StarRocks 助力首汽约车精细化运营

作者:任智红,首汽约车大数据负责人
更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/334%201%202/ffbe5
导读:
本文整理自首汽约车大数据负责人任智红在 StarRocks 年度峰会上的演讲,介绍了 StarRocks 在公司内部的应用。主要业务场景包括:
运效诊断与干预:实现秒级数据接入和计算,分钟级生成和应用标签,提高了数据处理效率。
供需平衡联动:支持实时计算数百亿数据,确保分钟级联动,提升供需匹配效率。
自助查询与多维分析:查询性能从分钟级延迟提升到秒级,显著降低了数据开发和维护成本。
引入StarRocks的背景
首汽约车公司及业务介绍
首汽约车成立于 2015 年,主营网约车业务,曾为冬奥会、冬残奥会等国家级重点会议提供出行服务。公司最初仅在北京运营,随后逐步扩展至全国。目前,我们的业务已覆盖全国 200 多个城市。
首汽约车专注于特色化业务和差异化运营,服务用户涵盖 To C 和 To B 两大类。我们不仅面向普通消费者,也为商务人士提供高品质出行服务,满足不同用户的需求,包括服务敏感型和价格敏感型群体。
首汽约车数据架构变化
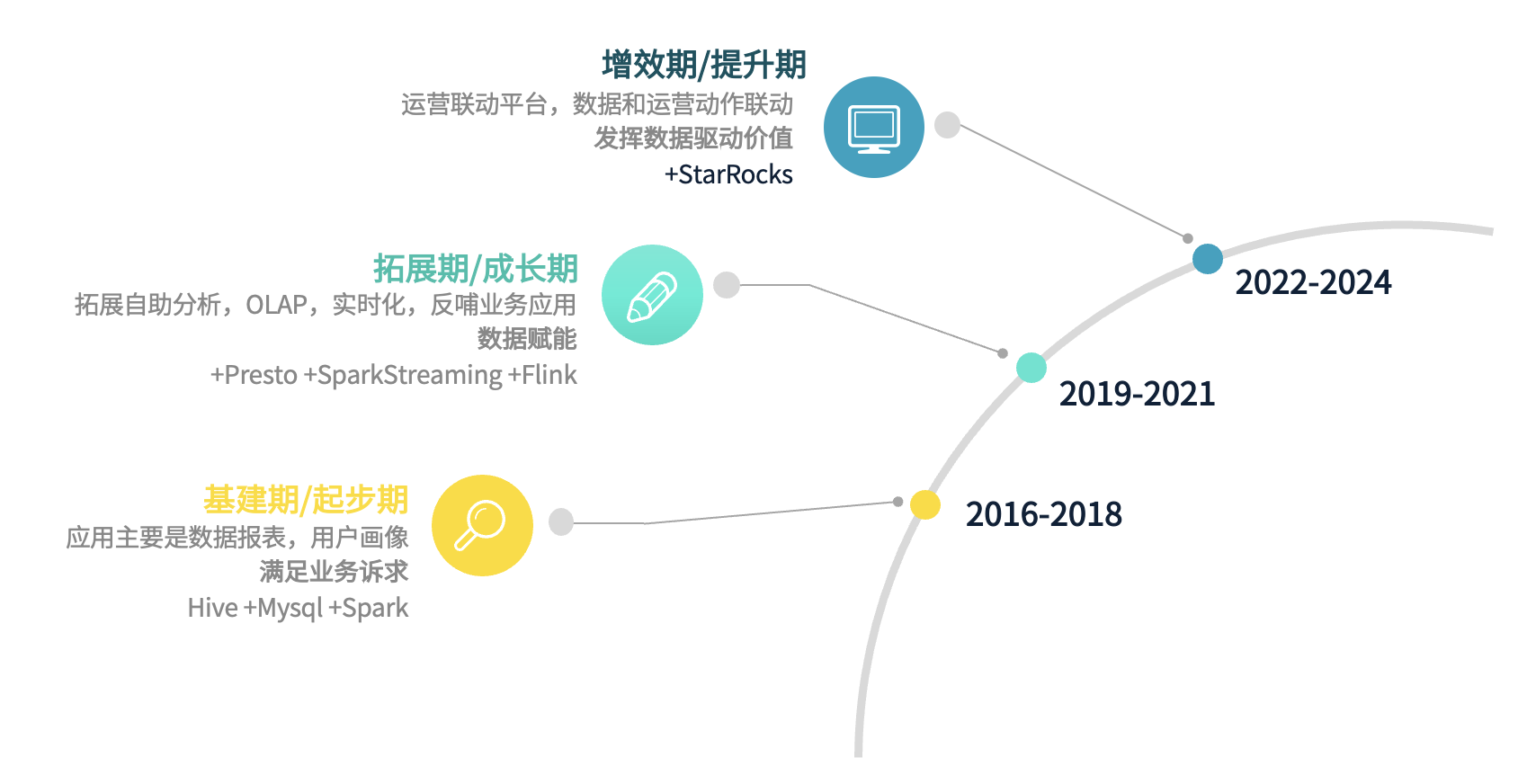
我们的数据架构经历了多个重要发展阶段,与大多数公司类似。最初,我们专注于满足业务报表的数据需求,处于数据基础建设期。随后,我们引入更多组件,进入快速发展期,数据开始反哺业务,发挥赋能作用。
目前,我们通过引入 StarRocks,对底层数据进行了标准化与一致化,进入增效期,充分发挥数据的驱动价值,使其与业务产生更紧密的联动。由于数据架构的发展路径在业内较为相似,这里不再展开详细介绍。
精细化运营带来的挑战
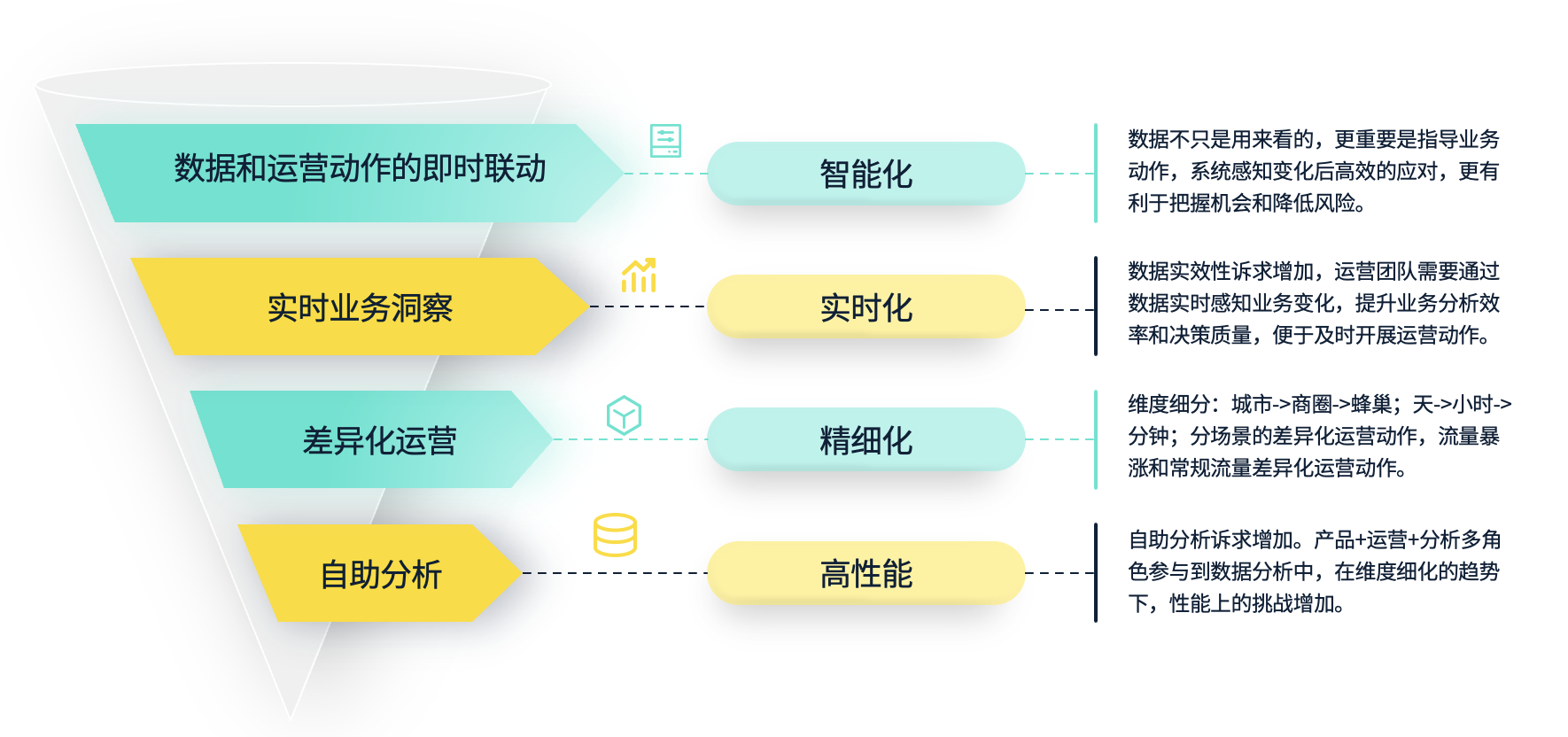
随着业务逐步拓展,开设的城市数量增加,需求来源和种类也变得更加多样,运力来源和总量也在不断扩大。我们进入了精细化运营阶段,这为数据建设和使用带来了许多挑战。首先,更多的角色将参与数据分析过程。其次,数据的视角和维度将更加丰富和细化,这对数据处理和查询提出了更高的要求。此外,数据的时效性要求也更为严格。业务需要更加实时的数据来感知变化并做出快速决策。这种实时联动不仅仅是通过报表展示数据,业务在看到数据后做出相应的动作,更是通过系统化的自动联动,实现智能化调控效果。
引入 StarRocks 的原因
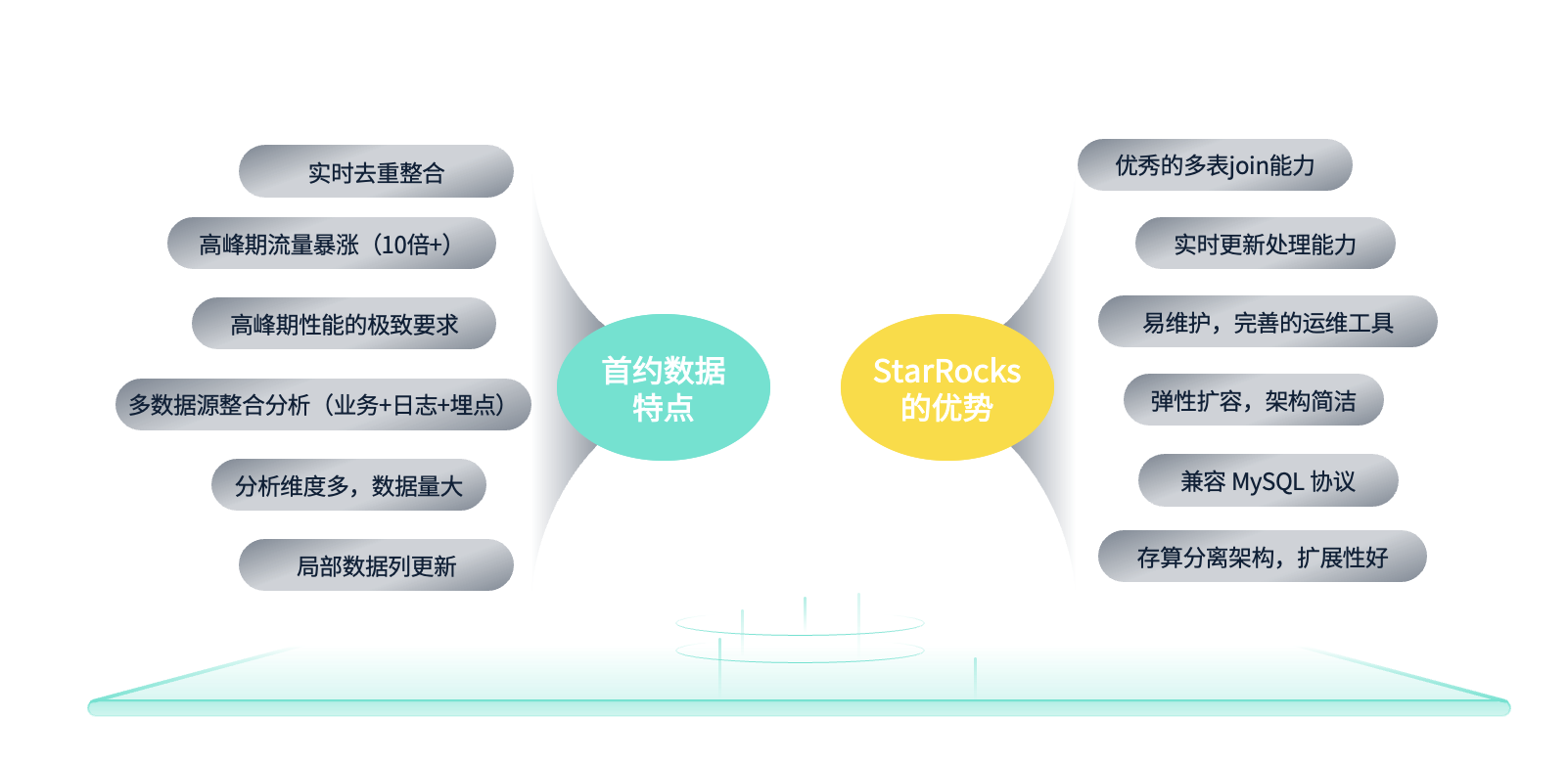
在这样的背景下,经过选型调研后,我们最终选择了引入 StarRocks。选择 StarRocks 不仅因为它的产品特性和优异性能,还因为它与我们首汽约车的数据特点有着完美的契合。例如,我们的数据存在明显的高峰期和低谷期,尤其是在高峰期,相比低谷期,我们的数据量可能会增长十倍以上。与此同时,很多策略主要依赖于高峰期的流量暴增,因此我们对高峰期的性能要求非常高。
另外,我们的数据源和种类也非常丰富,涵盖司机端数据、乘客端数据、第三方数据、通过埋点采集的端上操作数据、业务过程数据以及策略服务日志类数据等。我们的数据处理复杂度也较高,涉及很多实时数据整合的场景,也有很多历史数据的局部更新场景。这些特性完全依赖于 StarRocks 的产品特性和性能优势,能够很好地支撑我们的需求。
StarRocks的基建情况和应用创新
基于StarRocks的实时生态系统
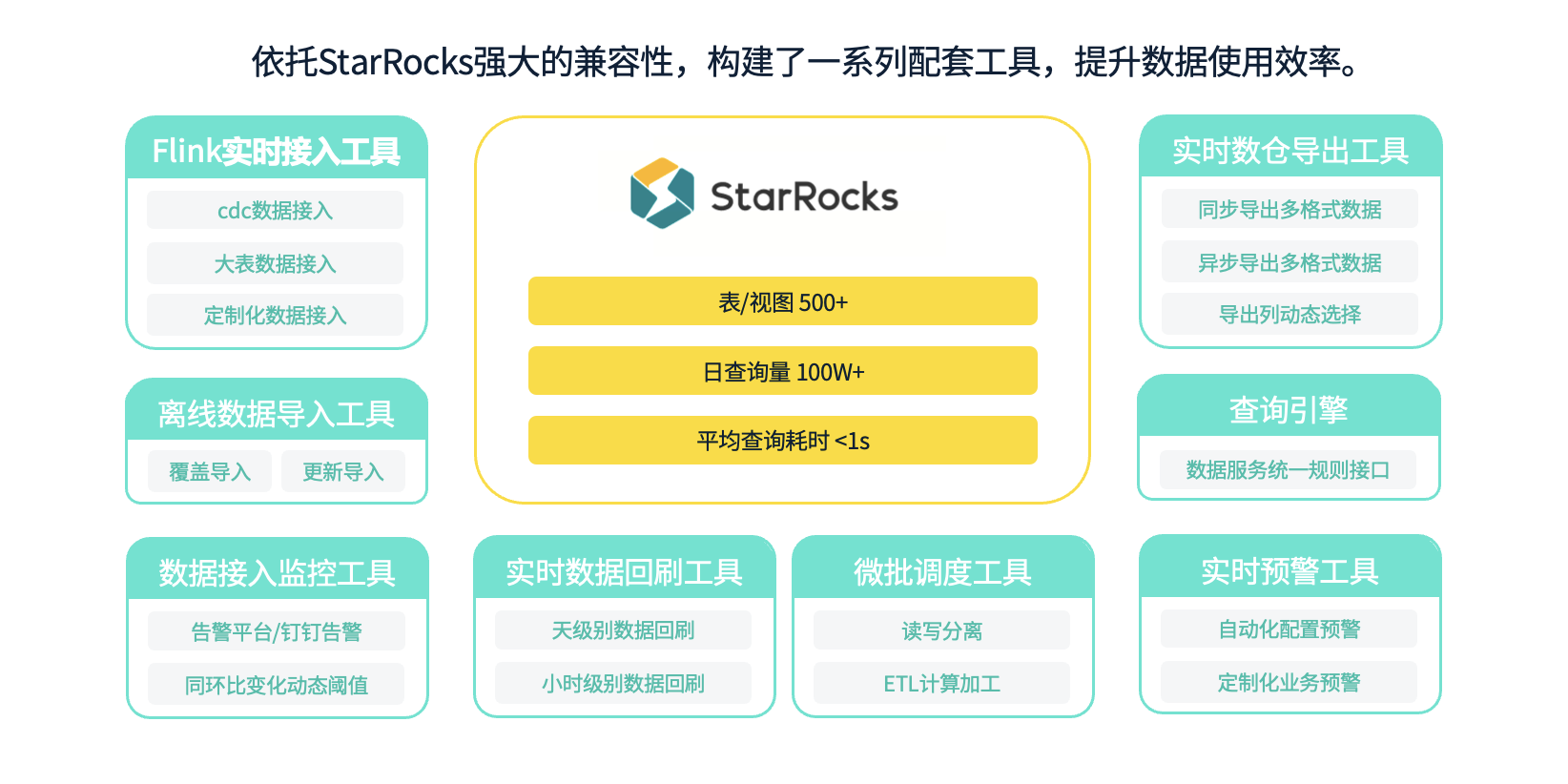
我们按照标准的数据建设规范,依托 StarRocks 构建了一套完整的数据体系,包括明细数据、主题数据以及视图类数据等。目前,这套体系已经广泛应用于我们的多个业务场景中,涉及算法策略、报表工具、自助查询工具以及实时预警工具等。现在,日查询量已经突破百万次,涵盖系统性调用和人工探索性查询,整体查询性能能够控制在秒级别。
除了数据建设本身,我们还借助 StarRocks 强大的兼容性,建立了一系列配套工具。例如,在数据接入方面,我们基于 Flink 构建了分场景的数据接入工具,支持离线数据导入工具,并且具备数据接入效率监控工具。在数据处理过程中,我们有微批调度工具,当数据出现轻微延迟时,能够自动补充数据或回刷。在应用方面,我们有统一查询引擎、配置化预警工具以及数据导出工具等。这些数据建设和配套工具共同构成了一个完整的数据生态体系。
StarRocks 的业务场景
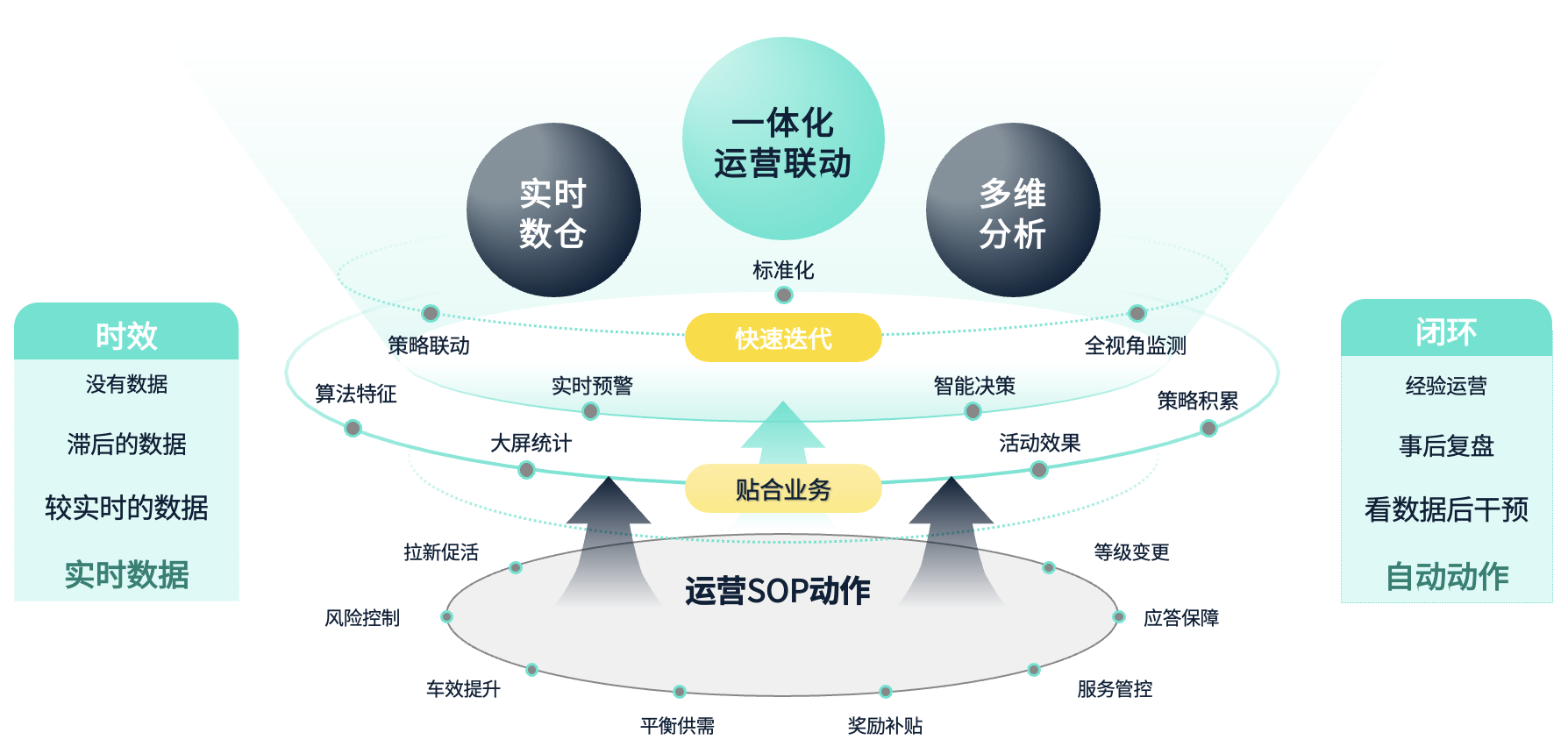
现在,StarRocks 在我们内部的应用贯穿了整个业务的运营生命周期。在我们公司,数据和业务是相互联动、相辅相成的。一方面,业务场景的落地往往会对数据建设提出新的需求。例如,当业务需要实施新的策略时,可能需要相应的数据支持。另一方面,数据能力的提升和突破也会推动业务动作的细化和标准化。例如,最初我们在司机风险管理上主要依赖事后管控手段,但随着实时处理能力的突破和增强,我们已经逐步从事后管控扩展到事前防护和事中拦截。当某些问题有迹象时,我们会通过预警和引导手段进行管理,丰富了对司机的管理手段。
我们的数据理念是通过工具化方式提升数据使用的闭环性和时效性,从而提高数据与业务的协同效率。
场景举例1——运效诊断与干预
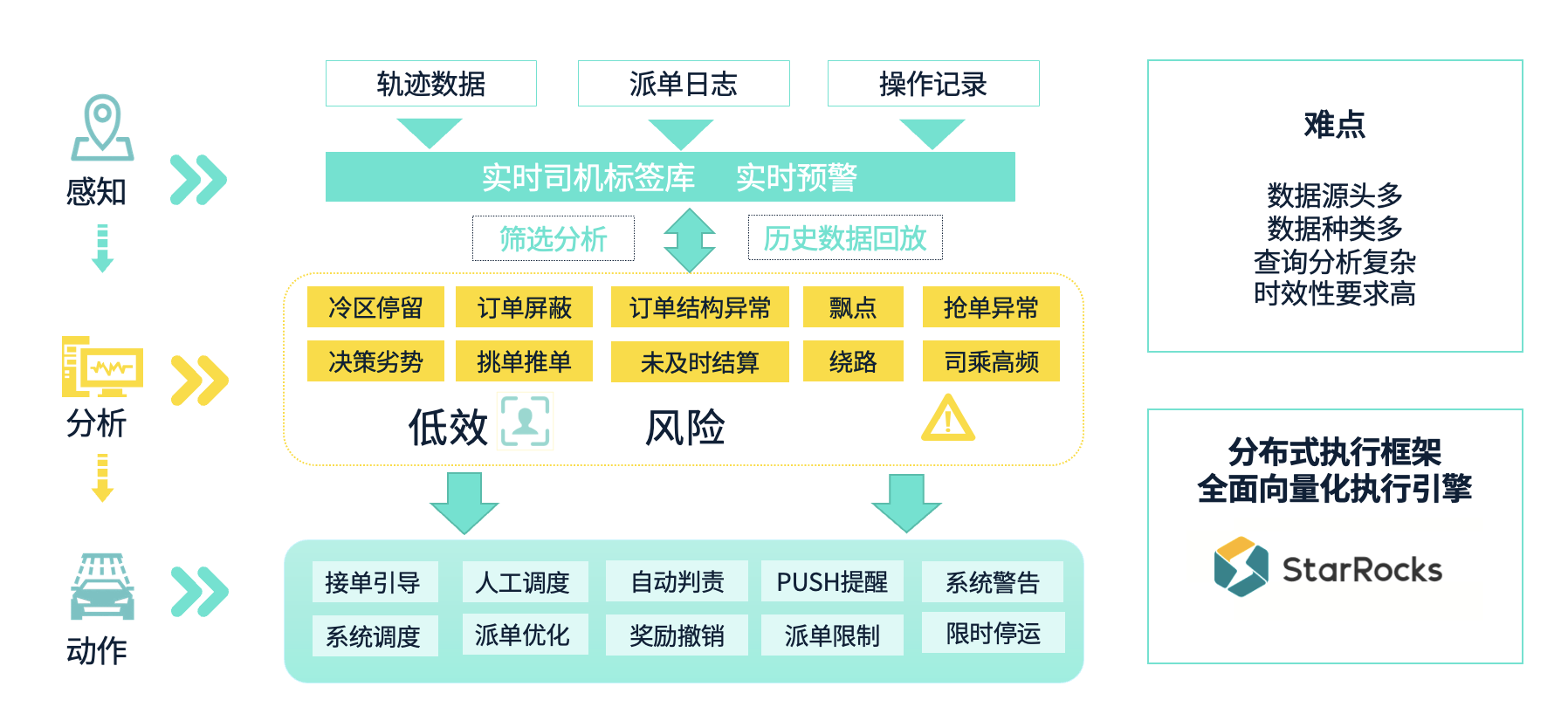
第一个场景是运效的诊断与干预。运力是网约车业务的核心运营主体,通常我们对运力的运营目标是提升其运营效率,并管控服务风险。因此,我们需要精准、快速、高效地识别哪些是高效的,哪些是有风险的。
要全面感知和识别运力的各种问题,涉及到多个数据源和多种数据类型,这正是这个场景的主要难点。数据进来后,我们还需要进行复杂的计算,以统计出许多行为并进行标签化。基于这些标签,我们进一步在业务动作上进行联动。整体的查询分析复杂度高,且时效性要求强,这是该场景的另一个挑战。依托 StarRocks 的分布式执行框架、全面向量化的执行引擎等一系列处理能力,我们成功地支撑了这个场景的需求。
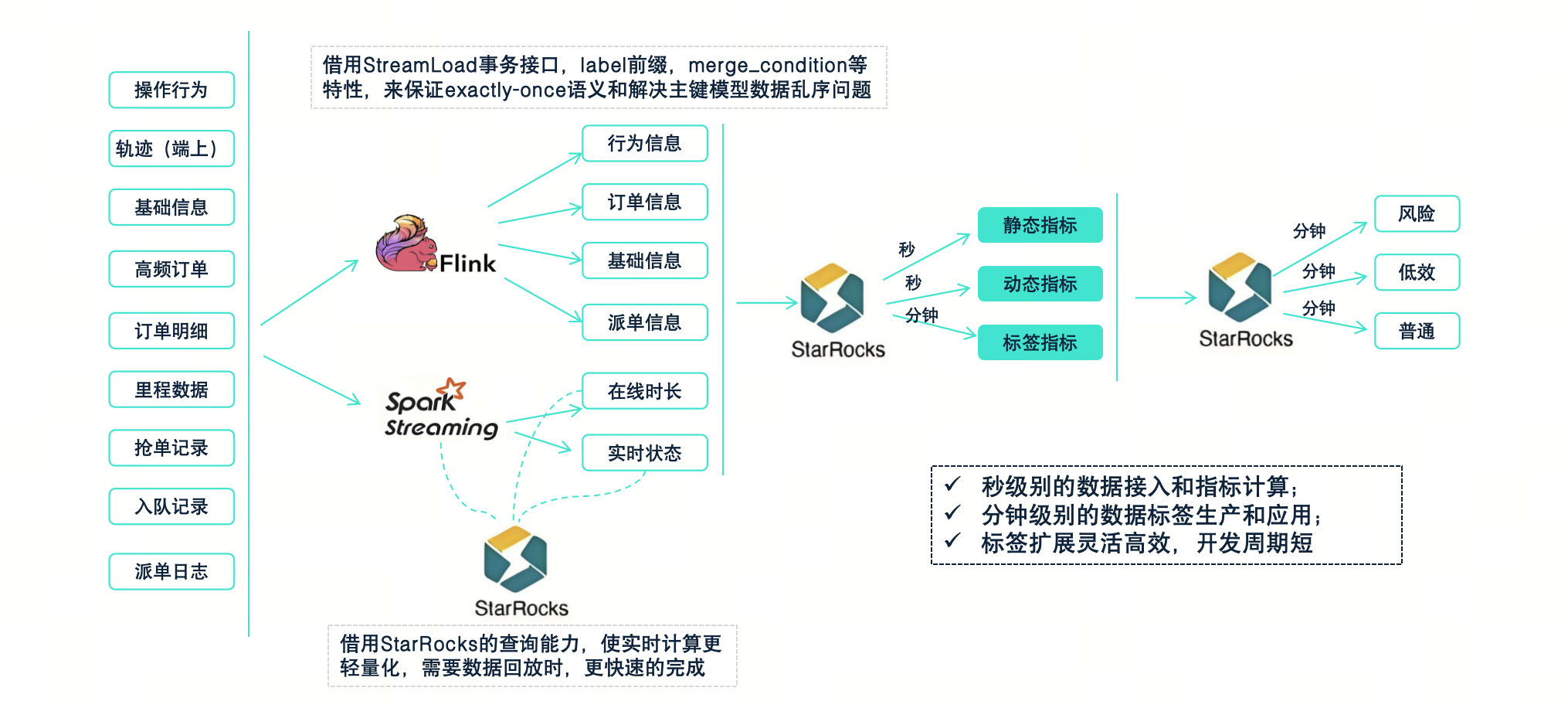
在具体的数据处理流程中,首先需要对各种与实际相关的数据进行接入和整合。例如,C端用户的操作行为日志、行为轨迹、基础信息、业务过程中的订单数据以及派单日志等。在这个过程中,依靠 StarRocks 的一些特性,确保了数据处理的效率、一致性和准确性。
在这个处理过程中,部分数据会临时写入 StarRocks,借助其查询能力,使得整体的实时计算更加轻量化。当涉及数据回放时,StarRocks 也能够快速完成。在数据整合后,我们进一步加工生成静态指标和动态指标。例如,司机当前的空闲时长、在冷区的停留时长、异常轨迹点数量以及被订单异常过滤的次数。这些指标会进一步加工,形成各类司机标签,例如冷区停留、挑单、推单等。这些标签会实时联动到相应的业务动作中,进行相应的管理。例如,对于冷区停留的司机,我们可能会通过系统调度将其引导到周围的热区接单,从而提高其运营效率。对于有风险或服务问题的司机,我们会实时联动派单策略,对其派单进行限制或降权,以保障整体的服务质量。
这个场景的实现效果是使我们能够对各种类型和来源的数据进行秒级数据接入和计算,并在分钟级别生成和应用标签。这一切都依赖于 StarRocks 底层优异的特性。此外,由于我们的数据和业务不断扩展,若新增数据源或标签,我们可以按照这套模式高效、灵活地进行开发和落地。
场景举例2——供需平衡联动
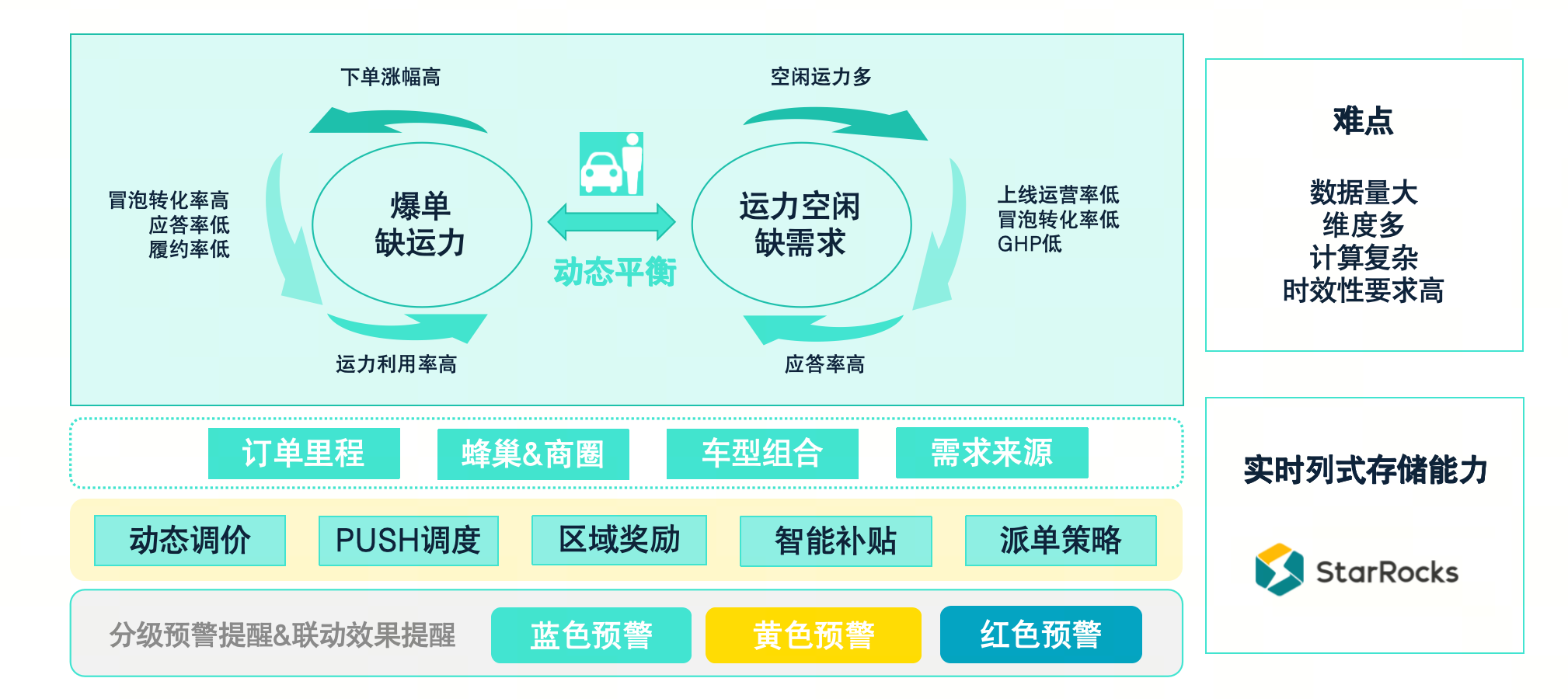
第二个场景是供需平衡联动。网约车是一个双边业务,除了供需两侧各自的运营和增长,平衡供需之间的匹配效率和匹配关系也是一个非常重要的线上策略。与上一个场景相比,这个场景的数据来源可能没有那么多,但数据量和维度种类却非常多。如果我们要精准识别供需情况,我们不仅需要当前时刻的实时数据,还需要与实时数据相关的历史数据,因此整体的数据量会非常庞大。
此外,如果要进行精细化调控,随着每个维度的扩展,数据量会暴增。例如,从城市级别的调控细化到商圈和蜂巢级别的调控,单一维度的数据量可能会扩展千倍之多。如果要进行更精细的调控,还需要依赖订单的结构、来源、车型组合等综合维度,这样整体的数据量会大幅膨胀。
数据接入和初步处理后,我们还会关联到相应的业务动作。例如,可能需要对某些区域进行局部调价、进行 PUSH 调度、区域奖励或智能补贴等。这些动作的计算复杂度较高,并且时效性要求非常高,这也是该场景的主要难点之一。依靠 StarRocks 的实时存储能力及其相关的实时处理能力,我们的场景性能得到了很好的保障。
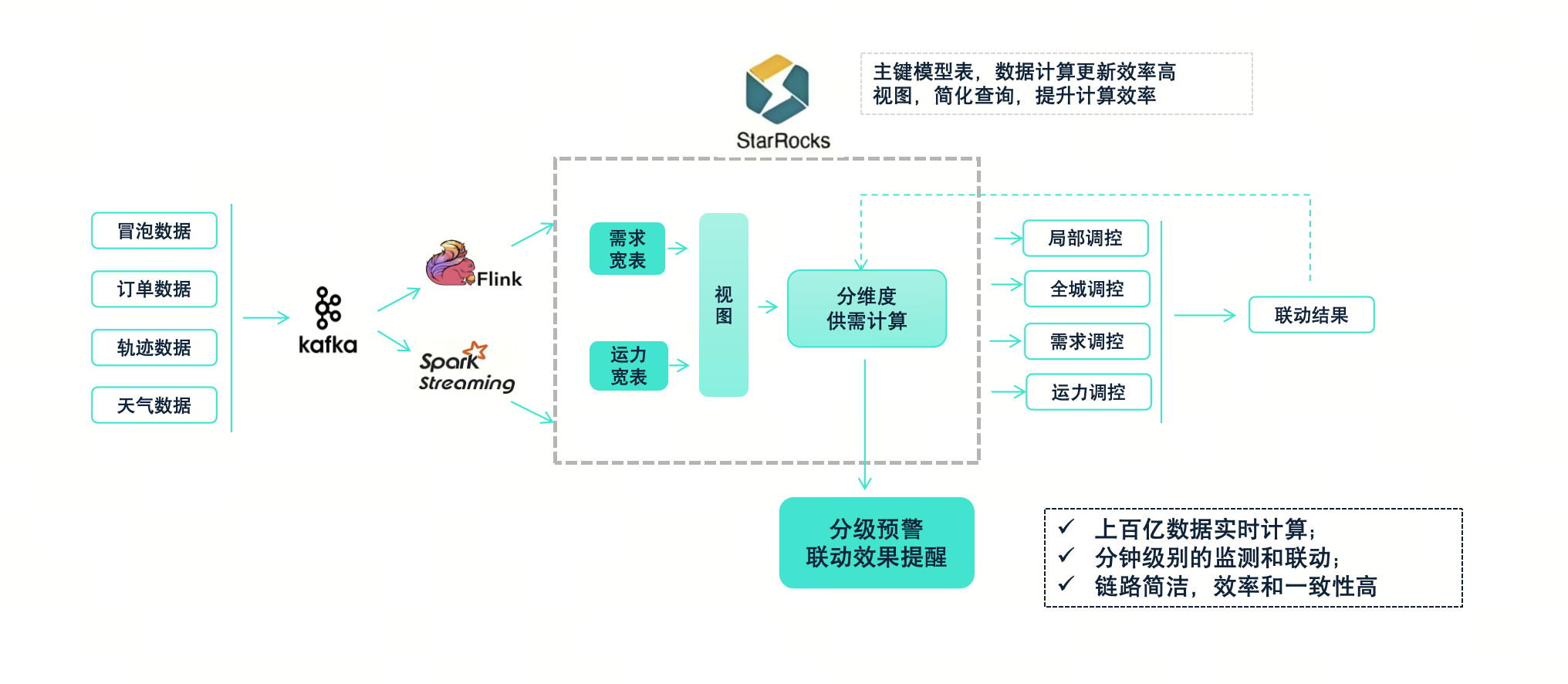
在具体的数据处理过程中,首先我们会整合各类数据,然后将其直接写入需求宽表和运力宽表,这两个表是该场景中的核心基础表。这些表采用主键模型表,确保数据更新计算的效率。在这两个表之上,我们会构建一系列视图,通过这些视图来简化查询并提升计算效率。
在 StarRocks 中,数据的写入和查询是并行进行的。得益于 StarRocks 的高效性能,我们在数据写入的同时还能确保较高的查询性能,从而保障了该场景的正常运作。在需求宽表和视图之上,我们会进行分维度的供需计算。计算结果会帮助我们确定调控范围和对象,判断是进行全程调控还是局部调控,确定是主要调控需求端还是运力端。
这些调控结果有的会作为算法模型的特征输入,直接调用算法模型;有的则会作为规则模型的输入,直接联动到相应的策略中。
最后,联动效果会实时回写到我们的分维度数据中,经过整合和打包,形成分级预警和联动效果提醒。通过钉钉和我们的运营平台,这些结果会传递给业务方,使他们能够感知到效果。整体实现效果是:
-
能够实时计算数百亿的数据,这些数据不仅包括实时数据,还包含与实时数据相关联的历史数据。
-
能够实现分钟级别的监测和联动。我们许多复杂策略已经能够实现分钟级别的联动。例如,我们能够在分钟级别实现大单降价、小单涨价,热区到冷区的需求涨价,以及冷区到热区的需求涨价。可以调整冷区派单半径的扩大,热区派单半径的缩小。整体目标是将高质量订单最大化转化,并将运力留在需求最热的区域。
-
整体的数据处理链路简洁,联动过程不需要借助额外的组件来实现,绝大多数数据直接从 StarRocks 中查询,确保了执行效率和一致性。
场景举例3——自助查询&多维分析
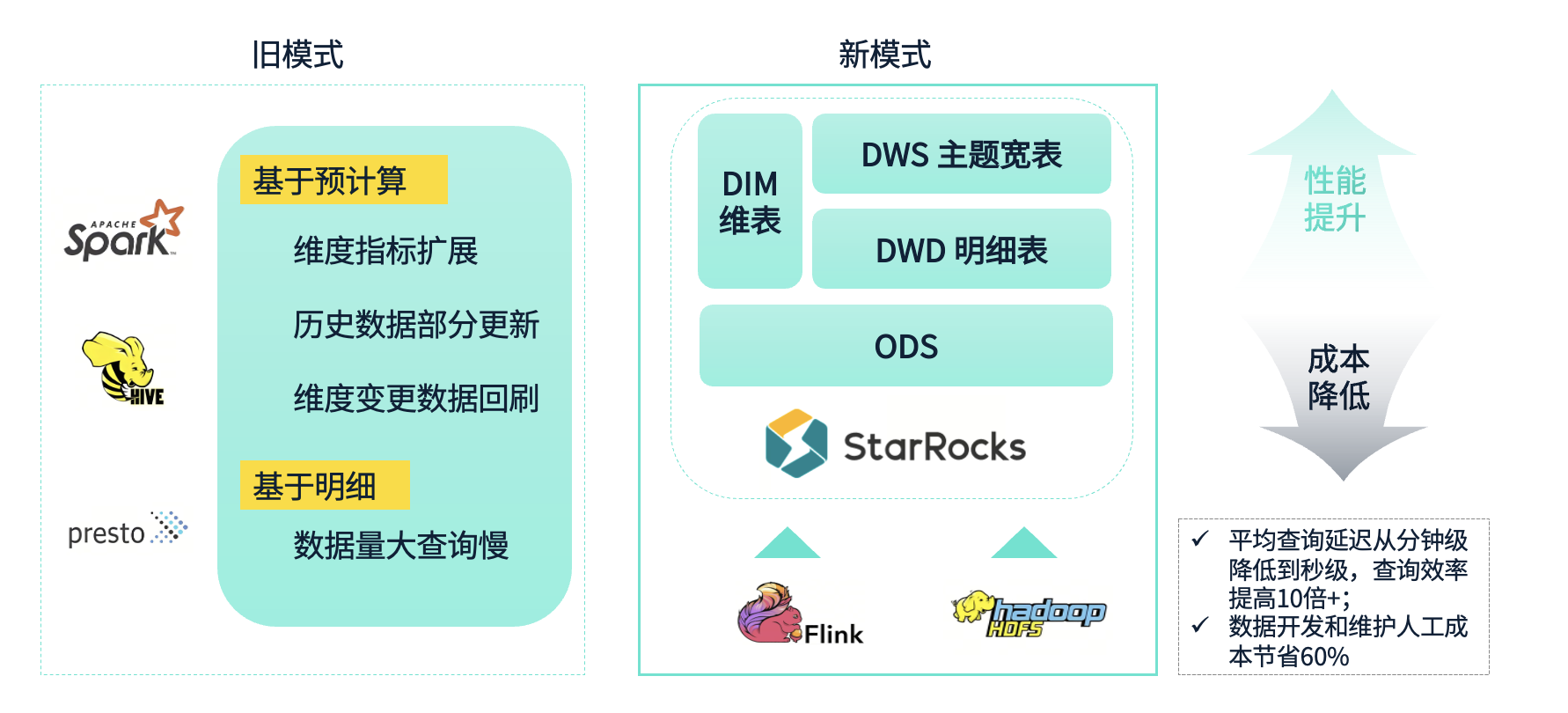
自助多维分析是我们内部非常重要的一个场景,最初我们使用了两种模式来进行数据查询和分析:预计算模式和明细查询模式。
预计算模式:主要通过 Spark 和 Hive 来进行数据的汇总和计算,然后将计算结果生成统计表。由于这种模式是通过空间换时间,能够减少查询时的计算负担。然而,随着业务的快速发展,维度数量的迅速增加,开发和维护成本也随之激增。特别是当我们需要进行历史数据的局部更新时,预计算模式带来了巨大的压力。如果业务进行了调整,比如城市或需求分类的重新调整,预计算模式就需要重新处理大量的数据,导致数据回刷的成本非常高。
明细查询模式:为了应对预计算模式的限制,我们还使用了基于明细查询的模式,这主要依赖 Presto 进行查询。这种模式在维度扩展上更加灵活,能够快速响应多维度查询。但当数据量变得庞大时,查询性能显得有些不足,尤其是在查询量和维度不断增加的情况下,性能瓶颈变得越来越明显。尽管我们尝试通过预计算来优化性能,但随着维度数量的扩展,整体查询性能还是面临了很大的挑战。
依靠我们在 StarRocks 上建立的这些数据体系和相应的一些工具,我们形成了一个全新的自助多维分析模式。
一些数据通过我们的一些主题数据表直接进行查询,一些数据则通过明细表和维度表进行实时校验查询,另外还有一些数据是基于视图进行查询。这种灵活高效的查询方式,满足了不同场景下的多维分析需求,最终实现了性能提升和成本降低的效果。
-
在性能方面,我们从最初的旧模式(分钟级延迟)转变为新模式(秒级查询),查询性能提升了数十倍。
-
在成本方面,数据开发和维护的成本也大幅降低,初步估算节省了至少一半。通过这种优化,数据开发团队可以从低效和重复性的工作中抽离出来,专注于更有价值的探索。
随着查询性能瓶颈的突破,更多的人能够参与到自助分析过程中,这不仅促进了精细化运营的开展,也增强了数据与业务之间的联动,推动了公司数据驱动的业务发展。
成果总结
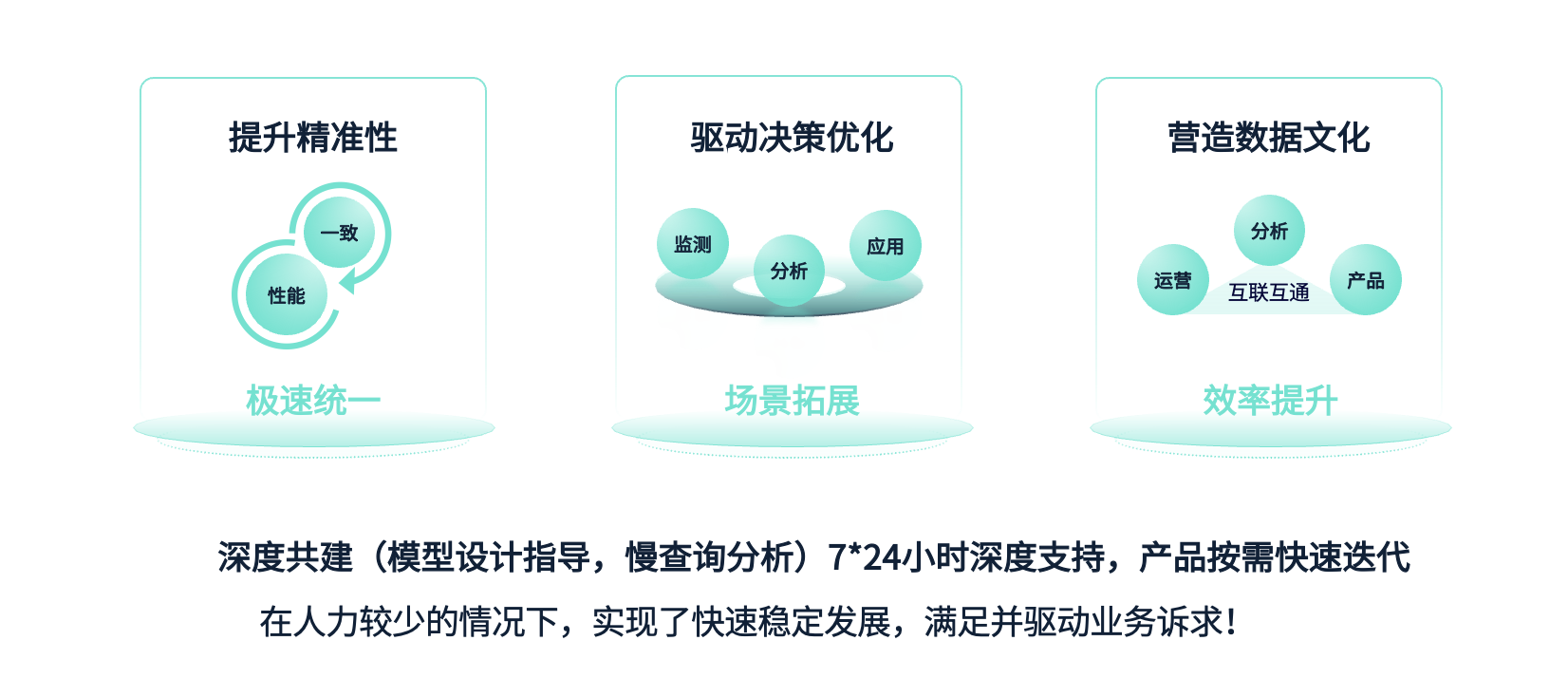
总结来说,基于我们引入 StarRocks 以及在底层建设上的努力,我们在性能统一、场景拓展和效率提升方面取得了显著突破。特别感谢 StarRocks 的技术团队,他们在模型设计指导、慢查询分析等方面提供了大量专业支持。由于我们的许多业务都涉及线上应用,技术团队在我们需要时能够及时响应和支持,这对我们的项目非常关键。
另外,结合我们数据的特点,StarRocks 能够按需快速迭代,满足我们的一些定制化需求。总结起来,在 StarRocks 强大的产品特性、性能优势以及技术团队的大力支持下,我们在人力相对有限的情况下,实现了基础建设的快速稳步发展,并成功驱动了业务需求的满足。很多以前想做却无法实现的场景现在得以实施,例如对风险司机的实时管控;之前难以做到的高成本场景现在也能以低成本执行,比如我们的自助多维分析工具。
未来规划
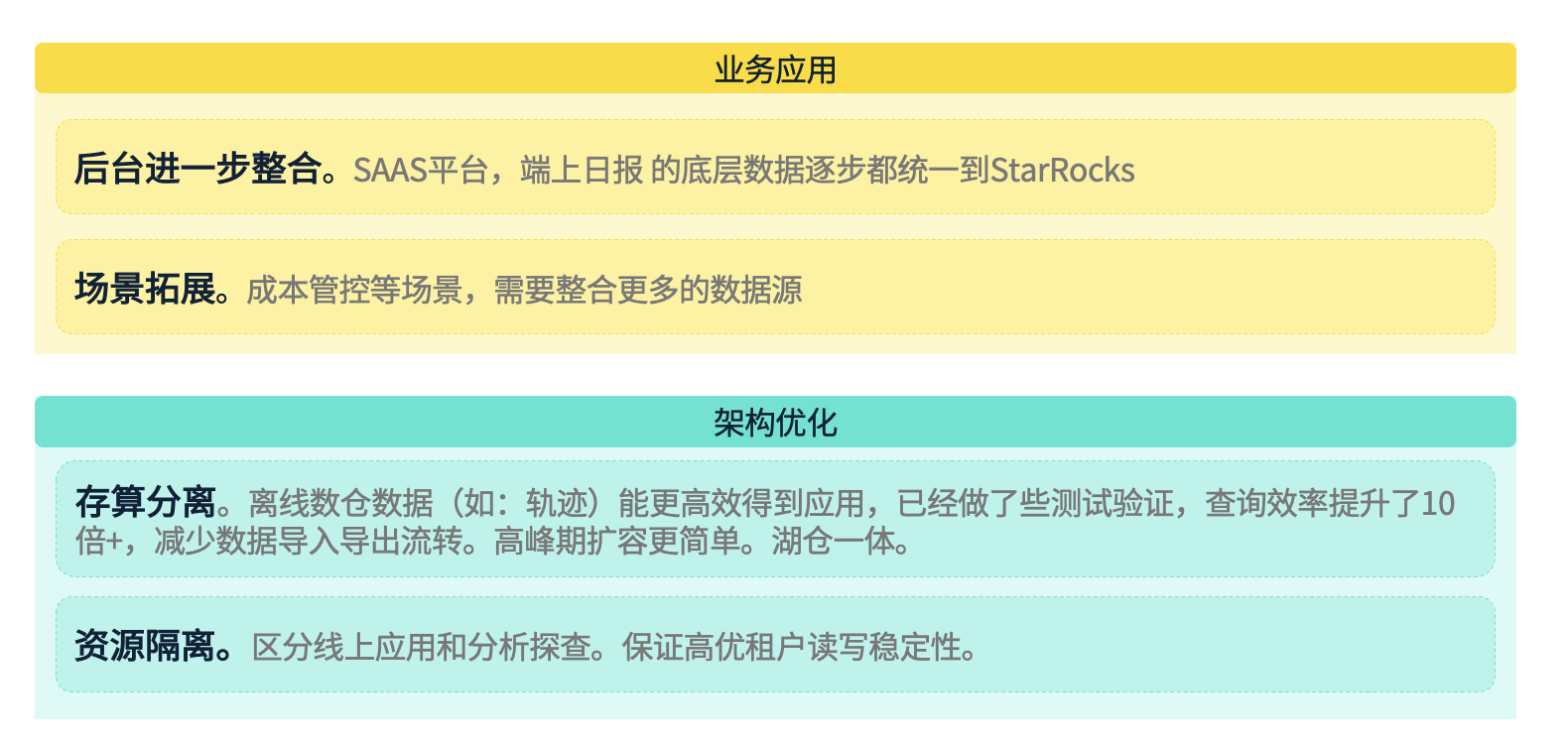
首先,在业务层面,我们计划进一步整合后台系统,充分发挥 StarRocks 的性能优势。例如,针对我们对外提供的加盟商 SAAS 平台,以及 C 端和乘客端的数据展示或数据统计,未来这些都可能逐步切换到 StarRocks 平台。
其次,场景方面,我们将持续拓展现有场景,并结合业务发展的需求,构建新的应用场景。例如,目前我们正在与财务团队合作,开发业务成本的实时管控功能。这些场景的扩展需要我们进一步加强数据基础建设,同时对 StarRocks 资源进行投入和扩展。
在架构层面,我们将重点推进存算分离。我们的业务已经积累了大量的离线数据,如何高效地利用这些数据是我们接下来的关键任务。初步设想是在离线数据中引入数据湖组件,并利用 StarRocks 作为统一的查询引擎来提高数据处理效率,同时减少数据在导入和导出过程中的流转成本。存算分离之后,我们也计划提升在高峰期的临时扩容能力,进一步降低成本,提高效率。最终目标是朝着湖仓一体的方向发展。
最后,我们还计划做资源隔离,确保不同业务应用场景的稳定性。由于我们目前的业务场景非常广泛,包括线上应用、报表工具、自助查询等不同场景,这些场景对系统的稳定性要求不同。通过资源隔离,我们可以确保关键应用场景的绝对稳定性。
相关文章:
StarRocks 助力首汽约车精细化运营
作者:任智红,首汽约车大数据负责人 更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/334%201%202/ffbe5 导读: 本文整理自首汽约车大数据负责人任智红在 StarRocks 年度峰会上的演讲…...

Springboot--Kafka客户端参数关键参数的调整方法
调整 Kafka 客户端参数需结合生产者、消费者和 Broker 的配置,以实现性能优化、可靠性保障或资源限制。以下是关键参数的调整方法和注意事项: 一、生产者参数调整 max.request.size 作用:限制单个请求的最大字节数(包括消…...

C++ 基类的虚析构函数与派生的析构函数关系
1、基类非虚析构函数,派生类析构函数,基类指针指向派生类 class Base { public:~Base() { // 非虚析构函数std::cout << "Base class destructor" << std::endl;} };class Derived : public Base { public:~Derived() { // 派生…...
)
解决Spring Boot上传默认限制文件大小和完善超限异常(若依框架)
文章目录 报错信息问题分析技术原理解决方法1️⃣调整 Spring Boot 配置文件2️⃣检查内嵌 Tomcat 配置(可选)3️⃣ 代码自定义配置(覆盖配置文件) 全局异常处理代码 报错信息 org.springframework.web.multipart.MaxUploadSizeE…...
)
AI平台如何实现推理?数算岛是一个开源的AI平台(主要用于管理和调度分布式AI训练和推理任务。)
数算岛是一个开源的AI平台,主要用于管理和调度分布式AI训练和推理任务。它基于Kubernetes构建,支持多种深度学习框架(如TensorFlow、PyTorch等)。以下是数算岛实现模型推理的核心原理、架构及具体实现步骤: 一、数算岛…...

痉挛性斜颈康复助力:饮食调养指南
痉挛性斜颈患者除了积极治疗,合理饮食也能辅助缓解症状,提升生活质量。其健康饮食可从以下方面着手: 高蛋白质食物助力肌肉修复 痉挛性斜颈会导致颈部肌肉异常收缩,消耗较多能量,蛋白质有助于肌肉的修复与维持。日常可…...

mysql镜像创建docker容器,及其可能遇到的问题
前提,已经弄好基本的docker服务了。 一、基本流程 1、目录准备 我自己的资料喜欢放在 /data 目录下,所以老规矩: 先进入 /data 目录: cd /data 创建 mysql 目录并进入: mkdir mysql cd mysql 2、镜像查找 docke…...

Dify平台
目录 安装介绍Dify:开源大语言模型应用开发平台核心功能应用场景架构设计优势 安装 基于RDS PostgreSQL与Dify平台构建AI应用 使用RDS PostgreSQL打造RAG应用 介绍 Dify是一个开源的大语言模型(LLM)应用开发平台,融合了后端即…...

荣耀90 GT信息
外观设计 屏幕:采用 6.7 英寸 AMOLED 荣耀绿洲护眼屏,超窄边框设计,其上边框 1.6mm,左右黑边 1.25mm,屏占较高,带来更广阔的视觉体验。屏幕还支持 120Hz 自由刷新率,可根据使用场景自动切换刷新…...
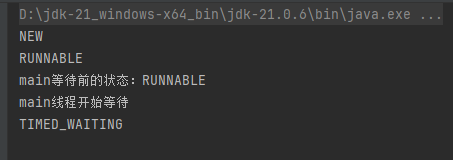
JavaEE——线程的状态
目录 前言1. NEW2. TERMINATED3. RUNNABLE4. 三种阻塞状态总结 前言 本篇文章来讲解线程的几种状态。在Java中,线程的状态是一个枚举类型,Thread.State。其中一共分为了六个状态。分别为:NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING, TERMI…...

spring mvc 在拦截器、控制器和视图中获取和使用国际化区域信息的完整示例
在拦截器、控制器和视图中获取和使用国际化区域信息的完整示例 1. 核心组件代码示例 1.1 配置类(Spring Boot) import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.spring…...

1021 Deepest Root
1021 Deepest Root 分数 25 全屏浏览 切换布局 作者 CHEN, Yue 单位 浙江大学 A graph which is connected and acyclic can be considered a tree. The height of the tree depends on the selected root. Now you are supposed to find the root that results in a highest…...

RuntimeError: Error(s) in loading state_dict for ChartParser
一 bug错误 最近使用千问大模型有一个bug,报错信息如下 raise RuntimeError(Error(s) in loading state_dict for {}:\n\t{}.format( RuntimeError: Error(s) in loading state_dict for ChartParser:Unexpected key(s) in state_dict: "pretrained_model.em…...

WHAT - React 惰性初始化
目录 在 React 中如何使用惰性初始化示例:常规初始化 vs. 惰性初始化1. 常规初始化2. 惰性初始化 为什么使用惰性初始化示例:从 localStorage 获取值并使用惰性初始化总结 在 React 中,惰性初始化(Lazy Initialization)…...

2025 年安徽交安安全员考试:利用记忆宫殿强化记忆
安徽考生在面对交安安全员考试繁杂的知识点时,记忆宫殿是强大的记忆工具。选择一个熟悉且空间结构清晰的场所作为记忆宫殿,如自己居住的房屋。将房屋的不同区域,如客厅、卧室、厨房等,分别对应不同知识板块,像客厅对应…...
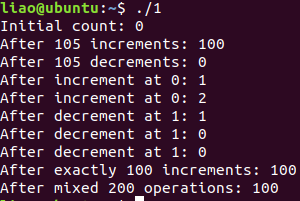
安全编码课程 实验6 整数安全
实验项目 实现安全计数器:实现 Counter 结构,确保计数范围为 0~100。 实验要求: 1、使用 struct 封装计数值value; 2、计数器初值为 0; 3、increment() 方法增加计数,但不能超过 100; 4、decrem…...
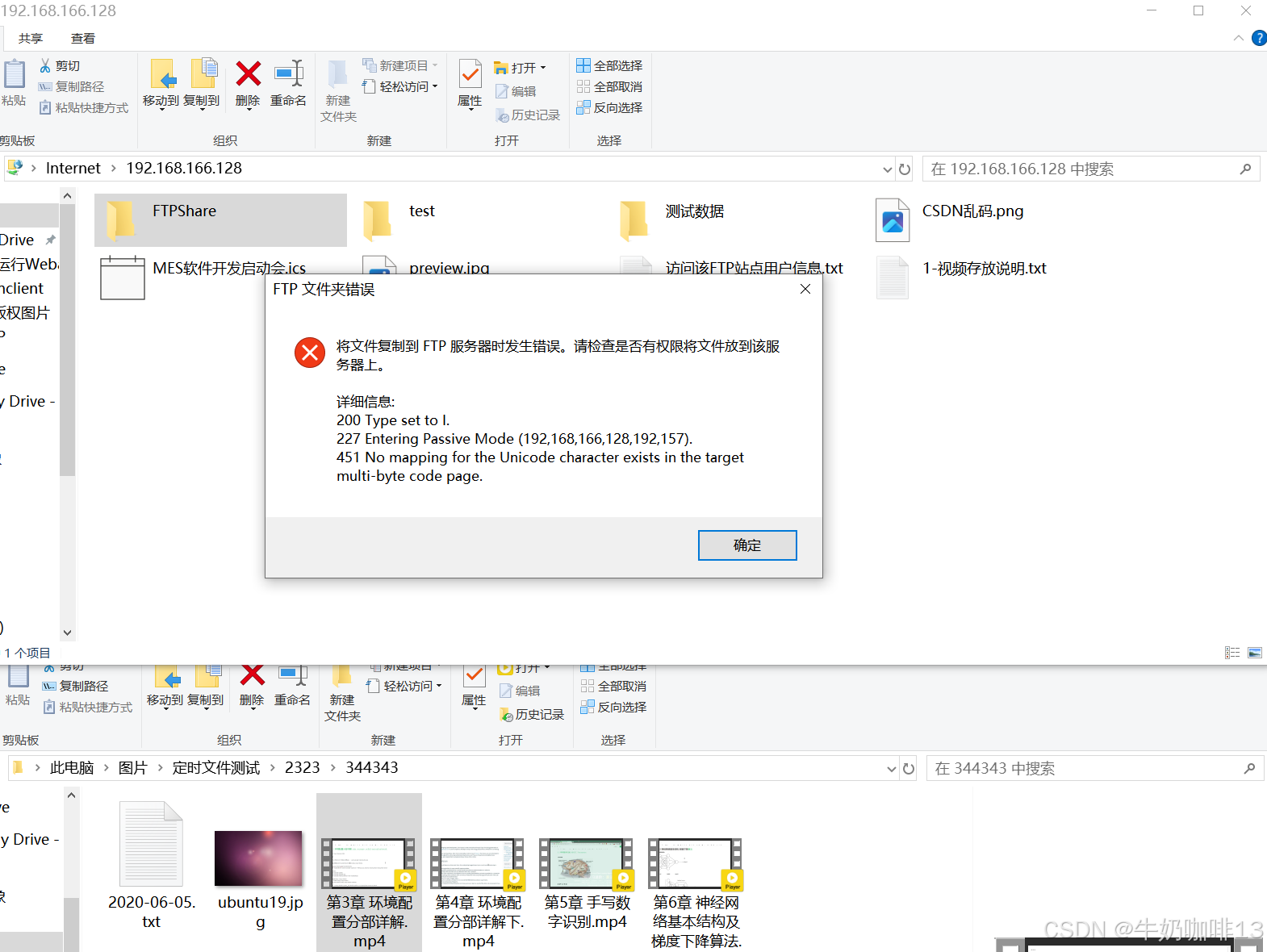
解决上传PDF、视频、音频等格式文件到FTP站点时报错“将文件复制到FTP服务器时发生错误。请检查是否有权限将文件放到该服务器上”问题
一、问题描述 可以将文本文件(.txt格式),图像文件(.jpg、.png等格式)上传到我们的FTP服务器上;但是上传一些PDF文件、视频等文件时就会报错“ 将文件复制到FTP服务器时发生错误。请检查是否有权限将文件放到该服务器上。 详细信息: 200 Type set to l. 227 Entering Pas…...
【Linux操作系统】:信号
Linux操作系统下的信号 一、引言 首先我们可以简单理解一下信号的概念,信号,顾名思义,就是我们操作系统发送给进程的消息。举个简单的例子,我们在写C/C程序的时候,当执行a / 0类似的操作的时候,程序直接就挂…...
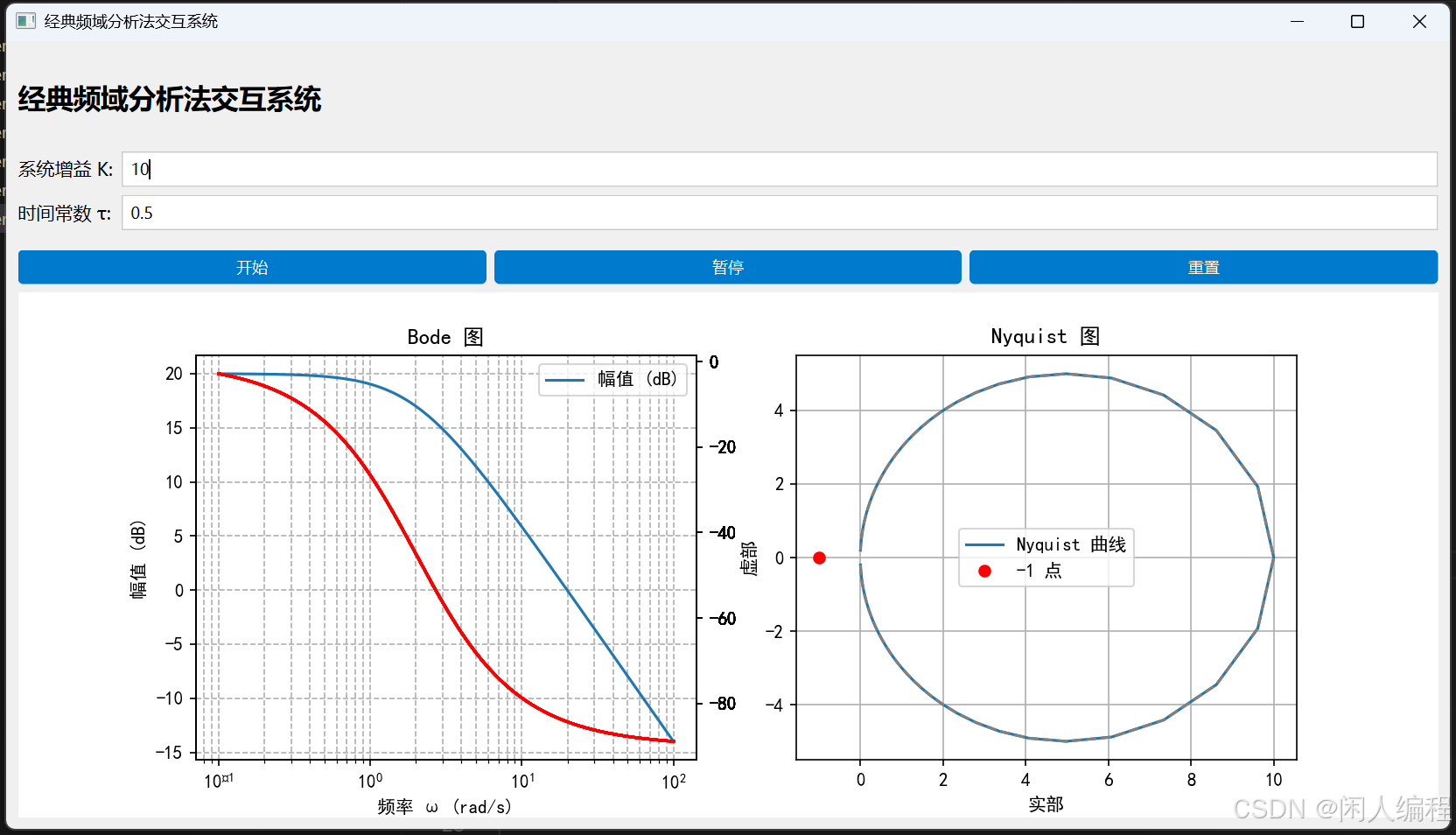
经典频域分析法(Bode图、Nyquist判据) —— 理论、案例与交互式 GUI 实现
目录 经典频域分析法(Bode图、Nyquist判据) —— 理论、案例与交互式 GUI 实现一、引言二、经典频域分析方法的基本原理2.1 Bode 图分析2.2 Nyquist 判据三、数学建模与公式推导3.1 一阶系统的频域响应3.2 多极系统的 Bode 图绘制3.3 Nyquist 判据的数学描述四、经典频域分析…...
使用scoop一键下载jdk和实现版本切换
安装 在 PowerShell 中输入下面内容,保证允许本地脚本的执行: set-executionpolicy remotesigned -scope currentuser然后执行下面的命令安装 Scoop: iwr -useb get.scoop.sh | iex国内用户可以使用镜像源安装:powershell iwr -us…...
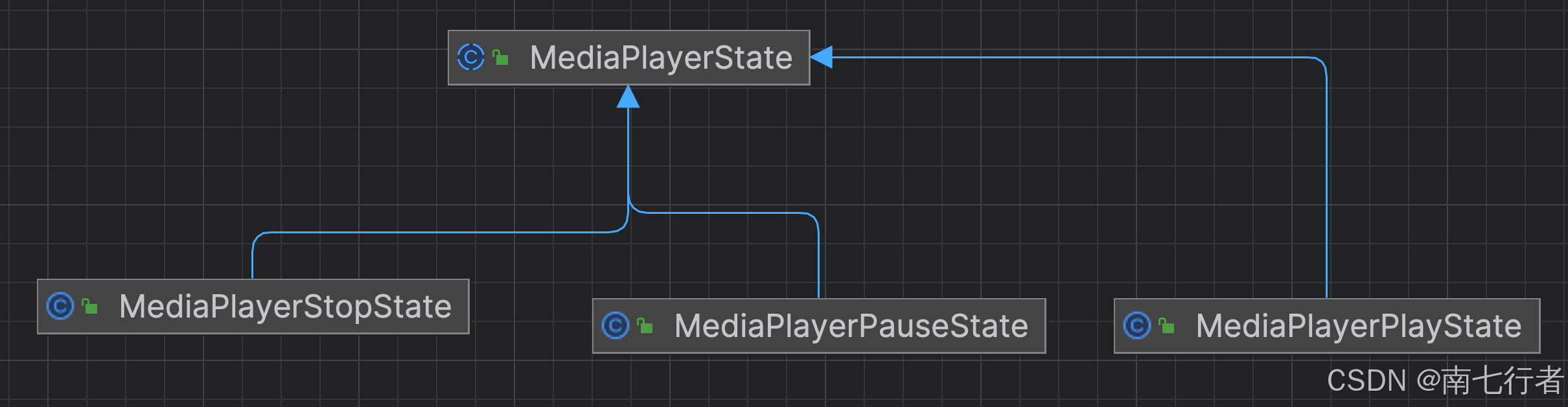
对状态模式的理解
对状态模式的理解 一、场景二、不采用状态模式1、代码2、缺点 三、采用状态模式1、代码1.1 状态类1.2 上下文(这里指:媒体播放器)1.3 客户端 2、优点 一、场景 同一个东西(例如:媒体播放器),有一…...

LangChain与LangGraph内置回调函数
LangChain与LangGraph回调函数指南 回调函数概述 LangChain和LangGraph共享同一套回调系统,通过BaseCallbackHandler类提供了丰富的生命周期钩子,可用于监控、调试和跟踪AI应用的执行过程。 回调函数流程图 #mermaid-svg-EsqgET3Cjlj0l0Z1 {font-fami…...

字符串哈希算法详解:原理、实现与应用
字符串哈希是一种高效处理字符串匹配和比较的技术,它通过将字符串映射为一个唯一的数值(哈希值),从而在O(1)时间内完成子串的比较。本文将结合代码实现,详细讲解前缀哈希法的工作原理,并通过流程图逐步解析…...

vue2(webpack)集成electron和 electron 打包
前言 之前发过一篇vue集成electron的文章,但是用vue3vite实现的,在vue2webpack工程可能不适用,所以这篇文章就主要介绍vue2webpack集成electron方法 创建项目 vue create vue-electron-demo目录架构 vue-electron-demo/ ├── src/ …...

C++内存管理优化实战:提升应用性能与效率
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle…...
redis数据迁移之通过redis-dump镜像
这里写目录标题 一、redis-dump 镜像打包1.1 安装windows docker1.2 idea项目创建1.3 idea镜像打包 二、redis数据迁移2.1 数据导出2.2 数据导入 一、redis-dump 镜像打包 没有找到可用的redis-dump镜像,需要自己打包一下,这里我是在idea直接打包的 1.…...

C语言单链表的增删改补
目录 (一)单链表的结构定义及初始化 (二)单链表的尾插,头插 (三)单链表的尾删,头删 (四)单链表的查找,删除,销毁 单链表是数据结构课程里的第二个数据结构。单链表在逻辑结构是连续的,在物理…...

redis导入成功,缺不显示数据
SpringBootTest class SecurityApplicationTests {AutowiredStringRedisTemplate template; //添加这句代码,自动装载,即可解决文章三处代码报错Testvoid contextLoads() {String compact Jwts.builder().signWith(Jwts.SIG.HS512.key().build()).subj…...

从表格到序列:Swift 如何优雅地解 LeetCode 251 展开二维向量
文章目录 摘要描述题解答案题解代码分析示例测试及结果时间复杂度空间复杂度总结 摘要 在这篇文章中,我们将深入探讨 LeetCode 第 251 题——“展开二维向量”的问题。通过 Swift 语言,我们不仅会提供可运行的示例代码,还会结合实际场景进行…...

汇丰xxx
1. Spring Boot 的了解,解决什么问题? 我的理解: Spring Boot 是一个基于 Spring 框架的快速开发脚手架,它简化了 Spring 应用的初始搭建和开发过程。解决的问题: 简化配置: 传统的 Spring 应用需要大量的…...