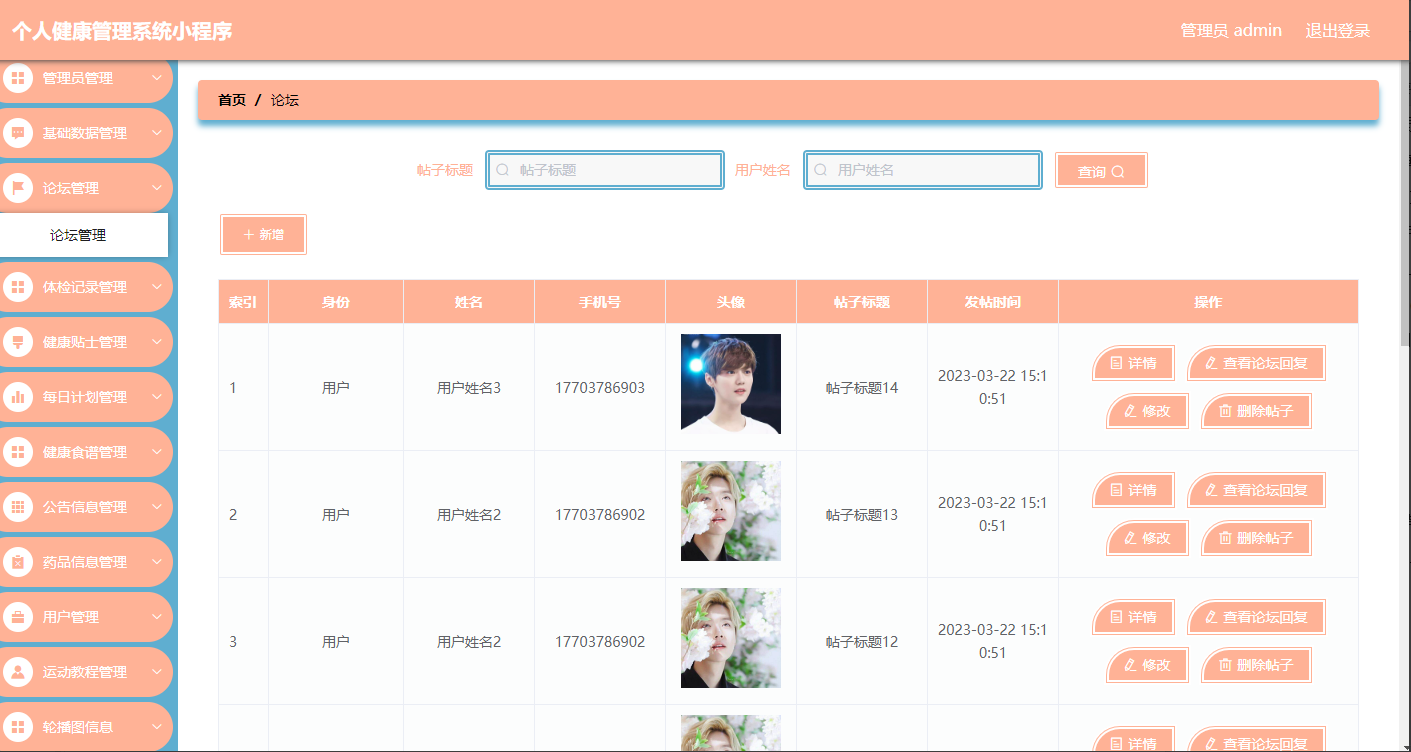
52.个人健康管理系统小程序(基于springbootvue)
目录 1.系统的受众说明 2.开发环境与技术 2.1 MYSQL数据库 2.2 Java语言 2.3 微信小程序技术 2.4 SpringBoot框架 2.5 B/S架构 2.6 Tomcat 介绍 2.7 HTML简介 2.8 MyEclipse开发工具 3.系统分析 3.1 可行性分析 3.1.1 技术可行性 3.1.2 经济可行性 3.1.3 操作…...
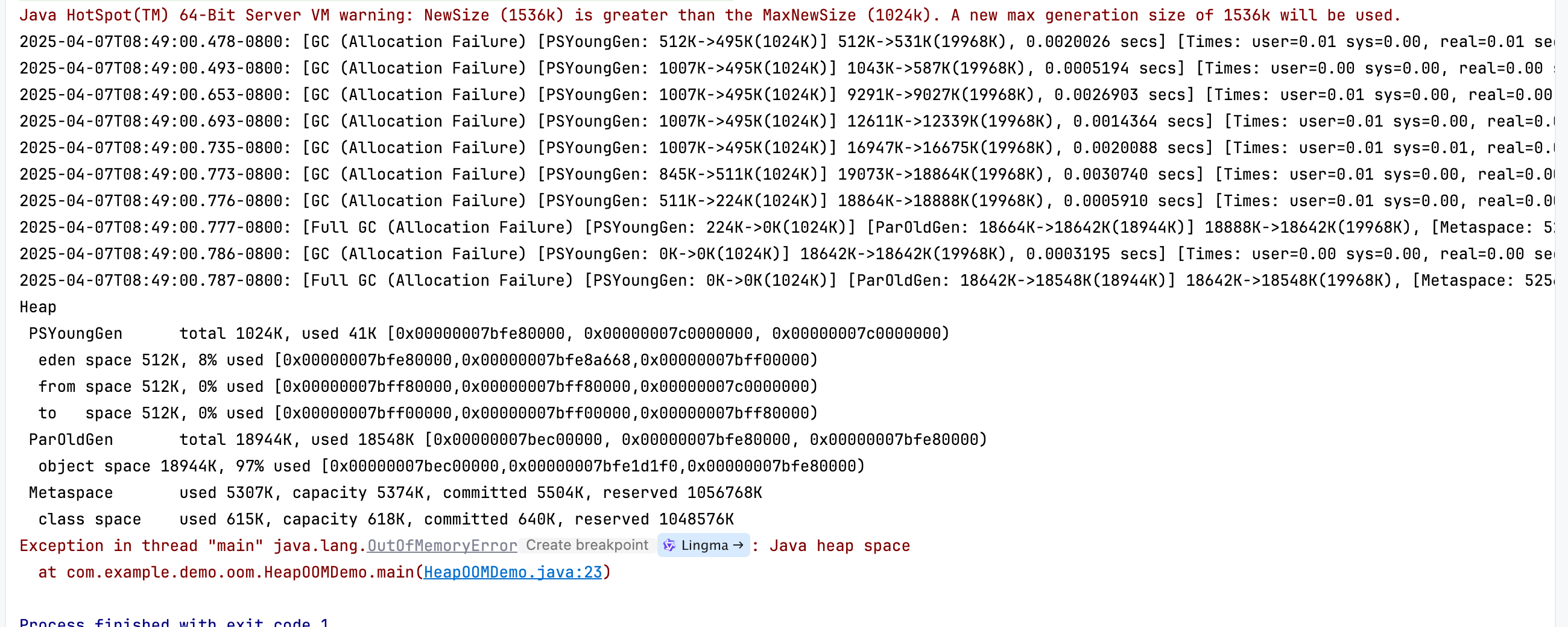
学习比较JVM篇(六):解读GC日志
一、前言 在之前的文章中,我们对JVM的结构、垃圾回收算法、垃圾回收器做了一些列的讲解,同时也使用了JVM自带的命令行工具进行了实际操作。今天我们继续讲解JVM。 我们学习JVM的目的是为了了解JVM,然后优化对应的参数。那么如何了解JVM运行…...
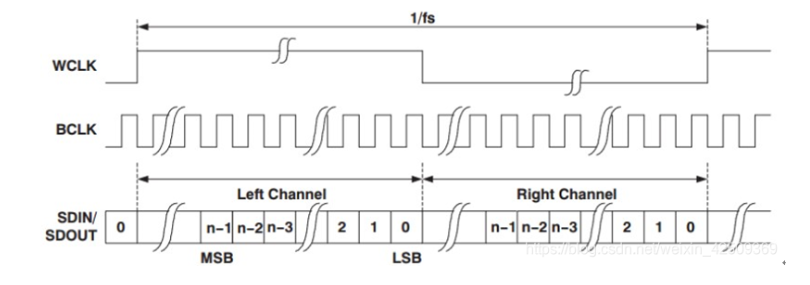
I²S协议概述与信号线说明
IIS协议概述 IS(Inter-IC Sound)协议,又称 IIS(Inter-IC Sound),是一种专门用于数字音频数据传输的串行总线标准,由飞利浦(Philips)公司提出。该协议通常用于微控制器…...

b4a安卓开发技术和建议,VB6开发Android APK
b4a功能建议实现方法想法创意Wait For可以在参数中直接返回结果吗?Wait For (cam.OpenCamera(front)) Complete (TaskIndex As Int) Wait For B4XPage_PermissionResult (Permission As String, Result As Boolean) 函数别名,减少代码,通用函…...

计算机网络-子网划分试题七
计算机网络中IP地址为172.16.20.60、172.16.30.60、172.16.80.60,子网掩码为255.255.192.0的三台计算机的网络号,子网号及主机号,并确定三台计算机是否处于同一个子网,如果不是请指出哪些在同一个子网,哪些不是&#x…...

免费Deepseek-v3接口实现Browser-Use Web UI:浏览器自动化本地模拟抓取数据实录
源码 https://github.com/browser-use/web-ui 我们按照官方教程,修订几个环节,更快地部署 步骤 1:克隆存储库 git clone https://github.com/browser-use/web-ui.git cd web-ui Step 2: Set Up Python Environment 第 2 步:设置…...
[蓝桥杯] 求和
题目链接 P8772 [蓝桥杯 2022 省 A] 求和 - 洛谷 题目理解 这道题就是公式题,我们模拟出公式后,输出最终结果即可。 本题不难,相信很多同学第一次见到这道题都是直接暴力解题。 两个for循环,测试样例,直接拿下。 #in…...
-kafka详解)
大数据学习(100)-kafka详解
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

通过Ollama本地部署DeepSeek R1模型(Windows版)
嗨,大家好,我是心海 以下是一份详细的Windows系统下通过Ollama本地部署DeepSeek R1模型的教程,内容简洁易懂,适合新手用户参考 本地部署大模型,就有点像在你自己的电脑或者服务器上,安装并运行这样一个“私…...
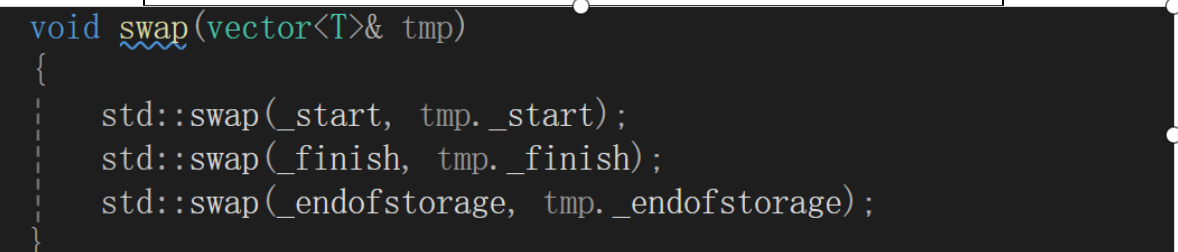
【C++】vector的底层封装和实现
目录 目录前言基本框架迭代器容量第一个测试,野指针异常第二轮测试,浅拷贝的问题 元素访问修改操作push_backinsert迭代器失效问题 erase 默认成员函数构造函数双重构造引发调用歧义 拷贝构造赋值重载析构函数 源码end 目录 前言 废话不多说࿰…...

Open CASCADE学习|读取点集拟合样条曲线(续)
问题 上一篇文章已经实现了样条曲线拟合,但是仍存在问题,Tolerance过大拟合成直线了,Tolerance过大头尾波浪形。 正确改进方案 1️⃣ 核心参数优化 通过调整以下参数控制曲线平滑度: Standard_Integer DegMin 3; // 最低阶…...

ARM Cortex-M用于控制中断和异常处理的寄存器:BASEPRI、PRIMASK 和 FAULTMASK
在ARM Cortex-M处理器中,BASEPRI、PRIMASK 和 FAULTMASK 是用于控制中断和异常处理的系统级寄存器。它们的主要区别在于作用范围和灵活性,以下是详细说明: 1. PRIMASK • 功能: 禁用除以下情况的异常和所有中断(Maska…...

Kafka 中的生产者分区策略
Kafka 中的 生产者分区策略 是决定消息如何分配到不同分区的机制。这个策略对 Kafka 的性能、负载均衡、消息顺序性等有重要影响。了解它对于高效地使用 Kafka 进行消息生产和消费至关重要。 让我们一起来看 Kafka 中 生产者的分区策略,它如何工作,以及…...

【Django】教程-11-ajax弹窗实现增删改查
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

结构化需求分析:专业方法论与实践
结构化需求分析是一种用于软件开发或其他项目中的系统分析方法,旨在全面、准确地理解和描述用户对系统的需求。以下是关于结构化需求分析的详细介绍: 一、概念 结构化需求分析是采用自顶向下、逐步分解的方式,将复杂的系统需求分解为若干个…...
R语言:气象水文领域的数据分析与绘图利器
R 语言是一门由统计学家开发的用于统计计算和作图的语言(a Statistic Language developed for Statistic by Statistician),由 S 语言发展而来,以统计分析功能见长。R 软件是一款集成 了数据操作、统计和可视化功能的优秀的开源软…...