面试算法高频01
题目描述 验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
示例 1:
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false
import redef isPalindrome(s: str) -> bool:left, right = 0, len(s) - 1while left < right:# Move left pointer to the next alphanumeric characterwhile left < right and not s[left].isalnum():left += 1# Move right pointer to the previous alphanumeric characterwhile left < right and not s[right].isalnum():right -= 1# Compare characters in a case-insensitive mannerif s[left].lower() != s[right].lower():return Falseleft += 1right -= 1return True# Test cases
print(isPalindrome("A man, a plan, a canal: Panama")) # True
print(isPalindrome("race a car")) # False
print(isPalindrome("")) # True
print(isPalindrome("a")) # True# 测试用例
print(isPalindrome("A man, a plan, a canal: Panama")) # True
print(isPalindrome("race a car")) # False
print(isPalindrome("")) # True
print(isPalindrome("a")) # True
True
False
True
True
True
False
True
True
单向链表 vs 双向链表
1. 结构
-
单向链表
- 每个节点包含:
value(数据)和next(指向下一个节点的指针)。 - 头节点(
head)指向第一个节点,尾节点的next为null。 - 示例:
Head → Node1 → Node2 → Node3 → null
- 每个节点包含:
-
双向链表
- 每个节点包含:
value、next(下一个节点)和prev(前一个节点的指针)。 - 头节点的
prev为null,尾节点的next为null。 - 示例:
null ← Node1 ↔ Node2 ↔ Node3 → null
- 每个节点包含:
2. 核心操作
| 操作 | 单向链表实现 | 双向链表实现 |
|---|---|---|
| 查找节点 | 需从头节点遍历至目标节点(时间复杂度 O(n))。 | 若已知位置或节点,可双向遍历优化(时间复杂度 O(n),但实际效率可能更高)。 |
| 插入节点 | - 头部插入:直接修改头指针(O(1))。 - 中间/尾部插入:需遍历找到位置(O(n))。 | - 头部/尾部插入:直接修改头尾指针(O(1))。 - 中间插入:通过 prev 指针快速定位(O(1))。 |
| 删除节点 | - 头部删除:直接修改头指针(O(1))。 - 中间/尾部删除:需遍历找到前驱节点(O(n))。 | - 任意位置删除:通过 prev 和 next 指针直接修改前后节点连接(O(1))。 |
3. 时间复杂度对比
| 操作 | 单向链表 | 双向链表 |
|---|---|---|
| Prepend | O(1) | O(1) |
| Append | O(1)(若有尾指针) | O(1) |
| Lookup | O(n) | O(n) |
| Insert | O(n)(中间) | O(1)(已知位置) |
| Delete | O(n)(中间) | O(1)(已知位置) |
4. 空间复杂度
- 单向链表:每个节点存储
value和next,空间复杂度 O(n)。 - 双向链表:每个节点额外存储
prev,空间复杂度 O(n)(比单向链表多一个指针)。
5. 应用场景
-
单向链表:
- 简单场景(如栈、队列)。
- 节省空间(若不需要反向遍历)。
-
双向链表:
- 需要频繁插入/删除中间节点的场景(如 LRU 缓存)。
- 需要快速反向遍历的场景(如双向队列)。
6. 优缺点总结
| 类型 | 优点 | 缺点 |
|---|---|---|
| 单向链表 | 实现简单,节省内存。 | 中间操作效率低,无法反向遍历。 |
| 双向链表 | 中间操作高效(O(1)),支持双向遍历。 | 实现复杂,内存占用更高。 |
7. 工程中的应用
- 单向链表:Java 的
LinkedList(底层为双向链表,但可模拟单向操作)、简单数据结构实现。 - 双向链表:Java 的
LinkedList、Redis 的字典(结合哈希表)、LRU 缓存(与哈希表结合)。
跳表 vs 链表(单向/双向)对比
1. 数据结构特点
| 维度 | 跳表 | 链表(单向/双向) |
|---|---|---|
| 结构 | 多层索引 + 原始链表(分层跳跃结构)。 | 单层线性结构(单向仅向后,双向可前后)。 |
| 节点指针 | 每个节点包含多个层级的指针数组(forward)。 | 单向链表:1个指针(next);双向链表:2个指针(next和prev)。 |
| 有序性 | 天然有序(基于索引层级和节点值)。 | 无序(需额外排序逻辑)。 |
2. 时间复杂度对比
| 操作 | 跳表 | 单向链表 | 双向链表 |
|---|---|---|---|
| 查找 | O(logn) | O(n) | O(n) |
| 插入 | O(logn) | O(n)(中间) | O(1)(已知位置) |
| 删除 | O(logn) | O(n)(中间) | O(1)(已知位置) |
| 范围查询 | O(logn + k)(k为结果数) | 不支持直接范围查询 | 不支持直接范围查询 |
3. 空间复杂度
| 结构 | 跳表 | 单向链表 | 双向链表 |
|---|---|---|---|
| 平均 | O(n)(每个节点平均2层) | O(n) | O(n) |
| 最坏 | O(n)(所有节点1层) | O(n) | O(n) |
| 额外开销 | 索引层级的指针数组 | 无 | 多1个prev指针 |
4. 核心优势
| 跳表 | 链表(单向/双向) |
|---|---|
| 支持快速查找、插入、删除(O(logn))。 | 实现简单,空间占用低。 |
| 天然有序,支持高效范围查询。 | 双向链表支持O(1)时间插入/删除已知节点。 |
| 适合高并发场景(锁粒度更细)。 | 单向链表适合栈、队列等简单场景。 |
5. 典型应用场景
| 跳表 | 链表(单向/双向) |
|---|---|
| Redis有序集合、LevelDB索引。 | 单向链表:栈、简单队列、哈希冲突链。 |
| 内存数据库、搜索引擎的倒排索引。 | 双向链表:LRU缓存、双向队列。 |
| 需要快速范围查询的场景(如排行榜)。 | 不需要复杂操作的场景。 |
6. 对比总结
| 维度 | 跳表 | 链表 |
|---|---|---|
| 效率 | 查找/插入/删除均为O(logn),适合大规模数据。 | 单向链表:O(n)操作;双向链表:部分操作O(1),但整体仍受限于线性结构。 |
| 空间 | 更高(需存储索引)。 | 更低(单向无额外空间,双向多1指针)。 |
| 有序性 | 自动维护有序性。 | 无序,需手动排序。 |
| 实现难度 | 中等(需处理多层索引和随机层数)。 | 简单(单向)或中等(双向)。 |
| 并发性能 | 高(锁粒度细,适合多线程)。 | 低(需全局锁或复杂同步机制)。 |
7. 如何选择?
-
选跳表:
- 数据量大且需要快速增删查。
- 需要范围查询或有序性。
- 高并发场景(如Redis)。
-
选链表:
- 数据量小,操作简单。
- 空间敏感,不需要高效查询。
- 特定场景(如LRU缓存结合哈希表)。
总结:跳表通过分层索引和空间换时间策略,在链表的基础上实现了高效操作,适用于对性能要求较高的有序数据管理;链表则更适合轻量级、无序或简单操作的场景。
题目描述
设计一个LRU(最近最少使用)缓存机制,支持以下操作:
get(key):如果key存在于缓存中,返回其对应的值,并将该key标记为最近使用;否则返回-1。put(key, value):如果key已存在,更新其值并标记为最近使用;如果不存在且缓存未满,添加新键值对;如果缓存已满,删除最久未使用的key后再添加新键值对。
要求:所有操作的时间复杂度均为O(1)。
Python 实现思路
我们采用 哈希表(字典)+ 双向链表 的组合实现:
- 哈希表:快速查找键是否存在,时间复杂度为O(1)。
- 双向链表:维护元素的访问顺序,便于在O(1)时间内插入、删除和移动节点。
关键操作:
- get(key):若键存在,将对应节点移动到链表头部(表示最近使用),并返回值。
- put(key, value):若键存在,更新值并移动到头部;若不存在,创建新节点。若容量已满,删除链表尾部节点(最久未使用)。
Python 代码
class LRUCache:class Node:def __init__(self, key, value):self.key = keyself.value = valueself.prev = Noneself.next = Nonedef __init__(self, capacity: int):self.capacity = capacityself.map = {} # 哈希表存储键到节点的映射self.head = self.Node(-1, -1) # 虚拟头节点self.tail = self.Node(-1, -1) # 虚拟尾节点self.head.next = self.tailself.tail.prev = self.headself.size = 0def get(self, key: int) -> int:if key not in self.map:return -1node = self.map[key]self._move_to_head(node)return node.valuedef put(self, key: int, value: int) -> None:if key in self.map:node = self.map[key]node.value = valueself._move_to_head(node)returnnew_node = self.Node(key, value)self.map[key] = new_nodeself._add_to_head(new_node)self.size += 1if self.size > self.capacity:removed_node = self._remove_tail()del self.map[removed_node.key]self.size -= 1def _move_to_head(self, node: Node) -> None:self._remove_node(node)self._add_to_head(node)def _add_to_head(self, node: Node) -> None:node.prev = self.headnode.next = self.head.nextself.head.next.prev = nodeself.head.next = nodedef _remove_node(self, node: Node) -> None:prev_node = node.prevnext_node = node.nextprev_node.next = next_nodenext_node.prev = prev_nodedef _remove_tail(self) -> Node:tail_node = self.tail.prevself._remove_node(tail_node)return tail_node
代码解释
- Node 类:双向链表节点,包含键、值、前驱和后继指针。
- LRUCache 类:
map:哈希表存储键到节点的映射。head和tail:虚拟头节点和尾节点,简化边界条件处理。capacity和size:缓存容量和当前元素数量。
- get 方法:检查键是否存在,存在则移动到头部并返回值。
- put 方法:处理键存在或不存在的情况,维护链表顺序和容量限制。
- 辅助方法:
_move_to_head:将节点移动到链表头部。_add_to_head:将节点插入头部。_remove_node:从链表中删除节点。_remove_tail:删除链表尾部节点(最久未使用)。
复杂度分析:
- 时间复杂度:所有操作均为O(1),因为哈希表查找和链表操作均为常数时间。
- 空间复杂度:O(n),其中n为缓存容量,存储所有键值对。
题目复述
盛最多水的容器
给定一个长度为 n 的整数数组 height,其中每个元素表示坐标 i 处的柱子高度。选择两个柱子,与它们之间的区域形成一个容器,求能容纳最多水的容器的最大面积。
示例
输入:height = [1,8,6,2,5,4,8,3,7]
输出:49
解释:选择索引 1 和 8(高度分别为 8 和 7),容器面积为 (8-1) * min(8,7) = 7*7=49。
最优解思路
双指针法
- 初始条件:使用左右两个指针分别指向数组的首尾。
- 移动规则:每次移动较短的一边的指针,因为较短的一边决定了当前容器的高度,移动较长的一边无法增加面积。
- 维护最大面积:每次计算当前容器的面积,并更新最大值。
关键逻辑:
- 面积由两柱子的间距和较小高度决定。
- 移动较短的指针可以尝试寻找更高的柱子,从而可能增大面积。
Python 代码实现
class Solution:def maxArea(self, height: List[int]) -> int:max_area = 0left = 0right = len(height) - 1while left < right:# 计算当前面积current_area = (right - left) * min(height[left], height[right])max_area = max(max_area, current_area)# 移动较短的指针if height[left] < height[right]:left += 1else:right -= 1return max_area
代码解释
- 初始化:
left指针指向数组开头,right指针指向数组末尾,max_area初始化为 0。 - 循环条件:当
left < right时继续循环。 - 计算当前面积:两指针间距乘以较小高度。
- 更新最大面积:比较当前面积与
max_area,取较大值。 - 移动指针:若左边高度小于右边,则左指针右移;否则右指针左移。
复杂度分析
- 时间复杂度:O(n),每个元素最多被访问一次。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 双指针法:通过贪心策略避免暴力枚举,线性时间内找到最优解。
- 移动规则:每次移动较短的指针,确保可能找到更高的柱子。
- 正确性:虽然跳过了部分情况,但最优解一定在移动路径中被覆盖。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目描述
移动零
给定一个数组 nums,将所有的 0 移动到数组的末尾,同时保持非零元素的相对顺序。要求在原数组上操作,不能拷贝额外的数组,且尽量减少操作次数。
示例
输入:nums = [0, 1, 0, 3, 12]
输出:[1, 3, 12, 0, 0]
最优解思路
双指针法
- 初始化指针:使用指针
j记录当前非零元素应放置的位置。 - 遍历数组:用指针
i遍历数组,若nums[i]非零,则将其移动到j的位置,并递增j。 - 填充零:遍历结束后,将
j到数组末尾的所有位置填充为 0。
关键逻辑:
- 非零元素按顺序移动到数组前半部分,零元素自动留在后半部分。
- 仅需两次遍历(一次处理非零元素,一次填充零),时间复杂度为 O(n)。
Python 代码实现
class Solution:def moveZeroes(self, nums: List[int]) -> None:j = 0 # 记录非零元素的位置for i in range(len(nums)):if nums[i] != 0:nums[j] = nums[i]j += 1# 将剩余位置填充为 0while j < len(nums):nums[j] = 0j += 1
代码解释
- 初始化指针
j:从数组开头开始记录非零元素的位置。 - 遍历数组
i:- 若
nums[i]非零,将其赋值给nums[j],并递增j。
- 若
- 填充零:遍历结束后,
j指向第一个需要填充零的位置,将剩余位置全部置零。
复杂度分析
- 时间复杂度:O(n),每个元素最多被访问两次(一次非零处理,一次填充零)。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 双指针法:通过
j指针记录非零元素的位置,确保非零元素按顺序排列。 - 原地操作:直接修改原数组,避免额外空间开销。
- 高效性:仅需两次遍历,满足题目要求的最少操作次数。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目描述
爬楼梯
假设你正在爬楼梯,需要 n 阶才能到达顶部。每次你可以爬 1 或 2 步。问有多少种不同的方法可以爬到楼顶?
示例
输入:n = 3
输出:3
解释:有三种方法:1+1+1,1+2,2+1。
最优解思路
动态规划 + 空间优化
- 问题分析:到达第
n阶的方法数等于到达第n-1阶和第n-2阶的方法数之和(最后一步为 1 步或 2 步)。 - 状态定义:
a表示到达第n-2阶的方法数。b表示到达第n-1阶的方法数。
- 状态转移:
c = a + b(到达第n阶的方法数)。
- 优化:仅用两个变量存储前两个状态,避免使用数组,空间复杂度优化为 O(1)。
Python 代码实现
class Solution:def climbStairs(self, n: int) -> int:if n == 0:return 1a, b = 1, 1 # a对应n-2,b对应n-1for _ in range(n - 1):c = a + ba, b = b, creturn b
代码解释
- 处理边界条件:当
n=0时,返回 1(不爬楼梯也算一种方法)。 - 初始化变量:
a和b分别初始化为 1(对应n=0和n=1的情况)。 - 循环计算:通过
n-1次迭代,逐步更新a和b,最终b即为到达第n阶的方法数。
复杂度分析
- 时间复杂度:O(n),仅需一次线性遍历。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 动态规划:将问题分解为子问题,利用前两阶的结果推导当前阶的结果。
- 空间优化:避免存储整个数组,仅用两个变量交替更新状态。
- 正确性:该解法等价于斐波那契数列,但初始条件不同(斐波那契数列从
F(0)=0开始,而本题从F(0)=1开始)。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目描述
三数之和
给定一个包含 n 个整数的数组 nums,找出所有不重复的三元组 (nums[i], nums[j], nums[k]),使得 i、j、k 互不相同,且这三个数的和为 0。需返回所有符合条件且不重复的三元组。
示例
输入:nums = [-1, 0, 1, 2, -1, -4]
输出:[[-1, -1, 2], [-1, 0, 1]]
解释:两个符合条件的三元组,且无重复。
最优解思路
排序 + 双指针法
- 排序数组:方便后续双指针操作和去重。
- 固定第一个数:遍历数组,固定
nums[i],将问题转化为在剩余元素中寻找两数之和为-nums[i]。 - 双指针法:在
i之后的元素中使用左右指针left和right,通过移动指针找到满足条件的两数。 - 去重:跳过重复元素,避免生成重复的三元组。
关键逻辑:
- 排序后,相同元素相邻,便于跳过重复。
- 双指针法将时间复杂度优化至 O(n²)。
Python 代码实现
from typing import Listclass Solution:def threeSum(self, nums: List[int]) -> List[List[int]]:nums.sort()n = len(nums)res = []for i in range(n):# 若当前数大于0,后续不可能有解,直接breakif nums[i] > 0:break# 跳过重复的nums[i]if i > 0 and nums[i] == nums[i-1]:continueleft = i + 1right = n - 1while left < right:total = nums[i] + nums[left] + nums[right]if total == 0:res.append([nums[i], nums[left], nums[right]])# 跳过重复的nums[left]while left < right and nums[left] == nums[left + 1]:left += 1# 跳过重复的nums[right]while left < right and nums[right] == nums[right - 1]:right -= 1# 移动指针继续寻找left += 1right -= 1elif total < 0:left += 1else:right -= 1return res
代码解释
- 排序数组:
nums.sort()将数组排序,方便后续操作。 - 遍历固定第一个数:
- 若
nums[i] > 0,直接终止循环,因为后续元素更大,无法满足和为 0。 - 若
nums[i]与前一个元素相同,跳过以避免重复。
- 若
- 双指针法寻找两数:
- 计算当前三数之和
total。 - 若
total == 0,将三元组加入结果,并跳过重复的nums[left]和nums[right]。 - 若
total < 0,左指针右移以增大和;若total > 0,右指针左移以减小和。
- 计算当前三数之和
复杂度分析
- 时间复杂度:O(n²),排序 O(n logn),双指针遍历 O(n²),总体为 O(n²)。
- 空间复杂度:O(1) 或 O(n)(取决于排序实现,Python 的
sort()使用 O(logn) 栈空间)。
关键点总结
- 排序优化:将数组排序后,便于双指针操作和去重。
- 双指针法:通过左右指针的移动,线性时间内找到两数之和为目标值。
- 去重逻辑:跳过重复元素,确保结果无重复三元组。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目复述
反转链表:给定单链表的头节点 head,反转该链表并返回反转后链表的头节点。例如,输入 1 -> 2 -> 3 -> 4 -> 5,输出应为 5 -> 4 -> 3 -> 2 -> 1。
解法思路
采用 迭代法:
- 利用三个指针
prev(前一个节点,初始为None)、current(当前节点,初始为head)、next(记录当前节点的下一个节点)。 - 循环中,将
current的next指向prev,然后prev和current向前移动,直到current为空。此时prev即为反转后链表的头节点。
代码实现
from typing import Optional# 定义链表节点类
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass Solution:def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:prev = Nonecurrent = headwhile current:next_node = current.next # 保存下一个节点current.next = prev # 反转指针prev = current # 前指针后移current = next_node # 当前指针后移return prev
代码解释
- 初始化:
prev设为None,current设为head。 - 循环:
next_node = current.next:保存当前节点的下一个节点,避免丢失。current.next = prev:将当前节点的next指向前一个节点,实现反转。prev = current和current = next_node:prev和current依次后移。
- 返回:循环结束后,
prev即为反转后链表的头节点。
该方法时间复杂度为 ( O(n) )(遍历链表一次),空间复杂度为 ( O(1) )(仅用常数额外空间),是反转链表的经典高效解法。
题目复述
两两交换链表中的节点:给定一个链表的头节点 head,将链表中相邻的节点两两交换,并返回交换后链表的头节点。例如,输入链表 1 -> 2 -> 3 -> 4,输出应为 2 -> 1 -> 4 -> 3。
解法思路
采用 迭代法,利用虚拟头节点简化边界处理:
- 初始化虚拟头节点:
dummy = ListNode(0, head),方便统一处理链表开头的交换。 - 定义指针
prev:prev始终指向当前要交换的两个节点的前一个节点。 - 循环交换:当
prev.next和prev.next.next都存在时,交换这两个节点:- 保存第一个节点
first = prev.next,第二个节点second = first.next。 - 调整指针:
prev.next = second,first.next = second.next,second.next = first。 prev移动到first的位置,继续下一轮交换。
- 保存第一个节点
代码实现
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass Solution:def swapPairs(self, head: ListNode) -> ListNode:dummy = ListNode(0, head) # 虚拟头节点prev = dummywhile prev.next and prev.next.next: # 还有两个节点可交换first = prev.nextsecond = first.next# 调整指针完成交换prev.next = secondfirst.next = second.nextsecond.next = firstprev = first # 移动prev到下一对的前一个位置return dummy.next # 返回交换后的头节点
代码解释
- 虚拟头节点
dummy:避免特殊处理头节点交换,统一操作逻辑。 - 循环条件:
prev.next和prev.next.next存在时,说明还有相邻节点对可交换。 - 指针调整:
prev.next = second:将prev的后续指向第二个节点。first.next = second.next:第一个节点的后续指向原第二个节点的后续(即下一对节点或None)。second.next = first:第二个节点的后续指向第一个节点,完成两两交换。
- 返回结果:
dummy.next为交换后的链表头节点。
该方法时间复杂度为 ( O(n) )(遍历链表一次),空间复杂度为 ( O(1) )(仅用常数额外空间),是解决本题的高效方法。
题目描述
环形链表:给定一个链表的头节点 head,判断链表中是否存在环。如果存在环,返回 True;否则,返回 False。
解法思路
采用 快慢指针法:
- 慢指针
slow每次移动一步,快指针fast每次移动两步。 - 若链表有环,快指针会在环内追上慢指针(即
slow == fast);若链表无环,快指针会先到达链表末尾(fast或fast.next为None)。
代码实现
class ListNode:def __init__(self, x):self.val = xself.next = Noneclass Solution:def hasCycle(self, head: ListNode) -> bool:if not head:return Falseslow = headfast = headwhile fast and fast.next:slow = slow.nextfast = fast.next.nextif slow == fast:return Truereturn False
代码解释
- 特殊情况处理:若
head为None,直接返回False(无环)。 - 初始化指针:
slow和fast均指向head。 - 循环判断:
- 每次循环中,
slow移动一步(slow = slow.next),fast移动两步(fast = fast.next.next)。 - 若
slow == fast,说明两指针相遇,链表有环,返回True。
- 每次循环中,
- 循环结束:若
fast或fast.next为None,说明链表无环,返回False。
该方法时间复杂度为 ( O(n) )(( n ) 为链表节点数,快指针最多遍历 ( O(n) ) 步),空间复杂度为 ( O(1) )(仅用常数额外空间),是判断链表是否有环的经典高效解法。
题目描述
环形链表 II:给定一个链表的头节点 head,返回链表开始入环的第一个节点。如果链表无环,则返回 null。
示例
输入:head = [3,2,0,-4],环在节点 2 处闭合
输出:返回节点 2
最优解思路
快慢指针法 + 数学推导
- 判断是否有环:使用快慢指针找到相遇点。
- 确定环入口:从链表头和相遇点同时出发,每次移动一步,最终相遇点即为环入口。
数学推导:
- 设链表头到环入口的距离为
F,环周长为C,相遇点到环入口的距离为a。 - 快慢指针相遇时,慢指针移动距离为
F + a,快指针移动距离为F + a + nC(n为快指针绕环圈数)。 - 因快指针速度是慢指针的 2 倍,有
F + a + nC = 2(F + a),化简得F = nC - a。 - 此时从链表头和相遇点出发的指针各移动
F步后,必然在环入口相遇。
Python 代码实现
class ListNode:def __init__(self, x):self.val = xself.next = Noneclass Solution:def detectCycle(self, head: ListNode) -> ListNode:# 步骤一:判断是否存在环slow = fast = headwhile fast and fast.next:slow = slow.nextfast = fast.next.nextif slow == fast:breakelse:return None # 无环# 步骤二:找到环入口ptr1 = headptr2 = slowwhile ptr1 != ptr2:ptr1 = ptr1.nextptr2 = ptr2.nextreturn ptr1
代码解释
-
判断是否有环:
slow和fast初始均指向head。- 每次循环中,
slow移动一步,fast移动两步。 - 若两指针相遇,说明存在环,进入下一步;否则返回
null。
-
确定环入口:
ptr1从头节点出发,ptr2从相遇点出发。- 两指针每次移动一步,最终相遇点即为环入口。
复杂度分析
- 时间复杂度:O(n),快慢指针遍历链表的总时间为 O(n)。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 快慢指针法:高效判断环的存在,并通过数学推导确定环入口。
- 双指针移动:从链表头和相遇点出发的指针最终在环入口相遇。
- 数学推导:利用相遇点的性质,避免遍历整个链表。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目描述
k 个一组翻转链表:给定链表的头节点 head,每 k 个节点一组进行翻转,返回翻转后的链表。若最后一组不足 k 个节点,则保持原样。
示例
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
最优解思路
迭代法 + 分组反转
- 虚拟头节点:简化头节点处理。
- 分组判断:遍历链表,找到每组的起始和结束位置。
- 反转每组:使用迭代法反转每组的
k个节点。 - 连接各组:将反转后的组连接到前一组的末尾。
关键逻辑:
- 通过两次循环实现:外层循环遍历所有组,内层循环确定每组的结束位置。
- 反转时记录每组的新头和新尾,确保正确连接。
Python 代码实现
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass Solution:def reverseKGroup(self, head: ListNode, k: int) -> ListNode:dummy = ListNode(0)dummy.next = headprev_group = dummywhile True:# 找到当前组的结束节点end_group = prev_groupfor _ in range(k):end_group = end_group.nextif not end_group:return dummy.next # 不足k个,直接返回# 反转当前组start = prev_group.nextend = end_groupnew_head, new_tail = self.reverse(start, end)# 连接到前一组prev_group.next = new_head# 更新前一组的尾prev_group = new_tailreturn dummy.nextdef reverse(self, start: ListNode, end: ListNode) -> (ListNode, ListNode):prev = Nonecurrent = startwhile current != end.next:next_node = current.nextcurrent.next = prevprev = currentcurrent = next_nodereturn (prev, start)
代码解释
- 虚拟头节点
dummy:统一处理头节点反转。 - 遍历所有组:
end_group从prev_group出发,移动k次确定每组的结束位置。- 若
end_group为None,说明不足k个节点,返回结果。
- 反转当前组:
start为当前组的第一个节点,end为最后一个节点。- 通过迭代反转链表,返回新的头节点
new_head和尾节点new_tail。
- 连接各组:
- 将
prev_group的next指向new_head。 prev_group更新为new_tail,以便下一组的连接。
- 将
复杂度分析
- 时间复杂度:O(n),每个节点被访问一次。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 分组反转:每次处理一组,确保逻辑清晰。
- 虚拟头节点:简化边界条件处理。
- 迭代反转:避免递归的栈空间开销。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
题目描述
k 个一组翻转链表:给定链表的头节点 head,每 k 个节点一组进行翻转,返回翻转后的链表。若最后一组不足 k 个节点,则保持原样。
示例
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
最优解思路
迭代法 + 分组反转
- 虚拟头节点:简化头节点处理。
- 分组判断:遍历链表,找到每组的起始和结束位置。
- 反转每组:使用迭代法反转每组的
k个节点。 - 连接各组:将反转后的组连接到前一组的末尾。
关键逻辑:
- 通过两次循环实现:外层循环遍历所有组,内层循环确定每组的结束位置。
- 反转时记录每组的新头和新尾,确保正确连接。
Python 代码实现
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass Solution:def reverseKGroup(self, head: ListNode, k: int) -> ListNode:dummy = ListNode(0)dummy.next = headprev_group = dummywhile True:# 找到当前组的结束节点end_group = prev_groupfor _ in range(k):end_group = end_group.nextif not end_group:return dummy.next # 不足k个,直接返回# 反转当前组start = prev_group.nextend = end_groupnew_head, new_tail = self.reverse(start, end)# 连接到前一组prev_group.next = new_head# 更新前一组的尾prev_group = new_tailreturn dummy.nextdef reverse(self, start: ListNode, end: ListNode) -> (ListNode, ListNode):prev = Nonecurrent = startwhile current != end.next:next_node = current.nextcurrent.next = prevprev = currentcurrent = next_nodereturn (prev, start)
代码解释
- 虚拟头节点
dummy:统一处理头节点反转。 - 遍历所有组:
end_group从prev_group出发,移动k次确定每组的结束位置。- 若
end_group为None,说明不足k个节点,返回结果。
- 反转当前组:
start为当前组的第一个节点,end为最后一个节点。- 通过迭代反转链表,返回新的头节点
new_head和尾节点new_tail。
- 连接各组:
- 将
prev_group的next指向new_head。 prev_group更新为new_tail,以便下一组的连接。
- 将
复杂度分析
- 时间复杂度:O(n),每个节点被访问一次。
- 空间复杂度:O(1),仅使用常数额外空间。
关键点总结
- 分组反转:每次处理一组,确保逻辑清晰。
- 虚拟头节点:简化边界条件处理。
- 迭代反转:避免递归的栈空间开销。
该解法在时间和空间上均达到最优,是解决本题的经典方法。
堆栈(Stack)与双端队列(Deque)总结与对比(Python实现)
1. 堆栈(Stack)
- 定义:后进先出(LIFO)数据结构,仅允许在栈顶操作。
- 核心操作:
push(item):将元素压入栈顶。pop():弹出栈顶元素。peek():查看栈顶元素。empty():判断栈是否为空。
- Python实现:
# 使用列表模拟堆栈 stack = [] stack.append(1) # push top = stack[-1] # peek popped = stack.pop() # pop is_empty = len(stack) == 0 - 时间复杂度:
- 插入、删除、查询栈顶:O(1)(均摊)。
- 其他操作(如搜索):O(n)。
- 空间复杂度:O(n)(存储n个元素)。
2. 双端队列(Deque)
- 定义:支持在两端(头部和尾部)插入/删除的数据结构,兼具FIFO和LIFO特性。
- 核心操作:
- 头部操作:
appendleft(item),popleft()。 - 尾部操作:
append(item),pop()。 - 查询操作:
[0](头部)、[-1](尾部)。
- 头部操作:
- Python实现:
from collections import dequedq = deque() dq.append(1) # 尾部添加 dq.appendleft(0) # 头部添加 front = dq[0] # 查看头部 rear = dq[-1] # 查看尾部 popped_front = dq.popleft() # 弹出头部 popped_rear = dq.pop() # 弹出尾部 - 时间复杂度:
- 两端插入、删除、查询:O(1)。
- 空间复杂度:O(n)(存储n个元素)。
3. 对比表格
| 特性 | 堆栈(Stack) | 双端队列(Deque) |
|---|---|---|
| 数据结构 | LIFO(后进先出) | 支持FIFO/LIFO,两端操作 |
| 典型操作 | push, pop, peek | appendleft, popleft, append |
| Python实现 | list(推荐deque) | collections.deque |
| 时间复杂度 | ||
| - 插入(尾部) | O(1)(均摊) | O(1)(两端) |
| - 删除(尾部) | O(1)(均摊) | O(1)(两端) |
| - 访问元素 | O(n)(需遍历) | O(1)(仅头尾) |
| 空间复杂度 | O(n) | O(n) |
| 应用场景 | 函数调用栈、括号匹配、浏览器后退 | 任务调度、缓存淘汰(LRU)、双端缓冲区 |
4. 选择建议
- 仅需LIFO:
优先用collections.deque(效率高于列表模拟的堆栈)。 - 需要两端操作:
必须用deque(列表无法高效操作头部)。 - 性能优化:
deque的append/pop在两端均为O(1),而列表的insert(0, x)和pop(0)为O(n)。
通过合理选择数据结构,可显著提升代码效率。
| Data Structure | Time Complexity(Average) | Time Complexity(Worst) | Space Complexity(Worst) |
|---|---|---|---|
| Access | Search | Insertion | |
| Array | O(1) | O(n) | O(n) |
| Stack | O(n) | O(n) | O(1) |
| Queue | O(n) | O(n) | O(1) |
| Singly - Linked List | O(n) | O(n) | O(1) |
| Doubly - Linked List | O(n) | O(n) | O(1) |
| Skip List | O(log(n)) | O(log(n)) | O(log(n)) |
| Hash Table | N/A | O(1) | O(1) |
| Binary Search Tree | O(log(n)) | O(log(n)) | O(log(n)) |
| B - Tree | O(log(n)) | O(log(n)) | O(log(n)) |
| Red - Black Tree | O(log(n)) | O(log(n)) | O(log(n)) |
| AVL Tree | O(log(n)) | O(log(n)) | O(log(n)) |
题目描述
给定一个只包含 (、)、{、}、[、] 的字符串 s,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合,每个右括号都有一个对应的相同类型左括号。
最优解(栈解法)
class Solution: def isValid(self, s: str) -> bool: stack = [] # 右括号到左括号的映射 bracket_map = {')': '(', '}': '{', ']': '['} for char in s: if char in bracket_map.values(): # 左括号,入栈 stack.append(char) else: # 右括号,检查匹配 if not stack or bracket_map[char] != stack.pop(): return False return not stack # 栈空则所有括号匹配
解法分析
- 思路:利用栈的后进先出特性。遍历字符串,遇到左括号压入栈;遇到右括号时,检查栈顶是否为对应的左括号(通过
bracket_map映射判断)。若匹配,弹出栈顶;不匹配或栈空(无左括号可匹配),直接返回False。遍历结束后,若栈为空,说明所有括号正确闭合,返回True。 - 时间复杂度:( O(n) ),每个字符仅遍历一次。
- 空间复杂度:( O(n) ),栈最多存储 ( n ) 个左括号(如全是左括号的情况)。
此解法通过栈高效维护括号匹配状态,是解决该问题的经典最优方案。
最小栈问题的详细解析(双栈法)
问题描述
设计一个栈,支持以下操作:
push(val):将元素压入栈。pop():弹出栈顶元素。top():返回栈顶元素。getMin():在常数时间内返回栈中的最小元素。
核心思路:双栈法
使用两个栈:
- 数据栈(
stack):存储所有元素。 - 最小栈(
min_stack):存储当前栈中的最小值。
关键逻辑:
-
push操作:
- 将元素压入数据栈。
- 若元素小于等于最小栈的栈顶元素(或最小栈为空),将其压入最小栈。
- 作用:确保最小栈的栈顶始终是当前栈的最小值。
-
pop操作:
- 弹出数据栈的栈顶元素。
- 若弹出的元素等于最小栈的栈顶元素,同时弹出最小栈的栈顶。
- 作用:维护最小栈的栈顶为当前栈的最小值。
-
getMin操作:直接返回最小栈的栈顶元素(O(1)时间)。
示例说明
场景:依次压入元素 3 → 5 → 2 → 2。
-
push(3):
- 数据栈:
[3] - 最小栈:
[3](空栈,直接压入)
- 数据栈:
-
push(5):
- 数据栈:
[3, 5] - 最小栈:
[3](5 > 3,不压入)
- 数据栈:
-
push(2):
- 数据栈:
[3, 5, 2] - 最小栈:
[3, 2](2 ≤ 3,压入)
- 数据栈:
-
push(2):
- 数据栈:
[3, 5, 2, 2] - 最小栈:
[3, 2, 2](2 ≤ 2,压入)
- 数据栈:
-
pop():
- 数据栈弹出
2→[3, 5, 2] - 弹出元素等于最小栈栈顶(2),最小栈弹出 →
[3, 2]
- 数据栈弹出
-
getMin():返回
2(当前最小栈栈顶)
代码实现(Python)
class MinStack: def __init__(self): self.stack = [] # 存储所有元素 self.min_stack = [] # 存储当前最小值 def push(self, val: int) -> None: self.stack.append(val) # 若新元素 ≤ 最小栈栈顶,或最小栈为空,压入最小栈 if not self.min_stack or val <= self.min_stack[-1]: self.min_stack.append(val) def pop(self) -> None: # 弹出数据栈栈顶元素 popped_val = self.stack.pop() # 若弹出的是当前最小值,同步弹出最小栈栈顶 if popped_val == self.min_stack[-1]: self.min_stack.pop() def top(self) -> int: return self.stack[-1] # 直接访问数据栈栈顶 def getMin(self) -> int: return self.min_stack[-1] # 直接访问最小栈栈顶
关键问题解释
-
为什么使用双栈?
- 数据栈存储所有元素,最小栈跟踪最小值。双栈配合确保每次操作均为O(1)时间。
-
push时为何比较
val <= min_stack[-1]?- 若当前元素等于最小值,仍需压入最小栈。例如,多次压入相同最小值时,确保后续pop操作能正确维护最小值。
-
pop时为何检查
popped_val == min_stack[-1]?- 若弹出的是当前最小值,需同步弹出最小栈的栈顶,否则最小栈的栈顶会变为之前的最小值。
复杂度分析
- 时间复杂度:
push、pop、top、getMin均为 ( O(1) )。
- 空间复杂度:
- 最坏情况下(所有元素单调递减),( O(n) ),两个栈存储 ( n ) 个元素。
此解法通过双栈同步维护元素与最小值,是解决该问题的最优方案。
题目描述
给定一个非负整数数组 heights,其中每个元素表示一个宽度为 1 的柱子的高度。求在这些柱子组成的直方图中,能够勾勒出的最大矩形面积。
最优解(单调栈算法)
from typing import List class Solution: def largestRectangleArea(self, heights: List[int]) -> int: stack = [-1] # 初始化栈,-1 作为边界值 max_area = 0 n = len(heights) for i in range(n): # 当当前高度小于栈顶高度时,弹出栈顶计算面积 while stack[-1] != -1 and heights[i] < heights[stack[-1]]: current_height = heights[stack.pop()] current_width = i - stack[-1] - 1 # 计算宽度 max_area = max(max_area, current_height * current_width) stack.append(i) # 压入当前索引 # 处理栈中剩余元素 while stack[-1] != -1: current_height = heights[stack.pop()] current_width = n - stack[-1] - 1 max_area = max(max_area, current_height * current_width) return max_area
核心思路
-
单调栈维护递增序列:
- 栈中存储柱子的索引,确保栈内索引对应的高度递增。
- 当遇到当前高度
heights[i]小于栈顶索引对应高度时,弹出栈顶索引,计算以该高度为矩形高的面积。
-
计算面积的逻辑:
- 高度:弹出的栈顶索引
j对应的高度heights[j]。 - 宽度:左侧第一个比
heights[j]小的柱子索引为stack[-1],右侧第一个比heights[j]小的柱子索引为i。宽度为i - stack[-1] - 1。 - 面积:
heights[j] * (i - stack[-1] - 1)。
- 高度:弹出的栈顶索引
-
处理剩余元素:
- 遍历结束后,栈中剩余元素的右侧边界视为
n(数组长度),假设右侧有一个高度为0的虚拟柱子,计算剩余元素的面积。
- 遍历结束后,栈中剩余元素的右侧边界视为
示例分析
输入:heights = [2, 1, 5, 6, 2, 3]
输出:10
过程解析:
- 遍历
i=1(高度1):- 弹出栈顶
0(高度2),计算宽度1 - (-1) - 1 = 1,面积2 × 1 = 2。
- 弹出栈顶
- 遍历
i=4(高度2):- 弹出栈顶
3(高度6),面积6 × 1 = 6。 - 弹出栈顶
2(高度5),面积5 × 2 = 10。
- 弹出栈顶
- 处理剩余元素:
- 弹出
5(高度3),面积3 × 1 = 3。 - 弹出
4(高度2),面积2 × 4 = 8。 - 弹出
1(高度1),面积1 × 6 = 6。 - 最终最大面积为
10。
- 弹出
复杂度分析
- 时间复杂度:( O(n) ),每个元素进栈、出栈各一次。
- 空间复杂度:( O(n) ),最坏情况下栈存储所有元素。
关键点总结
- 单调栈的作用:高效找到每个柱子的左右边界,避免暴力枚举。
- 宽度计算:利用栈中相邻索引的差值,直接确定左右边界。
- 边界处理:初始栈底
-1和虚拟右边界n确保所有元素被正确计算。
此方法通过单调栈将时间复杂度优化到线性,是解决该问题的经典方案。
哈希表(Hash Table)、映射(Map)和集合(Set)的原理、实现及应用。主要内容包括:
- 哈希表的应用场景:电话号码簿、用户信息表、缓存(LRU Cache)、键值对存储(Redis)等。
- 哈希表核心机制:哈希函数设计、冲突解决(链表法)、扩容策略。
- 编程语言实现:Java的
HashMap和HashSet、Python的字典和集合。 - 复杂度分析:哈希表操作的时间与空间复杂度。
关键知识点
-
哈希表基础
- 哈希函数:将键映射为索引的函数(如将字符串转换为整数)。
- 哈希冲突:不同键映射到同一索引时,通过链表或红黑树解决冲突。
- 负载因子:默认值0.75,平衡时间与空间效率。
-
Java实现细节
HashMap:基于数组+链表/红黑树实现,允许null键和值。HashSet:底层使用HashMap存储元素,值为固定占位符PRESENT。- 扩容机制:当元素数量超过负载因子×容量时,数组长度翻倍。
-
Python实现
- 字典(
dict):动态哈希表,支持高效键值操作。 - 集合(
set):基于哈希表,确保元素唯一性。
- 字典(
-
复杂度分析
- 平均情况:插入、删除、查找操作均为 ( O(1) )。
- 最坏情况:哈希冲突严重时退化为 ( O(n) )(链表)或 ( O(\log n) )(红黑树)。
典型代码示例
-
Java
HashMap初始化:HashMap<String, Integer> numbers = new HashMap<>(); numbers.put("one", 1); Integer n = numbers.get("two"); -
Python 字典与集合:
map_x = {'jack': 100, '张三': 80} set_x = {'jack', 'selina', 'Andy'}
扩展思考
- 哈希表设计权衡:初始容量、负载因子的选择影响性能。
- 冲突解决策略:链表法(Java)与开放寻址法(如Python)的差异。
- 线程安全:Java的
Hashtable线程安全但效率低,ConcurrentHashMap为高性能替代方案。
总结
哈希表是一种高效的数据结构,通过哈希函数和冲突解决策略实现快速查找与插入。掌握其原理和编程语言的具体实现,对优化算法和系统设计至关重要。实际应用中需根据场景选择合适的哈希表实现(如Java的HashMap、Python的dict),并注意哈希冲突和扩容带来的性能影响。
题目
给定两个字符串 s 和 t,编写一个函数来判断 t 是否是 s 的字母异位词。字母异位词指两个字符串包含的字符种类和数量完全相同,仅字符顺序不同。
解答
class Solution(object): def isAnagram(self, s, t): if len(s) != len(t): return False count = [0] * 26 for char in s: count[ord(char) - ord('a')] += 1 for char in t: count[ord(char) - ord('a')] -= 1 if count[ord(char) - ord('a')] < 0: return False return True
思路分析
- 长度判断:若
s和t长度不同,直接返回False,因为字母异位词长度必须相等。 - 统计字符次数:使用长度为 26 的数组
count(对应 26 个小写字母)。遍历s,统计每个字母出现次数(通过ord(char) - ord('a')映射到数组索引)。 - 验证
t的字符:遍历t,对每个字母在count中减 1。若出现负数,说明t中该字母数量超过s,直接返回False。 - 最终检查:若所有字符统计均合法,返回
True,表明t是s的字母异位词。
此方法时间复杂度为 ( O(n) )(( n ) 为字符串长度),空间复杂度为 ( O(1) )(数组大小固定为 26),高效且简洁。
题目描述
给定一个整数数组 nums 和一个整数 k,找出所有长度为 k 的滑动窗口中的最大值。
最优解(单调队列法)
from collections import deque
from typing import List class Solution: def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]: dq = deque() # 双端队列存储索引,确保对应值递减 result = [] n = len(nums) for i in range(n): # 维护队列递减性,弹出比当前值小的队尾元素 while dq and nums[i] >= nums[dq[-1]]: dq.pop() dq.append(i) # 移除超出窗口范围的队头元素 while dq[0] <= i - k: dq.popleft() # 窗口形成后记录最大值 if i >= k - 1: result.append(nums[dq[0]]) return result
解题思路
- 单调队列维护递减序列:
- 队列
dq存储元素索引,保证队列中索引对应的值递减。每次加入新元素nums[i]时,从队尾弹出所有比nums[i]小的元素,确保队列头部始终是当前窗口的最大值索引。
- 队列
- 窗口边界处理:
- 当队头元素的索引
dq[0]小于等于i - k(即超出窗口左边界),弹出队头元素,保持队列只包含当前窗口内的索引。
- 当队头元素的索引
- 记录结果:
- 当
i >= k - 1时,窗口形成,队头元素dq[0]对应的值即为当前窗口最大值,加入结果列表result。
- 当
复杂度分析
- 时间复杂度:( O(n) ),每个元素最多入队、出队各一次。
- 空间复杂度:( O(n) ),队列最多存储所有元素的索引。
此方法通过单调队列高效维护滑动窗口内的最大值,确保每个元素仅需常数时间处理,是解决该问题的最优方案。
题目描述
给定一个整数数组 nums 和一个目标值 target,在数组中找出两个整数,使得它们的和等于 target,并返回它们的数组下标。假设每种输入只有一个答案,且不能重复利用数组中同一个元素。
解法思路
利用哈希表(字典)记录已遍历元素及其下标。遍历数组时,对每个元素 nums[i],计算补数 complement = target - nums[i]。若 complement 在哈希表中存在,说明找到匹配对,返回两者下标;若不存在,将 nums[i] 存入哈希表。此方法只需一次遍历,时间复杂度为 ( O(n) ),空间复杂度为 ( O(n) )。
代码实现(Python)
class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: num_dict = {} for i, num in enumerate(nums): complement = target - num if complement in num_dict: return [num_dict[complement], i] num_dict[num] = i return []
代码解释
num_dict存储元素值到下标的映射。- 遍历
nums,对每个元素num(下标i),计算complement。 - 检查
complement是否在num_dict中,若在,返回对应下标和当前下标i;若不在,将num存入num_dict。 - 确保每个元素仅使用一次,且一次遍历即可找到答案,高效解决问题。
相关文章:

面试算法高频01
题目描述 验证回文串 给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。 示例 1: 输入: "A man, a plan, a canal: Panama" 输出: true示例 2: 输入: "race a car" 输出: falseimport…...

如何深刻理解Reactor和Proactor
前言: 网络框架的设计离不开 I/O 线程模型,线程模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等。目前主流的网络框架,在网络 IO 处理层面几乎都采用了I/O 多路复用方案(又以epoll为主),这是服务端应对高并发的性能利器。 …...

java基础 数组Array的介绍
Array 数组定义一维数组多维数组动态数组常见方法Arrays排序1.sort() 排序 2.parallelSort() 排序 查找:binarySearch()填充:fill()比较:equals() 和 deepEquals()复制:copyOf() 和 copyOfRange()转换为列表:asList()转…...

Elixir语言的函数定义
Elixir语言的函数定义 Elixir是一种基于Erlang虚拟机(BEAM)的函数式编程语言,因其并发特性及可扩展性而受到广泛欢迎。在Elixir中,函数是程序的基本构建块,了解如何定义和使用函数对于掌握这门语言至关重要。本文将深…...
我的NISP二级之路-02
目录 一.数据库 二.TCP/IP协议 分层结构 三.STRIDE模型 四.检查评估与自评估 检查评估 自评估 五.信息安全应急响应过程 六.系统工程 七.SSE-CMM 八.CC标准 九.九项重点工作 记背: 一.数据库 关于数据库恢复技术,下列说法不正确的是:…...

k8s1.24升级1.28
0、简介 这里只用3台服务器来做一个简单的集群,当前版本是1.24.17目标升级到1.28.17 地址主机名192.168.160.40kuber-master-1192.168.160.41kuber-master-2192.168.160.42kuber-node-1 因为1.24已经更换过了容器运行时,所以之后的升级相对就会简单&am…...
常见的微信个人号二次开发功能
一、常见开发功能 1. 好友管理 好友列表维护 添加/删除好友 修改好友信息(备注、标签等) 分组管理 创建/编辑/删除标签 好友分类与筛选 2. 消息管理 信息发送 支持多类型内容:文本、图片、视频、文件、小程序、名片、URL链接等 附加功…...

unity的dots中instantiate克隆对象后,对象会在原位置闪现的原因和解决
原因 在Entity中有两个位置信息,一个是local transform。一个是local to world 其中local transform负责具体位置,local to world 负责渲染位置,即图像的渲染的位置是根据local to world的。 local to world 的更新是引擎自己控制的&#x…...

去中心化固定利率协议
核心机制与分类 协议类型: 借贷协议(如Yield、Notional):通过零息债券模型(如fyDai、fCash)锁定固定利率。 收益聚合器(如Saffron、BarnBridge):通过风险分级或博弈论…...

Java面试黄金宝典31
1. 什么是封锁协议 定义:封锁协议是在运用封锁机制时,为了保证事务的一致性和隔离性,对何时申请封锁、持锁时间以及何时释放封锁等问题制定的规则。它可防止并发操作引发的数据不一致问题,如丢失修改、不可重复读和读 “脏” 数据…...
R语言——绘制生命曲线图(细胞因子IL5)
绘制生命曲线图(根据细胞因子) 说明流程代码加载包读取Excel文件清理数据重命名列名处理IL-5中的"<"符号 - 替换为检测下限的一半首先找出所有包含"<"的值检查缺失移除缺失值根据IL-5中位数将患者分为高低两组 创建生存对象拟…...

在内网环境中为 Gogs 配置 HTTPS 访问
在内网环境中为 Gogs 配置 HTTPS 访问,虽然不需要公网域名,但仍需通过自签名证书或私有证书实现加密。以下是详细步骤和方案: 一、核心方案选择 方案适用场景优点缺点自签名证书快速测试、临时使用无需域名,快速生成浏览器提示“…...

神马系统8.5搭建过程,附源码数据库
项目介绍 神马系统是多年来流行的一款电视端应用,历经多年的发展,在稳定性和易用性方面都比较友好。 十多年前当家里的第一台智能电视买回家,就泡在某论坛,找了很多APP安装在电视上,其中这个神马系统就是用得很久的一…...
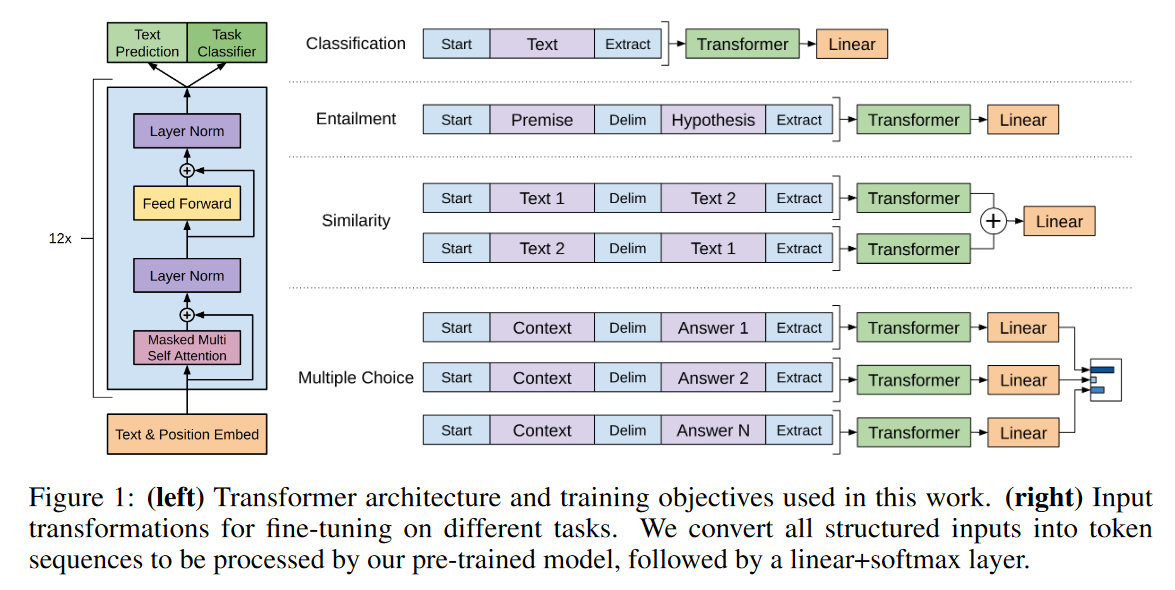
大模型论文:Improving Language Understanding by Generative Pre-Training
大模型论文:Improving Language Understanding by Generative Pre-Training OpenAI2018 文章地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf 摘要 自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文…...

SDL视频显示函数
文章目录 1. **`SDL_Init()`**2. **`SDL_CreateWindow()`**3. **`SDL_CreateRenderer()`**4. **`SDL_CreateTexture()`**5. **`SDL_UpdateTexture()`**6. **`SDL_RenderCopy()`**7. **`SDL_RenderPresent()`**8. **`SDL_Delay()`**9. **`SDL_Quit()`**总结示例代码:代码说明:…...

[ctfshow web入门] web18
前置知识 js(javascript)语言用于前台控制,不需要知道他的语法是什么,以高级语言的阅读方式也能看懂个大概。 在JavaScript中,confirm()是一个用于显示确认对话框的内置函数,不用知道怎么使用。 信息收集 提示:不要…...

基于 docker 的 Xinference 全流程部署指南
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 一、下载代码 请在控制台下面执行…...

Vue组件化开发深度解析:Element UI与Ant Design Vue对比实践
一、Vue组件化开发的核心优势 1.1 组件化架构的天然优势 Vue的组件系统是其最核心的特性之一,采用单文件组件(.vue)形式,将HTML、CSS和JavaScript组合在同一个文件中,形成高内聚、低耦合的代码单元。这种设计显著提升…...

SQL Server查询性能下降:执行计划不稳定与索引优化
问题现象: SQL Server 2022 中某些关键查询性能突然下降,执行时间从毫秒级增至数秒,日志中未报错,但查询计划显示低效的索引扫描或键查找。 快速诊断 捕获实际执行计划: -- 启用实际执行计划 SET STATISTICS XML, TIME…...
)
【学Rust写CAD】31 muldiv255函数(muldiv255.rs,已经取消)
源码 // Calculates floor(a*b/255 0.5) #[inline] pub fn muldiv255(a: u32, b: u32) -> u32 {// The deriviation for this formula can be// found in "Three Wrongs Make a Right" by Jim Blinn.let tmp a * b 128;(tmp (tmp >> 8)) >> 8 }代…...
`uia.WindowControl` 是什么:获取窗口文字是基于系统的 UI 自动化接口,而非 OCR 方式
uia.WindowControl 是什么:获取窗口文字是基于系统的 UI 自动化接口,而非 OCR 方式 uia.WindowControl 通常是基于 Windows 系统的 UI 自动化框架(如 pywinauto 中的 uia 模块)里用于表示窗口控件的类。在 Windows 操作系统中,每个应用程序的窗口都可以看作是一个控件,ui…...
vue3 处理文字 根据文字单独添加class
下面写的是根据后端返回的html 提取我需要的标签和字 将他们单独添加样式 后端返回的数据 大概类似于<h1>2024年“双11”购物节网络零售监测报告</h1><p>表1 “双11” 期间网络零售热销品类TOP10</p> function checkfun(newList){if (newList) {let …...

Python爬虫教程011:scrapy爬取当当网数据开启多条管道下载及下载多页数据
文章目录 3.6.4 开启多条管道下载3.6.5 下载多页数据3.6.6 完整项目下载3.6.4 开启多条管道下载 在pipelines.py中新建管道类(用来下载图书封面图片): # 多条管道开启 # 要在settings.py中开启管道 class DangdangDownloadPipeline:def process_item(self, item, spider):…...
Jupyter Notebook不能自动打开默认浏览器怎么办?
在安装anaconda的过程中,部分用户可能会遇到,打开Jupyter Notebook的时候,不会弹出默认浏览器。本章教程给出解决办法。 一、生成一个jupyter默认配置文件 打开cmd,运行以下命令,会生成一个jupyter_notebook配置文件。 jupyter notebook --generate-config二、编辑jupyter_…...

VUE中数据绑定之OptionAPI
<template> <div> 姓名:<input v-model="userName" /> {{ userName }} <br /> 薪水:<input type="number" v-model="salary" /> <br /> <button v-on:click="submit">提交</button>…...

Spring Boot 工程创建详解
2025/4/2 向全栈工程师迈进! 一、SpingBoot工程文件的创建 点击Project Structure 然后按着如下点击 最后选择Spring Boot ,同时记得选择是Maven和jar,而不是war。因为Boot工程内置了Tomcat,所以不需要war。 紧接着选择Spring We…...
Spring Boot + MyBatis + Maven论坛内容管理系统源码
项目描述 xxxForum是一个基于Spring Boot MyBatis Maven开发的一个论坛内容管理系统,主要实现了的功能有: 前台页面展示数据、广告展示内容模块:发帖、评论、帖子分类、分页、回帖统计、访问统计、表单验证用户模块:权限、资料…...

国网B接口协议资源上报流程详解以及上报失败原因(电网B接口)
文章目录 一、B接口协议资源上报接口介绍B.2.1 接口描述B.2.2 接口流程B.2.3 接口参数B.2.3.1 SIP头字段B.2.3.2 SIP响应码B.2.3.3 XML Schema参数定义 B.2.4 消息示例B.2.4.1 上报前端系统的资源B.2.4.2 响应消息 二、B接口资源上报失败常见问题(一)证书…...
布谷一对一直播源码android版环境配置流程及功能明细
一:举例布谷交友(一对一直播源码)搭建部署的基本环境说明 1. 首先安装Center OS 7.9系统,硬盘最低 40G 2. 安装宝塔环境 https://bt.cn(强烈推荐使用) 3. 安装环境 ● PHP 7.3(安装redis扩展…...

TypeScript 类型系统详解
基础类型 TypeScript 支持丰富的基础数据类型,涵盖number、string、boolean、null、undefined、symbol以及bigint。这些类型为构建可靠的代码提供了基石。 数值类型(number):在 TypeScript 里,所有数字均为浮点数…...