量子计算模拟中的GPU加速:从量子门操作到Shor算法实现
一、量子模拟的算力困境与GPU破局
量子计算模拟面临指数级增长的资源需求:n个量子比特的态向量需要2^n个复数存储空间。当n>30时,单机内存已无法承载(1TB需求)。传统CPU模拟器(如Qiskit的Aer)在n=28时计算速度降至0.1门操作/秒。
GPU凭借大规模并行计算能力和高带宽内存成为破局关键:
- 单个A100 GPU的显存带宽达2TB/s(是DDR4的10倍)
- CUDA的线程分级机制(Block/Grid/Warp)完美匹配量子门操作的张量并行性
- 混合精度计算可将单精度浮点运算速度提升至19.5 TFLOPS
二、量子模拟的GPU加速核心设计
2.1 量子态表示与存储优化
采用分块压缩存储策略降低显存压力:
# CUDA核函数实现量子态分块存储
__global__ void quant_state_compress(cuComplex *state, int n_qubits) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < (1 << (n_qubits-3))) { // 按8-qubit分块 // 执行稀疏化压缩(阈值1e-7) if (cuCabsf(state[idx]) < 1e-7) state[idx] = make_cuComplex(0,0); }
} 实验显示,该策略在n=30时可减少显存占用62%
2.2 量子门操作的并行化实现
以CNOT门为例,GPU加速的关键在于位操作映射的并行化:
// CNOT门的CUDA核函数
__global__ void cnot_gate(cuComplex *state, int ctrl, int target, int n) { int idx = threadIdx.x + blockIdx.x * blockDim.x; int mask = 1 << target; if (idx & (1 << ctrl)) { int paired_idx = idx ^ mask; cuComplex temp = state[idx]; state[idx] = state[paired_idx]; state[paired_idx] = temp; }
} 测试表明,在A100上执行10^6次CNOT门操作仅需1.2ms,比Qiskit Aer快1200倍
2.3 Shor算法的关键优化
针对Shor算法的模幂运算(modular exponentiation),采用预计算-并行化策略:
- 预先计算a(2i) mod N的结果(i=0,1,…,2n)
- 使用CUDA的原子操作并行化连分数展开计算:
from numba import cuda
@cuda.jit
def continued_fraction(q, N, results): idx = cuda.grid(1) s = 0 for k in range(1, 200): den = (k*q) // N if den !=0 and (k*q) % N == 1: results[idx] = k return 在RTX 4090上分解1024位整数,该优化使计算速度提升17倍
三、混合编程实践:Qiskit+CUDA协同加速
3.1 系统架构设计
核心流程:
- Qiskit解析量子线路生成中间表示(OpenQASM 2.0)
- CUDA动态生成设备端内核函数
- 使用Zero-Copy内存实现主机-设备零拷贝传输
3.2 性能对比实验
| 量子比特数 | Qiskit Aer (s) | CUDA加速 (s) | 加速比 |
|---|---|---|---|
| 20 | 12.7 | 0.48 | 26x |
| 25 | 328.5 | 5.12 | 64x |
| 28 | 超时(>3600) | 87.3 | >41x |
测试环境:Intel Xeon 6346 + NVIDIA A100 80GB
四、技术挑战与优化方向
- 内存墙限制:n>35时显存容量成为瓶颈,需探索分布式GPU集群方案
- 通信开销:量子纠缠操作导致PCIe传输延迟,可尝试NVIDIA NVSwitch技术
- 算法革新:将Tensor Core应用于幺正矩阵的分解计算(SVD加速)
- 混合精度优化:FP16/FP32混合训练可将门操作速度提升40%
结语
量子计算模拟的GPU加速正在突破经典计算的极限。通过Qiskit与CUDA的深度融合,我们在Shor算法实现中取得了数量级的性能提升。随着Hopper架构的HBM3显存和第三代张量核心的普及,未来有望在单卡上突破40量子比特模拟大关。这场经典与量子的算力博弈,正在GPU的并行架构中书写新的篇章。
参考文献
- Qiskit Aer白皮书. IBM Research, 2023
- NVIDIA A100架构解析. 英伟达开发者博客
- 量子模拟的GPU加速方法. IEEE QC 2024
- Shor算法优化实践. ACM SIGMOD 2025
相关文章:

量子计算模拟中的GPU加速:从量子门操作到Shor算法实现
一、量子模拟的算力困境与GPU破局 量子计算模拟面临指数级增长的资源需求:n个量子比特的态向量需要2^n个复数存储空间。当n>30时,单机内存已无法承载(1TB需求)。传统CPU模拟器(如Qiskit的Aer)在n28…...

牛客 小红杀怪
通过枚举所有使用y技能的次数来枚举出所有方案,选出最合适的 #include<iostream> #include<cmath> #include<algorithm> using namespace std;int a, b, x, y; int ans500;int main() {ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);cin>&…...

部署大模型不再难:DeepSeek + 腾讯云 HAI 实战教程
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...
系统:数字化转型的核心引擎)
企业资源计划(ERP)系统:数字化转型的核心引擎
在当今高度数字化的商业环境中,企业资源计划(Enterprise Resource Planning,ERP)系统已成为企业优化运营、提升竞争力的重要工具。本文将从定义与发展、核心功能模块、行业应用场景、优势与挑战以…...

基于二叉堆实现的 PriorityQueue
基于二叉堆实现的 PriorityQueue 是一种常见的数据结构,广泛用于任务调度、路径搜索、事件模拟等场景。下面我将用 Java 语言实现一个简单的基于最小堆的 PriorityQueue,即优先级最小的元素先出队。 ✅ 实现目标 使用数组实现二叉最小堆(即父…...
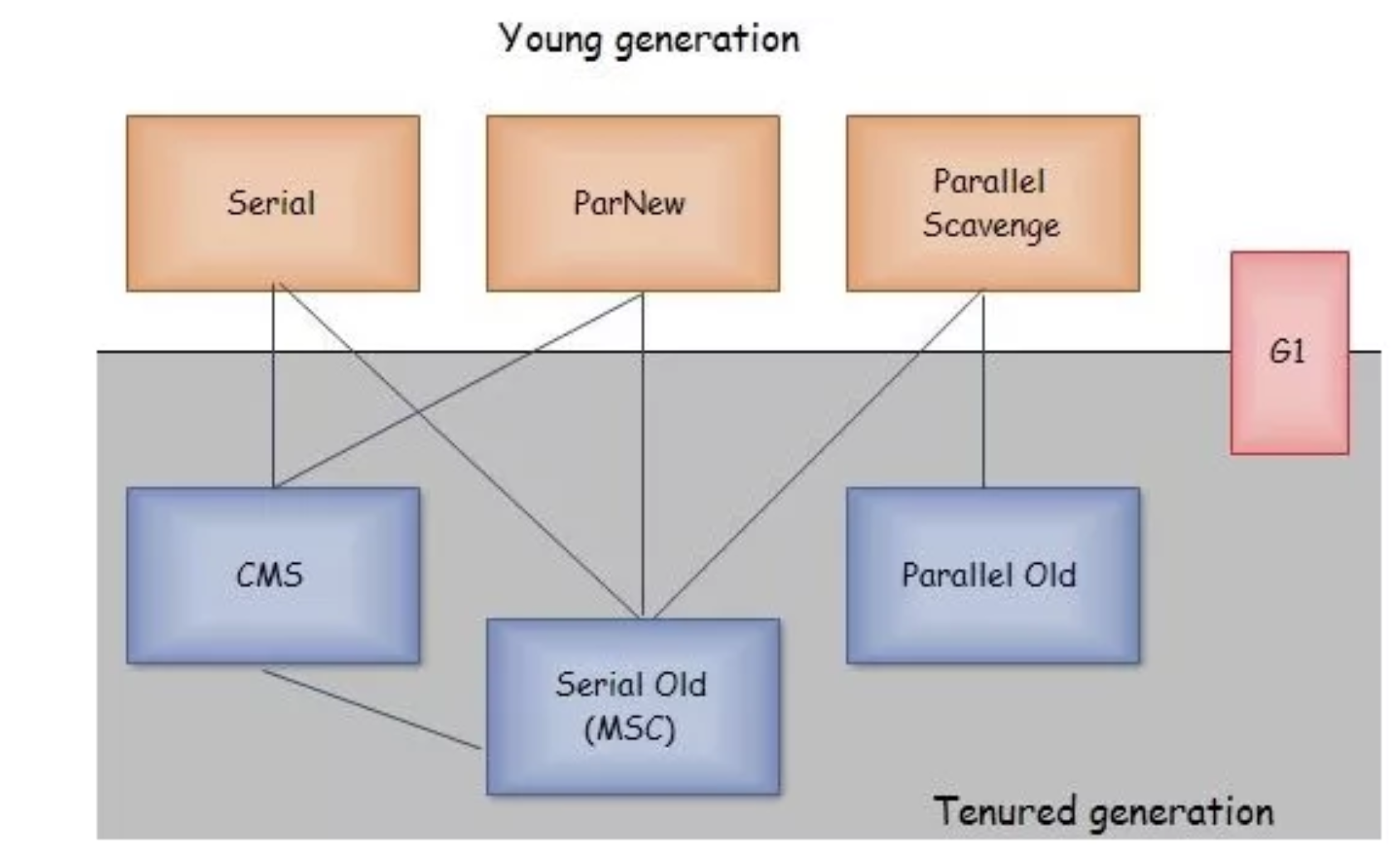
JVM中常见的垃圾回收器(Garbage Collectors)
JVM中常见的垃圾回收器(Garbage Collectors)的分类和描述: 一、新生代收集器(Young Generation Collectors) 新生代收集器主要负责收集新创建的对象,这些对象通常存活时间较短。 Serial GC • 单线程收集…...
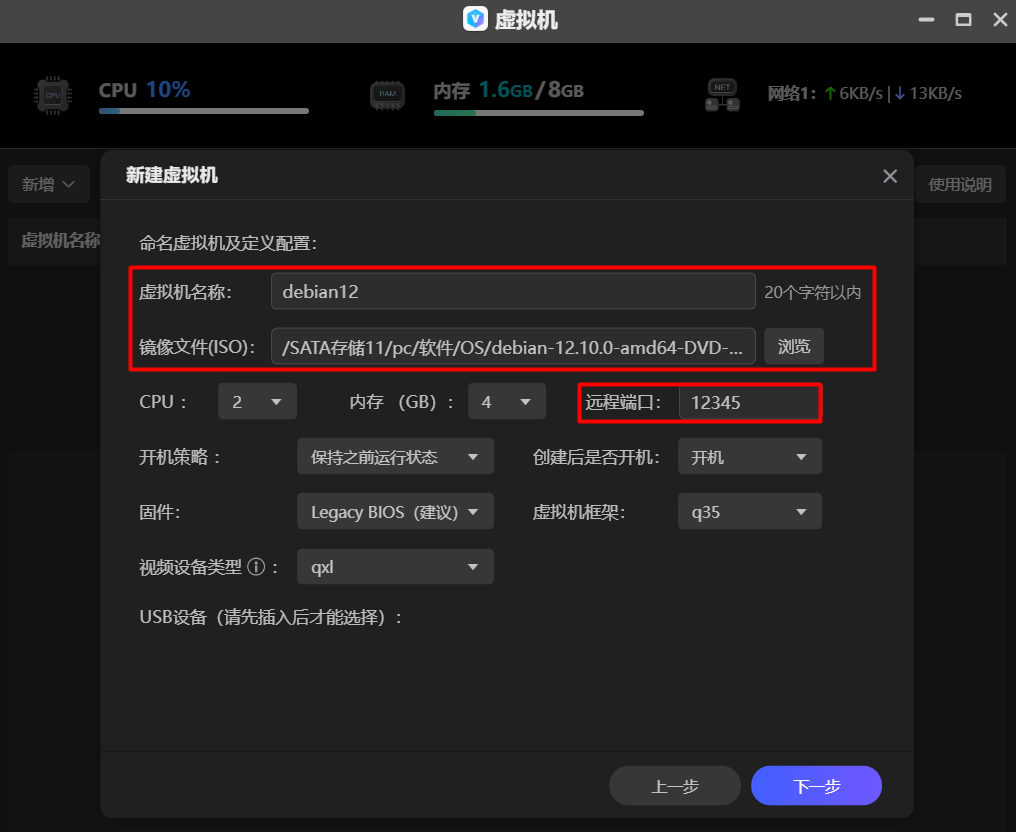
极空间NAS进阶玩法:Debian 系统安装教程
文章目录 第 1 步:下载 Debian 镜像第 2 步:创建虚拟机创建虚拟机安装操作系统第 3 步:登录 Debian第 4 步:使用 Docker 搭建跳板机远程访问参考🚀 本文目标:在极空间 NAS 中安装 Debian 12。 第 1 步:下载 Debian 镜像 下载地址:https://www.debian.org/distrib/ 第…...

煤矿数据机房防静电地板:智能化时代的“隐形守护者”
在煤矿行业,调度室不仅是安全生产的“大脑”,更是数据交互的“神经中枢”。随着智能化升级,如今的煤矿调度室早已不再是传统的电话挂图配置,而是集成了高清监控、精准定位系统、智能传感器等高精密电子设备的数字化空间。然而&…...
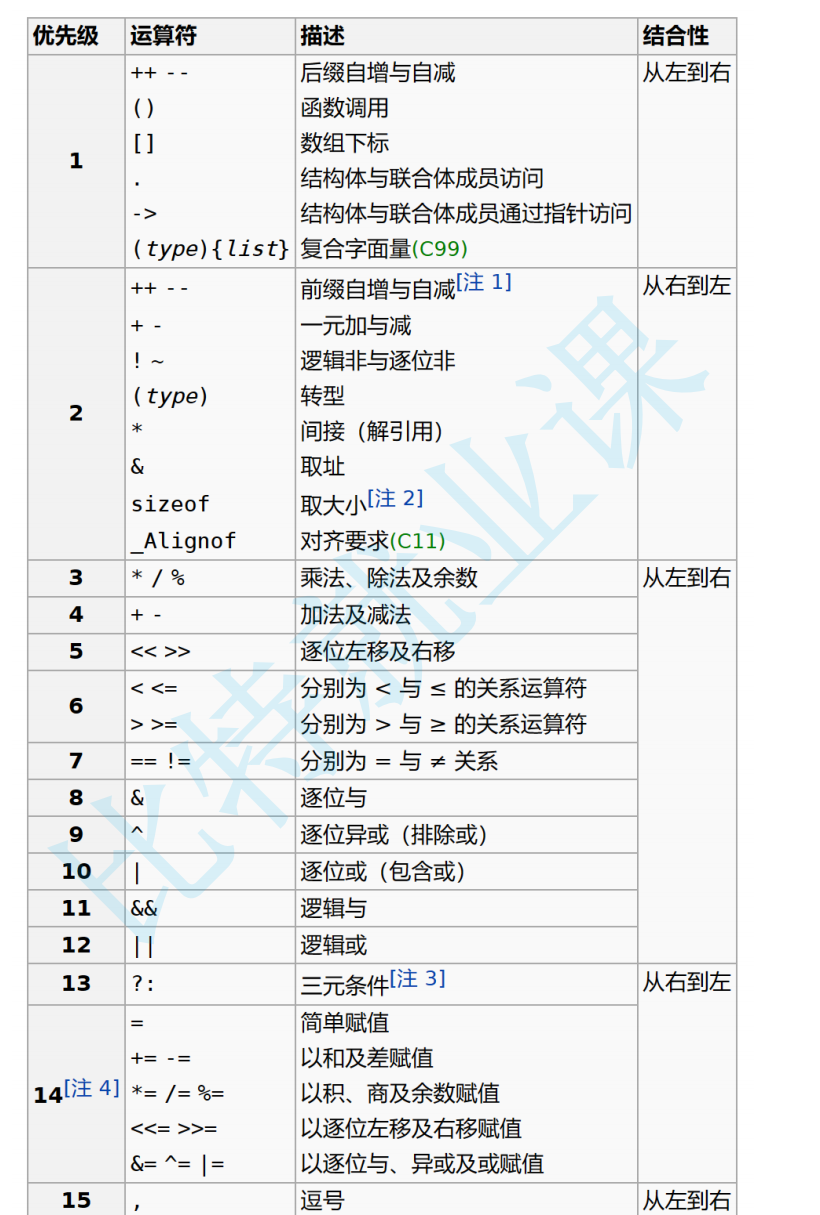
操作符详解(下)——包含整形提升
1.讲解剩下的操作符 1.1:逗号表达式 逗号表达式,就是用逗号隔开的多个表达式。 逗号表达式,从左向右依次执⾏。整个表达式的结果是最后⼀个表达式的结果 例题1: //C的值是多少? int main() {int a 1;int b 2;int c (a &g…...

Kairos 的野望:构建“智能体即服务”生态,让万物皆可 “Agent”
随着 AI Agent 成为 AI 领域的主要叙事,AI 赛道的发展也逐渐进入到 2.0 时代。聚焦于 AI Agent 概念本身,其是一种具备感知环境、进行决策和执行任务或服务的智能系统,它们通常能够理解自然语言指令,学习用户偏好,并在…...
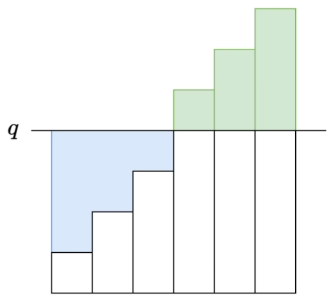
LeetCode 2968.执行操作使频率分数最大
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。 你可以对数组执行 至多 k 次操作: 从数组中选择一个下标 i ,将 nums[i] 增加 或者 减少 1 。 最终数组的频率分数定义为数组中众数的 频率 。 请你返回你可以得到的 最大 频率分数。 众数指的…...

多模态智能体框架MM-StoryAgent:跨模态叙事视频生成的技术突破
一、研究背景与核心价值 由上海交通大学与阿里巴巴联合研发的MM-StoryAgent系统,基于多智能体协同框架实现了故事创作到视频生成的完整自动化流程。该系统通过整合文本、视觉、语音、音效等多模态生成技术,构建了包含角色一致性保持、跨模态适配优化等创新机制的叙事内容生产…...

Codeforces Round 1013 (Div. 3)
Problem - A - Codeforces 解题思路: 对每个需要的数字进行计数 #include<bits/stdc.h> using namespace std;int main() {int t;cin >> t;while (t--){int n;cin >> n;int two 2;int zero 3;int five 1;int three 1;int one 1;int flag …...

STM32 CRC校验与芯片ID应用全解析:从原理到实践 | 零基础入门STM32第九十七步
主题内容教学目的/扩展视频CRC与芯片ID原理实现CRC校验和读取芯片ID为单片机应用提供数据验证和身份识别的功能。 师从洋桃电子,杜洋老师 📑文章目录 一、CRC校验功能解析1.1 CRC基本原理1.2 核心功能对比 二、CRC校验应用实战2.1 典型应用场景2.2 程序实…...

巴特沃斯滤波器
一、MATLAB 实现 1. 巴特沃斯滤波器函数(支持图像/信号) function H butterworth_filter(D0, size, n, mode) % BUTTERWORTH_FILTER 生成巴特沃斯滤波器 % - D0: 截止频率 % - size: 滤波器尺寸(图像:[height, width]&…...
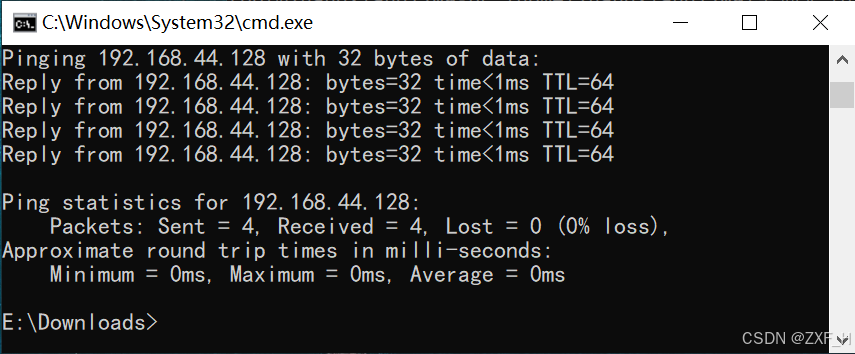
银河麒麟系统虚拟机网络ping不通的解决方法
问题描述:使用NAT模式搭建了银河麒麟系统虚拟主机,虚拟机内部可以联网,可以查询到具体的ip地址,同时也可以在虚拟机内部ping同宿主机ip,但使用宿主机却无法ping同银河麒麟虚拟机ip,使用ssh、ftp、sftp等工具…...
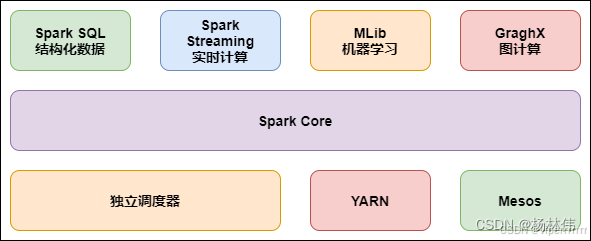
大数据学习(105)-大数据组件分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

基于SpinrgBoot+Vue的医院管理系统-026
一、项目技术栈 Java开发工具:JDK1.8 后端框架:SpringBoot 前端:Vue开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 二、功能介绍 (1)…...

Mujoco xml模型
Mujoco xml模型 一个例子compileroptionassetmesh default基本使用childclass与class多个class worldbodybody关系inertialjointgeom XML主要分为以下三个部分: < asset> : 用 tag导入STL文件;< worldbody>:用tag定义…...
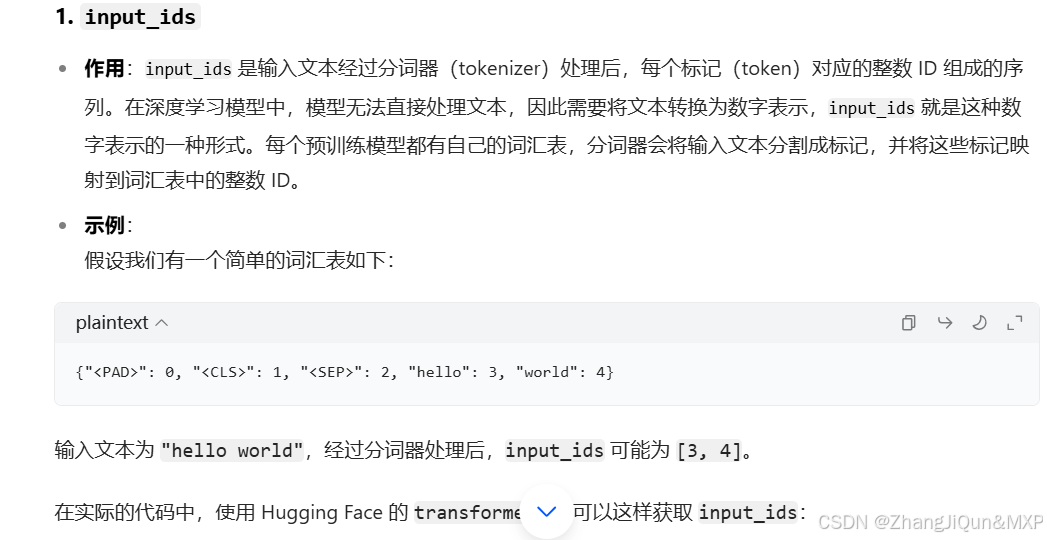
LLM 为什么使用ID,每个单词不都是有编码的吗
LLM 为什么使用ID,每个单词不都是有编码的吗 在自然语言处理(NLP)里,把文本转换为整数 ID 来表示是一种常见的做法,以下为你详细阐述使用 ID 的原因,以及是否每个单词都有编码。 使用 ID 的原因 1. 计算机可处理性 计算机没办法直接处理文本数据,因为文本是人类使用的…...

vue专题1---vue中绑定的自定义事件对应的事件处理函数,如何在传递参数的同时接收事件对象 event
在 Vue 中,如果想在事件处理函数中传递参数,可以使用箭头函数或者 v-bind 来实现。下面是两种常见的方法: 方法1:使用箭头函数 你可以直接在事件监听中使用箭头函数来传递参数,同时接收事件对象 e。 <template&g…...

转行嵌入式,需要自学多久?
作为一个本硕都学机械,却阴差阳错进入嵌入式行业的老兵,这个问题我能聊一整天。十几年前我还在工厂车间穿着工装和机床打交道,偶然接触到单片机后就一发不可收拾。 转行这条路我走得异常艰辛,踩过的坑比写过的代码还多。去年我终…...

实现抗隐私泄漏的AI人工智能推理
目录 什么是私人AI? 什么是可信执行环境? TEE 如何在 AI 推理期间保护数据? 使用 TEE 是否存在风险? 有哪些风险? Atoma 如何应对这些风险 为什么去中心化网络是解决方案 人工智能推理过程中还有其他保护隐私的方法吗? 私人人工智能可以实现什么? 隐私驱动的应…...

SeaTunnel系列之:Apache SeaTunnel编译和安装
Apache SeaTunnel编译 Prepare编译克隆源代码本地安装子项目从源代码构建 SeaTunnel构建子模块安装 JetBrains IDEA Scala 插件安装 JetBrains IDEA Lombok 插件代码风格运行简单示例不仅如此 安装下载 SeaTunnel 发布包下载连接器插件从源代码构建 SeaTunnel 运行 SeaTunnel 在…...

数据结构刷题之贪心算法
贪心算法(Greedy Algorithm) 是一种在每个步骤中都选择当前最优解的算法设计策略。它通常用于解决优化问题,例如最小化成本或最大化收益。贪心算法的核心思想是:在每一步选择中,都做出局部最优的选择,希望…...

Spring进阶:掌控Bean的作用域与生命周期
在上一篇文章中,我们了解了Spring IoC容器如何接管对象的创建和依赖注入,实现了松耦合。容器创建并管理的对象,我们称之为Bean。 但是,容器仅仅是创建Bean就够了吗?显然不是。我们还需要关心: 这个Bean在容…...

【Leetcode-Hot100】移动零
题目 解答 首先,使用的解题思路是:使用两个指针,分别指向数组的第一个0元素位置,以该元素位置1为起始点寻找接下来第一个非0元素位置。二者确定后,对其进行交换。随后继续寻找下一个0元素位置。重复上述操作。 但第一…...

安装 Calico 的两种主流方式对比
本文对比了 Calico 的两种主流安装方式: 使用 calico.yaml 的 Manifest 安装方式使用 Tigera Operator(tigera-operator.yaml custom-resources.yaml)安装方式 ✅ 1. 使用 Manifest 方式安装(直接部署 calico.yaml) …...

leetcode_203. 移除链表元素_java
203. 移除链表元素https://leetcode.cn/problems/remove-linked-list-elements/ 1、题目 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1: 输入:head …...

常见算法模板总结
文章目录 一、二叉树1. DFS2. BFS 二、回溯模板三、记忆化搜索四、动态规划1. 01背包朴素版本滚动数组优化 2. 完全背包朴素版本滚动数组优化 3. 最长递增子序列LIS朴素版本贪心二分优化 4. 最长公共子序列5. 最长回文子串 五、滑动窗口六、二分查找七、单调栈八、单调队列九、…...