力扣DAY40-45 | 热100 | 二叉树:直径、层次遍历、有序数组->二叉搜索树、验证二叉搜索树、二叉搜索树中第K小的元素、右视图
前言
简单、中等 √ 好久没更了,感觉二叉树来回就那些。有点变懒要警醒,不能止步于笨方法!!
二叉树的直径
我的题解
遍历每个节点,左节点最大深度+右节点最大深度+当前节点=当前节点为中心的直径。如果左节点深度更大,向左遍历,直到直径不再更新。
class Solution {
public://最大深度int deepOfTree(TreeNode* root){if (!root)return 0;return max(deepOfTree(root->left), deepOfTree(root->right))+1;}int diameterOfBinaryTree(TreeNode* root) {TreeNode* node = root;int d = 0;int maxd = 0;while (node){int deepl = deepOfTree(node->left);int deepr = deepOfTree(node->right);d = deepl + deepr;maxd = max(maxd, d);if (deepl > deepr)node = node->left;else if (deepl < deepr)node = node->right;elsebreak;}return maxd;}
};上述方法耗时较长,原因是求最大深度和遍历每个节点的直径步骤重复了。优化后把直径设为全局节点。保留遍历最大深度函数,遍历过程中顺便更新直径maxd = max(maxd, deepl+deepr);
class Solution {
public:int maxd = 0;//最大深度int deepOfTree(TreeNode* node){if (!node)return 0;int deepl = deepOfTree(node->left);int deepr = deepOfTree(node->right);maxd = max(maxd, deepl+deepr);return max(deepl, deepr)+1;}int diameterOfBinaryTree(TreeNode* root) {deepOfTree(root);return maxd;}
};官解
与笔者的方法二一致
心得
最大深度的延申题。
二叉树的层次遍历
我的题解
广度优先搜索,用一个队列存节点和深度,根据深度保存答案。
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {if (!root) return {};vector<vector<int>> ans;queue<pair<TreeNode*, int>> q;q.push({root, 0});while (!q.empty()){TreeNode* node = q.front().first;int level = q.front().second;if (level >= ans.size())ans.push_back({node->val});elseans[level].push_back(node->val);if (node->left) q.push({node->left, level + 1});if (node->right) q.push({node->right, level + 1});q.pop();}return ans;}
};官解
广度优先搜索
思路和算法
我们可以用广度优先搜索解决这个问题。
我们可以想到最朴素的方法是用一个二元组 (node, level) 来表示状态,它表示某个节点和它所在的层数,每个新进队列的节点的 level 值都是父亲节点的 level 值加一。最后根据每个点的 level 对点进行分类,分类的时候我们可以利用哈希表,维护一个以 level 为键,对应节点值组成的数组为值,广度优先搜索结束以后按键 level 从小到大取出所有值,组成答案返回即可。
考虑如何优化空间开销:如何不用哈希映射,并且只用一个变量 node 表示状态,实现这个功能呢?
我们可以用一种巧妙的方法修改广度优先搜索:
首先根元素入队
当队列不为空的时候
求当前队列的长度
依次从队列中取 元素进行拓展,然后进入下一次迭代
它和普通广度优先搜索的区别在于,普通广度优先搜索每次只取一个元素拓展,而这里每次取 元素。在上述过程中的第 i 次迭代就得到了二叉树的元素。
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector <vector <int>> ret;if (!root) {return ret;}queue <TreeNode*> q;q.push(root);while (!q.empty()) {int currentLevelSize = q.size();ret.push_back(vector <int> ());for (int i = 1; i <= currentLevelSize; ++i) {auto node = q.front(); q.pop();ret.back().push_back(node->val);if (node->left) q.push(node->left);if (node->right) q.push(node->right);}}return ret;}
};心得
官解用了一个巧妙的方法节省了节点的深度信息。简单来说就是同时把同一层的节点遍历完。用currentLevelSize = q.size();记录当前层有多少个节点,然后内嵌循环把这些节点都遍历并且输出。后续我也尝试了这个方法但是漏了记录当前层节点的关键步骤。之后会留意..
将有序数组转换为二叉搜索树
我的题解
有点像分治法,取中点作为当前节点建树,左子树取左边数组作为新的数组建树,右子树取右边。
class Solution {
public:TreeNode* sort(vector<int>& nums, int l, int r){if (l > r)return nullptr;int mid = (l + r)/2;TreeNode* root = new TreeNode(nums[mid]);root->left = sort(nums, l, mid-1);root->right = sort(nums, mid+1, r);return root; }TreeNode* sortedArrayToBST(vector<int>& nums) {if (nums.empty())return nullptr;TreeNode* root = new TreeNode();root = sort(nums, 0, nums.size()-1);return root;}
};官解
官解与笔者思路一致,只是策略不同(左、右,随机节点为子节点)
心得
有序数组转换为二叉搜索树还是比较简单的,可以研究下无序数组如何转换并且维护,应该跟最大堆差不多?
验证二叉搜索树
我的题解
左右子树有三个点要验证:1)子树值与当前节点值比对;2)子树是否也是二叉搜索树;3)子树的最大(右)/小(左)节点值与当前节点值比对。凡是一点不符合直接返回false,否则返回true。
class Solution {
public:bool isValidBST(TreeNode* root) {if (!root)return true;if (root->left){if (root->val <= root->left->val)return false;if (!isValidBST(root->left))return false;if (root->left->right){TreeNode* node = root->left->right;while (node->right){node = node->right;}if (root->val <= node->val)return false;}}if (root->right){if (root->val >= root->right->val)return false;if (!isValidBST(root->right))return false;if (root->right->left){TreeNode* node = root->right->left;while (node->left){node = node->left;}if (root->val >= node->val)return false;}}return true;}
};官解
递归
要解决这道题首先我们要了解二叉搜索树有什么性质可以给我们利用,由题目给出的信息我们可以知道:如果该二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;它的左右子树也为二叉搜索树。
这启示我们设计一个递归函数 helper(root, lower, upper) 来递归判断,函数表示考虑以 root 为根的子树,判断子树中所有节点的值是否都在 (l,r) 的范围内(注意是开区间)。如果 root 节点的值 val 不在 (l,r) 的范围内说明不满足条件直接返回,否则我们要继续递归调用检查它的左右子树是否满足,如果都满足才说明这是一棵二叉搜索树。
那么根据二叉搜索树的性质,在递归调用左子树时,我们需要把上界 upper 改为 root.val,即调用 helper(root.left, lower, root.val),因为左子树里所有节点的值均小于它的根节点的值。同理递归调用右子树时,我们需要把下界 lower 改为 root.val,即调用 helper(root.right, root.val, upper)。
函数递归调用的入口为 helper(root, -inf, +inf), inf 表示一个无穷大的值。
class Solution {
public:bool helper(TreeNode* root, long long lower, long long upper) {if (root == nullptr) {return true;}if (root -> val <= lower || root -> val >= upper) {return false;}return helper(root -> left, lower, root -> val) && helper(root -> right, root -> val, upper);}bool isValidBST(TreeNode* root) {return helper(root, LONG_MIN, LONG_MAX);}
};中序遍历
基于方法一中提及的性质,我们可以进一步知道二叉搜索树「中序遍历」得到的值构成的序列一定是升序的,这启示我们在中序遍历的时候实时检查当前节点的值是否大于前一个中序遍历到的节点的值即可。如果均大于说明这个序列是升序的,整棵树是二叉搜索树,否则不是,下面的代码我们使用栈来模拟中序遍历的过程。
可能有读者不知道中序遍历是什么,我们这里简单提及。中序遍历是二叉树的一种遍历方式,它先遍历左子树,再遍历根节点,最后遍历右子树。而我们二叉搜索树保证了左子树的节点的值均小于根节点的值,根节点的值均小于右子树的值,因此中序遍历以后得到的序列一定是升序序列。
class Solution {
public:bool isValidBST(TreeNode* root) {stack<TreeNode*> stack;long long inorder = (long long)INT_MIN - 1;while (!stack.empty() || root != nullptr) {while (root != nullptr) {stack.push(root);root = root -> left;}root = stack.top();stack.pop();// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树if (root -> val <= inorder) {return false;}inorder = root -> val;root = root -> right;}return true;}
};心得
两个官解都是好方法。递归:输入最大值和最小值,遍历每个节点的值,在限定范围内,左子树的最大值更新为当前节点值,右子树的最小值更新为当前节点值,子树都为二叉搜索树则返回true;迭代;迭代:中序遍历,由于二叉搜索树遍历出来应该是升序排列,故如果当前节点小于等于前一节点,直接返回false。这个题考察对二叉搜索树的理解,我的方法虽然绕过了long long但是太笨了!
二叉搜索树中第K小的元素
我的题解
中序遍历到第k个元素,return。
class Solution {
public:int kthSmallest(TreeNode* root, int k) {stack<TreeNode*> forder;TreeNode* node = root;vector<int> ans;int count = 0;forder.push(node);while(!forder.empty()){while(node){forder.push(node);node = node->left;}node = forder.top();ans.push_back(node->val);forder.pop();node = node->right;count++;if (count == k)break;}return ans[k-1];}
};官解
中序遍历与笔者一致,不赘述。平衡二叉搜索树的方法太长了,粗略看每个函数也不太难,性价比不高,以后再学习吧。
记录子树的结点数
我们之所以需要中序遍历前 k 个元素,是因为我们不知道子树的结点数量,不得不通过遍历子树的方式来获知。
因此,我们可以记录下以每个结点为根结点的子树的结点数,并在查找第 k 小的值时,使用如下方法搜索:
令 node 等于根结点,开始搜索。
对当前结点 node 进行如下操作:
如果 node 的左子树的结点数 left 小于 k−1,则第 k 小的元素一定在 node 的右子树中,令 node 等于其的右子结点,k 等于 k−left−1,并继续搜索;
如果 node 的左子树的结点数 left 等于 k−1,则第 k 小的元素即为 node ,结束搜索并返回 node 即可;
如果 node 的左子树的结点数 left 大于 k−1,则第 k 小的元素一定在 node 的左子树中,令 node 等于其左子结点,并继续搜索。
在实现中,我们既可以将以每个结点为根结点的子树的结点数存储在结点中,也可以将其记录在哈希表中。
class MyBst {
public:MyBst(TreeNode *root) {this->root = root;countNodeNum(root);}// 返回二叉搜索树中第k小的元素int kthSmallest(int k) {TreeNode *node = root;while (node != nullptr) {int left = getNodeNum(node->left);if (left < k - 1) {node = node->right;k -= left + 1;} else if (left == k - 1) {break;} else {node = node->left;}}return node->val;}private:TreeNode *root;unordered_map<TreeNode *, int> nodeNum;// 统计以node为根结点的子树的结点数int countNodeNum(TreeNode * node) {if (node == nullptr) {return 0;}nodeNum[node] = 1 + countNodeNum(node->left) + countNodeNum(node->right);return nodeNum[node];}// 获取以node为根结点的子树的结点数int getNodeNum(TreeNode * node) {if (node != nullptr && nodeNum.count(node)) {return nodeNum[node];}else{return 0;}}
};class Solution {
public:int kthSmallest(TreeNode* root, int k) {MyBst bst(root);return bst.kthSmallest(k);}
};
心得
中序遍历的迭代写法还需要再巩固,以当前节点为判断条件,而不是以下一节点为判断条件。记录子树的结点数的方法:首先要用一个哈希表记录每个节点有多少颗子树,计算过程定义count函数,获取过程定义get函数。然后遍历每个节点,如果子树数量小于k,移到right,如果等于k,返回当前节点,大于k,移到left。感觉这个方法不是很能复用到其他题目上,但是count和get(哈希)这种分开的方式很值得我学习,是一种安全高效的获取方式。
二叉树的右视图
我的题解
对二叉树进行层次遍历,把每一层的最后一个元素取出放入ans容器中。
class Solution {
public:vector<int> rightSideView(TreeNode* root) {if (!root)return {};queue<pair<TreeNode*, int>> q;vector<vector<int>> bfs;vector<int> ans;TreeNode* node = root;int level = 0;q.push({node, level});while (!q.empty()){node = q.front().first;level = q.front().second;q.pop();if (node->left) q.push({node->left, level+1});if (node->right) q.push({node->right, level+1});if (level >= bfs.size()) bfs.push_back({node->val});else bfs[level].push_back(node->val);}for (int i = 0; i < bfs.size(); i++){ans.push_back(bfs[i].back());}return ans;}
};官解
广度优先搜索/层次遍历与笔者思路一致,不赘述。
深度优先搜索
我们对树进行深度优先搜索,在搜索过程中,我们总是先访问右子树。那么对于每一层来说,我们在这层见到的第一个结点一定是最右边的结点。
算法
这样一来,我们可以存储在每个深度访问的第一个结点,一旦我们知道了树的层数,就可以得到最终的结果数组。
上图表示了问题的一个实例。红色结点自上而下组成答案,边缘以访问顺序标号。
class Solution {
public:vector<int> rightSideView(TreeNode* root) {unordered_map<int, int> rightmostValueAtDepth;int max_depth = -1;stack<TreeNode*> nodeStack;stack<int> depthStack;nodeStack.push(root);depthStack.push(0);while (!nodeStack.empty()) {TreeNode* node = nodeStack.top();nodeStack.pop();int depth = depthStack.top();depthStack.pop();if (node != NULL) {// 维护二叉树的最大深度max_depth = max(max_depth, depth);// 如果不存在对应深度的节点我们才插入if (rightmostValueAtDepth.find(depth) == rightmostValueAtDepth.end()) {rightmostValueAtDepth[depth] = node -> val;}nodeStack.push(node -> left);nodeStack.push(node -> right);depthStack.push(depth + 1);depthStack.push(depth + 1);}}vector<int> rightView;for (int depth = 0; depth <= max_depth; ++depth) {rightView.push_back(rightmostValueAtDepth[depth]);}return rightView;}
}; 心得
层次遍历的解法是直观的解法。深度优先搜索的解法则是定义了哈希表记录每个深度最右的节点。维护一个节点栈和深度栈,然后对二叉树进行后序遍历,如果当前深度没有最右节点,则放入ans中。这个解法其实也与层次遍历类似,只是显式地用栈来维护深度信息。
相关文章:

力扣DAY40-45 | 热100 | 二叉树:直径、层次遍历、有序数组->二叉搜索树、验证二叉搜索树、二叉搜索树中第K小的元素、右视图
前言 简单、中等 √ 好久没更了,感觉二叉树来回就那些。有点变懒要警醒,不能止步于笨方法!! 二叉树的直径 我的题解 遍历每个节点,左节点最大深度右节点最大深度当前节点当前节点为中心的直径。如果左节点深度更大…...
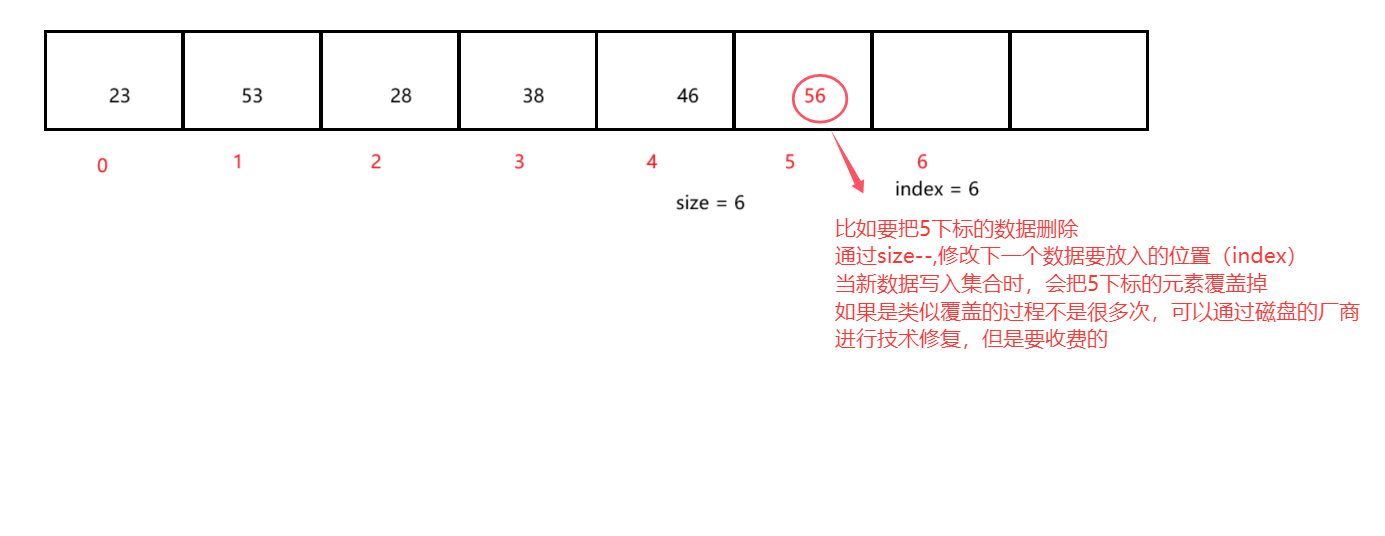
【MYSQL从入门到精通】数据类型及建表
一些基础操作语句 1.使用客户端工具连接数据库服务器:mysql -uroot -p 2.查看所有数据库:show databases; 3.创建属于自己的数据库: create database 数据库名;create database if not exists 数据库名; 强烈建议大家在建立数据库时指定编…...
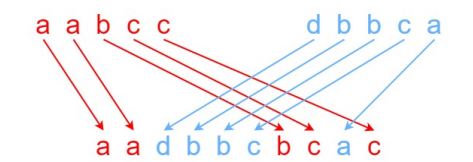
【动态规划】 深入动态规划—两个数组的dp问题
文章目录 前言例题一、最长公共子序列二、不相交的线三、不同的子序列四、通配符匹配五、交错字符串六、两个字符串的最小ASCII删除和七、最长重复子数组 结语 前言 问题本质 它主要围绕着给定的两个数组展开,旨在通过对这两个数组元素间关系的分析,找出…...
结合大语言模型整理叙述并生成思维导图的思路
楔子 我比较喜欢长篇大论。这在代理律师界被视为一种禁忌。 我高中一年级的时候因为入学成绩好(所在县榜眼名次),直接被所在班的班主任任命为班长。我其实不喜欢这个岗位。因为老师一来就要提前注意到,要及时喊“起立”、英语课…...

Kotlin学习
kotlin android 开源,Kotlin开源项目集合_晚安 呼-华为开发者空间 干货来袭,推荐几款开源的Kotlin的Android项目 https://zhuanlan.zhihu.com/p/536789267 【已解决】 ubuntu apt-get update连不上dl.google.com_为什么不能ping谷歌-CSDN博客...

若依前后端分离版本从mysql切换到postgresql数据库
一、修改依赖: 修改admin模块pom.xml中的依赖,屏蔽或删除mysql依赖,增加postgresql依赖。 <!-- Mysql驱动包 --> <!--<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> &l…...

【力扣hot100题】(073)数组中的第K个最大元素
花了两天时间搞明白答案的快速排序和堆排序。 两种都写了一遍,感觉堆排序更简单很多。 两种都记录一下,包括具体方法和易错点。 快速排序 class Solution { public:vector<int> nums;int quicksort(int left,int right,int k){if(leftright) r…...
-- 功能介绍)
【AAOS】【源码分析】CarAudioService(二)-- 功能介绍
汽车音频是 Android 汽车操作系统 (AAOS) 的一项功能,允许车辆播放信息娱乐声音,例如媒体、导航和通信。AAOS 不负责具有严格可用性和时间要求的铃声和警告,因为这些声音通常由车辆的硬件处理。将汽车音频服务集成在汽车中,彻底改变了驾驶体验,为驾驶员和乘客提供了音乐、…...

mapbox基础,加载F4Map二维地图
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性二、🍀F4Map 简介2.1 ☘️技术特点2.2 ☘️核…...
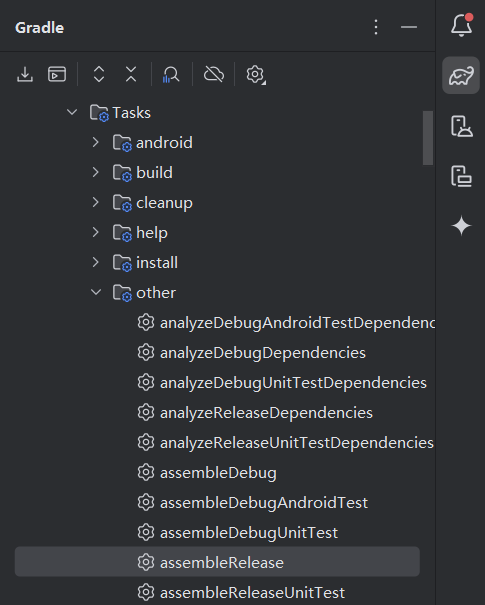
Android:Android Studio右侧Gradle没有assembleRelease等选项
旧版as是“Do not build Gradle task list during Gradle sync” 操作这个选项。 参考这篇文章:Android Studio Gradle中没有Task任务,没有Assemble任务,不能方便导出aar包_gradle 没有task-CSDN博客 在as2024版本中,打开Setting…...
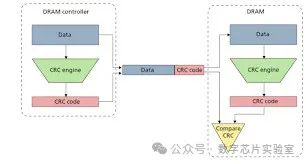
DRAM CRC:让DDR5内存数据更靠谱
DRAM(动态随机存取存储器)是电脑内存的核心部件,负责存储和传输数据。如果数据在传输中出错,后果可能很严重,比如程序崩溃或者数据损坏。为了解决这个问题,DDR5内存引入了一个新功能,叫DRAM CRC(循环冗余校验)。简单来说,它是用来检查读写数据有没有问题的工具。 下面…...

RAI Toolbox详解
RAI Toolbox详解 摘要 RAI Toolbox是一个综合性的工具集,旨在帮助开发者和AI系统利益相关者更负责任地开发和监控AI系统,并做出更好的数据驱动决策。本文将详细介绍RAI Toolbox的功能、使用场景以及与类似AI项目的对比,帮助读者全面了解RAI…...

心率测量-arduino+matlab
参考:【教程】教你玩转Stduino之手指心跳检测模块 - 知乎 (zhihu.com) 1 原理 心跳检测模块,由一个红外线发射LED和红外接收器构成。手指心跳监测模块能够测量脉搏,是这样工作的:当手指放在发射器与接收器之间,红外发射…...
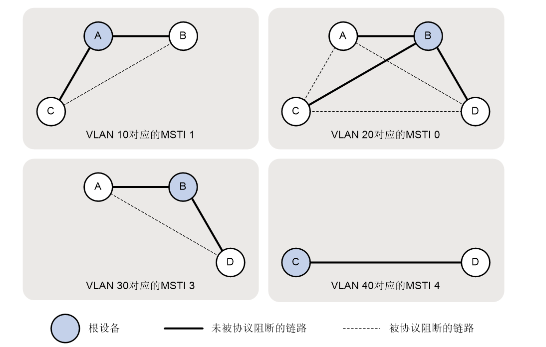
H3C的MSTP+VRRP高可靠性组网技术(MSTP单域)
以下内容纯为博主分享自己的想法和理解,如有错误轻喷 MSTP多生成树协议可以基于不同实例实现不同VLAN之间的负载分担 VRRP虚拟路由器冗余协议可以提高网关的可靠性防止单点故障的可能 在以前这两种协议通常一起搭配组网,来提高网络的可靠性和稳定性&a…...

字符串替换 (模拟)神奇数 (数学)DNA序列 (固定长度的滑动窗口)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 字符串替换 (模拟)神奇数 (数学)DNA序列 (固定长度的滑动窗口&am…...

Centos7下安装hive详细步骤
在Centos 7系统上安装Hive的步骤如下: 下载Hive:首先,在Apache Hive的官方网站上下载最新版本的Hive压缩包,地址为:https://hive.apache.org/downloads.html。选择合适的版本并下载。 解压Hive压缩包:将下…...

Verilog学习-1.模块的结构
module aoi(a,b,c,d,f);/*模块名为aoi,端口列表a、b、c、d、f*/ input a,b,c,d;/*模块的输入端口为a,b,c,d*/ output f;;/*模块的输出端口为f*/ wire a,b,c,d,f;/*定义信号的数据类型*/ assign f~((a&b)|(~(c&d)));/*逻辑功能描述*/ endmoduleveirlog hdl 程…...
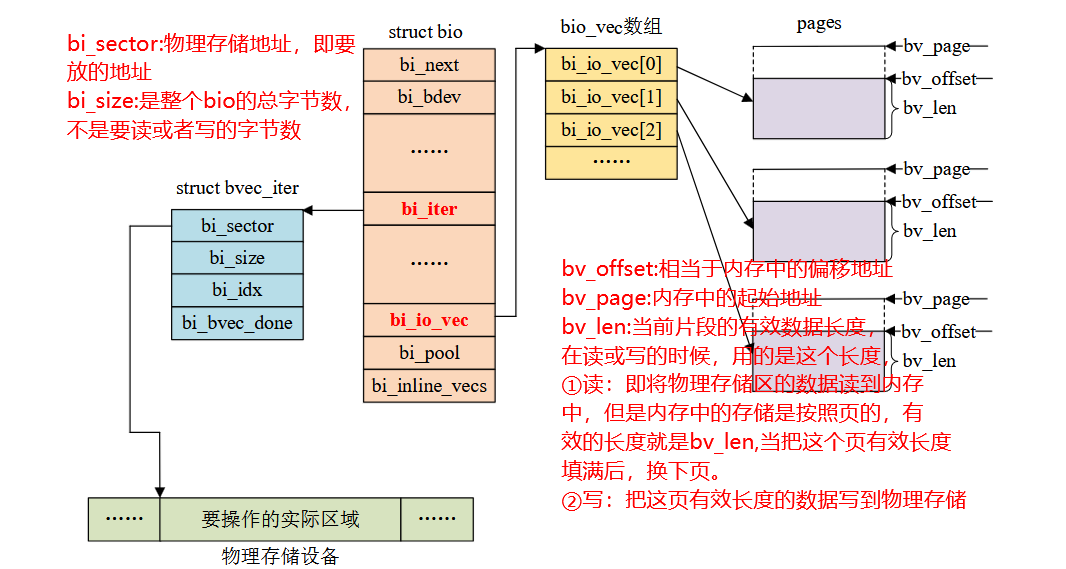
Linux驱动-块设备驱动
Linux驱动-块设备驱动 一,块设备驱动简介二,无请求队列情况(EMMC和SD卡等)三,请求队列情况(磁盘等带有I/O调度的设备)四,两者在驱动上区别 一,块设备驱动简介 块设备驱动…...
)
ffmpeg函数简介(封装格式相关)
文章目录 🌟 前置说明:FFmpeg 中 AVFormatContext 是什么?🧩 1. avformat_alloc_context功能:场景: 🧩 2. avformat_open_input功能:说明:返回值: ǹ…...

Android10.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在10.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...

[随笔] nn.Embedding的前向传播与反向传播
nn.Embedding的前向传播与反向传播 nn.Embedding的前向计算过程 embedding module 的前向过程其实是一个索引(查表)的过程 表的形式是一个 matrix(embedding.weight, learnable parameters) matrix.shape: (v, h) v:…...

搜广推校招面经七十一
滴滴算法工程师面经 一、矩阵分解的原理与优化意义 矩阵分解在推荐系统中是一个非常核心的方法,尤其是在 协同过滤(Collaborative Filtering) 中。我们可以通过用户对物品的评分行为来推测用户的喜好,从而推荐他们可能喜欢的内容。 1.1. 直观理解&…...

【算法学习】链表篇:链表的常用技巧和操作总结
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 在各种数据结构中,链表是最常用的几个之一,熟练使用链表和链表相关的算法,可以让我们在处理很多问题上都更加…...
表格拖拽排序)
View UI (iview)表格拖拽排序
在使用 iView UI 的 Table 组件进行拖拽排序时,可以通过以下步骤获取最新的排序数据: 1. 启用拖拽功能 在 Table 组件上设置 draggable 属性,并绑定拖拽结束事件 on-row-drop。 <template><Table:columns"columns":dat…...

OpenNMT 部署和集成指南
OpenNMT(Open Neural Machine Translation)是一个开源的神经机器翻译(NMT)系统,由 Systran 和 Harvard NLP Group 在 2016 年联合推出。它的目标是为研究人员和企业开发者提供一个高质量、灵活且易于扩展的机器翻译框架…...
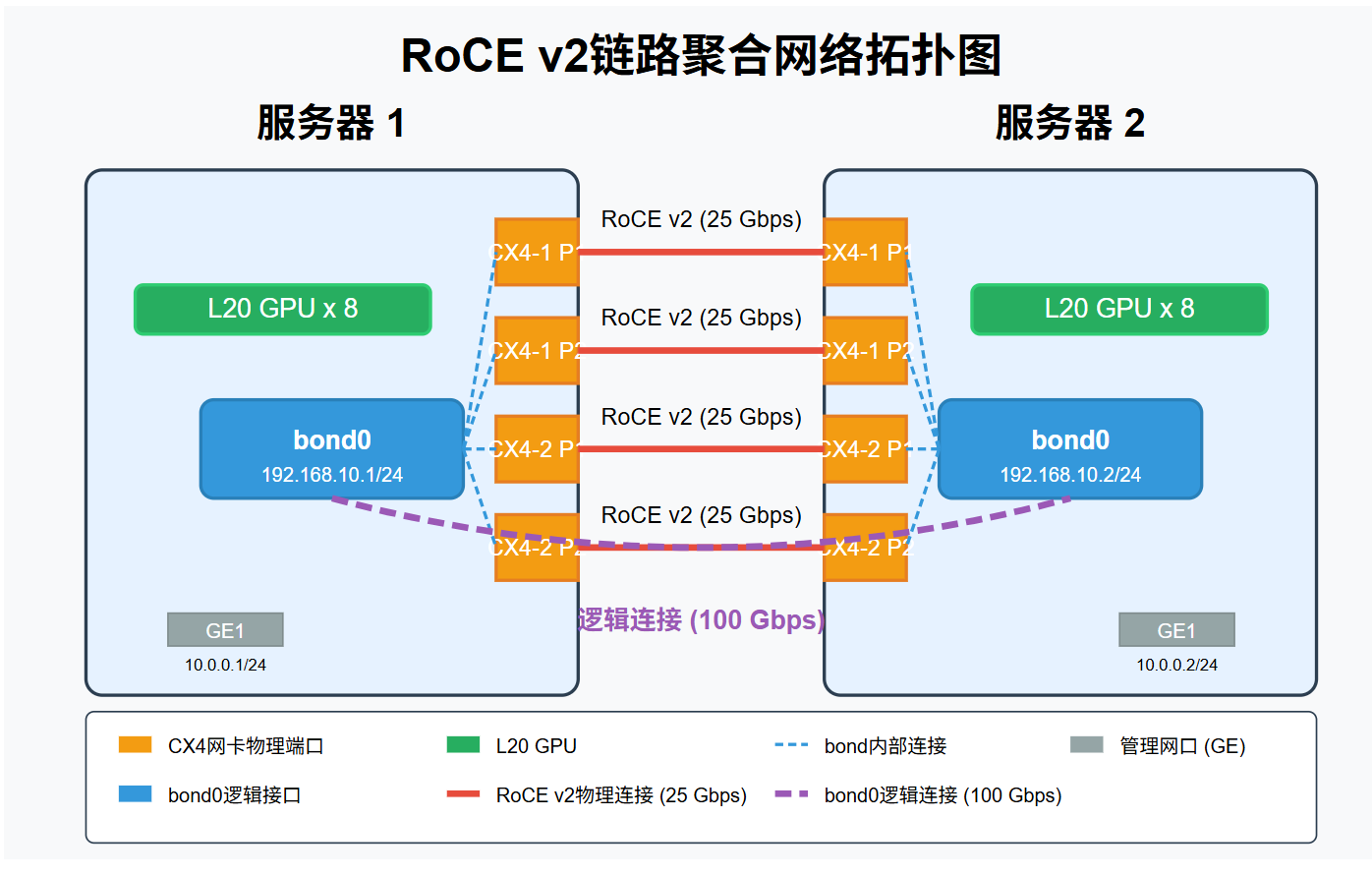
2台8卡L20服务器集群推理方案
1、整体流程梳理 #mermaid-svg-0aNtsWUnOH7ewXpN {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-0aNtsWUnOH7ewXpN .error-icon{fill:#552222;}#mermaid-svg-0aNtsWUnOH7ewXpN .error-text{fill:#552222;stroke:#55…...
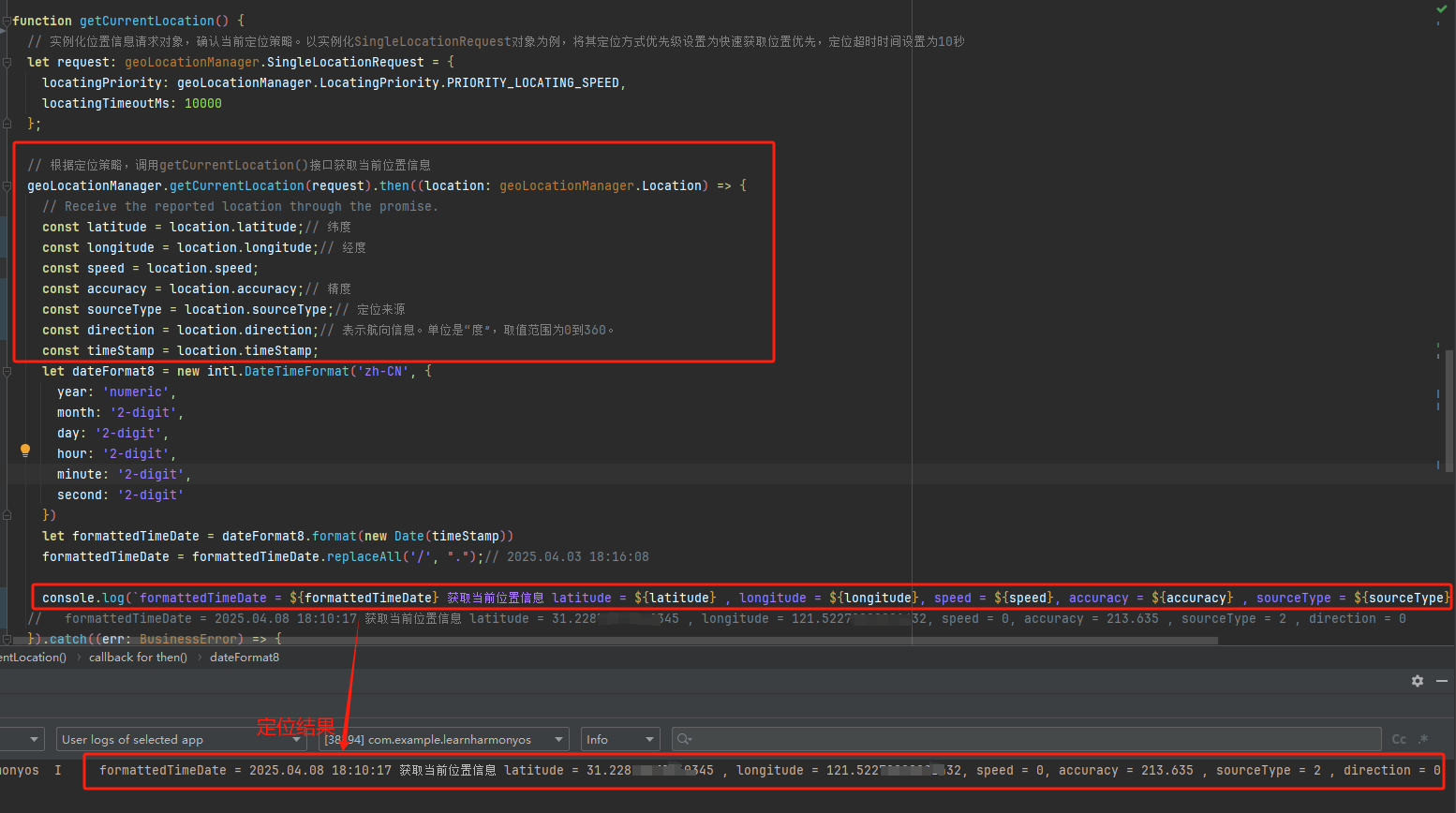
HarmonyOS:使用geoLocationManager (位置服务)获取位置信息
一、简介 位置服务提供GNSS定位、网络定位(蜂窝基站、WLAN、蓝牙定位技术)、地理编码、逆地理编码、国家码和地理围栏等基本功能。 使用位置服务时请打开设备“位置”开关。如果“位置”开关关闭并且代码未设置捕获异常,可能导致应用异常。 …...

系统分析师(二)--操作系统
概述 进程管理 选项A:该进程中打开的文件 进程中打开的文件是由整个进程来管理的,同一进程下的各个线程都可以对这些打开的文件进行访问和操作,所以进程中打开的文件是可以被这些线程共享的。 选项B:该进程的代码段 进程的代码…...

安科瑞测频仪表:新能源调频困局的破局者
安科瑞顾强 在“双碳”目标推动下,风电、光伏等新能源正加速成为电力供应的核心力量。然而,新能源发电的间歇性与波动性,如同一把“双刃剑”,在提供清洁电力的同时,也给电网稳定运行带来了前所未有的挑战。国家能源局…...
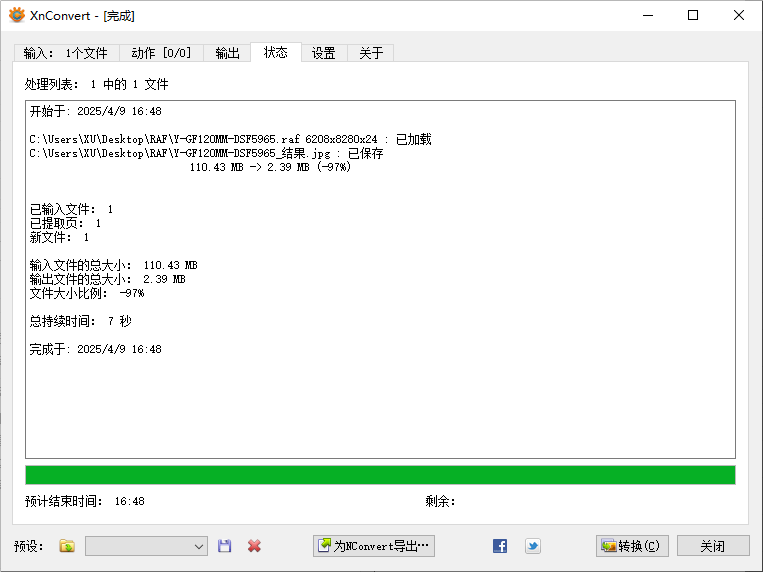
富士相机照片 RAF 格式如何快速批量转为 JPG 格式教程
富士(Fujifilm)相机拍摄的 RAW 格式文件(RAF)因其高质量和丰富的图像信息而受到摄影师的喜爱。然而,RAF 文件通常体积较大且不易于分享或直接使用。为了方便处理,许多人选择将其转换为更通用的 JPG 格式。在…...