数据采集爬虫三要素:User-Agent、随机延迟、代理ip
做爬虫的朋友都懂:你刚打开一个页面,还没来得及发第二个请求,服务器已经把你当成了“可疑流量”。403、429、验证码、JS挑战……这些“欢迎仪式”你是不是也经常收到?防爬策略越来越猛,采集工程师越来越秃。

但别慌,今天我们不讲高级逆向,只聊聊最基础也最实用的三样宝贝:User-Agent、随机延迟,还有高匿代理IP。
这三者,几乎是任何数据采集工程的“基本操作”,就像盖楼之前你得先打地基一样。
目录
一、User-Agent:别让服务器一眼识破你是机器人
📌 为什么要伪装 User-Agent?
✅ 最佳实践
示例 UA:
Python 静态 UA 示例:
Python 动态 UA 示例:
二、随机延迟:模拟“人”的操作节奏,降低可疑性
🧠 为什么要加入延迟?
⏳ 常见的延迟策略:
🧪 Python 示例代码:
💡 更进一步:结合线程池/协程做延迟控制
三、让你拥有一整个“代理军团”(扩展详解)
代理工作机制简图
🧩 为什么一定要用代理IP?
🛠 ipwo 提供了哪些能力?
🔧 集成示例(requests 配合 ipwo 使用):
🧠 实战优化建议:
🧪 结合 代理IP 的优势:
四、进阶玩法:打造自己的“分布式爬虫 + IP 代理池”系统
一、User-Agent:别让服务器一眼识破你是机器人
在 HTTP 协议中,User-Agent 是浏览器或客户端用来表明自己身份的请求头之一。简单来说,它就像是你浏览网页时递出去的一张“身份证”。
对于反爬虫系统来说,User-Agent 是识别你是不是“真用户”的第一道关卡。如果你用的是 Python 的 requests 模块,它默认的 User-Agent 是这样:
User-Agent: python-requests/2.31.0👮♂️ 这就像你走进图书馆,手里拿着一把电钻——谁都知道你不是来看书的。
📌 为什么要伪装 User-Agent?
-
默认值太显眼:requests 的 UA 太好识别了,几乎所有网站都会立马拒绝。
-
反爬策略过于敏感:有些网站会对不在“白名单”中的 UA 直接返回验证码、JS验证或封禁。
✅ 最佳实践
-
伪装成常见浏览器(Chrome、Edge、Safari)
-
定期更换 UA:最好配合随机列表,让每次请求都像来自不同浏览器用户。
示例 UA:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36Python 静态 UA 示例:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)Python 动态 UA 示例:
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent': ua.random # 每次请求随机挑一个真实浏览器 UA
}
response = requests.get(url, headers=headers)🚨 注意事项:某些服务器会检测 UA 和 IP 是否匹配(比如你来自美国但 UA 是中文浏览器),这时候就要配合 ipwo 的多国家 IP 设置匹配的 UA,提升真实度。
二、随机延迟:模拟“人”的操作节奏,降低可疑性
如果你每 0.1 秒发一次请求,那你不是爬虫你就是 DDOS 攻击者。大多数网站都有速率限制,太频繁的访问会触发封禁机制。即使你伪装得像浏览器,用了最新的 User-Agent,访问频率不正常还是会被踢出局。
🧠 为什么要加入延迟?
-
模拟真实用户的操作节奏,让你的行为看起来“正常”。
-
避免被触发网站的访问速率阈值,防止返回 429 Too Many Requests。
-
给服务器一个喘息机会,减少因高频访问带来的封禁风险。
⏳ 常见的延迟策略:
| 策略类型 | 示例 | 特点 |
|---|---|---|
| 固定延迟 | time.sleep(2) | 简单粗暴,容易识别 |
| 随机延迟 | random.uniform(1, 3) | 更拟人化,推荐使用 |
| 渐进式延迟 | 每次请求延迟时间累加 | 控流,适合密集采集 |
| 节点动态控制 | 基于响应时间动态调整延迟 | 高级玩法,适合大规模部署 |
🧪 Python 示例代码:
import time, random
urls = ['https://example.com/page1', 'https://example.com/page2']
for url in urls:delay = random.uniform(1, 3)print(f"等待 {delay:.2f} 秒后请求 {url}")time.sleep(delay)response = requests.get(url)⚠️ 实践中建议为不同页面、接口设置不同的延迟策略,比如:搜索接口延迟 5 秒,普通文章页延迟 2 秒。
💡 更进一步:结合线程池/协程做延迟控制
如果你使用多线程或异步框架,仍可以加入延迟机制,保证并发不“炸服”:
-
多线程:在每个线程中加入
sleep(random.uniform(x,y)) -
asyncio:使用
await asyncio.sleep(random.uniform(x,y))
这些策略既保证了效率,也降低了被封禁的概率。
三、让你拥有一整个“代理军团”(扩展详解)
就算你换了 User-Agent,加了延迟,但只要你的请求都从同一个 IP 发出,网站照样会识破你。就像一个人连续几百次敲门,再伪装也会引起怀疑。
这时候,代理 IP 就成了你最需要的工具。这时就需要代理来提供稳定、高匿、易集成的全球 IP 资源。这里推荐一个自用代理:IPWO。其全球代理资源更可以让你坐在家中,畅通无阻获取世界各地一手信息。
这真的是我最近发现的好用工具,通过灵活运用代理工具与服务,能够稳定高效地访问全球技术资源。选对工具、配置得当,就能在激烈的全球技术浪潮中抢占先机,真正做到连接世界、赋能开发。
代理工作机制简图
以ipwo代理为例:
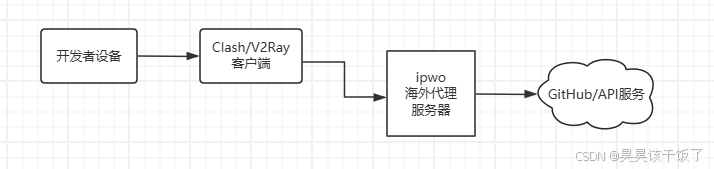
🧩 为什么一定要用代理IP?
-
IP 频控是第一杀手:多数网站对同一 IP 的访问频率有限制,一旦超出,就会临时封禁或永久拉黑。
-
目标内容“因地区而异”:比如电商页面、航班、价格等,只有用不同地区 IP 才能采集全量。
-
多线程爬虫易触发风控:如果 10 个线程用同一个 IP,那就等于你拿着喇叭在喊“我在爬数据!”
🛠 ipwo 提供了哪些能力?
| 功能模块 | 描述 |
| 海量代理池 | 提供动态/住宅 IP,按需调用,数量充足,日更新上万 |
| 区域选择 | 可选国家/地区节点,适配不同采集目标(如美、日、新、港) |
| 协议支持 | 支持 HTTP / HTTPS / SOCKS5,兼容 requests/scrapy 等 |
| 实时 API 提取 | 提供稳定提取接口,按需拉取可用 IP,配合脚本使用方便 |
| 高匿名保障 | 防止 DNS 泄露、不暴露真实源 IP,提高爬虫“伪装等级” |
| 并发限制管理 | 控制连接频率,避免“IP重用”导致同一IP短时内请求过多 |
🔧 集成示例(requests 配合 ipwo 使用):
import requests
import random# ========== 配置信息 ==========# IPWO网址:https://www.ipwo.net/?ref=hao
# 新用户现在注册赠送500M流量!api提取,各种需求随心选择API_URL = "https://api.ipwo.com/fetch"
USERNAME = "你的用户名"
PASSWORD = "你的密码"
NUM = 2 # 提取IP数量
REGION = "us" # 可选:如 cn, us, jp, sg,多个国家可用逗号隔开
PROTOCOL = "http" # 可选值:http 或 socks5
RETURN_TYPE = "json" # 或 txt
CUSTOM_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
TARGET_URL = "https://httpbin.org/ip" # 可替换成你想采集的真实目标# ========== 获取代理 ==========
params = {"num": NUM,"regions": REGION,"protocol": PROTOCOL,"format": RETURN_TYPE
}try:ip_data = requests.get(API_URL, params=params).json()proxy_list = ip_data.get("data", [])if not proxy_list:print("⚠️ 没有获取到代理IP,请检查账号或参数配置")else:for proxy_info in proxy_list:ip = proxy_info["ip"]port = proxy_info["port"]proxy_string = f"{USERNAME}:{PASSWORD}@{ip}:{port}"proxies = {'http': f"http://{proxy_string}",'https': f"http://{proxy_string}"}print(f"🔍 正在使用代理 {ip}:{port} 请求 {TARGET_URL}")response = requests.get(TARGET_URL, headers=CUSTOM_HEADERS, proxies=proxies, timeout=10)print(f"✅ 响应结果:{response.text}")except Exception as e:print(f"❌ 获取或请求失败:{e}")
| 参数名 | 类型 | 必选 | 描述 |
|---|---|---|---|
num | int | 是 | 提取IP的数量 |
regions | string | 否 | 指定国家,如 us,jp,cn |
protocol | string | 否 | http 或 socks5 |
format | string | 否 | json 或 txt |
return_type | string | 否 | 返回格式,同上,推荐用 json |
lb | string | 否 | 分隔符控制 |
sb | string | 否 | 自定义分隔符 |
如需要配置请求设备的 IP 到白名单中,可使用以下接口:
api_key = "你的API Key"
white_ip = "你的本地出口IP"# 添加白名单
requests.get(f"https://www.ipwo.net/api/user/add_white_ip?api_key={api_key}&ips={white_ip}")# 查询白名单
resp = requests.get(f"https://www.ipwo.net/api/user/white_ip_list?api_key={api_key}")
print(resp.json())# 删除白名单
requests.get(f"https://www.ipwo.net/api/user/del_white_ip?api_key={api_key}&ips={white_ip}")
💡 小贴士:可以用
while True做 IP 池轮询、失败重试、过期检测,构建一个稳定持久的代理调度模块。
🧠 实战优化建议:
-
设置“每次请求前提取新 IP”逻辑,确保高匿名
-
多线程/协程并发时,每个 worker 拿一个独立 IP
-
给 IP 设置 TTL(有效期)机制,避免重复使用被封 IP
🧪 结合 代理IP 的优势:
| 项目需求 | ipwo 如何应对 |
| 高频采集 | IP 池支持轮换+并发,避免封禁 |
| 数据完整性 | 支持多地区节点,突破区域限制 |
| 接口兼容性 | 全兼容 Python 主流请求库配置 |
| 自动化调度 | 提供 API,可集成至爬虫调度器 |
四、进阶玩法:打造自己的“分布式爬虫 + IP 代理池”系统
如果你有更大的采集需求,比如每天上百万条数据,那建议你考虑:
-
用
Scrapy或aiohttp做协程爬虫框架 -
搭配 Redis/MongoDB 做分布式任务队列
-
写一个自动轮换 IP 的中间件(调用 ipwo API)
-
失败重试机制、代理检测模块、爬虫控制面板等
最终实现自动调度、自动轮换、自动采集的“无人值守爬虫系统”。
做数据采集,从来不是靠一腔热血猛冲。过反爬、抗封锁才是常态作战。本文分享的 User-Agent、延迟策略和代理IP,是爬虫三大基础护法,总而言之,核心思想就是绕过封锁,模拟真人,记得不要给对方网站施加太大压力!
有了这套“三件套”,你可以更安心地采集你所需的数据内容。数据工程师的快乐,从稳定的一条 IP 开始!
相关文章:
数据采集爬虫三要素:User-Agent、随机延迟、代理ip
做爬虫的朋友都懂:你刚打开一个页面,还没来得及发第二个请求,服务器已经把你当成了“可疑流量”。403、429、验证码、JS挑战……这些“欢迎仪式”你是不是也经常收到?防爬策略越来越猛,采集工程师越来越秃。 但别慌&am…...
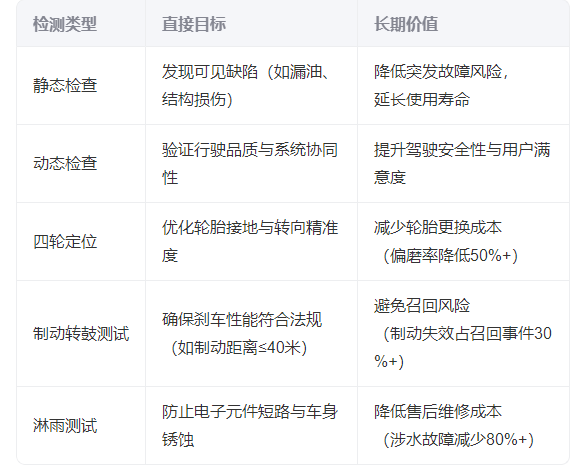
汽车的四大工艺
文章目录 冲压工艺核心流程关键技术 焊接工艺核心流程 涂装工艺核心流程 总装工艺核心流程终检与测试静态检查动态检查四轮定位制动转鼓测试淋雨测试总结 简单总结下汽车的四大工艺(从网上找了一张图,感觉挺全面的)。 冲压工艺 将金属板材通过…...
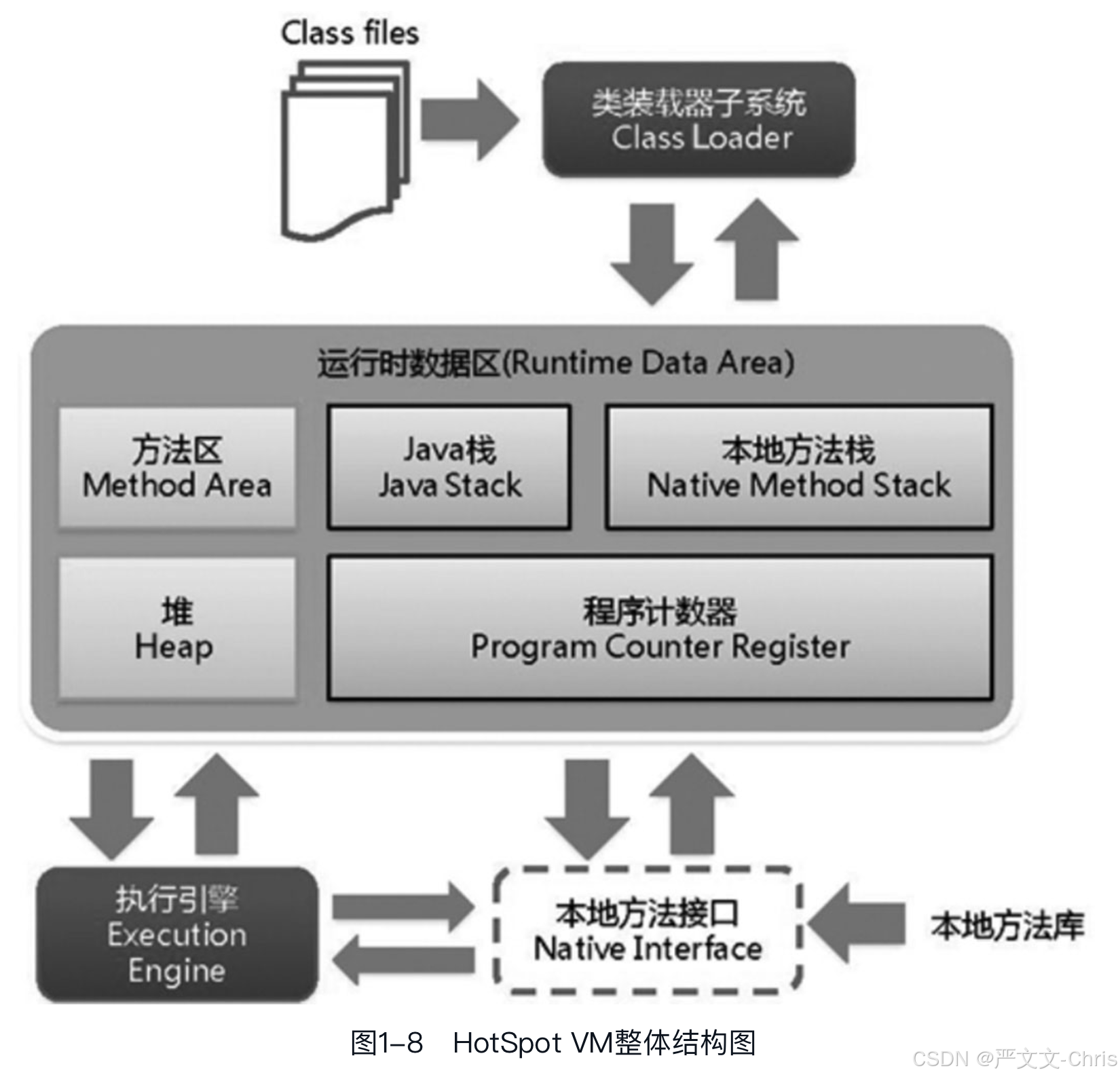
【JVM是什么?JVM解决什么问题?JVM在JDK体系中是什么?虚拟机和JVM、操作系统是什么关系?】
1. JVM 是什么? JVM(Java Virtual Machine,Java 虚拟机) 是一个虚拟的计算机程序,它是 Java 程序运行的核心环境。JVM 的主要职责是加载、验证、解释或编译 Java 字节码(.class 文件)ÿ…...

21 天 Python 计划:MySQL中DML与权限管理
文章目录 前言一、介绍二、MySQL数据操作:DML2.1 插入数据(INSERT)2.1.1 插入完整数据(顺序插入)2.1.2 指定字段插入数据2.1.3 插入多条记录2.1.4 插入查询结果 2.2 更新数据(UPDATE)2.3 删除数…...
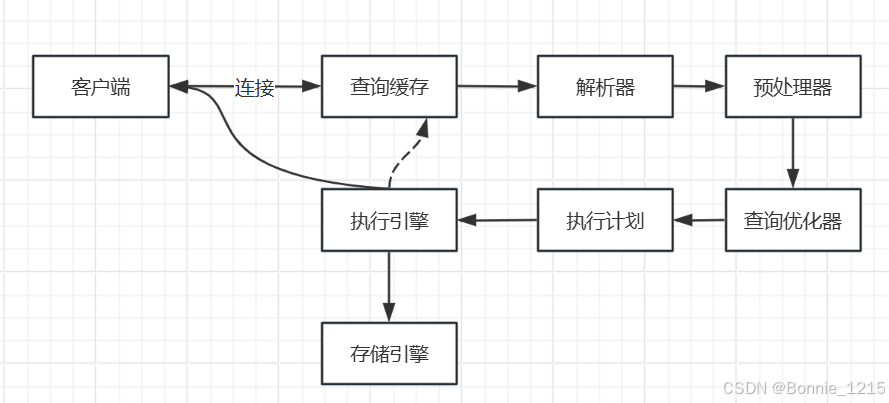
10-MySQL-性能优化思路
1、优化思路 当我们发现了一个慢SQL的问题的时候,需要做性能优化,一般我们是为了提高SQL查询更快,一个查询的流程由下图的各环节组成,每个环节都会消耗时间,要减少消耗时候需要从各个环节都分析一遍。 2 连接配置优化 第一个环节是客户端连接到服务端,这块可能会出现服务…...
MySQL学习笔记十
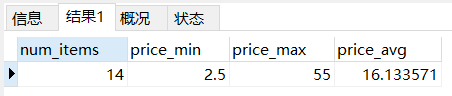
第十二章汇总数据 12.1聚集函数 聚集函数运行在行组上,计算和返回单个值。 12.1.1AVG()函数 输入: SELECT AVG(prod_price) AS avg_price FROM products; 输出: 说明:AVG()函数通过对表中行数计数并计算特定列值之和&#…...

在Halcon的语义分割中,过度拟合解决方法
在Halcon语义分割中出现过拟合是比较常见的问题,以下是一些解决方法。 数据方面 - 扩大数据集:收集更多不同场景、角度、光照条件下的图像数据。例如,在做工业零件语义分割时,如果仅用少量固定角度和光照下的零件图像训练…...

Active Directory 域服务
1.活动目录有什么特点 1. 目录服务 集中管理:提供集中式的用户、计算机、组和其他资源的管理。 结构化存储:以层次结构的方式存储信息,便于组织和检索。 2. 域和林结构 域(Domain):一个逻辑分组&#x…...
Redis快的原因
1、基于内存实现 Redis将所有数据存储在内存中,因此它可以非常快速地读取和写入数据,而无需像传统数据库那样将数据从磁盘读取和写入磁盘,这样也就不受I/O限制。 2、I/O多路复用 多路指的是多个socket连接;复用指的是复用一个线…...

Android 自己的智能指针
在 Android 系统中,强指针模板类(sp<T>) 是一种基于引用计数的智能指针实现,专门用于管理对象的生命周期。它被广泛用于 Android Framework 的底层(Native 层/C 代码),尤其是与 Binder 通…...

如何在React中集成 PDF.js?构建支持打印下载的PDF阅读器详解
本文深入解析基于 React 和 PDF.js 构建 PDF 查看器的实现方案,该组件支持 PDF 渲染、图片打印和下载功能,并包含完整的加载状态与错误处理机制。 完整代码在最后 一个PDF 文件: https://mozilla.github.io/pdf.js/web/compressed.tracemo…...

【完美解决】VSCode连接HPC节点,已配置密钥却还是提示需要输入密码
目录 问题描述软件版本原因分析错误逻辑链 解决方案总结 问题描述 本人在使用 VSCode Remote-SSH 插件连接超算集群节点时,遇到以下问题:已正确配置 SSH 密钥,且 VSCode 能识别密钥文件(如图1),但在…...

智能DNS解析:解决高防IP地区访问异常的实战指南
摘要:针对高防IP在部分地区无法访问的问题,本文设计基于智能DNS的流量调度方案,提供GeoDNS配置与故障切换代码示例。 一、问题背景 运营商误拦截或线路波动可能导致高防IP在福建、江苏等地访问异常。传统切换方案成本高,智能DNS可…...
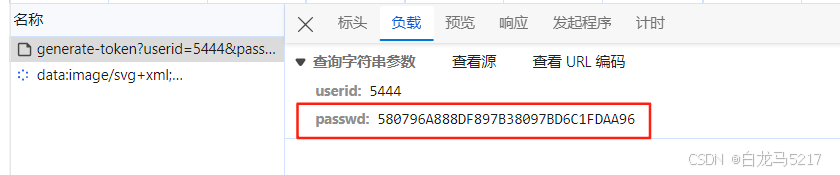
【JSON2WEB】16 login.html 登录密码加密传输
【JSON2WEB】系列目录 【JSON2WEB】01 WEB管理信息系统架构设计 【JSON2WEB】02 JSON2WEB初步UI设计 【JSON2WEB】03 go的模板包html/template的使用 【JSON2WEB】04 amis低代码前端框架介绍 【JSON2WEB】05 前端开发三件套 HTML CSS JavaScript 速成 【JSON2WEB】06 JSO…...

ruby超高级语法
以下是 Ruby 中一些 极度硬核 的语法和底层特性,涉及元编程的深渊、虚拟机原理、语法黑魔法等,适用于追求极限的 Ruby 开发者: 高级语法一 一、语法核弹级操作 1. 动态修改继承链 class A; def foo; "A"; end end class B; def …...

第十二天 - Flask/Django基础 - REST API开发 - 练习:运维管理后台API
从零开始用Flask/Django构建运维管理后台API(实战指南) 前言:为什么选择Python Web框架? 在运维自动化领域,构建管理后台是每个运维工程师的必修课。本文将通过Flask和Django两个主流框架,手把手教你构建…...

Docker 容器内运行程序的性能开销
在 Docker 容器内运行程序通常会有一定的性能开销,但具体损失多少取决于多个因素。以下是详细分析: 1. CPU 性能 理论开销:容器直接共享宿主机的内核,CPU 调度由宿主机管理,因此 CPU 运算性能几乎与原生环境一致&…...

从递归入手一维动态规划
从递归入手一维动态规划 1. 509. 斐波那契数 1.1 思路 递归 F(i) F(i-1) F(i-2) 每个点都往下展开两个分支,时间复杂度为 O(2n) 。 在上图中我们可以看到 F(6) F(5) F(4)。 计算 F(6) 的时候已经展开计算过 F(5)了。而在计算 F(7)的时候,还需要…...

【2025年认证杯数学中国数学建模网络挑战赛】A题解题思路与模型代码
【2025年认证杯数学建模挑战赛】A题 该题为典型的空间几何建模轨道动力学建模预测问题。 ⚙ 问题一:利用多个天文台的同步观测,确定小行星与地球的相对距离 问题分析 已知若干地面天文台的观测数据:方位角 (Azimuth) 和 高度角 (Altitude)&…...

蓝桥杯备赛 Day16 单调数据结构
单调栈和单调队列能够动态的维护,还需用1-2两个数组在循环时从单调栈和单调队列中记录答案 单调栈 要点 1.时刻保持内部元素具有单调性质的栈(先进后出),核心是:入栈时逐个删除所有"更差的点",一般可分为单调递减栈、单调递增栈、单调不减栈、单调不增…...

轻量级爬虫框架Feapder入门:快速搭建企业级数据管道
一、目标与前置知识 1. 目标概述 本教程的主要目标是: 介绍轻量级爬虫框架 Feapder 的基本使用方式。快速搭建一个采集豆瓣电影数据的爬虫,通过电影名称查找对应的电影详情页并提取相关信息(电影名称、导演、演员、剧情简介、评分…...
golang gmp模型分析
思维导图: 1. 发展过程 思维导图: 在单机时代是没有多线程、多进程、协程这些概念的。早期的操作系统都是顺序执行 单进程的缺点有: 单一执行流程、计算机只能一个任务一个任务进行处理进程阻塞所带来的CPU时间的浪费 处于对CPU资源的利用&…...

深入理解Java Optional:告别NullPointerException的优雅方式
大家好!今天我们来聊聊Java 8引入的一个超实用类 - Optional。不是那个让你重启电脑的CtrlAltDel哦!😄 这是一个能让我们优雅处理null值的工具类,彻底告别烦人的NullPointerException! 一、为什么需要Optional&#x…...

【算法竞赛】树上最长公共路径前缀(蓝桥杯2024真题·团建·超详细解析)
目录 一、题目 二、思路 1. 问题转化:同步DFS走树 2. 优化:同步DFS匹配 3. 状态设计:dfs参数含义 4. 匹配过程:用 map 建立权值索引 5. 终止条件:无法匹配则更新答案 6. 总结 三、完整代码 四、知识点总…...
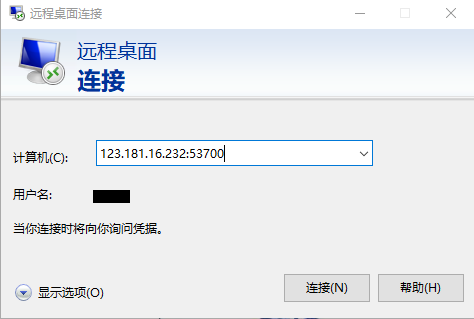
【windows10】基于SSH反向隧道公网ip端口实现远程桌面
【windows10】基于SSH反向隧道公网ip端口实现远程桌面 1.背景2.SSH反向隧道3.远程连接电脑 1.背景 Windows 10远程桌面协议的简称是RDP(Remote Desktop Protocol)。 RDP是一种网络协议,允许用户远程访问和操作另一台计算机。 远程桌面功…...

Python----概率论与统计(贝叶斯,朴素贝叶斯 )
一、贝叶斯 1.1、贝叶斯定理 贝叶斯定理(Bayes Theorem)也称贝叶斯公式,是关于随机事件的条件概率的定理 贝叶斯的的作用:根据已知的概率来更新事件的概率。 1.2、定理内容 提示: 贝叶斯定理是“由果溯因”的推断&…...
)
NO.88十六届蓝桥杯备战|动态规划-多重背包|摆花(C++)
多重背包 多重背包问题有两种解法: 按照背包问题的常规分析⽅式,仿照完全背包,第三维枚举使⽤的个数;利⽤⼆进制可以表⽰⼀定范围内整数的性质,转化成01 背包问题。 ⼩建议:并不是所有的多重背包问题都能…...

vue项目打包里面pubilc里的 tinymce里的js文件问题
以下是解决 Vue 项目打包后 public/tinymce 中 JS 文件路径问题的完整方案: 问题原因 当使用 public 目录存放静态资源时,Vue CLI 默认会将 public 下的文件 直接复制到打包目录的根路径,但以下操作可能导致路径错误: 开发环境使…...
)
Python星球日记 - 第18天:小游戏开发(猜数字游戏)
🌟引言: 上一篇:Python星球日记 - 第17天:数据可视化 名人说:路漫漫其修远兮,吾将上下而求索。(屈原《离骚》) 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、游戏概述与原理1. 游戏基本规则2. 编程知识点3.猜数字游戏流程图二、游戏逻辑设计…...
爬虫抓包工具和PyExeJs模块
我们在处理一些网站的时候, 会遇到一些屏蔽F12, 以及只要按出浏览器的开发者工具就会关闭甚至死机的现象. 在遇到这类网站的时候. 我们可以使用抓包工具把页面上屏蔽开发者工具的代码给干掉. Fiddler和Charles 这两款工具是非常优秀的抓包工具. 他们可以监听到我们计算机上所…...