Elasticsearch 8.X 如何利用嵌入向量提升搜索能力?
众所周知,Elasticsearch 是一个非常流行的搜索引擎,因为它速度快、扩展性强,尤其擅长全文搜索。
近两年,向量嵌入(Vector Embedding)技术的引入,让 Elasticsearch 在处理高级搜索场景时变得更强大,比如语义搜索、推荐系统和 AI 驱动的查询。
干货 | 详述 Elasticsearch 向量检索发展史
Elasticsearch 8.X 向量检索和普通检索能否实现组合检索?如何实现?
高维向量搜索:在 Elasticsearch 8.X 中利用 dense_vector 的实战探索
我们来一步步拆解这个技术。

1、什么是向量嵌入?
简单来说,向量嵌入就是把文字、图片或者其他数据变成一组多维的数字(数学数组)。这些数字能让机器理解数据之间的“语义相似性”。
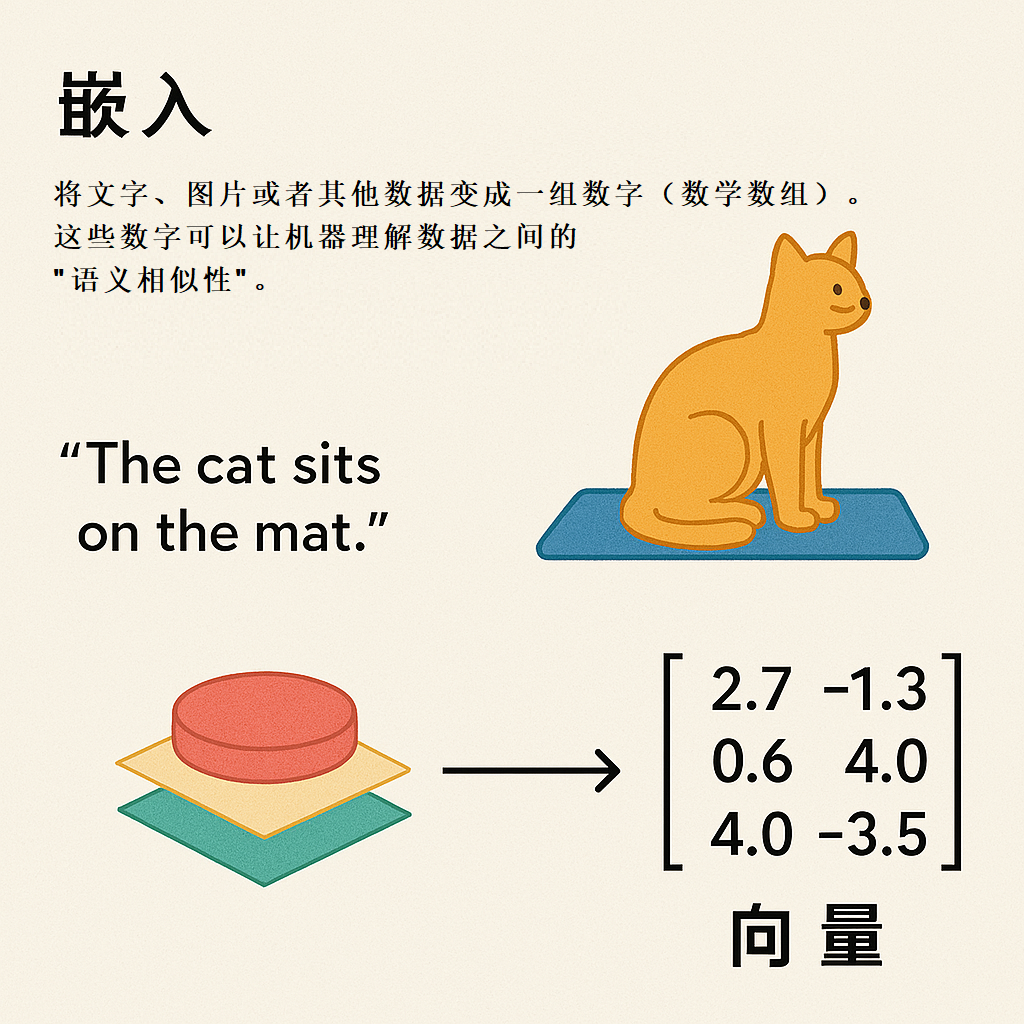
比如,你搜索“新能源 小米”汽车,即使结果里没有完全匹配的关键词,系统也能返回像“小米 SU7”这样的内容,因为它们在语义上是相关的。
2、在Elasticsearch中使用向量嵌入
要在 Elasticsearch 里用上向量嵌入,需要一个完整的流程:
2.1 生成向量嵌入
用AI模型(比如OpenAI的嵌入模型或Transformer模型)把原始文本转成一组数字,这些数字反映了数据之间的关系。
2.2 在Elasticsearch中存储向量
把生成的向量作为字段存进 Elasticsearch,方便后续基于相似性的查询。

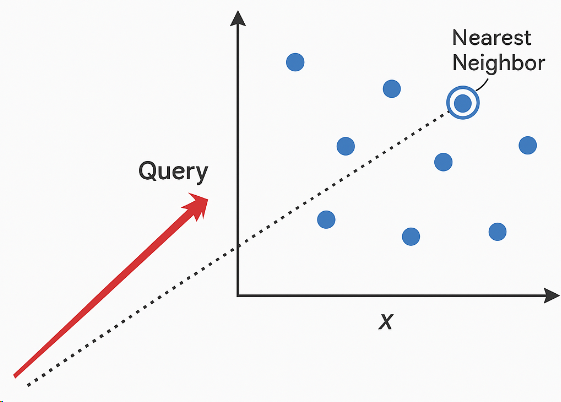
2.3 用向量查询
不再是简单的关键词搜索,而是把查询也转成向量,通过比较向量之间的“距离”来找到最接近的结果,这种方法叫“最近邻搜索”(Nearest Neighbor Search)。
2.4 向量嵌入大致流程如下
Step1:提取关键数据(比如标题、描述)。
Step2:用AI模型生成嵌入向量(可以用 Python工具,比如HuggingFace 或 sentence-transformers)。
Step3:把这些向量存进Elasticsearch,用的是“dense_vector”字段类型。
深入浅出 Elasticsearch 的 dense_vector 字段类型
Step4:通过Elasticsearch的 KNN(k-Nearest Neighbor)功能实现向量查询。
接下来,我们重点聊聊怎么为 Elasticsearch 生成向量嵌入,尤其针对日志数据的场景,咱们介绍了两种方法。
3、基于 Python 的实现向量嵌入
用Python实现时,通常会借助elasticsearch或requests库,直接跟Elasticsearch交互。
完整代码实现如下:
from elasticsearch import Elasticsearch, helpersimport requestsimport configparserimport warningsimport timeimport randomimport concurrent.futuresimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)# 忽略警告信息(如果需要)warnings.filterwarnings("ignore")# 初始化 Elasticsearch 客户端,根据指定的配置文件读取连接信息。def init_es_client(config_path='./conf/config.ini'): """初始化并返回基于配置文件中的 Elasticsearch 客户端""" config = configparser.ConfigParser() config.read(config_path) es_host = config.get('elasticsearch', 'ES_HOST') es_user = config.get('elasticsearch', 'ES_USER') es_password = config.get('elasticsearch', 'ES_PASSWORD') es = Elasticsearch( hosts=[es_host], basic_auth=(es_user, es_password), verify_certs=False, ca_certs='conf/http_ca.crt' ) return es# 设置嵌入服务 URL 为本地 Ollama 的端点EMBEDDING_SERVICE_URL = "http://localhost:11434/api/embeddings"# 从 Elasticsearch 中获取尚未生成嵌入的文档,使用 scroll API 提高效率。def fetch_documents_from_elasticsearch(es_client, index="logs", query=None, batch_size=25): """ 从 Elasticsearch 中获取缺少嵌入的文档 """ query = query or { "query": { "bool": { "must_not": {"exists": {"field": "embedding"}} } }, "size": batch_size, "sort": [{"@timestamp": "asc"}] } response = es_client.search(index=index, body=query, scroll="1m") scroll_id = response["_scroll_id"] documents = response["hits"]["hits"] while documents: for doc in documents: yield doc response = es_client.scroll(scroll_id=scroll_id, scroll="1m") scroll_id = response["_scroll_id"] documents = response["hits"]["hits"]# 通过向嵌入服务发送 POST 请求,为给定的文本获取嵌入向量。def fetch_embeddings(text): try: response = requests.post( EMBEDDING_SERVICE_URL, json={"model": "all-minilm", "prompt": text}, timeout=10 ) response.raise_for_status() result = response.json() logger.info("result.embedding: %s", result["embedding"]) return result.get("embedding") except requests.exceptions.RequestException as e: logger.error("Error fetching embedding: %s", str(e)) return None# 更新 Elasticsearch 中的文档,添加嵌入向量及元数据,使用脚本避免覆盖已有数据。def update_document_in_elasticsearch(es_client, doc_id, index="logs", embedding=None): """ 更新 Elasticsearch 文档,添加嵌入数据 """ body = { "script": { "source": ''' if (ctx._source.containsKey("embedding_processed_at") && ctx._source.embedding_processed_at != null) { ctx.op = "noop"; } else { ctx._source.embedding = params.embedding; ctx._source.embedding_processed_at = params.timestamp; ctx._source.processing_status = params.status; if (params.error_message != null) { ctx._source.error_message = params.error_message; } } ''', "params": { "embedding": embedding if embedding else None, "timestamp": time.strftime('%Y-%m-%dT%H:%M:%SZ'), "status": "failed" if embedding is None else "success", "error_message": None if embedding else "嵌入生成失败" } } } es_client.update(index=index, id=doc_id, body=body)# 主函数,协调获取文档、生成嵌入并更新 Elasticsearch 的流程,按批次处理。def process_documents(es_client, batch_size=25): """ 主函数:获取文档,生成嵌入,并更新 Elasticsearch """ for doc in fetch_documents_from_elasticsearch(es_client, batch_size=batch_size): doc_id = doc["_id"] text_content = doc["_source"].get("content", "") embedding = fetch_embeddings(text_content) update_document_in_elasticsearch(es_client, doc_id, embedding=embedding)if __name__ == "__main__": # 初始化 Elasticsearch 客户端 es = init_es_client(config_path='./conf/config.ini') # 开始处理文档 process_documents(es, batch_size=25)其中:Ollama 是一个轻量级的开源工具,用于运行语言模型并生成嵌入向量(embeddings)。在这里,它被用作嵌入生成服务。
最核心:"model": "all-minilm"。主要指——指定使用名为 "all-minilm" 的模型来生成嵌入向量。
all-minilm 是 Sentence Transformers 模型家族中的一种轻量级模型(基于 MiniLM),适用于生成短文本的嵌入,速度快且资源占用低。 Ollama 支持加载此类模型,并通过 API 提供服务。
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
执行结果:
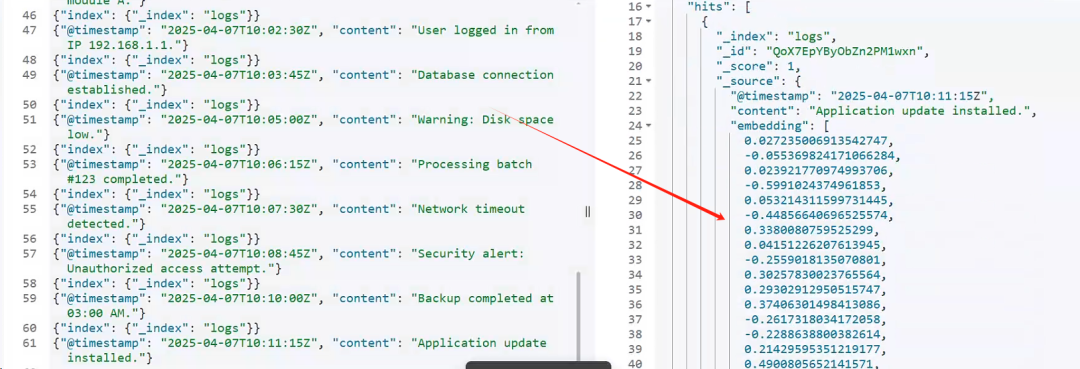
3.1 python 方案嵌入向量优点
灵活性强——可以完全控制数据处理、错误处理和重试策略。
调试方便——支持详细的日志记录和调试。
精细控制——能调整并发、批次大小和重试逻辑。
AI集成简单——跟机器学习模型、大语言模型无缝衔接。
3.2 python 方案嵌入向量缺点
扩展性有限——Python的全局解释器锁(GIL)限制了多线程在CPU密集任务中的表现。
开发成本高——需要手动处理重试、错误监控和优化。
资源占用多——处理大数据时,内存和 CPU 消耗较高。
4、基于 Logstash 实现向量嵌入
4.1 概览
Logstash 是一个轻量级、可扩展的 ETL 工具,特别适合处理大数据流。
4.2 Logstash 嵌入向量实操指南
4.2.1 【输入】Elasticsearch 输入
input {elasticsearch {hosts => ["https://127.0.0.1:9200"]user => "elastic"password => "changeme"ssl_enabled => trueca_file => "E:\logstash-8.15.3-windows-x86_64\logstash-8.15.3\config\http_ca.crt"index => "logs_20250409"query => '{"query": {"bool": {"must_not": {"exists": {"field": "embedding"}}}}}'schedule => "*/1 * * * *"docinfo => truedocinfo_target => "[@metadata]" #这行非常重要size => 25}
}4.2.2 【中间处理】过滤:调用嵌入服务
filter {http {url => "http://localhost:11434/api/embeddings" # Updated to Ollama's default endpointverb => "POST"body_format => "json"body => { "model" => "all-minilm" # Added model field for Ollama compatibility"prompt" => "%{[content]}" # Changed "text" to "prompt" for Ollama}target_body => "embedding_response"}
}4.2.3【输出】更新Elasticsearch
output {elasticsearch {hosts => ["https://127.0.0.1:9200"] # Updated to https for SSLuser => "elastic"password => "changme"ssl_enabled => truecacert => "E:\logstash-8.15.3-windows-x86_64\logstash-8.15.3\config\http_ca.crt"index => "logs_20250409"document_id => "%{[@metadata][_id]}" # Ensure correct document ID usageaction => "update"doc_as_upsert => true # Ensure documents are created if they don't existretry_on_conflict => 5 # Increase the retry attempts for handling conflicts}
}4.3 Logstash 方案优点
扩展性强——通过管道工作线程轻松扩展。
容错性好——内置重试和故障处理机制。
开发简单——用声明式配置,几乎不用写代码。
高效处理——专为高吞吐量数据流优化。
4.4 Logstash 方案缺点
调试困难——出错时排查问题不灵活。
定制性弱——不支持复杂的自定义逻辑或原生ML模型。
依赖性强 ——跟Elasticsearch耦合紧密,替换成本高。
5、如何选择最适合你的方法?
5.1 选型 Python 的情况
需要复杂的自定义逻辑或集成机器学习模型。希望对每个处理步骤有精细控制。要跟Elasticsearch之外的多个系统对接。
5.2 选型 Logstash的情况
需要高效处理海量日志。希望扩展性强,开发工作量少。想要一个开箱即用的ETL方案,专为 Elasticsearch 优化。
6、总结
如果你的目标是处理大规模、高吞吐量的日志数据,Logstash 通常是更好的选择。但如果你的工作流需要高级定制或机器学习支持,Python 会更合适。
Elasticsearch 8.X “图搜图”实战
基于 Qwen2.5-14B + Elasticsearch RAG 的大数据知识库智能问答系统
Elasticsearch:普通检索和向量检索的异同?
干货 | Elasticsearch 向量搜索的工程化实战

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
相关文章:
Elasticsearch 8.X 如何利用嵌入向量提升搜索能力?
众所周知,Elasticsearch 是一个非常流行的搜索引擎,因为它速度快、扩展性强,尤其擅长全文搜索。 近两年,向量嵌入(Vector Embedding)技术的引入,让 Elasticsearch 在处理高级搜索场景时变得更强…...
MySQL体系架构(一)
1.1.MySQL的分支与变种 MySQL变种有好几个,主要有三个久经考验的主流变种:Percona Server,MariaDB和 Drizzle。它们都有活跃的用户社区和一些商业支持,均由独立的服务供应商支持。同时还有几个优秀的开源关系数据库,值得我们了解一下。 1.1.1.Drizzle Drizzle是真正的M…...

【Docker项目实战】使用Docker部署ToDoList任务管理工具
【Docker项目实战】使用Docker部署ToDoList任务管理工具 一、ToDoList介绍1.1 ToDoList简介1.2 ToDoList主要特点二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载ToDoList镜像…...
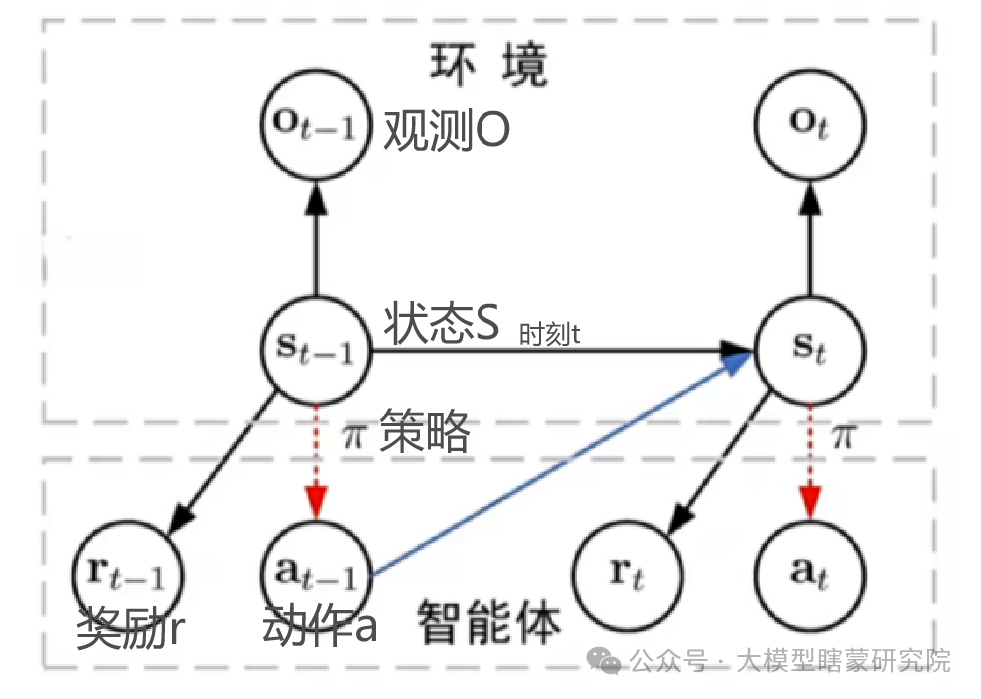
深度强化学习基础 0:通用学习方法
过去自己学习深度强化学习的痛点: 只能看到各种术语、数学公式勉强看懂,没有建立清晰且准确关联 多变量交互关系浮于表面,有时候连环境、代理控制的变量都混淆 模型种类繁多,概念繁杂难整合、对比或复用,无框架分析所…...

Traefik应用:配置容器多个网络时无法访问问题
Traefik应用:配置容器多个网络时无法访问问题 介绍解决方法问题原因: **容器多网络归属导致 Traefik 无法正确发现路由规则**。解决方案方法 1:将应用容器 **仅连接** 到 traefik-public 网络方法 2:显式指定 Traefik 监听的网络 …...
虚幻5的C++调试踩坑
本地调试VS附加调试 踩坑1 预编译版本的UE5没有符号文件,无法调试源码 官方代码调试所需要的符号文件bdp需要下载导入。我安装的5.5.4是预编译版本,并非ue5源码。所以不含bdp文件。需要调试官方代码则需要通过EPIC中下载安装。右键UE版本,打…...

react 中将生成二维码保存到相册
需求:生成二维码,能保存到相册 框架用的 react 所以直接 qrcode.react 插件,然后直接用插件生成二维码,这里一定要写 renderAs{‘svg’} 属性,否则会报错,这里为什么会报错??&#…...

通信协议详解(十):PSI5 —— 汽车安全传感器的“抗干扰狙击手”
一、PSI5是什么? 一句话秒懂 PSI5就像传感器界的“防弹信使”:在汽车安全系统(如气囊)中,用两根线同时完成供电数据传输,即便车祸时线路受损,仍能确保关键信号准确送达! 基础概念…...

C语言【模仿strcpy】
题目 模仿strcpy 思路(注意事项) 注意需要在复制的字符串结尾加\0表示字符串的终止 纯代码 #include<stdio.h>void cpy(const char *a, char *b){int i 0;while (a[i] ! \0){b[i] a[i];i ;}b[i] \0; } int main(){char a[] "HELLO&quo…...
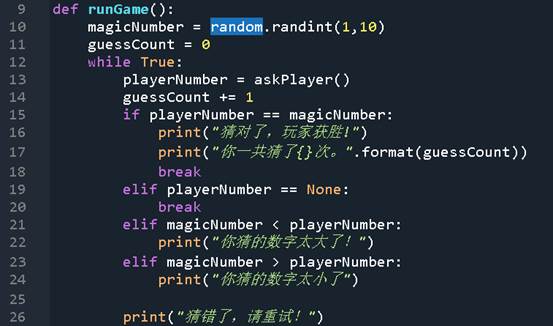
从零开始学Python游戏编程18-函数3
《从零开始学Python游戏编程17-函数2》中,通过代码重构的方式将游戏的主要代码写入到自定义函数runGame()中。对于runGame()中的代码,可以继续对其进行重构,以达到简化代码结构的目的。 1 自定义函数askPlayer() 1.1 函数作用 自定义函数a…...
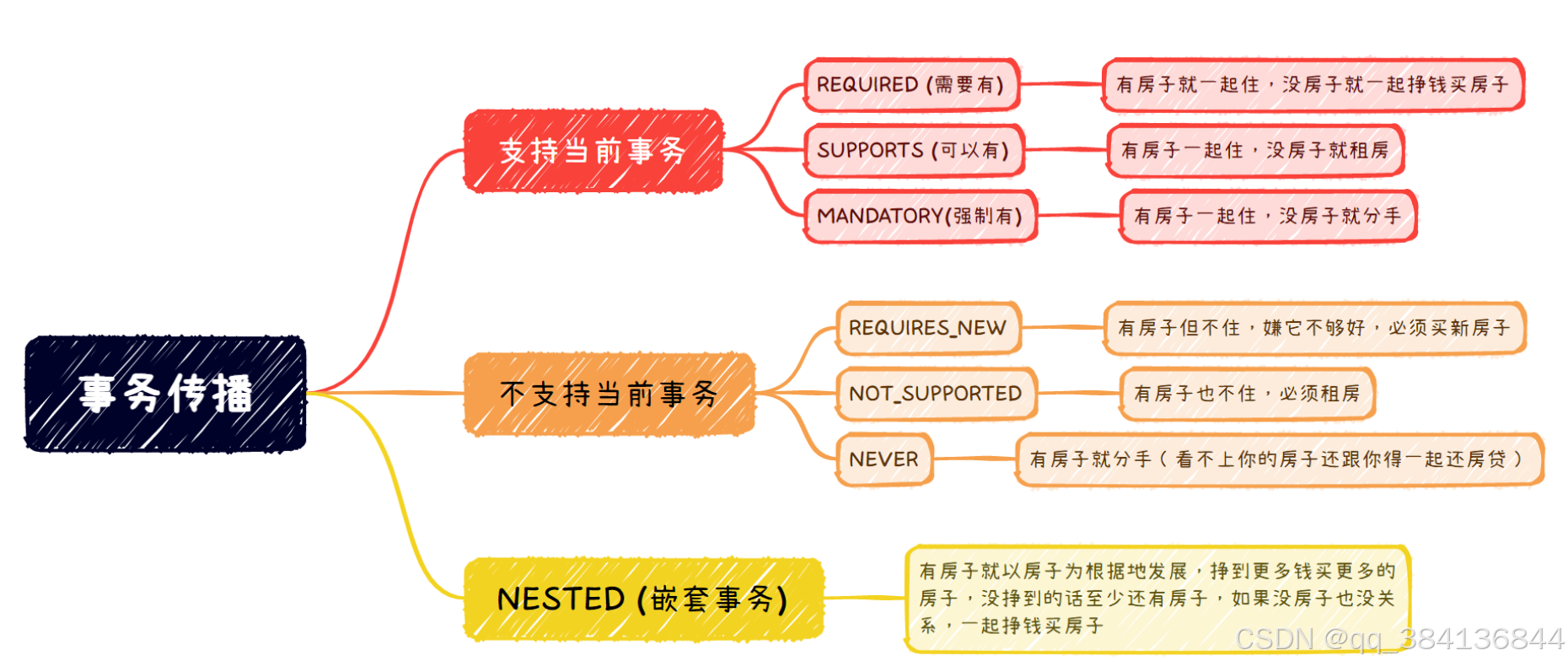
Spring事务传播机制
Spring 事务传播机制定义了在多个事务方法相互调用时,事务如何在这些方法间传播。它决定了一个事务方法调用另一个事务方法时,新的事务是如何开启、是否要加入已有的事务等情况。Spring 提供了 7 种事务传播行为,下面是详细介绍。 解释说明&…...

不同PHP框架之间的兼容性问题及应对策略!
在PHP开发领域,Laravel、Symfony、Yii、ThinkPHP、亿坊PHP等框架因其高效性和便捷性广受开发者青睐。但当项目需要跨框架协作或迁移时,兼容性问题直击要害。本文将从实际案例出发,剖析不同PHP框架间常见的兼容性痛点,并为大家提供…...

Qt 子项目依赖管理:从原理到实践的最佳分析:depends还是 CONFIG += ordered
1. 问题背景 在Qt项目开发中,当一个工程包含多个子项目(如库、插件、测试模块)时,如何正确管理它们的构建顺序和依赖关系? 如: 在开发一个包含核心库(core)、GUI模块(g…...

大数据专业学习路线
大数据专业学习路线 目录 基础知识核心技术进阶技能实战项目职业发展学习资源学习计划常见问题 1. 基础知识 1.1 编程语言 Python:大数据分析的基础语言 基础语法和数据类型函数和模块面向对象编程文件操作和异常处理常用库:NumPy, Pandas, Matplot…...

点云从入门到精通技术详解100篇-基于点云的三维多目标追踪与目标检测
目录 知识储备 基于Python和Open3D库实现的三维点云多目标检测与跟踪 技术要点解析 : 运行环境配置: 扩展改进建议 : 前言 三维多目标追踪技术 点云目标检测算法 2 二维多目标追踪框架及三维点云目标检测 2.1 二维多目标追踪框架 2.1.1 Deep SORT总体架构 2.1…...

dubbo配置中心
配置中心 简介 配置中心(config-center)在dubbo中可承担两类职责: 外部化配置:启动配置的集中式存储。流量治理规则存储。 Dubbo动态配置中心定义了两个不同层次的隔离选项,分别是namespace和group。 namespace&a…...
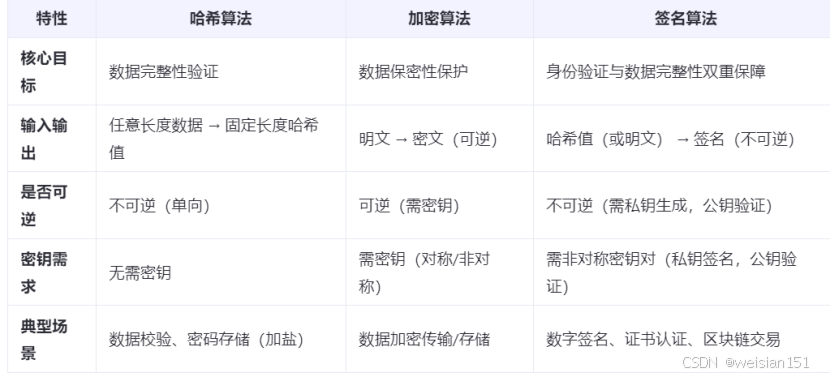
Java常用工具算法-5--哈希算法、加密算法、签名算法关系梳理
1、哈希算法 数学本质:将任意长度输入(明文)映射为固定长度输出(哈希值,也称摘要)。主要特点: 不可逆性:无法通过哈希值反推原始输入。雪崩效应:输入的微小变化导致哈希…...
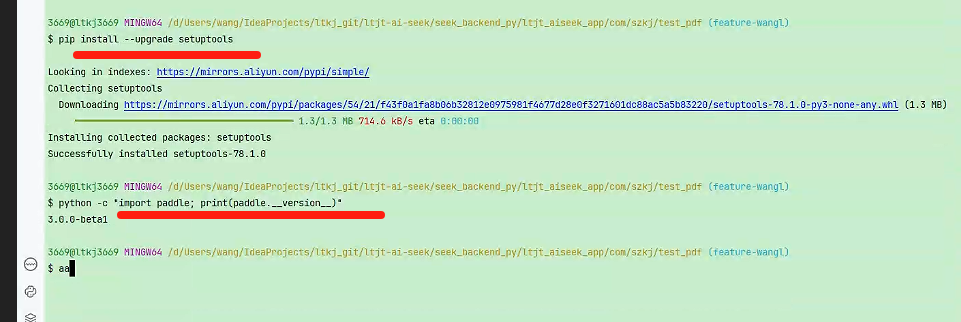
python之安装PaddlePaddle和PaddleX解析pdf表格
目录标题 飞桨PaddlePaddle本地安装教程1-1. 基于 Docker 安装飞桨1-2. 基于 pip 安装飞桨2. 我两个环境 都选择的是pip 安装10. 如果报错10. 离线安装 飞桨PaddlePaddle本地安装教程 源码下载:https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/do…...

【11408学习记录】英语语法核心突破:揭秘表语从句结构与通知写作实战技巧
表语从句与通知写作 英语语法总结——主从复合句表语从句语句结构系动词表语从句的位置 写作通知写作第二段第三段落款 每日一句词汇第一步:找谓语第二步:断句第三步:简化第一句第二句第三句第四句第五句 英语 语法总结——主从复合句 表语…...

React Native 0.79发布 - 更快的工具及更多改进
React Native 0.79版本发布了。 此版本在多个方面进行了性能改进,并修复了一些漏洞。首先,得益于延迟哈希技术,Metro的启动速度变快了,并且对包导出提供了稳定支持。由于JS包压缩方式的改变等原因,Android的启动时间也…...

封装红黑树实现map和set
前言: 之前我们学习了set与map容器的如何使用,红黑树的实现。接下来我们来看看如何通过封装红黑树,实现我们自己的set与map 相关文章:oi!让我来给你唠唠咋实现红黑树☝️-CSDN博客 超详细介绍map&…...

解码AI大脑:Claude的思维显微镜与语言炼金术
(前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站)。 一、多语言思维实验:Claude的“概念空间”如何运转? 跨语言谜题:反义词的…...
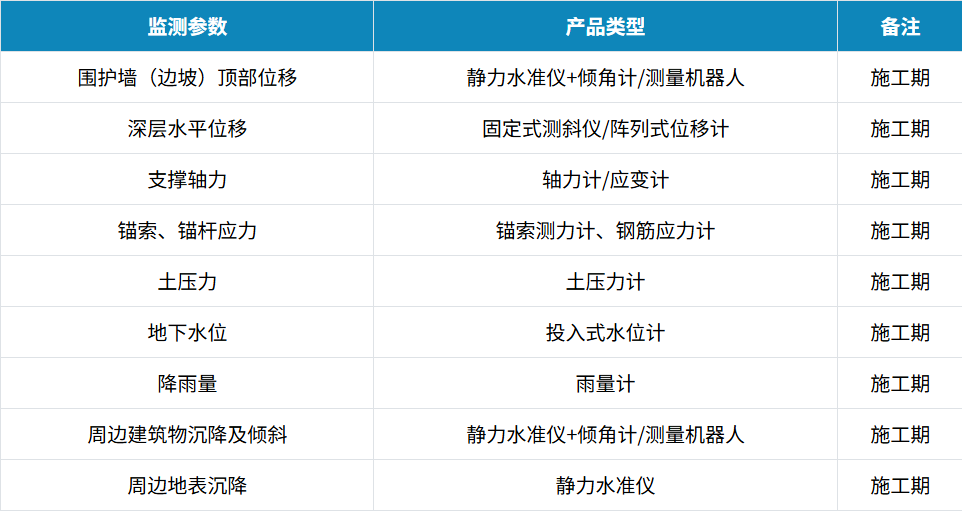
中科岩创基坑自动化监测解决方案
1.行业现状 城市基坑开挖具有施工风险高、施工难度大等特点。由于地下土体性质、荷载条件、施工环境的复杂性,单根据地质勘察资料和室内土工试验参数来确定设计和施工方案,往往含有许多不确定因素,对在施工过程中引发的土体性状、环境、邻近建…...

机器学习01-支持向量机(SVM)(未完)
参考浙大 胡浩基老师 的课以及以下链接: https://blog.csdn.net/m0_74100344/article/details/139560508 https://blog.csdn.net/2301_78630677/article/details/132657023 https://blog.csdn.net/lsb2002/article/details/131338700 一、一些定义 T是倒置&…...

CUDA编译器nvcc
nvcc(NVIDIA CUDA Compiler)是 NVIDIA 提供的 CUDA 编译器,用于编译 .cu 文件(CUDA C/C 代码)。它支持多种参数来控制编译过程,包括 GPU 架构优化、CUDA 库链接、调试选项等。以下是 nvcc 常用参数分类详解…...

Elasticsearch 系列专题 - 第一篇:Elasticsearch 入门
Elasticsearch 是一个功能强大的开源分布式搜索和分析引擎,广泛应用于日志分析、实时搜索、数据可视化等领域。本篇将带你了解 Elasticsearch 的基本概念、安装方法以及简单操作,帮助你快速上手。 1. 什么是 Elasticsearch? 1.1 Elasticsearch 的定义与核心概念 Elasticse…...

leetcode_数组 189. 轮转数组
189. 轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3输出: [5,6,7,1,2,3,4] 示例 2: 输入:nums [-1,-100,3,99], k 2输出:[3,99,-1,-100] 思…...

Python基础全解析:从输入输出到字符编码的深度探索
一、Python程序交互的基石:Print函数详解 1.1 基础输出功能 # 输出数字 print(20.5) # 输出浮点数:20.5 print(0b0010) # 输出二进制数:10# 输出字符串 print(Hello World!) # 经典输出示例# 表达式计算 print(4 4 * (2-1)…...

[ctfshow web入门] web32
前置知识 协议相关博客:https://blog.csdn.net/m0_73353130/article/details/136212770 include:include "filename"这是最常用的方法,除此之外还可以 include url,被包含的文件会被当做代码执行。 data://:…...

指针数组 vs 数组指针
一、指针数组:「数组装指针」—— 每个元素都是指针 🔍 核心定义 语法:类型* 数组名[长度]; ([]优先级高于*,先形成数组,元素是指针)本质:一个 数组,数组的每个元素是 …...