深度学习基础--CNN经典网络之分组卷积与ResNext网络实验探究(pytorch复现)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- ResNext是分组卷积的开始之作,这里本文将学习ResNext网络;
- 本文复现了ResNext50神经网络,并用其进行了猴痘病分类实验;
- 没有最好的网络。只有最适合的网络,网络不是越复杂,越优秀越好,必须根据实际数据情况,目标要求决定,很多时候,简单的网络反而效果更好;
- 欢迎收藏 + 关注,本人将会持续更新
文章目录
- 1、知识简介
- 1、分组卷积
- 2、split-transform-merge
- 3、ResNext-50简介
- 2、ResNext-50实验
- 1、导入数据
- 1、导入库
- 2、查看数据信息和导入数据
- 3、展示数据
- 4、数据导入
- 5、数据划分
- 6、动态加载数据
- 2、构建ResNext-50网络
- 3、模型训练
- 1、构建训练集
- 2、构建测试集
- 3、设置超参数
- 4、模型训练
- 5、结果可视化
- 6、模型评估
- 3、参考资料
1、知识简介
1、分组卷积
分组卷积最早出现在AlexNet网络中,在这里将通道数分成两组,采用两个GPU并行提取特征,网络结构如下:

提取到的特征图如下:

作者发现第一组提取的主要是黑白特征,第二组提取的主要是彩色特征,这样分组特征可以更好的提取不同特征数据。
普通卷积 VS 分组卷积
先看常规卷积,在常规卷积中,输入feature map尺寸为 n 个,输出feature map与卷积和数量相同也是n个,卷积核大小为:c * k * k,n个卷积核总大小为:n * c * k * k,最后输出的维度是:n * h1 * w1,如下图左边所示:

分组卷积,就是对输入的feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸为 c * h * w,输出的feature map为 n,假设分为 g 组,则每组的输入的feature map数量为 c / g,每组输出的feature map为 n / g。但是注意:只是每个卷积核的输入通道数量变成了 c / g,卷积核大小是不变的,每一组卷积核运算后得到了 (n / g) * h1 * w1,最后将各组矩阵进行拼接就可以得出最后的结果,最后输出的维度依然是n * h1 * w1,与常规卷积一样。
参数了对比:
- 常规卷积:c * k * k * n,c通道数,k * k:卷积核矩阵大小,n卷积核数量;
- 分组卷积:(c / g) * k * k * (n / g) * g = k * k * c * n * (1 / g),从参数了来看,分组卷积更小;
更详细的图如下:

2、split-transform-merge
“Split-Transform-Merge” 是一种常见的设计模式或处理流程,广泛应用于软件开发、数据处理和系统架构中。它的核心思想是将一个复杂的问题分解为更小的部分(Split),对每个部分进行独立的处理或转换(Transform),最后将处理后的结果重新组合(Merge)以完成整体任务。
1. Split(拆分)
在这一阶段,输入数据或任务被分解成更小、更易于管理的部分。拆分的方式取决于具体问题和上下文。例如:
- 数据拆分:将大数据集分割成多个小块。
- 任务拆分:将一个复杂的任务分解为多个子任务。
- 并行化:通过拆分实现并行处理,提高效率。
示例:
- 分组卷积中,输入通道分组拆分,分组进行卷积。
2. Transform(转换/处理)
在拆分后,每个部分被独立处理或转换。这是整个流程的核心阶段,通常涉及计算、分析或修改操作。转换的具体内容取决于任务需求:
- 数据清洗、格式转换。
- 算法计算或模型推理。
- 对子任务的独立执行。
示例:
- 分组卷积中 ,每一组分别进行卷积计算,互补干扰。
3. Merge(合并)
在所有子任务完成后,将处理后的结果重新组合起来,形成最终的输出。合并的方式需要确保结果的完整性和一致性:
- 数据合并:将多个处理后的数据块拼接成完整的数据集。
- 结果整合:将多个子任务的结果汇总为最终答案。
- 冲突解决:如果子任务之间存在冲突或重复,需要在合并阶段解决。
示例:
- 分组卷积中,最后将每一组卷积的结果进行组合。
3、ResNext-50简介
ResNext网络被誉为,分组卷积的开山之作,是何凯明团队在2017年CVPR会与提出的,是ResNet网络的升级版。
在论文中,作者提到了一个普遍存在的现象,提高模型准确率,往往采用的是加深或加宽网络的方法,这种方法虽然有一定效果,但是网络设计的难度和计算了也随着增加,因为不代表网络越深就越好,有时候提升了精度,但是代价也大,就如VGG16提出来的时候,计算了庞大。
在论文中,作者提出了在不额外增加计算代价的情况下,提升网络精度,提出了cardinality概念(cardinality指的是分组卷积中的“组数”).
下图中,左边是(Resnet)右边数(Resnext)的模块差异,在ResNet中,输入具有256个通道特征经过1 * 1卷积压缩到4倍到64个通道特征,然后通过3 * 3卷积核进行特征提取,最后经过 3 * 3卷积核进行还原通道数量输出,并于原来特征进行残差连接。在ResNext中,将256个输入通道特征分成32个组,每个组首先进行64倍压缩到4个通道,然后用3 * 3卷积核大小进行特征提取,最后通过1 * 1卷积核进行通道还原,后会将每个分组的结构进行维度拼接并与原始特征进行残差连接。

cardinatity指的是一个block中所具有的相同分支的数目,即“组数”.
下面进行ResNext-50网络图的搭建(pytorch复现)
2、ResNext-50实验
1、导入数据
1、导入库
import torch
import torch.nn as nn
import torchvision
import numpy as np
import os, PIL, pathlib # 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"device
'cuda'
2、查看数据信息和导入数据
数据目录有两个文件:一个数据文件,一个权重。
data_dir = "./data/"data_dir = pathlib.Path(data_dir)# 类别数量
classnames = [str(path).split('/')[0] for path in os.listdir(data_dir)]classnames
['Monkeypox', 'Others']
3、展示数据
import matplotlib.pylab as plt
from PIL import Image # 获取文件名称
data_path_name = "./data/Others"
data_path_list = [f for f in os.listdir(data_path_name) if f.endswith(('jpg', 'png'))]# 创建画板
fig, axes = plt.subplots(2, 8, figsize=(16, 6))for ax, img_file in zip(axes.flat, data_path_list):path_name = os.path.join(data_path_name, img_file)img = Image.open(path_name) # 打开# 显示ax.imshow(img)ax.axis('off')plt.show()

4、数据导入
from torchvision import transforms, datasets # 数据统一格式
img_height = 224
img_width = 224 data_tranforms = transforms.Compose([transforms.Resize([img_height, img_width]),transforms.ToTensor(),transforms.Normalize( # 归一化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] )
])# 加载所有数据
total_data = datasets.ImageFolder(root=data_dir, transform=data_tranforms)
5、数据划分
# 大小 8 : 2
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_size train_data, test_data = torch.utils.data.random_split(total_data, [train_size, test_size])
6、动态加载数据
batch_size = 32 train_dl = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True
)test_dl = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False
)
# 查看数据维度
for data, labels in train_dl:print("data shape[N, C, H, W]: ", data.shape)print("labels: ", labels)break
data shape[N, C, H, W]: torch.Size([32, 3, 224, 224])
labels: tensor([1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0,0, 1, 0, 0, 0, 1, 0, 0])
2、构建ResNext-50网络
ResNet-50网络结构图:


在复现ResNext50网络中,我查阅了不少资料,但是我好像都没怎么看懂那个代码,后面我发现这个就是在ResNet50上加了分组卷积,其他网络结构就是在每一层,第二层的数量是resnet的2倍,后面基于以前搭建的ResNet网络结果进行修改,代码如下所示。
在ResNext50中,有几个参数需要注意:
- 分组卷积:cardinality参数代表分组卷积数量,在Conv2d中groups参数就是分组卷积数量。
- 通道数计算:每组的输出通道数由 group_depth 决定,总输出通道数为 cardinality × group_depth。这里,下面本人搭建的ResNext50网络结构,每一层输入通道数,输出通道数,都是自己手动输入的,故这里group_depth隐藏在filters中(手动计算).
回忆:
Bottleneck 的基本概念
Bottleneck 结构通常由三个卷积层组成,他是ResNet以及其变体的基本网络层单元。
- 第一个 1×1 卷积:降低输入特征图的通道数,减少后续计算量。
- 中间的 3×3 卷积:核心特征提取过程。在 ResNeXt 中,这一层使用分组卷积来增强表达能力。
- 最后一个 1×1 卷积:恢复通道数到原始或者更高的数量,以便与输入特征图进行残差连接。
注意:
- 在ResNext网络结构中,分组卷积只在Bottleneck只在第二层使用
import torch.nn.functional as F# Bottleneck: 分为残差模块一、残差模块二# 定义残差模块一,这个用于处理输入和输出通道一样的情况
'''
卷积核大小:1 3 1
核心特点:尺寸不变:输入和输出的尺寸保持一致。 没有下采样:没有使用步长大于1的卷积操作,因此没有改变特征图的空间尺寸
'''
class Identity_block(nn.Module):def __init__(self, in_channels, kernel_size, filters, cardinality):super(Identity_block, self).__init__()# 输出通道filter1, filter2, filter3 = filters# 卷积层一, 降维self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=1)self.bn1 = nn.BatchNorm2d(filter1)# 卷积层2, 分组卷积, 核心:特征提取self.conv2 = nn.Conv2d(filter1, filter2, kernel_size=kernel_size, padding=1,groups=cardinality) # 通过卷积输入输出公式发现,padding=1,可以保证输入和输出尺寸相同self.bn2 = nn.BatchNorm2d(filter2)# 卷积层3, 升维self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1)self.bn3 = nn.BatchNorm2d(filter3)def forward(self, x):# 记录原始值xx = xx = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.bn3(self.conv3(x))# 残差连接,输入、输出维度不变x += xxx = F.relu(x)return x # 定义卷积模块二:用于处理输入和输出不一样的情况
'''
* 卷积核还是:1 3 1
* stride=2
* 这里的分支是采用一个Conv2D,和一个归一化BN层,也是为了处理数据维度吧, 这种维度的变化,可以用ai举例子核心特点:尺寸变化,stride=2降维
'''
class ConvBlock(nn.Module):def __init__(self, in_channels, kernel_size, filters, cardinality, stride=2):super(ConvBlock, self).__init__()filter1, filter2, filter3= filters# 卷积层1, 降维self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride)self.bn1 = nn.BatchNorm2d(filter1)# 卷积2, 分组卷积,核心:特征提取self.conv2 = nn.Conv2d(filter1, filter2, kernel_size=kernel_size, padding=1,groups=cardinality) # 需要维持维度不变self.bn2 = nn.BatchNorm2d(filter2)# 卷积3, 降维self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1) # stride = 1,维持通道不变self.bn3 = nn.BatchNorm2d(filter3)# 用于匹配维度的shortcut卷积,这个就是上面Identity_block的x分支self.shortcut = nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride)self.shortcut_bn = nn.BatchNorm2d(filter3)def forward(self, x):xx = xx = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.bn3(self.conv3(x))temp = self.shortcut_bn(self.shortcut(xx))x += tempx = F.relu(x)return x # 定义ResNext50
class ResNext50(nn.Module):def __init__(self, classes): # 类别数量super().__init__()# 头顶, resnet以及变体一般都是这个self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.bn1 = nn.BatchNorm2d(64)self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 第一部分self.part1_1 = ConvBlock(64, 3, [128, 128, 256], cardinality=32, stride=1)self.part1_2 = Identity_block(256, 3, [128, 128, 256], cardinality=32)self.part1_3 = Identity_block(256, 3, [128, 128, 256], cardinality=32)# 第二部分self.part2_1 = ConvBlock(256, 3, [256, 256, 512], cardinality=32)self.part2_2 = Identity_block(512, 3, [256, 256, 512], cardinality=32)self.part2_3 = Identity_block(512, 3, [256, 256, 512], cardinality=32)self.part2_4 = Identity_block(512, 3, [256, 256, 512], cardinality=32)# 第三部分self.part3_1 = ConvBlock(512, 3, [512, 512, 1024], cardinality=32)self.part3_2 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)self.part3_3 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)self.part3_4 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)self.part3_5 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)self.part3_6 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)# 第四部分self.part4_1 = ConvBlock(1024, 3, [1024, 1024, 2048], cardinality=32)self.part4_2 = Identity_block(2048, 3, [1024, 1024, 2048], cardinality=32)self.part4_3 = Identity_block(2048, 3, [1024, 1024, 2048], cardinality=32)# 平均池化self.avg_pool = nn.AvgPool2d(kernel_size=7)# 全连接self.fn1 = nn.Linear(2048, classes)def forward(self, x):# 头部x = F.relu(self.bn1(self.conv1(x)))x = self.max_pool(x)x = self.part1_1(x)x = self.part1_2(x)x = self.part1_3(x)x = self.part2_1(x)x = self.part2_2(x)x = self.part2_3(x)x = self.part2_4(x)x = self.part3_1(x)x = self.part3_2(x)x = self.part3_3(x)x = self.part3_4(x)x = self.part3_5(x)x = self.part3_6(x)x = self.part4_1(x)x = self.part4_2(x)x = self.part4_3(x)x = self.avg_pool(x)x = x.view(x.size(0), -1) # 扁平化x = self.fn1(x)return x model = ResNext50(classes=len(classnames)).to(device)model
ResNext50((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(part1_1): ConvBlock((conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))(shortcut_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part1_2): Identity_block((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part1_3): Identity_block((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_1): ConvBlock((conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_2): Identity_block((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_3): Identity_block((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_4): Identity_block((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_1): ConvBlock((conv1): Conv2d(512, 512, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_2): Identity_block((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_3): Identity_block((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_4): Identity_block((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_5): Identity_block((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_6): Identity_block((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_1): ConvBlock((conv1): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_2): Identity_block((conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_3): Identity_block((conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(avg_pool): AvgPool2d(kernel_size=7, stride=7, padding=0)(fn1): Linear(in_features=2048, out_features=2, bias=True)
)
3、模型训练
1、构建训练集
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)batch_size = len(dataloader)train_acc, train_loss = 0, 0 for X, y in dataloader:X, y = X.to(device), y.to(device)# 训练pred = model(X)loss = loss_fn(pred, y)# 梯度下降法optimizer.zero_grad()loss.backward()optimizer.step()# 记录train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_acc /= sizetrain_loss /= batch_sizereturn train_acc, train_loss
2、构建测试集
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)batch_size = len(dataloader)test_acc, test_loss = 0, 0 with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= batch_sizereturn test_acc, test_loss
3、设置超参数
loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr) # 优化器
4、模型训练
import copy train_acc = []
train_loss = []
test_acc = []
test_loss = []epoches = 50best_acc = 0for i in range(epoches):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_model if epoch_test_acc > best_acc: best_acc = epoch_test_acc best_model = copy.deepcopy(model) # 拷贝最好模型train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率 lr = optimizer.state_dict()['param_groups'][0]['lr']# 输出template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))print("Done")PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)
Epoch: 1, Train_acc:62.3%, Train_loss:0.696, Test_acc:66.4%, Test_loss:0.604
Epoch: 2, Train_acc:67.9%, Train_loss:0.620, Test_acc:69.9%, Test_loss:0.580
Epoch: 3, Train_acc:69.5%, Train_loss:0.580, Test_acc:68.3%, Test_loss:0.603
Epoch: 4, Train_acc:71.6%, Train_loss:0.547, Test_acc:73.9%, Test_loss:0.530
Epoch: 5, Train_acc:74.7%, Train_loss:0.519, Test_acc:75.1%, Test_loss:0.520
Epoch: 6, Train_acc:78.2%, Train_loss:0.464, Test_acc:67.8%, Test_loss:0.683
Epoch: 7, Train_acc:78.1%, Train_loss:0.459, Test_acc:69.0%, Test_loss:0.652
Epoch: 8, Train_acc:80.8%, Train_loss:0.411, Test_acc:72.7%, Test_loss:0.643
Epoch: 9, Train_acc:84.8%, Train_loss:0.362, Test_acc:74.8%, Test_loss:0.575
Epoch:10, Train_acc:87.4%, Train_loss:0.314, Test_acc:77.9%, Test_loss:0.536
Epoch:11, Train_acc:89.3%, Train_loss:0.266, Test_acc:79.0%, Test_loss:0.505
Epoch:12, Train_acc:89.4%, Train_loss:0.260, Test_acc:78.3%, Test_loss:0.601
Epoch:13, Train_acc:90.7%, Train_loss:0.226, Test_acc:81.4%, Test_loss:0.493
Epoch:14, Train_acc:93.9%, Train_loss:0.159, Test_acc:80.4%, Test_loss:0.616
Epoch:15, Train_acc:93.8%, Train_loss:0.152, Test_acc:80.4%, Test_loss:0.620
Epoch:16, Train_acc:92.2%, Train_loss:0.190, Test_acc:82.3%, Test_loss:0.621
Epoch:17, Train_acc:94.0%, Train_loss:0.142, Test_acc:82.3%, Test_loss:0.582
Epoch:18, Train_acc:95.8%, Train_loss:0.106, Test_acc:79.3%, Test_loss:0.625
Epoch:19, Train_acc:95.5%, Train_loss:0.127, Test_acc:81.1%, Test_loss:0.625
Epoch:20, Train_acc:95.4%, Train_loss:0.113, Test_acc:83.0%, Test_loss:0.482
Epoch:21, Train_acc:96.7%, Train_loss:0.087, Test_acc:83.0%, Test_loss:0.667
Epoch:22, Train_acc:97.3%, Train_loss:0.083, Test_acc:80.4%, Test_loss:0.695
Epoch:23, Train_acc:97.1%, Train_loss:0.077, Test_acc:83.7%, Test_loss:0.634
Epoch:24, Train_acc:96.6%, Train_loss:0.086, Test_acc:82.5%, Test_loss:0.732
Epoch:25, Train_acc:96.6%, Train_loss:0.098, Test_acc:83.9%, Test_loss:0.711
Epoch:26, Train_acc:96.0%, Train_loss:0.107, Test_acc:75.3%, Test_loss:0.821
Epoch:27, Train_acc:95.6%, Train_loss:0.105, Test_acc:81.6%, Test_loss:0.596
Epoch:28, Train_acc:96.7%, Train_loss:0.088, Test_acc:84.4%, Test_loss:0.606
Epoch:29, Train_acc:97.5%, Train_loss:0.071, Test_acc:86.5%, Test_loss:0.615
Epoch:30, Train_acc:98.2%, Train_loss:0.051, Test_acc:80.4%, Test_loss:0.772
Epoch:31, Train_acc:98.5%, Train_loss:0.041, Test_acc:83.7%, Test_loss:0.694
Epoch:32, Train_acc:98.5%, Train_loss:0.048, Test_acc:82.8%, Test_loss:0.671
Epoch:33, Train_acc:97.7%, Train_loss:0.064, Test_acc:84.1%, Test_loss:0.745
Epoch:34, Train_acc:98.4%, Train_loss:0.054, Test_acc:83.7%, Test_loss:0.661
Epoch:35, Train_acc:98.2%, Train_loss:0.068, Test_acc:83.0%, Test_loss:0.605
Epoch:36, Train_acc:96.8%, Train_loss:0.086, Test_acc:83.2%, Test_loss:0.551
Epoch:37, Train_acc:97.8%, Train_loss:0.063, Test_acc:82.3%, Test_loss:0.739
Epoch:38, Train_acc:97.6%, Train_loss:0.065, Test_acc:83.0%, Test_loss:0.583
Epoch:39, Train_acc:98.2%, Train_loss:0.045, Test_acc:83.4%, Test_loss:0.697
Epoch:40, Train_acc:98.1%, Train_loss:0.048, Test_acc:82.5%, Test_loss:0.710
Epoch:41, Train_acc:98.2%, Train_loss:0.054, Test_acc:83.2%, Test_loss:0.564
Epoch:42, Train_acc:98.4%, Train_loss:0.051, Test_acc:85.5%, Test_loss:0.514
Epoch:43, Train_acc:99.0%, Train_loss:0.025, Test_acc:83.9%, Test_loss:0.663
Epoch:44, Train_acc:99.1%, Train_loss:0.029, Test_acc:85.5%, Test_loss:0.594
Epoch:45, Train_acc:98.3%, Train_loss:0.036, Test_acc:84.6%, Test_loss:0.719
Epoch:46, Train_acc:98.7%, Train_loss:0.036, Test_acc:84.4%, Test_loss:0.631
Epoch:47, Train_acc:97.7%, Train_loss:0.055, Test_acc:81.4%, Test_loss:0.643
Epoch:48, Train_acc:98.7%, Train_loss:0.040, Test_acc:85.1%, Test_loss:0.607
Epoch:49, Train_acc:98.8%, Train_loss:0.037, Test_acc:80.2%, Test_loss:0.897
Epoch:50, Train_acc:98.6%, Train_loss:0.042, Test_acc:84.4%, Test_loss:0.601
Done
5、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息epochs_range = range(epoches)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
plt.show()

6、模型评估
# 加载最好模型
best_model.load_state_dict(torch.load(PATH, map_location=device))
# 模型测试
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)print(epoch_test_acc, epoch_test_loss)
0.8648018648018648 0.6145411878824234
3、参考资料
- 深度学习——分类之ResNeXt - 知乎
- 通义 - 你的个人AI助手
- ResNeXt代码复现+超详细注释(PyTorch)-CSDN博客
相关文章:
深度学习基础--CNN经典网络之分组卷积与ResNext网络实验探究(pytorch复现)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 ResNext是分组卷积的开始之作,这里本文将学习ResNext网络;本文复现了ResNext50神经网络,并用其进行了猴痘病分类实验…...

AutoGen深度解析:从核心架构到多智能体协作的完整指南
AutoGen是微软推出的一个革命性多智能体(Multi-Agent)框架,它通过模块化设计和灵活的对话机制,极大地简化了基于大型语言模型(LLM)的智能体系统开发。本文将深入剖析AutoGen的两个核心模块——core基础架构和agentchat多智能体对话系统,带您全…...
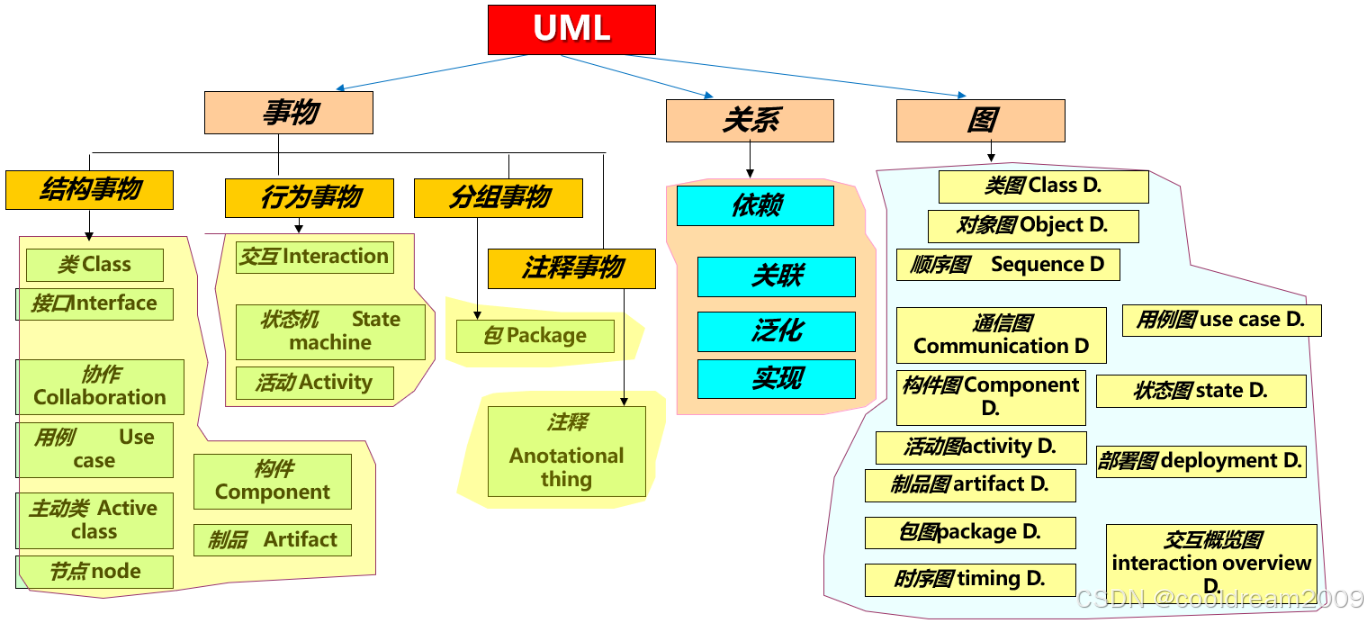
面向对象的需求分析与UML构造块详解
目录 前言1 面向对象的需求分析概述2 UML构造块概述3 UML事物详解3.1 结构事物(Structural Things)3.2 行为事物(Behavioral Things)3.3 分组事物(Grouping Things)3.4 解释事物(Annotational T…...

计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比
计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比 一、前言二、RGB 色彩空间2.1 RGB 色彩空间原理2.1.1 基本概念2.1.2 颜色混合机制 2.2 RGB 在计算机视觉中的应用2.2.1 图像读取与显示2.2.2 颜色识别2.2.3 RGB 色彩空间的局限性 三、HSV 色彩空…...

使用Docker安装Gogs
1、拉取镜像 docker pull gogs/gogs 2、运行容器 # 创建/var/gogs目录 mkdir -p /var/gogs# 运行容器 # -d,后台运行 # -p,端口映射:(宿主机端口:容器端口)->(10022:22)和(10880:3000) # -v,数据卷映射:(宿主机目…...

【Web API系列】XMLHttpRequest API和Fetch API深入理解与应用指南
前言 在现代Web开发中,客户端与服务器之间的异步通信是构建动态应用的核心能力。无论是传统的AJAX技术(基于XMLHttpRequest)还是现代的Fetch API,它们都为实现这一目标提供了关键支持。本文将从底层原理、核心功能、代码实践到实…...
)
Spring Boot 自定义 Redis Starter 开发指南(附动态 TTL 实现)
一、功能概述 本 Starter 基于 Spring Boot 2.7 实现以下核心能力: Redis 增强:标准化 RedisTemplate 配置(JSON 序列化 LocalDateTime 支持)缓存扩展:支持 Cacheable(value “key#60s”) 语法动态设置 TTL配置集中…...
ESP32开发入门:基于VSCode+PlatformIO环境搭建指南
前言 ESP32作为一款功能强大的物联网开发芯片,结合PlatformIO这一现代化嵌入式开发平台,可以大幅提升开发效率。本文将详细介绍如何在VSCode中搭建ESP32开发环境,并分享实用开发技巧。 一、环境安装(Windows/macOS/Linux…...

2025.4.13机器学习笔记:文献阅读
2025.4.13周报 题目信息摘要创新点网络架构实验结论不足以及展望 题目信息 题目: Physics-informed neural networks for inversion of river flow and geometry with shallow water model期刊: Physics of Fluids作者: Y. Ohara; D. Moteki…...

Quartz修仙指南:从定时任务萌新到调度大能的终极奥义
各位被Thread.sleep()和ScheduledExecutorService折磨的道友们!今天要解锁的是Java界任务调度至尊法宝——Quartz!这货能让你像玉皇大帝安排天庭日程一样,精确控制每个任务的执行时机!准备好告别蹩脚的手动定时器了吗?…...

如何免费使用Meta Llama 4?
周六, Meta发布了全新开源的Llama 4系列模型。 架构介绍查看上篇文章。 作为开源模型,Llama 4存在一个重大限制——庞大的体积。该系列最小的Llama 4 Scout模型就拥有1090亿参数,如此庞大的规模根本无法在本地系统运行。 不过别担心!即使你没有GPU,我们也找到了通过网页…...

编程助手fitten code使用说明(超详细)(vscode)
这两年 AI 发展迅猛,作为开发人员,我们总是追求更快、更高效的工作方式,AI 的出现可以说改变了很多人的编程方式。 AI 对我们来说就是一个可靠的编程助手,给我们提供了实时的建议和解决方,无论是快速修复错误、提升代…...

Python自动化爬虫:Scrapy+APScheduler定时任务
在数据采集领域,定时爬取网页数据是一项常见需求。例如,新闻网站每日更新、电商价格监控、社交媒体舆情分析等场景,都需要定时执行爬虫任务。Python的Scrapy框架是强大的爬虫工具,而APScheduler则提供了灵活的任务调度功能。 一、…...

技术分享|iTOP-RK3588开发板Ubuntu20系统旋转屏幕方案
iTOP-3588开发板采用瑞芯微RK3588处理器,是全新一代AloT高端应用芯片,采用8nmLP制程,搭载八核64位CPU,四核Cortex-A76和四核Cortex-A55架构,主频高达2.4GHz。是一款可用于互联网设备和其它数字多媒体的高性能产品。 在…...

Java中的参数是值传递还是引用传递?
在java中, 参数传递只有值传递 ,不论是基本类型还是引用类型。 其中的区别在于: 基本数据类型(如byte,short,int等):传递的参数是值的副本,即基本类型的数值本身。因此在方法中&am…...
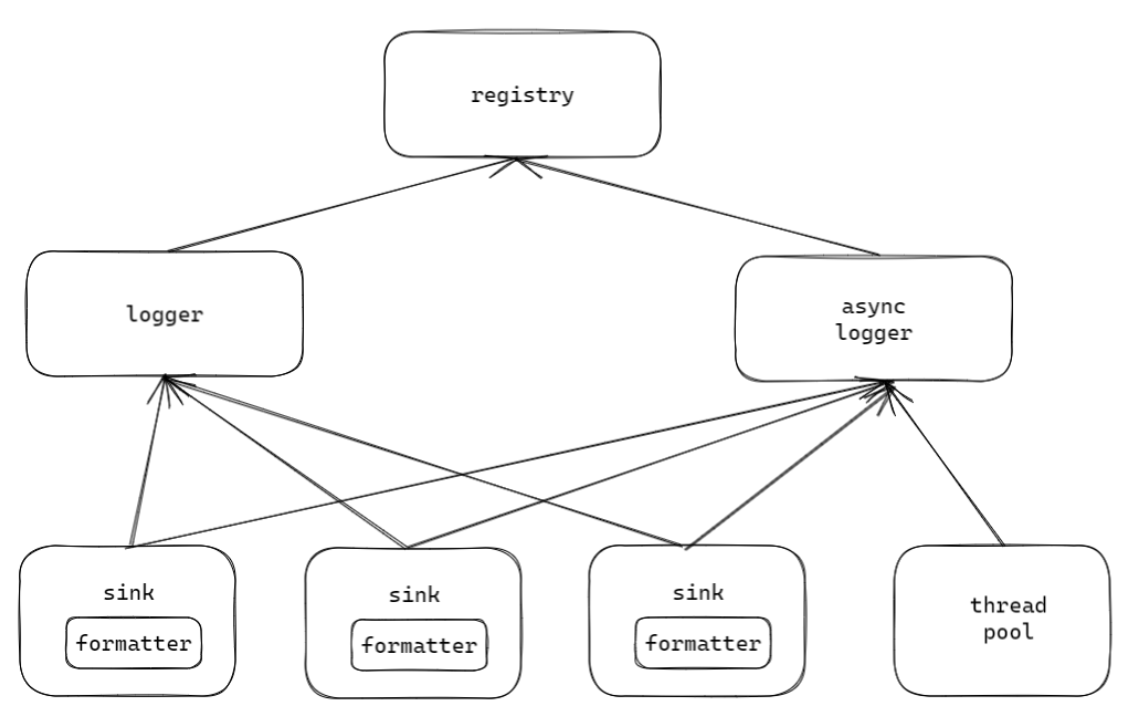
3.3.1 spdlog异步日志
文章目录 3.3.1 spdlog异步日志1. spdlog1. 日志作用2 .同步日志和异步日志区别 2. spdlog是什么下载命令:2. spdlog为什么高效3. spdlog特征5. spdlog输出控制6. 处理流程7. 文件io8.问题 2. 如何创建logger3. 如何创建sink4. 如何自定义格式化5. 如何创建异步日志…...

SSRF漏洞公开报告分析
文章目录 1. SSRF | 获取元数据 | 账户接管2. AppStore | 版本上传表单 | Blind SSRF3. HOST SSRF一、为什么HOST修改不会影响正常访问二、案例 4. Turbonomic 的 终端节点 | SSRF 获取元密钥一、介绍二、漏洞分析 5. POST | Blind SSRF6. CVE-2024-40898利用 | SSRF 泄露 NTL…...

生物化学笔记:医学免疫学原理14 感染免疫 感染免疫的机制+病原体的免疫逃逸机制
感染免疫的基本概念 感染免疫的机制 病原体的免疫逃逸机制...

RocketMQ深度百科全书式解析
一、核心架构与设计哲学 1. 设计目标 海量消息堆积:单机支持百万级消息堆积,适合大数据场景(如日志采集)。严格顺序性:通过队列分区(Queue)和消费锁机制保证局部顺序。事务…...

谈谈模板方法模式,模板方法模式的应用场景是什么?
一、模式核心理解 模板方法模式是一种行为设计模式,通过定义算法骨架并允许子类重写特定步骤来实现代码复用。 如同建筑图纸规定房屋结构,具体装修由业主决定,该模式适用于固定流程中需要灵活扩展的场景。 // 基础请求处理…...

电脑的usb端口电压会大于开发板需要的电压吗
电脑的USB端口电压通常不会大于开发板所需的电压,以下是详细解释: 1. USB端口电压标准 根据USB规范,USB接口的标称输出电压为5V。实际测量时,USB接口的输出电压会略有偏差,通常在4.75V到5.25V之间。USB 2.0和USB 3.0…...

DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用
DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用 DeepSeek作为中国人工智能领域的新锐力量,其推出的DeepSeek-V3和DeepSeek-R1系列模型在开源社区和商业应用中引起了广泛关注。本指南将系统介绍这两款模型的架构特点、安装部署方法以及实际应用…...
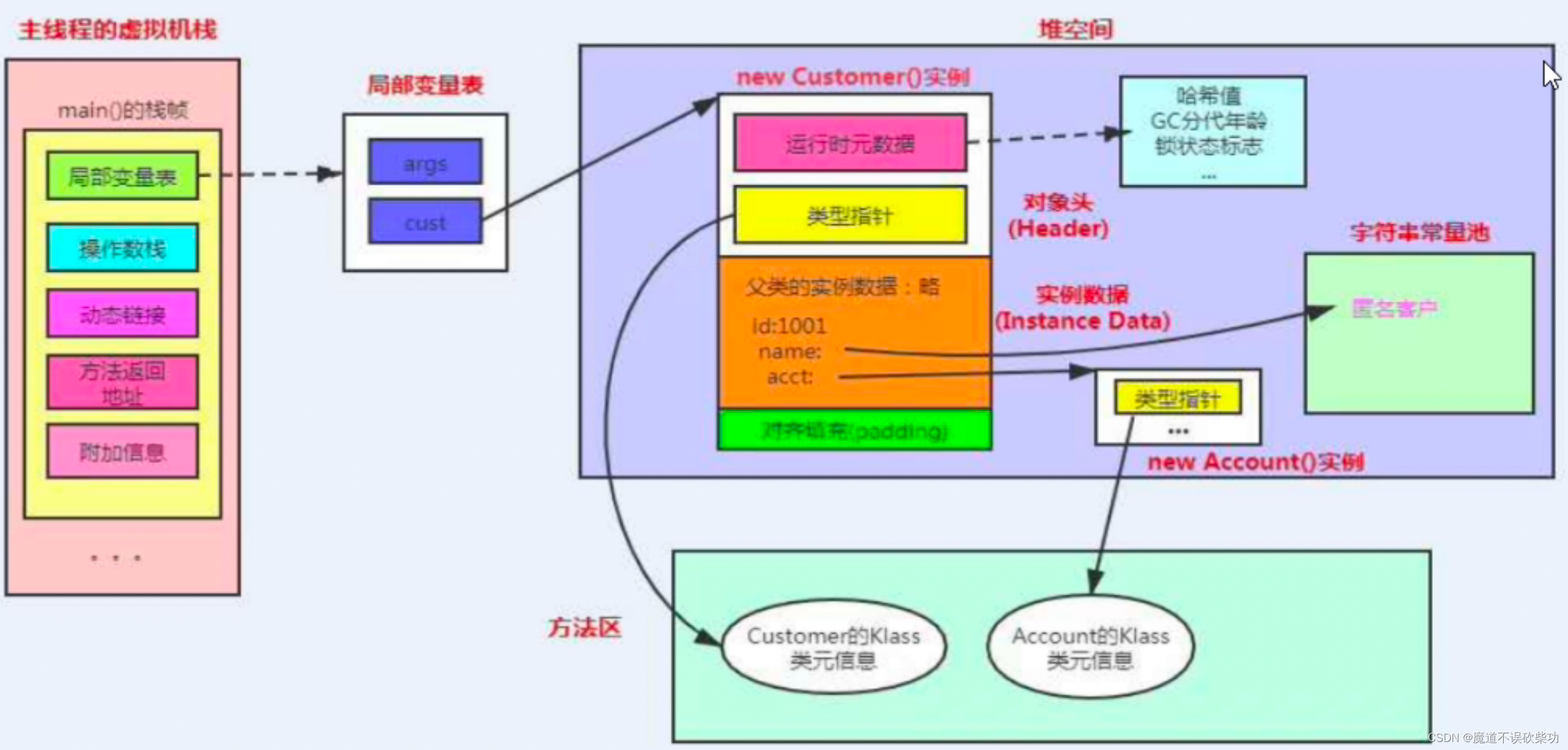
Java 基础(4)—Java 对象布局及偏向锁、轻量锁、重量锁介绍
一、Java 对象内存布局 1、对象内存布局 一个对象在 Java 底层布局(右半部分是数组连续的地址空间),如下图示: 总共有三部分总成: 1. 对象头:储对象的元数据,如哈希码、GC 分代年龄、锁状态…...

Flink回撤流详解 代码实例
一、概念介绍 1. 回撤流的定义 在 Flink 中,回撤流主要出现在使用 Table API 或 SQL 进行聚合或更新操作时。对于那些结果并非单纯追加(append-only)的查询,Flink 会采用“回撤流”模式来表达更新。 回撤流的数据格式ÿ…...
工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明)
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,适用于开发和生产环境。它可以帮助你实时监控 Java 应用的性能指标(如响应时间、SQL 查询、JVM 状态等),无需复杂配置即可快速定位性能瓶颈。 1. 核心功能 功能说明请求性能分析记录 HTTP 请…...

台式电脑插入耳机没有声音或麦克风不管用
目录 一、如何确定插孔对应功能1.常见音频插孔颜色及功能2.如何确认电脑插孔?3.常见问题二、 解决方案1. 检查耳机连接和设备选择2. 检查音量设置和静音状态3. 更新或重新安装声卡驱动4. 检查默认音频格式5. 禁用音频增强功能6. 排查硬件问题7. 检查系统服务8. BIOS设置(可选…...

直播电商革命:东南亚市场的“人货场”重构方程式
一、人设经济3.0:从流量收割到情感基建 东南亚直播战场正经历从"叫卖式促销"到"沉浸式信任"的质变,新加坡市场成为最佳观察样本: 数据印证趋势:Shopee直播用户日均停留28分钟,超短视频平台&#…...

AI图像生成
要通过代码实现AI图像生成,可以使用深度学习框架如TensorFlow、PyTorch或GANs等技术。下面是一个简单的示例代码,演示如何使用GANs生成手写数字图像: import torch import torchvision import torchvision.transforms as transforms import …...

Spring Boot 通过全局配置去除字符串类型参数的前后空格
1、问题 避免前端输入的字符串参数两端包含空格,通过统一处理的方式,trim掉空格 2、实现方式 /*** 去除字符串类型参数的前后空格* author yanlei* since 2022-06-14*/ Configuration AutoConfigureAfter(WebMvcAutoConfiguration.class) public clas…...

【AI论文】OLMoTrace:将语言模型输出追溯到万亿个训练标记
摘要:我们提出了OLMoTrace,这是第一个将语言模型的输出实时追溯到其完整的、数万亿标记的训练数据的系统。 OLMoTrace在语言模型输出段和训练文本语料库中的文档之间找到并显示逐字匹配。 我们的系统由扩展版本的infini-gram(Liu等人…...