力扣DAY46-50 | 热100 | 二叉树:展开为链表、pre+inorder构建、路径总和、最近公共祖先、最大路径和
前言
中等 、困难 √,越来越有手感了,二叉树done!
二叉树展开为链表
我的题解
前序遍历树,当遇到左子树为空时,栈里pop节点,取右子树接到左子树位置,同时断开该右子树与父节点的连接,直至整个树被遍历完。注意,由于要求展开的单链表向右,最后要把所有的左指针改为右指针。
class Solution {
public:void flatten(TreeNode* root) {TreeNode* node = root;stack<TreeNode*> stk;TreeNode* leaf;TreeNode* rmright;while(node || !stk.empty()){if (node && node != root) leaf->left = node;while (node){stk.push(node);leaf = node;node = node->left;}node = stk.top();rmright = node;stk.pop();node = node->right;rmright->right = nullptr;}node = root;while(node){node->right = node->left;node->left = nullptr;node = node->right;}}
};官解
前序遍历
将二叉树展开为单链表之后,单链表中的节点顺序即为二叉树的前序遍历访问各节点的顺序。因此,可以对二叉树进行前序遍历,获得各节点被访问到的顺序。由于将二叉树展开为链表之后会破坏二叉树的结构,因此在前序遍历结束之后更新每个节点的左右子节点的信息,将二叉树展开为单链表。
对二叉树的前序遍历不熟悉的读者请自行练习「144. 二叉树的前序遍历」。
前序遍历可以通过递归或者迭代的方式实现。以下代码通过递归实现前序遍历。
class Solution {
public:void flatten(TreeNode* root) {vector<TreeNode*> l;preorderTraversal(root, l);int n = l.size();for (int i = 1; i < n; i++) {TreeNode *prev = l.at(i - 1), *curr = l.at(i);prev->left = nullptr;prev->right = curr;}}void preorderTraversal(TreeNode* root, vector<TreeNode*> &l) {if (root != NULL) {l.push_back(root);preorderTraversal(root->left, l);preorderTraversal(root->right, l);}}
};前序遍历和展开同步进行
使用方法一的前序遍历,由于将节点展开之后会破坏二叉树的结构而丢失子节点的信息,因此前序遍历和展开为单链表分成了两步。能不能在不丢失子节点的信息的情况下,将前序遍历和展开为单链表同时进行?
之所以会在破坏二叉树的结构之后丢失子节点的信息,是因为在对左子树进行遍历时,没有存储右子节点的信息,在遍历完左子树之后才获得右子节点的信息。只要对前序遍历进行修改,在遍历左子树之前就获得左右子节点的信息,并存入栈内,子节点的信息就不会丢失,就可以将前序遍历和展开为单链表同时进行。
该做法不适用于递归实现的前序遍历,只适用于迭代实现的前序遍历。修改后的前序遍历的具体做法是,每次从栈内弹出一个节点作为当前访问的节点,获得该节点的子节点,如果子节点不为空,则依次将右子节点和左子节点压入栈内(注意入栈顺序)。
展开为单链表的做法是,维护上一个访问的节点 prev,每次访问一个节点时,令当前访问的节点为 curr,将 prev 的左子节点设为 null 以及将 prev 的右子节点设为 curr,然后将 curr 赋值给 prev,进入下一个节点的访问,直到遍历结束。需要注意的是,初始时 prev 为 null,只有在 prev 不为 null 时才能对 prev 的左右子节点进行更新。
class Solution {
public:void flatten(TreeNode* root) {if (root == nullptr) {return;}auto stk = stack<TreeNode*>();stk.push(root);TreeNode *prev = nullptr;while (!stk.empty()) {TreeNode *curr = stk.top(); stk.pop();if (prev != nullptr) {prev->left = nullptr;prev->right = curr;}TreeNode *left = curr->left, *right = curr->right;if (right != nullptr) {stk.push(right);}if (left != nullptr) {stk.push(left);}prev = curr;}}
};寻找前驱节点
前两种方法都借助前序遍历,前序遍历过程中需要使用栈存储节点。有没有空间复杂度是 O(1) 的做法呢?
注意到前序遍历访问各节点的顺序是根节点、左子树、右子树。如果一个节点的左子节点为空,则该节点不需要进行展开操作。如果一个节点的左子节点不为空,则该节点的左子树中的最后一个节点被访问之后,该节点的右子节点被访问。该节点的左子树中最后一个被访问的节点是左子树中的最右边的节点,也是该节点的前驱节点。因此,问题转化成寻找当前节点的前驱节点。
具体做法是,对于当前节点,如果其左子节点不为空,则在其左子树中找到最右边的节点,作为前驱节点,将当前节点的右子节点赋给前驱节点的右子节点,然后将当前节点的左子节点赋给当前节点的右子节点,并将当前节点的左子节点设为空。对当前节点处理结束后,继续处理链表中的下一个节点,直到所有节点都处理结束。
class Solution {
public:void flatten(TreeNode* root) {TreeNode *curr = root;while (curr != nullptr) {if (curr->left != nullptr) {auto next = curr->left;auto predecessor = next;while (predecessor->right != nullptr) {predecessor = predecessor->right;}predecessor->right = curr->right;curr->left = nullptr;curr->right = next;}curr = curr->right;}}
};心得
我属于方法二,一边前序遍历一边展开,但是展开方向错了,应该向右展开而不是左边。具体方法是记录当前节点curr和前置节点pre,并把pre的左指针置空,右指针置为cur。方法一太简单粗暴不赘叙了,就是按照前序遍历的顺序把节点存入容器再重新定义左右指针。方法三挺有意思,寻找右子树节点的前驱节点,是左子树的右节点。“该节点的左子树中的最后一个节点被访问之后,该节点的右子节点被访问”。找到该节点后,把当前节点的右子树接到前驱节点的右指针上,然后把当前节点的左子树接到右指针上。如此循环遍历整个链表。这个做法无需栈来存储树,且优雅十分。
从前序和中序遍历构造二叉树
我的题解
前序遍历:先遍历根节点。中序遍历:根节点左边是左子树,右边是右子树。知道这两个特征之后就可以用递归实现。首先定义哈希表存储所有节点在中序遍历中的index。接着重点是边界判断,我们通过当前节点与中序数组左边界的距离得出前序数组的左子树的右边界,与中序数组右边界的距离得出前序数组右子树距离的有边界。共更新八个边界。
class Solution {
public:unordered_map<int, int> index;TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder, int pl, int pr, int il, int ir){int val = preorder[pl];TreeNode* root = new TreeNode(val);if (pl+1 <= pl+(index[val]-il))root->left = buildTree(preorder, inorder, pl+1, pl+(index[val]-il), il, index[val]-1);if ( pl+(index[val]-il)+1 <= pr)root->right = buildTree(preorder, inorder, pl+(index[val]-il)+1, pr, index[val]+1, ir);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if (preorder.empty())return nullptr;for (int i = 0; i < inorder.size(); i++){index[inorder[i]] = i; }return buildTree(preorder, inorder, 0, preorder.size()-1, 0, inorder.size()-1);}
};官解
递归与笔者思路一致,迭代太麻烦了,略过。
心得
这个题想了超级久,大致的思路都能想到,最后是没想到要更新那么多边界值(传参数量),所以卡着一直没写出来。(瞄了一眼参数之后)很快就做完了。刚开始也想过用迭代的做法,总有案例不过,原因是只考虑了个例不具有通用性。教训是要相信自己的思路,不要怕麻烦,而且要学会如何设计参数,不要怕多,只要逻辑够清晰,是很容易的。
路径总和Ⅲ
我的题解
用哈希表+前缀和+递归解答此题,哈希表存前缀和,键为前缀和,值为出现次数。每次递归往下,只会父节点到叶子节点,所以传递的哈希表只有父节点的前缀和。依据 前缀和+当前节点-target = 某个前缀和 的关系,更新ans,最后更新哈希表,遍历左右节点。
class Solution {
public:int ans = 0;void findpath(unordered_map<long long, int> premap, TreeNode* node, int target, long long presum){presum = node->val + presum;auto it = premap.find(presum - target);if (it != premap.end())ans += it->second;premap[presum]++;if (node->left) findpath(premap, node->left, target, presum);if (node->right) findpath(premap, node->right, target, presum);}int pathSum(TreeNode* root, int targetSum) {unordered_map<long long, int> premap;premap[0]++;if (root) findpath(premap, root, targetSum, 0);return ans;}
};官解
深度优先搜索是穷举所有路径,复杂度On2,不可取。
前缀和
我们仔细思考一下,解法一中应该存在许多重复计算。我们定义节点的前缀和为:由根结点到当前结点的路径上所有节点的和。我们利用先序遍历二叉树,记录下根节点 root 到当前节点 p 的路径上除当前节点以外所有节点的前缀和,在已保存的路径前缀和中查找是否存在前缀和刚好等于当前节点到根节点的前缀和 curr 减去 targetSum。
class Solution {
public:unordered_map<long long, int> prefix;int dfs(TreeNode *root, long long curr, int targetSum) {if (!root) {return 0;}int ret = 0;curr += root->val;if (prefix.count(curr - targetSum)) {ret = prefix[curr - targetSum];}prefix[curr]++;ret += dfs(root->left, curr, targetSum);ret += dfs(root->right, curr, targetSum);prefix[curr]--;return ret;}int pathSum(TreeNode* root, int targetSum) {prefix[0] = 1;return dfs(root, 0, targetSum);}
};心得
官解和笔者思路很相似,不同之处在于笔者把哈希表作为递归参数传递,而官解把前缀和哈希表定义为公共变量。关键之处在于,递归子节点前,对哈希表进行更新操作prefix[curr]++;,递归完对哈希表进行复原prefix[curr]--;另外,这道题思路来源于之前几乎一眼的题目,寻找连续数组和等于k的个数,日积月累中,我也会举一反三了~
二叉树的最近公共祖先
我的题解
这道题同样是递归完成,首先判断当前节点是不是目标节点,再判断左右节点是不是目标节点,如果当前/左/右节点=目标节点任意一个为真,返回真,当前/左/右任意两个节点为真,则当前节点为题解。
class Solution {
public:TreeNode* ans = new TreeNode();bool find(TreeNode* node, TreeNode* p, TreeNode* q){bool itb = false, lb = false, rb = false;if (!node) return false;if (node == p || node == q)itb = true;lb = find(node->left, p, q);rb = find(node->right, p, q);if ((itb && lb) || (itb && rb) || (lb && rb))ans = node;return (itb || lb || rb);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {if (find(root, p, q))return ans;return nullptr;}
};官解
递归与笔者思路一致,不赘叙。
存储父节点
我们可以用哈希表存储所有节点的父节点,然后我们就可以利用节点的父节点信息从 p 结点开始不断往上跳,并记录已经访问过的节点,再从 q 节点开始不断往上跳,如果碰到已经访问过的节点,那么这个节点就是我们要找的最近公共祖先。
从根节点开始遍历整棵二叉树,用哈希表记录每个节点的父节点指针。
从 p 节点开始不断往它的祖先移动,并用数据结构记录已经访问过的祖先节点。
同样,我们再从 q 节点开始不断往它的祖先移动,如果有祖先已经被访问过,即意味着这是 p 和 q 的深度最深的公共祖先,即 LCA 节点。
class Solution {
public:unordered_map<int, TreeNode*> fa;unordered_map<int, bool> vis;void dfs(TreeNode* root){if (root->left != nullptr) {fa[root->left->val] = root;dfs(root->left);}if (root->right != nullptr) {fa[root->right->val] = root;dfs(root->right);}}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {fa[root->val] = nullptr;dfs(root);while (p != nullptr) {vis[p->val] = true;p = fa[p->val];}while (q != nullptr) {if (vis[q->val]) return q;q = fa[q->val];}return nullptr;}
};心得
思路简单,现在会使用全局变量返回结果了。第二个方法也不难,就是用哈希表记录所有节点的父节点,然后回溯,其实是最直观的解法。
二叉树中的最大路径和
我的题解
递归完成,计算左右节点的最大值,如果为负数则置为0,如果左+右+当前节点值大于ans更新ans。函数返回当前节点值+左右分支中更大的一个。
class Solution {
public:int ans = INT_MIN;int maxpath(TreeNode* node){if (!node)return 0;int left_max = max(maxpath(node->left), 0);int right_max = max(maxpath(node->right), 0);ans = max(ans, left_max + right_max + node->val);return max(left_max, right_max) + node->val;}int maxPathSum(TreeNode* root) {maxpath(root);return ans;}
};官解
官解与笔者一致,不赘叙。
心得
这道题跟二叉树的直径解法几乎一致。一开始笔者没有“负数置零”的一步,导致后面赋值非常冗余,要对比自己、左+自己、右+自己、左+右+自己,返回也是要多重对比。但也顺利做出来,这个困难题实际上算是中等程度吧。至此整个二叉树做完了,感觉最右挑战的反而是本科做过的“前序+中序遍历构建二叉树”...想了好久。其他的思路都很顺畅,继续加油!!
相关文章:

力扣DAY46-50 | 热100 | 二叉树:展开为链表、pre+inorder构建、路径总和、最近公共祖先、最大路径和
前言 中等 、困难 √,越来越有手感了,二叉树done! 二叉树展开为链表 我的题解 前序遍历树,当遇到左子树为空时,栈里pop节点,取右子树接到左子树位置,同时断开该右子树与父节点的连接&#x…...
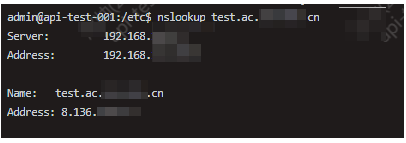
服务器DNS失效
服务器异常 xx.t.RequestException: java.net.UnknownHostException: test.ac.xxxx.cn现象分析 本地测试正常,说明域名本身无问题。服务器 DNS 解析异常,导致 UnknownHostException。**服务器可正常解析 ****baidu.com**,说明网络正常&#…...
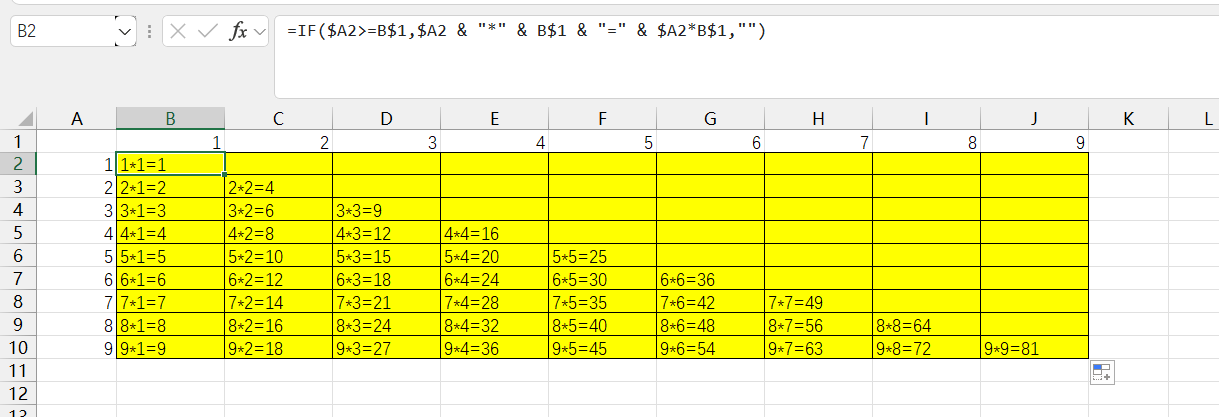
用excel做九乘九乘法表
公式: IF($A2>B 1 , 1, 1,A2 & “" & B$1 & “” & $A2B$1,”")...
企业数据安全如何保障?深度解析AIGC系统源码本地化部署
—从数据加密到权限管控,构建企业级AI安全防线 企业AIGC面临的5大数据安全风险 1. 数据出境违规 典型场景: 使用ChatGPT处理客户信息 → 数据经美国服务器中转 → 违反《个人信息保护法》第38条某金融公司因通过Midjourney生成宣传图,导致产…...

《妖风》-来自DeepSeek
《妖风》 周明揉了揉酸胀的眼睛,电脑屏幕上的Excel表格已经模糊成一片绿色的小格子。窗外,三月的阳光懒洋洋地洒进来,带着春天特有的那种让人昏昏欲睡的温暖。办公室里中央空调的嗡嗡声像是一首催眠曲,他的眼皮越来越重。 "…...

鬼泣:蓄力攻击
文章目录 蓄力攻击:有两个动作,蓄力时触发蓄力动作,攻击时触发攻击动作1.蓄力动作2.攻击动作 浮空上挑1.蓄力对齐位置 2.攻击 下劈斩1.蓄力对齐位置 2.攻击 beiwuf debug事件分发器发送:调用发送器即可发送消息接收:绑…...

企业指标设计方法指南
该文档聚焦企业指标设计方法,适用于企业中负责战略规划、业务运营、数据分析、指标管理等相关工作的人员,如企业高管、部门经理、数据分析师等。 主要内容围绕指标设计展开:首先指出指标设计面临的困境,包括权责不清、口径不统一、缺乏标准规范、报表体系混乱、指标…...

CSS学习02 动态列数表格开发,解决多组数据布局与边框重合问题
概要 在前端开发中,表格常用于展示结构化数据。当数据组的字段数量不统一时(如有的行包含 3 组数据,有的行包含 2 组或 1 组),传统固定列数的表格会出现结构错位、边框重合等问题。本文通过 HTML/CSS 规范方法&#x…...

加载js/mjs模块时服务器返回的 MIME 类型不对导致模块被拒绝执行
浏览器报错 Failed to load module script: The server responded with a non-JavaScript MIME type of "text/html". Strict MIME type checking is enforced for module scripts per HTML spec.Understand this errorAI 核心问题 浏览器加载模块脚本(如…...
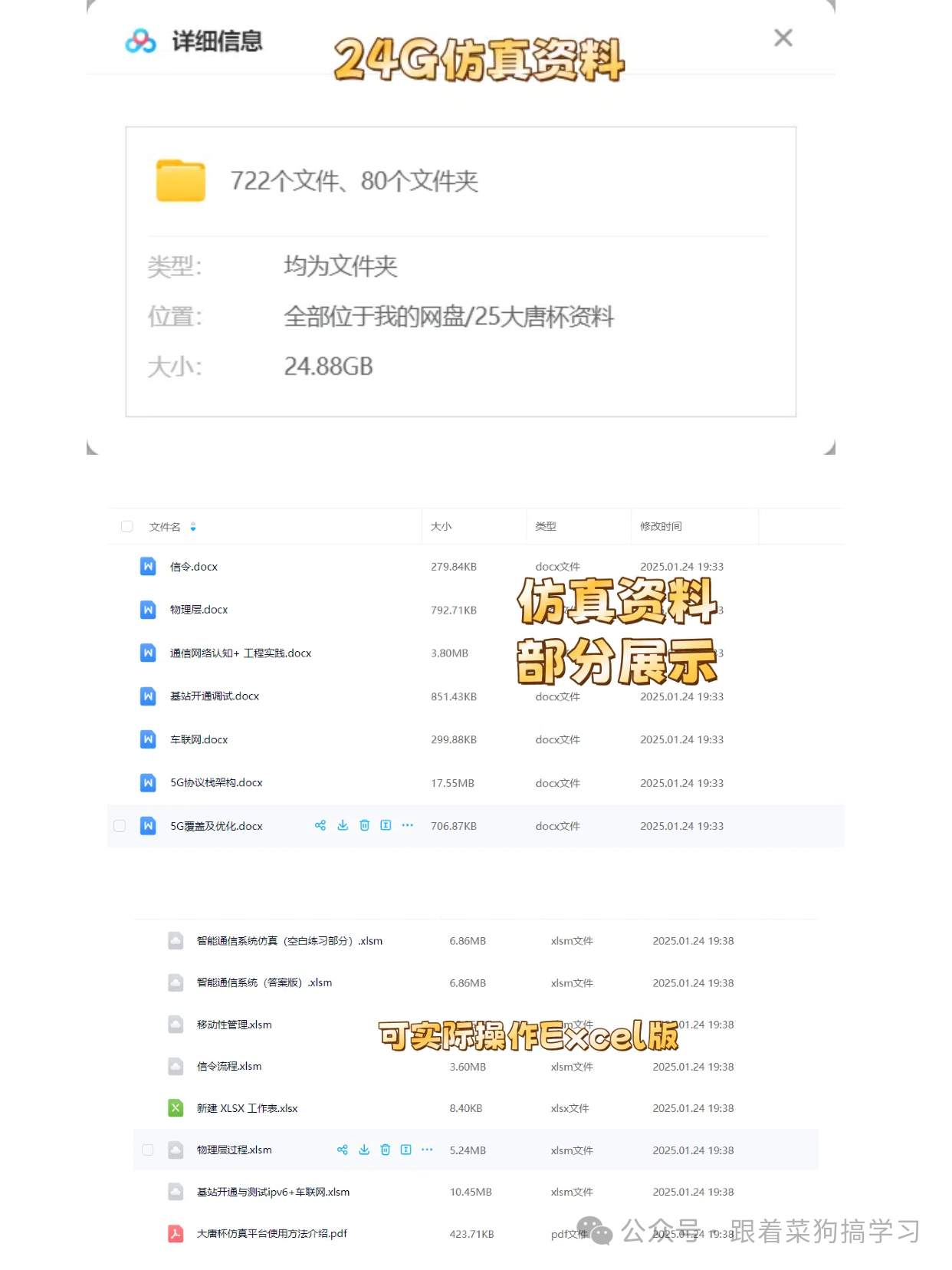
大唐杯省赛安排来了!还有7天,该如何准备?
(一)赛道一:工程实践赛 1、理论赛阶段由参赛队伍使用两台电脑分别登录学唐平台作答,仿真实践赛阶段为参赛队伍共用一台电脑,以竞赛小组方式共同作答(按照报名顺序,用第1选手账号登录仿真平台)。最终统计理…...

iframe学习与应用场景指南
一、iframe核心原理与学习路径 1. 嵌套网站的本质原理 技术特性: • 浏览器为每个iframe创建独立的window对象和DOM环境 • 资源独立加载:子页面拥有自己的CSS/JS/Cookie作用域 • 跨域限制:同源策略下无法直接访问DOM(需CORS或…...
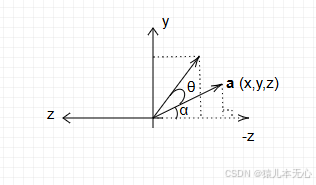
WebGL数学手记:矩阵基础
一、矩阵的定义 矩阵,数学术语。在数学中,矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。 1.英文发音(Matrix) Matrix的发音类似于中文的[美吹克斯],知道它的发音。方便后期看教程时…...

IO流——字符输入输出流:FileReader FileWriter
一、文件字符输入流:FileReader 作用:以内存为基准,可以把文件中的数据以字符的形式读入到内存中去 public class Test5 {public static void main(String[] args) {try (Reader fr new FileReader("E:\\IDEA\\JavaCodeAll\\file-io-t…...
Graphpad Prism for Mac医学绘图
Graphpad Prism for Mac医学绘图 一、介绍 GraphPad Prism for Mac是一款功能强大、易于使用的科学和统计分析软件,适用于各种类型的数据处理和可视化需求。无论您是进行基础研究、临床试验还是学术写作,GraphPad Prism for Mac都能为您短时间内做出最…...
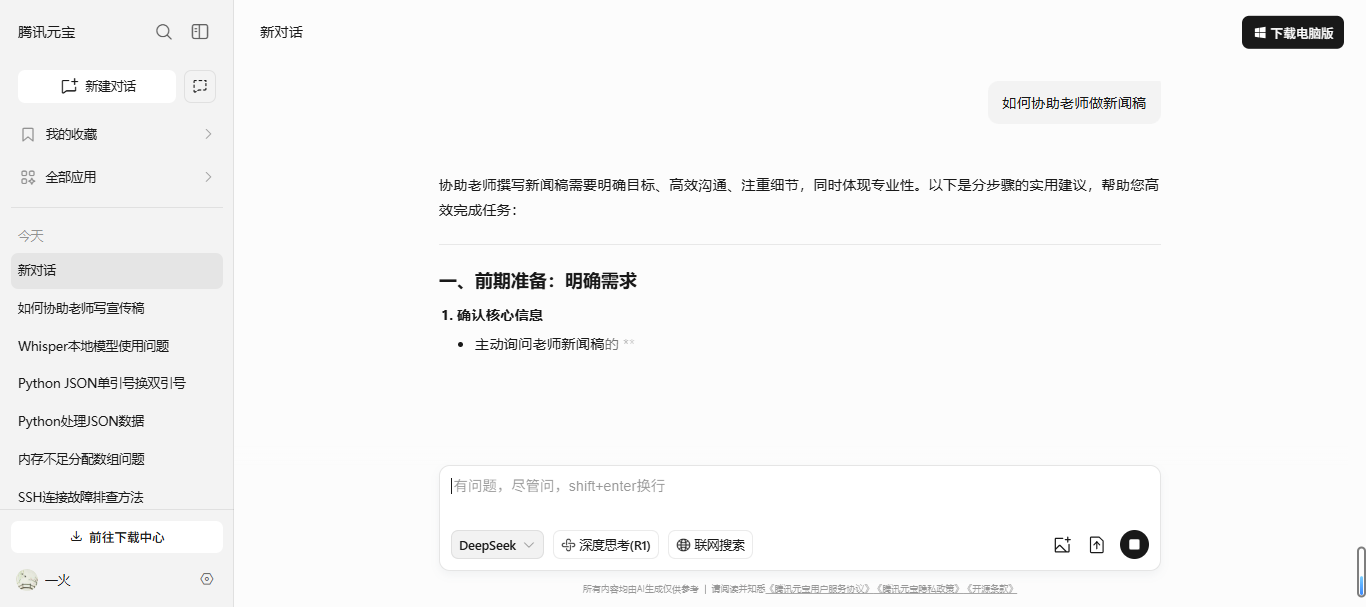
使用人工智能大模型腾讯元宝,如何免费快速做高质量的新闻稿?
今天我们学习使用人工智能大模型腾讯元宝,如何免费快速做高质量的新闻稿? 手把手学习视频地址:https://edu.csdn.net/learn/40402/666431 第一步在腾讯元宝对话框中输入如何协助老师做新闻稿,通过提问,我们了解了老师…...

破解root密码
一、背景: 必须是服务器的管理者,涉及重启服务器 二、破解过程: 1)重启系统,进入 救援模式 开机过程中,按e进入救援模式 在linux开头的该行,将此行的ro修改为rw 然后空格输入 rd.break 按 ctrl x 启动,…...

嵌入式---烧录器
一、核心定义与本质功能 烧录器(Programmer)是一种将用户编写的程序代码(如.hex/.bin文件)写入单片机内部存储器(Flash/EEPROM/ROM)的专用工具,核心功能包括: 程序烧写:…...

机器学习 | 强化学习基本原理 | MDP | TD | PG | TRPO
文章目录 📚什么是强化学习🐇监督学习 vs 强化学习🐇马尔科夫决策过程(MDP)📚基本算法(value-based & policy-based)🐇时序差分算法(TD)🐇SARSA和Q-learning🐇策略梯度算法(PG)🐇REINFORCE和Actor-Critic🐇信任区域策略优化算法(TRPO)⭐️参考…...

Spring中使用Kafka的详细配置,以及如何集成 KRaft 模式的 Kafka
在 Spring 中使用 Apache Kafka 的配置主要涉及 Spring Boot Starter for Kafka,而开启 KRaft 模式(Kafka 的元数据管理新模式,替代 ZooKeeper)需要特定的 Kafka Broker 配置。以下是详细步骤: 一、Spring 中集成 …...

llinux上的pip国内镜像全局配置
1、创建全局 pip 配置文件(推荐) sudo tee /etc/pip.conf <<EOF [global] index-url https://pypi.tuna.tsinghua.edu.cn/simple trusted-host pypi.tuna.tsinghua.edu.cn EOF2、验证配置 任意用户运行以下命令应显示配置的镜像: …...

ASEG的鉴定
等位基因特异性表达(Allele-Specific Expression, ASE)基因的鉴定是研究杂种优势和基因表达调控的重要手段。以下是鉴定ASE基因的详细流程和方法: ### **1. 实验设计与样本准备** - **选择材料**:选择杂交种及其亲本作为研究材料。例如,玉米中的B73和Mo17及其杂交组合B73…...

swift菜鸟教程14(闭包)
一个朴实无华的目录 今日学习内容:1.Swift 闭包1.1闭包定义1.2闭包实例1.3闭包表达式1.3.1sorted 方法:据您提供的用于排序的闭包函数将已知类型数组中的值进行排序。1.3.2参数名称缩写:直接通过$0,$1,$2来顺序调用闭包的参数。1.3.3运算符函…...
新手宝塔部署thinkphp一步到位
目录 一、下载对应配置 二、加载数据库 三、添加FTP 四、上传项目到宝塔 五、添加站点 六、配置伪静态 七、其他配置 开启监控 八、常见错误 一、打开宝塔页面,下载对应配置。 二、加载数据库 从本地导入数据库文件 三、添加FTP 四、上传项目到宝塔…...
)
Java常用工具算法-7--秘钥托管云服务2(阿里云 KMS)
阿里云的KMS(Key Management Service)也是一种托管式密钥管理服务,帮助用户安全地创建、控制和使用密钥,保护敏感数据。通过使用KSM,您可以专注于构建和优化应用程序,而不必担心密钥管理的复杂性。 1、主要…...

基于STM32 的实时FFT处理(Matlab+MDK5)
目录 一、 任务介绍二、基本原理三、软件仿真3.1 软件仿真基本原理3.2 软件仿真序列的软件模拟 四、模拟测试五、 附加题六、 源码 一、 任务介绍 1、在硬件平台上实现 FFT 算法; 2、模拟数据,通过 FFT 算法进行谱分析; 3、测定 PWM 输出方波…...
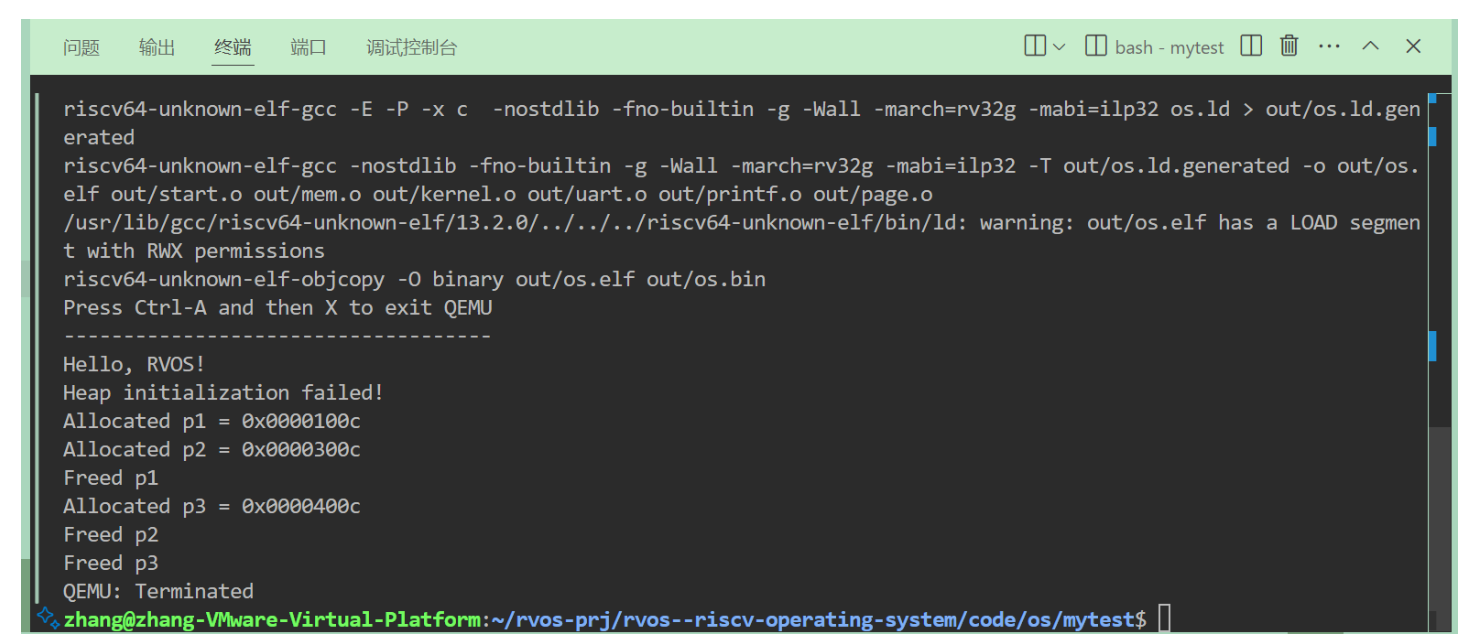
RVOS-3.实现内存管理
3.内存管理 3.1 实验目的 对内存进一步的管理,实现动态的分配和释放。 实现 Page 级别的内存分配和释放。 在 page 分配的基础上实现更细颗粒度的,精确到字节为单位的内存管理。 (练习8.1) void *malloc(size_t size); void fr…...

MySQL 约束(入门版)
目录 一、约束的基本概念 二、约束演示 三、外键约束 (一)介绍 (二)外键约束语法 (三)删除/更新行为 一、约束的基本概念 1、概念:约束是作用于表中字段上的规则,用于限制存储…...

系统与网络安全------Windows系统安全(11)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 制作U启动盘 U启动程序 下载制作U启程序 Ventoy是一个制作可启动U盘的开源工具,只需要把ISO等类型的文件拷贝到U盘里面就可以启动了 同时支持x86LegacyBIOS、x86_64UEFI模式。 支持Windows、L…...

电容命名解析与多类型电容的必要性
一、电容命名:NP0、COG及其他类型 1. NP0与COG的命名与识别 COG(EIA标准): 命名规则: C:温度系数 0 ppm/℃(Class I介质) O:容值偏差 30 ppm/℃ G:温度范围…...

重返JAVA之路-初识JAVA
目录 1.什么是JDK? 2.什么是JRE? 3.什么是JVM? 4.JDK,JRE,JAM之间的关系是怎么样的? 5.什么是驼峰命名法? 1.什么是JDK? JDK(Java Development Kit):Java 开发工具包,是 Jav…...