Python爬虫生成CSV文件的完整流程

引言
在当今数据驱动的时代,网络爬虫已成为获取互联网数据的重要工具。Python凭借其丰富的库生态系统和简洁的语法,成为了爬虫开发的首选语言。本文将详细介绍使用Python爬虫从网页抓取数据并生成CSV文件的完整流程,包括环境准备、网页请求、数据解析、数据清洗和CSV文件输出等关键环节。
一、准备工作
在开始编写爬虫之前,我们需要安装一些必要的Python库。以下是主要的依赖库及其用途:
- Requests:用于发送HTTP请求,获取网页内容。
- BeautifulSoup4:用于解析HTML文档,提取所需数据。
- csv:Python内置的库,用于操作CSV文件。
二、目标网站分析
在编写爬虫之前,我们需要明确目标网站的结构,了解数据所在的HTML标签和属性。例如,假设我们要抓取一个新闻网站的标题和链接,我们首先需要查看网页的源代码,找到新闻标题和链接所在的HTML元素。
以一个简单的新闻网站为例,其HTML结构可能如下:
<div class="news-list"><div class="news-item"><a href="link1.html">新闻标题1</a></div><div class="news-item"><a href="link2.html">新闻标题2</a></div>...
</div>
预览
从上述结构中,我们可以看到新闻标题和链接都包含在<a>标签中,且这些<a>标签位于class="news-item"的<div>标签内。
三、编写爬虫代码
1. 发送HTTP请求
使用requests库发送HTTP请求,获取网页的HTML内容。
import requestsurl = "https://example.com/news" # 目标网站的URL
response = requests.get(url)if response.status_code == 200:html_content = response.text
else:print("Failed to retrieve the webpage")exit()
2. 解析HTML内容
使用BeautifulSoup解析HTML内容,提取新闻标题和链接。
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_content, 'html.parser')
news_items = soup.find_all('div', class_='news-item')news_data = []
for item in news_items:title = item.find('a').textlink = item.find('a')['href']news_data.append({'title': title, 'link': link})
3. 数据保存到CSV文件
使用Python内置的csv模块将数据保存到CSV文件中。
import csvcsv_file = "news_data.csv" # CSV文件名
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=['title', 'link'])writer.writeheader()for data in news_data:writer.writerow(data)
四、完整代码实现
将上述代码片段整合为一个完整的Python脚本:
import requests
from bs4 import BeautifulSoup
import csv# 代理信息
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"# 构造代理服务器的认证信息
proxies = {"http": f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}","https": f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"
}# 目标网站URL
url = "https://example.com/news"# 发送HTTP请求
try:response = requests.get(url, proxies=proxies, timeout=10) # 设置超时时间为10秒if response.status_code == 200:html_content = response.textelse:print(f"Failed to retrieve the webpage. Status code: {response.status_code}")print("Please check the URL's validity or try again later.")exit()
except requests.exceptions.RequestException as e:print(f"An error occurred while trying to retrieve the webpage: {e}")print("This issue might be related to the URL or the network. Please check the URL's validity and your network connection.")print("If the problem persists, consider using a different proxy or checking the target website's accessibility.")exit()# 解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
news_items = soup.find_all('div', class_='news-item')# 提取新闻数据
news_data = []
for item in news_items:title = item.find('a').textlink = item.find('a')['href']news_data.append({'title': title, 'link': link})# 保存到CSV文件
csv_file = "news_data.csv" # CSV文件名
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=['title', 'link'])writer.writeheader()for data in news_data:writer.writerow(data)print(f"Data has been successfully saved to {csv_file}")
六、注意事项
- 遵守法律法规:在使用爬虫抓取数据时,必须遵守相关法律法规,不得侵犯网站的版权和隐私。
- 尊重网站的robots.txt文件:查看目标网站的
robots.txt文件,了解哪些页面允许爬取,哪些页面禁止爬取。 - 设置合理的请求间隔:避免对目标网站造成过大压力,建议在请求之间设置合理的间隔时间。
- 处理异常情况:在实际应用中,可能会遇到网络请求失败、HTML结构变化等问题。建议在代码中添加异常处理机制,确保爬虫的稳定运行。
七、扩展应用
Python爬虫生成CSV文件的流程可以应用于多种场景,例如:
- 电商数据采集:抓取商品信息、价格、评价等数据,用于市场分析和竞争情报。
- 社交媒体数据挖掘:抓取用户评论、帖子内容等数据,用于舆情分析和用户行为研究。
- 新闻资讯聚合:抓取新闻标题、内容、发布时间等数据,用于新闻聚合和信息推送。
通过灵活运用Python爬虫技术和CSV文件操作,我们可以高效地获取和整理互联网上的数据,为数据分析、机器学习和商业决策提供有力支持。
相关文章:
Python爬虫生成CSV文件的完整流程
引言 在当今数据驱动的时代,网络爬虫已成为获取互联网数据的重要工具。Python凭借其丰富的库生态系统和简洁的语法,成为了爬虫开发的首选语言。本文将详细介绍使用Python爬虫从网页抓取数据并生成CSV文件的完整流程,包括环境准备、网页请求、…...

21.OpenCV获取图像轮廓信息
OpenCV获取图像轮廓信息 在计算机视觉领域,识别和分析图像中的对象形状是一项基本任务。OpenCV 库提供了一个强大的工具——轮廓检测(Contour Detection),它能够帮助我们精确地定位对象的边界。这篇博文将带你入门 OpenCV 的轮廓…...
医学图像分割效率大幅提升!U-Net架构升级,助力精度提升5%!
在医学图像分割领域,U-Net模型及其变体的创新应用正在带来显著的性能提升和效率优化。最新研究显示,通过引入结构化状态空间模型(SSM)和轻量级LSTM(xLSTM)等技术,VMAXL-UNet模型在多个医学图像数…...

智能设备运行监控系统
在工业 4.0 与智能制造浪潮下,设备运行效率与稳定性成为企业竞争力的核心要素。然而,传统设备管理模式面临数据采集分散、状态分析滞后、维护成本高昂等痛点。为破解这些难题,设备运行监控系统应运而生,通过融合智能传感、5G 通信…...

详细分析单例模式
目录 1.单例模式的定义 2.单例模式的实现方式 1.饿汉模式 2.懒汉模式 (1)线程不安全的问题怎么解决? (2)直接对整个getInstance方法代码块加锁吗? (3)那对if语句加锁不就行了吗…...

Windwos的DNS解析命令nslookup
nslookup 解析dns的命令 有两种使用方式,交互式&命令行方式。 交互式 C:\Users\Administrator>nslookup 默认服务器: UnKnown Address: fe80::52f7:edff:fe28:35de> www.baidu.com 服务器: UnKnown Address: fe80::52f7:edff:fe28:35de非权威应答:…...
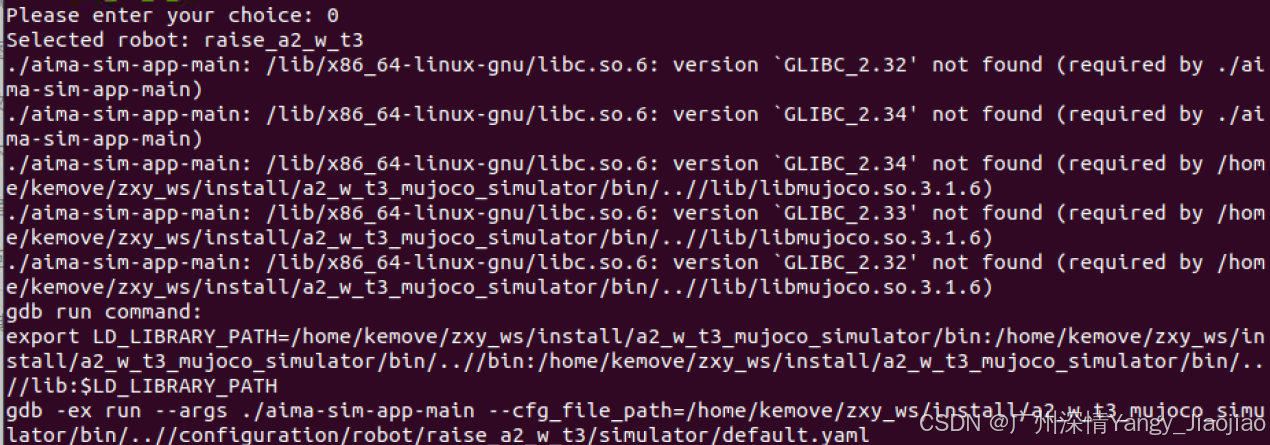
服务器报错:xxx/libc.so.6: version `GLIBC_2.32‘ not found
/lib/x86_64-linux-gnu/libc.so.6: version GLIBC_2.32 not found (required by ./aima-sim-app-main) 解决思路 根据错误信息,您的应用程序 aima-sim-app-main 和 libmujoco.so.3.1.6 库依赖于较新的 GNU C Library (glibc) 版本(如 GLIBC_2.32, GLIBC…...

Flutter之页面布局一
目录: 1、页面布局一2、无状态组件StatelessWidget和有状态组件StatefulWidget2.1、无状态组件示例2.2、有状态组件示例2.3、在 widget 之间共享状态1、使用 widget 构造函数2、使用 InheritedWidget3、使用回调 3、布局小组件3.1、布置单个 Widget3.2、容器3.3、垂…...

架构思维: 数据一致性的两种场景深度解读
文章目录 Pre案例数据一致性问题的两种场景第一种场景:实时数据不一致不要紧,保证数据最终一致性就行第二种场景:必须保证实时一致性 最终一致性方案实时一致性方案TCC 模式Seata 中 AT 模式的自动回滚一阶段二阶段-回滚二阶段-提交 Pre 架构…...
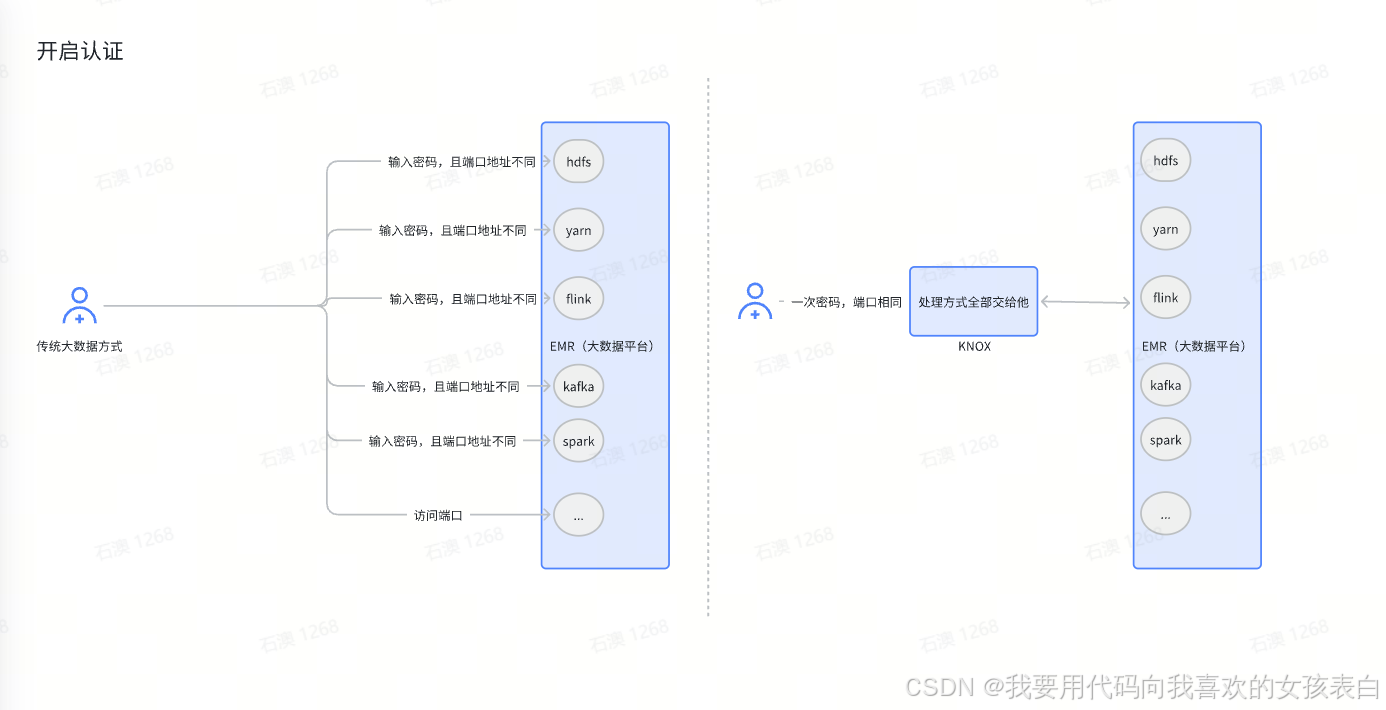
大数据knox网关API
我们过去访问大数据组件,如sparkui,hdfs的页面,以及yarn上面看信息是很麻烦的一件事。要记每个端口号,比如50070,8090,8088,4007,如果换到另一个集群,不同版本࿰…...
)
UI测试(2)
1、HTML 是用来描述网页的一种语言。 指的是超文本标记语言 (Hyper Text Markup Language) ,HTML 不是一种编程语言,而是一种标记语言 (markup language) 负责定义页面呈现的内容:标签语言:<标签名>标签值<标签名>&am…...

【Tauri2】015——前端的事件、方法和invoke函数
目录 前言 正文 准备 关键url 获取所有命令 切换主题set_theme 设置大小 获得版本version 名字name 监听窗口移动 前言 【Tauri2】005——tauri::command属性与invoke函数-CSDN博客https://blog.csdn.net/qq_63401240/article/details/146581991?spm1001.2014.3001.…...
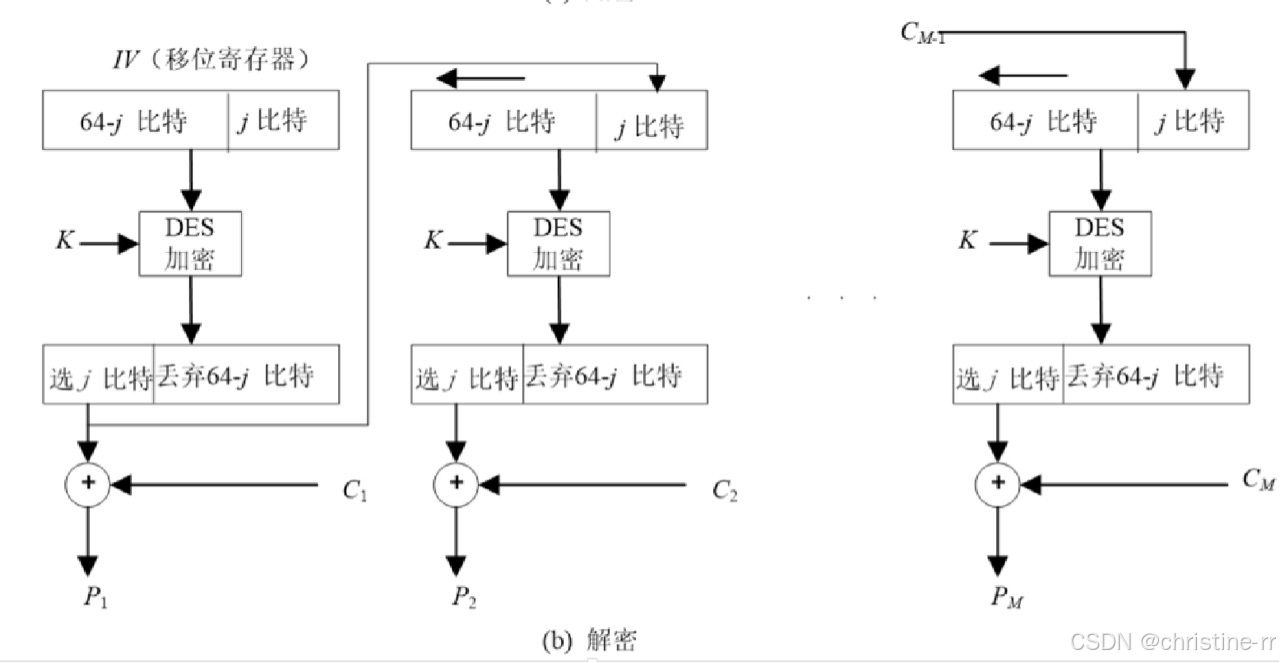
密码学基础——分组密码的运行模式
前面的文章中文我们已经知道了分组密码是一种对称密钥密码体制,其工作原理可以概括为将明文消息分割成固定长度的分组,然后对每个分组分别进行加密处理。 下面介绍分组密码的运行模式 1.电码本模式(ECB) 2.密码分组链接模式&…...

Android SELinux权限使用
Android SELinux权限使用 一、SELinux开关 adb在线修改seLinux(也可以改配置文件彻底关闭) $ getenforce; //获取当前seLinux状态,Enforcing(表示已打开),Permissive(表示已关闭) $ setenforce 1; //打开seLinux $ setenforce 0; //关闭seLinux二、命令查看sel…...

Python----计算机视觉处理(Opencv:道路检测完整版:透视变换,提取车道线,车道线拟合,车道线显示,)
Python----计算机视觉处理(Opencv:道路检测之道路透视变换) Python----计算机视觉处理(Opencv:道路检测之提取车道线) Python----计算机视觉处理(Opencv:道路检测之车道线拟合) Python----计算机视觉处理࿰…...
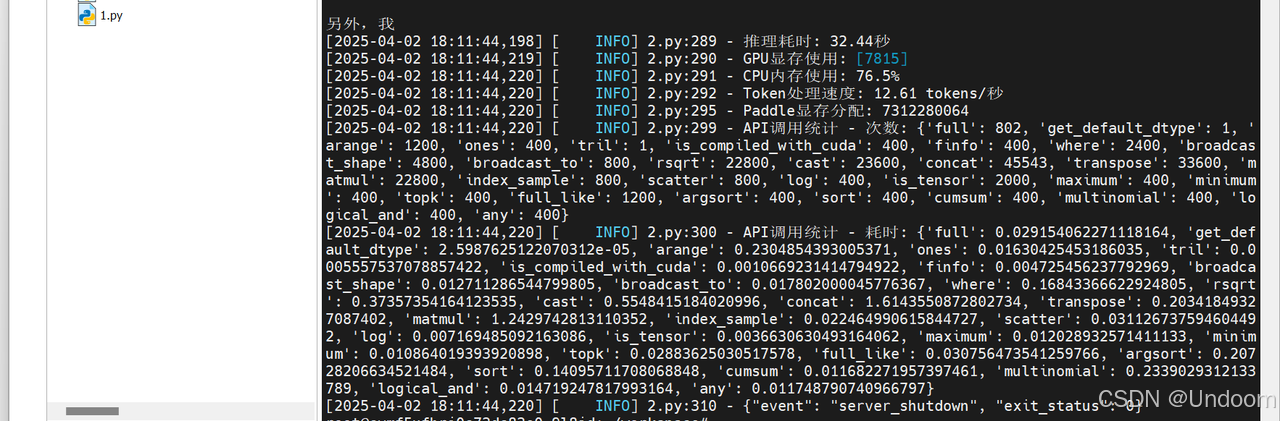
基于飞桨框架3.0本地DeepSeek-R1蒸馏版部署实战
深度学习框架与大模型技术的融合正推动人工智能应用的新一轮变革。百度飞桨(PaddlePaddle)作为国内首个自主研发、开源开放的深度学习平台,近期推出的3.0版本针对大模型时代的开发痛点进行了系统性革新。其核心创新包括“动静统一自动并行”&…...
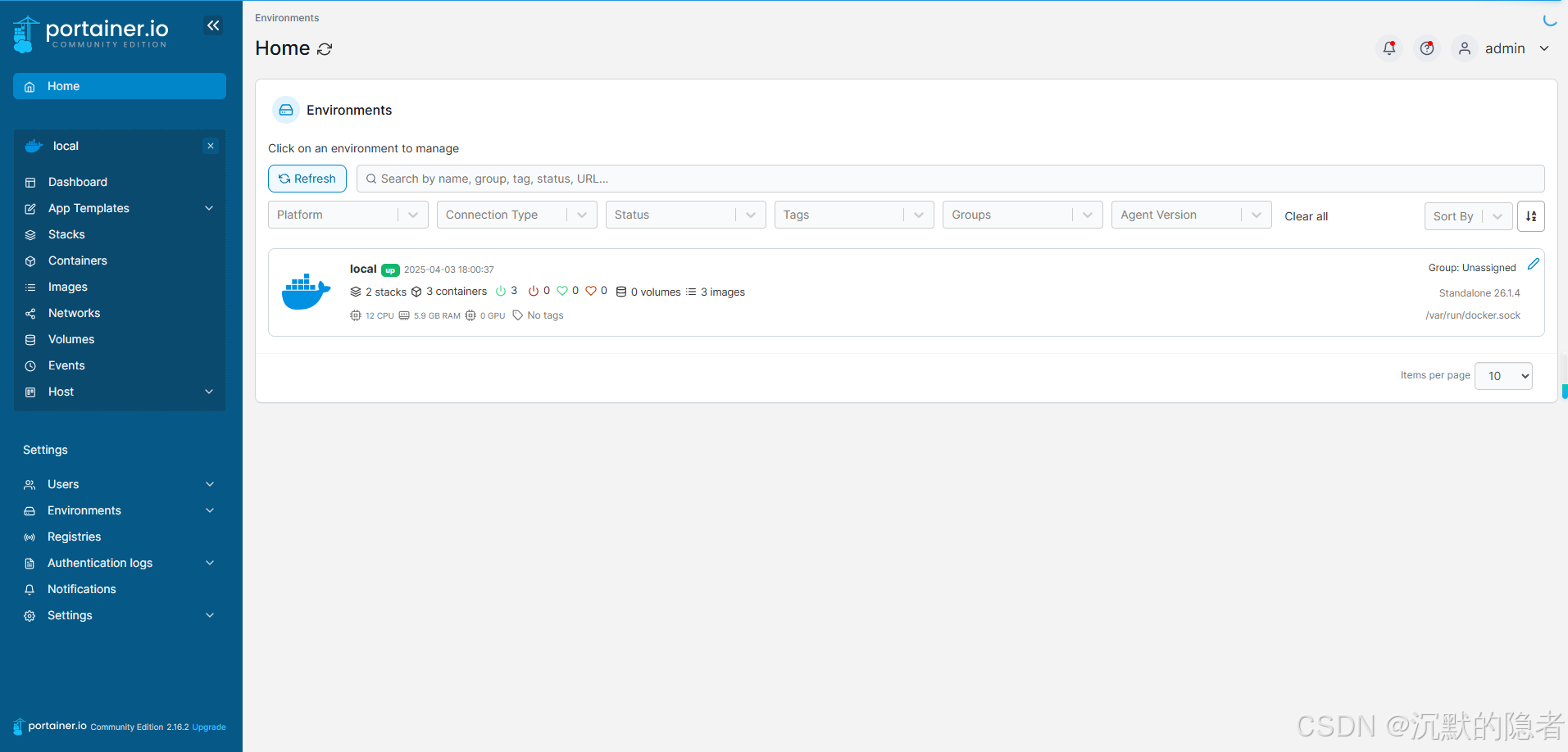
docker初始环境搭建(docker、Docker Compose、portainer)
docker、Docker Compose和portainer的安装部署、使用 docker、Docker Compose和portainer的安装部署、使用一.安装docker1.失败的做法2.首先卸载旧版本(没安装则下一步)3.配置下载的yum来源,不然yum search搜不到4.安装启动docker5.替换国内源…...
开源RuoYi AI助手平台的未来趋势
近年来,人工智能技术的迅猛发展已经深刻地改变了我们的生活和工作方式。 无论是海外的GPT、Claude等国际知名AI助手,还是国内的DeepSeek、Kimi、Qwen等本土化解决方案,都为用户提供了前所未有的便利。然而,对于那些希望构建属于自…...
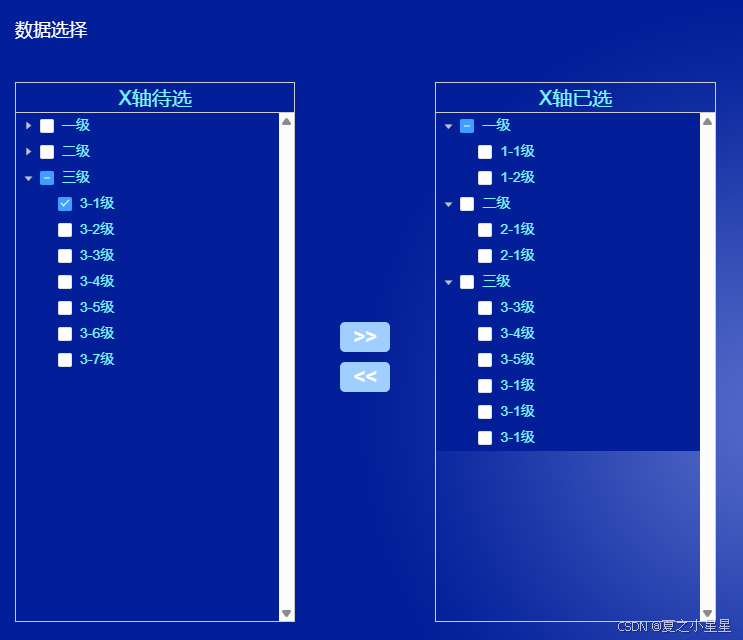
element-ui自制树形穿梭框
1、需求 由于业务特殊需求,想要element穿梭框功能,数据是二级树形结构,选中左边数据穿梭到右边后,左边数据不变。多次选中左边相同数据进行穿梭操作,右边数据会多次增加相同的数据。右边数据穿梭回左边时,…...

Linux系统学习Day04 阻塞特性,文件状态及文件夹查询
知识点4【文件的阻塞特性】 文件描述符 默认为 阻塞 的 比如:我们读取文件数据的时候,如果文件缓冲区没有数据,就需要等待数据的到来,这就是阻塞 当然写入的时候,如果发现缓冲区是满的,也需要等待刷新缓…...

Module模块化
导出:export关键字 export var color "red"; 重命名导出 在模块中使用as用导出名称表示本地名称。 import { add } from "./05-module-out.js"; 导入: import关键字 导入单个绑定 import { sum } from "./05-module-out.js&…...
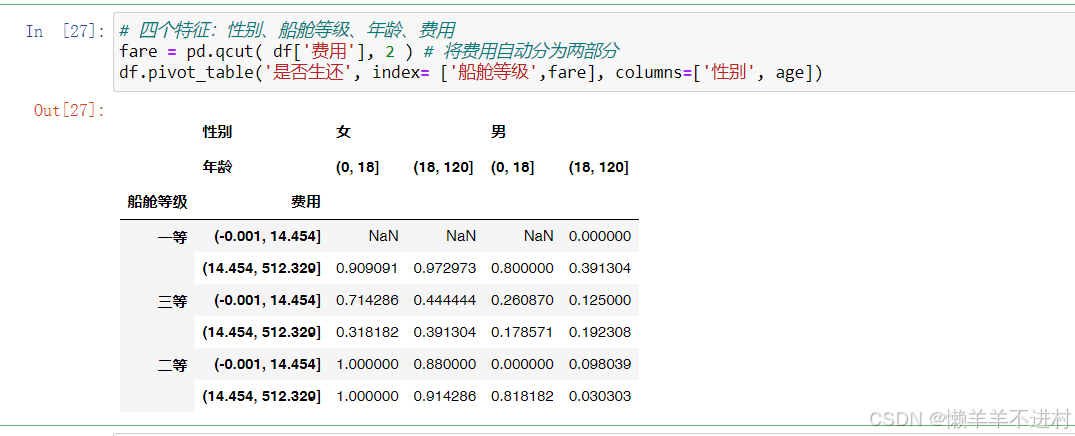
Python基础——Pandas库
对象的创建 导入 Pandas 时,通常给其一个别名“pd”,即 import pandas as pd。作为标签库,Pandas 对象在 NumPy 数组基础上给予其行列标签。可以说,列表之于字典,就如 NumPy 之于 Pandas。Pandas 中,所有数…...

C++: 类型转换
C: 类型转换 (一)C语言中的类型转换volatile关键字 修饰const变量 (二)C四种强制类型转换1. static_cast2. reinterpret_cast3. const_cast4. dynamic_cast总结 (三)RTTI (一)C语言中的类型转换 在C语言中…...
)
[ctfshow web入门] 零基础版题解 目录(持续更新中)
ctfshow web入门 零基础版 前言 我在刷题之前没有学过php,但是会python和C,也就是说,如果你和我一样会一门高级语言,就可以开始刷题了。我会以完全没学过php的视角来写题解,你也完全没有必要专门学习php,这…...

【蓝桥杯】动态规划:线性动态规划
1. 最长上升子序列(LIS) 1.1. 题目 想象你有一排数字,比如:3, 1, 2, 1, 8, 5, 6 你要从中挑出一些数字,这些数字要满足两个条件: 你挑的数字的顺序要和原来序列中的顺序一致(不能打乱顺序) 你挑的数字要一个比一个大(严格递增) 问:最多能挑出多少个这样的数字? …...
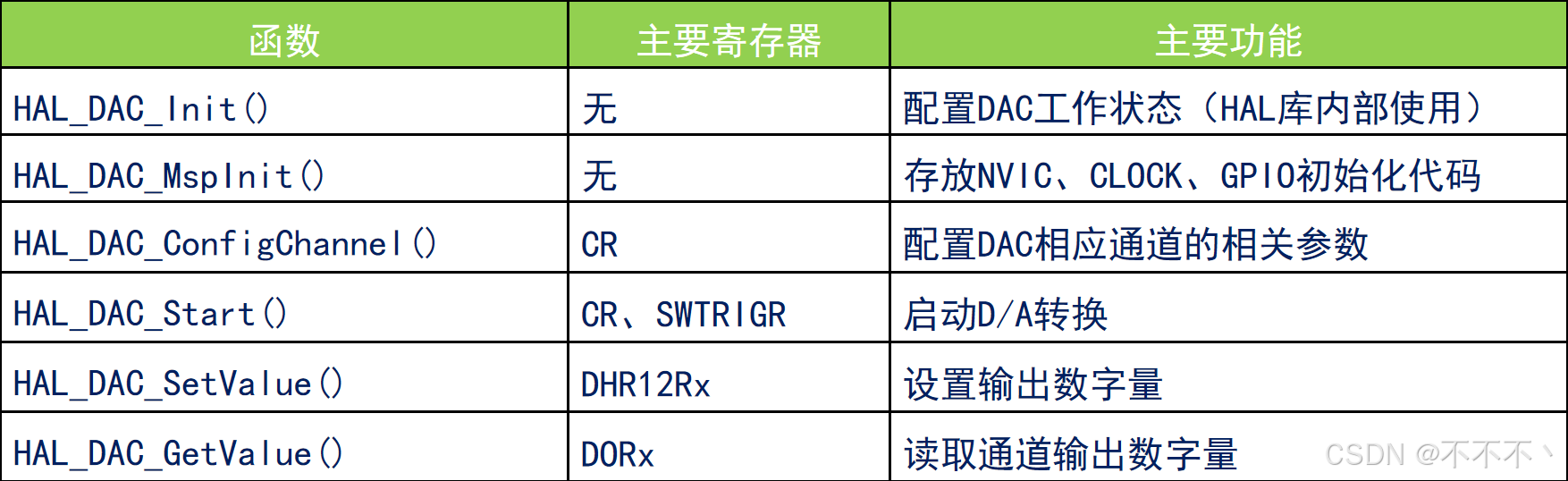
STM32——DAC转换
DAC简介 DAC,全称:Digital-to-Analog Converter,扑指数字/模拟转换器 ADC和DAC是模拟电路与数字电路之间的桥梁 DAC的特性参数 1.分辨率: 表示模拟电压的最小增量,常用二进制位数表示,比如:…...
Kafka的索引设计有什么亮点
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring Kafka的索引设计有什么亮点? Kafka 之所以能在海量数据的传输和处理过程中保持高…...

在深度学习中,如何统计模型的 FLOPs(浮点运算次数) 和 参数量(Params)
在深度学习中,统计模型的FLOPs(浮点运算次数)和参数量(Params)是评估模型复杂度和计算资源需求的重要步骤。 一、参数量(Params)计算 参数量指模型中所有可训练参数的总和,其计算与…...

智能手表该存什么音频和文本?场景化存储指南
文章目录 为什么需要“场景化存储”?智能手表的定位手机替代不了的场景碎片化的场景存储 音频篇:智能手表该存什么音乐和音频?运动场景通勤场景健康场景 文本篇:哪些文字信息值得放进手表?(部分情况可使用图…...

Linux之Shell脚本--命令提示的写法
原文网址:Linux之Shell脚本--命令提示的写法-CSDN博客 简介 本文介绍Linux的Shell脚本命令提示的写法。 场景描述 在写脚本时经常会忘记怎么使用,需要进行命令提示。比如:输入-h参数,能打印用法。 实例 新建文件:…...