大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
🍋一、CDH
CDH(Cloudera Distribution Including Apache Hadoop)是由Cloudera公司提供的一个集成了Apache Hadoop以及相关生态系统的发行版本。CDH是一个大数据平台,简化和加速了大数据处理分析的部署和管理。CDH提供Hadoop的核心元素-可伸缩存储和分布式计算-以及基于web的用户界面和重要的企业功能。CDH是Apache许可的开放源码,是唯一提供统一批处理、交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。
CDH是一个强大的商业版数据中心管理工具,提供了以下功能:
1.提供了各种能够快速稳定运行的数据计算框架,如Spark;
2.使用Apache Impala做为对HDFS、HBase的高性能SQL查询引擎;
3.使用Hive数据仓库工具帮助用户分析数据;
4.提供CM安装HBase分布式列式NoSQL数据库;
5.包含原生的Hadoop搜索引擎以及Cloudera Navigator Optimizer去对Hadoop上的计算任务进行一个可视化的协调优化,提高运行效率;
6.提供的各种软件能让用户在一个可视化的UI界面中方便地管理、配置和监控Hadoop以及其它所有相关组件,并有一定的容错容灾处理;
7.提供了基于角色的访问控制安全管理。
CDH和原生Hadoop区别
原生Hadoop的问题
1.版本管理过于混乱
2.部署过程较为繁琐,升级难度较大
3.兼容性差
4.安全性低
CDH优点
1. 提供基于web的用户界面,操作方便
2、集成的组件丰富,支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop
3、搭建容易,运维比原生hadoop方便。简化了大数据平台的安装和使用难度
4、版本划分清晰、更新速度快、文档清晰、支持多种安装方式、支持Kerberos安全认证等
CDH 组件
CDH作为一套开源的大数据处理平台,包含了许多不同的组件,每个组件都有各自的功能和特点。下面大概介绍下各个组件的功能和用途。
🍋二、Hadoop HDFS

Hadoop HDFS(Hadoop Distributed File System)是CDH中的一个核心组件,它是一个可扩展的分布式文件系统,用于存储大规模的数据文件。HDFS通过将文件切分为多个块,并将这些块分布在不同的计算节点上,实现了高可用性和高性能的文件存储。
HDFS文件系统维护着一个命名空间,它是一个树状结构,包含文件和目录。这个命名空间以根目录“/”开始,用户可以创建、删除文件和目录,以及修改它们的权限。
1.NameNode
负责客户端请求的响应
元数据的管理(查询,修改)
namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
2.JournalNode
NameNode之间共享数据(主要体现在 NameNode配置 HA)
3.DataNode
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
🍋三、Hadoop YARN
YARN的核心思想是将资源管理和作业调度从特定的计算框架(如MapReduce)中分离出来使其成为单独的守护进程,使得Hadoop集群能够更通用地支持多种类型的应用程序和工作负载。
这个想法是拥有一个全局的 ResourceManager ( RM ) 和每个应用程序的 ApplicationMaster ( AM )。应用程序可以是单个作业,也可以是作业的 DAG。ResourceManager 和 NodeManager 构成了数据计算框架。 ResourceManager是系统中所有应用程序之间资源仲裁的最终权威。 NodeManager 是每台机器的框架代理,负责容器、监视其资源使用情况(CPU、内存、磁盘、网络)并将其报告给ResourceManager/Scheduler。每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是与 ResourceManager 协商资源并与 NodeManager 一起执行和监视任务。(ApplicationMaster 是由应用程序框架(如 MapReduce、Spark、Impala 等)提供的。每个框架都会根据自己的需求和特点来实现 ApplicationMaster。这也意味着,不同的应用程序框架会有不同的 ApplicationMaster 实现,它们负责处理与框架相关的特定逻辑。)

Hadoop YARN(Yet Another Resource Negotiator)是CDH中的另一个核心组件,它是一个资源管理器,负责对集群中的计算资源进行统一管理和调度。YARN可以根据应用程序的需求,动态分配计算资源,实现任务的高效执行。
🍋四、Hadoop MapReduce
Hadoop MapReduce是CDH中用于分布式计算的编程模型和框架,它将大规模的数据切分为多个小任务,并在集群中的计算节点上并行执行这些任务。MapReduce可以实现大规模数据的处理和分析,支持复杂的数据转换和计算操作。
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
🍋五、HBase
HBase是CDH的一个分布式数据库,它基于Hadoop HDFS存储数据,并提高性能的随机读写能力。HBase适用于需要快速访问和查询大规模数据的场景,如日志分析、推荐系统等。
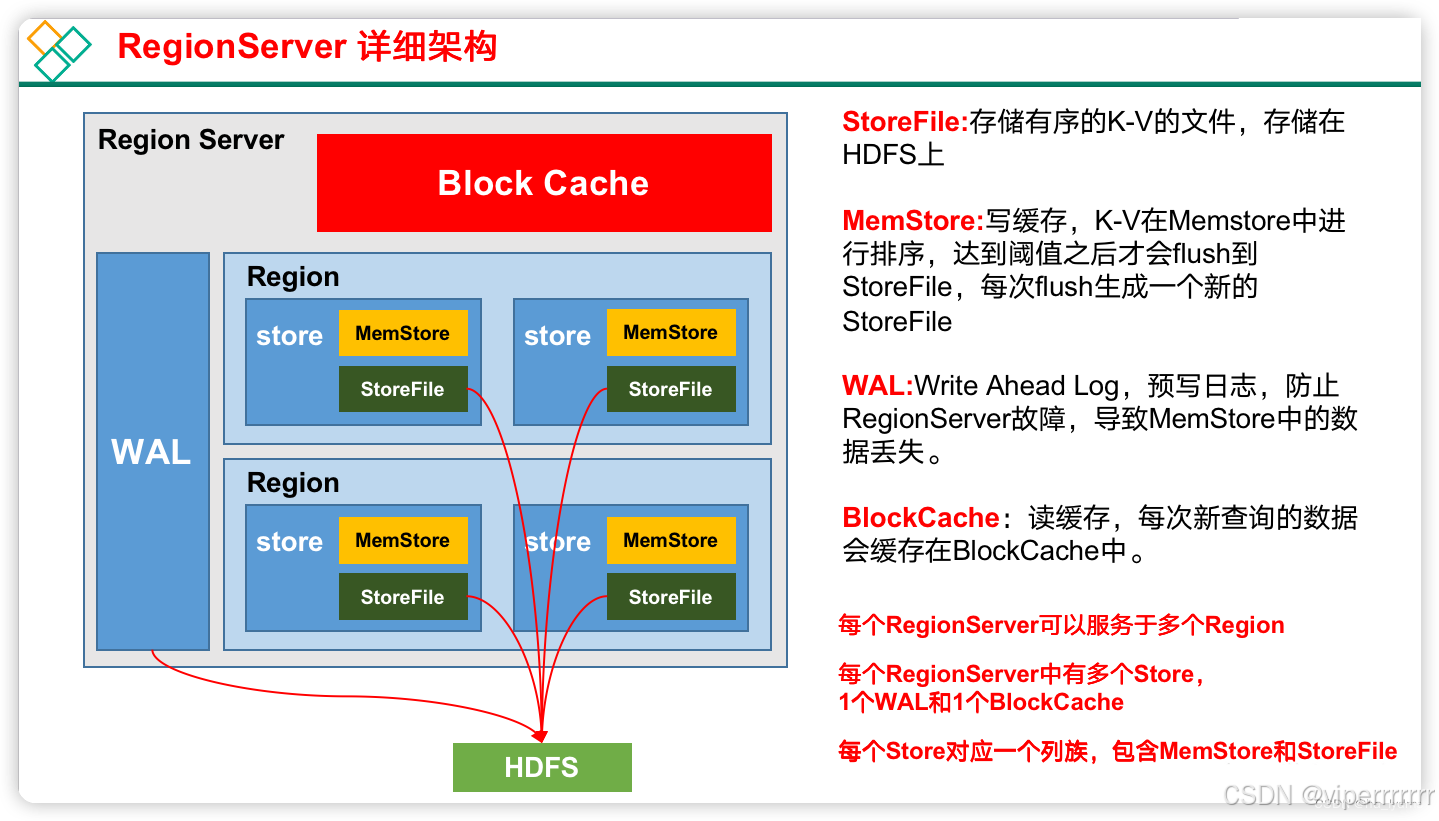
1)StoreFile
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
2)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
3)HLog
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个实现了Write-Ahead logfile机制的文件HLog中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
🍋六、Hive
Hive是CDH中的一个数据仓库工具,它提供了类似于SQL的查询语言(HiveSQL),它可以将结构化的数据映射到Hadoop集群中的文件,并支持高性能的数据查询和分析。Hive可以方便地进行数据的ETL(Extract、Transform、Load)操作,适用于数据分析和报表生成等任务。
Hive

基于 MapReduce 或 Tez:
Hive 最初是基于 MapReduce 的,MapReduce 是一种批处理框架,适合处理大规模数据,但延迟较高。即使后来引入了 Tez 作为执行引擎,Hive 仍然是以批处理为核心,不适合低延迟查询。
中间结果写磁盘:
MapReduce 和 Tez 在执行过程中会将中间结果写入磁盘,导致额外的 I/O 开销。
🍋七、Impala
Impala是CDH中的一个交互式查询引擎,它可以直接访问存储在Hadoop HDFS和HBase中的数据,并提供类似于SQL的查询语言。Impala通过在内存中执行查询操作,实现了低延迟的数据查询和分析,适用于实时数据处理和探索性数据分析等场景。
Impala
直接访问 HDFS:Impala 直接读取 HDFS 数据,避免了 MapReduce 的额外开销。
优化数据格式:Impala 对 Parquet 和 ORC 等列式存储格式进行了深度优化,能够快速读取和处理数据。
数据本地性:Impala 充分利用数据本地性(Data Locality),在数据所在的节点上执行计算,减少了数据传输的开销。
内存计算:Impala的计算引擎支持基于内存的计算,能够大大降低查询的延迟。与传统的基于磁盘的MapReduce计算模型相比,Impala的内存计算模型在处理大规模数据集时具有更高的性能。
分布式并行处理:Impala的计算引擎采用分布式并行处理架构,能够将查询任务拆分成多个子任务,并在多个节点上并行执行。这种架构能够充分利用集群的计算资源,提高查询的吞吐量。
与存储引擎分离:Impala的计算引擎与存储引擎是分离的,这意味着Impala可以支持多种不同的存储系统,如HDFS、HBase等。这种分离的设计使得Impala更加灵活和可扩展。
Impala 的功能相对精简,专注于 OLAP 场景,适合快速查询。Impala 的设计目标是低延迟查询,适合实时分析和交互式查询。
🍋八、Sqoop
Sqoop架构
(1) Sqoop Client
Sqoop的客户端组件,提供了命令行工具和API,用于与Sqoop Server进行通信,并提交数据导入和导出的任务。
(2) Sqoop Server
Sqoop的服务器组件,负责接收来自客户端的请求,并协调和管理数据导入和导出的任务。Sqoop Server可以在独立模式下运行,也可以与Hadoop集群中的其他组件(如HDFS、YARN)集成。
(3) Connector
Sqoop的连接器,用于与不同类型的关系型数据库进行交互。每个关系型数据库都需要一个相应的连接器来支持数据的导入和导出。Sqoop提供了一些内置的连接器,如MySQL、Oracle、SQL Server等,同时还支持自定义连接器。
(4) Metastore
Sqoop的元数据存储,用于保存与数据导入和导出相关的元数据信息,如表结构、字段映射、导入导出配置等。Metastore可以使用关系型数据库(如MySQL、PostgreSQL)或Hadoop的分布式文件系统(HDFS)来存储元数据。
(5) Hadoop/HDFS
Sqoop与Hadoop生态系统紧密集成,使用Hadoop的分布式文件系统(HDFS)来存储导入的数据。Sqoop可以将关系型数据库中的数据导入到HDFS中,也可以将HDFS中的数据导出到关系型数据库中。
Sqoop是CDH中的数据导入导出工具,它可以将关系型数据库(如Mysql、Oracle等)中的数据导入到Hadoop集群中的HDFS或HBase中,也可以将Hadoop集群中的数据导出到关系型数据库中。Sqoop支持自动化的数据传输和转换,方便进行数据的迁移和集成。
🍋九、Flume
Flume 的架构设计简单但非常灵活,主要由以下几个核心组件构成:Source、Channel 和 Sink。这些组件通过配置文件进行定义和连接,形成一个数据流管道。
9.1 Source
Source 是 Flume 的数据输入组件,负责从外部数据源收集数据,并将数据转换为 Flume 的内部事件(Event)格式。常见的 Source 类型包括:
Exec Source:从命令执行的输出中读取数据,例如从 tail -F 命令读取日志文件。
Spooling Directory Source:从指定目录中读取新文件的内容。
Netcat Source:通过网络套接字接收数据。
HTTP Source:通过 HTTP POST 请求接收数据。
9.2 Channel
Channel 是 Flume 的数据缓冲组件,负责在 Source 和 Sink 之间暂存数据,确保数据传输的可靠性和高效性。常见的 Channel 类型包括:
Memory Channel:将数据存储在内存中,适用于低延迟和高吞吐量的场景。
File Channel:将数据存储在磁盘文件中,适用于需要高可靠性的场景。
Kafka Channel:使用 Apache Kafka 作为 Channel,适用于需要高可用性和持久化的场景。
9.3 Sink
Sink 是 Flume 的数据输出组件,负责将 Channel 中的数据传输到目标存储系统。常见的 Sink 类型包括:
HDFS Sink:将数据写入到 Hadoop 分布式文件系统(HDFS)。
HBase Sink:将数据写入到 HBase 数据库。
ElasticSearch Sink:将数据写入到 Elasticsearch。
Kafka Sink:将数据写入到 Apache Kafka。
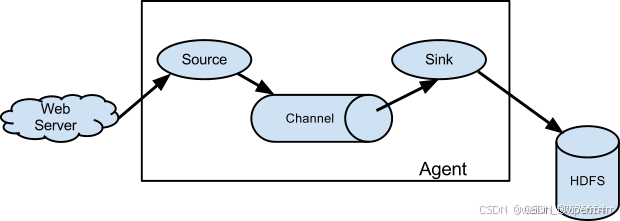
Flume是CDH中的一个日志收集和传输工具,它可以实时地将分布在不同计算节点上的日志数据收集到中央存储(如HDFS)中。Flume支持灵活的数据流管道配置,可以根据需求进行数据过滤、转换和路由操作,适用于大规模分布式系统的日志管理。
🍋十、ZooKeeper
ZooKeeper是CDH中的一个分布式协调服务,它可以实现分布式系统中的数据一致性和协同操作。ZooKeeper提供了高可用性和高性能的数据存储和访问接口,可以用于分布式锁、配置管理、命名服务等场景。
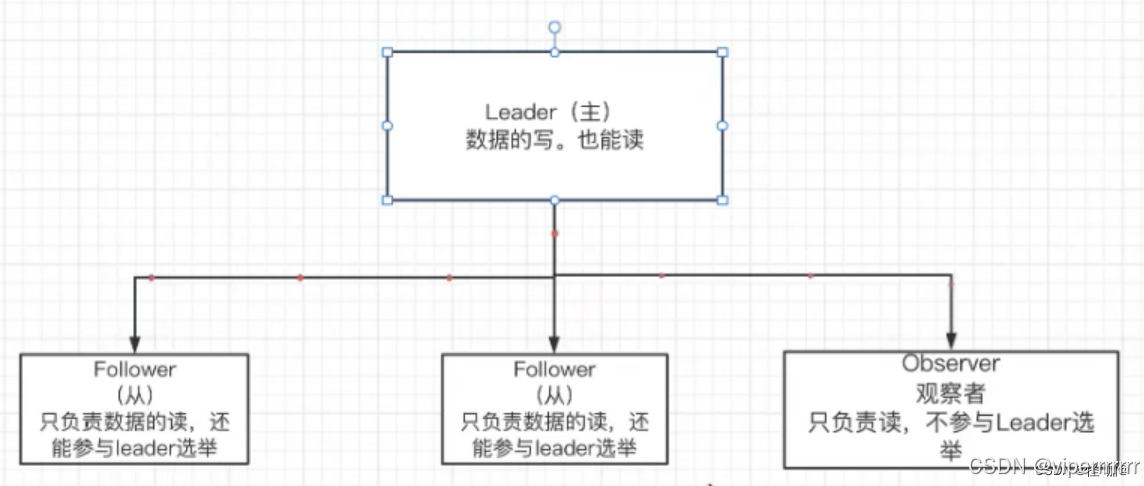
ZooKeeper的选举机制是基于ZAB(Zookeeper Atomic Broadcast)协议的,这是一种基于Paxos协议的变种,专门用于ZooKeeper的分布式协调服务。该机制确保集群中只有一个领导节点(Leader),负责处理所有的写请求和大部分的读请求,其他的节点则作为跟随者(Follower)或观察者(Observer),负责处理读请求并接收来自领导者的更新。
ZooKeeper 采用 主从架构,包含以下角色:
-
Leader
负责处理写请求和事务操作。通过选举机制产生。(ZooKeeper 的选举机制主要用于其集群管理,特别是在集群启动或领导者节点故障时,用于选出一个新的领导者节点。这个领导者节点将负责处理客户端的请求、维护集群状态以及与其他节点进行通信。) -
Follower
处理读请求,并将写请求转发给 Leader。参与 Leader 选举。 -
Observer(可选)
与 Follower 类似,但不参与选举,用于扩展读性能。 -
Client
与 ZooKeeper 集群交互的客户端。
🍋十一、Spark
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
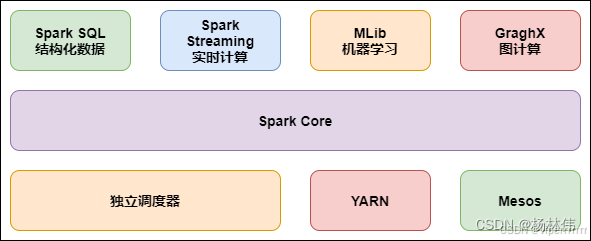
Spark有完善的生态圈,如下:
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
🍋十二、Oozie
Oozie是一个工作流调度和协调工具,它可以将多个Hadoop任务组织成一个工作流,并按照指定的时间和依赖关系进行调度执行。Oozie支持复杂的任务依赖关系和条件触发,可以实现数据处理和分析的自动化流程控制。
🍋十三、CM(Cloudera Manager)
CDH分为Cloudera Manager管理平台(CM)和CDH parcel(parcel包含各种组件的安装包),需要先安装CM,再安装parcel
CM(Cloudera Manager)提供了一个管理和监控Hadoop等大数据服务的web界面,能让我们方便安装大数据生态圈的大部分服务。(至于具体CM运行见:https://blog.csdn.net/weixin_61006262/article/details/146241299?spm=1011.2124.3001.6209)
相关文章:
大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

基于SpinrgBoot+Vue的医院管理系统-026
一、项目技术栈 Java开发工具:JDK1.8 后端框架:SpringBoot 前端:Vue开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 二、功能介绍 (1)…...

Mujoco xml模型
Mujoco xml模型 一个例子compileroptionassetmesh default基本使用childclass与class多个class worldbodybody关系inertialjointgeom XML主要分为以下三个部分: < asset> : 用 tag导入STL文件;< worldbody>:用tag定义…...
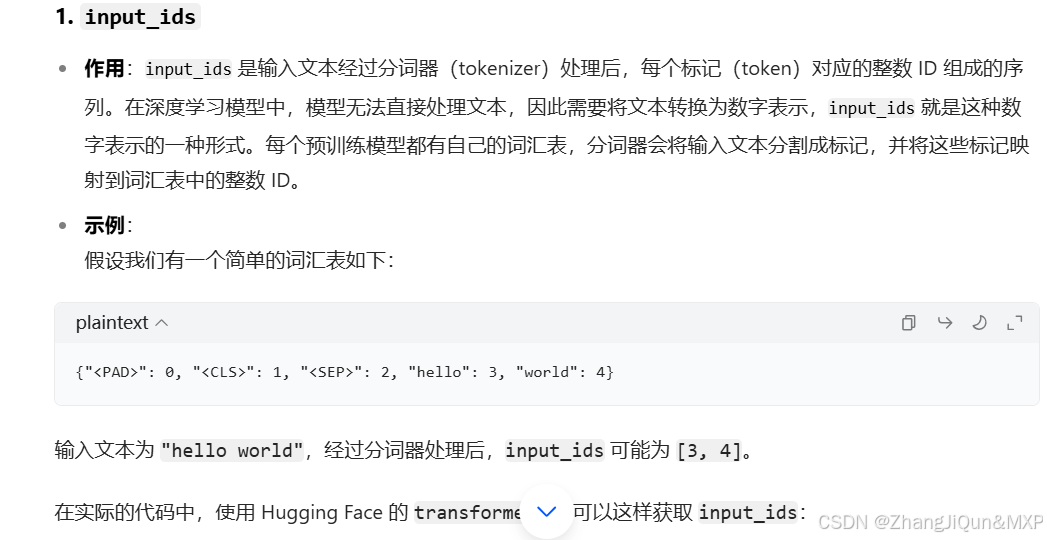
LLM 为什么使用ID,每个单词不都是有编码的吗
LLM 为什么使用ID,每个单词不都是有编码的吗 在自然语言处理(NLP)里,把文本转换为整数 ID 来表示是一种常见的做法,以下为你详细阐述使用 ID 的原因,以及是否每个单词都有编码。 使用 ID 的原因 1. 计算机可处理性 计算机没办法直接处理文本数据,因为文本是人类使用的…...

vue专题1---vue中绑定的自定义事件对应的事件处理函数,如何在传递参数的同时接收事件对象 event
在 Vue 中,如果想在事件处理函数中传递参数,可以使用箭头函数或者 v-bind 来实现。下面是两种常见的方法: 方法1:使用箭头函数 你可以直接在事件监听中使用箭头函数来传递参数,同时接收事件对象 e。 <template&g…...

转行嵌入式,需要自学多久?
作为一个本硕都学机械,却阴差阳错进入嵌入式行业的老兵,这个问题我能聊一整天。十几年前我还在工厂车间穿着工装和机床打交道,偶然接触到单片机后就一发不可收拾。 转行这条路我走得异常艰辛,踩过的坑比写过的代码还多。去年我终…...

实现抗隐私泄漏的AI人工智能推理
目录 什么是私人AI? 什么是可信执行环境? TEE 如何在 AI 推理期间保护数据? 使用 TEE 是否存在风险? 有哪些风险? Atoma 如何应对这些风险 为什么去中心化网络是解决方案 人工智能推理过程中还有其他保护隐私的方法吗? 私人人工智能可以实现什么? 隐私驱动的应…...

SeaTunnel系列之:Apache SeaTunnel编译和安装
Apache SeaTunnel编译 Prepare编译克隆源代码本地安装子项目从源代码构建 SeaTunnel构建子模块安装 JetBrains IDEA Scala 插件安装 JetBrains IDEA Lombok 插件代码风格运行简单示例不仅如此 安装下载 SeaTunnel 发布包下载连接器插件从源代码构建 SeaTunnel 运行 SeaTunnel 在…...

数据结构刷题之贪心算法
贪心算法(Greedy Algorithm) 是一种在每个步骤中都选择当前最优解的算法设计策略。它通常用于解决优化问题,例如最小化成本或最大化收益。贪心算法的核心思想是:在每一步选择中,都做出局部最优的选择,希望…...

Spring进阶:掌控Bean的作用域与生命周期
在上一篇文章中,我们了解了Spring IoC容器如何接管对象的创建和依赖注入,实现了松耦合。容器创建并管理的对象,我们称之为Bean。 但是,容器仅仅是创建Bean就够了吗?显然不是。我们还需要关心: 这个Bean在容…...

【Leetcode-Hot100】移动零
题目 解答 首先,使用的解题思路是:使用两个指针,分别指向数组的第一个0元素位置,以该元素位置1为起始点寻找接下来第一个非0元素位置。二者确定后,对其进行交换。随后继续寻找下一个0元素位置。重复上述操作。 但第一…...

安装 Calico 的两种主流方式对比
本文对比了 Calico 的两种主流安装方式: 使用 calico.yaml 的 Manifest 安装方式使用 Tigera Operator(tigera-operator.yaml custom-resources.yaml)安装方式 ✅ 1. 使用 Manifest 方式安装(直接部署 calico.yaml) …...

leetcode_203. 移除链表元素_java
203. 移除链表元素https://leetcode.cn/problems/remove-linked-list-elements/ 1、题目 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head …...

常见算法模板总结
文章目录 一、二叉树1. DFS2. BFS 二、回溯模板三、记忆化搜索四、动态规划1. 01背包朴素版本滚动数组优化 2. 完全背包朴素版本滚动数组优化 3. 最长递增子序列LIS朴素版本贪心二分优化 4. 最长公共子序列5. 最长回文子串 五、滑动窗口六、二分查找七、单调栈八、单调队列九、…...
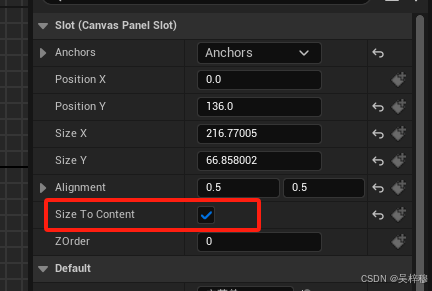
UE5学习笔记 FPS游戏制作44 统一UI大小 sizeBox
如果我们希望多个类似的UI大小一样,例如不同菜单的标题,可以使用sizeBox组件 我们在标题控件上,用sizeBox包裹所有子物体 然后指定他的最小宽高,或最大宽高 如果指定的是最小宽高,当子元素(如图片…...

# 基于BERT的文本分类
基于BERT的文本分类项目的实现 一、项目背景 该文本分类项目主要是情感分析,二分类问题,以下是大致流程及部分代码示例: 二、数据集介绍 2.1 数据集基本信息 数据集自定义类型二分类(正面/负面)样本量训练集 验证…...
C++学习之服务器EPOLL模型、处理客户端请求、向客户端回复数、向客户端发送文件
目录 1.启动epoll模型 2.和客户端建立新连接 3.接受客户端Http请求数据 4.代码回顾从接受的数据中读出请求行 5.请求行解析 6.正则表达式以及匹配 7.解析请求行以及后续处理 8.对path处理说明 9.如何回复响应数据 10.对文件对应content-type如何查询 11.服务器处理流…...

BUUCTF-web刷题篇(17)
26.BabyUpload 源码:https://github.com/imaginiso/GXY_CTF/tree/master/Web/babyupload 查看题目源码: 写着:SetHandler application/x-httpd-php 通过源码可以看出这道文件上传题目主要还是考察.htaccess配置文件的特性,倘若…...

国网B接口协议调阅实时视频接口流程详解以及检索失败原因(电网B接口)
文章目录 一、B接口协议调阅实时视频接口介绍B.6.1 接口描述B.6.2 接口流程B.6.3 接口参数B.6.3.1 SIP头字段B.6.3.2 SIP响应码B.6.3.3 SDP参数定义B.6.3.4 RTP动态Payload定义 B.6.4 消息示例B.6.4.1 调阅实时视频请求B.6.4.2 调阅实时视频请求响应 二、B接口调阅实时视频失败…...
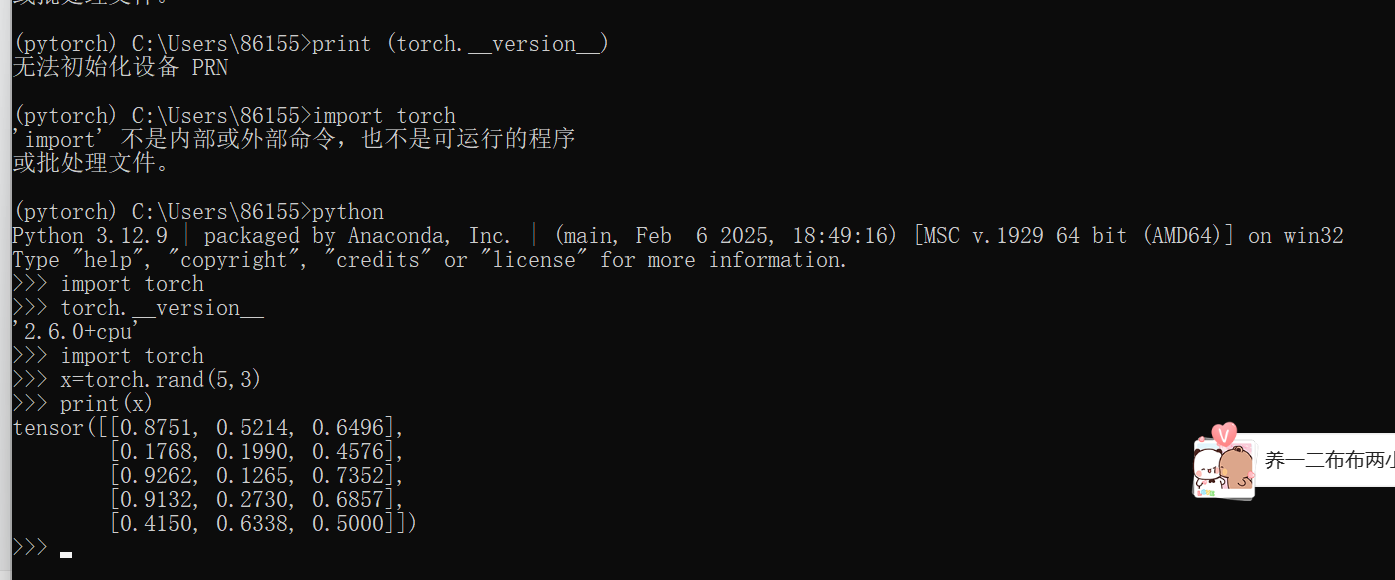
windows11下pytorch(cpu)安装
先装anaconda 见最下方 Pytorch 官网:PyTorch 找到下图(不要求版本一样)(我的电脑是集显(有navdia的装gpu),装cpu) 查看已有环境列表 创建环境 conda create –n 虚拟环境名字(…...
NVR接入录像回放平台用EasyCVR打造地下车库安防:大型商居安全优选方案
一、背景分析 随着居民生活品质的提升,大型商业建筑和住宅小区纷纷配套建设地下停车库。但是地下车库盗窃、失火、恶意毁坏车辆、外部人员随意进出等事件频发,部署视频监控系统成为保障地下车库的安全关键举措。 目前,很多商业和住宅都会在…...

玻璃期货数据下载与分析:Python金融实战分享
期货数据下载与分析:Python实战分享 引言 在金融市场中,期货分析是一项重要的工作,而获取准确且及时的数据是进行有效分析的基础。今天,我们将深入探讨一段使用Python编写的代码,该代码用于从郑州商品交易所…...
)
excel常见错误包括(#N/A、#VALUE!、#REF!、#DIV/0!、#NUM!、#NAME?、#NULL! )
目录 1. #N/A2. #VALUE!3. #REF!4. #DIV/0!5. #NUM!6. #NAME?7. #NULL!8.图表总结 在 Excel 中,可能会遇到以下常见的错误值,每个都有特定的含义和成因: 1. #N/A 含义: 表示“Not Available”(不可用)。…...

乾元通渠道商中标川藏铁路西藏救援队应急救援装备项目
乾元通渠道商中标川藏铁路西藏救援队应急救援装备项目,项目内通信指挥车基于最新一代应急指挥车解决方案打造,配合乾元通自研的车载多链路聚合路由及系统,主要用途为保障应急通讯,满足任务执行时指挥协调、通信联络及数据传输的要…...

数学知识——矩阵乘法
使用矩阵快速幂优化递推问题 对于一个递推问题,如递推式的每一项系数都为常数,我们可以使用矩阵快速幂来对算法进行优化。 一般形式为: F n F 1 A n − 1 F_nF_1A^{n-1} FnF1An−1 由于递推式的每一项系数都为常数,因此对…...
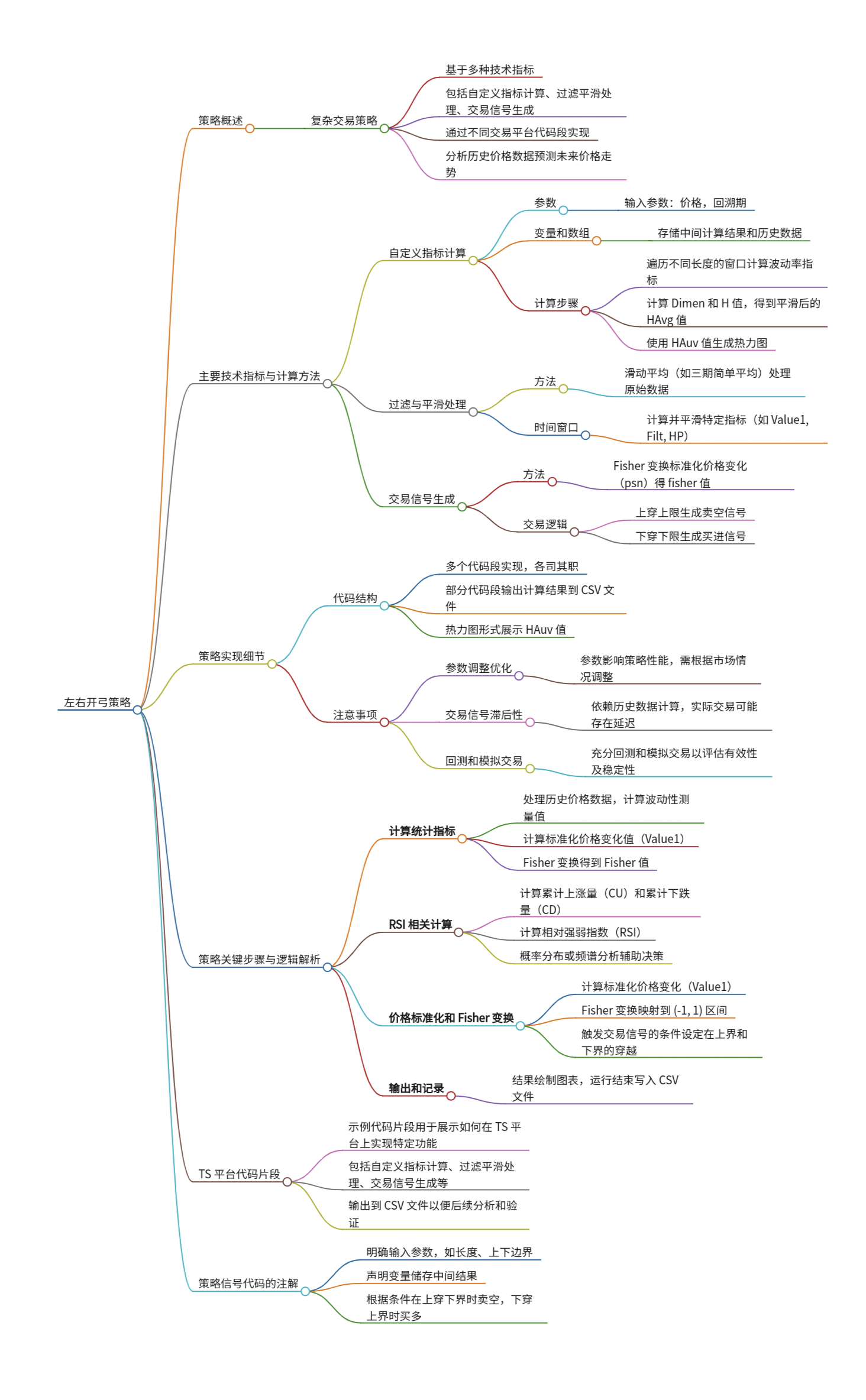
左右开弓策略思路
一、策略概述 本策略是一种基于多种技术指标的复杂交易策略,包括自定义指标计算、过滤平滑处理以及交易信号生成。 该策略通过不同的交易平台代码段实现,旨在通过分析历史价格数据来预测未来价格走势,并据此生成交易信号。 二、主要技术指标…...

将jar包制作成deb一键安装包
文章目录 准备环境准备deb包结构构建Deb包测试安装常用操作命令 本文介绍如何将java运行环境、jar程序一起打包成一个deb格式的安装包,创建桌面图标,通过点击图标可使用系统自带浏览器快捷访问web服务的URL,同时注册服务并配置好开机自启。 准…...

Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明
以下是 Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明: 1. 授权模型类型与定义 模型名称定义特点RBAC(基于角色的访问控制)通…...

aws平台练习
注册 AWS 账户 访问 AWS 官方网站,点击“免费注册”按钮,按照提示完成账户注册: 提供电子邮件地址、密码和电话号码。 验证身份(可能需要手机验证码)。 设置 billing 信息。 2. 登录 AWS 管理控制台 使用注册的邮箱和…...

力扣DAY40-45 | 热100 | 二叉树:直径、层次遍历、有序数组->二叉搜索树、验证二叉搜索树、二叉搜索树中第K小的元素、右视图
前言 简单、中等 √ 好久没更了,感觉二叉树来回就那些。有点变懒要警醒,不能止步于笨方法!! 二叉树的直径 我的题解 遍历每个节点,左节点最大深度右节点最大深度当前节点当前节点为中心的直径。如果左节点深度更大…...