spark数据清洗案例:流量统计
一、项目背景
在互联网时代,流量数据是反映用户行为和业务状况的重要指标。通过对流量数据进行准确统计和分析,企业可以了解用户的访问习惯、业务的热门程度等,从而为决策提供有力支持。然而,原始的流量数据往往存在格式不规范、缺失值、异常值等问题,这就需要进行数据清洗工作。本文将介绍如何使用Spark进行流量统计项目中的数据清洗工作。
二、数据来源与数据样例
流量数据通常来源于服务器的日志文件,这些日志记录了用户的每一次访问请求,包括访问时间、用户IP、请求的页面、产生的流量大小等信息。 ### 数据样例 假设我们拿到的原始流量数据格式如下
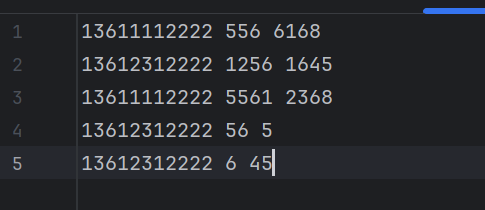
但实际数据中可能存在格式错误,比如时间格式不对,或者流量值为负数等异常情况。
三、项目完成思路
(一)数据读取
使用Spark的 `SparkSession` 来读取数据。
(二)数据清洗
1. **字段拆分** 原始数据是一行文本,需要将其拆分成对应的字段。可以使用 `split()` 函数来实现。这里将每一行数据按逗号拆分成不同字段,并为每个字段取别名,同时将流量大小字段转换为数值类型。
2. **处理缺失值** 检查数据中是否存在缺失值,并根据情况进行处理。可以使用 `drop()` 方法删除包含缺失值的行,或者使用 `fill()` 方法进行填充。
3. **处理异常值** 对于流量统计,比如流量大小不能为负数,可以过滤掉异常数据。同时,对于时间格式错误等情况,也可以通过正则表达式等方式进行校验和处理。
(三)流量统计
经过清洗后的数据,就可以进行流量统计相关操作了。
(四)结果输出
将统计结果输出到文件或者展示在控制台。如果要输出到文件
四、代码
设置依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>Flow</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><!-- 添加hadoop-client 3.1.0的依赖 --><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.0</version></dependency></dependencies></project>FlowBean
package com.example.flow;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;// hadoop序列化
// 三个属性:手机号,上行流量,下行流量
public class FlowBean implements Writable {private String phone;private Long upFlow;private Long downFlow;public FlowBean(String phone, Long upFlow, Long downFlow) {this.phone = phone;this.upFlow = upFlow;this.downFlow = downFlow;}// 定义get/set方法public String getPhone() {return phone;}public void setPhone(String phone) {this.phone = phone;}public Long getUpFlow() {return upFlow;}public void setUpFlow(Long upFlow) {this.upFlow = upFlow;}public Long getDownFlow() {return downFlow;}public void setDownFlow(Long downFlow) {this.downFlow = downFlow;}// 定义无参构造public FlowBean() {}// 定义一个获取总流量的方法public Long getTotalFlow() {return upFlow + downFlow;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(phone);dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);}@Overridepublic void readFields(DataInput dataInput) throws IOException {phone = dataInput.readUTF();upFlow = dataInput.readLong();downFlow = dataInput.readLong();}
}FlowMapper
package com.example.flow;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// 1.继承Mapper
// 2.重写map函数
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1.获取一行数据,使用空格拆分// 手机号就是第一个元素// 上行留了就是第二个元素// 下行留了就是第三个元素String[] split = value.toString().split(" ");System.out.printf("%s\t%s\t%s\n", split[0], split[1], split[2]);String phone = split[0];Long upFlow = Long.parseLong(split[1]);Long downFlow = Long.parseLong(split[2]);// 2.封装对象FlowBean flowBean = new FlowBean(phone, upFlow, downFlow);// 3.写入 手机号为key,值就是这个对象context.write(new Text(phone), flowBean);}
}FlowReducer
package com.example.flow;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// 1.继承Reducer
// 2.重写reduce方法
public class FlowReducer extends Reducer<Text, FlowBean, Text, Text> {@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//1. 遍历集合,取出每一个元素,计算上行流量和下行流量的汇总long upFlowSum = 0L;long downFlowSum = 0L;for (FlowBean flowBean : values) {upFlowSum += flowBean.getUpFlow();downFlowSum += flowBean.getDownFlow();}// 2. 计算总的汇总long sumFlow = upFlowSum + downFlowSum;String flowDesc = String.format("总的上行流量是:%d,总下行流量是:%d,总流量是:%d", upFlowSum, downFlowSum, sumFlow);context.write(key, new Text(flowDesc));}
}FlowDriver
package com.example.flow;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;// 提交job的类,一共做七件事
public class FlowDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 1. 获取配置,得到job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2. 设置jar包路径job.setJarByClass(FlowDriver.class);//3.关联Mapper和Reducer的输出类型job.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);// 4. 设置Mapper和Reducer的输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);// 5. 设置reducer输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 6. 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path("data"));FileOutputFormat.setOutputPath(job, new Path("output"));// 7.提交job,根据返回值设置程序退出codeboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
五、总结
通过使用Spark进行数据清洗和流量统计,我们能够从原始的、杂乱的流量数据中提取出有价值的信息。在实际项目中,数据清洗的规则和方法可能会因数据的具体情况而有所不同,需要根据实际场景灵活调整。同时,Spark强大的分布式计算能力使得处理大规模流量数据变得高效可行,为后续的数据分析和挖掘工作奠定了良好的基础。希望本文能对大家在Spark数据清洗和流量统计项目上有所帮助。 以上博客内容供你参考,你可以根据实际项目细节和需求对代码示例、描述等进行进一步调整和完善。
相关文章:
spark数据清洗案例:流量统计
一、项目背景 在互联网时代,流量数据是反映用户行为和业务状况的重要指标。通过对流量数据进行准确统计和分析,企业可以了解用户的访问习惯、业务的热门程度等,从而为决策提供有力支持。然而,原始的流量数据往往存在格式不规范、…...

git commit时自动生成Change-ID
创建全局钩子目录: 创建一个全局的Git hooks目录: mkdir -p ~/.githooks 下载并设置commit-msg钩子脚本: 下载Gerrit的commit-msg钩子脚本,并放置在全局钩子目录中(如下载不了,可从本页面附件中下载,“…...
list的使用以及模拟实现
本章目标 1.list的使用 2.list的模拟实现 1.list的使用 在stl中list是一个链表,并且是一个双向带头循环链表,这种结构的链表是最优结构. 因为它的实现上也是一块线性空间,它的使用上是与string和vector类似的.但相对的因为底层物理结构上它并不像vector是线性连续的,它并没有…...

分布式防护节点秒级切换:实战配置与自动化运维
摘要:针对DDoS攻击导致节点瘫痪的问题,本文基于群联AI云防护的智能调度系统,详解如何实现节点健康检查、秒级切换与自动化容灾,并提供Ansible部署脚本。 一、分布式节点的核心价值 资源分散:攻击者难以同时击溃所有节…...

【今日三题】小乐乐改数字 (模拟) / 十字爆破 (预处理+模拟) / 比那名居的桃子 (滑窗 / 前缀和)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 小乐乐改数字 (模拟)十字爆破 (预处理模拟)比那名居的桃子 (滑窗 / 前缀和) 小乐乐改数字 (模拟) 小乐乐改数字…...
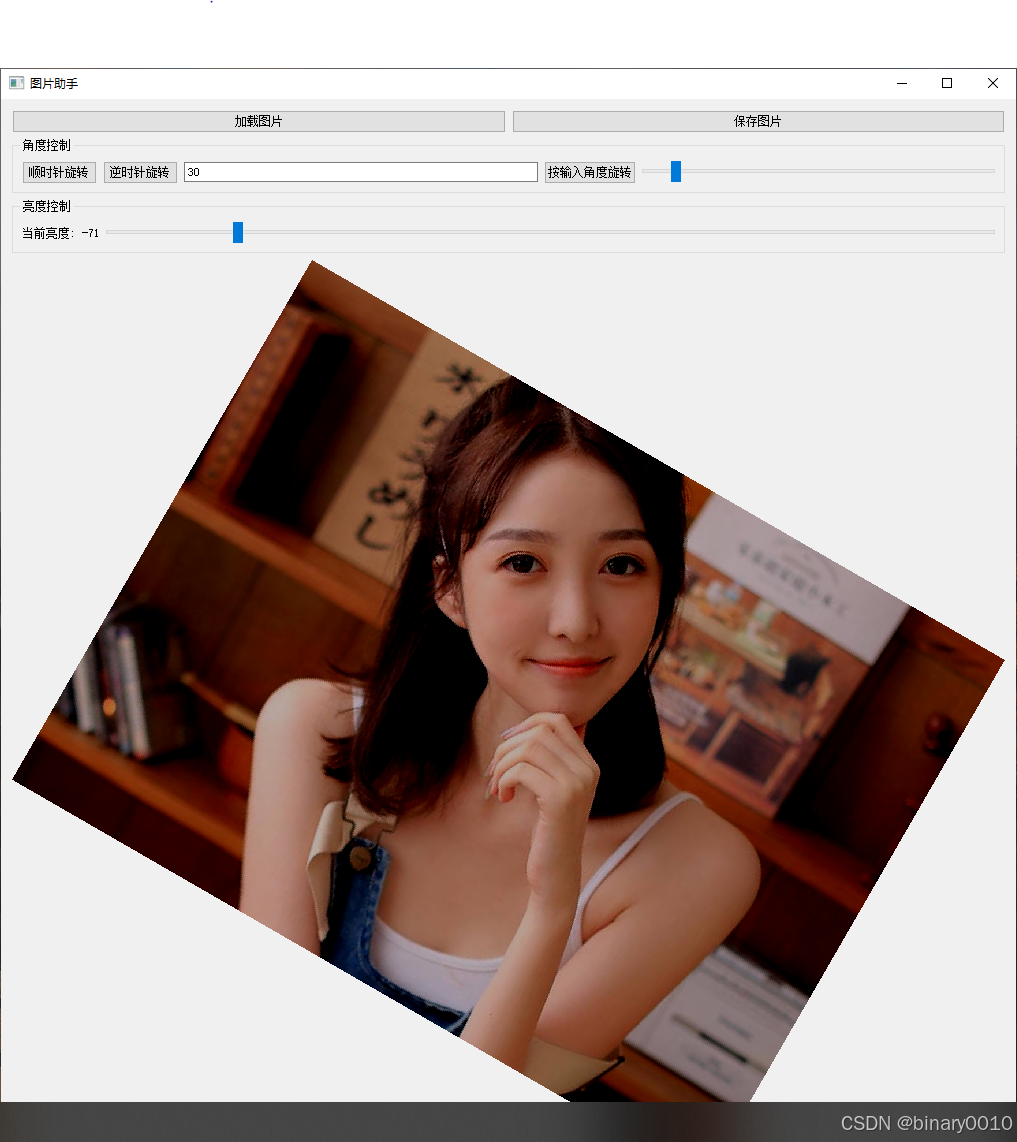
基于 Qt 的图片处理工具开发(一):拖拽加载与基础图像处理功能实现
一、引言 在桌面应用开发中,图片处理工具的核心挑战在于用户交互的流畅性和异常处理的健壮性。本文以 Qt为框架,深度解析如何实现一个支持拖拽加载、亮度调节、角度旋转的图片处理工具。通过严谨的文件格式校验、分层的架构设计和用户友好的交互逻辑&am…...

CentOS 7 yum 无法安装软件的解决方法
一、解决方法 1、备份原有的 CentOS 7 默认 YUM 源配置文件 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup2、从阿里云镜像源下载 CentOS 7 的 YUM 源配置文件,并覆盖原有的配置文件 wget -O /etc/yum.repos.d/CentOS-Base.re…...

3DGS之光栅化
光栅化(Rasterization)是计算机图形学中将连续的几何图形(如三角形、直线等)转换为离散像素的过程,最终在屏幕上形成图像。 一、光栅化的核心比喻 像画家在画布上作画 假设你是一个画家,要把一个3D立方体画…...
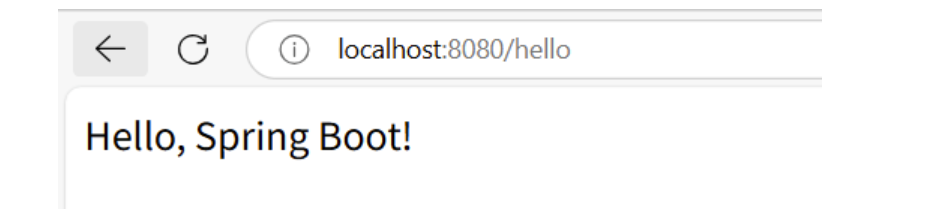
44、Spring Boot 详细讲义(一)
Spring Boot 详细讲义 目录 Spring Boot 简介Spring Boot 快速入门Spring Boot 核心功能Spring Boot 技术栈与集成Spring Boot 高级主题Spring Boot 项目实战Spring Boot 最佳实践总结 一、Spring Boot 简介 1. Spring Boot 概念和核心特点 1.1、什么是 Spring Boot&#…...
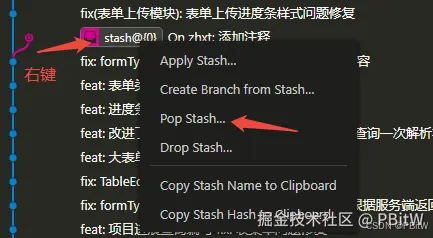
虽然理解git命令,但是我选择vscode插件!
文章目录 2025/3/11 补充一个项目一个窗口基本操作注意 tag合并冲突已有远程,新加远程仓库切换分支stash 只要了解 git 的小伙伴,应该都很熟悉这些指令: git init – 初始化git仓库git add – 把文件添加到仓库git commit – 把文件提交到仓库…...

【Pandas】pandas DataFrame head
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行 pandas.DataFrame.head pandas.DataFrame.head 是一个方法,用于返回 DataFrame 的前几行。这个方法非常有用,特别是在需要快速查看 DataFrame 的前…...
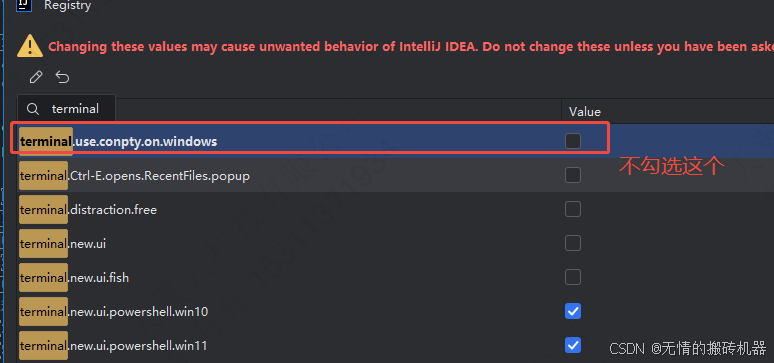
idea 打不开terminal
IDEA更新到2024.3后Terminal终端打不开的问题_idea terminal打不开-CSDN博客...

【JVM】JVM调优实战
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...
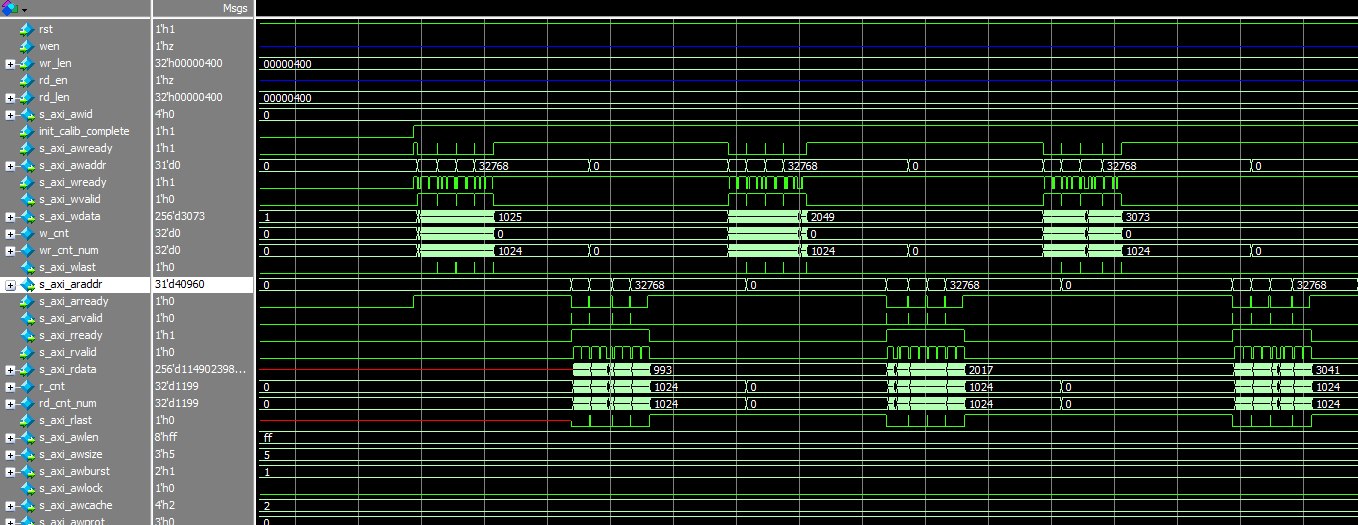
FPGA_DDR(二)
在下板的时候遇到问题 1:在写一包数据后再读,再写再读 这时候读无法读出 查看时axi_arready没有拉高 原因 : 由于读地址后没有拉高rready,导致数据没有读出卡死现象。 解决结果...

Genspark vs manus
1. 产品定位与核心技术 Genspark Super Agent 定位:由前百度高管景鲲创立的MainFunc公司推出,主打“快速、准确、可控”的通用AI Agent,强调从思考到执行的全闭环能力,聚焦复杂任务自动化(如旅行规划、电话预订)。 核心技术: 混合代理架构(MoA):集成8个不同规模的LL…...
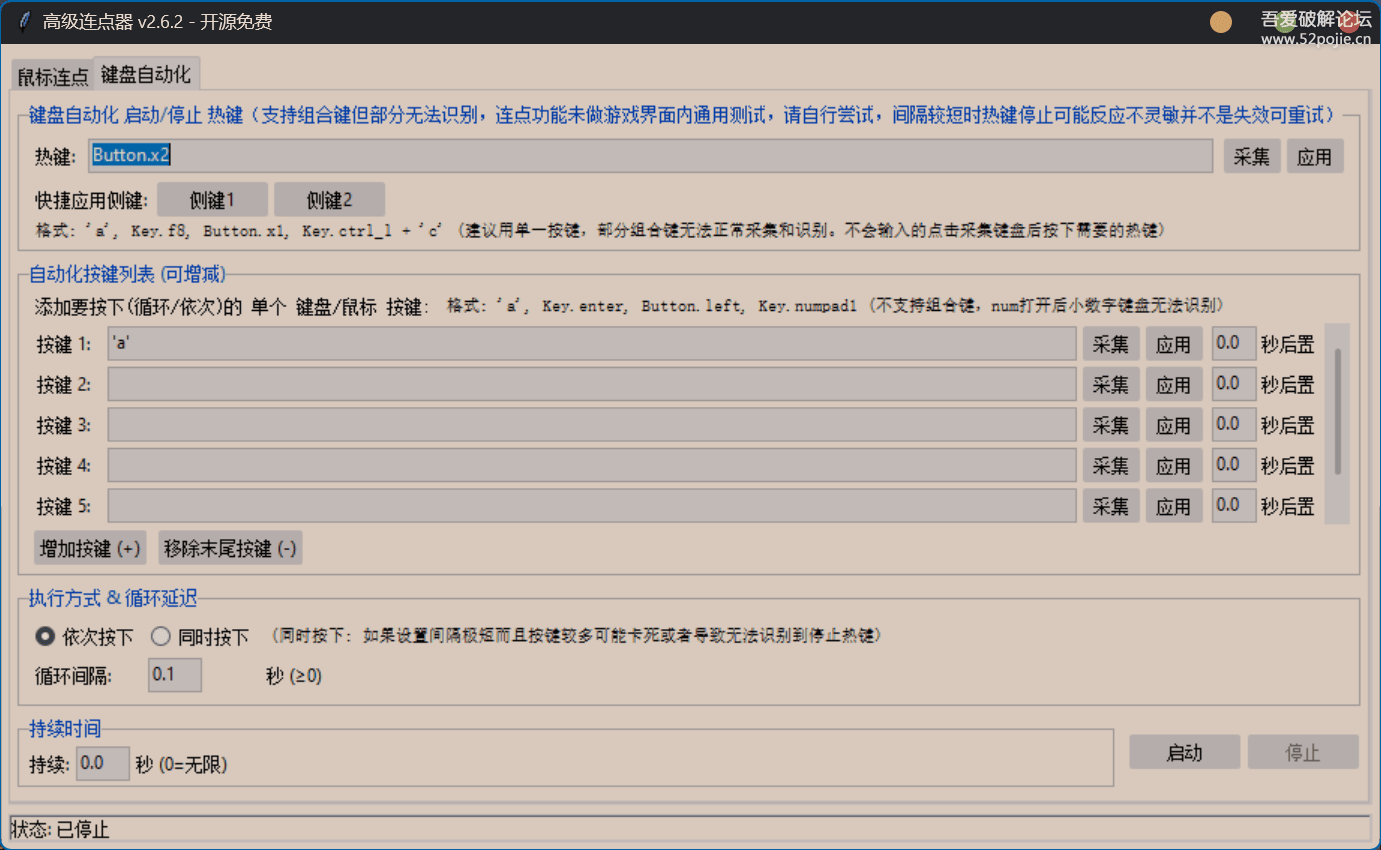
【吾爱出品】[Windows] 鼠标或键盘可自定义可同时多按键连点工具
[Windows] 鼠标或键盘连点工具 链接:https://pan.xunlei.com/s/VONSFKLNpyVDeYEmOCBY3WZJA1?pwduik5# [Windows] 鼠标或键盘可自定义可同时多按键连点工具 就是个连点工具,功能如图所示,本人系统win11其他系统未做测试,自己玩…...
vue3实战一、管理系统之实战立项
目录 管理系统之实战立项对应相关文章链接入口:实战效果登录页:动态菜单:动态按钮权限白天黑夜模式:全屏退出全屏退出登录:菜单收缩: 管理系统之实战立项 vue3实战一、管理系统之实战立项:这个项…...

【MySQL 删除数据详解】
文章目录 一、前言二、MySQL 中的三种删除方式1. DELETE 语句✅ 基本语法:🔥 示例:删除指定行:删除所有数据:删除多行: 2. TRUNCATE 语句✅ 基本语法:🔥 示例: 3. DROP 语…...
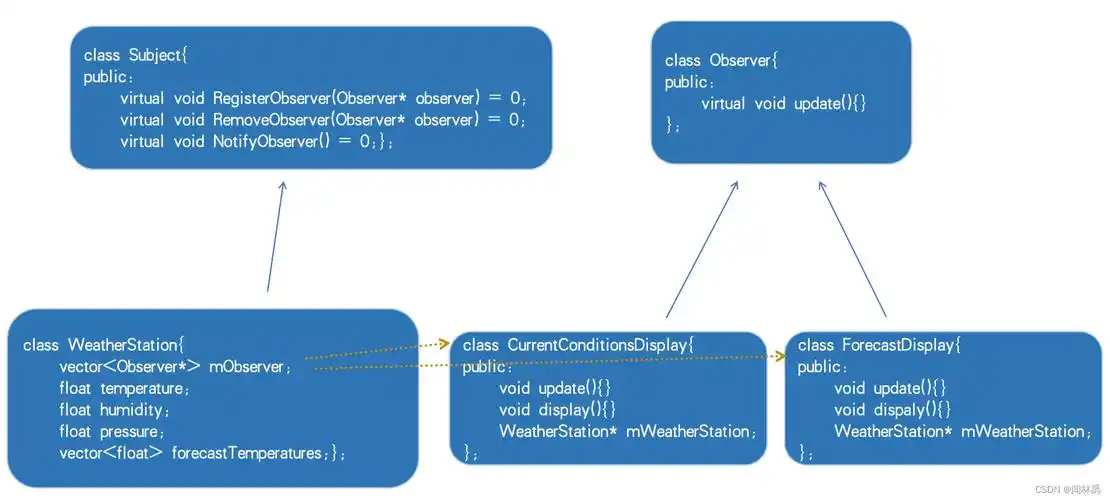
设计模式 Day 6:深入讲透观察者模式(真实场景 + 回调机制 + 高级理解)
观察者模式(Observer Pattern)是一种设计结构中最实用、最常见的行为模式之一。它的魅力不仅在于简洁的“一对多”事件推送能力,更在于它的解耦能力、模块协作设计、实时响应能力。 本篇作为 Day 6,将带你从理论、底层机制到真实…...

C#异步方法返回Task<T>的同步调用
在C#中我们已经非常习惯使用async/await来实现异步调用,但是某些时候并不允许异步调用,比如在一个Dynamics365的插件或操作中 为了确保事务性是不允许异步调用的,这个时候在使用httpclient发起请求时我们就可以使用Task<T>.Result来实现线程阻塞,进行同步方式的调用: va…...
用于执行两个矩阵(或数组)的逐元素减法操作函数sub())
OpenCV 图形API(18)用于执行两个矩阵(或数组)的逐元素减法操作函数sub()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 计算两个矩阵之间的逐元素差值。 sub 函数计算两个矩阵之间的差值,要求这两个矩阵具有相同的尺寸和通道数: dst ( I ) src…...
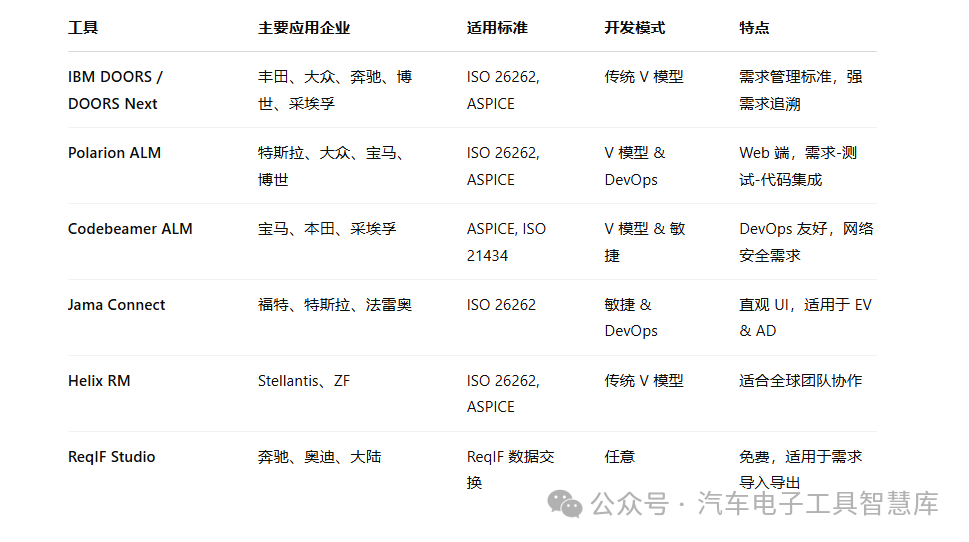
汽车软件开发常用的需求管理工具汇总
目录 往期推荐 DOORS(IBM ) 行业应用企业: 应用背景: 主要特点: Polarion ALM(Siemens) 行业应用企业: 应用背景: 主要特点: Codebeamer ALM&#x…...

AI 越狱技术剖析:原理、影响与防范
一、AI 越狱技术概述 AI 越狱是指通过特定技术手段,绕过人工智能模型(尤其是大型语言模型)的安全防护机制,使其生成通常被禁止的内容。这种行为类似于传统计算机系统中的“越狱”,旨在突破模型的限制,以实…...
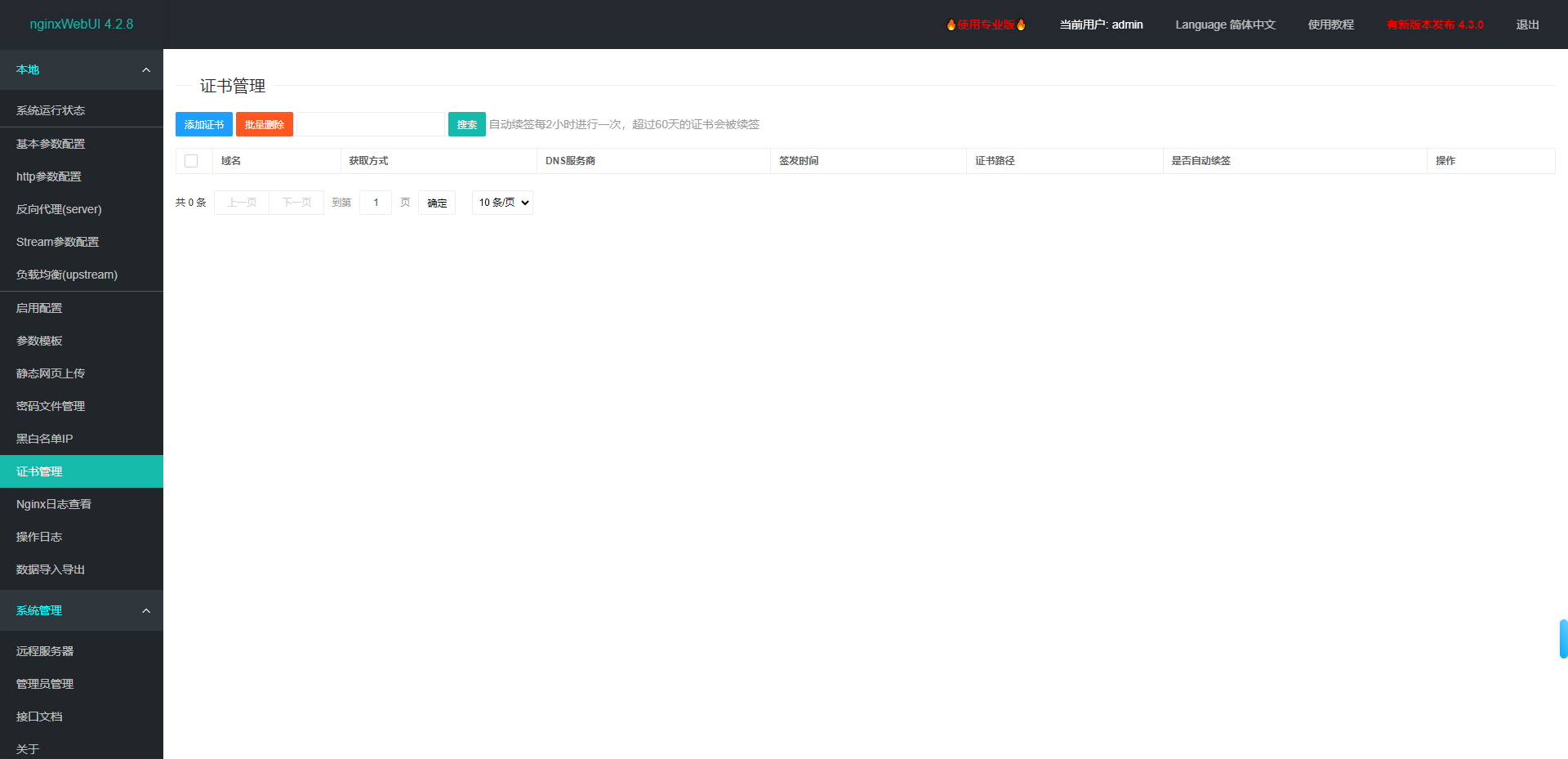
推荐一款Nginx图形化管理工具: NginxWebUI
Nginx Web UI是一款专为Nginx设计的图形化管理工具,旨在简化Nginx的配置与管理过程,提高开发者和系统管理的工作效率。项目地址:https://github.com/cym1102/nginxWebUI 。 一、Nginx WebUI的主要特点 简化配置:通过图形化的界…...

区间 dp 系列 题解
1.洛谷 P4342 IOI1998 Polygon 我的博客 2.洛谷 P4290 HAOI2008 玩具取名 题意 某人有一套玩具,并想法给玩具命名。首先他选择 W, I, N, G 四个字母中的任意一个字母作为玩具的基本名字。然后他会根据自己的喜好,将名字中任意一个字母用 W, I, N, G …...

Spring Boot 自动加载流程详解
前言 Spring Boot 是一个基于约定优于配置理念的框架,它通过自动加载机制大大简化了开发者的配置工作。本文将深入探讨 Spring Boot 的自动加载流程,并结合源码和 Mermaid 图表进行详细解析。 一、Spring Boot 自动加载的核心机制 Spring Boot 的自动加…...

《从底层逻辑剖析:分布式软总线与传统计算机硬件总线的深度对话》
在科技飞速发展的当下,我们正见证着计算机技术领域的深刻变革。计算机总线作为信息传输的关键枢纽,其发展历程承载着技术演进的脉络。从传统计算机硬件总线到如今备受瞩目的分布式软总线,每一次的变革都为计算机系统性能与应用拓展带来了质的…...
Fay 数字人部署环境需求
D:\ai\Fay>python main.py pygame 2.6.1 (SDL 2.28.4, Python 3.11.9) Hello from the pygame community. https://www.pygame.org/contribute.html [2025-04-11 00:10:16.7][系统] 注册命令... [2025-04-11 00:10:16.8][系统] restart 重启服务 [2025-04-11 00:10:16.8][…...
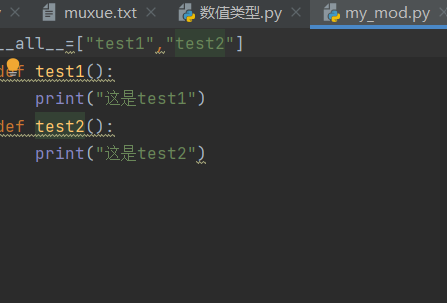
python:all列表
1.all列表的说明: 当模块中有__all__变量时,当使用from xxx import *时,只能导入这个列表中的元素。 2.具体的例子: 1.先创建一个模块my_mod,在列表__all__中分别写入第一次只写入test1,第二次写入test1、test2两个…...

基于 SpringBoot 的校园论坛系统
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...