Python爬虫第7节-requests库的高级用法
目录
前言
一、文件上传
二、Cookies
三、会话维持
四、SSL证书验证
五、代理设置
六、超时设置
七、身份认证
八、Prepared Request
前言
上一节,我们认识了requests库的基本用法,像发起GET、POST请求,以及了解Response对象是什么。这一节,咱们接着讲讲requests库的一些高级用法,比如怎么上传文件,如何设置Cookies和代理 。
一、文件上传
用requests,不光能模拟提交普通数据,实现文件上传也不在话下,而且操作起来很容易。
示例代码如下:
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post("http://httpbin.org/post", files=files)
print(r.text)要是之前保存过favicon.ico文件,这段代码就能拿它模拟文件上传。其中 httpbin.org 是一个基于 Python 和 Flask 开发的 HTTP 请求与响应服务网站。得注意,favicon.ico得和运行的脚本放在同一个文件夹里。要是想用其他文件模拟,改改代码就行。
运行上述代码,得到类似如下结果:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAABAAEAgIAAAAAAIAAoCAEA......
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "67793",
"Content-Type": "multipart/form-data; boundary=80503f6283733c2f23804bb45111c889",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-67f481ae-65a8a7c32119664b07375e48"
},
"json": null,
"origin": "14.18.236.76",
"url": "http://httpbin.org/post"
}
上面展示的结果,省略了一些内容。网站给出的响应里有files字段,form字段却是空的。这就说明,在文件上传时,会通过专门的files字段来标记上传的文件。
二、Cookies
以前用urllib处理Cookies,代码写起来挺麻烦。但requests不一样,获取和设置Cookies简单多了,操作一步就能搞定。下面通过实例,看看怎么用requests获取Cookies:
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)
for key, value in r.cookies.items():print(key + '=' + value)运行代码,结果如下:
<RequestsCookieJar[<Cookie BD0RZ=27315 for .baidu.com/>, <Cookie bsi=135335943568134141940014NN20303C0FNNNforw.baidu.com/>]>
BDORZ=27315
bsi=135335943568134141940014NN2030302FNNNO
先调用cookies属性,就能得到Cookies,它的数据类型是RequestCookieJar。然后用items()方法把它转成由元组组成的列表,一个个遍历输出每个Cookie的名称和值,这样就完成了Cookie的遍历解析。
用Cookie能维持登录状态。就拿知乎来说,登录知乎后,把Headers里的Cookie内容复制出来(也可以换成你自己的Cookie),设置到Headers里再发送请求,下面是示例代码:
cookie = "_zap=5852a467-84d5-48cd-b719-20cd08603c31; d_c0=a9CTVTvcRBqPTm6b5PunENpMjXLxX-7IGgk=|1744077733; captcha_session_v2=2|1:0|10:1744077734|18:captcha_session_v2|88:QkNNRGpaLzFMQ3NncGFVRXIxb1pSTXZlb3Axb3pCaGNibzlPRFI4cHhEUlpsU3ZyVUF5b0xGL2haSE1oS0xlZw==|d22291e8cfbad9e62e3ecf5b5879bd681e0dc56a87772f4b0a1bd674bfb6dc53; __snaker__id=1aUlWy7fvUjwSn3n; gdxidpyhxdE=%2BtQHnNHABo%2BnC7cQZNp5uprsnqVoGdyWn2QbuZGkZQ4K0Nio4pOnXNCRdPPZGh%2BOAJ8CYYhNxL%2B9bl%5CMngU%5Cb16zCg3nm9eIK%5C6dD0g%2BwE6q%2BUlwgi0dAj6TOMH5%2FqRH%5CYay%2BezxLU01dKTr4k9QPsXGtdRZ%2BkD6xU%5CxS6RKyHTSXxlh%3A1744078635509; q_c1=6573efe200e34e6e9cb0469042bfafde|1744077773000|1744077773000; z_c0=2|1:0|10:1744077775|4:z_c0|92:Mi4xUHZCWVJnQUFBQUJyMEpOVk85eEVHaGNBQUFCZ0FsVk56ZEhoYUFCU1V6WFFiOURmc3VsUnoyd0NtYUdYdTl6N1dB|29591bd5fc696067e49e9509e5fac6fd4663498734ece22be113ccb401123931; _xsrf=ee0ea1ed-31f9-45ab-a923-fc97da5d7663; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1744077734,1744104477; HMACCOUNT=29A6B844A9199C82; SESSIONID=alwM2PqMj7oxC3sRO72GFRwFMAnqV5ntSfBTuVLEheH; JOID=UV0WC0NgDf9xcWbsRRC3LEFGsaVfB2eDPEgwmwMBPJYCMl6ZEX3sAB18ZuFOibPgrBwBunupBMfuYiuxq0TeVS8=; osd=UVoSBkxgCvt8fmbrQR24LEZCvKpfAGOOM0g3nw4OPJEGP1GZFnnhDx17YuxBibTkoRMBvX-kC8fpZia-q0PaWCA=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1744104666; tst=v; BEC=8b4a1b0a664dd5d88434ef53342ae417; unlock_ticket=AOBXjeH6uhYXAAAAYAJVTeLz9Gd8qlW4_xKazEBGBzAktCSlnf9y0w=="
import requestsheaders = {'Cookie': cookie,'Host': 'www.zhihu.com','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36(KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36'
}
r = requests.get('https://www.zhihu.com/zvideo', headers=headers)
print(r.text)
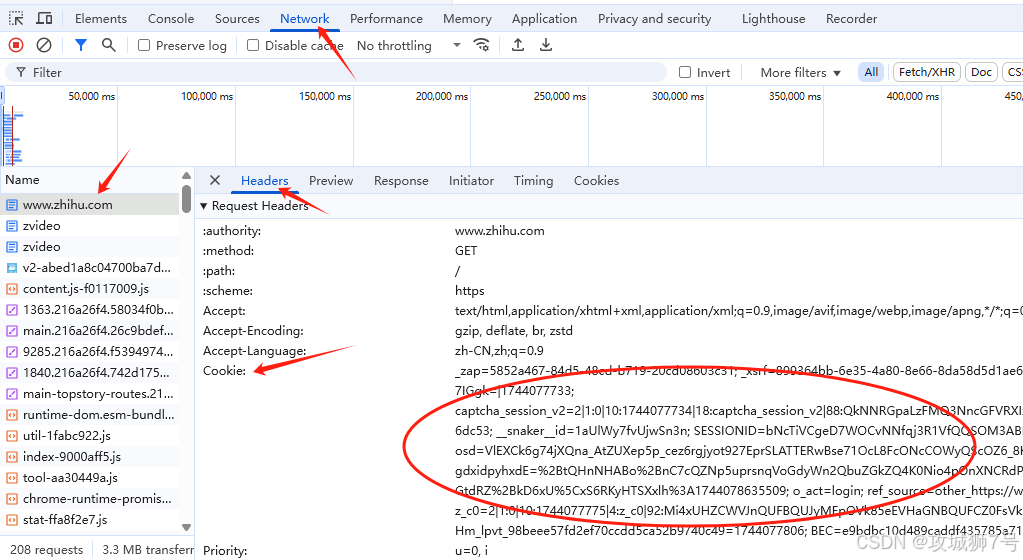
程序运行后,得到的结果里有登录后的页面内容,这就说明成功登录了。
除了前面的方法,我们还能通过cookies参数来设置Cookie。不过,这种方式得先构造RequestsCookieJar对象,还要对获取到的cookies进行分割,操作相对麻烦。下面来看示例:
import requests
cookie = "_zap=5852a467-84d5-48cd-b719-20cd08603c31; d_c0=a9CTVTvcRBqPTm6b5PunENpMjXLxX-7IGgk=|1744077733; captcha_session_v2=2|1:0|10:1744077734|18:captcha_session_v2|88:QkNNRGpaLzFMQ3NncGFVRXIxb1pSTXZlb3Axb3pCaGNibzlPRFI4cHhEUlpsU3ZyVUF5b0xGL2haSE1oS0xlZw==|d22291e8cfbad9e62e3ecf5b5879bd681e0dc56a87772f4b0a1bd674bfb6dc53; __snaker__id=1aUlWy7fvUjwSn3n; gdxidpyhxdE=%2BtQHnNHABo%2BnC7cQZNp5uprsnqVoGdyWn2QbuZGkZQ4K0Nio4pOnXNCRdPPZGh%2BOAJ8CYYhNxL%2B9bl%5CMngU%5Cb16zCg3nm9eIK%5C6dD0g%2BwE6q%2BUlwgi0dAj6TOMH5%2FqRH%5CYay%2BezxLU01dKTr4k9QPsXGtdRZ%2BkD6xU%5CxS6RKyHTSXxlh%3A1744078635509; q_c1=6573efe200e34e6e9cb0469042bfafde|1744077773000|1744077773000; z_c0=2|1:0|10:1744077775|4:z_c0|92:Mi4xUHZCWVJnQUFBQUJyMEpOVk85eEVHaGNBQUFCZ0FsVk56ZEhoYUFCU1V6WFFiOURmc3VsUnoyd0NtYUdYdTl6N1dB|29591bd5fc696067e49e9509e5fac6fd4663498734ece22be113ccb401123931; _xsrf=ee0ea1ed-31f9-45ab-a923-fc97da5d7663; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1744077734,1744104477; HMACCOUNT=29A6B844A9199C82; SESSIONID=alwM2PqMj7oxC3sRO72GFRwFMAnqV5ntSfBTuVLEheH; JOID=UV0WC0NgDf9xcWbsRRC3LEFGsaVfB2eDPEgwmwMBPJYCMl6ZEX3sAB18ZuFOibPgrBwBunupBMfuYiuxq0TeVS8=; osd=UVoSBkxgCvt8fmbrQR24LEZCvKpfAGOOM0g3nw4OPJEGP1GZFnnhDx17YuxBibTkoRMBvX-kC8fpZia-q0PaWCA=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1744104666; tst=v; BEC=8b4a1b0a664dd5d88434ef53342ae417; unlock_ticket=AOBXjeH6uhYXAAAAYAJVTeLz9Gd8qlW4_xKazEBGBzAktCSlnf9y0w=="
cookies = cookie
jar = requests.cookies.RequestsCookieJar()
headers = {'Host': 'www.zhihu.com','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 afari/537.36'
}
for cookie in cookies.split(';'):key, value = cookie.split('=', 1)jar.set(key, value)
r = requests.get("http://www.zhihu.com", cookies=jar, headers=headers)
print(r.text)首先,创建一个RequestsCookieJar对象。接着,把复制来的cookies进行分割,利用set()方法,为每个Cookie设置好对应的key和value。之后,调用requests库的get()方法,将处理好的cookies作为参数传入。由于知乎网站自身的访问规则限制,headers参数是必须设置的,但不用在headers里再单独设置cookie字段。经过测试,用这种方法同样能顺利登录知乎。
三、会话维持
当我们用requests的get()或者post()方法模拟网页请求时,每次请求就相当于开启了一个新会话,这就好比用两个不同的浏览器打开不同页面。举个例子,假如我们先用post()方法登录网站,接着用get()方法去请求个人信息页面,这两次请求就像是在两个独立的浏览器中操作,所以没办法成功获取个人信息。
有的朋友可能会想,通过设置相同的cookies能不能解决这个问题呢?确实可以,不过操作起来特别麻烦。其实,更好的办法是维持同一会话,这就像在同一个浏览器里打开新的选项卡一样。要实现这一点,我们可以借助Session对象。Session对象使用起来很方便,它不仅能维护会话,还能自动帮我们处理cookies相关问题。下面来看具体示例:
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
r = requests.get('http://httpbin.org/cookies')
print(r.text)
上述代码请求了测试网址http://httpbin.org/cookies/set/number/123456789设置cookie,名称为number,内容是123456789,随后请求http://httpbin.org/cookies获取当前Cookies。运行结果如下:
{"cookies": {}
} 可见,直接请求无法获取设置的Cookies。使用Session对象再次尝试:
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
运行结果如下:
{"cookies": {"number": "123456789"}
}这下成功获取数据了!从这就能看出,同一会话和不同会话存在明显差别。在实际应用里,Session用得特别多,尤其是模拟登录成功后,进行下一步操作的时候。比如说,模拟在同一个浏览器中,打开同一网站的不同页面。后面专门有章节,会对这部分内容进行详细讲解。
四、SSL证书验证
requests带有证书验证功能。当我们发送HTTP请求时,它会对SSL证书进行检查。通过verify参数,就能决定要不要执行这项检查。要是不设置verify参数,它默认是True,也就是会自动验证证书。
之前说过,很久以前的12306网站的证书不被官方CA机构认可,访问时就会出现证书验证错误。

下面用requests做个测试:
import requests
response = requests.get("https://www.12306.cn")
print(response.status_code)运行结果如下:
requests.exceptions.SSLError: ("bad handshake: Error([('SSL routines', 'tls process server certificate', 'certificate verify failed')],)")
程序提示SSLError错误,这说明证书验证没通过。当我们请求HTTPS网站,要是证书验证出了问题,就会弹出这个错误。要是想避开这个错误,把verify参数设为False就行。具体代码如下:
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)运行后会打印出请求成功的状态码,但会报出警告:
/usr/local/lib/python3.6/site-packages/urllib3/connectionpool.py:852:InsecureRequestWarning: UnverifiedHTTPS request is being made, Adding certificate verification is strongly advised. See:https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warningsInsecureRequestWarning)
200
可通过设置忽略警告或捕获警告到日志的方式屏蔽该警告。设置忽略警告:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)捕获警告到日志:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)除了上面的方法,我们还能指定本地证书当作客户端证书。这个本地证书,既可以是一个同时包含密钥和证书的文件,也能是一个包含两个文件路径的元组 :
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)上面这些代码只是用来演示的。在实际使用的时候,你得有crt和key这两个文件,并且要把它们的正确路径指出来。还有一点要注意,本地私有证书的key必须处于解密状态,要是key是加密状态,程序不支持。
五、代理设置
测试某些网站时,少量请求能正常获取内容,但大规模爬取时,频繁请求可能导致网站弹出验证码、跳转到登录认证页面,甚至封禁客户端IP。为避免这种情况,需设置代理,可通过proxies参数实现,示例如下:
import requests
proxies = {"http": "http://10.10.1.10:3128","https": "http://10.10.1.10:1080"
}
requests.get("https://www.taobao.com", proxies=proxies)上述代理可能无效,需替换为有效代理进行试验。若代理需要使用HTTP Basic Auth,可使用类似http://user:password@host:port的语法设置代理,示例如下:
import requests
proxies = {"http": "http://user:password@10.10.1.10:3128/"
}
requests.get("https://www.taobao.com", proxies=proxies)除基本的HTTP代理外,requests还支持SOCKS协议的代理。使用前需安装socks库:
pip3 install 'requests[socks]'安装后即可使用SOCKS协议代理,示例如下:
import requests
proxies = {'http':'socks5://user:password@host:port','https':'socks5://user:password@host:port'
}
requests.get("https://www.taobao.com", proxies=proxies)六、超时设置
要是你自己电脑的网络不好,或者服务器那边响应特别慢,甚至压根没反应,那你可能要等很久才能收到响应,弄不好最后还会报错。为了避免一直傻等,我们可以设定一个超时时间。意思就是,过了这个时间还没收到服务器的回应,程序就报错。这可以通过timeout参数来设置,例子如下:
import requests
r = requests.get("https://www.taobao.com", timeout =1)
print(r.status_code)上面代码里把超时时间设成了1秒,要是1秒内没收到响应,就会抛出异常。请求其实分两个阶段,一个是连接服务器(connect),另一个是读取数据(read)。刚才设置的timeout是这两个阶段加起来的总超时时间。要是你想分别给这两个阶段设置超时时间,可以传一个元组进去:
r = requests.get('https://www.taobao.com', timeout=(5, 11.30))若想永久等待,可将timeout设置为None,或不设置(默认值为None),用法如下:
r = requests.get('https://www.taobao.com', timeout=None)或直接不加参数:
r = requests.get('https://www.taobao.com')七、身份认证

访问网站时可能遇到认证页面,requests自带身份认证功能,示例如下:
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:5000', auth=HTTPBasicAuth('username', 'password'))
print(r.status_code)
若用户名和密码正确,请求时自动认证成功,返回200状态码;若认证失败,返回401状态码。直接传递HTTPBasicAuth类作为参数较繁琐,requests提供了更简便的写法,直接传一个元组,它会默认使用HTTPBasicAuth类进行认证,代码可简写为:
import requests
r = requests.get('http://localhost:5000', auth=('username', 'password'))
print(r.status_code)此外,requests还提供其他认证方式,如OAuth认证。使用OAuth认证需安装oauth包,安装命令如下:
pip3 install requests_oauthlib使用OAuth1认证的方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECRET', 'USER_OAUTH_TOKEN', 'USER_OAUTH_TOKEN_SECRET')
requests.get(url, auth=auth)更多详细功能可参考requests_oauthlib的官方文档https://requests-oauthlib.readthedocs.org/。
八、Prepared Request
在介绍urllib时,可将请求表示为数据结构,各参数通过一个对象表示。requests中也有类似功能,对应的数据结构是Prepared Request。示例如下:
from requests import Request, Session
url = "http://httpbin.org/post"
data = {'name': 'germey'}
headers = {'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)引入Request后,用url、data和headers参数构造Request对象,再调用Session的prepare_request()方法将其转换为Prepared Request对象,最后调用send()方法发送请求。运行结果如下:
{"args": {},"data": "","files": {},"form": {"name": "germey"},"headers": {"Accept": "*/*","Accept-Encoding": "gzip, deflate","Connection": "close","Content-Length": "11","Content-Type": "application/x-www-form-urlencoded","Host": "httpbin.org","User-Agent": "Mozilla/5.0(Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36"},"json": null,"origin": "182.32.203.166","url": "http://httpbin.org/post"
}从结果能看出,我们通过这种方式实现了和普通POST请求一样的效果。有了Request对象后,我们可以把每个请求当成一个独立个体。这在进行队列调度时特别方便,后续我们会利用它来构建一个Request队列。
这一节给大家介绍了requests的一些高级用法,在后面实际项目中,这些用法会经常用到,大家要熟练掌握。要是还想了解更多requests的用法,可以查看它的官方文档:http://docs.python-requests.org/ 。
参考学习书籍:Python 3网络爬虫开发实战
相关文章:
Python爬虫第7节-requests库的高级用法
目录 前言 一、文件上传 二、Cookies 三、会话维持 四、SSL证书验证 五、代理设置 六、超时设置 七、身份认证 八、Prepared Request 前言 上一节,我们认识了requests库的基本用法,像发起GET、POST请求,以及了解Response对象是什么。…...

Maven的安装配置-项目管理工具
各位看官,大家早安午安晚安呀~~~ 如果您觉得这篇文章对您有帮助的话 欢迎您一键三连,小编尽全力做到更好 欢迎您分享给更多人哦 今天我们来学习:Maven的安装配置-项目管理工具 目录 1.什么是Maven?Maven用来干什么的?…...
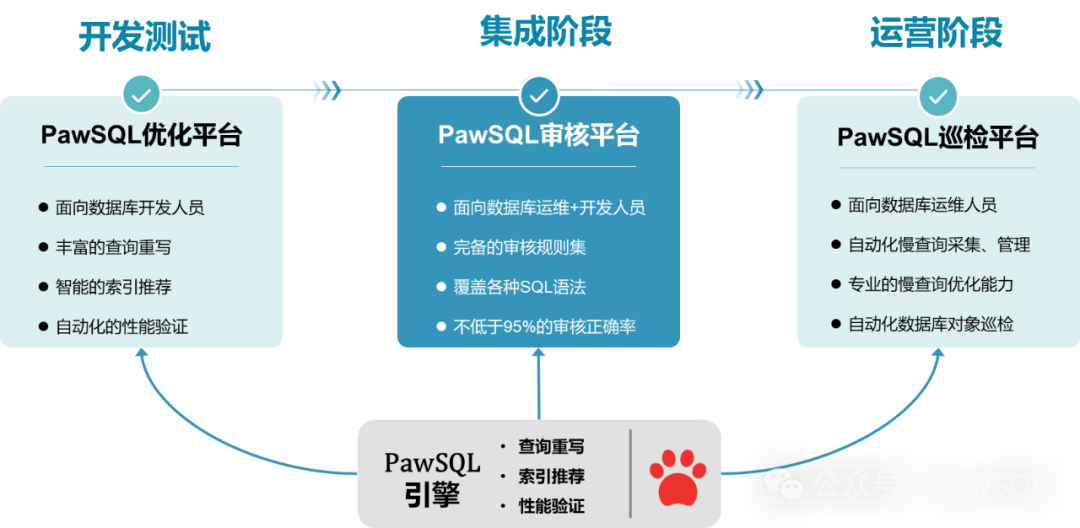
智能 SQL 优化工具 PawSQL 月度更新 | 2025年3月
📌 更新速览 本月更新包含 21项功能增强 和 9项问题修复,重点提升SQL解析精度与优化建议覆盖率。 一、SQL解析能力扩展 ✨ 新增SQL语法解析支持 SELECT...INTO TABLE 语法解析(3/26) ALTER INDEX RENAME/VISIBLE 语句解析&#…...
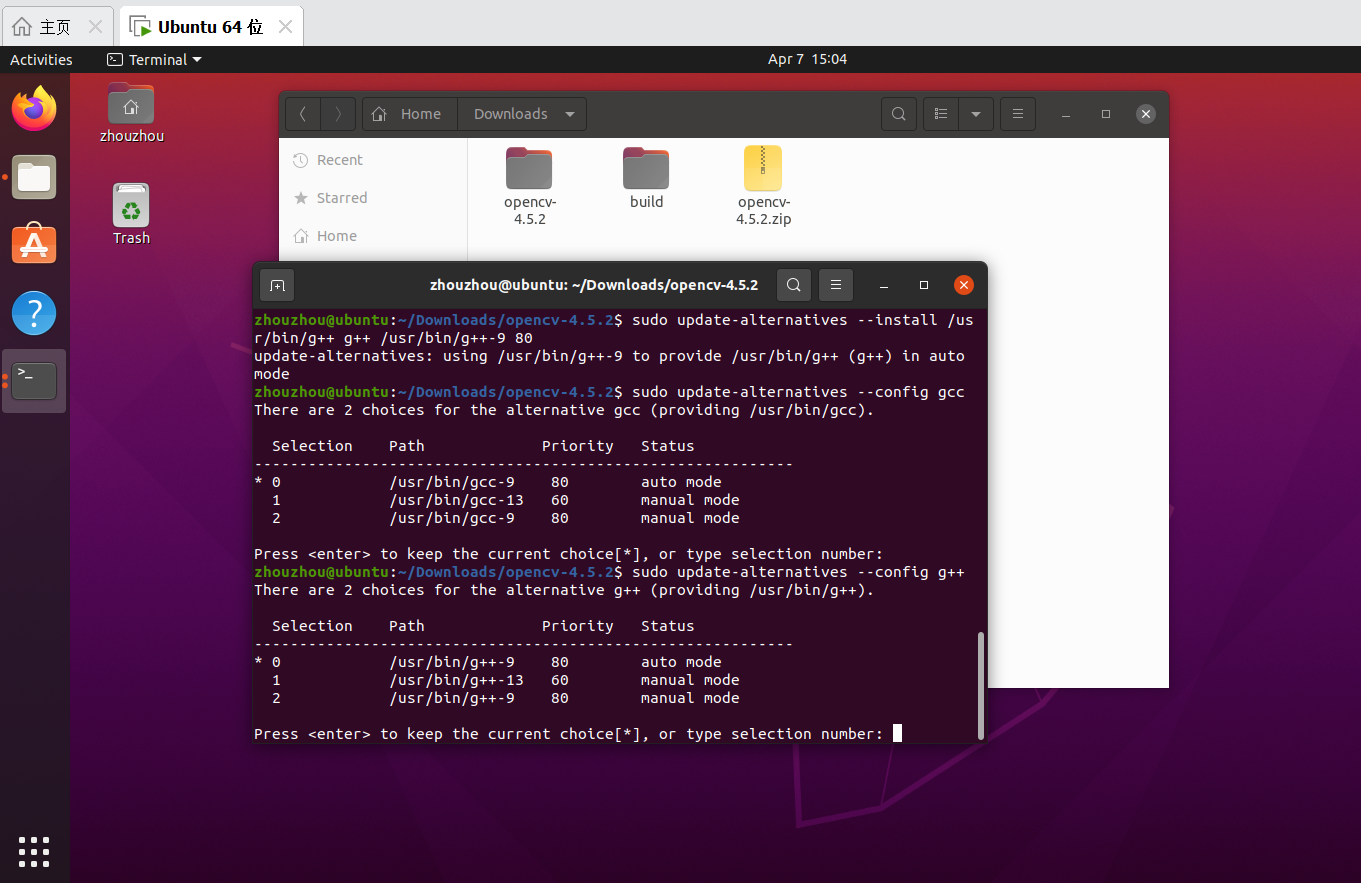
Ubuntu虚拟机编译安装部分OpenCV模块方法实现——保姆级教程
Ubuntu虚拟机的安装过程可以查看另一篇文章:VMware安装Ubuntu虚拟机实现COpenCV代码在虚拟机下运行教程-CSDN博客 目前我们已经下载好了OpenCV,这里以OpenCV4.5.2为例。 在内存要求尽可能小的情况下,可以尝试只编译安装代码中使用到的OpenC…...

find指令中使用正则表达式
linux查找命令能结合正则表达式吗 find命令要使用正则表达式需要结合-regex参数 另,-type参数可以指定查找类型(f为文件,d为文件夹) rootlocalhost:~/regular_expression# ls -alh 总计 8.0K drwxr-xr-x. 5 root root 66 4月 8日 16:26 . dr-xr-…...
)
Java Web从入门到精通:全面探索与实战(二)
Java Web从入门到精通:全面探索与实战(一)-CSDN博客 目录 四、Java Web 开发中的数据库操作:以 MySQL 为例 4.1 MySQL 数据库基础操作 4.2 JDBC 技术深度解析 4.3 数据库连接池的应用 五、Java Web 中的会话技术ÿ…...

基于大模型的阵发性室上性心动过速风险预测与治疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与目标 1.3 研究方法与数据来源 二、阵发性室上性心动过速概述 2.1 定义与分类 2.2 发病机制与流行病学 2.3 临床表现与诊断方法 三、大模型在阵发性室上性心动过速预测中的应用 3.1 大模型技术原理与特点 3.2 模型构…...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
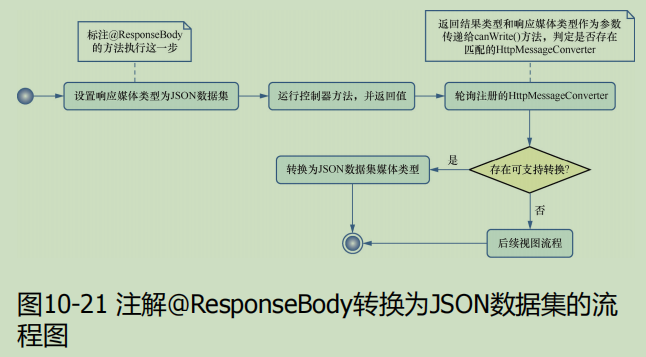
spring mvc @ResponseBody 注解转换为 JSON 的原理与实现详解
ResponseBody 注解转换为 JSON 的原理与实现详解 1. 核心作用 ResponseBody 是 Spring MVC 的一个注解,用于将方法返回的对象直接序列化为 HTTP 响应体(如 JSON 或 XML),而不是通过视图解析器渲染为视图(如 HTML&…...

TDengine.C/C++ 连接器
简介 C/C 开发人员可以使用 TDengine 的客户端驱动,即 C/C 连接器(以下都用 TDengine 客户端驱动表示),开发自己的应用来连接 TDengine 集群完成数据存储、查询以及其他功能。TDengine 客户端驱动的 API 类似于 MySQL 的 C API。…...

[docker] 简单操作场景
Docker的简单操作场景 1 安装 暂时没空写~ 2 登陆 一共4步: ~$ sudo docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d765d4c1eb5f ubuntu:24.04 "/bin/bash" …...

skynet.rawcall使用详解及应用场景
目录 核心特性函数原型使用场景场景 1:高性能二进制传输(如文件转发)场景 2:自定义序列化协议(如 Protocol Buffers)场景 3:跨服务共享内存(避免拷贝) 配套接收方实现与 …...
使用SpringSecurity下,发生重定向异常
使用SpringSecurity下,发生空转异常 环境信息: Spring Boot 3.4.4 , jdk 17 , springSecurity 6.4.4 问题背景: 没有自定义controller ,改写了login 页面,并且进行了成功后的跳转处理…...
)
gbase8s之逻辑导出导入脚本(完美版本)
该脚本dbexport.sh用于快速导出库和导入库(使用多并发unload,和多并发dbload的方式) #!/bin/sh #脚本功能:将数据导出成文本,迁移至其他实例 #最后更新时间:2023-12-19 #使用方法: #1.执行该脚…...
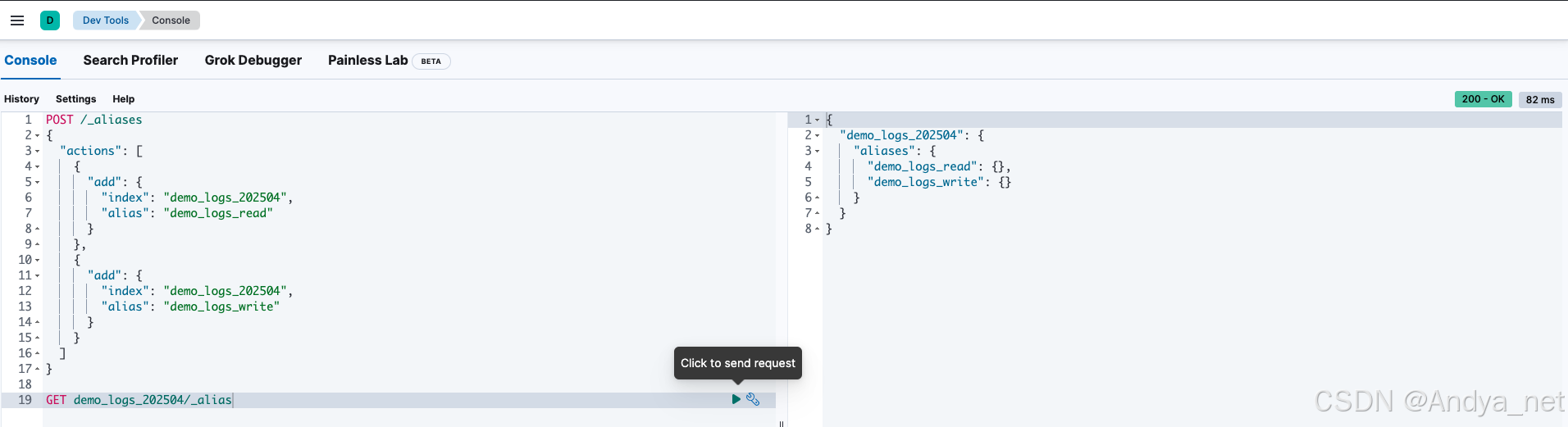
Elasticsearch | ES索引模板、索引和索引别名的创建与管理
关注:CodingTechWork 引言 在使用 Elasticsearch (ES) 和 Kibana 构建数据存储和分析系统时,索引模板、索引和索引别名的管理是关键步骤。本文将详细介绍如何通过 RESTful API 和 Kibana Dev Tools 创建索引模板、索引以及索引别名,并提供具…...

【Easylive】视频删除方法详解:重点分析异步线程池使用
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 方法整体功能 这个deleteVideo方法是一个综合性的视频删除操作,主要完成以下功能: 权限验证:检查视频是否存在及用户是否有权限删除核心数据删除&…...
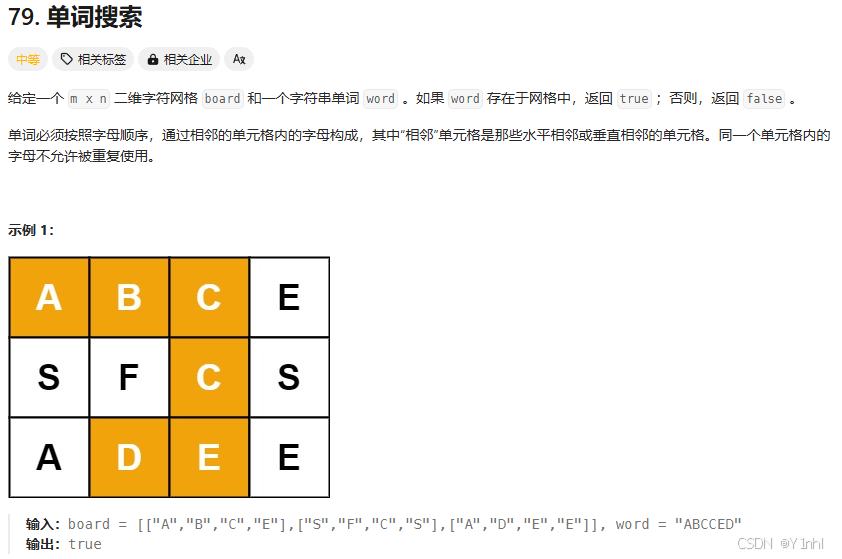
力扣hot100_回溯(2)_python版本
一、39. 组合总和(中等) 代码: class Solution:def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:ans []path []def dfs(i: int, left: int) -> None:if left 0:# 找到一个合法组合ans.append(pa…...

SGLang实战:从KV缓存复用到底层优化,解锁大模型高效推理的全栈方案
在当今快速发展的人工智能领域,大型语言模型(LLM)的应用已从简单对话扩展到需要复杂逻辑控制、多轮交互和结构化输出的高级任务。面对这一趋势,如何高效地微调并部署这些大模型成为开发者面临的核心挑战。本文将深入探讨SGLang——这一专为大模型设计的高…...
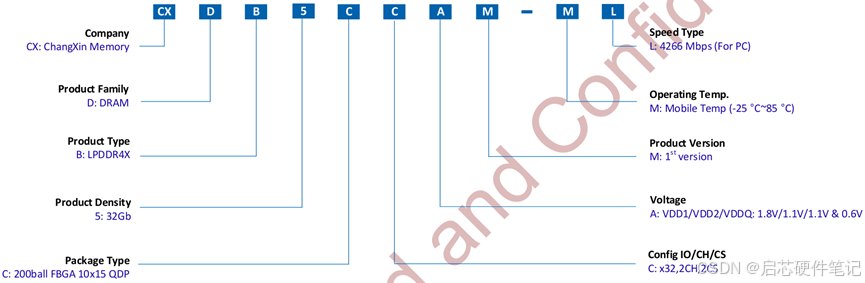
LPDDR4内存颗粒命名规则全解析:三星、镁光、海力士、南亚、长鑫等厂商型号解码与选型指南
由于之前DDR的系列选型文章有很好的反馈,所以补充LPDDR4低功耗内存的选型和命名规则,总结了目前市面上常用的内存,供硬件工程师及数码爱好者参考。 在智能手机、平板电脑和低功耗设备中,LPDDR4 SDRAM凭借其高带宽、低功耗特性成为…...

特权FPGA之Johnson移位
完整代码: module johnson(clk,rst_n,led,sw1_n,sw2_n,sw3_n);input clk; //时钟信号,50MHz input rst_n; //复位信号,低电平有效 output[3:0] led; //LED控制,1--灭…...
)
网络安全小知识课堂(最终完结版)
网络安全入门 :从 “小白” 到 “守护者” 的蜕变之旅 写在完结之际 历经 13 篇的深度探索,我们从 DDoS 攻击的 “流量洪水” 一路闯关到 HTTPS 的 “加密堡垒”,揭开了网络安全世界的层层面纱。感谢每一位读者的陪伴与互动,你们…...

2025年AI生成引擎搜索发展现状与趋势总结
2025年AI生成引擎搜索发展现状与趋势总结 一、国内外AI生成引擎搜索发展现状 1. 国内动态 社交搜索崛起:小红书2024年Q4日均搜索量达6亿次,用户更依赖社交平台UGC内容进行决策(如购物、旅游场景)&#…...

【杂谈】Godot4.4导出到Android平台(正式导出)
学博而后可约,事历而后知要。 目录 一、准备二、Gradle构建三、配置Java SDK四、配置Android SDK五、配置密钥 一、准备 本文在前文【杂谈】Godot4.4导出到安卓平台(调试导出)的基础上,进行正式导出。调试导出并不是真正的编译导…...

VBA将Word文档内容逐行写入Excel
如果你需要将Word文档的内容导入Excel工作表来进行数据加工,使用下面的代码可以实现: Sub ImportWordToExcel()Dim wordApp As Word.ApplicationDim wordDoc As Word.DocumentDim excelSheet As WorksheetDim filePath As VariantDim i As LongDim para…...

基于AI设计开发出来的业务系统是什么样的?没有菜单?没有表格?
基于AI设计开发出的业务系统仍然会包含菜单、表格等传统UI元素,但AI技术会显著改变它们的实现方式和交互逻辑。以下是具体分析: 一、传统元素的持续存在 功能刚需性 • 菜单承担着系统导航的核心功能,表格则是结构化数据展示的基础载体。根…...
)
C++ -异常之除以 0 问题(整数除以 0 编译时检测、整数除以 0 运行时检测、浮点数除以 0 编译时检测、浮点数除以 0 运行时检测)
一、整数除以 0(编译时检测) 1、演示 #include <iostream>using namespace std;int main() {int result 10 / 0;cout << result << endl;return 0; }程序无法运行,输出结果 error C2124: 被零除或对零求模2、演示解读 …...

数字足迹管理(DFM):你的网络隐身指南
数字足迹管理(DFM):你的网络隐身指南 你可能不知道,你的姓名、电话、住址正在网上被“明码标价” ——而这一切,可能只是因为你点过外卖、寄过快递,甚至注册过一个网站。 一、什么是数字足迹管理&#…...

如何避免“过度承诺”导致的验收失败
如何避免“过度承诺”导致的验收失败?关键在于: 评估可行性、设置合理目标、高频沟通反馈、阶段性验收、做好风险管理。其中设置合理目标至关重要,很多团队往往在项目初期为迎合客户或领导而报出“最理想方案”,忽略了资源、技术及…...

MySQL学习笔记集--游标
游标 在MySQL中,游标(Cursor)是一种数据库对象,它允许您逐行处理查询结果集。游标通常与存储过程一起使用,因为它们需要在存储过程或函数中声明和操作。游标的使用涉及几个步骤:声明游标、打开游标、从游标…...

紧跟数字人热潮:123 数字人分身克隆系统源码部署与风口洞察
在当今数字化浪潮中,数字人技术无疑已成为最具活力与潜力的领域之一,正以迅猛之势席卷多个行业,重塑着人们的交互方式与商业运作模式。C 站作为技术交流的前沿阵地,汇聚了众多关注前沿科技的开发者与技术爱好者,今天来…...