Proximal Policy Optimization (PPO)
2.1 策略梯度方法
策略梯度方法计算策略梯度的估计值并将其插入到随机梯度上升算法中。最常用的梯度估计器的形式如下:
g ^ = E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] (1) \hat{g} = \mathbb{E}_t \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \hat{A}_t \right] \tag{1} g^=Et[∇θlogπθ(at∣st)A^t](1)
其中 π θ \pi_{\theta} πθ是一个随机策略, A ^ t \hat{A}_t A^t是时间步 t t t时刻优势函数的估计值。这里,期望 E t [ ⋅ ] \mathbb{E}_t[\cdot] Et[⋅]表示在有限样本批次上的经验平均,算法在采样和优化之间交替进行。使用自动微分软件的实现通过构造目标函数,其梯度为策略梯度估计器;估计器 g ^ \hat{g} g^是通过对目标进行微分得到的。
L P G ( θ ) = E t [ log π θ ( a t ∣ s t ) A ^ t ] (2) L^{PG}(\theta) = \mathbb{E}_t \left[ \log \pi_{\theta}(a_t | s_t) \hat{A}_t \right] \tag{2} LPG(θ)=Et[logπθ(at∣st)A^t](2)
尽管执行多步优化以最小化此损失 L P G L^{PG} LPG看起来是有吸引力的,但这样做并不合理,从经验上看,这往往会导致破坏性的较大策略更新
2.2 信任域方法Trust Region Methods
在TRPO中,目标函数(即“替代”目标)在对策略更新的大小施加约束的条件下进行最大化。具体而言,
maximize θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t ] (3) \text{maximize}_{\theta} \mathbb{E}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t \right] \tag{3} maximizeθEt[πθold(at∣st)πθ(at∣st)A^t](3)
同时满足约束条件:
E t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ≤ δ (4) \mathbb{E}_t \left[ \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \leq \delta \tag{4} Et[KL[πθold(⋅∣st),πθ(⋅∣st)]]≤δ(4)
其中, θ old \theta_{\text{old}} θold是更新前的策略参数向量。该问题可以通过共轭梯度算法高效求解,首先对目标函数进行线性逼近,并对约束条件进行二次逼近。
理论上,TRPO的正当性实际上建议使用惩罚项而不是约束条件,即解决无约束优化问题为某个系数 β \beta β。
maximize θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (5) \text{maximize}_{\theta} \mathbb{E}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t - \beta \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \tag{5} maximizeθEt[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](5)
这一理论依据源自于某些替代目标(它计算状态上的最大KL,而不是均值)形成了策略性能的下界(即悲观边界)。TRPO使用硬约束而不是惩罚项,因为选择一个在不同问题上表现良好的 β \beta β值是困难的,甚至在单一问题中,由于特征在学习过程中会发生变化。因此,为了实现目标,即使用一阶算法来模拟TRPO的单调改进,实验表明,仅仅选择一个固定的惩罚系数 β \beta β并优化带有惩罚项的目标函数(方程(5))与SGD方法相结合是不够的;需要进行额外的修改。
3 裁剪的替代目标
设 r t ( θ ) r_t(\theta) rt(θ)表示概率比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),因此 r ( θ old ) = 1 r(\theta_{\text{old}}) = 1 r(θold)=1。TRPO最大化一个“替代”目标:
L C P I ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t ] = E ^ t [ r t ( θ ) A ^ t ] (6) L^{CPI}(\theta) = \hat{\mathbb{E}}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t \right] = \hat{\mathbb{E}}_t \left[ r_t(\theta) \hat{A}_t \right] \tag{6} LCPI(θ)=E^t[πθold(at∣st)πθ(at∣st)A^t]=E^t[rt(θ)A^t](6)
上标 C P I CPI CPI表示保守策略迭代(Conservative Policy Iteration),这是该目标提出的背景。在没有约束的情况下,最大化 L C P I L^{CPI} LCPI会导致过大的策略更新;因此,我们现在考虑如何修改目标,惩罚那些将 r t ( θ ) r_t(\theta) rt(θ)从1移开的策略变化。
我们提出的主要目标如下:
L C L I P ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] (7) L^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right] \tag{7} LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)](7)
其中, ϵ \epsilon ϵ是一个超参数,例如 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2。这个目标函数的动机如下:最小值内的第一项是 L C P I L^{CPI} LCPI。第二项, clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_t clip(rt(θ),1−ϵ,1+ϵ)A^t,通过裁剪概率比率来修改替代目标,这样可以移除策略更新时 r t ( θ ) r_t(\theta) rt(θ) 超出区间 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ]的激励。最后,我们取裁剪和未裁剪目标的最小值,因此最终目标是未裁剪目标的下界(即悲观边界)。在这种方案中,我们仅在使目标变差时忽略概率比率的变化,并且当它使目标变坏时,我们会将其包括在内。注意, L C L I P ( θ ) = L C P I ( θ ) L^{CLIP}(\theta) = L^{CPI}(\theta) LCLIP(θ)=LCPI(θ)对于 θ \theta θ的第一次逼近(即 r = 1 r = 1 r=1)是相同的,但随着 θ \theta θ偏离 θ old \theta_{\text{old}} θold,它们变得不同。图1绘制了 L C L I P L^{CLIP} LCLIP中的单个项(即,单个 t t t);请注意,概率比率 r r r会裁剪为 1 − ϵ 1 - \epsilon 1−ϵ或 1 + ϵ 1 + \epsilon 1+ϵ,这取决于优势是否为正或负。
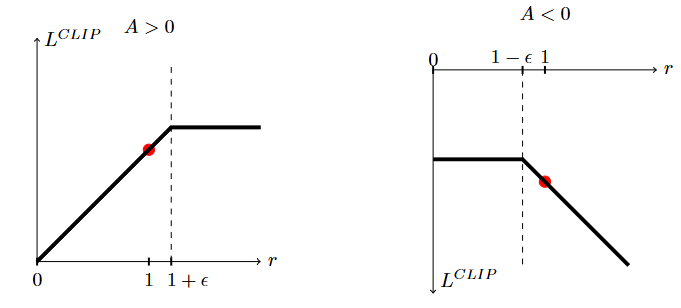 图1:绘制了替代目标函数 L C L I P L^{CLIP} LCLIP的单个项(即,单个时间步)相对于概率比率 r r r的图形,其中左侧表示正优势,右侧表示负优势。每个图上的红色圆圈表示优化的起始点,即 r = 1 r = 1 r=1。注意, L C L I P L^{CLIP} LCLIP是这些项的总和。
图1:绘制了替代目标函数 L C L I P L^{CLIP} LCLIP的单个项(即,单个时间步)相对于概率比率 r r r的图形,其中左侧表示正优势,右侧表示负优势。每个图上的红色圆圈表示优化的起始点,即 r = 1 r = 1 r=1。注意, L C L I P L^{CLIP} LCLIP是这些项的总和。
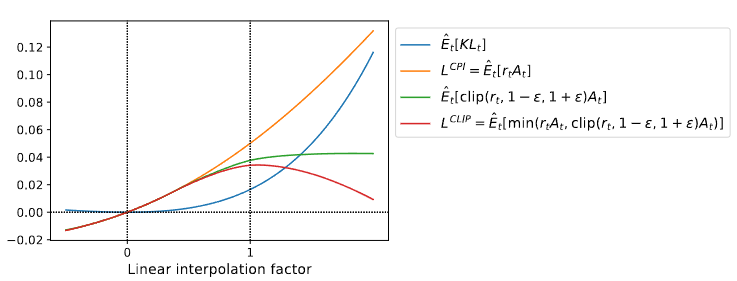
图2提供了关于替代目标 L C L I P L^{CLIP} LCLIP的另一个直观理解。它展示了当我们沿着策略更新方向进行插值时,多个目标是如何变化的,这个方向是通过近端策略优化在一个连续控制问题上获得的。我们可以看到, L C L I P L^{CLIP} LCLIP是 L C P I L^{CPI} LCPI的下界,并且对于策略更新过大有惩罚。
4 自适应KL惩罚系数
另一种方法,可以作为裁剪替代目标的替代方案,或作为附加方案,是对KL散度施加惩罚,并调整惩罚系数,以便在每次策略更新时实现KL散度的目标值 d t a r g d_{targ} dtarg。在我们的实验中,我们发现KL惩罚方法的表现优于裁剪的替代目标,然而我们仍将其包含在这里,因为它是一个重要的基线。
在该算法的最简单实现中,我们在每次策略更新时执行以下步骤:
- 使用几轮小批量SGD,优化KL惩罚目标:
L K L P E N ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (8) L^{KL PEN}(\theta) = \hat{\mathbb{E}}_t \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t - \beta \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)] \right] \tag{8} LKLPEN(θ)=E^t[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](8)
-
计算 d = E ^ t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d = \hat{\mathbb{E}}_t[\text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_{\theta}(\cdot | s_t)]] d=E^t[KL[πθold(⋅∣st),πθ(⋅∣st)]]
- 如果 d < d t a r g / 1.5 d < d_{targ}/1.5 d<dtarg/1.5,则 β ← β / 2 \beta \leftarrow \beta / 2 β←β/2
- 如果 d > d t a r g × 1.5 d > d_{targ} \times 1.5 d>dtarg×1.5,则 β ← β × 2 \beta \leftarrow \beta \times 2 β←β×2
更新后的 β \beta β将用于下一个策略更新。使用这种方案,我们偶尔会看到策略更新,其中KL散度与 d t a r g d_{targ} dtarg显著不同,但这些情况很少见,并且 β \beta β会快速调整。参数1.5和2是通过启发式选择的,但算法对它们并不特别敏感。 β \beta β的初始值是另一个超参数,但在实践中并不重要,因为算法会快速调整它。
5 算法
前面章节中的替代损失函数可以通过对典型的策略梯度实现进行少量修改来计算和求导。对于使用自动微分的实现,只需构造损失 L C L I P L^{CLIP} LCLIP或 L K L P E N L^{KL PEN} LKLPEN,代替 L P G L^{PG} LPG,然后对该目标执行多个随机梯度上升步骤。
大多数计算方差减少的优势函数估计的方法使用学习的状态值函数 V ( s ) V(s) V(s);例如,广义优势估计[Sch+15a],或[Mini+16]中的有限时域估计方法。如果使用共享策略和价值函数参数的神经网络架构,则必须使用结合策略替代函数和价值函数误差项的损失函数。该目标还可以通过添加一个熵奖励来进一步增强,以确保足够的探索,如过去的工作中所建议的[Wil92; Mini+16]。将这些项结合起来,我们得到如下目标函数,每次迭代时(大致)最大化:
L t C L I P + V F + S ( θ ) = E ^ t [ L t C L I P ( θ ) − c 1 L t V F ( θ ) + c 2 S [ π θ ] ( s t ) ] (9) L^{CLIP+VF+S}_t(\theta) = \hat{\mathbb{E}}_t \left[ L^{CLIP}_t(\theta) - c_1 L^{VF}_t(\theta) + c_2 S[\pi_{\theta}](s_t) \right] \tag{9} LtCLIP+VF+S(θ)=E^t[LtCLIP(θ)−c1LtVF(θ)+c2S[πθ](st)](9)
其中, c 1 c_1 c1和 c 2 c_2 c2是系数, S S S表示熵奖励, L t V F L^{VF}_t LtVF是平方误差损失 ( V θ ( s t ) − V t target ) 2 (V_{\theta}(s_t) - V_t^{\text{target}})^2 (Vθ(st)−Vttarget)2。
一种策略梯度实现方式,在[Mini+16]中流行并且适合与递归神经网络一起使用,为每个时间步运行策略(其中 T T T远小于回合长度),并使用收集到的样本进行更新。该方式需要一个不超出时间步 T T T的优势估计器。由[Mini+16]使用的估计器为:
A ^ t = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) (10) \hat{A}_t = -V(s_t) + r_t + \gamma r_{t+1} + \cdots + \gamma^{T - t + 1} r_{T-1} + \gamma^{T - t} V(s_T) \tag{10} A^t=−V(st)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)(10)
其中 t t t指定时间索引范围为 [ 0 , T ] [0, T] [0,T],在给定长度为 T T T的轨迹段内。推广此选择,我们可以使用广义优势估计的截断版本,当 λ = 1 \lambda = 1 λ=1时简化为方程(10):
A ^ t = δ t + ( γ λ ) δ t + 1 + ⋯ + ( γ λ ) T − t + 1 δ T − 1 , (11) \hat{A}_t = \delta_t + (\gamma \lambda) \delta_{t+1} + \cdots + (\gamma \lambda)^{T - t + 1} \delta_{T-1}, \tag{11} A^t=δt+(γλ)δt+1+⋯+(γλ)T−t+1δT−1,(11)
其中,
δ t = r t + γ V ( s t + 1 ) − V ( s t ) (12) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) \tag{12} δt=rt+γV(st+1)−V(st)(12)
一种使用固定长度轨迹段的近端策略优化(PPO)算法如下所示。在每次迭代中,每个 N N N(并行)演员收集 T T T时间步的数据。然后我们在这些 N T NT NT时间步的数据上构造替代损失,并使用小批量SGD(或通常为更好的性能,使用Adam [KB14])优化它,进行 K K K轮迭代。
算法1 PPO,Actor-Critic Style
for iteration=1, 2, ... dofor actor=1, 2, ..., N do# 在环境中运行策略$\pi_{\text{old}}$,共$T$时间步Run policy $\pi_{\text{old}}$ in environment for $T$ timesteps# 计算优势估计$\hat{A}_1, \dots, \hat{A}_T$Compute advantage estimates $\hat{A}_1, \dots, \hat{A}_T$end for# 优化替代目标$L$,与$\theta$,进行$K$轮,并使用小批量大小$M \leq NT$Optimize surrogate $L$ wrt $\theta$, with $K$ epochs and minibatch size $M \leq NT$# 更新$\theta_{\text{old}} \leftarrow \theta$$\theta_{\text{old}} \leftarrow \theta$end for
参考文献:Proximal Policy Optimization Algorithms
仅用于学习,如有侵权,联系删除
相关文章:
Proximal Policy Optimization (PPO)
2.1 策略梯度方法 策略梯度方法计算策略梯度的估计值并将其插入到随机梯度上升算法中。最常用的梯度估计器的形式如下: g ^ E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] (1) \hat{g} \mathbb{E}_t \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \h…...
微信小程序:动态表格实现,表头单元格数据完全从data中获取,宽度自定义,自定义文本框,行勾选,样式效果,横向滚动表格(解决背景色不足的问题)等
一、样式效果 二、代码 1、wxml <view class"line flex flex-center"><view class"none" wx:if"{{info.length 0}}">暂无料号</view><view wx:else class"table-container"><!-- 动态生成表头 -->&…...

Java基础编程练习第38题-除法器
题目:编写一个除法器,输入被除数和除数,并将结果输出。 这道题看似很简单,实则也不难。 就是假如用户输入的类型不同怎么办呢?用户输入int或者double类型应该怎么解决。这里我们就需要用到函数的重载。 代码如下&am…...

fabric.js基础使用
1.正方形 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Fabric.js Watermark Example</tit…...
python-Leetcode 65.搜索旋转排序数组
题目: 整数数组nums按升序排列,数组中的值互不相同 在传递给函数之前,nums在预先未知的某个小标K上进行了旋转,使数组变为[nums[k], nums[k1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]],小标从0开始计数。…...

质数质数筛
1.试除法判定质数–O(sqrt(N)) bool is_prime(int x) {if (x < 2) return false;for (int i 2; i < x / i; i )if (x % i 0)return false;return true; }2.试除法分解质因数–O(logN)~O(sqrt(N)) void divide(int x) {for (int i 2; i < x / i; i )if (x % i …...

Django学习记录-1
Django学习记录-1 虽然网上教程都很多,但是感觉自己记录一下才属于自己,之后想找也方面一点,文采不佳看的不爽可绕道。 参考贴 从零开始的Django框架入门到实战教程(内含实战实例) - 01 创建项目与app、加入静态文件、模板语法介绍ÿ…...

K8s私有仓库拉取镜像报错解决:x509 certificate signed by unknown authority
前言 在Kubernetes环境中使用自签名证书的私有Harbor镜像仓库时,常会遇到证书验证失败的问题。本文将详细讲解如何解决这个常见的证书问题。 环境信息: Kubernetes版本:1.28.2容器运行时:containerd 1.6.20私有仓库:…...

使用python访问mindie部署的vl多模态模型
说明 今天使用mindie1.0部署了qwen2_7b_vl模型,测试过程出现一些问题,这里总结下。 问题1:transformers版本太低 报错信息: [ERROR] [model_deploy_config.cpp:159] Failed to get vocab size from tokenizer wrapper with ex…...
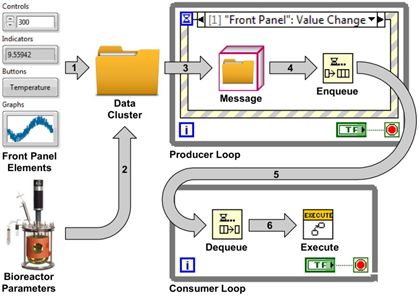
LabVIEW 长期项目开发
LabVIEW 凭借其图形化编程的独特优势,在工业自动化、测试测量等领域得到了广泛应用。对于长期运行、持续迭代的 LabVIEW 项目而言,其开发过程涵盖架构设计、代码管理、性能优化等多个关键环节,每个环节都对项目的成功起着至关重要的作用。下面…...

MongoDB 的详细介绍
以下是 MongoDB 的详细介绍,涵盖核心概念、使用场景、优势与操作示例: 一、MongoDB 简介 MongoDB 是一个开源的 文档型 NoSQL 数据库,采用灵活的 JSON-like(BSON)格式存储数据,适合处理非结构化或半结构化数据。 核心特点: Schema-free:无需预定义表结构,字段可动态扩…...

Ubuntu 22.04 AI大模型环境配置及常用工具安装
一、基础环境准备 1.1 系统准备 建议使用 Ubuntu22.04 以下配置皆以 Ubuntu22.04 系统版本为例 1.2 安装git apt-get update && apt-get install git -y1.3 安装 Python 3.9 【建议安装 3.10】(安装miniconda或者conda来管理虚拟环境) wget …...

蓝桥杯真题——好数、R格式
目录 蓝桥杯2024年第十五届省赛真题-好数 【模拟题】 题目描述 输入格式 输出格式 样例输入 样例输出 提示 代码1:有两个案例过不了,超时 蓝桥杯2024年第十五届省赛真题-R 格式 【vector容器的使用】 题目描述 输入格式 输出格式 样例输入…...

AWS S3深度剖析:云存储的瑞士军刀
1. 引言 在当今数据驱动的世界中,高效、可靠、安全的数据存储解决方案至关重要。Amazon Simple Storage Service (S3)作为AWS生态系统中的核心服务之一,为企业和开发者提供了一个强大而灵活的对象存储平台。本文将全面解析S3的核心特性,帮助读者深入理解如何充分利用这一&q…...

Qt基础:右键菜单
右键菜单 1. 基于鼠标事件实现1.1 原理1.2 操作 2. 基于窗口的菜单策略实现2.1 Qt::DefaultContextMenu2.2 Qt::ActionsContextMenu 2.3 Qt::CustomContextMenu 显示右键菜单, 其处理方式大体上有两种: 基于鼠标事件实现;基于窗口的菜单策略实现。 1. …...

Json快速入门
引言 Jsoncpp 库主要是用于实现 Json 格式数据的序列化和反序列化,它实现了将多个数据对象组织成 为Json格式字符串,以及将 Json 格式字符串解析得到多个数据对象的功能,独立于开发语言。 Json数据对象 Json数据对象类的表示: …...
——CheckBox控件详解)
WinForm真入门(10)——CheckBox控件详解
在 WinForm 中,CheckBox 控件是一个用于表示布尔状态(选中/未选中)的核心组件。它广泛应用于配置选项、表单提交、条件筛选等场景。以下是 CheckBox 的详细解析,涵盖属性、事件、使用技巧和实际案例。 一、CheckBox 核心属性…...

网络安全应急响应-系统排查
在网络安全应急响应中,系统排查是快速识别潜在威胁的关键步骤。以下是针对Windows和Linux系统的系统基本信息排查指南,涵盖常用命令及注意事项: 一、Windows系统排查 1. 系统信息工具(msinfo32.exe) 命令执行&#x…...

[QMT量化交易小白入门]-四十二、五年年化收益率26%,当日未成交的下单,取消后重新委托
本专栏主要是介绍QMT的基础用法,常见函数,写策略的方法,也会分享一些量化交易的思路,大概会写100篇左右。 QMT的相关资料较少,在使用过程中不断的摸索,遇到了一些问题,记录下来和大家一起沟通,共同进步。 文章目录 相关阅读委托查询功能3.1 数据获取层3.2 数据结构初始…...
Windows版-RabbitMQ自动化部署
一键完成Erlang环境变量配置(ERLANG_HOME系统变量) 一键完成RabbitMQ环境变量配置(RabbitMQ系统变量) 实现快速安装部署RabbitMQ PS: 需提前下载安装: - otp_win64_25.0.exe (Erlang) - rabbit…...
openEuler24.03 LTS下安装Flink
目录 Flink的安装模式下载Flink安装Local模式前提条件解压安装包启动集群查看进程提交作业文件WordCount持续流WordCount 查看Web UI配置flink-conf.yaml简单使用 关闭集群 Standalone Session模式前提条件Flink集群规划解压安装包配置flink配置flink-conf.yaml配置workers配置…...

LeetCode热题100记录-【二分查找】
二分查找 35.搜索插入位置 思考:二分查找先判定边界条件 记录:不需要二刷 class Solution {public int searchInsert(int[] nums, int target) {int left 0,right nums.length-1;if(nums[right] < target){return right1;}if(nums[left] > tar…...
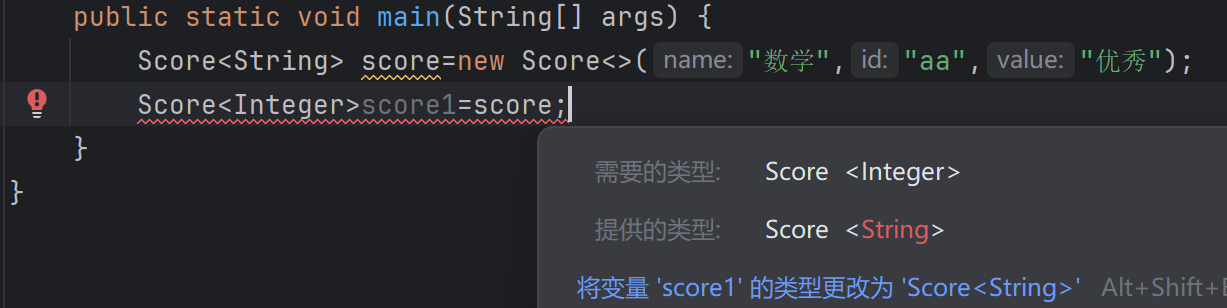
从零开始学java--泛型(1)
泛型 学生成绩可能是数字类型,也可能是字符串类型,如何存放可能出现的两种类型呢: public class Score {String name;String id;Object value; //因为Object是所有类型的父类,因此既可以存放Integer也能存放Stringpublic Score…...

【正点原子】STM32MP135去除SD卡引脚复用,出现 /dev/mmcblk1p5 not found!
如果在设备树中直接注释掉 sdmmc1 节点,就会导致系统启动时识别不到真正的 eMMC 设备,进而挂载失败,爆出 /dev/mmcblk1p5 not found 的问题。 正点原子STM32MP135开发板Linux核心板嵌入式ARM双千兆以太网CAN 正确操作是“放空”而不是“删光…...
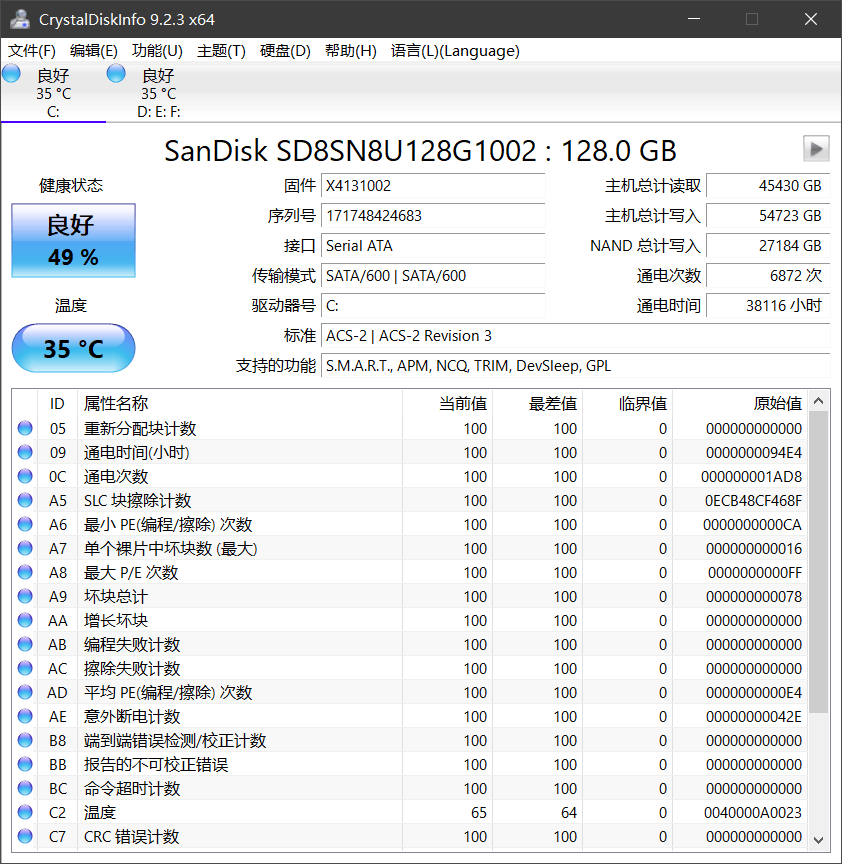
CrystalDiskInfo电脑硬盘监控工具 v9.6.0中文绿色便携版
前言 CrystalDiskInfo是一个不用花钱的硬盘小帮手软件,它可以帮你看看你的电脑硬盘工作得怎么样,健不健康。这个软件能显示硬盘的温度高不高、还有多少地方没用、传输东西快不快等等好多信息。用了它,你就能很容易地知道硬盘现在是什么情况&…...

详解模型蒸馏,破解DeepSeek性能谜题
大家好,不少关注 DeepSeek 最新动态的朋友,想必都遇到过 “Distillation”(蒸馏)这一术语。本文将介绍模型蒸馏技术的原理,同时借助 TensorFlow 框架中的实例进行详细演示。通过本文,对模型蒸馏有更深的认识…...

⭐算法OJ⭐数据流的中位数【最小堆】Find Median from Data Stream
最小堆 最小堆是一种特殊的完全二叉树数据结构。 基本定义 堆性质:每个节点的值都小于或等于其子节点的值(根节点是最小值)完全二叉树性质:除了最底层外,其他层的节点都是满的,且最底层的节点都靠左排列…...

园区网拓扑作业
作业要求: 需求: 需求分析: 1.按照图示的VLAN及IP地址需求,完成相关配需:VLAN 2、3、20、30 已分配子网,需在交换机上创建 VLAN 并配置三层接口作为网关。确保各 VLAN 内设备能互通,跨 VLAN 通…...

隔行换色总结
功能效果展示: 第一种思路: 使用数组,将数组的内容渲染到页面上,序号也就是将数组的下标输出到第一个td上,将数组的内容输出到第二个td上,(使用拼接字符串) 具体操作: …...

使用Docker Desktop进行本地打包和推送
使用Docker Desktop进行本地打包和推送 一、Docker Desktop配置二、IDEA配置1.下载Docker插件2.在“Settings”中,配置“Docker”3.选择“Docker Registry”,配置远程仓库。 三、POM配置 一共有三个地方需要配置 一、Docker Desktop配置 在Docker Deskt…...