浅入浅出 GRPO in DeepSeekMath
GRPO in DeepSeekMath
GRPO 通过在生成组内进行比较来直接评估模型生成的响应,以优化策略模型,而不是训练单独的价值模型,这种方法显著降低了计算成本。GRPO 可以应用于任何可以确定响应正确性的可验证任务。例如,在数学推理中,可以通过将响应与基本事实进行比较来轻松验证响应的正确性。
The GRPO Algorithm
Step 1: Group Sampling
第一步是为每个问题生成多个可能的答案。这会产生一组可以相互比较的多样化输出。
- q q q : question
- G G G : group size
- π θ o l d \pi_{\theta_{old}} πθold : trained model(policy)
- { o 1 , o 2 , o 3 , . . . , o G ; π θ o l d } \{o_1, o_2, o_3, ... , o_G;\pi_{\theta_{old}}\} {o1,o2,o3,...,oG;πθold} : group outputs
Step 2: Advantage Calculation
一旦我们有多个响应(output),我们就需要一种方法来确定哪些响应比其他响应更好,这就是优势计算。
-
首先为每个响应输出分配一个奖励分数,可以使用奖励模型也可以使用奖励函数。例如:为每一个正确的输出分配一个奖励分数 1,错误的输出分配一个奖励 0。
-
优势计算:
A i = r i − mean ( { r 1 , r 2 , . . . , r G } ) std ( { r 1 , r 2 , . . . , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, ..., r_G\})}{\text{std}(\{r_1, r_2, ..., r_G\})} Ai=std({r1,r2,...,rG})ri−mean({r1,r2,...,rG})
Step 3: Policy Update
J G R P O ( θ ) = [ 1 G ∑ i = 1 G min ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) , 1 − ϵ , 1 + ϵ ) A i ) ] − β D K L ( π θ , π r e f ) J_{GRPO}(\theta) = \Big[\frac{1}{G}\sum_{i=1}^G \text{min}\Big(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i,\text{clip}\big(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon\big)A_i\Big)\Big] - \beta D_{KL}(\pi_{\theta},\pi_{ref}) JGRPO(θ)=[G1i=1∑Gmin(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ϵ,1+ϵ)Ai)]−βDKL(πθ,πref)
- π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} πθold(oi∣q)πθ(oi∣q) : Probability Ratio,比较了新模型的响应概率与旧模型的响应概率的差异程度,同时纳入了对改善预期结果的响应的偏好,这个比率使我们能够控制模型在每个步骤中的变化量。
- clip ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) , 1 − ϵ , 1 + ϵ ) \text{clip}\big(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon\big) clip(πθold(oi∣q)πθ(oi∣q),1−ϵ,1+ϵ) : Clip Function,将上述比率限制为[1−ε,1+ε][1−ε.1+ε]以避免剧烈的变化/更新,以及远离旧的模型。换句话说,它限制了概率比可以增加的程度,通过避免将新模型推得太远的更新来帮助保持稳定性。
- β D K L ( π θ , π r e f ) = ∑ x ∈ X P ( x ) log P ( x ) Q ( x ) \beta D_{KL}(\pi_{\theta},\pi_{ref}) = \sum_{x\in X} P(x)\text{log}\frac{P(x)}{Q(x)} βDKL(πθ,πref)=∑x∈XP(x)logQ(x)P(x) : KL Divergence,KL 散度被最小化,以防止模型在优化过程中偏离其原始行为太远。这有助于在根据奖励信号提高性能和保持连贯性之间取得平衡。在这种情况下,最小化 KL 散度可以降低模型生成无意义文本的风险,或者在数学推理的情况下,产生极其错误答案的风险。
- β \beta β : 控制 KL 散度约束的强度:
- higher β \beta β : 模型更新限制更多,模型的输出仍然接近参考模型分布,难以探索更好的响应。
- lower β \beta β : 更自由的更新,存在不稳定风险,生成无意义的输出,可能会出现
reward-hacking行为。 - Original β \beta β : 0.04(DeepSeekMath)
GRPO Example
问题: Q : Calculate 2 + 2 × 6 Q : \text{Calculate} 2 + 2 \times 6 Q:Calculate2+2×6, A = 14 A = 14 A=14
Step 1: Group Sampling
G = 8 G = 8 G=8 , O = { o 1 : 14 , o 2 : 13 , o 3 : 11 , o 4 : 14 , o 5 : 14 , o 6 : 15 , o 7 : 14 , o 8 : 10 } O = \{o_1:14, o_2:13, o_3:11, o_4:14, o_5:14, o_6:15, o_7:14, o_8:10\} O={o1:14,o2:13,o3:11,o4:14,o5:14,o6:15,o7:14,o8:10}
Step 2: Advantage Calculation
R = { r 1 = 1 , r 2 = 0 , r 3 = 0 , r 4 = 1 , r 5 = 1 , r 6 = 0 , r 7 = 1 , r 8 = 0 } R = \{r_1 = 1, r_2 = 0, r_3 = 0, r_4 = 1, r_5 = 1, r_6=0, r_7=1, r_8 =0 \} R={r1=1,r2=0,r3=0,r4=1,r5=1,r6=0,r7=1,r8=0}
| Statistic | Value |
|---|---|
| Group Average | m e a n ( r i ) = 0.5 mean(r_i)=0.5 mean(ri)=0.5 |
| Standard Deviation | s t d ( r i ) = 0.53 std(r_i)=0.53 std(ri)=0.53 |
| Advantage Value (Correct response) | A i = 1 − 0.5 0.53 = 0.94 A_i=\frac{1−0.5}{0.53}=0.94 Ai=0.531−0.5=0.94 |
| Advantage Value (Wrong response) | A i = 0 − 0.5 0.53 = − 0.94 A_i=\frac{0−0.5}{0.53}=−0.94 Ai=0.530−0.5=−0.94 |
Step 3: Policy Update
假设: π θ o l d = 0.5 \pi_{\theta_{old}} = 0.5 πθold=0.5, π θ = 0.7 \pi_\theta = 0.7 πθ=0.7 , ϵ = 0.2 \epsilon = 0.2 ϵ=0.2
Probability Ratio = 0.7 0.5 = 1.4 after Clip → 1.2 \text{Probability Ratio} = \frac{0.7}{0.5} = 1.4 \text{ after Clip } \to 1.2 Probability Ratio=0.50.7=1.4 after Clip →1.2
Summary
GRPO对于数学推理任务特别强大,因为在数学推理任务中,正确性可以得到客观验证。与需要单独奖励:模型的传统 RLHF 方法相比,GRPO 方法允许更高效的训练。
- GRPO 比较一组内的多个输出,以确定哪些输出比其他输出更好,而无需单独的价值模型。
- 优势计算对奖励进行标准化,以确定哪些响应高于或低于平均水平。
- 策略更新使用带有 KL 发散惩罚的裁剪目标函数来确保稳定学习。
相关文章:

浅入浅出 GRPO in DeepSeekMath
GRPO in DeepSeekMath GRPO 通过在生成组内进行比较来直接评估模型生成的响应,以优化策略模型,而不是训练单独的价值模型,这种方法显著降低了计算成本。GRPO 可以应用于任何可以确定响应正确性的可验证任务。例如,在数学推理中&a…...

计算机网络起源
互联网的起源和发展是一个充满创新、突破和变革的历程,从20世纪60年代到1989年,这段时期为互联网的诞生和普及奠定了坚实的基础。让我们详细回顾这一段激动人心的历史。 计算机的发展与ARPANET的建立(20世纪60年代) 互联网的诞生…...
 与 <iframe> 的优缺点及使用场景和方式)
HTML 嵌入标签对比:小众(<embed>、<object>) 与 <iframe> 的优缺点及使用场景和方式
需求背景 在网页开发中,嵌入外部资源预览(如视频、PDF、地图或其他网页)是常见的需求。HTML 提供了多种标签来实现这一功能,其中 <embed>、<object> 和 <iframe> 是最常用的三种。本文将对比它们的优缺点&…...

[python] 作用域
Python中查找变量的顺序遵循LEGB规则(Local->Enclosing->Global->Built-in)。Python中的if/elif/else、for/while等代码块不会创建新的作用域,只有def、class、lambda才会改变作用域。这和C中不同,C中在{}代码块中创建的变量离开这个代码块后就…...

AICon 2024年全球人工智能与大模型开发与应用大会(脱敏)PPT汇总(36份).zip
AICon 2024年全球人工智能与大模型开发与应用大会(脱敏)PPT汇总(36份).zip 1、面向开放域的大模型智能体.pdf 2、企业一站式 AI 智能体构建平台演进实践.pdf 3、PPIO 模型平台出海实战,跨地域业务扩展中的技术优化之道…...
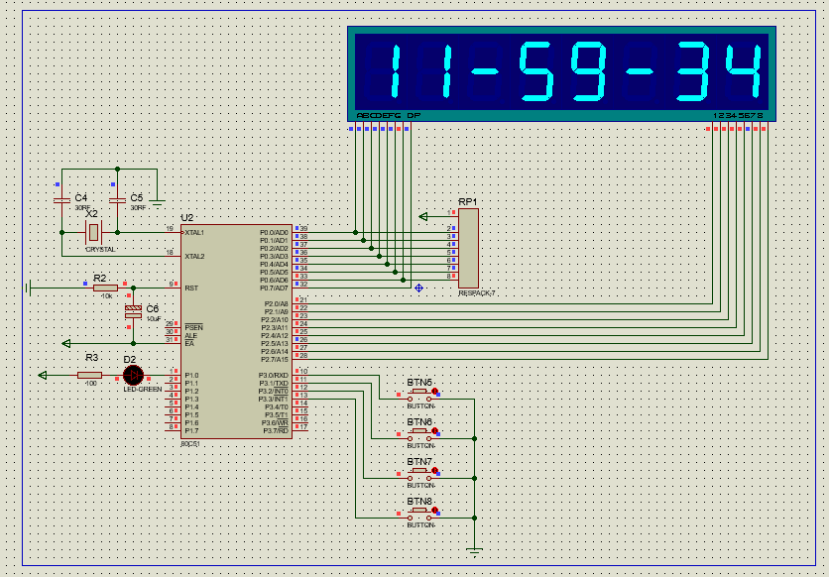
51电子表
设计要求: 基本任务: 用单片机和数码管设计可调式电子钟,采用24小时制计时方式,要求能够稳定准确计时,并能调整时间。发光二极管每秒亮灭一次。电子钟显示格式为:时、分、秒各两位,中间有分隔…...
9-函数的定义及用法
一.前言 C 语⾔强调模块化编程,这⾥所说的模块就是函数,即把每⼀个独⽴的功能均抽象为⼀个函数来实现。从⼀定意义上讲,C 语⾔就是由⼀系列函数串组成的。 我们之前把所有代码都写在 main 函数中,这样虽然程序的功能正常实现&…...

高清视频会议系统BeeWorks Meet,支持私有化部署
在数字化办公时代,视频会议已成为企业协作的关键工具。然而,随着信息安全意识的不断提高,传统的公有云视频会议软件已难以满足企业对数据安全和隐私保护的严格要求。BeeWorks Meet凭借其独特的私有化部署模式、强大的功能集成以及对国产化的适…...

用HTML和CSS绘制佩奇:我不是佩奇
在这篇博客中,我将解析一个完全使用HTML和CSS绘制的佩奇(Pig)形象。这个项目展示了CSS的强大能力,仅用样式就能创造出复杂的图形,而不需要任何图片或JavaScript。 项目概述 这个名为"我不是佩奇"的项目是一个纯CSS绘制的卡通猪形象…...
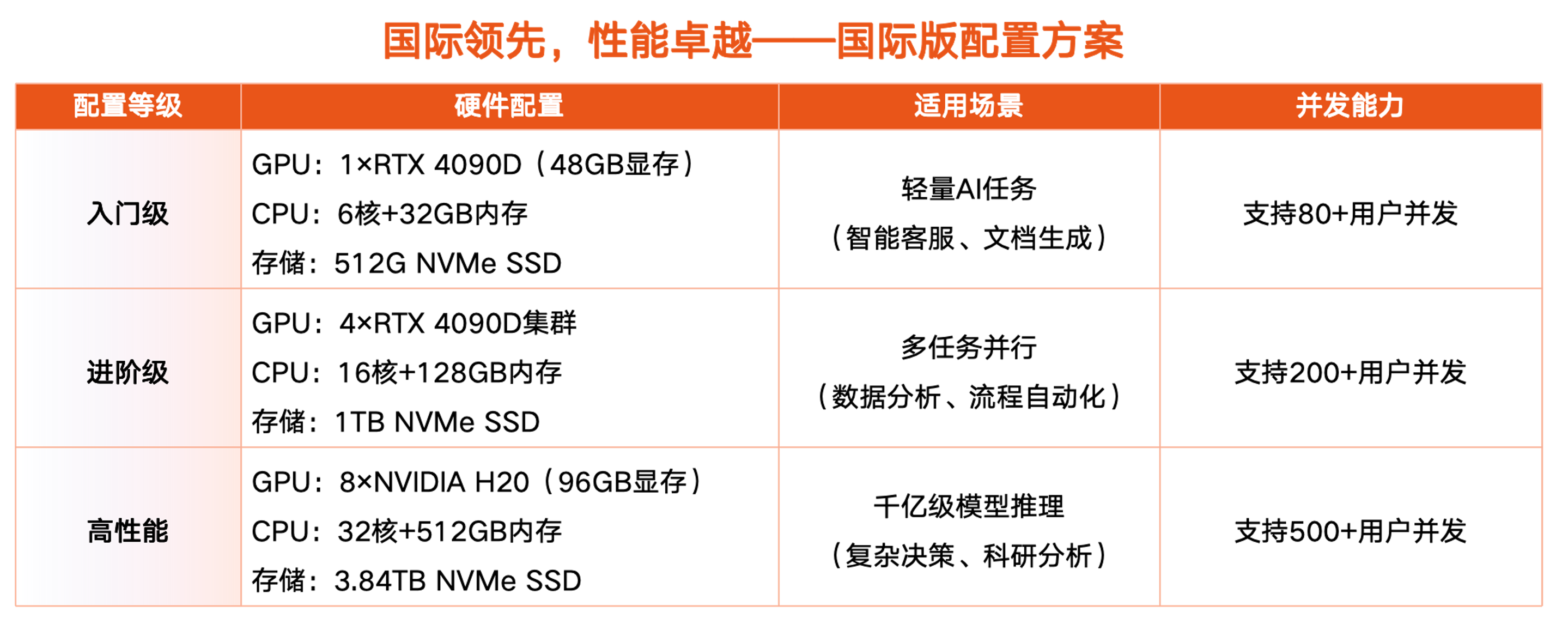
彩讯携Rich AICloud与一体机智算解决方案亮相中国移动云智算大会
2025年4月10日,2025中国移动云智算大会在苏州盛大开幕,本次大会以“由云向智 共绘算网新生态”为主题,与会嘉宾围绕算力展开重点探讨。 大会现场特设区域展出各参会单位的最新算力成果,作为中国移动重要合作伙伴,彩讯…...
BERT - 直接调用transformers.BertModel, BertTokenizerAPI不进行任何微调
本节代码将使用 transformers 库加载预训练的BERT模型和分词器(Tokenizer),并处理文本输入。 1. 加载预训练模型和分词器 from transformers import BertTokenizer, BertModelmodel_path "/Users/azen/Desktop/llm/models/bert-base-…...

安卓开发提示Android Gradle plugin错误
The project is using an incompatible version (AGP 8.9.1) of the Android Gradle plugin. Latest supported version is AGP 8.8.0-alpha05 See Android Studio & AGP compatibility options. 改模块级 build.gradle(如果有独立配置):…...

声学测温度原理解释
已知声速,就可以得到温度。 不同温度下的胜诉不同。 25度的声速大约346m/s 绝对温度-273度 不同温度下的声速。 FPGA 通过测距雷达测温度,固定测量距离,或者可以测出当前距离。已知距离,然后雷达发出声波到接收到回波的时间&a…...

Cuto壁纸 2.6.9 | 解锁所有高清精选壁纸,无广告干扰
Cuto壁纸 App 提供丰富多样的壁纸选择,涵盖动物、风景、创意及游戏动漫等类型。支持分类查找与下载,用户可轻松将心仪壁纸设为手机背景,并享受软件内置的编辑功能调整尺寸。每天更新,确保用户总能找到新鲜、满意的壁纸。 大小&am…...

C语言 AI 通义灵码 VSCode插件安装与功能详解
在 C 语言开发领域,一款高效的编码助手能够显著提升开发效率和代码质量。 通义灵码,作为阿里云技术团队打造的智能编码助手,凭借其强大的功能,正逐渐成为 C 语言开发者的新宠。 本文将深入探讨通义灵码在 C 语言开发中的应用&am…...

二分查找5:852. 山脉数组的峰顶索引
链接:852. 山脉数组的峰顶索引 - 力扣(LeetCode) 题解: 事实证明,二分查找不局限于有序数组,非有序的数组也同样适用 二分查找主要思想在于二段性,即将数组分为两段。本体就可以将数组分为ar…...

1.2 测试设计阶段:打造高质量的测试用例
测试设计阶段:打造高质量的测试用例 摘要 本文详细介绍了软件测试流程中的测试设计阶段,包括测试用例设计、测试数据准备、测试环境搭建和测试方案设计等内容。通过本文,读者可以系统性地了解测试设计的方法和技巧,掌握如何高效…...

【模拟电路】稳压二极管/齐纳二极管
齐纳二极管也被称为稳压二极管,是一种特殊的二极管,其工作原理是利用PN结的反向击穿状态。在齐纳二极管中,当反向电压增加到一定程度,即达到齐纳二极管的击穿电压时,反向电流会急剧增加,但此时齐纳二极管的电压却基本保持不变。这种特性使得齐纳二极管可以作为稳压器或电…...
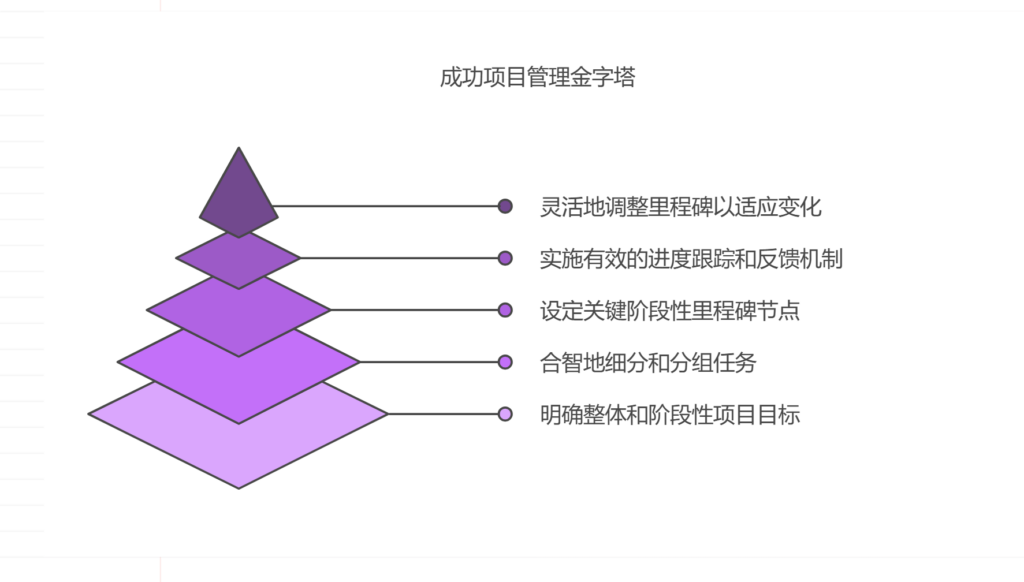
项目周期过长,如何拆分里程碑
应对项目周期过长,合理拆分里程碑需要做到:明确项目整体目标与阶段目标、合理进行任务细分与分组、设定阶段性里程碑节点、实施有效的进度跟踪与反馈机制、灵活进行里程碑调整。其中,明确项目整体目标与阶段目标尤为关键。这能够帮助团队在长…...
)
Java基础 - 泛型(常见用法)
文章目录 泛型类泛型方法泛型类派生子类示例 1:子类固定父类泛型类型(StringBox 继承自 Box<String>)示例 2:子类保留父类泛型类型(AdvancedBox<T> 继承自 Box<T>)示例 3:添加子类自己的…...

蓝桥杯刷题总结 + 应赛技巧
当各位小伙伴们看到这篇文章的时候想必蓝桥杯也快开赛了,那么本篇文章博主就来总结一下一些蓝桥杯的应赛技巧,那么依旧先来走个流程 那么接下来我们分成几个板块进行总结 首先是一些基本语法 编程语言的基本语法 首先是数组,在存数据的时候…...

希哈表的学习
#include <stdio.h> #include <stdlib.h> #include "uthash.h"typedef struct {int id; // 学号,作为keychar name[20]; // 姓名,作为valueUT_hash_handle hh; // 必须有这个字段 } Student;Student* studen…...
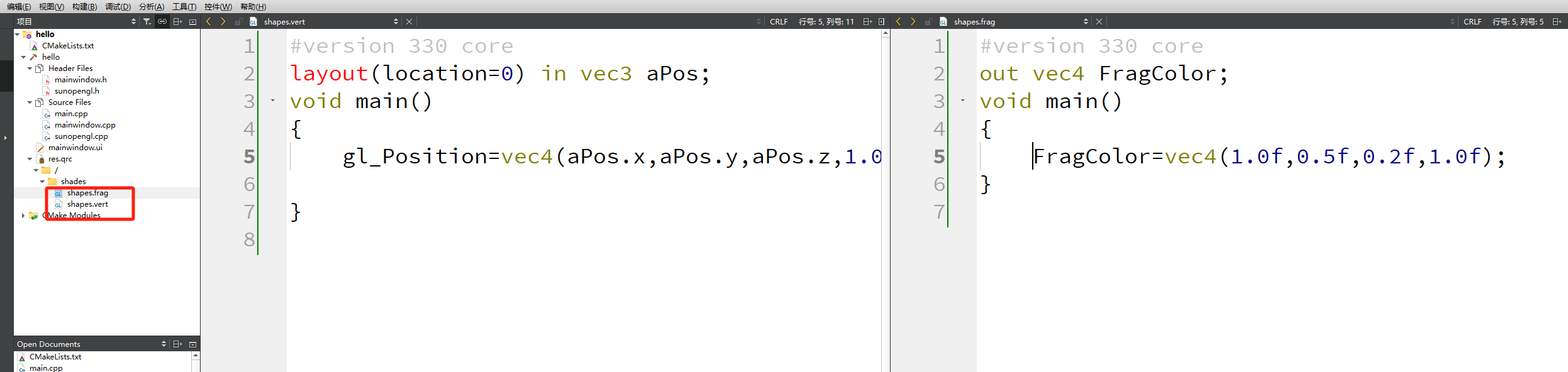
Qt之OpenGL使用Qt封装好的着色器和编译器
代码 #include "sunopengl.h"sunOpengl::sunOpengl(QWidget *parent) {}unsigned int VBO,VAO; float vertices[]{0.5f,0.5f,0.0f,0.5f,-0.5f,0.0f,-0.5f,-0.5f,0.0f,-0.5f,0.5f,0.0f };unsigned int indices[]{0,1,3,1,2,3, }; unsigned int EBO; sunOpengl::~sunO…...

备赛蓝桥杯-Python-考前突击
额,,离蓝桥杯开赛还有十个小时,最近因为考研复习节奏的问题,把蓝桥杯的优先级后置了,突然才想起来还有一个蓝桥杯呢。。 到目前为止python基本语法熟练了,再补充一些常用函数供明天考前再背背,算…...
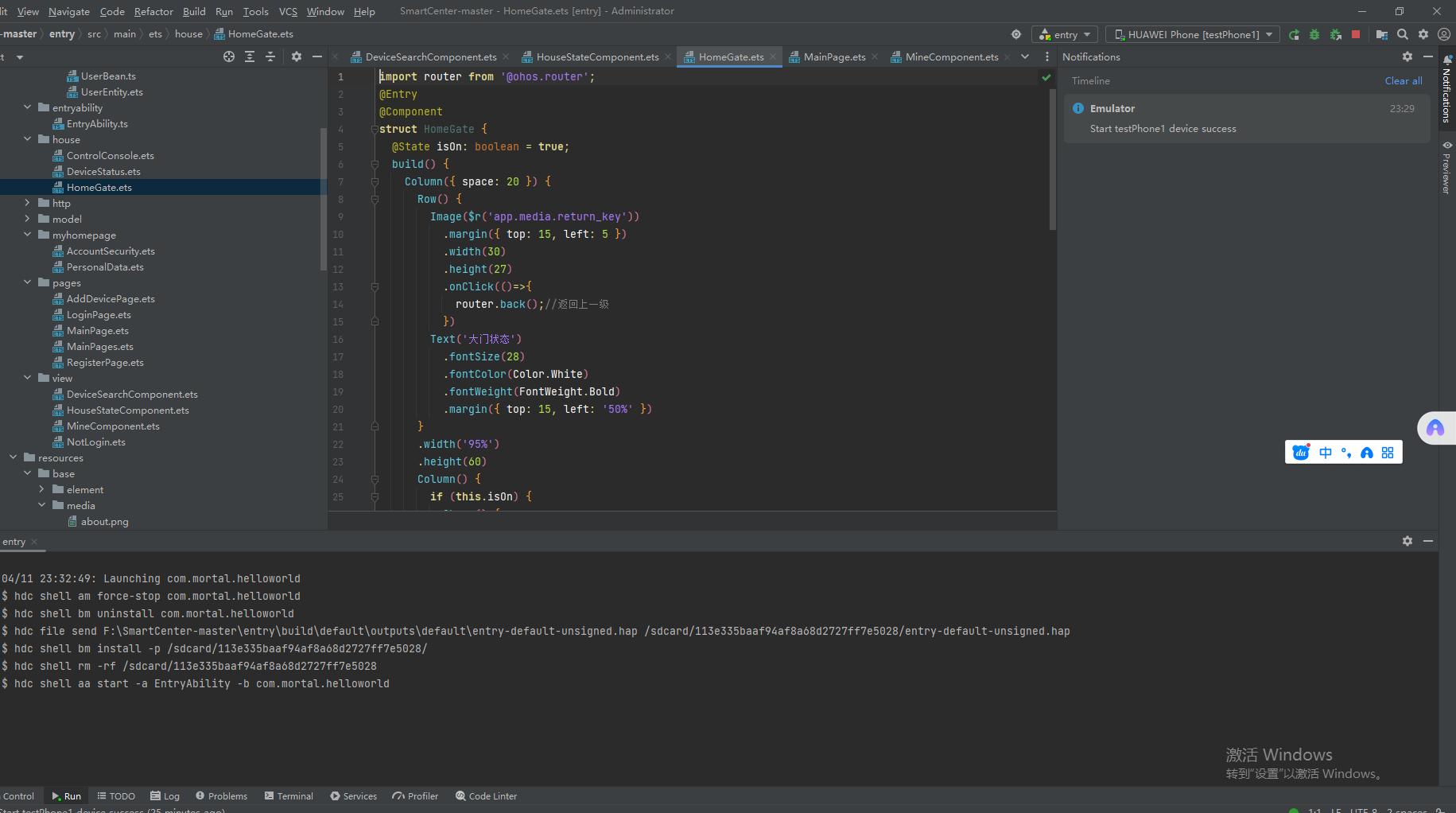
零基础开始学习鸿蒙开发-智能家居APP离线版介绍
目录 1.我的小屋 2.查找设备 3.个人主页 前言 好久不发博文了,最近都忙于面试,忙于找工作,这段时间终于找到工作了。我对鸿蒙开发的激情依然没有减退,前几天做了一个鸿蒙的APP,现在给大家分享一下! 具体…...
不再卡顿!如何根据使用需求挑选合适的电脑内存?
电脑运行内存多大合适?在选购或升级电脑时,除了关注处理器的速度、硬盘的容量之外,内存(RAM)的大小也是决定电脑性能的一个重要因素。但究竟电脑运行内存多大才合适呢?这篇文章将帮助你理解不同使用场景下适…...
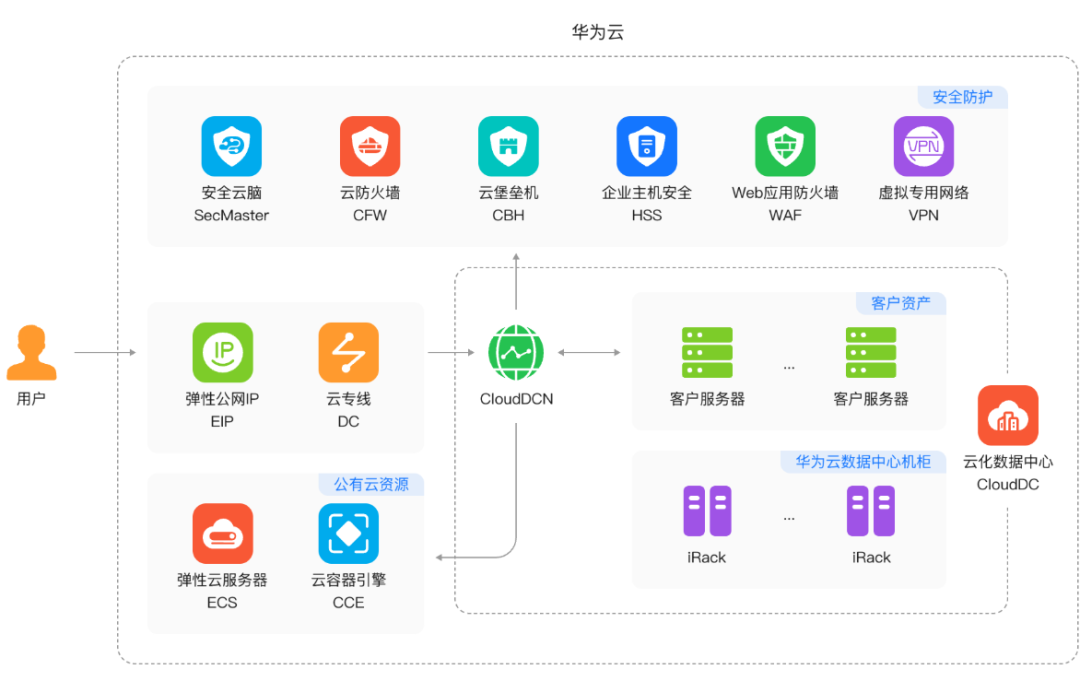
华为云 云化数据中心 CloudDC | 架构分析与应用场景
云化数据中心 CloudDC 云化数据中心 (CloudDC)是一种满足传统DC客户云化转型诉求的产品,支持将客户持有服务器设备部署至华为云机房,通过外溢华为云的基础设施管理、云化网络、裸机纳管、确定性运维等能力,帮助客户DC快速云化转型。 云化数据…...

【射频仿真学习笔记】变压器参数的Mathematica计算以及ADS仿真建模
变压器模型理论分析 对于任意的无源电路或者等效电路,当画完原理图后,能否认为已经知道其中的两个节点?vin和vout之间的明确解析解 是否存在一个通用的算法,将这里的所有元素都变成了符号,使得这个算法本身就是一个函…...
Linux系统Docker部署开源在线协作笔记Trilium Notes与远程访问详细教程
今天和大家分享一款在 G 站获得了 26K的强大的开源在线协作笔记软件,Trilium Notes 的中文版如何在 Linux 环境使用 docker 本地部署,并结合 cpolar 内网穿透工具配置公网地址,轻松实现远程在线协作的详细教程。 Trilium Notes 是…...

C++基础精讲-01
1C概述 1.1初识C 发展历程: C 由本贾尼・斯特劳斯特卢普在 20 世纪 70 年代开发,它在 C 语言的基础上增加了面向对象编程的特性,最初被称为 “C with Classes”,后来逐渐发展成为独立的 C 语言。 语言特点 (1&#x…...