API 请求失败时的处理方法
在使用 Python 爬虫调用 API 时,请求失败是一个常见的问题。这可能是由于网络问题、API 限制、服务器错误或其他原因导致的。为了确保爬虫的稳定性和可靠性,我们需要合理地处理这些失败的请求。以下是一些有效的处理方法:
1. 捕获异常
使用 try-except 语句捕获可能的异常,可以防止程序因异常而崩溃,并提供适当的错误处理。常见的异常类型包括:
-
网络错误(如
ConnectionError):通常表示网络连接问题。 -
HTTP 错误(如
HTTPError):表示 HTTP 请求返回的状态码不是 200。 -
解析错误(如
ValueError):通常发生在解析 HTML 或 JSON 数据时。
示例代码:
Python
import requests
from requests.exceptions import HTTPError, ConnectionError, Timeouturl = "http://example.com/api/data"try:response = requests.get(url, timeout=10)response.raise_for_status() # 如果响应状态码不是200,抛出HTTPErrordata = response.json()
except HTTPError as http_err:print(f"HTTP error occurred: {http_err}")
except ConnectionError as conn_err:print(f"Connection error occurred: {conn_err}")
except Timeout as timeout_err:print(f"Timeout error occurred: {timeout_err}")
except Exception as err:print(f"An error occurred: {err}")2. 重试机制
在请求失败时,可以设置重试机制,让爬虫重新尝试获取数据。可以通过以下方法实现:
-
使用
retrying库:提供简单的重试机制。 -
自定义重试逻辑:在捕获到特定异常后,设置最大重试次数和重试间隔时间。
使用 retrying 库的示例:
Python
from retrying import retry
import requests@retry(stop_max_attempt_number=3, wait_fixed=2000)
def fetch_url(url):response = requests.get(url)response.raise_for_status()return response.texturl = "http://example.com/api/data"
try:data = fetch_url(url)print(f"Successfully fetched {url}")
except Exception as err:print(f"Failed to fetch {url}: {err}")自定义重试逻辑的示例:
Python
import time
import requestsdef fetch_url(url, max_retries=3, wait_time=2):for attempt in range(max_retries):try:response = requests.get(url)response.raise_for_status()return response.textexcept requests.exceptions.RequestException as req_err:print(f"Attempt {attempt + 1} failed: {req_err}")time.sleep(wait_time)raise Exception(f"Failed to fetch {url} after {max_retries} attempts")url = "http://example.com/api/data"
try:data = fetch_url(url)print(f"Successfully fetched {url}")
except Exception as err:print(f"Failed to fetch {url}: {err}")3. 指数退避
当 API 返回“429 Too Many Requests”状态码时,表示请求过于频繁。此时可以使用指数退避策略,即在每次重试之间增加等待时间。这有助于避免因请求频率过高而被限制。
示例代码:
Python
import time
import requestsdef fetch_url_with_backoff(url, max_retries=5):retry_count = 0while retry_count < max_retries:try:response = requests.get(url)response.raise_for_status()return response.textexcept requests.exceptions.HTTPError as http_err:if http_err.response.status_code == 429:retry_after = int(http_err.response.headers.get('Retry-After', 1))print(f"Rate limit exceeded. Retrying in {retry_after} seconds...")time.sleep(retry_after)retry_count += 1else:raiseexcept requests.exceptions.RequestException as req_err:print(f"Request failed: {req_err}")breakraise Exception(f"Failed to fetch {url} after {max_retries} attempts")url = "http://example.com/api/data"
try:data = fetch_url_with_backoff(url)print(f"Successfully fetched {url}")
except Exception as err:print(f"Failed to fetch {url}: {err}")4. 日志记录
在异常处理中,及时记录异常信息是非常重要的。可以使用 Python 内置的 logging 模块或第三方库(如 loguru)来记录异常日志。这有助于快速定位问题并进行修复。
示例代码:
Python
import logging
import requestslogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')url = "http://example.com/api/data"try:response = requests.get(url)response.raise_for_status()data = response.json()
except requests.exceptions.RequestException as req_err:logging.error(f"Request failed: {req_err}")5. 优化请求
-
缓存结果:对于不需要频繁更新的数据,可以将 API 调用的结果缓存起来,减少不必要的请求。
-
批量请求:尽量合并多个单独的请求为一个批量请求,以减少总的调用次数。
-
合理安排请求频率:避免短时间内频繁发送请求。
6. 使用代理
如果请求被限制或被封禁,可以使用代理服务器来隐藏真实的 IP 地址。这有助于避免因 IP 被封禁而导致的请求失败。
示例代码:
Python
import requestsproxies = {"http": "http://your-proxy-ip:port","https": "http://your-proxy-ip:port"
}url = "http://example.com/api/data"
try:response = requests.get(url, proxies=proxies)response.raise_for_status()data = response.json()
except requests.exceptions.RequestException as req_err:print(f"Request failed: {req_err}")总结
通过上述方法,可以有效处理 API 请求失败的问题,提高爬虫的稳定性和可靠性。合理捕获异常、设置重试机制、使用指数退避策略、记录日志以及优化请求频率,都是确保爬虫稳定运行的重要手段。
相关文章:

API 请求失败时的处理方法
在使用 Python 爬虫调用 API 时,请求失败是一个常见的问题。这可能是由于网络问题、API 限制、服务器错误或其他原因导致的。为了确保爬虫的稳定性和可靠性,我们需要合理地处理这些失败的请求。以下是一些有效的处理方法: 1. 捕获异常 使用…...

【MySQL | 八、 事务管理】
文章目录 什么是事务?事务的特性:事务的意义事务的提交查看事务提交方式事务的自动提交事务的手动提交开始事务执行SQL操作事务操作提交事务示例: 事务的隔离级别并发访问的基本概念并发事务的典型问题对ACID特性的影响查看和设置隔离属性各个…...

AlDente Pro for Mac电脑 充电限制保护工具
AlDente Pro for Mac电脑 充电限制保护工具 一、介绍 AlDente Pro for Mac,是一款充电限制保护工具,是可以限制最大充电百分比来保护电池的工具。锂离子和聚合物电池(如 MacBook 中的电池)在40% 至 80% 之…...
算法训练之动态规划(一)
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...
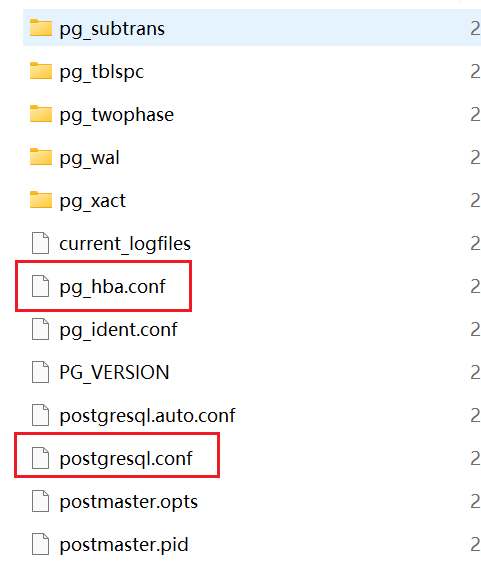
Navicat连接远程PostGreSQL失败
问题描述 使用本地Navicat连接Windows远程服务器上部署的PostGreSQL数据库时,出现以下错误: 解决方案 出现以上报错信息,是因为PostGreSQL数据库服务尚未设置允许客户端建立远程连接。可做如下配置, 1. 找到PostGreSQL数据库安装目录下的data子文件夹,重点关注:postgres…...
)
漏洞扫描系统docker版本更新(2025.4.10)
一、github地址 https://github.com/huan-cdm/info_scan本人一直维护的一个项目,持续更新中,感兴趣的小伙伴帮忙点点星 二、docker版本更新 1. 账号密码:nginx/web/mysql:admin/123456 2. 创建docker自定义网络,使容…...
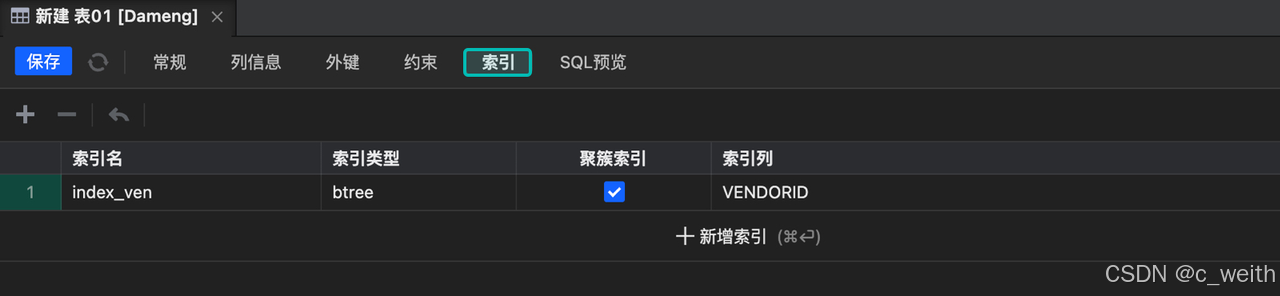
新一代达梦官方管理工具SQLark:可视化建表操作指南
在数据库管理工作中,新建表是一项基础且频繁的操作。SQLark 的可视化建表功能为我们提供了一种高效、便捷且丝滑流畅的建表新体验。一起来了解下吧。 SQLark 官方下载链接:www.sqlark.com 新建表作为常见的功能,相比其他管理工具,…...

什么是EXR透视贴图 ?
EXR透视贴图是一种基于 OpenEXR 格式的高动态范围(HDR)图像技术,主要用于3D建模、渲染和视觉特效领域。它通过高精度图像数据和透视映射功能,为场景创建逼真的光影效果和空间深度。 技术原理 高动态范围(HDR…...

音频转文本:如何识别音频成文字
Python脚本:MP4转MP3并语音识别为中文 以下是一个完整的Python脚本,可以将MP4视频转换为MP3音频,然后使用语音识别模型将音频转换为中文文本。 准备工作 首先需要安装必要的库: pip install moviepy pydub SpeechRecognition openai-whisper完整脚本 import os from m…...
每日一题(小白)数组娱乐篇21
由于题意可知我们是要将对应的数字转换为英文,我们要考虑两点一个是进制的转换,也就是类似于我们的十进制一到9就多一位,这里的进制就是Z进制也就是27进制一旦到26下一位则进位;另一方面要考虑数字的转换也就是1~26对应A~Z。解决上…...
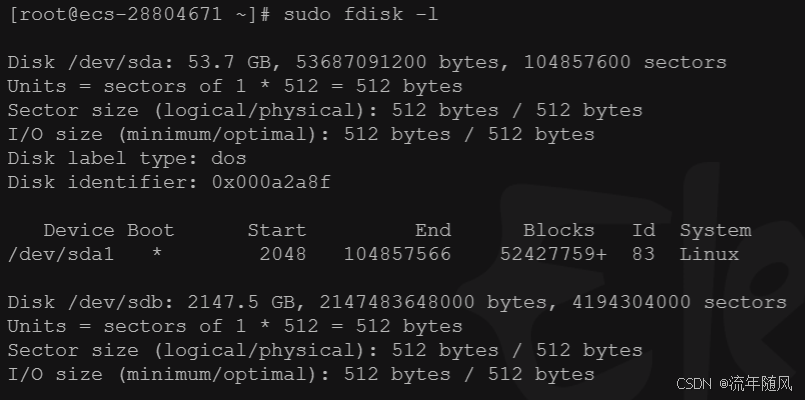
LINUX的使用(1)-挂载云硬盘
1.磁盘的挂载: 这个输出是来自 fdisk 或类似的工具,它展示了两块磁盘的分区信息。让我们逐个分析: 第一块磁盘 /dev/sda: 磁盘大小: 53.7 GB (约 53687091200 字节),总共有 104857600 个扇区。扇区单位: 每个扇区大小为 512 字节…...
GPT-4o-image模型:开启AI图片编辑新时代
在生成式AI技术爆发式迭代的今天,智创聚合API率先突破多模态创作边界,正式发布集成GPT-4o-image模型的创作平台,以“文生图-图生图-循环编辑”三位一体的技术矩阵,重新定义数字内容生产流程。生成图像效率较传统工具提升300%&…...

基于Python的网络爬虫技术研究
基于Python的网络爬虫技术研究 以下从多个方面为你介绍基于 Python 的网络爬虫技术: 概述 网络爬虫是一种自动获取网页内容的程序,在 Python 中可以借助诸多强大的库和工具实现。网络爬虫能应用于数据采集、搜索引擎、舆情监测等众多领域。 核心库 …...

使用pip3安装PyTorch与PyG,实现NVIDIA CUDA GPU加速
使用python3的pip3命令安装python依赖库。 # python3 -V Python 3.12.3 # # pip3 -V pip 25.0.1 from /root/.pyenv/versions/3.12.3/lib/python3.12/site-packages/pip (python 3.12)Usage: pip3 install [options] <package> ...pip3 install [options] -r <re…...

Rust主流框架性能比拼: Actix vs Axum vs Rocket
本内容是对知名性能评测博主 Anton Putra Actix (Rust) vs Axum (Rust) vs Rocket (Rust): Performance Benchmark in Kubernetes 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 在以下中,我们将比较 Rust 生态中最受欢迎的几个框架。我会将三个应用程序…...

设计模式-观察者模式和发布订阅模式区别
文章目录 其他不错的文章 二者有类似的地方,也有区别。 引用的文章说的已经比较清楚了,这里只列出对比图。 对比点观察者模式发布订阅模式中间人角色无事件中心,观察者直接订阅目标有事件中心,发布者与订阅者通过事件中心通信关系…...
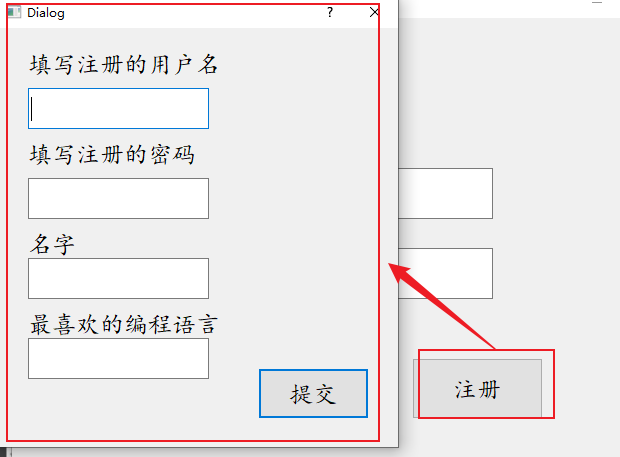
【QT】QT的消息盒子和对话框(自定义对话框)
QT的消息盒子和对话框(自定义对话框) 一、消息盒子QMessageBox1、弹出警告盒子示例代码:现象: 2、致命错误盒子示例代码:现象: 3、帮助盒子示例代码:现象: 4、示例代码: …...

ArcGIS 给大面内小面字段赋值
文章目录 引言:地理数据处理中的自动化赋值为何重要?实现思路模型实现关键点效果实现步骤1、准备数据2、执行3、完成4、效果引言:地理数据处理中的自动化赋值为何重要? 在地理信息系统(GIS)的日常工作中,空间数据的属性字段赋值是高频且关键的操作,例如在土地利用规划…...
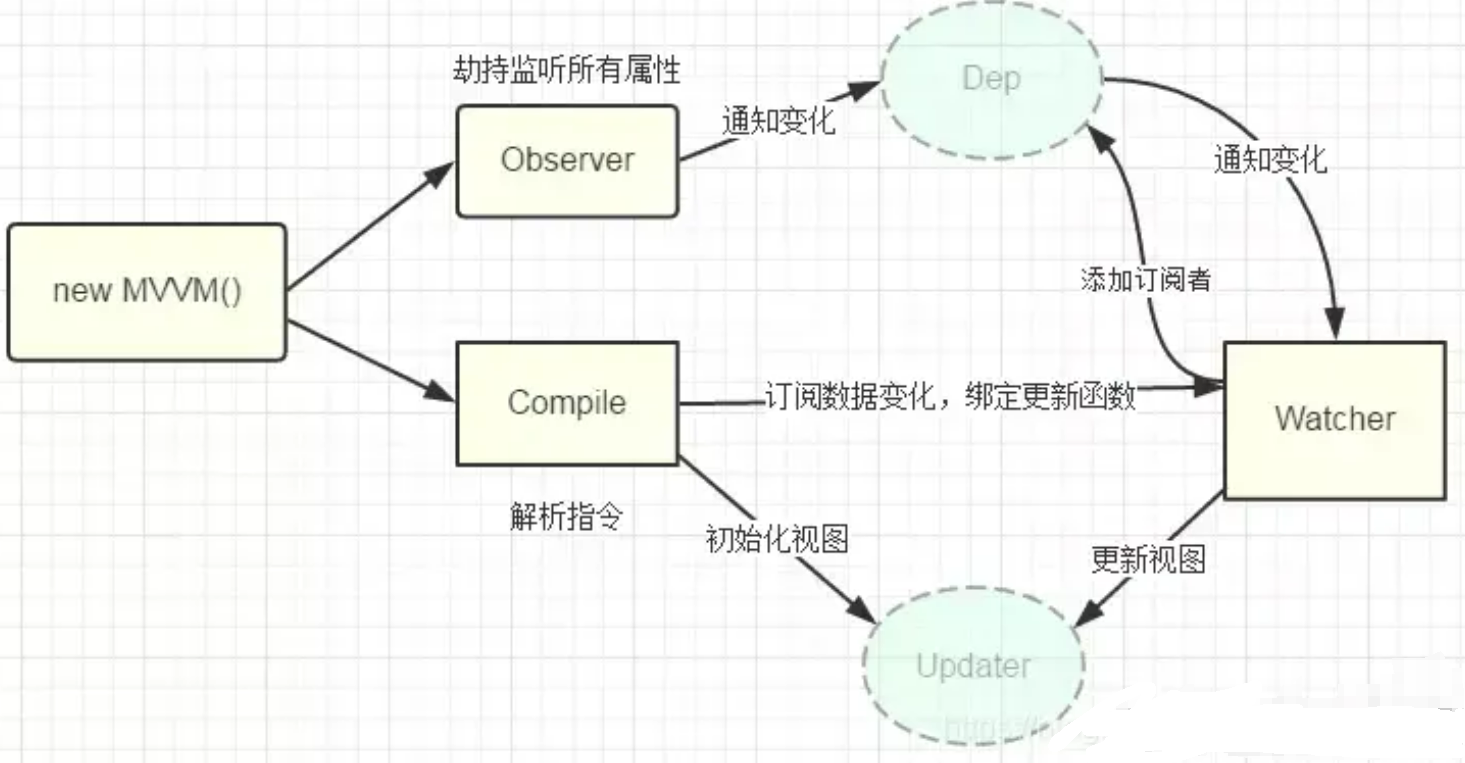
【结合vue源码,分析vue2及vue3的数据绑定实现原理】
结合vue源码,分析vue2及vue3的数据绑定实现原理 Vue 2 数据绑定实现整体思路详细实现1. Observer 类:数据劫持2. Dep 类:依赖收集3. Watcher 类:订阅者 Vue 3 数据绑定实现整体思路详细实现1. reactive 函数:创建响应式…...

WebGPU:前端图形技术的革命性进化与WebGL的未来
WebGPU:前端图形技术的革命性进化与WebGL的未来 WebGPU作为新一代Web图形API,正在引发前端图形领域的深刻变革。本文将全面剖析WebGPU的技术优势、性能表现、应用场景,以及它与WebGL的关系和未来发展趋势。 WebGPU与WebGL的技术代差 WebGP…...
如何实现H5端对接钉钉登录并优雅扩展其他平台
如何实现H5端对接钉钉登录并优雅扩展其他平台 钉钉H5登录逻辑后端代码如何实现?本次采用策略模式工厂方式进行定义接口确定会使用的基本鉴权步骤具体逻辑类进行实现采用注册表模式(Registry Pattern)抽象工厂进行基本逻辑定义具体工厂进行对接…...

Android MediaStore访问的外部存储公共空间都不需要申请权限,这些目录具体指的是哪些
在 Android 10 及更高版本中,通过 MediaStore 访问以下 外部存储公共目录 时,如果操作的是应用自己创建的文件,则无需申请存储权限。这些目录属于系统明确定义的媒体集合,具体包括: 1. 媒体类型目录…...

Java中的Exception和Error有什么区别?还有更多扩展
概念 在Java中,Exception和Error都是Throwable的子类,用于处理程序中的错误和异常情况。 然而,它们在用途和处理方式上有显著的不同: Exception: 用于表示程序在正常运行过程中可能出现的错误,如文件未找…...

LabVIEW真空度监测与控制系统
开发了一种基于LabVIEW的真空度信号采集与管理系统,该系统通过图形化编程语言实现了真空度的高精度测量和控制。利用LabVIEW的强大功能,研制了相应的硬件并设计了完整的软件解决方案,以满足工业应用中对真空度监测的精确要求。 项目背景 随着…...

虚拟dom工作原理以及渲染过程
浏览器渲染引擎工作流程都差不多,大致分为5步,创建DOM树——创建StyleRules——创建Render树——布局Layout——绘制Painting 第一步,用HTML分析器,分析HTML元素,构建一颗DOM树(标记化和树构建)。 第二步,用…...
数据采集爬虫三要素:User-Agent、随机延迟、代理ip
做爬虫的朋友都懂:你刚打开一个页面,还没来得及发第二个请求,服务器已经把你当成了“可疑流量”。403、429、验证码、JS挑战……这些“欢迎仪式”你是不是也经常收到?防爬策略越来越猛,采集工程师越来越秃。 但别慌&am…...
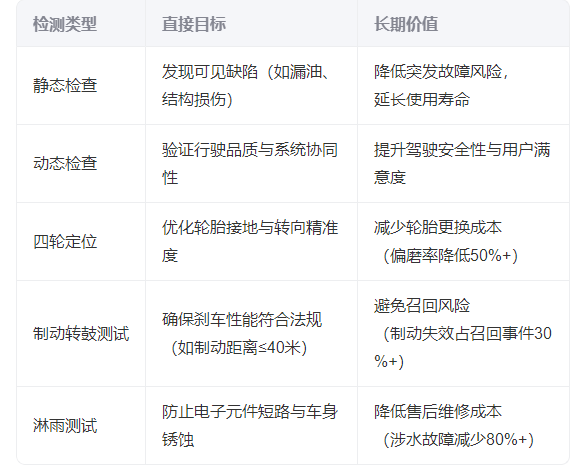
汽车的四大工艺
文章目录 冲压工艺核心流程关键技术 焊接工艺核心流程 涂装工艺核心流程 总装工艺核心流程终检与测试静态检查动态检查四轮定位制动转鼓测试淋雨测试总结 简单总结下汽车的四大工艺(从网上找了一张图,感觉挺全面的)。 冲压工艺 将金属板材通过…...
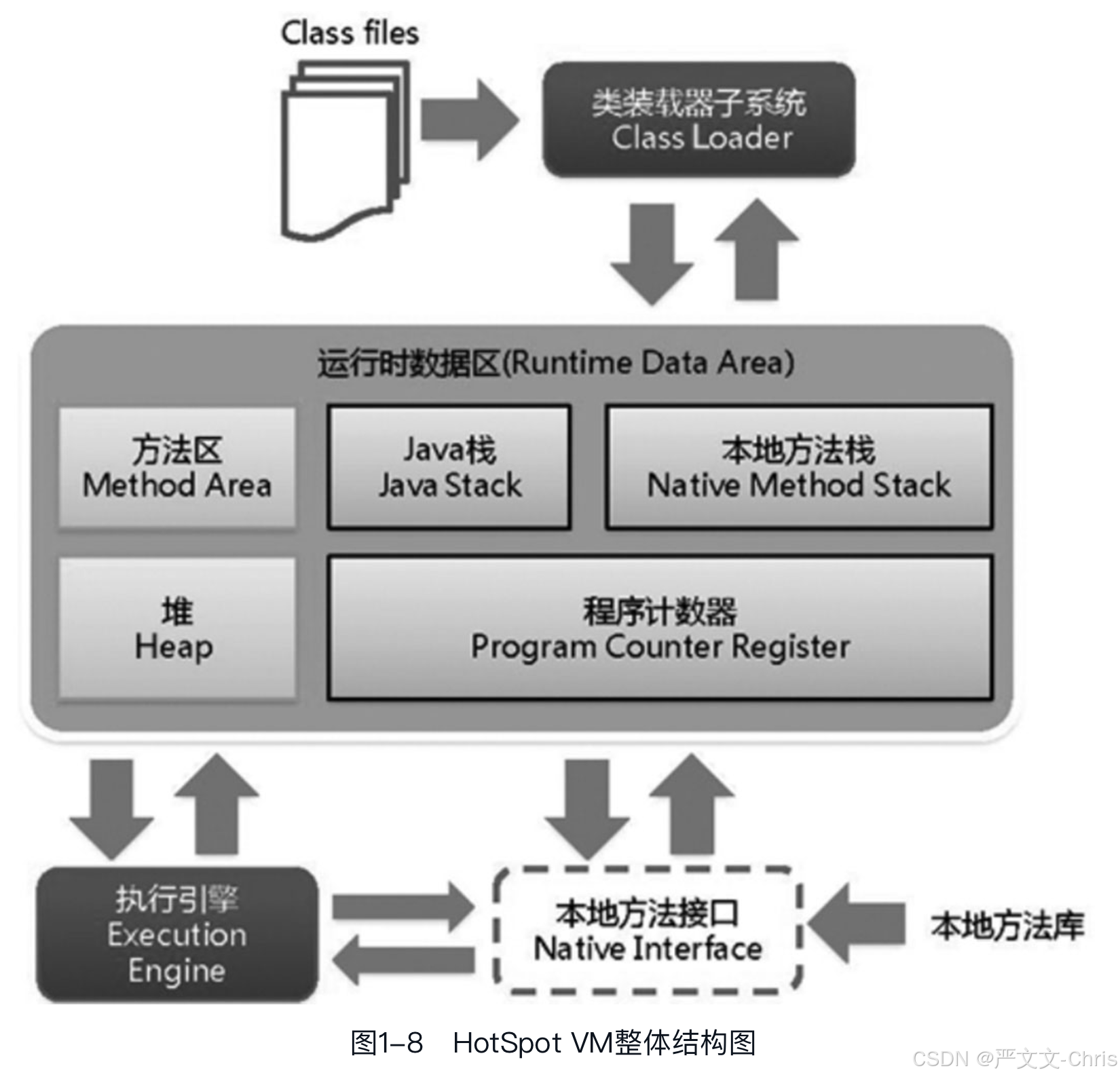
【JVM是什么?JVM解决什么问题?JVM在JDK体系中是什么?虚拟机和JVM、操作系统是什么关系?】
1. JVM 是什么? JVM(Java Virtual Machine,Java 虚拟机) 是一个虚拟的计算机程序,它是 Java 程序运行的核心环境。JVM 的主要职责是加载、验证、解释或编译 Java 字节码(.class 文件)ÿ…...

21 天 Python 计划:MySQL中DML与权限管理
文章目录 前言一、介绍二、MySQL数据操作:DML2.1 插入数据(INSERT)2.1.1 插入完整数据(顺序插入)2.1.2 指定字段插入数据2.1.3 插入多条记录2.1.4 插入查询结果 2.2 更新数据(UPDATE)2.3 删除数…...
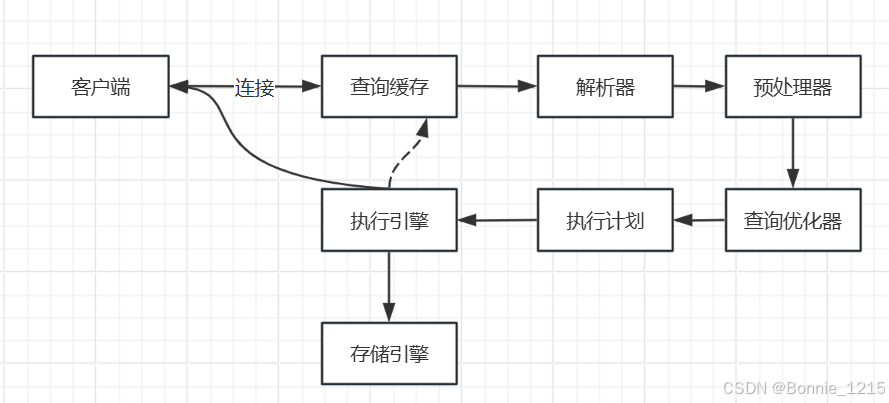
10-MySQL-性能优化思路
1、优化思路 当我们发现了一个慢SQL的问题的时候,需要做性能优化,一般我们是为了提高SQL查询更快,一个查询的流程由下图的各环节组成,每个环节都会消耗时间,要减少消耗时候需要从各个环节都分析一遍。 2 连接配置优化 第一个环节是客户端连接到服务端,这块可能会出现服务…...