详解模型蒸馏,破解DeepSeek性能谜题
大家好,不少关注 DeepSeek 最新动态的朋友,想必都遇到过 “Distillation”(蒸馏)这一术语。本文将介绍模型蒸馏技术的原理,同时借助 TensorFlow 框架中的实例进行详细演示。通过本文,对模型蒸馏有更深的认识,解锁深度学习优化的新视角。
1.模型蒸馏原理
在深度学习领域,模型蒸馏是优化模型的关键技术。它让小的学生模型不再单纯依赖原始标签,而是基于大的教师模型软化后的概率输出进行训练。
以图像分类为例,普通模型只是简单判断图像内容,而运用模型蒸馏技术的学生模型,能从教师模型的置信度分数(如80%是狗,15%是猫,5%是狐狸)中获取更丰富信息,从而保留更细致知识。
这样一来,学生模型能用更少参数实现与教师模型相近的性能,在保持高精度的同时,减小模型规模、降低计算需求,为深度学习模型优化开辟了新路径。下面通过一个例子来看看具体是如何操作的,以使用MNIST数据集训练卷积神经网络(CNN)为例。
MNIST (Modified National Institute of Standards and Technology database)数据集在机器学习和计算机视觉里常用,有 70,000 张 28x28 像素的手写数字(0 - 9)灰度图,60,000 张训练图、10,000 张测试图。
模型蒸馏要先建教师模型,是用 MNIST 数据集训练的 CNN,参数多、结构复杂。
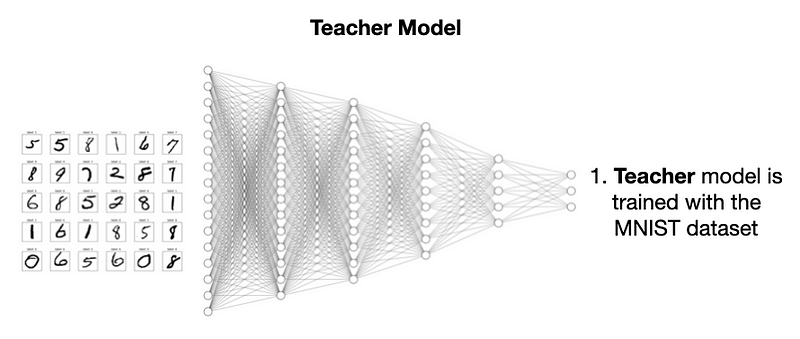
再建个更简单、规模更小的学生模型:
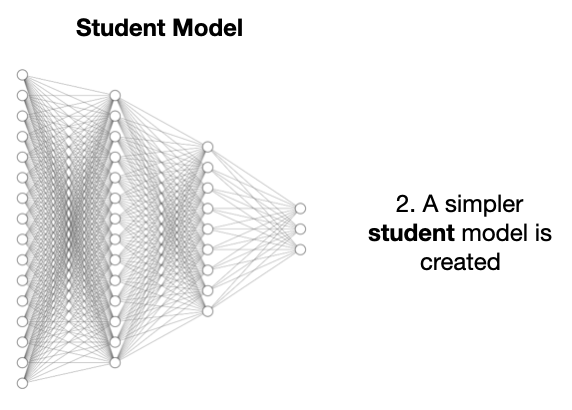
目的是让学生模型模仿教师模型性能,还能减少计算量和训练时间。
训练时,两个模型都用 MNIST 数据集预测,接着算它们输出的 Kullback-Leibler(KL)散度。这个值能确定梯度,指导调整学生模型。
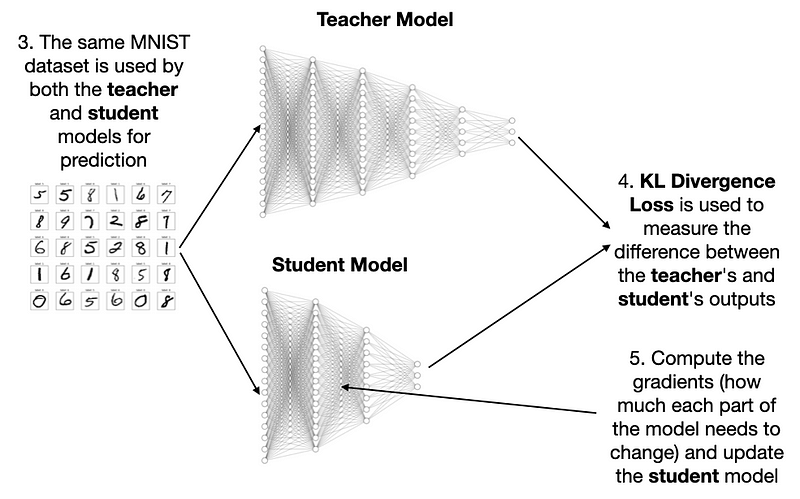
一番操作后,学生模型就能达到和教师模型差不多的准确率,成功 “出师”。
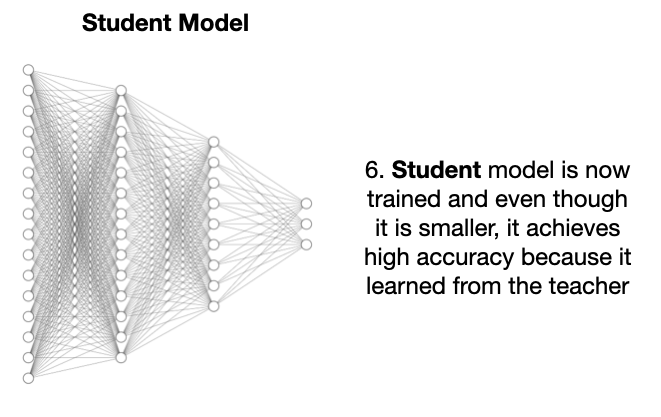
2.TensorFlow 和 MNIST 构建模型
接下来,借助 TensorFlow 和 MNIST 数据集,搭建一个模型蒸馏示例项目。
先训练一个教师模型,再通过模型蒸馏技术,训练出一个更小的学生模型。这个学生模型能模仿教师模型的性能,而且所需资源更少。
2.1 使用MNIST数据集
确保已经安装了TensorFlow:
!pip install tensorflow
然后加载MNIST数据集:
from tensorflow import keras
import matplotlib.pyplot as plt# 加载数据集(MNIST)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()fig = plt.figure()# 可视化部分数字
for i in range(9):plt.subplot(3,3,i+1)plt.tight_layout()plt.imshow(x_train[i], interpolation='none')plt.title("Digit: {}".format(y_train[i]))# 不显示x轴和y轴刻度plt.xticks([])plt.yticks([])
以下是MNIST数据集中的前9个样本数字及其标签:

还需要对图像数据进行归一化处理,并扩展数据集的维度,为训练做准备:
import tensorflow as tf
import numpy as np# 归一化图像
x_train, x_test = x_train / 255.0, x_test / 255.0# 为卷积神经网络扩展维度
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)# 将标签转换为分类(独热编码)
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
2.2 定义教师模型
在基于模型蒸馏的示例项目构建中,定义并训练教师模型是关键的环节。这里,构建一个多层卷积神经网络(CNN)作为教师模型。代码如下:
# 教师模型
teacher_model = keras.Sequential([keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),keras.layers.MaxPooling2D((2, 2)),keras.layers.Conv2D(64, (3, 3), activation='relu'),keras.layers.MaxPooling2D((2, 2)),keras.layers.Flatten(),keras.layers.Dense(128, activation='relu'),keras.layers.Dense(10) # 不使用softmax,输出原始logits用于蒸馏
])
需要注意的是,模型最后一层设置了 10 个单元,对应 0 - 9 这 10 个数字,但未采用 softmax 激活函数,而是输出原始的 logits。这一设计对于模型蒸馏很重要,因为在后续的蒸馏过程里,会借助 softmax 函数来计算教师模型与学生模型之间的 Kullback-Leibler(KL)散度,以此衡量二者差异,为学生模型的优化提供方向。
完成模型定义后,要使用compile()方法对其进行配置,设置优化器、损失函数以及评估指标:
teacher_model.compile(optimizer = 'adam',loss = tf.keras.losses.CategoricalCrossentropy(from_logits = True),metrics = ['accuracy']
)
配置完成,就可以使用fit()方法启动模型训练:
# 训练教师模型
teacher_model.fit(x_train, y_train, epochs = 5, batch_size = 64, validation_data = (x_test, y_test))
本次训练设定了 5 个训练周期,训练过程中的详细信息如下:
Epoch 1/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 8s 8ms/step - accuracy: 0.8849 - loss: 0.3798 - val_accuracy: 0.9844 - val_loss: 0.0504
Epoch 2/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 9s 9ms/step - accuracy: 0.9847 - loss: 0.0494 - val_accuracy: 0.9878 - val_loss: 0.0361
Epoch 3/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 9s 10ms/step - accuracy: 0.9907 - loss: 0.0302 - val_accuracy: 0.9898 - val_loss: 0.0316
Epoch 4/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 10s 10ms/step - accuracy: 0.9928 - loss: 0.0223 - val_accuracy: 0.9895 - val_loss: 0.0303
Epoch 5/5
938/938 ━━━━━━━━━━━━━━━━━━━━ 10s 11ms/step - accuracy: 0.9935 - loss: 0.0197 - val_accuracy: 0.9919 - val_loss: 0.0230
从这些数据中,可以直观地看到模型在训练过程中的准确率和损失变化,了解模型的学习效果,为后续的模型优化和评估提供依据。
2.3 定义学生模型
教师模型训练完成后,定义学生模型。与教师模型相比,学生模型的架构更简单,层数更少:
# 学生模型
student_model = keras.Sequential([keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),keras.layers.MaxPooling2D((2, 2)),keras.layers.Flatten(),keras.layers.Dense(64, activation='relu'),keras.layers.Dense(10) # 不使用softmax,输出原始logits用于蒸馏
])
2.4 定义蒸馏损失函数
在模型蒸馏的实现过程中,distillation_loss() 函数发挥着核心作用,它借助 Kullback-Leibler(KL)散度来精准计算蒸馏损失,从而推动学生模型向教师模型 “看齐”。下面,我们就来详细解读这个函数的代码实现。
蒸馏损失函数的计算,依赖于教师模型和学生模型的预测结果,具体步骤如下:
-
使用教师模型为输入批次生成软目标(概率)。
-
使用学生模型的预测计算其软概率。
-
计算教师模型和学生模型软概率之间的Kullback-Leibler(KL)散度。
-
返回蒸馏损失。
软概率和常见的硬标签不同。硬标签是明确分类,像判断邮件是否为垃圾邮件,结果只有 “是”(1)或 “否”(0)。而软概率会给出多种结果的概率,比如某邮件是垃圾邮件的概率为 0.85,不是的概率为 0.15,能更全面反映模型判断。
计算软概率要用到 softmax 函数,且受温度参数影响。在知识蒸馏里,教师模型的软概率包含类间丰富信息,学生模型学习后,能提升泛化能力和性能,更好地模仿教师模型。
以下是distillation_loss()函数的定义:
def distillation_loss(y_true, y_pred, x_batch, teacher_model, temperature=5):"""使用KL散度计算蒸馏损失。"""# 计算当前批次的教师模型logitsteacher_logits = teacher_model(x_batch, training=False)# 将logits转换为软概率teacher_probs = tf.nn.softmax(teacher_logits / temperature)student_probs = tf.nn.softmax(y_pred / temperature)# KL散度损失(教师模型和学生模型分布之间的差异)return tf.reduce_mean(tf.keras.losses.KLDivergence()(teacher_probs, student_probs))
Kullback-Leibler(KL)散度,也称为相对熵,用于衡量一个概率分布与另一个参考概率分布之间的差异。
2.5 使用知识蒸馏训练学生模型
现在准备好使用知识蒸馏来训练学生模型,首先,定义train_step()函数:
optimizer = tf.keras.optimizers.Adam()@tf.function
def train_step(x_batch, y_batch, student_model, teacher_model):with tf.GradientTape() as tape:# 获取学生模型的预测student_preds = student_model(x_batch, training=True)# 计算蒸馏损失(显式传入教师模型)loss = distillation_loss(y_batch, student_preds, x_batch, teacher_model, temperature=5)# 计算梯度gradients = tape.gradient(loss, student_model.trainable_variables)# 应用梯度 - 训练学生模型optimizer.apply_gradients(zip(gradients, student_model.trainable_variables))return loss
这个函数执行单个训练步骤:
-
计算学生模型的预测。
-
使用教师模型的预测计算蒸馏损失。
-
计算梯度并更新学生模型的权重。
为了训练学生模型,需要创建一个训练循环,遍历数据集,在每一步更新学生模型的权重,并在每个训练周期结束时打印损失,以监控训练进度:
# 训练循环
epochs = 5
batch_size = 32# 准备数据集批次
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)for epoch in range(epochs):total_loss = 0num_batches = 0for x_batch, y_batch in train_dataset:loss = train_step(x_batch, y_batch, student_model, teacher_model)total_loss += loss.numpy()num_batches += 1avg_loss = total_loss / num_batchesprint(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}")print("Student Model Training Complete!")
训练后,应该会看到类似以下的输出:
Epoch 1, Loss: 0.1991
Epoch 2, Loss: 0.0588
Epoch 3, Loss: 0.0391
Epoch 4, Loss: 0.0274
Epoch 5, Loss: 0.0236
Student Model Training Complete!
2.6 评估学生模型
学生模型已经训练完成,可以使用测试集(x_test和y_test)对其进行评估,观察其性能:
student_model.compile(optimizer='adam',loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),metrics=['accuracy']
)student_acc = student_model.evaluate(x_test, y_test, verbose=0)[1]
print(f"Student Model Accuracy: {student_acc:.4f}")
如预期,学生模型达到了相当不错的准确率:
Student Model Accuracy: 0.9863
2.7 使用教师模型和学生模型进行预测
现在可以使用教师模型和学生模型进行一些预测,看看是否都能准确预测MNIST测试数据集中的数字:
import numpy as np
_, (x_test, y_test) = keras.datasets.mnist.load_data()for index in range(5): plt.figure(figsize=(2, 2))plt.imshow(x_test[index], interpolation='none')plt.title("Digit: {}".format(y_test[index]))# 不显示x轴和y轴刻度plt.xticks([])plt.yticks([])plt.show()# 现在可以进行预测x = x_test[index].reshape(1,28,28,1)predictions = teacher_model.predict(x)print(predictions)print("Predicted value by teacher model: ", np.argmax(predictions, axis=-1))predictions = student_model.predict(x)print(predictions)print("Predicted value by student model: ", np.argmax(predictions, axis=-1))
以下是前两个结果:

如果测试更多的数字,会发现学生模型的表现与教师模型一样好。
相关文章:
详解模型蒸馏,破解DeepSeek性能谜题
大家好,不少关注 DeepSeek 最新动态的朋友,想必都遇到过 “Distillation”(蒸馏)这一术语。本文将介绍模型蒸馏技术的原理,同时借助 TensorFlow 框架中的实例进行详细演示。通过本文,对模型蒸馏有更深的认识…...

⭐算法OJ⭐数据流的中位数【最小堆】Find Median from Data Stream
最小堆 最小堆是一种特殊的完全二叉树数据结构。 基本定义 堆性质:每个节点的值都小于或等于其子节点的值(根节点是最小值)完全二叉树性质:除了最底层外,其他层的节点都是满的,且最底层的节点都靠左排列…...

园区网拓扑作业
作业要求: 需求: 需求分析: 1.按照图示的VLAN及IP地址需求,完成相关配需:VLAN 2、3、20、30 已分配子网,需在交换机上创建 VLAN 并配置三层接口作为网关。确保各 VLAN 内设备能互通,跨 VLAN 通…...

隔行换色总结
功能效果展示: 第一种思路: 使用数组,将数组的内容渲染到页面上,序号也就是将数组的下标输出到第一个td上,将数组的内容输出到第二个td上,(使用拼接字符串) 具体操作: …...

使用Docker Desktop进行本地打包和推送
使用Docker Desktop进行本地打包和推送 一、Docker Desktop配置二、IDEA配置1.下载Docker插件2.在“Settings”中,配置“Docker”3.选择“Docker Registry”,配置远程仓库。 三、POM配置 一共有三个地方需要配置 一、Docker Desktop配置 在Docker Deskt…...

MTO和MTS不同模式制造业数字化转型的“三座大山“:MES/ERP/PLM系统集成技术全解析
1.导言:制造业的数字化转型与集成系统的作用 在工业4.0浪潮的推动下,制造业正处于深刻的数字化转型之中。这场变革的核心在于利用先进技术,如物联网(IoT)、人工智能(AI)、大数据分析和云计算&a…...
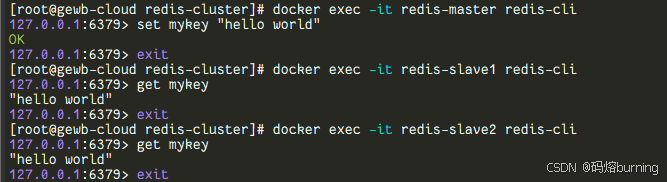
Redis主从复制:告别单身Redis!
目录 一、 为什么需要主从复制?🤔二、 如何搭建主从架构?前提条件✅步骤📁 创建工作目录📜 创建 Docker Compose 配置文件🚀 启动所有 Redis🔍 验证主从状态 💡 重要提示和后续改进 …...
)
数据库管理工具实战:IDEA 与 DBeaver 连接 TDengine(二)
五、DBeaver 连接 TDengine 实战 5.1 安装 DBeaver 下载安装包:访问 DBeaver 官方网站(https://dbeaver.io/download/ ),根据你的操作系统选择合适的安装包。如果是 Windows 系统,下载.exe 格式的安装文件࿱…...

ORM、Mybatis和Hibernate、Mybatis使用教程、parameterType、resultType、级联查询案例、resultMap映射
DAY21.1 Java核心基础 ORM Object Relationship Mapping 对象关系映射 面向对象的程序到—关系型数据库的映射 比如java – MySQL的映射 ORM框架就是实现这个映射的框架 Hibernate、Mybatis、MybatisPlus、Spring Data JPA、Spring JDBC Spring Data JPA的底层就是Hiber…...

简历EasyExcel相关
系列博客目录 文章目录 系列博客目录1.在easyExcel的基础上,应用多线程对数据进行分块有用吗为什么使用多线程对数据进行分块有用?实现方式示例:多线程与 EasyExcel 导出结合的基本思路解释:注意事项:总结:…...
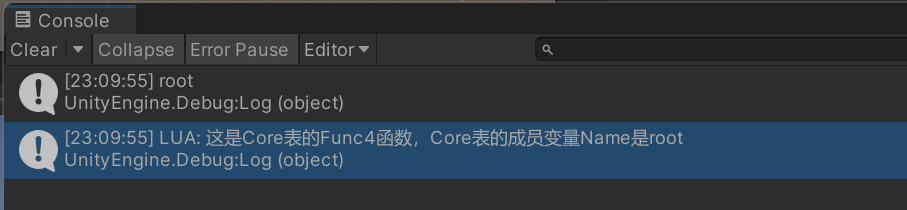
C#调用Lua方法1+C#调用Lua方法2,3
xLua中Lua调用C#代码 原因:C#实现的系统,因为Lua可以调用,所以完全可以换成Lua实现,因为Lua可以即时更改,即时运行,所以游戏的代码逻辑就可以随时更改。 实现和C#相同效果的系统,如何实现&#…...

stable diffusion 量化加速点
文章目录 一、导出为dynamic shape1)函数讲解(函数导出、输出检查)2)代码展示二、导出为static shape1)函数讲解(略)2)代码展示三、序列化为FP32测速1)测速2)代码四、序列化为FP16测速1)测速2)代码同上五、发现并解决解决CLIP FP16溢出,并测速1)如何找到溢出的算子…...
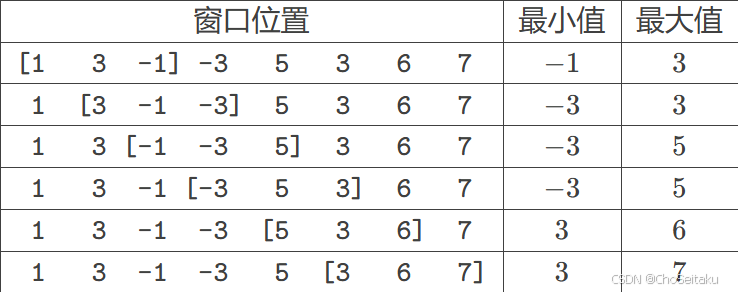
NO.77十六届蓝桥杯备战|数据结构-单调队列|质量检测(C++)
什么是单调队列? 单调队列,顾名思义,就是存储的元素要么单调递增要么单调递减的队列。注意,这⾥的队列和普通的队列不⼀样,是⼀个双端队列。单调队列解决的问题 ⼀般⽤于解决滑动窗⼝内最⼤值最⼩值问题,以…...

通过发票四要素信息核验增值税发票真伪-iOS发票查验接口
发票是企业经济间往来的重要凭证,现如今,随着经济环境的日益复杂,发票造假现象屡禁不止,这使得增值税发票查验成为企业必须高度重视的工作。人工智能时代,发票查验接口犹如一道坚固的防线,助力企业财务守护…...

区块链是怎么存储块怎么找到前一个块
前言:学习区块链的过程中在想怎么管理区块链呢 📌 推荐项目回顾: 👉 Jeiwan 的 blockchain_go 项目 GitHub 地址:https://github.com/Jeiwan/blockchain_go ❓它是怎么存储区块 & 找前一个区块的? 项…...

超详解glusterfs部署
glusterfs部署 GlusterFS 是一个开源的分布式文件系统,旨在提供高性能、高可用性和可扩展性,适用于存储大量数据。它通过将多个存储节点组合成一个统一的文件系统,允许用户透明地访问分布在不同节点上的数据。 主要组件 存储砖块ÿ…...

总结一下常见的EasyExcel面试题
说一下你了解的POI和EasyExcel POI(Poor Obfuscation Implementation):它是 Apache 软件基金会的一个开源项目,为 Java 程序提供了读写 Microsoft Office 格式文件的功能,支持如 Excel、Word、PowerPoint 等多种文件格…...

【JAVA】十、基础知识“类和对象”干货分享~(三)
目录 1. 封装 1.1 封装的概念 1.2 访问限定符 public(公开访问) private(私有访问) 1.3 包 1.3.1 包的概念 1.3.2 导入包中的类 1.3.3 自定义包 2. static成员 2.1 static变量(类变量) 2.1.1 sta…...
DeepSeek+SpringAI家庭AI医生
文章目录 项目架构项目开发内容项目用户用例图项目地址开发环境大模型使用本地:Ollama部署DeepSeek离线与在线api大模型客户端使用 数据库脚本代码deepseek创建定制医生模型 内网互通原则云服务器类型 项目架构 项目开发内容 项目用户用例图 项目地址 FamilyAIDoct…...

PyTorch:解锁AI新时代的钥匙
(前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站)。 揭开PyTorch面纱 对于许多刚开始接触人工智能领域的朋友来说,PyTorch这个名字或许既熟悉又陌生。…...

C++第14届蓝桥杯b组学习笔记
1. 日期统计 小蓝现在有一个长度为 100100 的数组,数组中的每个元素的值都在 00 到 99 的范围之内。数组中的元素从左至右如下所示: 5 6 8 6 9 1 6 1 2 4 9 1 9 8 2 3 6 4 7 7 5 9 5 0 3 8 7 5 8 1 5 8 6 1 8 3 0 3 7 9 2 7 0 5 8 8 5 7 0 9 9 1 9 4 4…...

解锁工业通信:Profibus DP到ModbusTCP网关指南!
解锁工业通信:Profibus DP到ModbusTCP网关指南! 在工业自动化领域,随着技术的不断进步和应用场景的日益复杂,不同设备和系统之间的通讯协议兼容性问题成为了工程师们面临的一大挑战。尤其是在Profibus DP和Modbus/TCP这两种广泛应…...

每日一题(小白)字符串娱乐篇16
分析题意可以了解到本题要求在一串字符串中找到所有组合起来排序递增的字符串。我们可以默认所有字符在字符串中的上升序列是1,从第一个字符开始找,如果后面的字符大于前面的字符就说明这是一个上序列那么后面字符所在的数组加一,如果连接不上…...

面试算法高频01
题目描述 验证回文串 给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。 示例 1: 输入: "A man, a plan, a canal: Panama" 输出: true示例 2: 输入: "race a car" 输出: falseimport…...

如何深刻理解Reactor和Proactor
前言: 网络框架的设计离不开 I/O 线程模型,线程模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等。目前主流的网络框架,在网络 IO 处理层面几乎都采用了I/O 多路复用方案(又以epoll为主),这是服务端应对高并发的性能利器。 …...

java基础 数组Array的介绍
Array 数组定义一维数组多维数组动态数组常见方法Arrays排序1.sort() 排序 2.parallelSort() 排序 查找:binarySearch()填充:fill()比较:equals() 和 deepEquals()复制:copyOf() 和 copyOfRange()转换为列表:asList()转…...

Elixir语言的函数定义
Elixir语言的函数定义 Elixir是一种基于Erlang虚拟机(BEAM)的函数式编程语言,因其并发特性及可扩展性而受到广泛欢迎。在Elixir中,函数是程序的基本构建块,了解如何定义和使用函数对于掌握这门语言至关重要。本文将深…...
我的NISP二级之路-02
目录 一.数据库 二.TCP/IP协议 分层结构 三.STRIDE模型 四.检查评估与自评估 检查评估 自评估 五.信息安全应急响应过程 六.系统工程 七.SSE-CMM 八.CC标准 九.九项重点工作 记背: 一.数据库 关于数据库恢复技术,下列说法不正确的是:…...

k8s1.24升级1.28
0、简介 这里只用3台服务器来做一个简单的集群,当前版本是1.24.17目标升级到1.28.17 地址主机名192.168.160.40kuber-master-1192.168.160.41kuber-master-2192.168.160.42kuber-node-1 因为1.24已经更换过了容器运行时,所以之后的升级相对就会简单&am…...
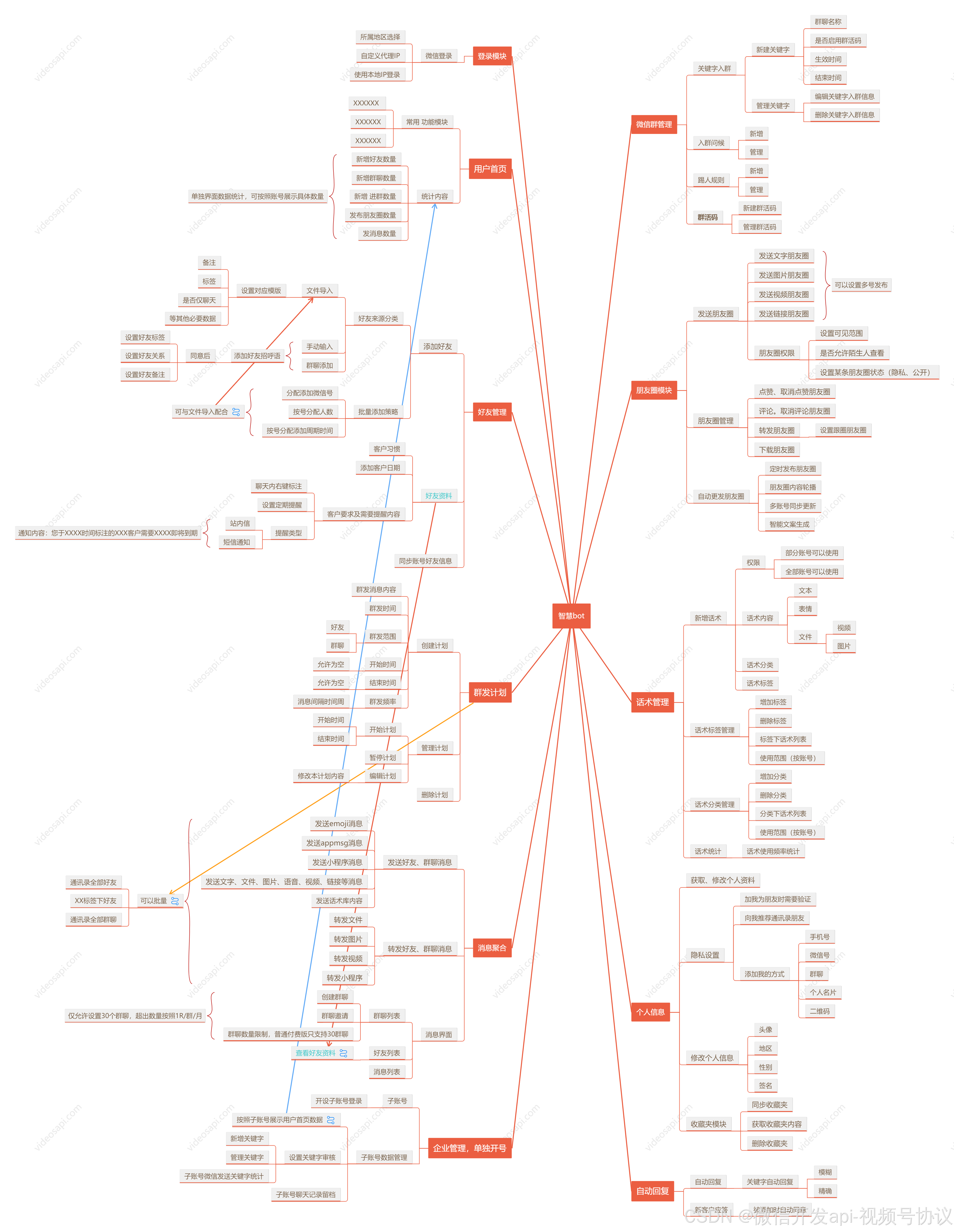
常见的微信个人号二次开发功能
一、常见开发功能 1. 好友管理 好友列表维护 添加/删除好友 修改好友信息(备注、标签等) 分组管理 创建/编辑/删除标签 好友分类与筛选 2. 消息管理 信息发送 支持多类型内容:文本、图片、视频、文件、小程序、名片、URL链接等 附加功…...