JAVA--流(Stream)的使用
一、概念
JDK8新特性,简单方便的对集合和数组进行处理。
Stream(流)是一个来自数据源的元素队列
-
数据源:流的来源,指的是集合或数组
-
元素队列:元素是特定类型的对象,形成一个队列
-
Stream 并不会存储元素,而是根据需要进行处理,如filter、map、skip等
-
Stream流有以下两个操作,都提供了相关的 API 方法
- 延迟操作:对 Stream 进行一系列的中间操作,但不会被马上执行,等待终结操作才会一次性被执行
- 终结操作:终结操作后,则一系列的延迟操作被执行,并产生相应的结果,流就被关闭了
1 2 3 | +--------------------+ +------+ +------+ +---+ +-------+ | stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect| +--------------------+ +------+ +------+ +---+ +-------+ |
二、特点
-
Stream API 旨在让编码更高效率、干净、简洁
-
提供了一种函数式编程的方式来操作集合
- API 方法 + Lambda表达式、方法引用
三、操作步骤
第一:定义数据源(集合、数组)
第二:把数据源转换为流(Stream)
-
集合对象
- 顺序流:集合对象.stream()
- 并行流:集合对象.parallelStream()
-
数组对象
- Arrays.stream(数组)
- Stream.of(元素集合|数组)
-
创建无限流
- 迭代:
Stream.iterate(final T seed,final UnaryOperator<T> f) - 生成:
Stream.generate(Supplier<T> s)
- 迭代:
第三:操作(API)
- 进行一个或多个中间操作;
- 使用终止操作产生一个结果,
Stream就不会再被使用了。
四、获取流
1、集合对象
在java.util.Collection接口中,加入了默认方法stream()用于获取流,因此所有实现类都可以通过此方法获取流。
语法一:顺序流
Stream<数据类型> 流对象 = 集合对象.stream() ;语法二:并行流
Stream<数据类型> 流对象 = 集合对象.parallelStream() ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | // 第一:定义数据源(集合、数组) List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);// 第二:把数组或集合转换为流对象 // 1)获取顺序流 Stream<Integer> stream1 = list.stream();// 2)获取并行流 Stream<Integer> stream2 = list.parallelStream();// 其它集合,获取流对象 // 1、Set集合 Set<String> c2 = new HashSet() ; Stream<String> s2 = c2.stream() ;// 2、Map合集 Map<Integer,String> c3 = new HashMap<>() ; // 2.1、键的集合 Stream<Integer> s3 = c3.keySet().stream(); // 2.2、值的集合 Stream<String> s4 = c3.values().stream(); // 2.3、键值对的集合 Set<Map.Entry<Integer, String>> entries = c3.entrySet(); Stream<Map.Entry<Integer, String>> s5 = entries.stream(); |
2、数组对象
在java.util.stream.Stream<T>中,提供了静态方法of可以获取数组对应的流。
语法一:
Stream<数据类型> 流对象 = Arrays.stream(元素集合|数组) ;语法二:
Stream<数据类型> 流对象 = Stream.of(元素集合|数组) ;
1 2 3 4 5 6 7 8 9 10 | String[] arr = {"aa","bb","cc"} ;// 1.使用 Arrays 获取流对象
Stream<String> stream1 = Arrays.stream(arr) ;// 2.使用 Stream 获取流对象
Stream<String> stream2 = Stream.of(arr);// 3.通过元素集合,获取流对象
Stream<Integer> stream3 = Stream.of(1, 2, 3, 4, 5);
|
3、创建无限流
迭代
public static<T> Stream<T> iterate(final T seed,final UnaryOperator<T> f)生成
public static<T> Stream<T> generate(Supplier<T> s)
1 2 3 4 5 6 7 8 9 10 11 12 | // 1.获取流对象,流对象的元素从0开始,每迭代一次加2 - T apply(T t); Stream stream = Stream.iterate(0,t -> t + 2);// 2.获取流的前面 10 个元素 - limit方法对流进行截取,截取前面 N 个元素 stream.limit(10).forEach(System.out::println);// 生成一个产生10以内随机数的流对象 - T get(); Stream stream = Stream.generate(()->new Random().nextInt(10));// 获取流的前面 10 个元素 - limit方法对流进行截取,截取前面 N 个元素 stream.limit(10).forEach(System.out::println); |
五、常用API方法
在JDK中,提供了非常丰富的API方法,主要分为以下两类:
1、延迟方法
返回值类型仍然为Stream接口自身类型的方法,因此支持链式调用,如:
1)筛选与切片
- filter:过滤满足条件的元素
- limit(N):获取 Stream 中前面的N个元素
- skip(N):跳过 Stream 中前面的N个元素
- distinct:去重
2)映射
- map:把一个 T 类型转换(映射)为一个 R 类型的流
- mapToDouble:把一个 T 类型的流 转换为 另一个 Double 类型流
- mapToInt:把一个 T 类型的流 转换为 另一个 int 类型流
- mapToLong:把一个 T 类型的流 转换为 另一个 Long 类型流
- flatMap:将流中的每个元素转换为另一个流,然后将这些流合并成一个流
3)排序
-
sorted
-
sorted(Comparator comparator)
-
组合:concat:把两个流合并为一个流 -
Stream.concat(stream1, stream2);
2、终结方法
返回值类型不再是Stream接口自身类型的方法。如:
1)遍历
forEach:逐一处理
1 | void forEach(Consumer<? super T> action); |
- 该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。
- Consumer接口是一个消费型的函数式接口,可以传递Lambda表达式,消费数据。
2)匹配与查找
- allMatch:检查是否匹配所有元素
- anyMatch:检查是否至少匹配一个元素
- noneMath:检查是否没有匹配所有元素
3)查找
- findFirst:返回第一个元素
- findAny:返回当前流中的任意元素
4)统计
- count:返回流中元素的总数
- max:返回流中最大值
- min:返回流中最小值
5)归约
归约是指将流中的元素按照指定的规则逐个进行操作,最终将它们归约(或者合并)为一个最终结果的过程。
归约操作可以是求和、求积、找出最大值或最小值等。
1 2 3 4 5 | // 返回 T T reduce(T identity, BinaryOperator<T> accumulator);// 返回 Optional<T> Optional<T> reduce(BinaryOperator<T> accumulator); |
6)收集
收集器(Collector)是一种用于将流中的元素收集到一个结果容器中,以便后续的处理和操作。
collect(Collectors.xxx)
6.1)收集 Stream 流中的数据到集合中
toList、toSet、toCollection
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | // 第一:定义数据源,并获取对应的流对象
Stream<String> stream = Stream.of("AA","BB","AA","CC") ;// 第二:操作 - 收集流中的数据
// 1.收集流中的数据到List集合中
List<String> list = stream.collect(Collectors.toList());// 2.收集流中的数据到Set集合中
Set<String> set = stream.collect(Collectors.toSet());// 3.收集流中的数据到指定的集合(ArrayList)中
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));// 4.收集流中的数据到指定的集合(HashSet)中
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
|
6.2)收集 Stream 流中的数据到数组中
Object[] toArray();- 使用无参,收集到数组,返回值为 Object[](Object类型将不好操作)
<A> A[] toArray(IntFunction<A[]> generator);- 使用有参,可以指定将数据收集到指定类型数组,方便后续对数组的操作
1 2 3 4 5 6 7 | // 第一:定义数据源,并获取对应的流对象
List<String> list = Arrays.asList("AA", "BB", "AA", "CC");// 第二:操作 - 收集流中的数据
Object[] objects = list.stream().toArray();String[] strings = list.stream().toArray(String[]::new);
|
6.3)聚合操作
类似于数据库的聚合函数。
- 最大值: Collectors.maxBy();
- 最小值: Collectors.minBy();
- 总和
- Collectors.summingInt();
- Collectors.summingDouble();
- Collectors.summingLong();
- 平均值
- Collectors.averagingInt();
- Collectors.averagingDouble();
- Collectors.averagingLong();
- 总个数:Collectors.counting();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | // 第一:定义数据源,并获取对应的流对象
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);// 第二:操作 - 收集流中的数据
// 1.最大值
Optional<Integer> maxOptional1 = list.stream().collect(Collectors.maxBy((o1, o2) -> o1 - o2));
System.out.println("最大值:"+maxOptional1.get());// Stream流的max方法也可以实现
Optional<Integer> maxOptional2 = list.stream().max((o1, o2) -> o1 - o2);
System.out.println("最大值:"+maxOptional2.get());// 2.最小值
Optional<Integer> minOptional1 = list.stream().collect(Collectors.minBy((o1, o2) -> o1 - o2));
System.out.println("最小值:"+minOptional1.get());// Stream流的min方法也可以实现
Optional<Integer> minOptional2 = list.stream().min((o1, o2) -> o1 - o2);
System.out.println("最小值:"+minOptional2.get());// 3.总数
Integer sum1 = list.stream().collect(Collectors.summingInt(d -> d));
System.out.println("总数:"+sum1);Integer sum2 = list.stream().reduce(0, (a, b) -> a + b);
System.out.println("总数:"+sum2);// 4.平均值
Double avg = list.stream().collect(Collectors.averagingInt(d -> d));
System.out.println("平均数:"+avg);// 5.统计数量
Long count = list.stream().collect(Collectors.counting());
System.out.println("数量为:"+count);
|
6.4)数据分组操作
类似SQL Server中的group by,根据需要可以根据某个属性来将数据进行分组。
- 接收一个 Function 参数
1 | groupingBy(Function<? super T, ? extends K> classifier) |
- 多级分组操作,接收两个参数:
- Function 参数
- Collector多级分组
1 | groupingBy(Function<? super T, ? extends K> classifier,Collector<? super T, A, D> downstream) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | // 第一:定义数据源,并获取对应的流对象
Student s1 = new Student("张三","男",18,55) ;
Student s2 = new Student("李四","女",28,63) ;
Student s3 = new Student("王五","男",38,50) ;
Student s4 = new Student("赵六","女",48,99) ;
List<Student> list = Arrays.asList(s1,s2,s3,s4);// 第二:操作 - 收集流中的数据
// 1.根据性别分组
Map<String, List<Student>> map = list.stream().collect(Collectors.groupingBy(s -> s.getSex()));// key:分组字段,value:分组结果
map.forEach((key,value)->{System.out.println(key+":"+value);
});// 2.根据分数分组
list.stream().collect(Collectors.groupingBy(stu-> {if (stu.getScore() >= 60) {return "及格";}return "不及格";
})).forEach((key,value)-> System.out.println(key+":"+value));
|
6.5)数据分区操作
将集合其分解成两个子集合。我们通过使用 Collectors.partitioningBy() ,根据返回值是否为 true,把集合分为两个列表,一个 true 列表,一个 false 列表。
分组和分区的区别就在:分组可以有多个组。分区只会有两个区(true 和 false)
-
.一个参数
1
partitioningBy(Predicate<? super T> predicate)
-
两个参数(多级分区)
1
partitioningBy(Predicate<? super T> predicate, Collector<? super T, A, D> downstream)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // 第一:定义数据源,并获取对应的流对象
Student s1 = new Student("张三","男",18,55) ;
Student s2 = new Student("李四","女",28,63) ;
Student s3 = new Student("王五","男",38,50) ;
Student s4 = new Student("赵六","女",48,99) ;
List<Student> list = Arrays.asList(s1,s2,s3,s4);// 第二:操作 - 分区操作
Map<Boolean, List<Student>> map = list.stream().collect(Collectors.partitioningBy(s -> s.getScore() >= 60)
);map.forEach((k,v)->{System.out.println(k + ":"+v);
});
|
6.6)数据拼接操作
-
无参数
1 2
// 等价于 joining(""); Collectors.joining() -
一个参数
1
Collectors.joining(CharSequence delimiter)
-
三个参数(前缀 + 后缀)
1
Collectors.joining(CharSequence delimiter, CharSequence prefix,CharSequence suffix)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | // 第一:定义数据源,并获取对应的流对象
Student s1 = new Student("张三","男",18,55) ;
Student s2 = new Student("李四","女",28,63) ;
Student s3 = new Student("王五","男",38,50) ;
Student s4 = new Student("赵六","女",48,99) ;
List<Student> list = Arrays.asList(s1,s2,s3,s4);// 第二:操作 - 拼接操作
// 1.无参:join()
String str1 = list.stream().map(s -> s.getName()).collect(Collectors.joining());
System.out.println(str1);// 2.一个参数:joining(CharSequence delimiter)
String str2 = list.stream().map(s -> s.getName()).collect(Collectors.joining(","));
System.out.println(str2);// 3.三个参数:joining(CharSequence delimiter, CharSequence prefix,CharSequence suffix)
String str3 = list.stream().map(s -> s.getName()).collect(Collectors.joining(",","[","]"));
System.out.println(str3); |
相关文章:
的使用)
JAVA--流(Stream)的使用
一、概念 JDK8新特性,简单方便的对集合和数组进行处理。 Stream(流)是一个来自数据源的元素队列 数据源:流的来源,指的是集合或数组 元素队列:元素是特定类型的对象,形成一个队列 Stream 并…...

使用ExcelJS实现专业级医疗数据导出功能:从数据到Excel报表的完整指南
在现代医疗信息系统中,数据导出是医护人员和行政人员日常工作中的重要需求。本文将详细介绍如何使用ExcelJS库在前端实现专业级的医疗数据导出功能,特别是针对住院缴费记录这类关键业务数据。 功能概述 这个exportExcel函数实现了以下核心功能…...

使用Pholcus编写Go爬虫示例
想用Pholcus库来写一个Go的爬虫程序。首先,我得确认Pholcus的当前状态,因为之前听说过它可能已经不再维护了。不过用户可能还是需要基于这个库的示例,所以得先提供一个基本的框架。 首先,我应该回忆一下Pholcus的基本用法。Pholc…...

深入解析大型应用架构:以dify为例进行分析
原文:https://juejin.cn/post/7437015214351286309 Dify 是一款开源的大语言模型(LLM)应用开发平台,旨在简化和加速生成式 AI 应用的创建和部署。 它融合了后端即服务(Backend as a Service, BaaS)和 LLM…...

单片机实现触摸按钮执行自定义任务组件
触摸按钮执行自定义任务组件 项目简介 本项目基于RT8H8K001开发板 RT6809CNN01开发板 TFT显示屏(1024x600) GT911触摸屏实现了一个多功能触摸按钮组件。系统具备按钮控制后执行任务的功能,可用于各类触摸屏人机交互场景。 硬件平台 MCU: STC8H8K64U࿰…...

快速入手-前后端分离Python权限系统 基于Django5+DRF+Vue3.2+Element Plus+Jwt
引用:打造前后端分离Python权限系统 基于Django5DRFVue3.2Element PlusJwt 视频教程 (火爆连载更新中..)_哔哩哔哩_bibili 说明:1、结合个人DRF基础和该视频去根据自己的项目进行开发。 2、引用该视频中作者的思路去升华自身的项…...

【go】slice的浅拷贝和深拷贝
浅拷贝(Shallow Copy) 浅拷贝是指只复制切片本身的结构(指针、长度和容量),而不复制底层数组的元素。 实现方式 直接赋值: slice1 : []int{1, 2, 3} slice2 : slice1 // 浅拷贝切片操作: slice1 : []int{1, 2, 3} s…...

Ai云防护技术解析——服务器数据安全的智能防御体系
本文深度解析AI云防护技术如何通过智能流量分析、动态行为建模、自适应防御策略构建服务器安全体系。结合2023年群联科技实战案例,揭示机器学习算法在识别新型DDoS攻击、加密流量检测、零日漏洞防御中的技术突破,并附Gartner最新防护效果验证数据。 AI驱动的流量特征建模技术…...

科技快讯 | DeepSeek 公布模型新学习方式;Meta发布开源大模型Llama 4;谷歌推出 Android Auto 14.0 正式版
Meta发布开源大模型Llama 4,首次采用“混合专家架构“ 4月6日,Meta推出开源AI模型Llama 4,包括Scout和Maverick两个版本,具备多模态处理能力。Scout和Maverick参数量分别为170亿和4000亿,采用混合专家架构。Meta同时训…...

JSONP跨域访问漏洞
一、漏洞一:利用回调GetCookie <?php$conn new mysqli(127.0.0.1,root,root,learn) or die("数据库连接不成功"); $conn->set_charset(utf8); $sql "select articleid,author,viewcount,creattime from learn3 where articleid < 5"; $result…...

记录一次StarRocks集群迁移的经历
记录一次StarRocks集群迁移的经历 新入职了一家公司,刚去做了两张报表后,接到一个任务,做StarRocks 集群迁移,背景是这样的就是以前是自建的SR,但是这个SR 是给线上业务用的,也就是说不是分析性业务,而是面向产品ToC 的,也了解了一下是因为单表数据量太大了,所以直接…...
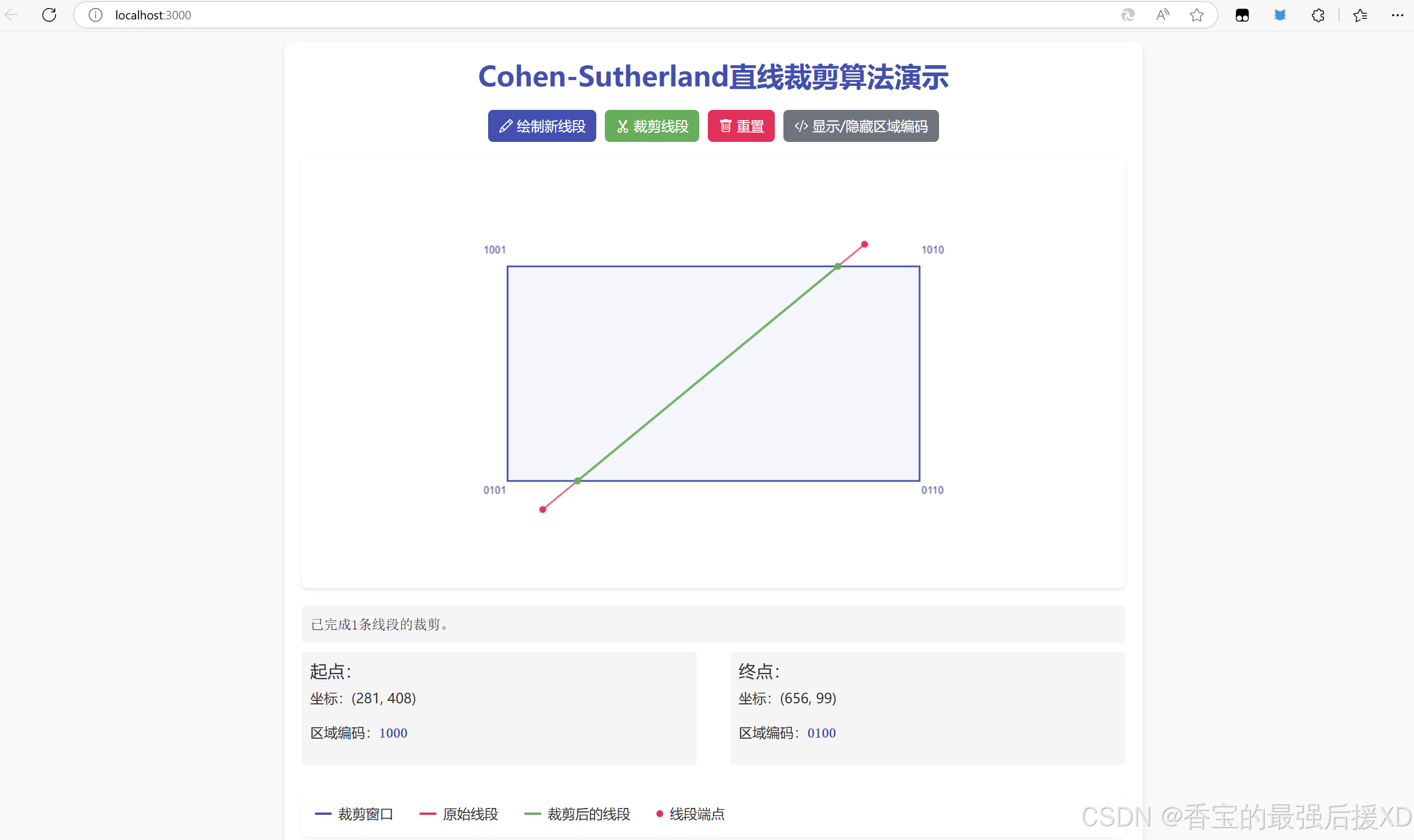
图形裁剪算法
1.学习目标 理解区域编码(Region Code,RC) 设计Cohen-Sutherland直线裁剪算法 编程实现Cohen-Sutherland直线裁剪算法 2.具体代码 1.具体算法 /*** Cohen-Sutherland直线裁剪算法 - 优化版* author AI Assistant* license MIT*/// 区域编码常量 - 使用对象枚举…...
(附源码))
Python字典实战: 三大管理系统开发指南(班级+会议+购物车)(附源码)
目录 摘要 一、班级管理系统(含成绩模块) 1. 功能概述 2. 完整代码与解析 3. 代码解析与亮点 二、会议管理系统 1. 功能概述 2. 完整代码 3. 代码解析与亮点 三、购物车管理系统 1. 功能概述 2. 完整代码 3. 代码解析与亮点 四、总结与扩…...
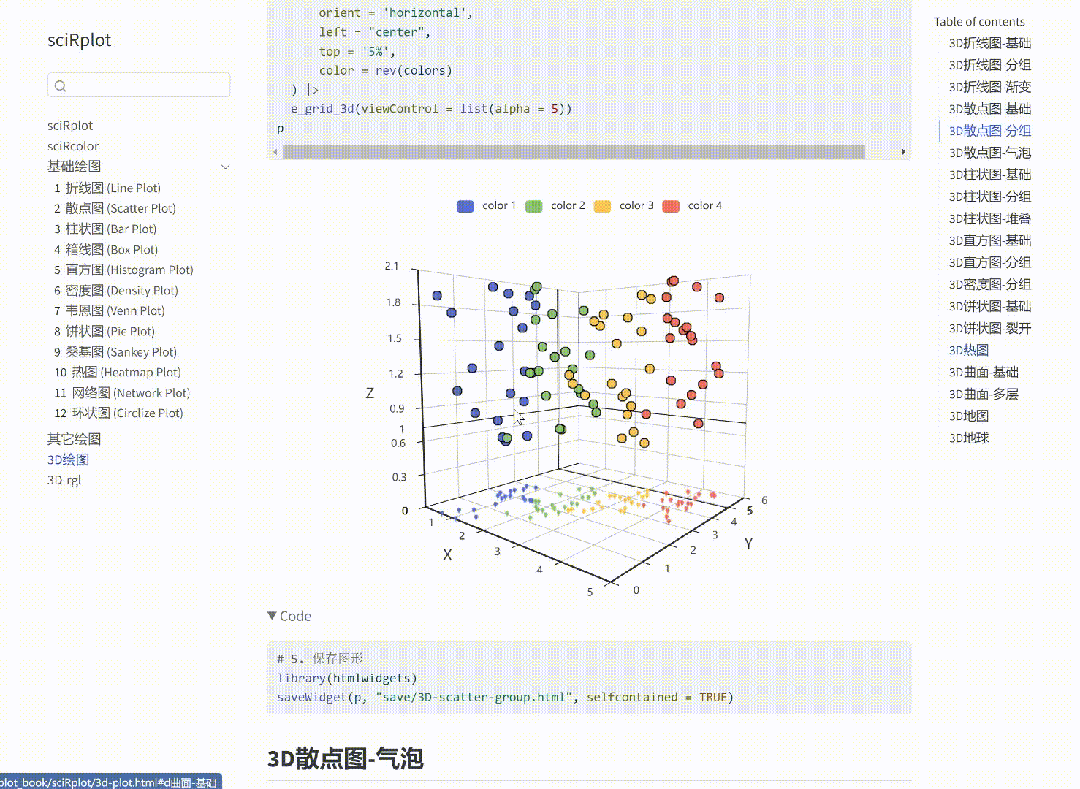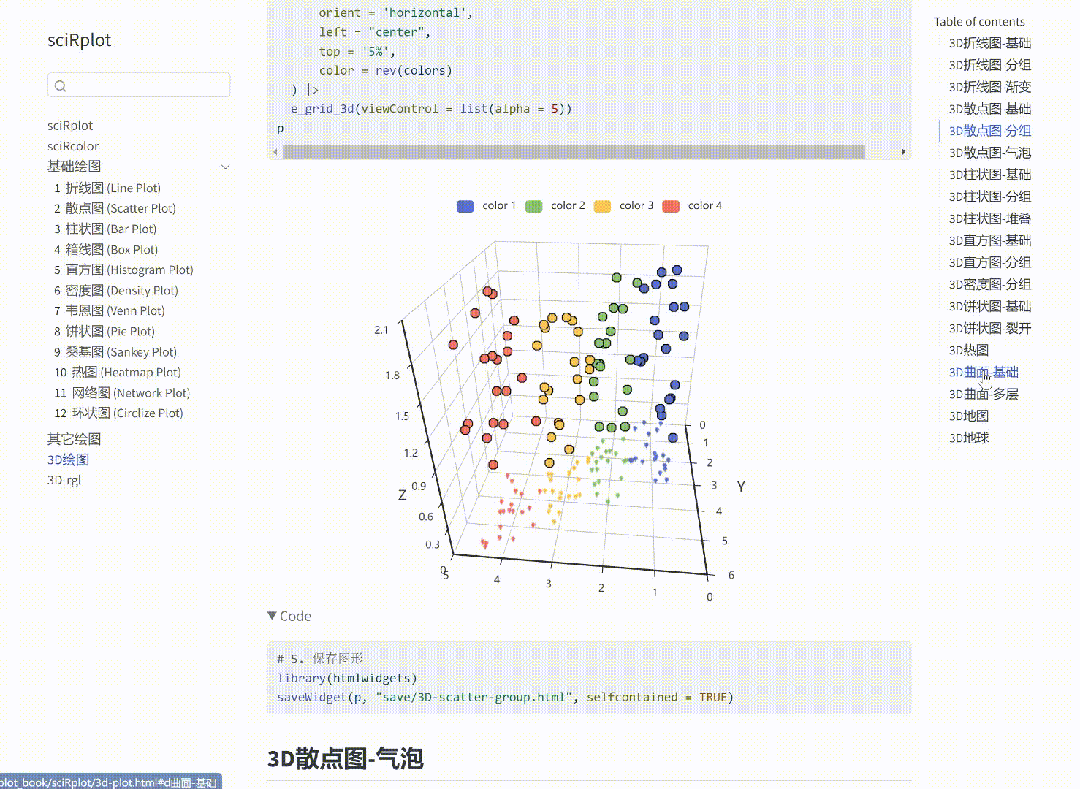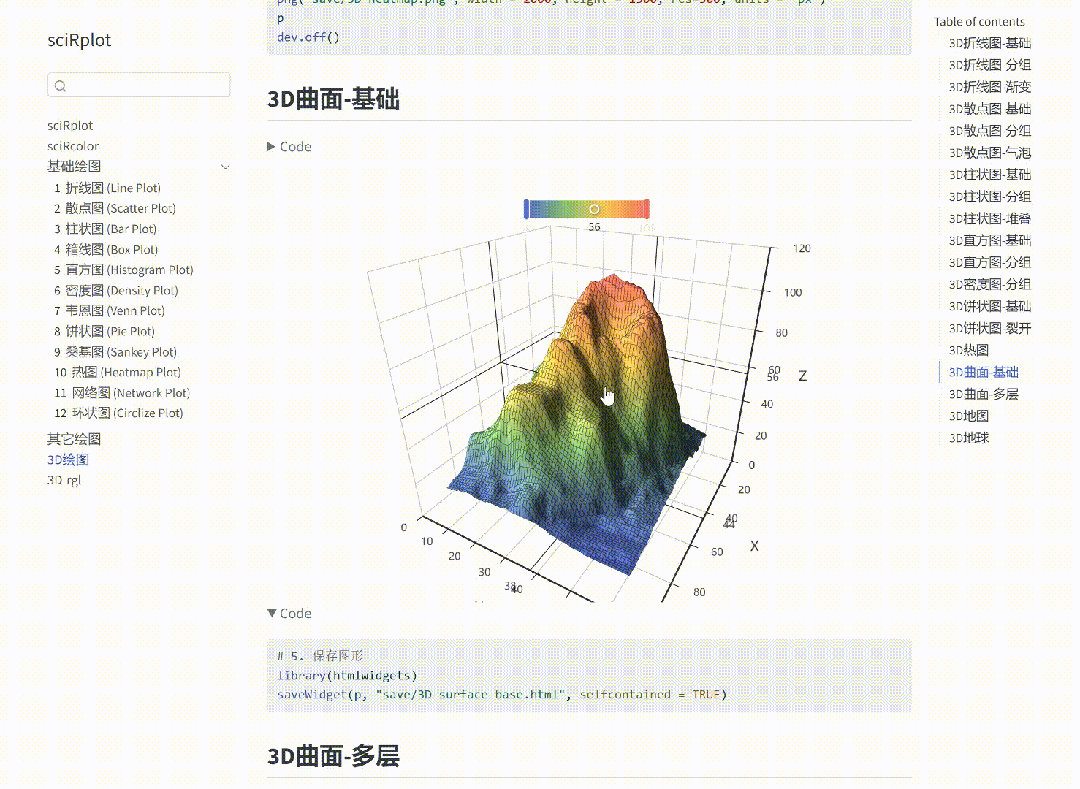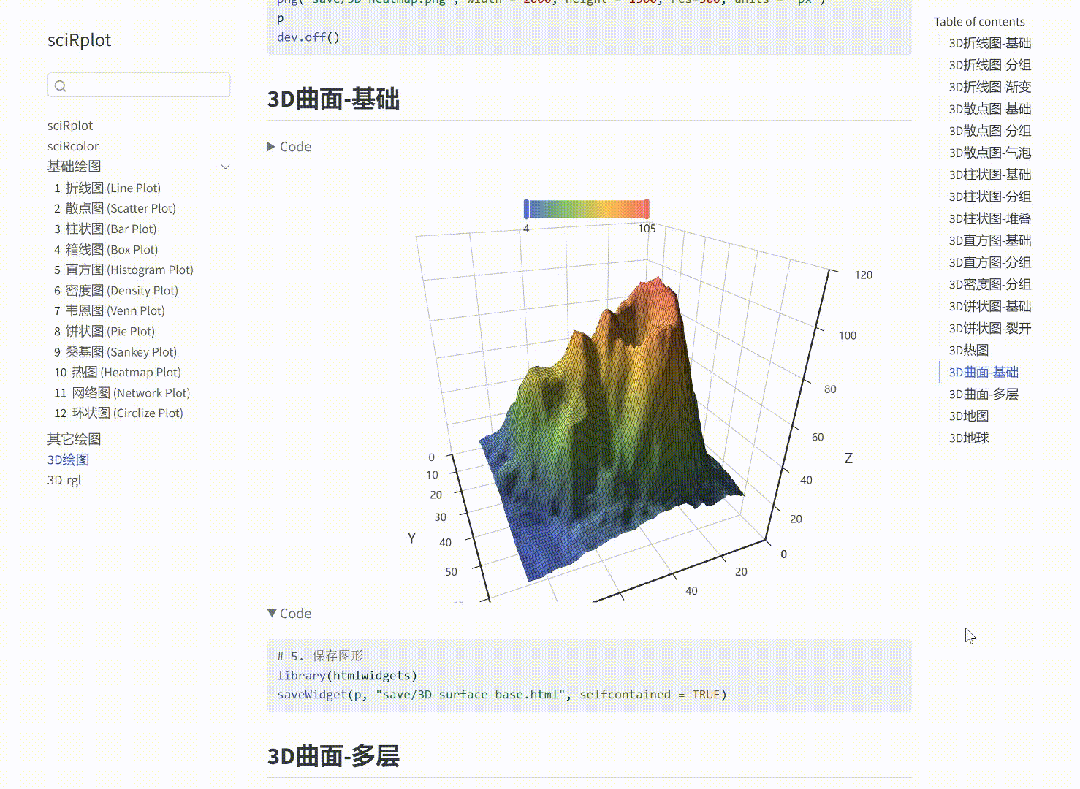
R 语言科研绘图第 36 期 --- 饼状图-基础
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

vue 3 从零开始到掌握
vue3从零开始一篇文章带你学习 升级vue CLI 使用命令 ## 查看vue/cli版本,确保vue/cli版本在4.5.0以上 vue --version ## 安装或者升级你的vue/cli npm install -g vue/cli ## 创建 vue create vue_test ## 启动 cd vue_test npm run servenvm管理node版本&#…...
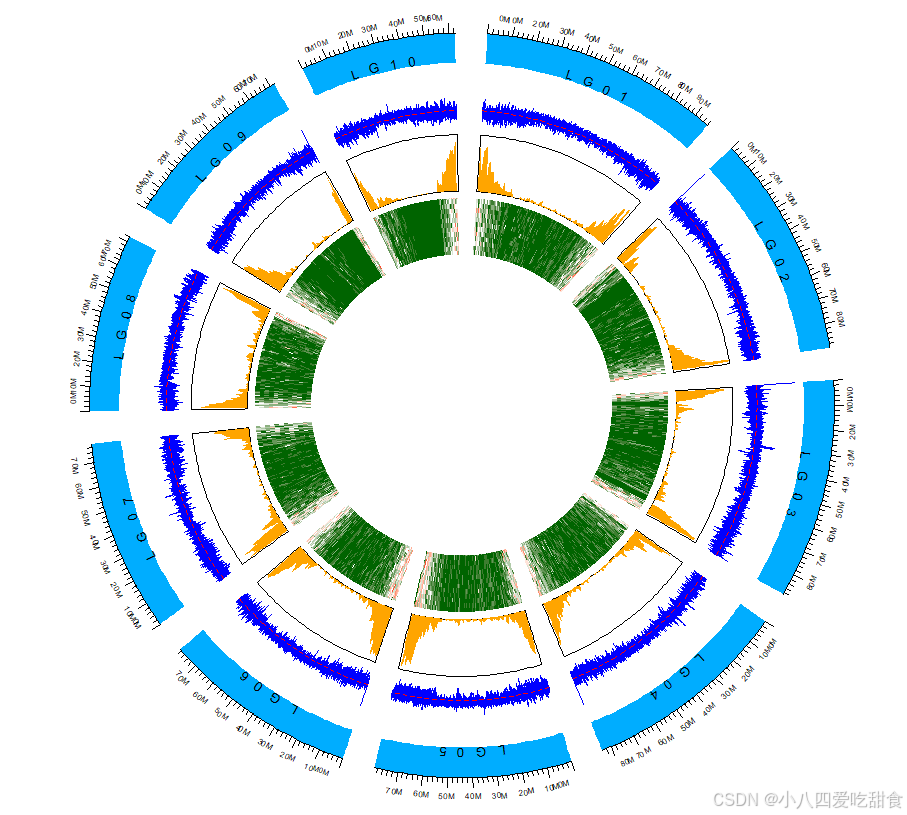
【R语言绘图】圈图绘制代码
绘制代码 rm(list ls())# 加载必要包 library(data.table) library(circlize) library(ComplexHeatmap) library(rtracklayer) library(GenomicRanges) library(BSgenome) library(GenomicFeatures) library(dplyr)### 数据准备阶段 ### # 1. 读取染色体长度信息 df <- re…...

OCR迁移
一、环境 操作系统:Centos57.6 数据库版本:12.2.0.1 场景:将OCR信息从DATA磁盘组迁移到OCR磁盘组 二、操作步骤 1.查看可用空盘 set lin 200 set pagesize 200 col DGNAME format a15 col DISKNAME format a15 col PATH format a20 col N…...
计算输入矩阵 src 中每个元素的平方根函数sqrt())
OpenCV 图形API(17)计算输入矩阵 src 中每个元素的平方根函数sqrt()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 计算数组元素的平方根。 cv::gapi::sqrt 函数计算每个输入数组元素的平方根。对于多通道数组,每个通道会独立处理。其精度大约与内置的 …...

python中的in关键字查找的时间复杂度
列表(List) 对于列表来说, in 运算符的复杂度是 O(n),其中n是列表的长度。这意味着如果列表中有n个元素,那么执行 in 运算符需要遍历整个列表来查找目标元素。 以下是一个示例,演示了在列表中使用 in 运算…...

Python爬虫第6节-requests库的基本用法
目录 前言 一、准备工作 二、实例引入 三、GET请求 3.1 基本示例 3.2 抓取网页 3.3 抓取二进制数据 3.4 添加headers 四、POST请求 五、响应 前言 前面我们学习了urllib的基础使用方法。不过,urllib在实际应用中存在一些不便之处。以网页验证和Cookies处理…...

什么是可靠性工程师?
一、什么是可靠性工程师? 可靠性工程师就是负责确保产品在使用过程中不出故障、不给客户添麻烦。 你可以理解为是那种“挑毛病的人”,但不是事后挑,是提前想清楚产品在哪些情况下可能会出问题,然后解决掉。 比如: …...
使用传统程序语言(C)进行编译---主,子程序连接:子程序的编译)
linux (CentOS 10)使用传统程序语言(C)进行编译---主,子程序连接:子程序的编译
1 主程序 rootlocalhost:~/testc/testlink3# cat thanks.c #include <stdio.h> // 声明子程序 void thanks_2(void); int main(void) {printf("Hello World\n");thanks_2(); }2 子程序 rootlocalhost:~/testc/testlink3# cat thanks_2.c #include <stdio.…...

如何根据设计稿进行移动端适配:全面详解
如何根据设计稿进行移动端适配:全面详解 文章目录 如何根据设计稿进行移动端适配:全面详解1. **理解设计稿**1.1 设计稿的尺寸1.2 设计稿的单位 2. **移动端适配的核心技术**2.1 使用 viewport 元标签2.1.1 代码示例2.1.2 参数说明 2.2 使用相对单位2.2.…...
【Kafka基础】Kafka 2.8以下版本的安装与配置指南:传统ZooKeeper依赖版详解
对于仍在使用Kafka 2.8之前版本的团队来说,需要特别注意其强依赖外部ZooKeeper的特性。本文将完整演示传统架构下的安装流程,并对比新旧版本差异。 1 版本特性差异说明 1.1 2.8 vs 2.8-核心区别 特性 2.8版本 2.8-版本 协调服务 可选内置KRaft模式 …...
Redis-x64-3.2.100.msi : Windows 安装包(MSI 格式)安装步骤
Redis-x64-3.2.100.msi 是 Redis 的 Windows 安装包(MSI 格式),适用于 64 位系统。 在由于一些环境需要低版本的Redis的安装包。 Redis-x64-3.2.100.msi 安装包下载:https://pan.quark.cn/s/cc4d38262a15 Redis 是一个开源的 内…...

ZoomCharts使用方法
本篇没有讲解,只是自己的小笔记,有看到的网友想明白具体用法的可以来私信我 <div class"zoomChartsComponent"><div id"zoomCharts-demo"></div></div> var ZoomChartsLicense ; var ZoomChartsLicenseKey…...

【云计算】打造高效容器云平台:规划、部署与架构设计
引言 随着移动互联网时代的大步跃进,互联网公司业务的爆炸式增长发展给传统行业带来了巨大的冲击和挑战,被迫考虑转型和调整。对于我们传统的航空行业来说,还存在传统的思维、落后的技术。一项新业务从提出需求到立项审批、公开招标、项目实…...

DeepSeek底层揭秘——《推理时Scaling方法》内容理解
4月初,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。 论文核心内容理解 DeepSeek与清华大学联合发布的论文《奖励模型的推理时Scaling方法及其在大规模语言模型中的应用》,核心在于提出一种新的推理时Scaling方法,即通过动态调…...
JavaScript之Json数据格式
介绍 JavaScript Object Notation, js对象标注法,是轻量级的数据交换格式完全独立于编程语言文本字符集必须用UTF-8格式,必须用“”任何支持的数据类型都可以用JSON表示JS内内置JSON解析JSON本质就是字符串 Json对象和JS对象互相转化 前端…...
与可变码率(VBR)?)
OBS 中如何设置固定码率(CBR)与可变码率(VBR)?
在使用 OBS 进行录制或推流时,设置“码率控制模式”(Rate Control)是非常重要的一步。常见的控制模式包括: CBR(固定码率):保持恒定的输出码率,适合直播场景。 VBR(可变码率):在允许的范围内动态调整码率,适合本地录制、追求画质。 一、CBR vs. VBR 的差异 项目CBR…...