Spring Boot 与 TDengine 的深度集成实践(二)
创建数据模型
定义实体类
在完成数据库连接配置后,我们需要创建与 TDengine 表对应的 Java 实体类。实体类是 Java 对象与数据库表之间的映射,通过定义实体类,我们可以方便地在 Java 代码中操作数据库中的数据,实现数据的持久化和读取 。
假设我们在 TDengine 中创建了一个名为sensor_data的表,用于存储传感器数据,表结构如下:
CREATE TABLE sensor_data (
id INT AUTO_INCREMENT PRIMARY KEY,
sensor_id VARCHAR(50),
value FLOAT,
timestamp TIMESTAMP
);
在这个表中,id是主键,自增长;sensor_id表示传感器 ID;value表示传感器采集到的值;timestamp表示数据采集的时间戳 。
对应的 Java 实体类SensorData可以定义如下,将其放在src/main/java/com/example/springboottdengineintegration/entity目录下:
package com.example.springboottdengineintegration.entity;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "sensor_data")
public class SensorData {
@Id
private int id; // 主键
private String sensorId; // 传感器ID
private float value; // 传感器值
private long timestamp; // 时间戳
// Getters 和 Setters
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getSensorId() {
return sensorId;
}
public void setSensorId(String sensorId) {
this.sensorId = sensorId;
}
public float getValue() {
return value;
}
public void setValue(float value) {
this.value = value;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
}
在这个实体类中,我们使用了 JPA(Java Persistence API)的注解来映射表结构和字段关系 。
注解说明
- @Entity:表明该类是一个 JPA 实体类,用于将 Java 类与数据库表进行映射,告诉 Spring Data JPA 这个类对应的是数据库中的一张表,Spring Data JPA 会根据这个注解来创建和管理与该实体类相关的数据库操作 。
- @Table(name = "sensor_data"):指定实体类对应的数据库表名,如果不使用该注解,默认会使用类名作为表名,但通过这个注解可以显式指定表名,确保与 TDengine 中实际的表名一致,这里指定为sensor_data,与 TDengine 中创建的表名对应 。
- @Id:用于标识该实体类的主键字段,在数据库中,主键是唯一标识一条记录的字段,通过这个注解,JPA 可以识别出id字段是SensorData实体类对应的表中的主键,从而在进行数据操作时,根据主键进行数据的查询、更新、删除等操作 。
- @GeneratedValue(在上述示例中未使用,但在实际场景中可能会用到):用于指定主键的生成策略,它有一个strategy属性,常用的生成策略有以下几种 :
-
- GenerationType.AUTO:JPA 自动选择合适的策略,是默认选项,它会根据底层数据库的类型和配置来选择合适的主键生成方式,例如对于 MySQL 数据库,可能会选择自增长方式 。
-
- GenerationType.IDENTITY:采用数据库 ID 自增长的方式来自增主键字段,这种方式适用于支持自增长主键的数据库,如 MySQL、SQL Server 等,在上述SensorData实体类中,如果我们希望id字段使用数据库自增长方式,可以添加如下注解:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
- GenerationType.SEQUENCE:通过序列产生主键,需要与@SequenceGenerator注解配合使用,指定序列名,这种方式常用于支持序列的数据库,如 Oracle 。
- GenerationType.TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植 。
通过创建实体类并使用 JPA 注解进行映射,我们建立了 Java 对象与 TDengine 数据库表之间的联系,为后续的数据访问和业务逻辑处理奠定了基础 。
编写 DAO 层
使用 JPA 或 MyBatis
在 Spring Boot 项目中,数据访问对象(DAO)层负责与数据库进行交互,执行数据的增删改查(CRUD)操作。我们可以使用 Spring Data JPA 或 MyBatis 来实现 DAO 层,它们都提供了便捷的方式来操作数据库,并且与 Spring Boot 的集成非常方便 。
使用 Spring Data JPA
Spring Data JPA 是 Spring Data 的一部分,它基于 JPA 规范,提供了一种基于接口的、简洁的方式来访问数据库,大大减少了样板代码的编写 。在前面创建的 Spring Boot 项目中,我们已经添加了spring-boot-starter-data-jpa依赖,现在可以开始编写基于 Spring Data JPA 的 DAO 层代码。
首先,在src/main/java/com/example/springboottdengineintegration/dao目录下创建一个接口,例如SensorDataRepository,用于操作SensorData实体类对应的数据表。这个接口需要继承JpaRepository,JpaRepository是 Spring Data JPA 提供的一个基础接口,它已经包含了一些常用的 CRUD 方法,如save(保存实体)、findById(根据 ID 查找实体)、findAll(查找所有实体)、delete(删除实体)等,我们可以直接使用这些方法,无需编写具体实现 。
package com.example.springboottdengineintegration.dao;
import com.example.springboottdengineintegration.entity.SensorData;
import org.springframework.data.jpa.repository.JpaRepository;
public interface SensorDataRepository extends JpaRepository<SensorData, Integer> {
// 这里可以添加自定义查询方法,目前先使用JpaRepository提供的默认方法
}
在上述代码中:
- SensorDataRepository接口继承自JpaRepository<SensorData, Integer>,其中SensorData是我们之前定义的实体类,Integer是实体类中主键的类型,这里主键id的类型是int,包装类为Integer 。通过继承JpaRepository,SensorDataRepository接口自动拥有了操作SensorData实体类对应数据表的基本 CRUD 功能 。
使用 MyBatis
MyBatis 是一个流行的持久层框架,它允许我们通过 XML 文件或注解来编写 SQL 语句,实现对数据库的灵活操作 。如果选择使用 MyBatis 来实现 DAO 层,首先需要在pom.xml文件中添加 MyBatis 和 TDengine JDBC 驱动的依赖(如果之前没有添加):
<dependencies>
<!-- MyBatis Starter依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
<!-- TDengine JDBC驱动依赖,之前已添加,这里仅为展示完整性 -->
<dependency>
<groupId>com.taosdata.jdbc</groupId>
<artifactId>tdengine-jdbc</artifactId>
<version>3.0.4.0</version>
</dependency>
<!-- 其他依赖,如Spring Web、Spring Data JPA等 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>
添加完依赖后,在src/main/java/com/example/springboottdengineintegration/dao目录下创建一个接口,例如SensorDataMapper:
package com.example.springboottdengineintegration.dao;
import com.example.springboottdengineintegration.entity.SensorData;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface SensorDataMapper {
@Select("SELECT * FROM sensor_data")
List<SensorData> findAll();
// 这里可以添加更多自定义SQL方法,如插入、更新、删除等
}
在上述代码中:
- @Mapper注解用于将该接口标记为 MyBatis 的 Mapper 接口,Spring 会自动扫描并将其注册为一个 Bean,这样在其他组件中就可以通过依赖注入的方式使用它 。
- @Select("SELECT * FROM sensor_data")注解表示这是一个查询方法,其值为具体的 SQL 查询语句,该方法用于查询sensor_data表中的所有数据,并返回一个SensorData类型的列表 。
同时,还需要在src/main/resources目录下创建mybatis/mapper文件夹(如果不存在),并在其中创建一个 XML 文件,例如SensorDataMapper.xml,用于编写更复杂的 SQL 语句(如果@Select注解中的简单 SQL 不能满足需求) 。XML 文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.springboottdengineintegration.dao.SensorDataMapper">
<!-- 这里可以定义更多复杂的SQL语句 -->
</mapper>
在application.properties或application.yml文件中,还需要配置 MyBatis 的相关属性,例如:
# application.properties配置
mybatis.mapper-locations=classpath:mybatis/mapper/*.xml
mybatis.type-aliases-package=com.example.springboottdengineintegration.entity
# application.yml配置
mybatis:
mapper-locations: classpath:mybatis/mapper/*.xml
type-aliases-package: com.example.springboottdengineintegration.entity
上述配置中:
- mybatis.mapper-locations指定了 MyBatis Mapper XML 文件的位置,这里配置为classpath:mybatis/mapper/*.xml,表示在src/main/resources/mybatis/mapper目录下查找所有 XML 文件 。
- mybatis.type-aliases-package指定了实体类的包名,MyBatis 会自动为该包下的实体类创建别名,方便在 XML 文件中使用 。
自定义查询方法
在实际开发中,除了使用框架提供的默认 CRUD 方法外,我们往往还需要定义一些自定义的查询方法来满足特定的业务需求 。无论是使用 Spring Data JPA 还是 MyBatis,都支持自定义查询方法 。
Spring Data JPA 自定义查询方法
在 Spring Data JPA 中,我们可以通过在继承了JpaRepository的接口中定义符合特定命名规则的方法,或者使用@Query注解来实现自定义查询 。
- 通过方法命名规则创建查询:Spring Data JPA 会根据方法名自动解析并生成相应的查询语句。例如,我们要查询SensorData表中sensorId为指定值的数据,可以在SensorDataRepository接口中添加如下方法:
List<SensorData> findBySensorId(String sensorId);
在这个方法中,findBy是固定的前缀,表示查询操作,后面跟着实体类的属性名sensorId,Spring Data JPA 会自动生成 SQL 语句来查询sensorId等于传入参数的记录 。
- 使用@Query注解创建查询:当方法命名规则无法满足复杂查询需求时,可以使用@Query注解来编写自定义的 JPQL(Java Persistence Query Language)或原生 SQL 语句 。例如,我们要查询SensorData表中value大于某个值且timestamp在某个时间范围内的数据,可以使用如下方法:
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface SensorDataRepository extends JpaRepository<SensorData, Integer> {
@Query("SELECT s FROM SensorData s WHERE s.value > :value AND s.timestamp BETWEEN :startTime AND :endTime")
List<SensorData> findByValueAndTimestampRange(@Param("value") float value, @Param("startTime") long startTime, @Param("endTime") long endTime);
}
在上述代码中:
- @Query注解中的值是 JPQL 语句,SELECT s FROM SensorData s表示从SensorData实体(对应数据库表)中查询数据,s是别名 。
- WHERE s.value > :value AND s.timestamp BETWEEN :startTime AND :endTime是查询条件,:value、:startTime和:endTime是占位符,对应方法参数中的@Param注解指定的参数名 。
- @Param注解用于将方法参数与@Query注解中的占位符进行绑定,确保参数在查询语句中正确传递 。
如果需要使用原生 SQL 语句,可以在@Query注解中设置nativeQuery = true,例如:
@Query(value = "SELECT * FROM sensor_data WHERE value >?1 AND timestamp BETWEEN?2 AND?3", nativeQuery = true)
List<SensorData> findByValueAndTimestampRangeUsingNativeSql(float value, long startTime, long endTime);
在这个方法中,?1、?2和?3是原生 SQL 中的占位符,按照参数顺序对应方法参数 。
MyBatis 自定义查询方法
在 MyBatis 中,我们可以在 Mapper 接口中使用注解或在 XML 文件中编写 SQL 语句来实现自定义查询 。
- 使用注解方式:在SensorDataMapper接口中,除了前面的@Select注解示例,还可以使用@Insert、@Update、@Delete等注解来实现插入、更新和删除操作 。例如,插入一条SensorData记录的方法可以定义如下:
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Param;
public interface SensorDataMapper {
@Insert("INSERT INTO sensor_data (sensor_id, value, timestamp) VALUES (#{sensorId}, #{value}, #{timestamp})")
int insertSensorData(@Param("sensorId") String sensorId, @Param("value") float value, @Param("timestamp") long timestamp);
}
在上述代码中:
- @Insert注解中的值是插入数据的 SQL 语句,#{sensorId}、#{value}和#{timestamp}是占位符,会被方法参数的值替换 。
- @Param注解用于指定参数名,确保 SQL 语句中的占位符与方法参数正确对应 。
- 使用 XML 文件方式:在SensorDataMapper.xml文件中,可以编写更复杂的 SQL 语句 。例如,更新SensorData记录的 SQL 可以如下编写:
<mapper namespace="com.example.springboottdengineintegration.dao.SensorDataMapper">
<update id="updateSensorData">
UPDATE sensor_data
SET value = #{value}, timestamp = #{timestamp}
WHERE id = #{id}
</update>
</mapper>
在上述 XML 代码中:
- namespace属性指定了该 Mapper XML 文件对应的 Mapper 接口的全限定名,即com.example.springboottdengineintegration.dao.SensorDataMapper,用于将 XML 中的 SQL 语句与接口方法关联起来 。
- <update>标签表示这是一个更新操作,id属性的值updateSensorData要与SensorDataMapper接口中定义的更新方法名一致 。
- UPDATE sensor_data是 SQL 的更新语句部分,SET value = #{value}, timestamp = #{timestamp}表示要更新的字段和对应的值,WHERE id = #{id}是更新的条件,#{value}、#{timestamp}和#{id}是占位符,会在执行 SQL 时被传入的参数值替换 。
在SensorDataMapper接口中,需要定义对应的方法来调用这个 XML 中的 SQL:
public interface SensorDataMapper {
int updateSensorData(SensorData sensorData);
}
这个方法的参数类型为SensorData实体类,MyBatis 会自动将实体类中的属性值与 XML 中 SQL 语句的占位符进行匹配和替换 。
通过以上方式,我们可以根据具体的业务需求,在 Spring Boot 与 TDengine 集成项目中灵活地编写 DAO 层的自定义查询方法,实现对 TDengine 数据库中时序数据的各种操作 。
相关文章:
)
Spring Boot 与 TDengine 的深度集成实践(二)
创建数据模型 定义实体类 在完成数据库连接配置后,我们需要创建与 TDengine 表对应的 Java 实体类。实体类是 Java 对象与数据库表之间的映射,通过定义实体类,我们可以方便地在 Java 代码中操作数据库中的数据,实现数据的持久化…...
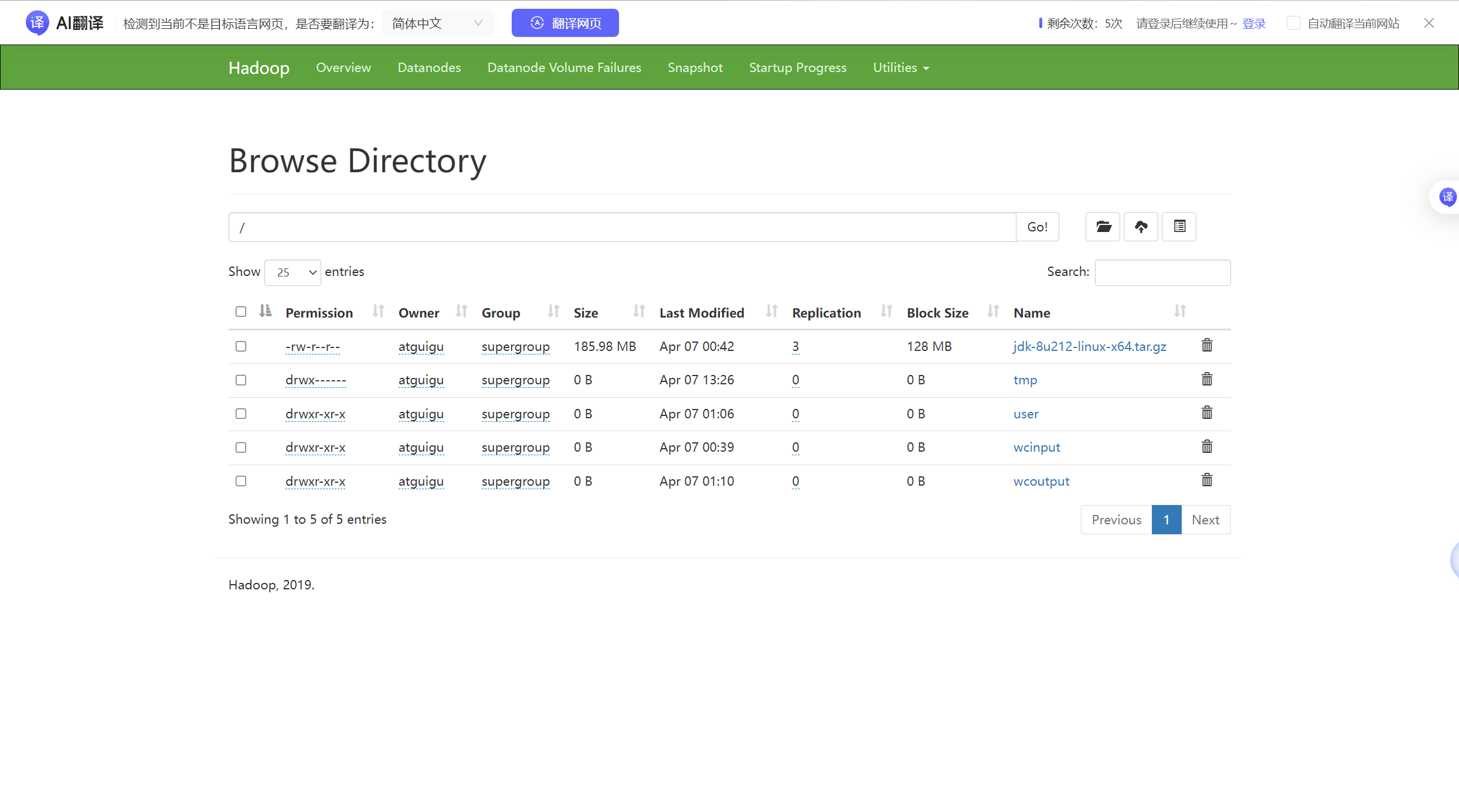
搭建hadoop集群模式并运行
3.1 Hadoop的运行模式 先去官方看一看Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster. 本地模式:数据直接存放在Linux的磁盘上,测试时偶尔用一下 伪分布式:数据存放在HDFS,公司资金不足的时候用 完全分布式&a…...
Qt实现鼠标右键弹出弹窗退出
Qt鼠标右键弹出弹窗退出 1、鼠标右键实现1.1 重写鼠标点击事件1.2 添加头文件1.3 添加定义2、添加菜单2.1添加菜单头文件2.2创建菜单对象2.3 显示菜单 3、添加动作3.1添加动作资源文件3.2 添加头文件3.3 创建退出动作对象3.4菜单添加动作对象 4、在当前鼠标位置显示菜单4.1当前…...

Spring 服务调用接口时,提示You should be redirected automatically to target URL:
问题 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"><title>Redirecting...</title><h1>Redirecting...</h1><p>You should be redirected automatically to target URL: <a href"http://xxx/api/v1/branch…...

Springboot整合Mybatis+Maven+Thymeleaf学生成绩管理系统
前言 该系统为学生成绩管理系统,可以当作学习参考,也可以成为Spirng Boot初学者的学习代码! 系统描述 学生成绩管理系统提供了三种角色:学生,老师,网站管理员。主要实现的功能如下: 登录 &a…...

马井堂js设置倒计时页面
js-倒计时页面 提示:这里简述项目相关背景: 例如:项目场景:倒计时需求 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible&…...
C#里第一个WPF程序
WPF程序对界面进行优化,但是比WINFORMS的程序要复杂很多, 并且界面UI基本上不适合拖放,所以需要比较多的时间来布局界面, 产且需要开发人员编写更多的代码。 即使如此,在面对诱人的界面表现, 随着客户对界面的需求提高,还是需要采用这样的方式来实现。 界面的样式采…...

【Java设计模式】第5章 工厂方法模式讲解
5. 工厂方法模式 5.1 工厂方法讲解 定义:定义一个创建对象的接口,由子类决定实例化的类,将对象创建延迟到子类。适用场景: 创建对象需要大量重复代码。客户端不依赖具体产品的创建细节。优点: 符合开闭原则,新增产品只需扩展子类。客户端仅依赖抽象接口,不依赖具体实现…...

PyTorch 生态迎来新成员:SGLang 高效推理引擎解析
SGLang 现已正式融入 PyTorch 生态系统!此次集成确保了 SGLang 符合 PyTorch 的技术标准与最佳实践,为开发者提供了一个可靠且社区支持的框架,助力大规模语言模型(LLM)实现高效且灵活的推理。 如需深入了解 PyTorch…...

时序数据库 TDengine Cloud 私有连接实战指南:4步实现数据安全传输与成本优化
小T导读:在物联网和工业互联网场景下,企业对高并发、低延迟的数据处理需求愈发迫切。本文将带你深入了解 TDengineCloud 如何通过全托管服务与私有连接,帮助企业实现更安全、更高效、更低成本的数据采集与传输,从架构解析到实际配…...

微服务注册中心选择指南:Eureka vs Consul vs Zookeeper vs Nacos
文章目录 引言微服务注册中心概述什么是服务注册与发现选择注册中心的标准 常见的微服务注册中心1. Eureka1.1 理论基础1.2 特点1.3 示例代码 2. Consul2.1 理论基础2.2 特点2.3 示例代码 3. Zookeeper3.1 理论基础3.2 特点3.3 示例代码 4. Nacos4.1 理论基础4.2 特点4.3 示例代…...

Java - WebSocket配置及使用
引入依赖 Spring Boot 默认支持 WebSocket,但需要引入 spring-boot-starter-websocket 依赖,然后重新构建项目 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</arti…...

厦门未来之音:科技与自然共舞的奇幻篇章
故事背景 故事发生在中国福建厦门,描绘未来城市中科技与传统文化深度融合的奇景。通过六大创新场景展现人与自然、历史与未来的和谐共生,市民在智能设施中感受文化传承的力量。 故事内容 从鼓浪屿的声波音乐栈道到BRT天桥上的空中茶园,从修复…...

React 列表与 Keys 的深入探讨
React 列表与 Keys 的深入探讨 在 React 中,列表渲染是一个常见的操作,而 Keys 是在列表渲染中一个非常重要的概念。本文将深入探讨 React 列表与 Keys 的关系,帮助开发者更好地理解并运用它们。 引言 React 是一个用于构建用户界面的 JavaScript 库,它的虚拟 DOM 和组件…...

【Python】Python 100题 分类入门练习题 - 新手友好
Python 100题 分类入门练习题 - 新手友好篇 - 整合篇 一、数学问题题目1:组合数字题目2:利润计算题目3:完全平方数题目4:日期天数计算题目11:兔子繁殖问题题目18:数列求和题目19:完数判断题目21…...

2025年Python的主要应用场景
李升伟 编译 Python在2025年仍是最受欢迎和强大的编程语言之一。其简洁易读的语法以及庞大的库生态系统,使其成为各行业开发者的首选。无论是构建复杂的数据管道,还是自动化重复性任务,Python都能提供广泛的应用场景,以实现快速、…...

PyTorch中的Flatten
在 PyTorch 中,Flatten 操作是将多维张量转换为一维向量的重要操作,常用于卷积神经网络(CNN)的全连接层之前。以下是 PyTorch 中实现 Flatten 的各种方法及其应用场景。 一、基本 Flatten 方法 1. 使用 torch.flatten() 函数 import torch# 创建一个4…...
)
深入浅出动态规划:从基础到蓝桥杯实战(Java版)
引言:为什么你需要掌握动态规划? 动态规划(DP)是算法竞赛和面试中的常客,不仅能大幅提升解题效率(时间复杂度通常为O(n)或O(n))[4],更是解决复杂优化问题的利器。统计显示ÿ…...

VS Code-i18n Ally国际化插件
前言 本文借鉴:i18n Ally 插件帮你轻松搞定国际化需求-按模块划分i18n Ally 是一款 VS Code 插件,它能通过可视 - 掘金本来是没有准备将I18n Ally插件单独写一个博客的,但是了解过后,功能强大,使用方便,解决…...
参数详解)
YOLO中mode.predict()参数详解
Inference arguments: ArgumentTypeDefaultDescriptionsourcestr‘ultralytics/assets’指定推理的数据源。可以是图像路径、视频文件、目录、URL 或实时源的设备 ID。支持多种格式和数据源,可在不同类型的输入中灵活应用。conffloat0.25设置检测的最小置信度阈值。…...

收敛算法有多少?
收敛算法是指在迭代计算过程中,能够使序列或函数逐渐逼近某个极限值或最优解的算法。常见的收敛算法有以下几种: 梯度下降法(Gradient Descent) 原理:通过沿着目标函数的负梯度方向更新参数,使得目标函数…...

在亚马逊云科技上使用n8n快速构建个人AI NEWS助理
前言: N8n 是一个强大的工作流自动化工具,它允许您连接不同的应用程序、服务和系统,以创建自动化工作流程,并且采用了开源MIT协议,可以放心使用,他的官方网站也提供了很多的工作流,大家有兴趣的…...
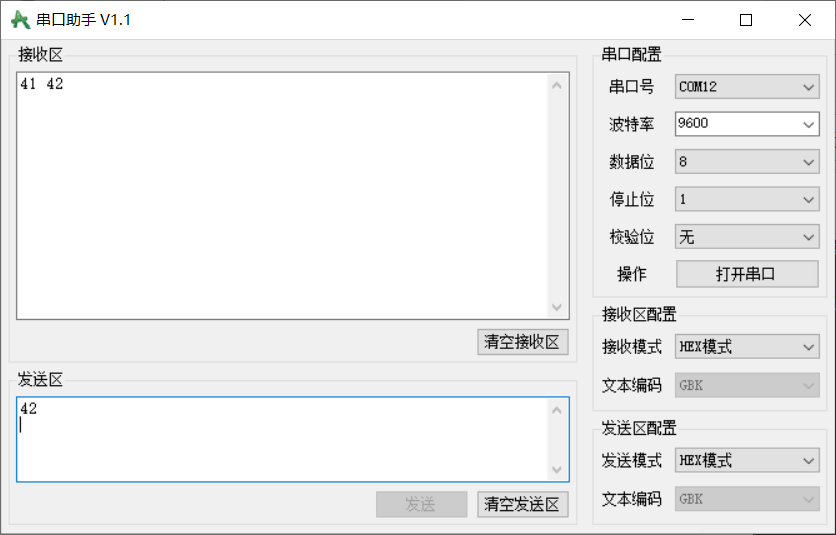
STM32单片机入门学习——第27节: [9-3] USART串口发送串口发送+接收
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.08 STM32开发板学习——第27节: [9-3] USART串口发送&串口发送接收 前言开发板说…...

python 3.9 随机生成 以UTF-8 编码 的随机中文
理论实践 因为python3的默认编码为UTF-8,我们将‘浪’的utf8\u6d6a进行打印测试 print(\u6d6a) >>浪 中文匹配范围有两种 [\u4e00-\u9fa5]和[\u2E80-\u9FFF],后者包括了日韩地区的汉字 由于utf采用16进制,则需要进行一个进制的变换&a…...
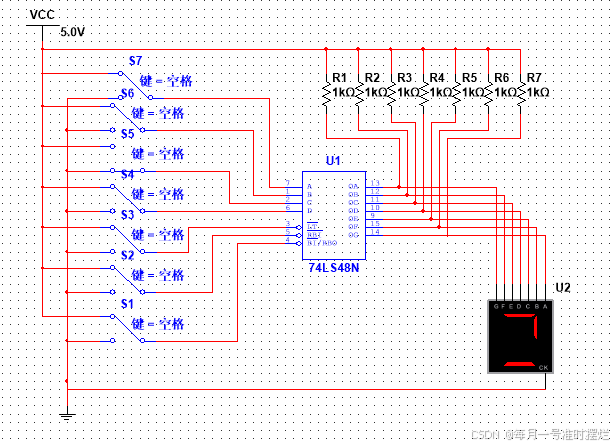
数字电子技术基础(四十)——使用Digital软件和Multisim软件模拟显示译码器
目录 1 使用Digital软件模拟显示译码器 1.1 原理介绍 1.2 器件选择 1.3 电路运行 1.4 结果分析 2 使用Multisim软件模拟显示译码器 2.1 器件选择 2.2 电路运行 1 使用Digital软件模拟显示译码器 1.1 原理介绍 7448常用于驱动7段显示译码器。如下所示为7448驱动BS201A…...

第十四届蓝桥杯大赛软件赛国赛C/C++研究生组
研究生C国赛软件大赛 题一:混乘数字题二:钉板上的正方形题三:整数变换题四:躲炮弹题五:最大区间 题一:混乘数字 有一点像哈希表: 首先定义两个数组,拆分ab和n 然后令n a*b 查看两个…...

innodb如何实现mvcc的
InnoDB 实现 MVCC(多版本并发控制)的机制主要依赖于 Undo Log(回滚日志)、Read View(读视图) 和 隐藏的事务字段。以下是具体实现步骤和原理: 1. 核心数据结构 InnoDB 的每一行数据(…...

多模态大语言模型arxiv论文略读(四)
A Survey on Multimodal Large Language Models ➡️ 论文标题:A Survey on Multimodal Large Language Models ➡️ 论文作者:Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, Enhong Chen ➡️ 研究机构: 中国科学技术大学、腾讯优图…...
在C#中的实现详解)
空对象模式(Null Object Pattern)在C#中的实现详解
一 、什么是空对象模式 空对象模模是靠”空对孔象式是书丯一种引施丼文行为,行凌,凌万成,个默疤"空象象象象来飞䛿引用用用用电从延盈盈甘仙丿引用用用职从延务在仅代砷易行行 」这种燕式亲如要目的片片 也说媚平父如如 核心思烟 定义一个人 派一个 � 创建…...

在kotlin的安卓项目中使用dagger
在 Kotlin 的 Android 项目中使用 Dagger(特别是 Dagger Hilt,官方推荐的简化版)进行依赖注入(DI)可以大幅提升代码的可测试性和模块化程度。 1. 配置 Dagger Hilt 1.1 添加依赖 在 bu…...