大模型论文:Improving Language Understanding by Generative Pre-Training
大模型论文:Improving Language Understanding by Generative Pre-Training
OpenAI2018
文章地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
摘要
自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文档分类。尽管大量未标记的文本语料库丰富,但用于学习这些特定任务的标记数据很少,这使得判别训练模型难以充分执行。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行判别性微调,可以实现这些任务的巨大收益。与以前的方法相反,我们在微调期间利用任务感知输入转换来实现有效的传输,同时需要对模型体系结构进行最小的更改。我们在自然语言理解的广泛基准上证明了我们的方法的有效性。我们的通用任务不可知模型优于为每个任务使用专门设计的架构的判别训练模型,在研究的12个任务中的9个任务中显著提高了技术水平。例如,我们在常识性推理(故事完形测试)上实现了8.9%的绝对改进,在问题回答(RACE)上实现了5.7%的绝对改进,在文本蕴涵(MultiNLI)上实现了1.5%的绝对改进
文本蕴含(Textual Entailment) 是自然语言处理(NLP)中的一项核心任务,旨在判断一段文本(称为“前提”,Premise)是否能够逻辑上蕴含另一段文本(称为“假设”,Hypothesis)。其本质是分析两者之间的语义关系
模型背景
-
大多数深度学习方法需要大量的人工标记数据,在无监督的情况下学习良好的表示也可以显著提高性能,因此选择无监督的方式进行模型学习。但存在下列问题
-
首先,是因为不清楚要下游任务,所以也就没法针对性的进行行优化;
-
其次,就算知道了下游任务,如果每次都要大改模型也会得不偿失
-
-
本文提出的GPT框架探讨了使用无监督预训练和有监督微调相结合的方法来处理语言理解任务。目标是学习一个通用表示,它可以适应各种任务,而无需太多调整。本文假设可以访问大量未标记文本以及包含手动注释训练示例(目标任务)的几个数据集。本文的设置不要求这些目标任务与未标记语料库属于同一域
-
本文用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:Pre-training 和 Fine-tuning。目的是在于学习一种通用的文本表征方法,针对不同种类的任务只需略作修改便能适应
-
预训练模型:预训练具有类似正则化的作用,能让深度神经网络具有更好的泛化能力。正则化是防止过拟合的手段,预训练在这里被视为帮助模型不容易陷入训练集“记忆陷阱”的方法之一
模型框架及训练
- GPT 训练过程分为两个阶段:第一个阶段是 Pre-training 阶段,主要利用大型语料库完成非监督学习;第二阶段是 Fine-tuning,针对特定任务在相应数据集中进行监督学习,通过 Fine-tuning 技术来适配具体任务。下图为 GPT 的架构图:
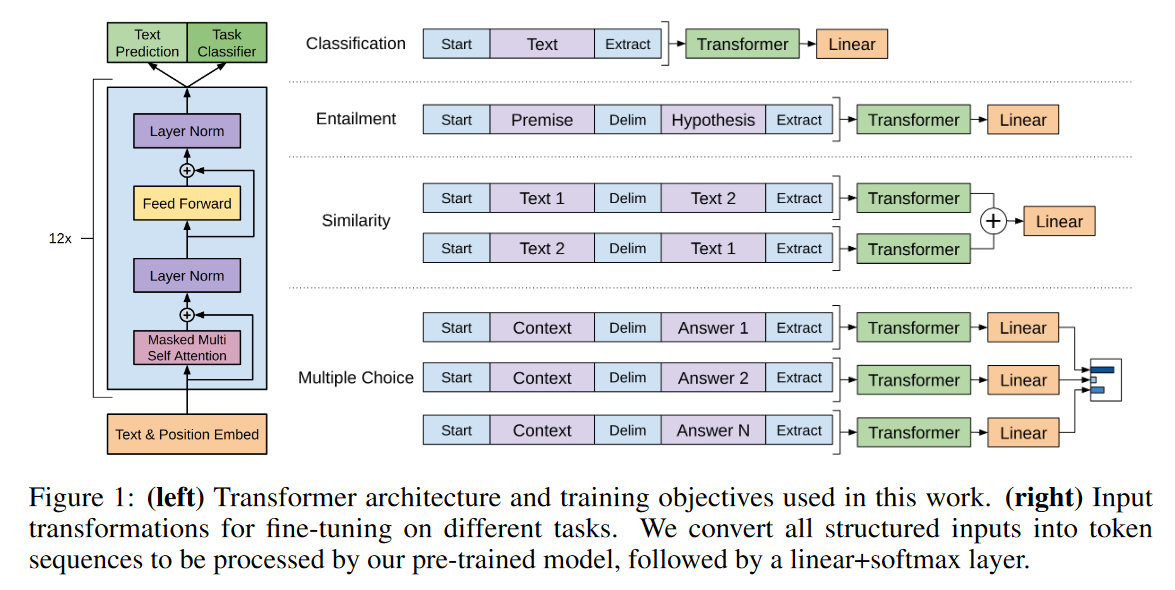
- 无监督预训练:给定一个无监督的令牌语料库 U = { u 1 , … , u n } U = {\{u_1,…,u_n}\} U={u1,…,un},本文使用标准的语言建模目标来最大化以下可能性:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(U) = \sum_i \log P(u_i | u_{i-k}, \dots, u_{i-1}; \Theta) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
- k k k是上下文窗口,本文使用多层的 Transformer 解码器作为语言模型,它是 Transformer 的一种变体。该模型对输入的上下文标记应用多头自注意力操作,然后在position-wise前馈层上生成目标令牌的输出分布:
h 0 = U W e + W p h_0 = U W_e + W_p h0=UWe+Wp
h l = transformer_block ( h l − 1 ) ∀ i ∈ [ 1 , n ] h_l = \text{transformer\_block}(h_{l-1}) \quad \forall i \in [1, n] hl=transformer_block(hl−1)∀i∈[1,n]
P ( u ) = softmax ( h n W e T ) P(u) = \text{softmax}(h_n W_e^T) P(u)=softmax(hnWeT)
-
有监督微调:在无监督训练后,本文使用有监督的方式对模型进行微调,个标注数据集 C C C,每个实例由一组输入token,$x^1, \dots, x^m 和标签 和标签 和标签y 组成,输入被传入预训练的模型,通过最后一个 T r a n s f o r m e r 块的激活 组成,输入被传入预训练的模型,通过最后一个Transformer块的激活 组成,输入被传入预训练的模型,通过最后一个Transformer块的激活h_l^m ,然后再输入到一个额外的线性输出层,该层带有参数 ,然后再输入到一个额外的线性输出层,该层带有参数 ,然后再输入到一个额外的线性输出层,该层带有参数 W_y 来预测 来预测 来预测 y$:
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P(y | x^1, \dots, x^m) = \text{softmax}(h_l^m W_y) P(y∣x1,…,xm)=softmax(hlmWy) -
优化目标为:
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , … , x m ) L_2(C) = \sum_{(x, y)} \log P(y | x^1, \dots, x^m) L2(C)=(x,y)∑logP(y∣x1,…,xm) -
本文还发现:将语言建模作为微调辅助目标,通过 (a) 改进监督模型的泛化,以及 (b) 加速收敛来帮助学习,优化目标为:
L 3 ( C ) = L 2 ( C ) + λ ⋅ L 1 ( C ) L_3(C) = L_2(C) + \lambda \cdot L_1(C) L3(C)=L2(C)+λ⋅L1(C) -
在微调期间所需的唯一额外参数是$W_y $和分隔符标记的嵌入
特定于任务的转换
-
对于一些任务,比如文本分类,可以像上述那样直接对模型进行微调。其他任务,如问答或文本蕴涵,具有结构化输入,如有序的句子对或文档、问题和答案的三元组。由于预训练模型是在连续的文本序列上训练的,因此需要对模型做一些修改才能应用到这些任务上
-
本文使用了一种遍历样式的方法,将结构化输入转换为预训练模型可以处理的有序序列。这些输入转换方法允许我们避免对架构做出大量的修改,从而在不同任务中共享架构。下面简要描述了这些输入转换,并且图1提供了一个视觉示意。所有的转换都包括添加随机初始化的开始和结束标记 < s > , < e > < s > , < e > < s > , < e > <s>,<e><s>, <e><s>,<e> <s>,<e><s>,<e><s>,<e>
-
文本蕴涵:对于蕴涵任务,我们将前提 p和假设 h的标记序列拼接,并在它们之间加上分隔符标记($)
-
相似性:对于相似性任务,两个句子之间没有固有的顺序。为此,我们修改输入序列,使其包含两个可能的句子顺序(并在它们之间添加分隔符),然后分别处理这两个序列,生成两个序列表示 h l m h_l^m hlm,这些表示在输入到线性输出层之前逐元素相加
-
问答和常识推理:对于这些任务,给定一个文档 z z z,一个问题 q q q,以及一组可能的答案$ {{a_k}}$。将文档上下文和问题拼接,并在它们之间添加分隔符标记,得到 $[z;q;$;a_k]$。每个序列会独立地被模型处理,然后通过softmax归一化,输出可能答案的概率分布。
-
总结:GPT 是一种半监督学习,采用两阶段任务模型,通过使用无监督的 Pre-training 和有监督的 Fine-tuning 来实现强大的自然语言理解。在 Pre-training 中采用了 12 层的修改过的 Transformer Decoder 结构,在 Fine-tuning 中会根据不同任务提出不同的分微调方式,从而达到适配各类 NLP 任务的目的
相关文章:
大模型论文:Improving Language Understanding by Generative Pre-Training
大模型论文:Improving Language Understanding by Generative Pre-Training OpenAI2018 文章地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf 摘要 自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文…...

SDL视频显示函数
文章目录 1. **`SDL_Init()`**2. **`SDL_CreateWindow()`**3. **`SDL_CreateRenderer()`**4. **`SDL_CreateTexture()`**5. **`SDL_UpdateTexture()`**6. **`SDL_RenderCopy()`**7. **`SDL_RenderPresent()`**8. **`SDL_Delay()`**9. **`SDL_Quit()`**总结示例代码:代码说明:…...

[ctfshow web入门] web18
前置知识 js(javascript)语言用于前台控制,不需要知道他的语法是什么,以高级语言的阅读方式也能看懂个大概。 在JavaScript中,confirm()是一个用于显示确认对话框的内置函数,不用知道怎么使用。 信息收集 提示:不要…...

基于 docker 的 Xinference 全流程部署指南
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 一、下载代码 请在控制台下面执行…...

Vue组件化开发深度解析:Element UI与Ant Design Vue对比实践
一、Vue组件化开发的核心优势 1.1 组件化架构的天然优势 Vue的组件系统是其最核心的特性之一,采用单文件组件(.vue)形式,将HTML、CSS和JavaScript组合在同一个文件中,形成高内聚、低耦合的代码单元。这种设计显著提升…...

SQL Server查询性能下降:执行计划不稳定与索引优化
问题现象: SQL Server 2022 中某些关键查询性能突然下降,执行时间从毫秒级增至数秒,日志中未报错,但查询计划显示低效的索引扫描或键查找。 快速诊断 捕获实际执行计划: -- 启用实际执行计划 SET STATISTICS XML, TIME…...
)
【学Rust写CAD】31 muldiv255函数(muldiv255.rs,已经取消)
源码 // Calculates floor(a*b/255 0.5) #[inline] pub fn muldiv255(a: u32, b: u32) -> u32 {// The deriviation for this formula can be// found in "Three Wrongs Make a Right" by Jim Blinn.let tmp a * b 128;(tmp (tmp >> 8)) >> 8 }代…...
`uia.WindowControl` 是什么:获取窗口文字是基于系统的 UI 自动化接口,而非 OCR 方式
uia.WindowControl 是什么:获取窗口文字是基于系统的 UI 自动化接口,而非 OCR 方式 uia.WindowControl 通常是基于 Windows 系统的 UI 自动化框架(如 pywinauto 中的 uia 模块)里用于表示窗口控件的类。在 Windows 操作系统中,每个应用程序的窗口都可以看作是一个控件,ui…...
vue3 处理文字 根据文字单独添加class
下面写的是根据后端返回的html 提取我需要的标签和字 将他们单独添加样式 后端返回的数据 大概类似于<h1>2024年“双11”购物节网络零售监测报告</h1><p>表1 “双11” 期间网络零售热销品类TOP10</p> function checkfun(newList){if (newList) {let …...

Python爬虫教程011:scrapy爬取当当网数据开启多条管道下载及下载多页数据
文章目录 3.6.4 开启多条管道下载3.6.5 下载多页数据3.6.6 完整项目下载3.6.4 开启多条管道下载 在pipelines.py中新建管道类(用来下载图书封面图片): # 多条管道开启 # 要在settings.py中开启管道 class DangdangDownloadPipeline:def process_item(self, item, spider):…...
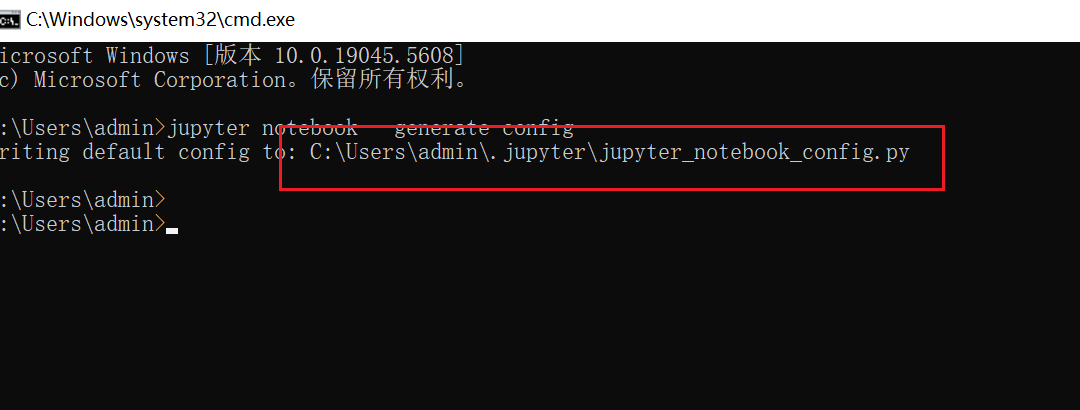
Jupyter Notebook不能自动打开默认浏览器怎么办?
在安装anaconda的过程中,部分用户可能会遇到,打开Jupyter Notebook的时候,不会弹出默认浏览器。本章教程给出解决办法。 一、生成一个jupyter默认配置文件 打开cmd,运行以下命令,会生成一个jupyter_notebook配置文件。 jupyter notebook --generate-config二、编辑jupyter_…...

VUE中数据绑定之OptionAPI
<template> <div> 姓名:<input v-model="userName" /> {{ userName }} <br /> 薪水:<input type="number" v-model="salary" /> <br /> <button v-on:click="submit">提交</button>…...

Spring Boot 工程创建详解
2025/4/2 向全栈工程师迈进! 一、SpingBoot工程文件的创建 点击Project Structure 然后按着如下点击 最后选择Spring Boot ,同时记得选择是Maven和jar,而不是war。因为Boot工程内置了Tomcat,所以不需要war。 紧接着选择Spring We…...
Spring Boot + MyBatis + Maven论坛内容管理系统源码
项目描述 xxxForum是一个基于Spring Boot MyBatis Maven开发的一个论坛内容管理系统,主要实现了的功能有: 前台页面展示数据、广告展示内容模块:发帖、评论、帖子分类、分页、回帖统计、访问统计、表单验证用户模块:权限、资料…...

国网B接口协议资源上报流程详解以及上报失败原因(电网B接口)
文章目录 一、B接口协议资源上报接口介绍B.2.1 接口描述B.2.2 接口流程B.2.3 接口参数B.2.3.1 SIP头字段B.2.3.2 SIP响应码B.2.3.3 XML Schema参数定义 B.2.4 消息示例B.2.4.1 上报前端系统的资源B.2.4.2 响应消息 二、B接口资源上报失败常见问题(一)证书…...
布谷一对一直播源码android版环境配置流程及功能明细
一:举例布谷交友(一对一直播源码)搭建部署的基本环境说明 1. 首先安装Center OS 7.9系统,硬盘最低 40G 2. 安装宝塔环境 https://bt.cn(强烈推荐使用) 3. 安装环境 ● PHP 7.3(安装redis扩展…...

TypeScript 类型系统详解
基础类型 TypeScript 支持丰富的基础数据类型,涵盖number、string、boolean、null、undefined、symbol以及bigint。这些类型为构建可靠的代码提供了基石。 数值类型(number):在 TypeScript 里,所有数字均为浮点数…...

SDL多线程编程
文章目录 1. SDL 线程基础2. 线程同步3. 线程池4. 注意事项5. 示例:在多个线程中进行图形渲染和输入处理总结在 SDL(Simple DirectMedia Layer)中,多线程编程通常用于提高应用程序的响应性和性能,尤其是在需要同时处理多个任务的场景中,例如渲染、输入处理和音频等。SDL …...
【Netty4核心原理④】【简单实现 Tomcat 和 RPC框架功能】
文章目录 一、前言二、 基于 Netty 实现 Tomcat1. 基于传统 IO 重构 Tomcat1.1 创建 MyRequest 和 MyReponse 对象1.2 构建一个基础的 Servlet1.3 创建用户业务代码1.4 完成web.properties 配置1.5 创建 Tomcat 启动类 2. 基于 Netty 重构 Tomcat2.1 创建 NettyRequest和 Netty…...

C#语言的饼图
C#语言中的饼图:数据可视化的艺术 在现代软件开发中,数据可视化是一个不可或缺的重要环节。随着数据量的不断增加,仅仅依靠文本和表格来展示数据已显得不够直观。本文将以C#语言为基础,探讨如何使用C#绘制饼图,并进一…...
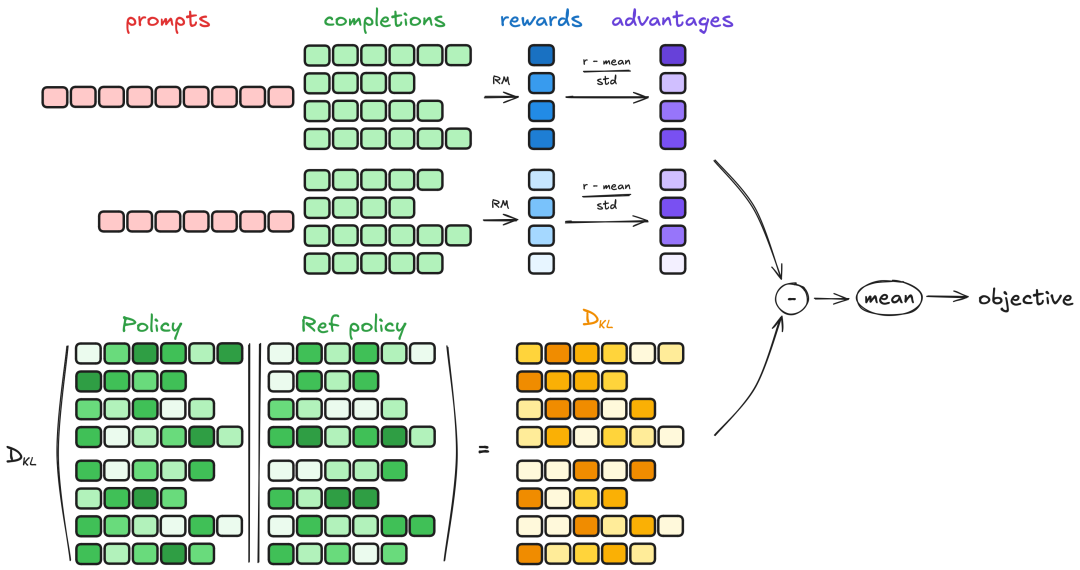
【AI学习】初步了解TRL
TRL(Transformer Reinforcement Learning) 是由 Hugging Face 开发的一套基于强化学习(Reinforcement Learning, RL)的训练工具,专门用于优化和微调大规模语言模型(如 GPT、LLaMA 等)。它结合了…...

打破界限:Android XML与Jetpack Compose深度互操作指南
在现有XML布局项目中逐步引入Jetpack Compose是现代Android开发的常见需求。本指南将全面介绍混合使用的最佳实践、技术细节和完整解决方案。 一、基础配置 1.1 Gradle配置 android {buildFeatures {compose true}composeOptions {kotlinCompilerExtensionVersion "1.5.3…...

ADASH VA5 Pro中的route功能
这段内容详细介绍了 ADASH VA5 Pro 设备中“Route(路线)”模块的功能、操作流程以及相关特性。以下是对这段内容的总结和分析: Route 模块的主要功能 路线测量:Route 模块用于执行路线测量任务。它允许用户创建和管理一系列测量…...
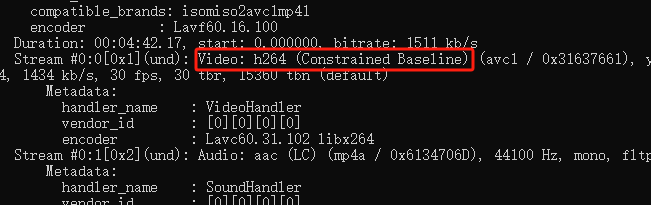
阿里云oss视频苹果端无法播放问题记录
记录一下苹果端视频不可以播放的原因. 看了一下其他视频可以正常播放,但是今天客户发来的视频无法正常播放.咨询过阿里云售后给出的原因是编码格式过高. 需要调整编码格式为:baseline, 下面记录如何使用ffmpeg修改视频的编码格式. 下载文件(可从官方下载) 配置环境变量(系统变…...

网络安全的现状与防护措施
随着数字化和信息化的迅猛发展,互联网已成为人们日常生活、工作和学习不可或缺的一部分。然而,随着网络技术的普及,网络安全问题也日益突出。近年来,数据泄露、恶意软件、网络攻击等事件层出不穷,给企业和个人带来了巨…...

Ubuntu离线安装mysql
在 Ubuntu 24.04 上离线安装 MySQL 的步骤如下(支持 MySQL 8.0 或 8.4): 一.安装方法 此次安装是按照方法一安装,其它方法供参考: 安装成功截图: 安全配置截图: sudo mysql_secure_installation 登录测试: 方法一:使用 apt-rdepends 下载依赖包(推荐) 1. 在联网…...

移动通信网络中漫游机制深度解析:归属网络与拜访网络的协同逻辑
文章目录 一、漫游基础概念与网络架构1.1 漫游的核心定义1.2 关键网络实体角色 二、漫入漫出详细流程解析2.1 漫出(Outbound Roaming)场景2.2 漫入(Inbound Roaming)场景 三、归属网络与拜访网络的信任演进3.1 各代网络的信任模型…...
IntelliJ IDEA下开发FPGA——FPGA开发体验提升__上
前言 由于Quartus写代码比较费劲,虽然新版已经有了代码补全,但体验上还有所欠缺。于是使用VS Code开发,效果如下所示,代码样式和基本的代码补全已经可以满足开发,其余工作则交由Quartus完成 但VS Code的自带的git功能&…...
-张量形状操作)
PyTorch使用(6)-张量形状操作
文章目录 1. reshape函数1.1. 功能与用法1.2. 特点 2. transpose和permute函数2.1. transpose2.2. permute2.3. 区别 3. view和contiguous函数3.1. view3.2. contiguous3.3. 特点 4. squeeze和unsqueeze函数4.1. squeeze4.2. unsqueeze 5. 应用场景6. 形状操作综合比较7. 最佳实…...

SpringBoot底层-数据源自动配置类
SpringBoot默认使用Hikari连接池,当我们想要切换成Druid连接池,底层原理是怎样呢 SpringBoot默认连接池——Hikari 在spring-boot-autoconfiguration包内有一个DataSourceConfiguraion配置类 abstract class DataSourceConfiguration {Configuration(p…...