基于 Q - learning 算法的迷宫导航
这段 Python 代码实现了一个基于 Q - learning 算法的迷宫导航系统。代码通过定义迷宫环境、实现 Q - learning 算法来训练智能体,使其能够在迷宫中找到从起点到终点的最优路径,同时利用训练好的 Q 表来测试智能体的导航能力。
在这个代码实现的迷宫环境和 Q-learning 算法中, Q 表存储的是每个状态(即迷宫中的每个格子位置)下对于每个可能动作(上、下、左、右四个方向)的 Q 值。
迷宫的大小由 size 参数决定,状态空间是由 size 确定的所有格子位置的集合,即 [(i, j) for i in range(size) for j in range(size)] ,动作空间固定为 ['up', 'down', 'left', 'right'] 这四个动作。
因此,总的 Q 值的数量就是状态空间中状态的数量(也就是格子的个数,等于 size * size )乘以动作的数量(这里是 4) ,即 size * size * 4 个 Q 值。每个状态都对应着四个动作的 Q 值,算法的目的就是通过不断的学习和更新这些 Q 值,找到从起始状态到目标状态的最优策略。
在 Q-learning 算法中, 经过不断的更新学习后,每个状态下的各个动作都有了对应的 Q 值。
当要确定最佳运行策略时,对于每个状态,我们会选择具有最大 Q 值的那个动作。因为最大的 Q 值意味着从这个状态执行该动作,在后续过程中能获得相对更多的累计奖励,也就是更优的选择。
从起始状态开始,不断按照每个状态下最大 Q 值对应的动作移动,最终形成的路径就是智能体在当前学习成果下找到的近似最佳运行策略。
模块导入
python
import numpy as np
导入numpy库,它是 Python 中用于科学计算的基础库,在代码中主要用于生成随机数以及数值计算。
迷宫环境类 MazeEnvironment
类初始化 __init__ 方法
python
class MazeEnvironment:def __init__(self, size=4):self.size = sizeself.state_space = [(i, j) for i in range(size) for j in range(size)]self.action_space = ['up', 'down', 'left', 'right']# 定义障碍物和目标位置self.obstacles = [(1, 2), (2, 1)] # 障碍物的位置self.goal = (size - 1, size - 1) # 终点# 初始状态设置为左上角self.start = (0, 0)self.reset()
- 功能:初始化迷宫环境的各种属性。
- 参数:
size:迷宫的大小,默认为 4x4 的迷宫。
- 属性说明:
size:迷宫的边长。state_space:一个列表,包含迷宫中所有可能的状态(位置),通过嵌套循环生成。action_space:一个列表,包含智能体可以采取的所有动作,即向上、向下、向左、向右移动。obstacles:一个列表,存储迷宫中障碍物的位置。goal:迷宫的终点位置,位于迷宫的右下角。start:迷宫的起点位置,位于迷宫的左上角。- 调用
reset方法将环境重置到初始状态。
重置环境 reset 方法
python
def reset(self):"""重置环境到初始状态"""self.current_state = self.startreturn self.current_state
- 功能:将环境的当前状态重置为起点位置,并返回该状态。
- 返回值:当前状态(起点位置)。
执行动作 step 方法
python
def step(self, action):"""执行一步操作,并返回下一状态、奖励以及是否完成标志"""row, col = self.current_stateif action == 'up': row -= 1elif action == 'down': row += 1elif action == 'left': col -= 1elif action == 'right':col += 1next_state = (row, col)# 检查边界条件if not (0 <= row < self.size and 0 <= col < self.size):next_state = self.current_state # 超出边界的移动无效reward = -1 # 默认每步都有负奖励鼓励快速达到目标done = Falseif next_state in self.obstacles:reward = -10 # 碰撞障碍物给予较大惩罚elif next_state == self.goal:reward = 10 # 达到目标给予正向奖励done = Trueself.current_state = next_statereturn next_state, reward, done
- 功能:根据智能体选择的动作,更新环境的状态,并返回下一状态、奖励和是否完成的标志。
- 参数:
action:智能体选择的动作,取值为'up'、'down'、'left'、'right'之一。
- 步骤说明:
- 根据动作更新当前位置的行和列。
- 检查更新后的位置是否超出迷宫边界,如果超出则将下一状态设置为当前状态。
- 初始化奖励为 -1,鼓励智能体尽快到达终点。
- 如果下一状态是障碍物,给予 -10 的惩罚;如果是终点,给予 10 的奖励并将完成标志设置为
True。 - 更新当前状态为下一状态,并返回下一状态、奖励和完成标志。
Q - learning 算法函数 q_learning
python
def q_learning(env, episodes=500, alpha=0.8, gamma=0.95, epsilon=0.1):# 初始化 Q 表q_table = {}for state in env.state_space:q_table[state] = {action: 0 for action in env.action_space}rewards_per_episode = []for episode in range(episodes):total_reward = 0current_state = env.reset()while True:# ε-greedy 策略选择动作if np.random.uniform(0, 1) < epsilon:action = np.random.choice(env.action_space) # 探索else:action = max(q_table[current_state], key=q_table[current_state].get) # 利用next_state, reward, done = env.step(action)# 更新 Q 值best_next_action = max(q_table[next_state], key=q_table[next_state].get)td_target = reward + gamma * q_table[next_state][best_next_action]td_error = td_target - q_table[current_state][action]q_table[current_state][action] += alpha * td_errortotal_reward += rewardcurrent_state = next_stateif done:breakrewards_per_episode.append(total_reward)return q_table, rewards_per_episode
- 功能:实现 Q - learning 算法,训练智能体在迷宫环境中找到最优策略。
- 参数:
env:迷宫环境实例。episodes:训练的回合数,默认为 500。alpha:学习率,控制 Q 值更新的步长,默认为 0.8。gamma:折扣因子,衡量未来奖励的重要性,默认为 0.95。epsilon:探索率,用于 ε - greedy 策略,默认为 0.1。
- 步骤说明:
- 初始化 Q 表:创建一个字典
q_table,键为状态,值为另一个字典,存储该状态下每个动作的 Q 值,初始值都为 0。 - 训练循环:进行
episodes个回合的训练。
- 在每个回合开始时,重置环境并初始化总奖励为 0。
- 使用 ε - greedy 策略选择动作:以
epsilon的概率随机选择动作(探索),以1 - epsilon的概率选择 Q 值最大的动作(利用)。 - 执行动作,获取下一状态、奖励和完成标志。
- 更新 Q 值:计算时间差分目标(TD target)和时间差分误差(TD error),并根据学习率更新当前状态 - 动作对的 Q 值。
- 累加总奖励,更新当前状态。
- 如果达到终点,结束当前回合。
- 返回结果:返回训练好的 Q 表和每个回合的总奖励列表。
- 初始化 Q 表:创建一个字典
测试智能体函数 test_agent
python
def test_agent(env, q_table):current_state = env.reset()path = [current_state]while True:action = max(q_table[current_state], key=q_table[current_state].get)next_state, _, done = env.step(action)path.append(next_state)if done:breakcurrent_state = next_statereturn path
- 功能:使用训练好的 Q 表测试智能体在迷宫中的导航能力,记录智能体走过的路径。
- 参数:
env:迷宫环境实例。q_table:训练好的 Q 表。
- 步骤说明:
- 重置环境并初始化路径列表,将起点添加到路径中。
- 在循环中,根据 Q 表选择 Q 值最大的动作。
- 执行动作,获取下一状态和完成标志,并将下一状态添加到路径中。
- 如果达到终点,结束循环。
- 返回智能体走过的路径。
主程序
python
# 创建环境实例并运行 Q-Learning
env = MazeEnvironment(size=4)
q_table, _ = q_learning(env)print("最终的 Q 表:")
for state, actions in q_table.items():print(f"{state}: {actions}")path = test_agent(env, q_table)
print("智能体走过的路径:", path)
- 功能:创建迷宫环境实例,调用
q_learning函数训练智能体,打印最终的 Q 表,然后调用test_agent函数测试智能体,并打印智能体走过的路径。
通过以上步骤,代码实现了智能体在迷宫环境中通过 Q - learning 算法学习最优策略,并利用该策略找到从起点到终点的路径。
完整代码
import numpy as npclass MazeEnvironment:def __init__(self, size=4):self.size = sizeself.state_space = [(i, j) for i in range(size) for j in range(size)]self.action_space = ['up', 'down', 'left', 'right']# 定义障碍物和目标位置self.obstacles = [(1, 2), (2, 1)] # 障碍物的位置self.goal = (size - 1, size - 1) # 终点# 初始状态设置为左上角self.start = (0, 0)self.reset()def reset(self):"""重置环境到初始状态"""self.current_state = self.startreturn self.current_statedef step(self, action):"""执行一步操作,并返回下一状态、奖励以及是否完成标志"""row, col = self.current_stateif action == 'up': row -= 1elif action == 'down': row += 1elif action == 'left': col -= 1elif action == 'right':col += 1next_state = (row, col)# 检查边界条件if not (0 <= row < self.size and 0 <= col < self.size):next_state = self.current_state # 超出边界的移动无效reward = -1 # 默认每步都有负奖励鼓励快速达到目标done = Falseif next_state in self.obstacles:reward = -10 # 碰撞障碍物给予较大惩罚elif next_state == self.goal:reward = 10 # 达到目标给予正向奖励done = Trueself.current_state = next_statereturn next_state, reward, donedef q_learning(env, episodes=500, alpha=0.8, gamma=0.95, epsilon=0.1):# 初始化 Q 表q_table = {}for state in env.state_space:q_table[state] = {action: 0 for action in env.action_space}rewards_per_episode = []for episode in range(episodes):total_reward = 0current_state = env.reset()while True:# ε-greedy 策略选择动作if np.random.uniform(0, 1) < epsilon:action = np.random.choice(env.action_space) # 探索else:action = max(q_table[current_state], key=q_table[current_state].get) # 利用next_state, reward, done = env.step(action)# 更新 Q 值best_next_action = max(q_table[next_state], key=q_table[next_state].get)td_target = reward + gamma * q_table[next_state][best_next_action]td_error = td_target - q_table[current_state][action]q_table[current_state][action] += alpha * td_errortotal_reward += rewardcurrent_state = next_stateif done:breakrewards_per_episode.append(total_reward)return q_table, rewards_per_episode# 创建环境实例并运行 Q-Learning
env = MazeEnvironment(size=4)
q_table, _ = q_learning(env)print("最终的 Q 表:")
for state, actions in q_table.items():print(f"{state}: {actions}")def test_agent(env, q_table):current_state = env.reset()path = [current_state]while True:action = max(q_table[current_state], key=q_table[current_state].get)next_state, _, done = env.step(action)path.append(next_state)if done:breakcurrent_state = next_statereturn pathpath = test_agent(env, q_table)
print("智能体走过的路径:", path)
相关文章:

基于 Q - learning 算法的迷宫导航
这段 Python 代码实现了一个基于 Q - learning 算法的迷宫导航系统。代码通过定义迷宫环境、实现 Q - learning 算法来训练智能体,使其能够在迷宫中找到从起点到终点的最优路径,同时利用训练好的 Q 表来测试智能体的导航能力。 在这个代码实现的迷宫环境…...

解决:AttributeError: module ‘cv2‘ has no attribute ‘COLOR_BGR2RGB‘
opencv AttributeError: module ‘cv2’ has no attribute ‘warpFrame’ 或者 opencv 没有 rgbd 解决上述问题的方法是: 卸载重装。 但是一定要卸载干净,仅仅卸载opencv-python是不行的。无限重复都报这个错。 使用pip list | grep opencv查看相关的…...
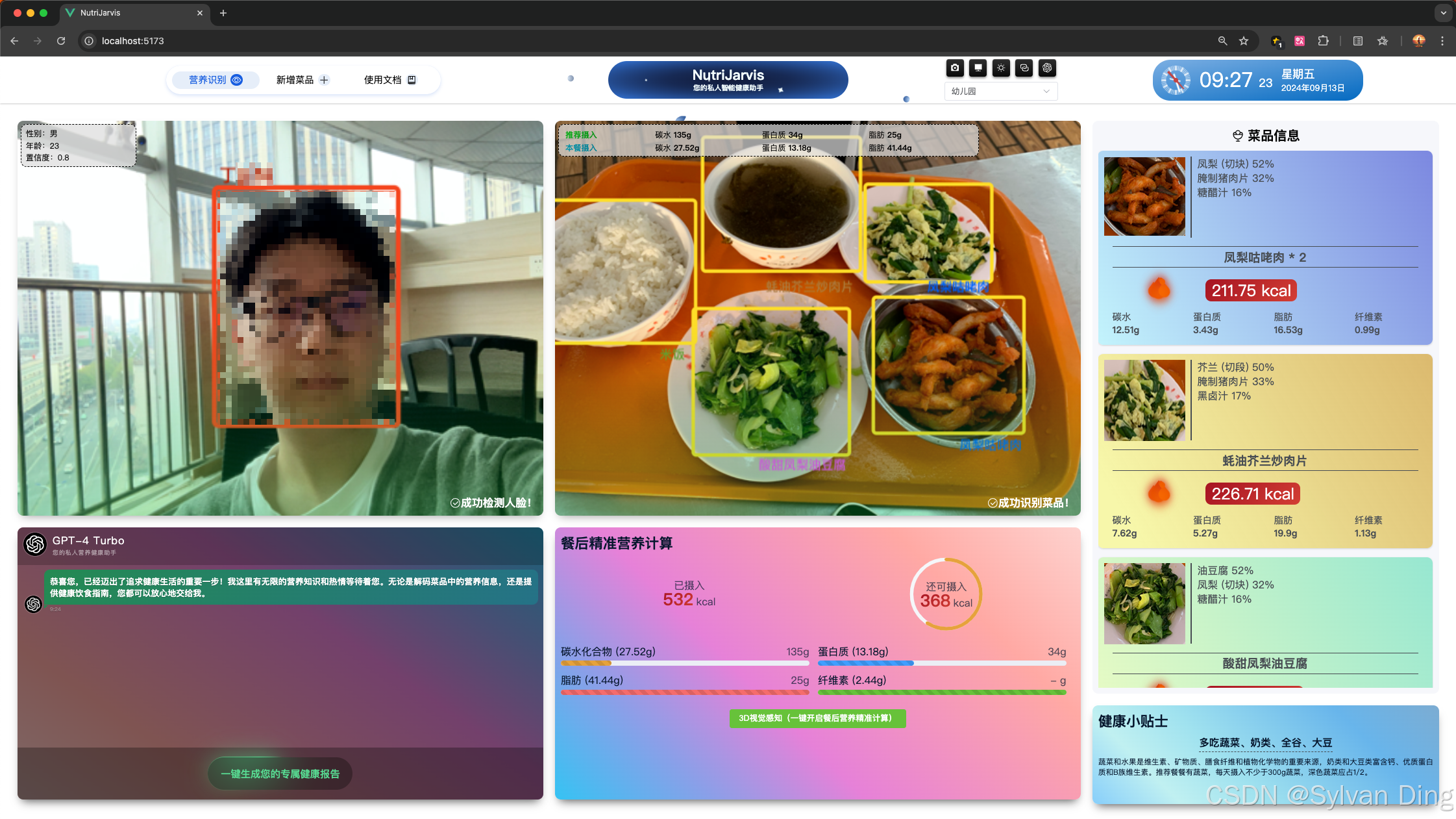
NutriJarvis:AI慧眼识餐,精准营养触手可及!—— 基于深度学习的菜品识别与营养计算系统
NutriJarvis:AI慧眼识餐,精准营养触手可及!—— 基于深度学习的菜品识别与营养计算系统 NutriJarvis 是一个基于深度学习的菜品识别与营养计算系统,旨在通过计算机视觉技术自动识别餐盘中的食物,并估算其营养成分&…...

作为一名java技术博主如何突围
作为一位Java开发和技术博主,想要在抖音上快速提升粉丝数量和视频播放量,可以结合以下策略进行优化: 1. 明确目标受众与技术方向 细分领域:技术领域广泛,可以专注于Java开发、算法、框架解析(如Spring Boo…...

【LaTeX】
基本使用 \documentclass 类型:文章(article)、报告(report)、书(book) 中文的文章是ctexart,中文字体是UTF8 \documentclass[UTF8]{ctexart} []说明可以省略不写的意思…...
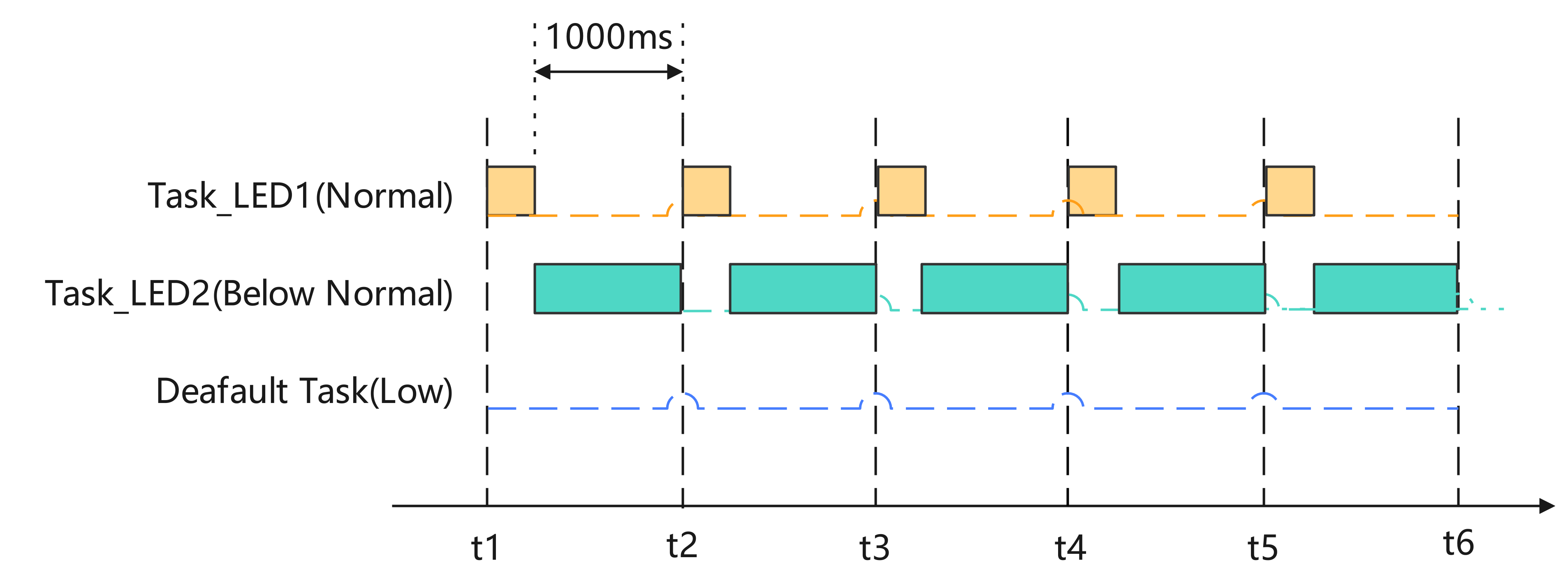
细说STM32单片机FreeRTOS任务管理相关函数及多任务编程的实现方法
目录 一、FreeRTOS任务管理相关函数 1、FreeRTOS函数 2、FreeRTOS宏函数 3、主要函数功能说明 (1)创建任务osThreadNew() (2)删除任务vTaskDelete() (3)挂起任务vTaskSuspend() (4&…...

uniapp微信小程序基于wu-input二次封装TInput组件(支持点击下拉选择、支持整数、电话、小数、身份证、小数点位数控制功能)
一、 最终效果 二、实现了功能 1、支持输入正整数---设置specifyTypeinteger 2、支持输入数字(含小数点)---设置specifyTypedecimal,可设置decimalLimit来调整小数点位数 3、支持输入手机号--设置specifyTypephone 4、支持输入身份证号---设…...
)
VLM-R1GRPO微调,强化学习训练, 实战训练教程(2)
https://www.dong-blog.fun/post/2013 VLM-R1GRPO微调, 实战训练教程(1): https://www.dong-blog.fun/post/1961 本博客这次使用多图进行GRPO。 官方git项目:https://github.com/om-ai-lab/VLM-R1?tabreadme-ov-f…...

系统弹出消息功能,且保证用户只能获取弹出一次消息
要实现系统弹出消息功能,且保证用户只能获取弹出一次消息,你可以借助 Redis 来达成。基本思路是:把消息存于 Redis 的列表中,同时用 Redis 的集合记录用户是否已接收过该消息。下面是一个示例工具类,其中包含推送消息和…...

Python代码解释
文章目录 代码解析执行过程等价写法其他类似操作 这段代码使用了 Python 的 map() 函数和 lambda 表达式来对列表中的每个元素进行平方运算。让我详细解释一下: 代码解析 numbers [1, 2, 3, 4] squared list(map(lambda x: x**2, numbers))numbers [1, 2, 3, …...

GPIO_ReadInputData和GPIO_ReadInputDataBit区别
目录 1、GPIO_ReadInputData: 2、GPIO_ReadInputDataBit: 总结 GPIO_ReadInputData 和 GPIO_ReadInputDataBit 是两个函数,通常用于读取微控制器GPIO(通用输入输出)引脚的输入状态,特别是在STM32系列微控制器中。它们之间的主要…...

MySQL数据库编程总结
MySQL数据库编程总结 一、数据库概述 数据库定义 • 数据库是管理数据的软件系统,用于高效存储、管理和检索数据,减少冗余。 • 核心功能:通过SQL语言定义、操作数据,维护完整性和安全性。 常见数据库 • MySQL、Oracle、SQL Ser…...
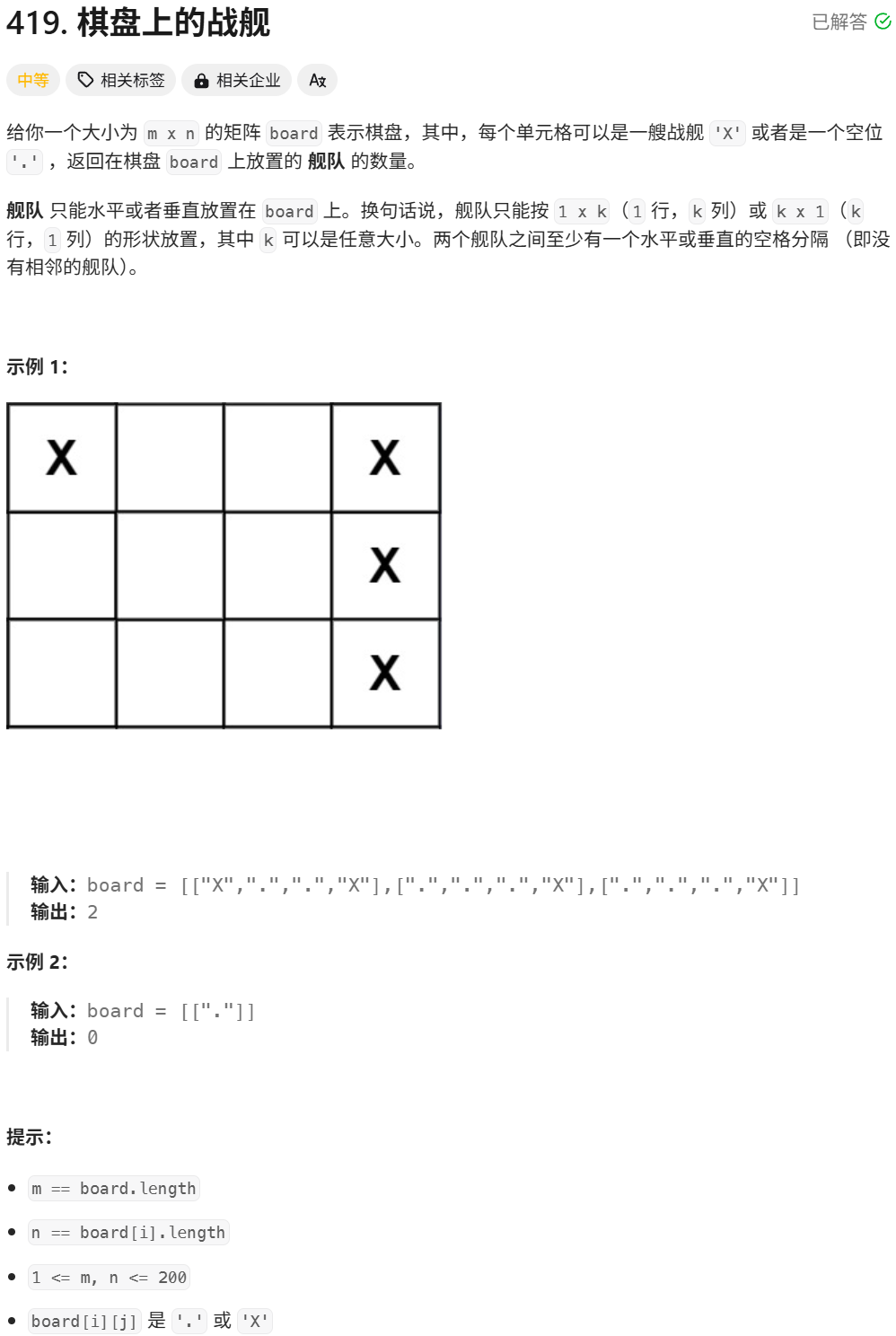
leetcode-419.棋盘上的战舰
leetcode-419.棋盘上的战舰 文章目录 leetcode-419.棋盘上的战舰一.题目描述二.第一次代码提交三.第二次代码提交 一.题目描述 二.第一次代码提交 class Solution { public:int countBattleships(vector<vector<char>>& board) {int m board.size(); //列数i…...
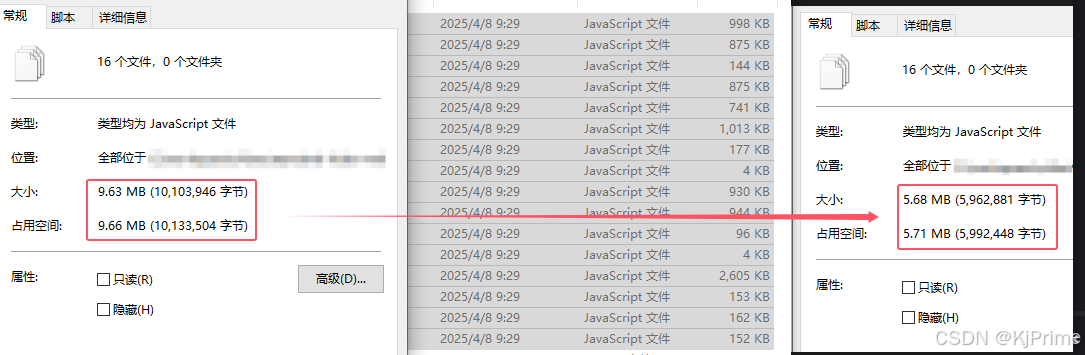
使用uglifyjs对静态引入的js文件进行压缩
前言 因为有时候js文件没有npm包,或者需要修改,只能引入静态的js,那么这个时候就可以对js进行压缩了。我其实想通过vite、webpack等插件进行压缩的,可是他都不能定位到public目录下面的文件,所以我只能自己压缩了。编…...

ecovadis评分要求,如何提高ecovadis分数,未来展望
EcoVadis评分要求、提升方法及未来展望 1. EcoVadis评分概述 EcoVadis是全球领先的企业可持续发展评级平台,评估企业在环境(E)、劳工与人权(L)、商业道德(B)、可持续采购(S&#x…...
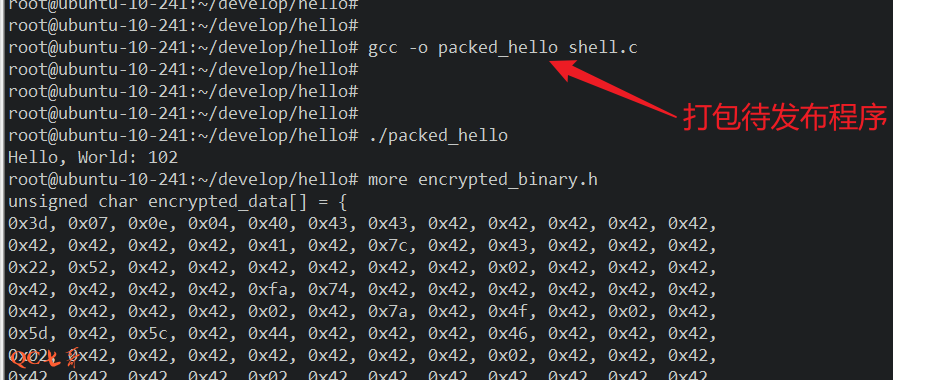
程序加壳脱壳原理和实现
理论 一个可运行的执行文件,至少会有一个代码段,程序的入口点指向代码段,程序运行的时候,从入口点开始执行代码段指令 为了将一个正常的程序进行加壳保护,至少要三部分逻辑配合 1、待加壳保护的程序 2、加壳逻辑 3…...
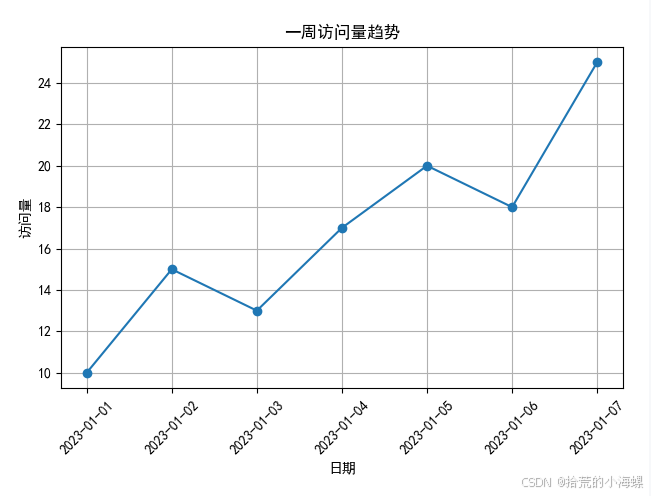
【数据分析实战】使用 Matplotlib 绘制折线图
1、简述 在日常的数据分析、科研报告、项目可视化展示中,折线图是一种非常常见且直观的数据可视化方式。本文将带你快速上手 Matplotlib,并通过几个实际例子掌握折线图的绘制方法。 Matplotlib 是 Python 中最常用的数据可视化库之一,它能够…...

数据仓库标准库模型架构相关概念浅讲
数据仓库与模型体系及相关概念 数据仓库与数据库的区别可参考:数据库与数据仓库的区别及关系_数据仓库和数据库-CSDN博客 总之,数据库是为捕获数据而设计,数据仓库是为分析数据而设计 数据仓库集成工具 在一些大厂中,其会有自…...
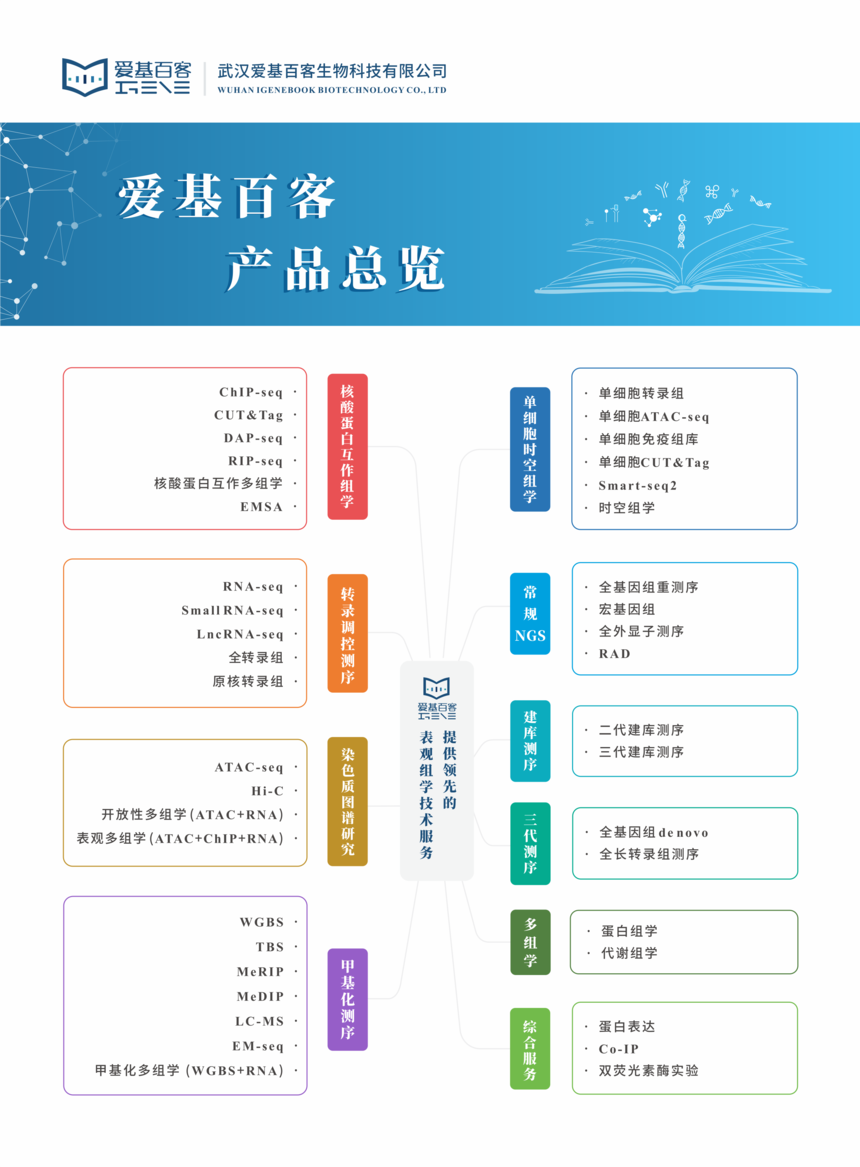
亚洲区域健康人群免疫细胞marker
最近发现一篇文献,作者来自新加坡基因研究所,这篇文章大概是整理了619个亚洲人群的免疫多样性图集(AIDA),跨越了7个国家,最终使用了1,265,624个免疫细胞的单细胞数据,并最终确定了8种主要的免疫…...

tree-sitter的grammar.js解惑
❓问题1:grammar.js 不是用正则表达式 /.../ 吗?为什么有 print 这样的字符串? ✅ 回答: grammar.js 分成两类“终结符”表示法: 表达方式含义xxx直接匹配该字符串字面量/regex/匹配符合正则的文本 💡 …...
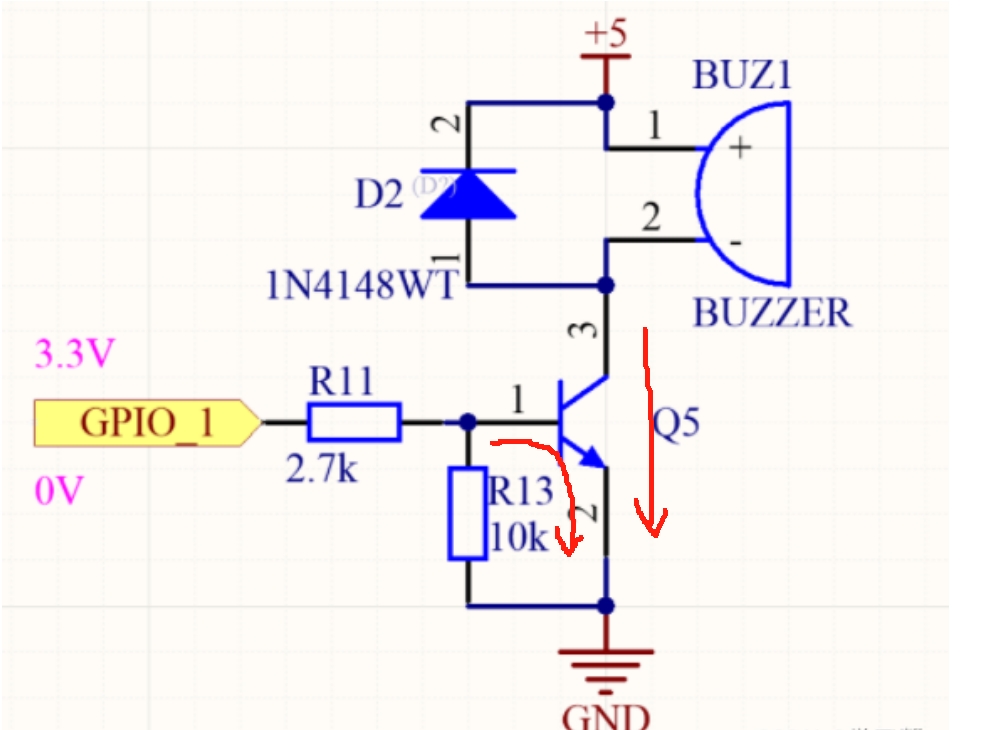
三极管以及mos管
三极管与mos管的高低电平导通判断 (1)三极管的高低电平导通判断 三极管中有2个PN结,分别称为发射结和集电极结,按材料划分为硅材料三极管(硅管),锗材料三极管(锗管)&am…...

第十七天 - Jenkins API集成 - 流水线自动化 - 练习:CI/CD流程优化
前言 在DevOps实践中,持续集成与持续交付(CI/CD)是现代软件工程的核心支柱。作为业界使用最广泛的自动化服务器,Jenkins凭借其强大的插件生态和灵活的流水线配置能力,成为企业级CI/CD落地的首选工具。本文将深入解析J…...

PPT模板之--个人简历
还在为制作 PPT 时毫无头绪、对着空白页面抓耳挠腮而烦恼吗?别担心,这里就是你的 PPT 灵感补给站!在这个快节奏的信息时代,一份吸睛又高效的 PPT 至关重要,它能在商务汇报中助你赢得先机,在课堂展示时让你脱…...
)
【远程工具】1.1 时间处理设计与实现(datetime库lib.rs)
一、设计原理与决策 时间单位选择 采用**秒(s)**作为基准单位,基于以下考虑: 国际单位制(SI)基本时间单位 整数秒(i64)方案优势: 精确无误差(相比浮点数&am…...

Nginx常用工具
Nginx常用工具 Nginx常用工具vscode配置Nginx插件在线生成Nginx配置文件Nginx可视化配置工具 Nginx常用工具 编写Nginx配置时,使用VSCodeNginx插件,能实现自动补全格式化配置. vscode配置Nginx插件 Nginx代码高亮插件: nginx-formatter Nginx代码格式化插件&#…...
之三)
应用安全系列之四十五:日志伪造(Log_Forging)之三
1、简介 针对Java的日志系统有多种,本文主要描述如何通过修改配置文件来解决logback和log4j的日志伪造问题。 2、logback 2.1、系统提供的解决方案 在logback.xml中配置编码器自动转义特殊字符: 复制 <configuration><appender name"C…...
springboot--页面的国际化
今天来实现页面中的国际化 首先,需要创建一个新的spring boot项目,导入前端模板,在我的博客中可以找到,然后将HTML文件放在templates包下,将其他的静态资源放在statics包下,如下图结构 页面的国际化主要在首…...

前端学习10—Ajax
1 AJAX 简介 AJAX 全称为 Asynchronous JavaScript And XML,就是异步的 JS 和 XML 通过 AJAX 可以在浏览器中向服务器发送异步请求,最大优势为:无刷新获取数据 AJAX 不是新的编程语言,而是一种将现有的标准组合在一起使用的新方…...

list的常见接口使用
今天,我们来讲解一下C关于STL标准库中的一个容器list的常见接口。 在我们之前c语言数据结构中,我们已经了解过了关于链表的知识点了,那么对于现在理解它也是相对来说比较容易的了。 数据结构--双向循环链表-CSDN博客 1. 定义与包含头文件 …...
一维差分数组
2.一维差分 - 蓝桥云课 问题描述 给定一个长度为 n 的序列 a。 再给定 m 组操作,每次操作给定 3 个正整数 l, r, d,表示对 a_{l} 到 a_{r} 中的所有数增加 d。 最终输出操作结束后的序列 a。 Update: 由于评测机过快,n, m 于 20…...