【Kafka基础】Kafka 2.8以下版本的安装与配置指南:传统ZooKeeper依赖版详解
对于仍在使用Kafka 2.8之前版本的团队来说,需要特别注意其强依赖外部ZooKeeper的特性。本文将完整演示传统架构下的安装流程,并对比新旧版本差异。
1 版本特性差异说明
1.1 2.8+ vs 2.8-核心区别
| 特性 | 2.8+版本 | 2.8-版本 |
| 协调服务 | 可选内置KRaft模式 | 强制依赖外部ZooKeeper集群 |
| 部署复杂度 | 单进程即可运行 | 需独立维护ZK集群 |
| 元数据性能 | 吞吐提升20%+ | 受ZK性能制约 |
| 推荐生产版本 | ≥3.0 | ≤2.7.x |
2 安装准备(以2.7.1为例)
2.1 组件下载
Kafka下载地址:Index of /dist/kafka/2.7.1
Zookeeper下载地址:Index of /dist/zookeeper
2.2. 解压安装包以及目录结构
# 解压kafka安装包
tar -zxvf kafka_2.13-2.7.1.tgz -C kafka_zk/
# 解压zk安装包
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C kafka_zk/# 目录结构
[root@node5 kafka_zk]# tree -L 2
.
├── apache-zookeeper-3.6.3-bin
│ ├── bin
│ ├── conf
│ ├── data
│ ├── docs
│ ├── lib
│ ├── LICENSE.txt
│ ├── logs
│ ├── NOTICE.txt
│ ├── README.md
│ └── README_packaging.md
└── kafka_2.13-2.7.1├── bin├── config├── libs├── LICENSE├── licenses├── logs├── NOTICE└── site-docs14 directories, 6 files
[root@node5 kafka_zk]# # 各个目录用途解释
.
├── apache-zookeeper-3.6.3-bin # ZooKeeper 安装目录
│ ├── bin # ZooKeeper 可执行脚本(启动/停止/运维)
│ ├── conf # ZooKeeper 配置文件(zoo.cfg 等)
│ ├── data # ZooKeeper 数据存储目录(手动创建)
│ ├── docs # ZooKeeper 官方文档
│ ├── lib # ZooKeeper 运行时依赖库(JAR 文件)
│ ├── LICENSE.txt # Apache 2.0 许可证文件
│ ├── logs # ZooKeeper 运行日志(自动生成)
│ ├── NOTICE.txt # 第三方组件版权声明
│ ├── README.md # 项目说明文件
│ └── README_packaging.md # 打包说明文件
└── kafka_2.13-2.7.1 # Kafka 安装目录├── bin # Kafka 管理脚本(启动/主题操作等)├── config # Kafka 配置文件(server.properties 等)├── libs # Kafka 依赖库(核心 JAR 文件)├── LICENSE # Apache 2.0 许可证文件├── licenses # 第三方依赖的许可证文件├── logs # Kafka 运行日志(需手动创建或自动生成)├── NOTICE # 项目版权声明└── site-docs # Kafka 离线文档(HTML 格式)3 ZooKeeper独立部署
3.1 编辑配置文件
# 编辑conf/zoo.cfg:备份conf/zoo.cfg文件并添加如下内容
cp conf/zoo.cfg conf/zoo.cfg_bak
cat >conf/zoo.cfg<<EOF
# ZooKeeper 基础配置
tickTime=2000
initLimit=10
syncLimit=5# 数据存储目录(需提前创建并赋予权限)
dataDir=/export/home/kafka_zk/apache-zookeeper-3.6.3-bin/data
dataLogDir=/export/home/kafka_zk/apache-zookeeper-3.6.3-bin/logs# 客户端连接端口
clientPort=2181# 单机模式无需集群配置
# server.1=ip:port:port (集群模式下需配置)# 高级优化(可选)
maxClientCnxns=60
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
admin.serverPort=8080
maxClientCnxns=60
EOF3.2 启动与验证
# 启动ZK(后台模式)
bin/zkServer.sh start conf/zoo.cfg# 验证状态
echo srvr | nc 192.168.10.34 2181[root@node5 apache-zookeeper-3.6.3-bin]# echo srvr | nc 192.168.10.34 2181
Zookeeper version: 3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMT
Latency min/avg/max: 0/0.0/0
Received: 3
Sent: 2
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 5
[root@node5 apache-zookeeper-3.6.3-bin]# 4 Kafka服务配置
4.1 编辑配置文件
# 编辑config/server.properties文件:备份文件并添加如下内容
cp config/server.properties config/server.properties_bak
cat >config/server.properties<<EOF
############################ 基础配置 #############################
# Broker唯一标识(单机保持默认)
broker.id=0# 监听地址(必须配置为实际IP或主机名,不能用0.0.0.0)
listeners=PLAINTEXT://192.168.10.34:9092
advertised.listeners=PLAINTEXT://192.168.10.34:9092# 日志存储目录(需提前创建并赋权)
log.dirs=/export/home/kafka_zk/kafka_2.13-2.7.1/logs# ZooKeeper连接地址(单机模式)
zookeeper.connect=192.168.10.34:2181############################# 单机特殊配置 #############################
# 强制内部Topic副本数为1(单机必须配置!)
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1# 禁用自动创建Topic(生产环境建议)
auto.create.topics.enable=false############################# 性能优化 #############################
# 网络线程数(建议CPU核数)
num.network.threads=2# IO线程数(建议2*CPU核数)
num.io.threads=4# 日志保留策略
log.retention.hours=168 # 保留7天
log.segment.bytes=1073741824 # 单个日志段1GB
log.retention.check.interval.ms=300000 # 检查间隔5分钟# 消息持久化
flush.messages=10000 # 每10000条消息刷盘
flush.ms=1000 # 每秒刷盘一次############################# 高级调优 #############################
# Socket缓冲区大小
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400# 副本同步设置(单机可忽略)
default.replication.factor=1
min.insync.replicas=1# 控制器配置
controller.socket.timeout.ms=30000
EOF4.2 编写启动脚本
# 创建bin/start-kafka.sh避免内存不足
#!/bin/bash
export KAFKA_HEAP_OPTS="-Xms1G -Xmx1G"
export JMX_PORT=9999
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-server-start.sh /export/home/kafka_zk/kafka_2.13-2.7.1/config/server.propertieschmod +x bin/start-kafka.sh4.3 启动服务并验证
# 启动
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/start-kafka.sh# 创建topic并查看详情
# 创建名为test的Topic,1分区1副本
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \--bootstrap-server 192.168.10.34:9092 \--replication-factor 1 \--partitions 1 \--topic test[root@node5 ~]# /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \
> --bootstrap-server 192.168.10.34:9092 \
> --replication-factor 1 \
> --partitions 1 \
> --topic test
Created topic test.
[root@node5 ~]# # 查看Topic详情
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.10.34:9092[root@node5 ~]# /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.10.34:9092Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs: min.insync.replicas=1,segment.bytes=1073741824Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
[root@node5 ~]# 5 版本特定问题解决
5.1 ZooKeeper连接超时
现象:Session expired错误
# 增加server.properties参数
zookeeper.session.timeout.ms=18000
zookeeper.connection.timeout.ms=150005.2. 磁盘写性能低下
# 禁用完全刷盘(牺牲部分可靠性)
log.flush.interval.messages=10000
log.flush.interval.ms=10005.3 监控指标缺失
# 启用JMX导出
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999"
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-server-start.sh /export/home/kafka_zk/kafka_2.13-2.7.1/bin/server.properties相关文章:
【Kafka基础】Kafka 2.8以下版本的安装与配置指南:传统ZooKeeper依赖版详解
对于仍在使用Kafka 2.8之前版本的团队来说,需要特别注意其强依赖外部ZooKeeper的特性。本文将完整演示传统架构下的安装流程,并对比新旧版本差异。 1 版本特性差异说明 1.1 2.8 vs 2.8-核心区别 特性 2.8版本 2.8-版本 协调服务 可选内置KRaft模式 …...
Redis-x64-3.2.100.msi : Windows 安装包(MSI 格式)安装步骤
Redis-x64-3.2.100.msi 是 Redis 的 Windows 安装包(MSI 格式),适用于 64 位系统。 在由于一些环境需要低版本的Redis的安装包。 Redis-x64-3.2.100.msi 安装包下载:https://pan.quark.cn/s/cc4d38262a15 Redis 是一个开源的 内…...

ZoomCharts使用方法
本篇没有讲解,只是自己的小笔记,有看到的网友想明白具体用法的可以来私信我 <div class"zoomChartsComponent"><div id"zoomCharts-demo"></div></div> var ZoomChartsLicense ; var ZoomChartsLicenseKey…...

【云计算】打造高效容器云平台:规划、部署与架构设计
引言 随着移动互联网时代的大步跃进,互联网公司业务的爆炸式增长发展给传统行业带来了巨大的冲击和挑战,被迫考虑转型和调整。对于我们传统的航空行业来说,还存在传统的思维、落后的技术。一项新业务从提出需求到立项审批、公开招标、项目实…...

DeepSeek底层揭秘——《推理时Scaling方法》内容理解
4月初,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。 论文核心内容理解 DeepSeek与清华大学联合发布的论文《奖励模型的推理时Scaling方法及其在大规模语言模型中的应用》,核心在于提出一种新的推理时Scaling方法,即通过动态调…...
JavaScript之Json数据格式
介绍 JavaScript Object Notation, js对象标注法,是轻量级的数据交换格式完全独立于编程语言文本字符集必须用UTF-8格式,必须用“”任何支持的数据类型都可以用JSON表示JS内内置JSON解析JSON本质就是字符串 Json对象和JS对象互相转化 前端…...
与可变码率(VBR)?)
OBS 中如何设置固定码率(CBR)与可变码率(VBR)?
在使用 OBS 进行录制或推流时,设置“码率控制模式”(Rate Control)是非常重要的一步。常见的控制模式包括: CBR(固定码率):保持恒定的输出码率,适合直播场景。 VBR(可变码率):在允许的范围内动态调整码率,适合本地录制、追求画质。 一、CBR vs. VBR 的差异 项目CBR…...
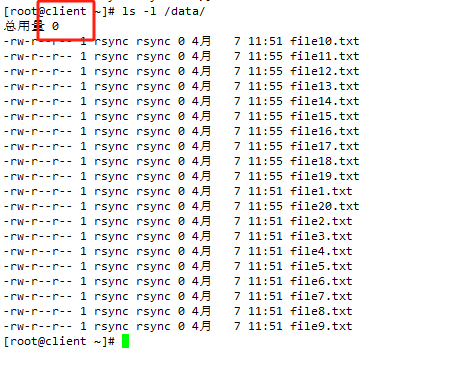
使用 Rsync + Lsyncd 实现 CentOS 7 实时文件同步
文章目录 🌀使用 Rsync Lsyncd 实现 CentOS 7 实时文件同步前言介绍架构图🧱系统环境🔧Rsync配置(两台都需安装)关闭SELinux(两台都需) 📦配置目标端(client)…...

C# 多线程并发编程基础
1. 线程基础 1.1 线程简介 C# 中的线程是操作系统能够进行运算调度的最小单位,它被包含在进程中,是进程中的实际运作单位。一个进程可以包含多个线程,这些线程可以并发执行不同的任务。 1.2 线程的创建与启动 在 C# 中,可以使…...
系统,提示词(Prompt)表现测试(数据说话))
RAG(检索增强生成)系统,提示词(Prompt)表现测试(数据说话)
在RAG(检索增强生成)系统中,评价提示词(Prompt)设计是否优秀,必须通过量化测试数据来验证,而非主观判断。以下是系统化的评估方法、测试指标和具体实现方案: 一、提示词优秀的核心标准 优秀的提示词应显著提升以下指标: 维度量化指标测试方法事实一致性Faithfulness …...

QML和C++交互
目录 1 QML与C交互基础1.1 全局属性1.2 属性私有化(提供接口访问) 2 QT与C交互(C创建自定义对象,qml文件直接访问)3 QT与C交互(qml直接访问C中的函数)4 QT与C交互(qml端发送信号 C端实现槽函数)…...

Android studio学习之路(六)--真机的调试以及多媒体照相的使用
多媒体应用(语言识别,照相,拍视频)在生活的各个方面都具有非常大的作用,所以接下来将会逐步介绍多媒体的使用,但是在使用多媒体之前,使用模拟器肯定是不行的,所以我们必须要使用真机…...

解决 Lettuce 在 Redis 集群模式下的故障转移问题
引言 在高可用系统中,故障转移是确保服务不中断的重要机制。当我们使用 Lettuce 作为 Redis 的 Java 客户端时,如何高效地处理故障转移成为一项关键任务。本篇文章将探讨如何在 Redis 集群模式下配置 Lettuce 以优化故障转移。 背景 在初期设置 Lettu…...
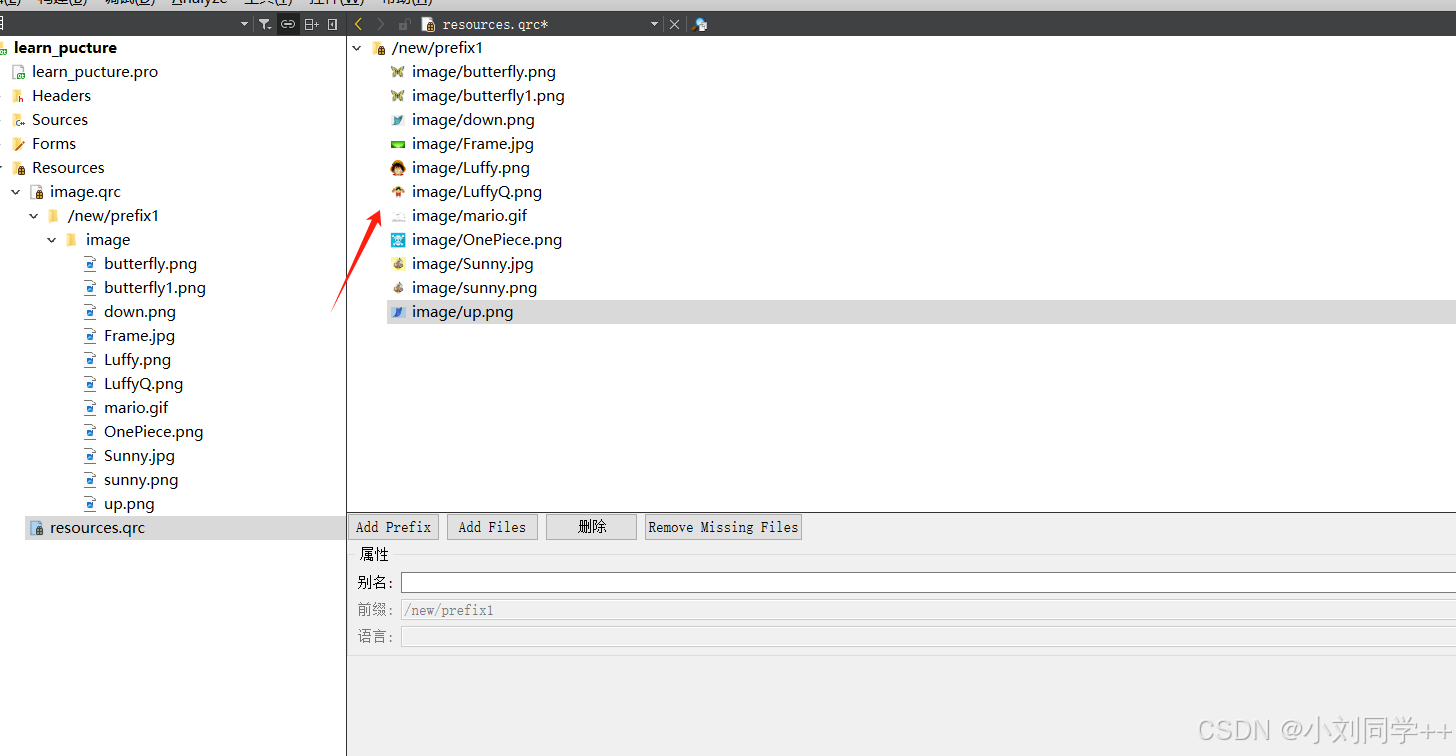
Qt 资源文件(.qrc 文件)
Qt 资源文件(.qrc 文件)是 Qt 提供的一种机制,用来将文件(如图像、音频、文本文件等)嵌入到应用程序中,使得这些文件不需要依赖外部文件路径,而是直接打包到程序的可执行文件中。通过使用 Qt 资…...

Vue 组件命名及子组件接收参数命名
1. 对于单个单词的组件 方式一:首字母大写。如 <School></School>。在 vue 开发者工具中默认使用的是该种方式。 方式二: 首字母小写。如 <school></school> 2. 对于多个单词的组件 方式一:每个单词都是小写&…...
PandaAI:一个基于AI的对话式数据分析工具
PandaAI 是一个基于 Python 开发的自然语言处理和数据分析工具,支持问答式(ChatGPT)的数据分析和报告生成功能。PandaAI 提供了一个开源的框架,主要核心组件包含用于数据处理的数据准备层(Pandas)以及实现 …...
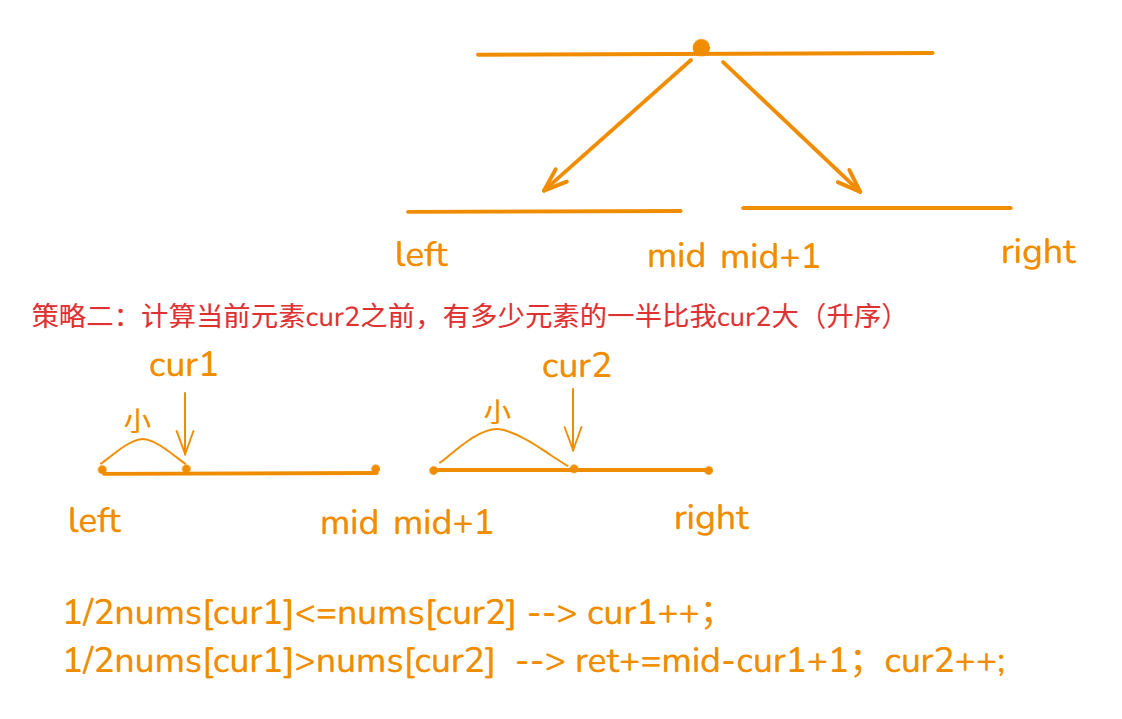
【C++算法】50.分治_归并_翻转对
文章目录 题目链接:题目描述:解法C 算法代码:图解 题目链接: 493. 翻转对 题目描述: 解法 分治 策略一:计算当前元素cur1后面,有多少元素的两倍比我cur1小(降序) 利用单…...

Github最新AI工具汇总2025年4月份第2周
根据GitHub官方动态及开发者生态最新进展,以下是2025年4月第二周(截至4月7日)值得关注的AI工具与技术更新汇总: 1. GitHub Copilot Agent Mode全量发布 核心功能:在VS Code中启用Agent模式后,Copilot可自主…...

用VAE作为标题显示标题过短,所以标题变成了这样
VAE (Variational Autoencoder / 变分自编码器) 基本概念: VAE 是一种生成模型 (Generative Model),属于自编码器 (Autoencoder) 家族。 它的目标是学习数据的潜在表示 (Latent Representation),并利用这个表示来生成新的、与原始数据相似的数据。 与标…...

docker的run命令 笔记250406
docker的run命令 笔记250406 Docker 的 run 命令用于创建并启动一个新的容器。它是 Docker 中最常用的命令之一,基本语法为: docker run [OPTIONS] IMAGE [COMMAND] [ARG...]常用选项(OPTIONS) 参数说明-d 或 --detach后台运行…...
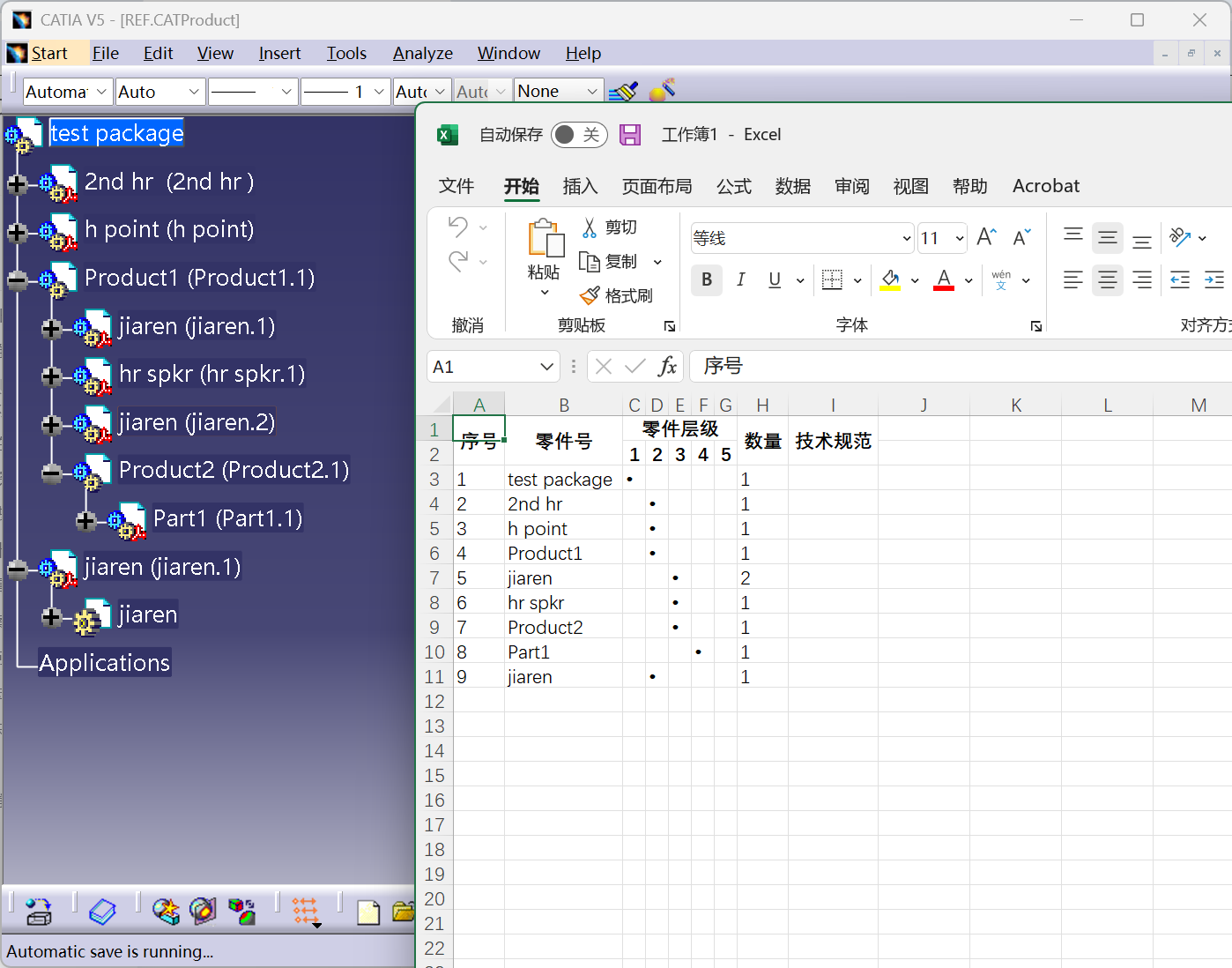
基于pycatia的CATIA层级式BOM生成器开发全解析
引言:BOM生成技术的革新之路 在高端装备制造领域,CATIA的BOM管理直接影响着研发效率和成本控制。传统VBA方案 虽能实现基础功能,但存在代码维护困难、跨版本兼容性差等痛点。本文基于pycatia框架,提出一种支持动态层级识别、智能查重、Excel联动的BOM生成方案,其核心突破…...
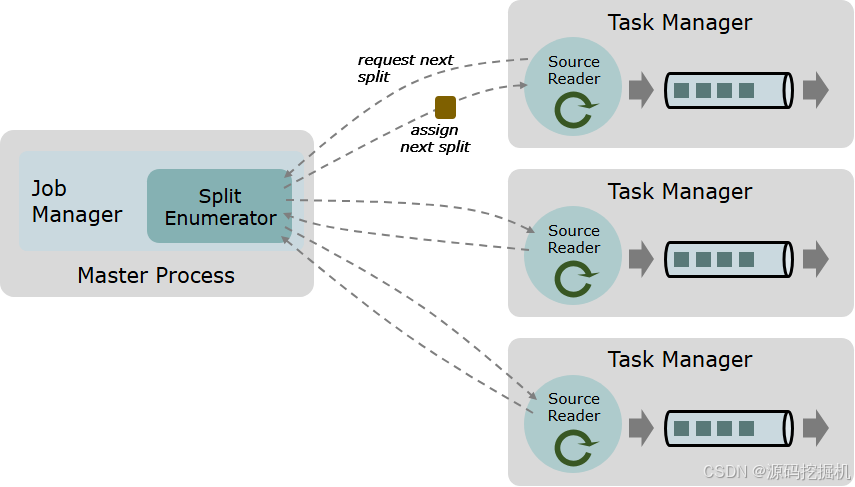
Flink 1.20 Kafka Connector:新旧 API 深度解析与迁移指南
Flink Kafka Connector 新旧 API 深度解析与迁移指南 一、Flink Kafka Connector 演进背景 Apache Flink 作为实时计算领域的标杆框架,其 Kafka 连接器的迭代始终围绕性能优化、语义增强和API 统一展开。Flink 1.20 版本将彻底弃用基于 FlinkKafkaConsumer/FlinkK…...

2025年渗透测试面试题总结- 某四字大厂面试复盘扩展 一面(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 某四字大厂面试复盘扩展 一面 一、Java内存马原理与查杀 二、冰蝎与哥斯拉原理对比(技术演…...
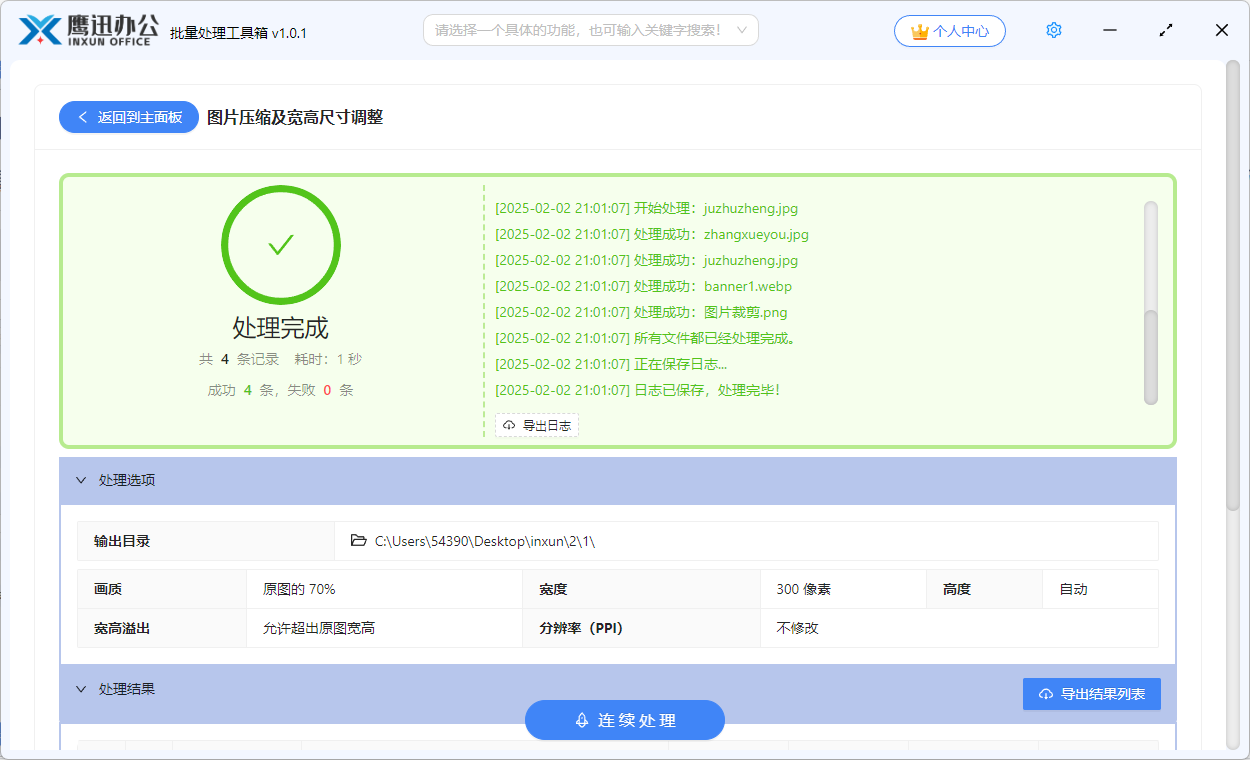
批量压缩 jpg/png 等格式照片|批量调整图片的宽高尺寸
图片格式种类非常的多,并且不同的图片由于像素、尺寸不一样,可能占用的空间也会不一样。文件太大会占用较多的磁盘空间,传输及上传系统都非常不方便,可能会收到限制,因此我们经常会碰到需要对图片进行压缩的需求。如何…...

目录穿越 + pickle反序列化 -- xyctf Signin WP
源代码 # -*- encoding: utf-8 -*-File : main.py Time : 2025/03/28 22:20:49 Author : LamentXUflag in /flag_{uuid4}from bottle import Bottle, request, response, redirect, static_file, run, route secret aapp Bottle() route(/) def index():return…...

Spring Boot 框架注解:@ConfigurationProperties
ConfigurationProperties(prefix "sky.jwt") 是 Spring Boot 框架里的一个注解,其主要功能是把配置文件(像 application.properties 或者 application.yml)里的属性值绑定到一个 Java 类的字段上。下面详细阐述其作用:…...

【动手学深度学习】卷积神经网络(CNN)入门
【动手学深度学习】卷积神经网络(CNN)入门 1,卷积神经网络简介2,卷积层2.1,互相关运算原理2.2,互相关运算实现2.3,实现卷积层 3,卷积层的简单应用:边缘检测3.1࿰…...

在huggingface上制作小demo
在huggingface上制作小demo 今天好兄弟让我帮他搞一个模型,他有小样本的化学数据,想让我根据这些数据训练一个小模型,他想用这个模型预测一些值 最终我简单训练了一个小模型,起初想把这个模型和GUI界面打包成exe发给他࿰…...

集合学习内容总结
集合简介 1、Scala 的集合有三大类:序列 Seq、集Set、映射 Map,所有的集合都扩展自 Iterable 特质。 2、对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包 不可变集合:scala.collect…...
51.评论日记
千万不能再挖了,否则整个华夏文明将被改写。_哔哩哔哩_bilibili 2025年4月7日22:13:42...