机器学习12-集成学习-案例
参考
【数据挖掘】基于XGBoost的垃圾短信分类与预测
【分类】使用XGBoost算法对信用卡交易进行诈骗预测
银行卡电信诈骗危险预测(LightGBM版本)
【数据挖掘】基于XGBoost的垃圾短信分类与预测
基于XGBoost的垃圾短信分类与预测
我分享了一个项目给你《【数据挖掘】基于XGBoost的垃圾短信分类与预测》,快来看看吧
1. 导入模块
import jieba,wordcloud,re,csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import metrics
import xgboost as xgbimport warnings
warnings.filterwarnings('ignore')
from matplotlib import font_managerfont_path = "ZhuqueFangsong-Regular.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
2. 数据读取及预处理
df = pd.read_csv("/home/mw/input/spammessage3546/垃圾短信分类数据集.csv")
df.head()
输出如下:
df.info()
输出如下:

通过查看数据信息,发现
数据集的Text列存在缺失值,由于该列是记录短信内容,无法进行生成填充,所以在此处进行直接删除处理
数据集各列的类型合理,无需进行类型转换处理
## 删除缺失值
df.dropna(axis=0,inplace=True)## 删除重复值
df.drop_duplicates(inplace=True)##
df = df.reset_index(drop=True)
3. 数据可视化
3.1 观测值数量分布
## 查看观测值的分布情况
k,v = df["Label"].value_counts().index.tolist(), df["Label"].value_counts().values.tolist()k = ["垃圾短信" if x==0 else "正常短信" for x in k]
print("k ",k)
print("v ",v)
输出如下

fig,ax = plt.subplots(1,1,figsize=(9,6),dpi=100)ax.pie(v, labels=k,autopct='%1.1f%%', startangle=90, textprops={'fontsize': 16}, wedgeprops = {'linewidth': 1, "width":.4, 'edgecolor':'#000'},pctdistance = .8)plt.show()
输出如下:
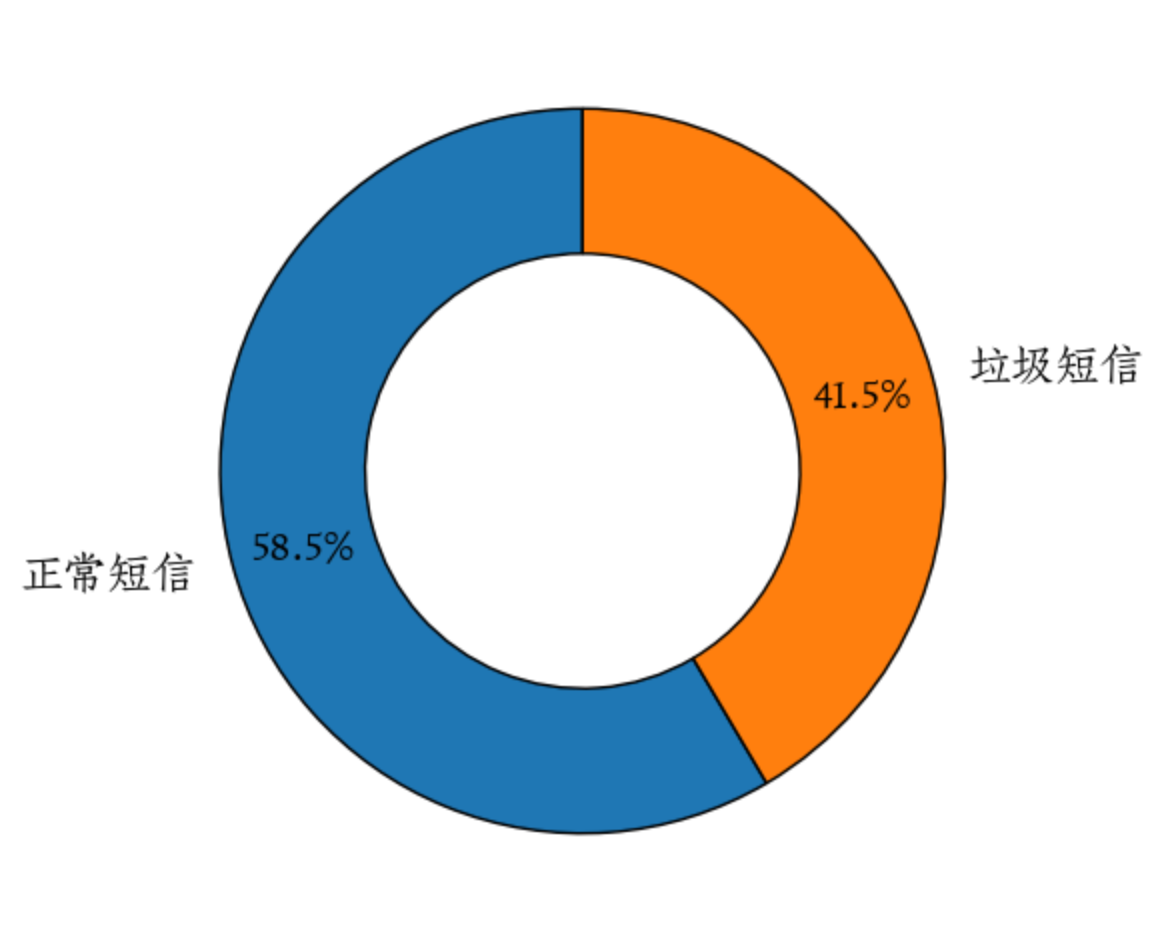
根据上述饼图所展示的内容:
数据集中正常短信的数量占比为58.5%,略高于垃圾短信的数量占比(41.5%)
正常短信与垃圾短信的数量比接近1:1
3.2 垃圾短信的词云图
## 读取停用词表
with open("/home/mw/input/stop6931/中文停用词库.txt","r",encoding="gbk") as f:stopwords = f.read()
## Zero is Spam
def DrawWordcloud(tag):words = []def GetWordCounts(row):row = "".join(re.findall(r'[\u4e00-\u9fff]+', row))for r in jieba.lcut(row):if len(r) > 1:words.append(r.strip())for i in df.query("Label == {}".format(tag))["Text"]:GetWordCounts(i)wc = wordcloud.WordCloud(font_path="ZhuqueFangsong-Regular.ttf",scale=4, background_color='white',stopwords=stopwords)wc.generate('/'.join(words))fig = plt.figure(figsize=(10,8),dpi=120)plt.imshow(wc)plt.axis('off')plt.show()
DrawWordcloud(0)
输出如下:

观察上述垃圾短信的词云图可以发现:
垃圾短信的内容主要集中在数据流量、招商证券等内容上,此外还出现有财富、收盘等字眼
初步概括,垃圾短信的内容主要与营销内容有关,更多的集中在营销推广这个方面
3.3 正常短信的词云图
DrawWordcloud(1)
输出如下:

与垃圾短信的内容相比,正常短信的内容有些许不同:
正常短信更多是由如中国移动、冲浪助手等相关机构发出的
此外还出现了一些关于社会新闻的短信内容
该类短信更具有社会实际意义
4. 分类建模预测
sw_l = stopwords.split("\n")def CutCleanWord(text):_ = "".join(re.findall(r'[\u4e00-\u9fff]+', text))words = [word for word in jieba.cut(str(_).strip()) if word not in sw_l and word != ' ']res = " ".join(words)return res
## 分词
df["CutText"] = df["Text"].map(lambda x:CutCleanWord(x))
df["CutText"]
输出如下:

## 向量化
x_train,x_test,y_train,y_test = train_test_split(df["CutText"],df["Label"],test_size=.2,random_state=42)vec = TfidfVectorizer(max_features=80000, ngram_range=(1, 2),min_df=2,max_df=0.96,strip_accents='unicode',norm='l2',token_pattern=r"(?u)\b\w+\b")vec.fit(df["CutText"])
x_train_ = vec.transform(x_train).toarray()
x_test_ = vec.transform(x_test).toarray()
# 原始数据
print("x_train[0:2] \n",x_train[0:2])
print("x_test[0:2] \n",x_test[0:2])
print("y_train[0:2] \n",y_train[0:2])
print("y_test[0:2] \n",y_test[0:2])
输出如下:

# 向量后的数据
print("x_train_[0:2] shape \n",x_train_.shape," \n x_train_[0:2] \n",x_train_[0:2])
print("x_test_[0:2] shape \n",x_test_[0:2].shape," \n x_test_[0:2] \n",x_test_[0:2])
for i in x_train_[0]:print(i,end=' ')
输出如下:


## 构建xgboost分类模型
model = xgb.XGBClassifier(objective = 'binary:logistic',max_depth = 2, learning_rate = 0.05, n_estimators = 100,silent = False,random_state=42)model.fit(x_train_, y_train)
输出如下:
XGBClassifier
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=2, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=100, n_jobs=None,
num_parallel_tree=None, random_state=42, …)
acc1 = metrics.accuracy_score(y_train, model.predict(x_train_))print("模型在训练集上的预测准确率:{}%".format(round(acc1,4)*100))
输出如下:
模型在训练集上的预测准确率:81.36%
## 模型在测试集上的预测准确率
y_pred = model.predict(x_test_)
acc2 = metrics.accuracy_score(y_test, y_pred)print("模型在测试集上的预测准确率:{}%".format(round(acc2,4)*100))print("\n\n模型在训练集到测试集上的预测准确率变化了:{}%".format(round((acc2-acc1)*100,2)))
模型在测试集上的预测准确率:78.12%
模型在训练集到测试集上的预测准确率变化了:-3.24%
## 模型在测试集上的预测结果的分类
print(metrics.classification_report(y_test, y_pred))
输出如下:
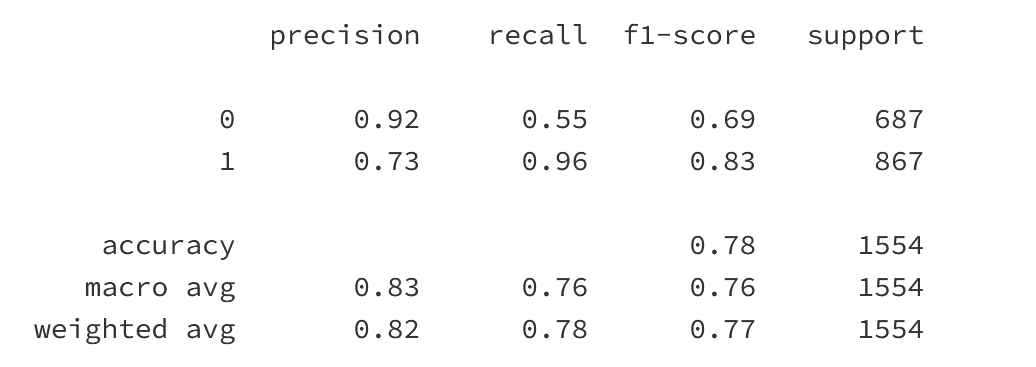
根据上述建模预测过程:
- 模型在训练集上的预测准确率为
81.36%,在测试集上的预测准确率为78.12% - 模型在训练集到测试集的预测准确率变化中呈下降结果,预测准确率降低了
3.24% - 在分类报告中,模型针对类别为
1即正常短信的预测F1得分为0.83,但在针对类别为0即垃圾短信的预测F1得分为0.69,这说明模型对类别为1的短信分类识别能力好于识别类别为0的能力
5. 拓展
针对上述模型预测出现的不足之处,可以有以下的优化:
- 使用更为高级的分类模型
- 对XGBoost分类模型进行超参数优化
- 使用交叉验证提高模型的泛化能力
项目使用数据集 👉👉 垃圾短信分类数据集
银行卡电信诈骗危险预测(LightGBM版本)
参考
我分享了一个项目给你《【竞赛学习】LightGBM+贝叶斯优化预测银行卡电信诈骗》,快来看看吧
相关文章:
机器学习12-集成学习-案例
参考 【数据挖掘】基于XGBoost的垃圾短信分类与预测 【分类】使用XGBoost算法对信用卡交易进行诈骗预测 银行卡电信诈骗危险预测(LightGBM版本) 【数据挖掘】基于XGBoost的垃圾短信分类与预测 基于XGBoost的垃圾短信分类与预测 我分享了一个项目给你《【数据挖掘】基于XG…...

使用Ubuntu18恢复群晖nas硬盘数据外接usb
使用Ubuntu18恢复群晖nas硬盘数据外接usb 1. 接入硬盘2.使用Ubuntu183.查看nas硬盘信息3. 挂载nas3.1 挂载损坏nas硬盘(USB)3.2 挂载当前运行的nas 4. 拷贝数据分批传输 5. 新旧数据对比 Synology NAS 出现故障,DS DiskStation损坏,则可以使用计算机和 U…...

微服务系统记录
记录下曾经工作涉及到微服务的相关知识。 1. 架构设计与服务划分 关键内容 领域驱动设计(DDD): 利用领域模型和限界上下文(Bounded Context)拆分业务,明确服务边界。通过事件风暴(Event Storm…...
【数据库原理及安全实验】实验二 数据库的语句操作
目录 指导书原文 实操备注 指导书原文 【实验目的】 1) 掌握使用SQL语言进行数据操纵的方法。 【实验原理】 1) 面对三个关系表student,course,sc。利用SQL语句向表中插入数据(insert),然后对数据进行delete&…...

python 微信小程序支付、查询、退款使用wechatpy库
首先使用 wechatpy 库,执行以下命令进行安装 pip install wechatpy 1、 直连商户支付 import logging from django.http import JsonResponse from django.views.decorators.http import require_http_methods from wechatpy.pay import WeChatPay from wechatpy.…...
)
蓝桥杯备赛学习笔记:高频考点与真题预测(C++/Java/python版)
2025蓝桥杯备赛学习笔记 ——高频考点与真题预测 一、考察趋势分析 通过对第13-15届蓝桥杯真题的分析,可以发现题目主要围绕基础算法、数据结构、数学问题、字符串处理、编程语言基础展开,且近年逐渐增加动态规划、图论、贪心算法等较难题目。 1. 基…...
【BFT帝国】20250409更新PBFT总结
2411 2411 2411 Zhang G R, Pan F, Mao Y H, et al. Reaching Consensus in the Byzantine Empire: A Comprehensive Review of BFT Consensus Algorithms[J]. ACM COMPUTING SURVEYS, 2024,56(5).出版时间: MAY 2024 索引时间(可被引用): 240412 被引:…...
Linux-CentOS-7—— 配置静态IP地址
文章目录 CentOS-7——配置静态IP地址VMware workstation的三种网络模式配置静态IP地址1. 编辑虚拟网络2. 确定网络接口名称3. 切换到网卡所在的目录4. 编辑网卡配置文件5. 查看网卡文件信息6. 重启网络服务7. 测试能否通网8. 远程虚拟主机(可选) 其他补…...

Jupyter Lab 无法启动 Kernel 问题排查与解决总结
📄 Jupyter Lab 无法启动 Kernel 问题排查与解决总结 一、问题概述 🚨 现象描述: 用户通过浏览器访问远程服务器的 Jupyter Lab 页面(http://xx.xx.xx.xx:8891/lab)后,.ipynb 文件可以打开,但无…...

算法训练之位运算
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

linux入门三:Linux 编辑器
一、轻量级编辑器:快速上手的首选 1.1 Leafpad:极简主义的轻量之选 核心特点 轻量快速:体积小、启动快,资源占用极低,适合低配设备或快速编辑简单文件。 无复杂功能:仅支持基础文本编辑,界面…...
C++设计模式+异常处理
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory> #include <stdexcept> // 包含异常类using namespace std;// 该作业要求各位写一…...

HttpServletRequest是什么
HttpServletRequest 是 Java Servlet API 中的一个接口,表示 HTTP 请求对象。它封装了客户端(如浏览器)发送到服务器的请求信息,并提供了访问这些信息的方法。 1. 基本概念 作用: HttpServletRequest 提供了一种机制&…...
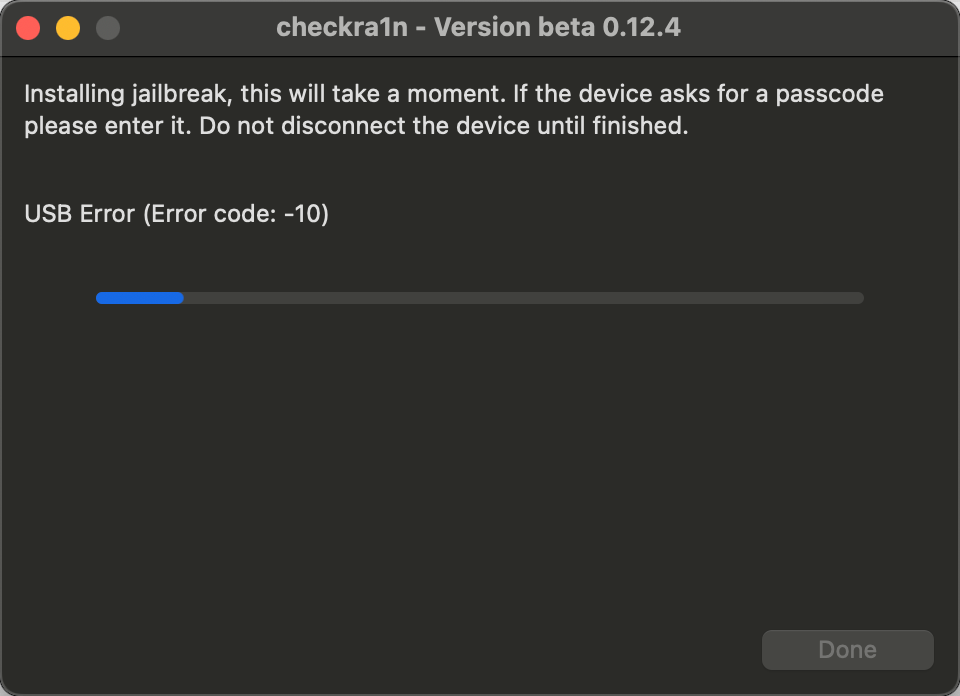
checkra1n越狱出现的USB error -10问题解决
使用checkra1n进行越狱是出现: 解决办法(使用命令行进行越狱): 1. cd /Applications/checkra1n.app/Contents/MacOS 2. ./checkra1n -cv 3. 先进入恢复模式 a .可使用爱思助手 b. 或者长按home,出现关机的滑条,同时按住home和电源键&#…...

golang-defer延迟机制
defer延迟机制 defer是什么 defer是go中一种延迟调用机制。 执行时机 defer后面的函数只有在当前函数执行完毕后才能执行。 执行顺序 将延迟的语句按defer的逆序进行执行,也就是说先被defer的语句最后被执行,最后被defer的语句,最先被执…...

【小沐学Web3D】three.js 加载三维模型(Angular)
文章目录 1、简介1.1 three.js1.2 angular.js 2、three.js Angular.js结语 1、简介 1.1 three.js Three.js 是一款 webGL(3D绘图标准)引擎,可以运行于所有支持 webGL 的浏览器。Three.js 封装了 webGL 底层的 API ,为我们提供了…...

一种替代DOORS在WORD中进行需求管理的方法 (二)
一、前景 参考: 一种替代DOORS在WORD中进行需求管理的方法(基于WORD插件的应用)_doors aspice-CSDN博客 二、界面和资源 WORD2013/WORD2016 插件 【已使用该工具通过第三方功能安全产品认证】: 1、 核心功能 1、需求编号和跟…...

一个基于ragflow的工业文档智能解析和问答系统
工业复杂文档解析系统 一个基于ragflow的工业文档智能解析和问答系统,支持多种文档格式的解析、知识库管理和智能问答功能。 系统功能 1. 文档管理 支持多种格式文档上传(PDF、Word、Excel、PPT、图片等)文档自动解析和分块处理实时处理进度显示文档解析结果预览批量文档…...

23种设计模式-行为型模式-访问者
文章目录 简介场景解决完整代码核心实现 总结 简介 访问者是一种行为设计模式,它能把算法跟他所作用的对象隔离开来。 场景 假如你的团队开发了一款能够使用图像里地理信息的应用程序。图像中的每个节点既能代表复杂实体(例如一座城市)&am…...

WebView2最低支持.NET frame4.5,win7系统
WebView2最低支持.NET frame什么版本 WebView2 对 .NET Framework 的最低版本要求 基础支持范围 WebView2 官方支持的 .NET Framework 最低版本为 4.5,同时兼容 .NET Core 3.0 及以上版本18。对于 WPF、WinForms 等桌面应用开发,需确…...

WHAT - React 组件的 props.children 属性
目录 一、什么是 children二、基本用法三、类型定义(TypeScript)四、一些高级用法1. 条件渲染 children2. 多个 children 插槽(命名插槽) 五、children 的优势总结 在 React 中,children 是一个非常重要且特殊的 内置属…...
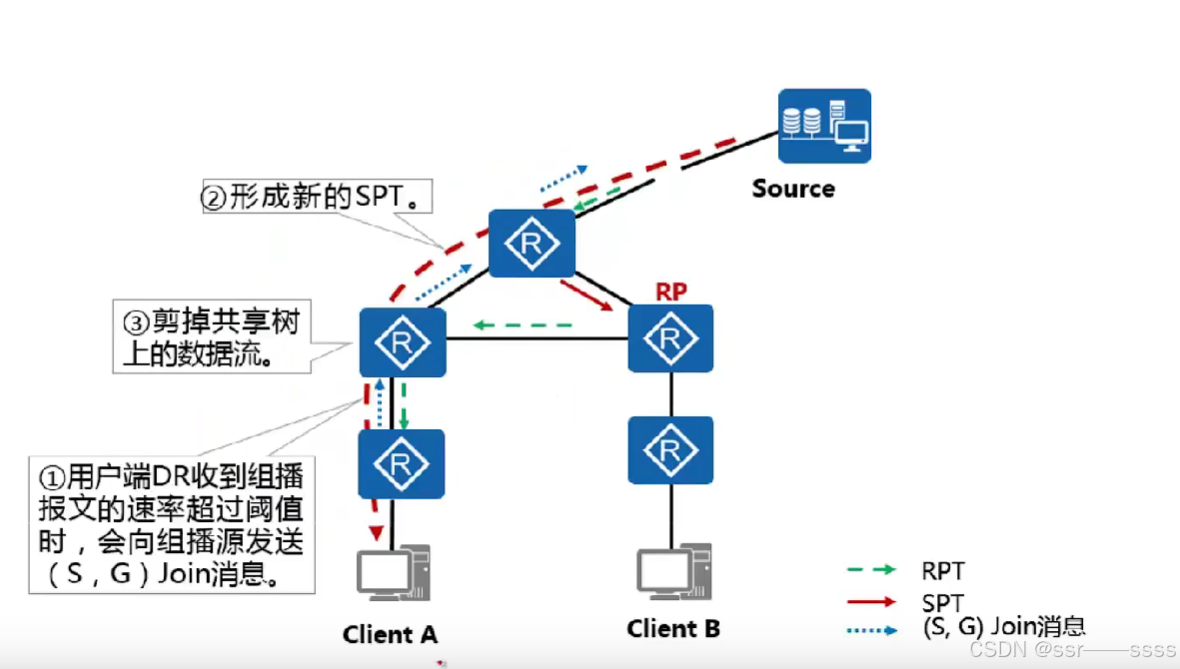
组播网络构建:IGMP、PIM 原理及应用实践
IP组播基础 组播基本架构 组播IP地址 一个组播IP地址并不是表示具体的某台主机,而是一组主机的集合,主机声明加入某组播组即标识自己需要接收目的地址为该组播地址的数据IP组播常见模型分为ASM模型和SSM模型ASM:成员接收任意源组播数据&…...
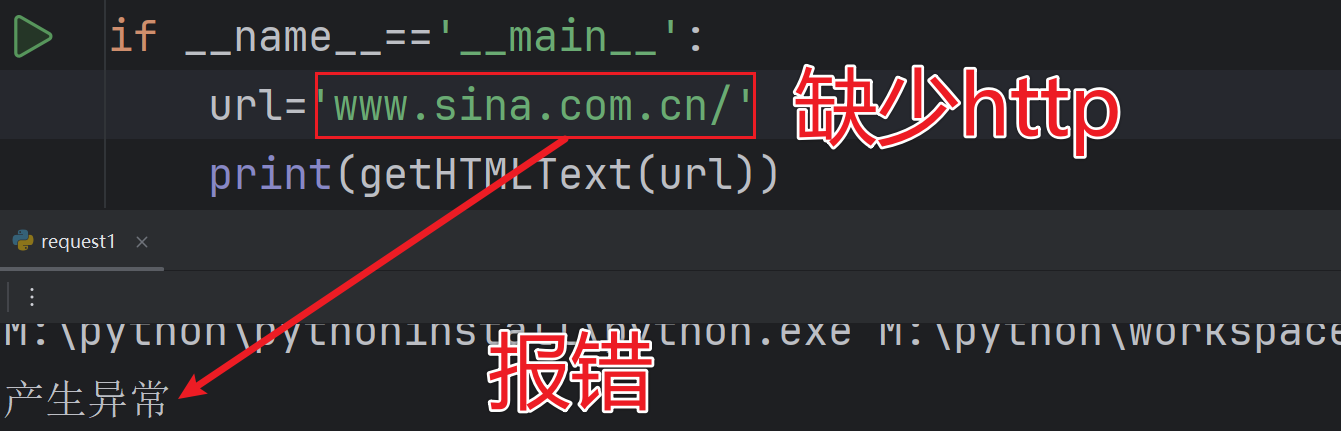
建筑兔零基础自学记录69|爬虫Requests-2
Requests库初步尝试 #导入requests库 import requests #requests.get读取百度网页 rrequests.get(http://www.baidu.com) #输出读取网页状态 print(r.status_code) #输出网页源代码 print(r.text) HTTP 状态码是三位数字,用于表示 HTTP 请求的结果。常见的状态码有…...

NVIDIA PhysX 和 Flow 现已完全开源
NVIDIA PhysX SDK 在 3-Clause BSD 许可下开源已有六年半了,但其中并非所有内容都是开源的。直到最近,随着 GPU 模拟内核源代码在 GitHub 上的发布,这种情况才有所改变。以下是 NVIDIA 分享的消息,以及 Flow SDK 着色器实现的发布…...

QML面试笔记--UI设计篇01常用控件分类
1. QML常用控件深度解析:从入门到实战2. 控件分类全景图3. 核心控件详解 3.1. 布局控件(构建界面骨架) 3.1.1. ▶ ColumnLayout 3.2. 交互控件 3.2.1. ▶ 智能搜索框(组合控件) 3.3. 数据可视化控件 3.3.1. ▶ 动态仪表…...
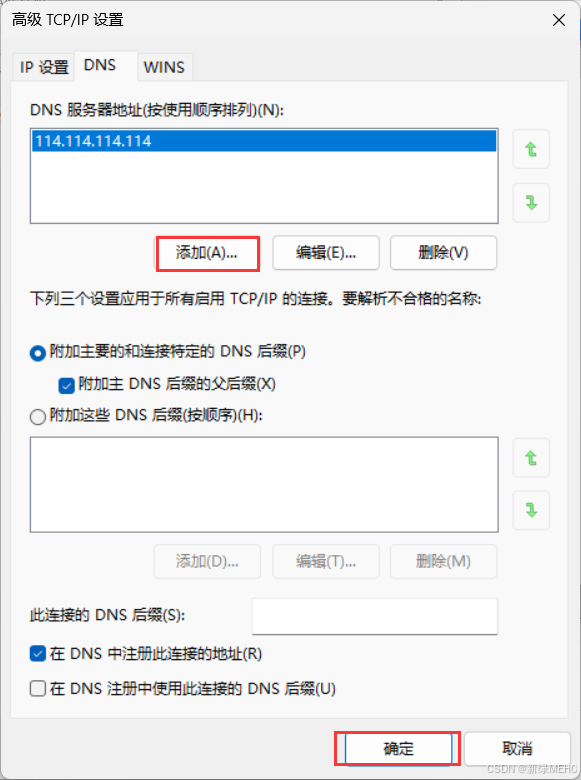
电脑DNS出错无法打开网页
目录 解决步骤 打开“控制面板”--》“查看网络状态和任务” 打开“更改适配器设置” 对WLAN右键,打开属性 打开“使用下面的DNS服务器地址”--》高级 添加“114.114.114.114”,点击确定 今天晚上突然网页打不开了,一开始我以为是网络的…...
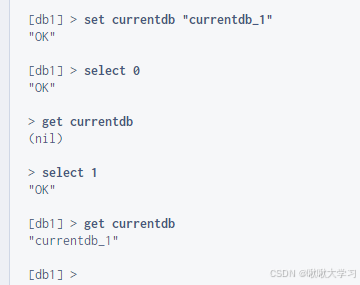
[Redis]redis-windows下载安装与使用
本篇记录windows redis下载安装与使用。 下载 官网下载方式(没windows版) https://redis.io/downloads/#stack 可以选择下载社区版Redis CE与增强版Redis Stack。 两者都不支持直接运行在windows上,需要Docker环境。 You can install Redis CE locally on your …...

Python-Django+vue宠物服务管理系统功能说明
❥(^_-) 上千个精美定制模板,各类成品Java、Python、PHP、Android毕设项目,欢迎咨询。 ❥(^_-) 程序开发、技术解答、代码讲解、文档,💖文末获取源码+数据库+文档💖 💖软件下载 | 实战案例 💖文章底部二维码,可以联系获取软件下载链接,及项目演示视频。 本项目…...

极氪汽车云原生架构落地实践
云原生架构落地实践的背景 随着极氪数字业务的飞速发展,背后的 IT 技术也在不断更新迭代。极氪极为重视客户对服务的体验,并将系统稳定性、业务功能的迭代效率、问题的快速定位和解决视为构建核心竞争力的基石。 为快速响应用户的需求,例如…...

2025年AI开发学习路线
目录 一、基础阶段(2-3个月) 1. 数学与编程基础 2. 机器学习入门 二、核心技能(3-4个月) 1. 深度学习与框架 2. 大模型开发(重点) 三、进阶方向(3-6个月) 1. 多模态与智能体…...