分库分表设计与Java实践:从理论到实现
在分布式系统和高并发场景下,单一数据库的性能瓶颈逐渐显现,分库分表成为提升数据库扩展性和性能的重要手段。作为Java开发者,掌握分库分表的设计原则和实现方法,不仅能应对海量数据和高并发的挑战,还能优化系统架构的整体稳定性。本文将从分库分表的基本概念入手,深入探讨其设计策略、实现方式及注意事项,并通过Java代码展示具体的分库分表实践,旨在为开发者提供全面的理论指导和可操作的实践参考。
一、分库分表的背景与意义
1. 为什么需要分库分表?
随着业务规模的增长,数据库面临以下挑战:
- 数据量激增:单表数据量过大(如亿级记录),查询性能下降。
- 并发压力:高并发读写导致锁冲突、IO瓶颈。
- 扩展性受限:单机数据库难以通过简单升级硬件满足需求。
- 可用性问题:单点故障可能导致整个系统不可用。
分库分表通过将数据分散到多个数据库或表中,降低单点压力,提高系统的扩展性和性能。
2. 分库与分表的定义
- 分库:将数据库按业务或规则拆分为多个数据库实例(如订单库、用户库),每个库独立运行。
- 分表:将单表按规则拆分为多个子表(如按用户ID分表),子表结构相同,数据分散。
3. 分库分表的优势
- 性能提升:分散数据和查询压力,减少单表扫描范围。
- 扩展性:支持水平扩展,新增节点即可增加容量。
- 隔离性:不同业务数据隔离,降低故障影响范围。
- 灵活性:可根据业务特点选择不同分片策略。
4. 分库分表的挑战
- 分布式事务:跨库操作难以保证强一致性。
- 查询复杂性:跨库或跨表查询需额外处理(如聚合、分页)。
- 数据迁移:历史数据拆分和迁移成本高。
- 运维难度:多库多表增加维护复杂性。
二、分库分表的设计策略
分库分表的设计需结合业务特点,常见策略包括以下几种:
1. 分库策略
- 按业务分库:
- 将不同业务模块的数据存储到独立数据库,如订单库、用户库、库存库。
- 优点:业务隔离清晰,故障影响范围小。
- 缺点:跨业务查询需额外处理。
- 适用场景:模块化业务系统(如电商平台)。
- 按地域分库:
- 根据用户所在地域分配数据库,如华东库、华南库。
- 优点:降低网络延迟,符合数据主权要求。
- 缺点:跨地域数据同步复杂。
- 适用场景:全球化业务。
- 按时间分库:
- 按时间段(如年、季度)分配数据库,如2023年库、2024年库。
- 优点:适合时间序列数据,归档方便。
- 缺点:跨时间查询需多库合并。
- 适用场景:日志、历史订单。
2. 分表策略
- 范围分表:
- 按字段范围(如ID、时间)分配子表,如
order_0(ID 1-100万)、order_1(ID 100万-200万)。 - 优点:实现简单,数据分布可控。
- 缺点:数据倾斜可能导致热点。
- 适用场景:数据增长平稳的场景。
- 按字段范围(如ID、时间)分配子表,如
- 哈希分表:
- 根据字段(如用户ID)哈希取模分配子表,如
order_0、order_1。 - 优点:数据分布均匀,避免热点。
- 缺点:扩容时需重新分配数据。
- 适用场景:高并发、数据分布均匀的场景。
- 根据字段(如用户ID)哈希取模分配子表,如
- 按时间分表:
- 按时间(如月、日)分表,如
order_202301、order_202302。 - 优点:适合时间相关查询,易于归档。
- 缺点:表数量随时间增长。
- 适用场景:日志、交易记录。
- 按时间(如月、日)分表,如
3. 分库分表的组合
实际项目中,分库和分表往往结合使用。例如:
- 先按业务分库(如订单库、用户库)。
- 在订单库内按用户ID哈希分表(如
order_0、order_1)。
这种方式兼顾了业务隔离和单表性能优化。
三、分库分表的关键问题与解决方案
1. 分片键选择
分片键(如用户ID、订单ID)决定数据如何分配。选择时需考虑:
- 高选择性:分片键应尽量分散数据,避免热点。
- 查询频率:常见查询条件应作为分片键。
- 业务相关性:分片键应与核心业务逻辑相关。
例如,电商系统常以用户ID作为分片键,因为订单查询通常按用户分组。
2. 分布式事务
跨库操作可能导致事务一致性问题。解决方案:
- 两阶段提交(2PC):通过XA协议保证强一致性,但性能较低。
- 最终一致性:使用消息队列(如RocketMQ)异步同步数据。
- 业务补偿:通过回滚机制处理失败事务。
3. 跨库查询
跨库查询(如JOIN、分页)效率低下。解决方案:
- 数据冗余:在分库间复制必要数据(如用户基础信息)。
- 宽表设计:将相关数据合并到一张表,减少关联。
- ElasticSearch:将查询移到搜索引擎处理。
4. 数据迁移
历史数据拆分需平滑迁移。常见方法:
- 双写策略:新数据写入新表,旧数据逐步迁移。
- ETL工具:使用工具(如DataX)批量迁移。
- 停机迁移:适合数据量较小的场景。
5. 动态扩容
哈希分表扩容需重新分配数据。解决方案:
- 一致性哈希:减少数据迁移量。
- 预分片:提前规划足够多的子表(如1024张)。
四、Java实现:基于ShardingSphere的分库分表实践
Apache ShardingSphere 是一个流行的分布式数据库中间件,支持分库分表、读写分离和分布式事务。以下通过Spring Boot和ShardingSphere实现一个分库分表案例,模拟电商系统的订单管理。
1. 案例背景
- 业务需求:
- 订单表按用户ID分库分表,分为2个库(
order_db_0、order_db_1),每个库4张表(order_0到order_3)。 - 支持订单插入、查询和分页。
- 订单表按用户ID分库分表,分为2个库(
- 分片规则:
- 分库:
user_id % 2。 - 分表:
user_id % 4。
- 分库:
2. 环境准备
- 数据库:MySQL 8.0,创建两个库:
CREATE DATABASE order_db_0;
CREATE DATABASE order_db_1;-- 在每个库中创建4张表
CREATE TABLE order_0 (id BIGINT PRIMARY KEY,user_id BIGINT NOT NULL,status VARCHAR(20) NOT NULL,create_time DATETIME NOT NULL
) ENGINE=InnoDB;CREATE TABLE order_1 (...);
CREATE TABLE order_2 (...);
CREATE TABLE order_3 (...);
- 依赖:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.4.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency>
</dependencies>
3. ShardingSphere配置
在 application.yml 中配置分库分表规则:
spring:shardingsphere:datasource:names: db0, db1db0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_0?useSSL=falseusername: rootpassword: passworddb1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_1?useSSL=falseusername: rootpassword: passwordrules:sharding:sharding-algorithms:db-sharding:type: INLINEprops:algorithm-expression: db${user_id % 2}table-sharding:type: INLINEprops:algorithm-expression: order_${user_id % 4}key-generate-strategy:column: idkey-generator-name: snowflakekey-generators:snowflake:type: SNOWFLAKEtables:order:actual-data-nodes: db${0..1}.order_${0..3}table-strategy:inline:sharding-column: user_idalgorithm-name: table-shardingkey-generate-strategy:column: idkey-generator-name: snowflakebinding-tables:- orderdefault-database-strategy:inline:sharding-column: user_idalgorithm-name: db-shardingprops:sql-show: true
mybatis:mapper-locations: classpath:mappers/*.xml
4. 实体与Mapper
实体类:
public class Order {private Long id;private Long userId;private String status;private Date createTime;// Getters and Setterspublic Long getId() { return id; }public void setId(Long id) { this.id = id; }public Long getUserId() { return userId; }public void setUserId(Long userId) { this.userId = userId; }public String getStatus() { return status; }public void setStatus(String status) { this.status = status; }public Date getCreateTime() { return createTime; }public void setCreateTime(Date createTime) { this.createTime = createTime; }
}
Mapper接口:
@Mapper
public interface OrderMapper {void insert(Order order);List<Order> findByUserId(@Param("userId") Long userId);List<Order> findByUserIdAndStatus(@Param("userId") Long userId, @Param("status") String status);
}
Mapper XML:
<!-- resources/mappers/OrderMapper.xml -->
<mapper namespace="com.example.demo.OrderMapper"><insert id="insert" parameterType="com.example.demo.Order">INSERT INTO order (id, user_id, status, create_time)VALUES (#{id}, #{userId}, #{status}, #{createTime})</insert><select id="findByUserId" resultType="com.example.demo.Order">SELECT id, user_id, status, create_timeFROM orderWHERE user_id = #{userId}</select><select id="findByUserIdAndStatus" resultType="com.example.demo.Order">SELECT id, user_id, status, create_timeFROM orderWHERE user_id = #{userId} AND status = #{status}</select>
</mapper>
5. 服务层逻辑
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;public void createOrder(Long userId, String status) {Order order = new Order();order.setUserId(userId);order.setStatus(status);order.setCreateTime(new Date());orderMapper.insert(order);}public List<Order> getUserOrders(Long userId) {return orderMapper.findByUserId(userId);}public List<Order> getUserOrdersByStatus(Long userId, String status) {return orderMapper.findByUserIdAndStatus(userId, status);}
}
6. 测试代码
@SpringBootApplication
public class ShardingDemoApplication implements CommandLineRunner {@Autowiredprivate OrderService orderService;public static void main(String[] args) {SpringApplication.run(ShardingDemoApplication.class, args);}@Overridepublic void run(String... args) {// 插入订单orderService.createOrder(1L, "PENDING"); // 存入 db0.order_1orderService.createOrder(2L, "COMPLETED"); // 存入 db1.order_2orderService.createOrder(5L, "PENDING"); // 存入 db1.order_1// 查询订单List<Order> orders = orderService.getUserOrders(1L);orders.forEach(order -> System.out.println("Order: " + order.getId() + ", Status: " + order.getStatus()));}
}
7. 运行效果
- 插入:订单根据
user_id % 2和user_id % 4分配到对应库和表。 - 查询:ShardingSphere自动路由到正确的库表,合并结果返回。
- 日志:设置
sql-show: true可查看实际SQL:SELECT * FROM order_1 WHERE user_id = 1
五、分库分表的优化与注意事项
1. 性能优化
- 缓存:使用Redis缓存热点数据,减少数据库压力。
- 批量操作:支持批量插入和更新,降低网络开销。
- 读写分离:结合ShardingSphere的读写分离功能,提升读性能。
2. 数据一致性
- 分布式事务:使用ShardingSphere的XA或Seata处理跨库事务。
- 异步同步:通过MQ(如Kafka)实现最终一致性。
- 补偿机制:记录失败操作,定时重试。
3. 运维管理
- 监控:监控各库表的数据分布和查询性能,防止倾斜。
- 备份:为每个分库配置独立备份策略。
- 扩容:预留足够的分片空间(如1024张表)。
4. 常见问题处理
- 数据倾斜:调整分片算法(如一致性哈希)。
- 跨库查询:引入ES或宽表设计。
- ID生成:使用Snowflake算法确保全局唯一。
六、分库分表的未来趋势
- 云原生数据库:如TiDB、CockroachDB,提供内置分库分表支持。
- Serverless架构:云服务(如AWS Aurora)动态分配分片。
- AI优化:通过机器学习预测数据分布,自动调整分片。
- 多模数据库:结合关系型和NoSQL,支持混合分片。
七、实践中的经验教训
- 前期规划:评估数据量和增长速度,预留扩展空间。
- 测试验证:模拟高并发,验证分片性能和一致性。
- 文档化:记录分片规则和路由逻辑,便于维护。
- 渐进实施:从小规模分片开始,逐步扩展。
- 团队协作:DBA与开发者共同制定分片策略。
八、总结
分库分表是应对数据库性能瓶颈和扩展性挑战的有效手段,其设计需平衡性能、一致性和运维成本。本文从分库分表的基本概念出发,分析了按业务、范围、哈希等分片策略,探讨了分布式事务、跨库查询等关键问题,并通过ShardingSphere的Java实践展示了一个完整的订单分库分表实现。代码示例覆盖了配置、插入、查询等核心功能,为开发者提供了可直接运行的参考。我!
相关文章:

分库分表设计与Java实践:从理论到实现
在分布式系统和高并发场景下,单一数据库的性能瓶颈逐渐显现,分库分表成为提升数据库扩展性和性能的重要手段。作为Java开发者,掌握分库分表的设计原则和实现方法,不仅能应对海量数据和高并发的挑战,还能优化系统架构的…...

P8667 [蓝桥杯 2018 省 B] 递增三元组
P8667 [蓝桥杯 2018 省 B] 递增三元组 题目描述 给定三个整数数组 A [ A 1 , A 2 , ⋯ , A N ] A [A_1, A_2,\cdots, A_N] A[A1,A2,⋯,AN], B [ B 1 , B 2 , ⋯ , B N ] B [B_1, B_2,\cdots, B_N] B[B1,B2,⋯,BN], C [ C 1 , C 2 , …...
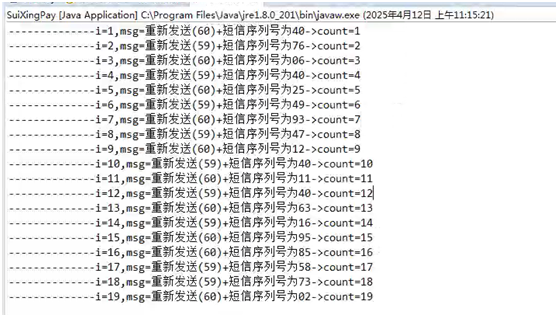
【随行付-注册安全分析报告-无验证方式导致隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 1. 暴力破解密码,造成用户信息泄露 2. 短信盗刷的安全问题,影响业务及导致用户投诉 3. 带来经济损失,尤其是后付费客户,风险巨大,造…...
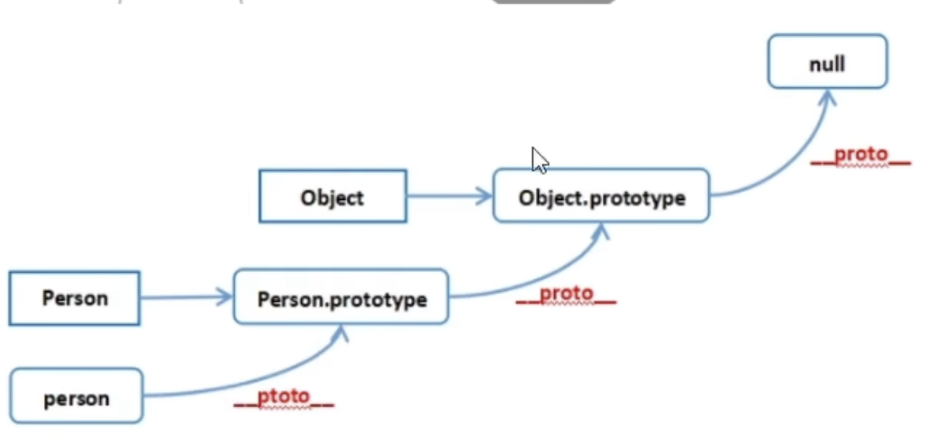
什么是原型、原型链?
一、原型 每个函数都有一个prototype属性,称之为原型,也称为原型对象。 原型可以放一些属性和方法,共享给实例对象使用。原型可以用作继承 二、原型链 对象都有_proto_属性,这个属性指向它的原型对象,原型对象也是…...

前端性能优化实战:从 Webpack 到 Vite 的全栈提速方案
一、引言:前端性能优化的核心挑战 在单页面应用(SPA)和复杂前端项目日益普及的今天,构建工具的选择直接影响着开发效率与最终产物性能。传统构建工具如 Webpack 虽然功能强大,但随着项目规模扩大,逐渐暴露出打包速度慢、配置复杂度高、开发阶段内存占用大等问题。本文将…...
ChatGPT的GPT-4o创建图像Q版人物提示词实例展示
最近感觉GPT-4o发布的新功能真的强大,所以总结了一些提示词分享给大家,大家可以去试试,玩法多多,可以用GPT-4o生成图片,然后用可灵进行图生视频,就能去发布视频了!接下来和笔者一起来试试&#…...

埃隆·马斯克与开源:通过协作重塑创新
李升伟 编译 埃隆马斯克以颠覆性创新闻名于世。从特斯拉(Tesla)、SpaceX、Neuralink到无聊公司(The Boring Company),他的商业版图始终围绕解决全球复杂挑战展开。然而,一个较少被讨论的维度是:…...

StringBuffer类基本使用
文章目录 1. 基本介绍2. String VS StringBuffer3. String和StringBuffer相互转换4. StringBuffer类常见方法5. StringBuffer类测试 1. 基本介绍 java.lang.StringBuffer 代表可变的字符序列,可以对字符串内容进行增删很多方法与String相同,但StringBuf…...
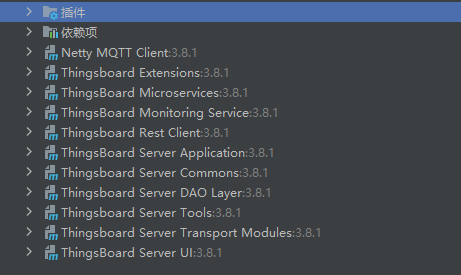
基于 Maven 构建的 Thingsboard 3.8.1 项目结构
一、生命周期(Lifecycle) Maven 的生命周期定义了项目构建和部署的各个阶段,图中列出了标准的生命周期阶段: clean:清理项目,删除之前构建生成的临时文件和输出文件。validate:验证项目配置是否…...
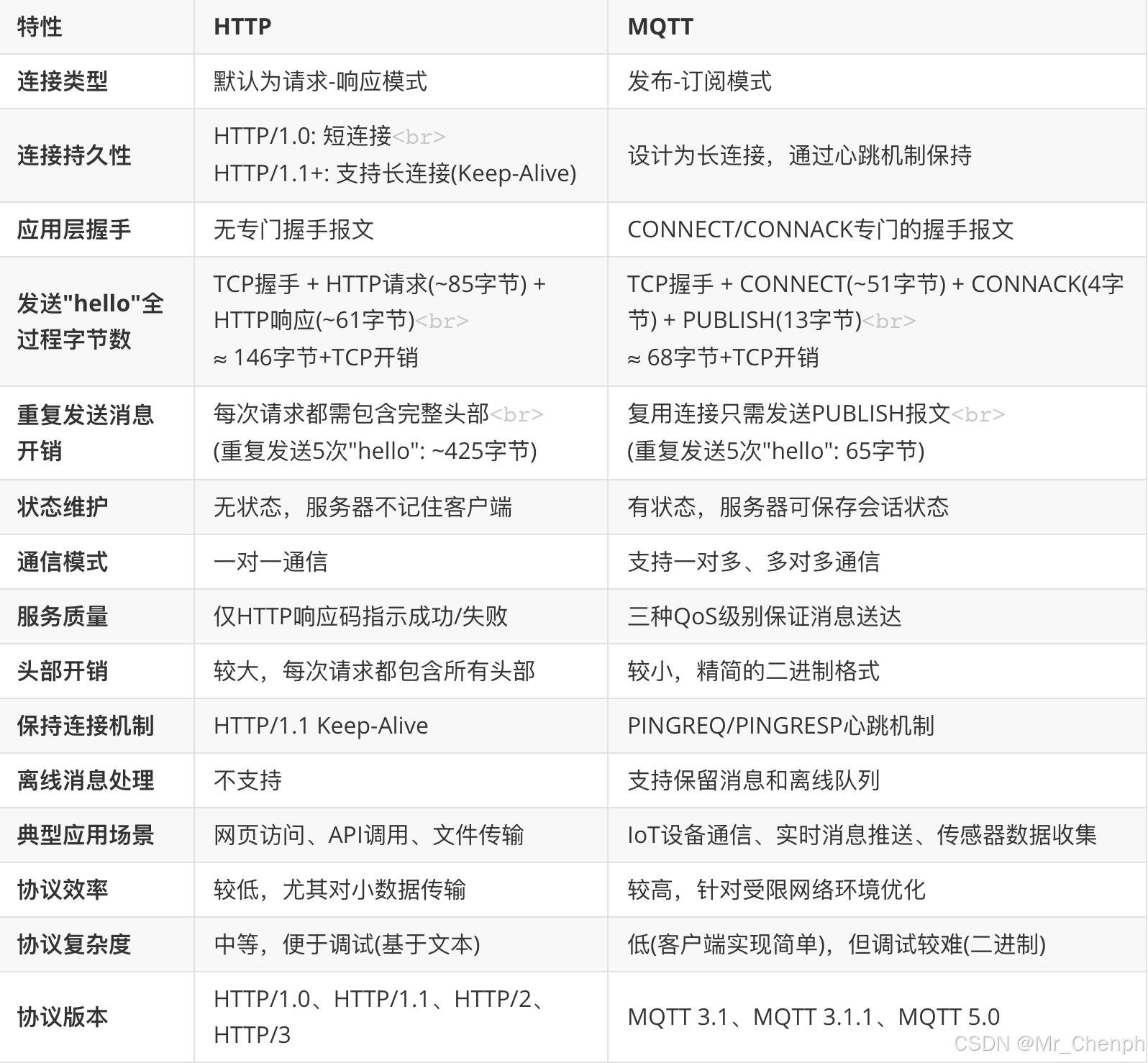
为啥物联网用MQTT?
前言 都说物联网用MQTT,那分别使用Http和Mqtt发送“Hello”,比较一下就知道啦 HTTP HTTP请求报文由请求行、头部字段和消息体组成。一个最简单的HTTP POST请求如下: POST / HTTP/1.1 Host: example.com Content-Length: 5 Content-Type: …...

《分布式软总线牵手云服务,拓展应用新维度》
分布式软总线与云服务的融合,正掀起一场前所未有的变革,重塑着我们工作、生活和交互的方式。二者的结合,犹如天作之合,不仅打破了设备与数据之间的壁垒,更开启了一系列令人瞩目的全新应用场景。 分布式软总线…...

十七、TCP编程
TCP 编程是网络通信的核心,其 API 围绕面向连接的特性设计,涵盖服务端和客户端的交互流程。以下是基于 C 语言的 TCP 编程核心 API 及使用流程的详细解析: 核心 API 概览 函数角色描述socket()通用创建套接字,指定协议族…...

DeepSeek vs Grok vs ChatGPT:三大AI工具优缺点深度解析
一、DeepSeek:低成本与中文专精的本地化AI 优点 中文处理能力卓越 DeepSeek针对中文语法和文化背景进行了深度优化,尤其在古文翻译、诗歌创作和技术文档生成中表现突出,远超ChatGPT的中文支持能力。高效推理与低成本 采用混合专家ÿ…...

微信小程序中的openid的作用
微信小程序中的openid的作用 引言 在当今数字化时代,用户体验成为了产品成功与否的关键因素之一。微信小程序作为连接用户与服务的重要桥梁,在提升用户体验方面发挥着重要作用。其中, openid(开放身份标识符)是微信小…...

spring--声明式事务
声明式事务 1、回顾事务 要么都成功,要么都失败! 事务在项目开发中,十分重要,涉及数据的一致性问题 确保完整性和一致性 事务ACID: 原子性:事务是原子性操作,由一系列动作组成,…...
小甲鱼第004讲:变量和字符串(下)| 课后测试题及答案
问答题: 0. 请问下面代码有没有毛病,为什么? 请问下面代码为什么会出错,应该如何解决? 答:这是由于在字符串中,反斜杠()会与其随后的字符共同构成转义字符。 为了避免这种不测情况的发生,我们可以在字符串的引号前面…...

MergeX亮相GTC2025:开启全球广告流量交易新篇章
全球流量盛宴GTC2025深圳启幕,共探出海新蓝海 2025年4月24日至25日,GTC2025全球流量大会将在深圳福田会展中心9号馆隆重召开。作为跨境出海领域内规模最大、资源最丰富、产业链最完备的年度盛会,此次大会将汇聚众多行业精英,共同探…...
Python可变与不可变类型内存机制解密:从底层原理到工程实践)
Python(10.2)Python可变与不可变类型内存机制解密:从底层原理到工程实践
目录 一、类型特性引发的内存现象1.1 电商促销活动事故分析1.2 内存机制核心差异 二、内存地址追踪实验2.1 基础类型验证2.2 复合对象实验 三、深度拷贝内存分析3.1 浅拷贝陷阱3.2 深拷贝实现 四、函数参数传递机制4.1 默认参数陷阱4.2 安全参数模式 五、内存优化最佳实践5.1 字…...

STM32(基于标准库)
参考博客:江科大STM32笔记 Stm32外设 一、GPIO 基础 GPIO位结构 I/O引脚的保护二极管是对输入电压进行限幅的上面的二极管接VDD, 3.3V,下面接VSS, 0V,当输入电压 >3.3V 那上方这个二极管就会导通,输入电压产生的电流就会大部分充入VD…...

国家优青ppt美化_青年科学基金项目B类ppt案例模板
国家优青 国家优青,全称“国家优秀青年基金获得者”。2025改名青年科学基金B类。 作为自然基金人才资助类型,支持青年学者在基础研究方面自主选择研究方向开展创新研究。它是通往更高层次科研荣誉的重要阶梯,是准杰青梯队。 / WordinPPT /…...
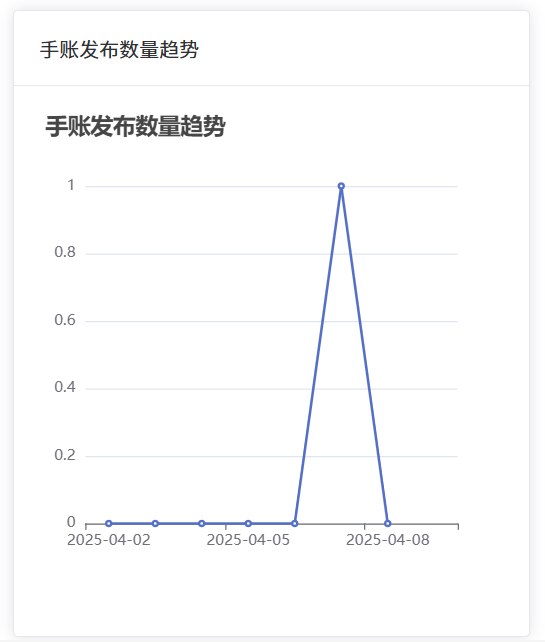
解决 ECharts 图表无数据显示问题
问题: 在开发项目时,后端明明已经成功返回了数据,但在展示手账发布数量趋势和树洞帖子发布数量趋势的 ECharts 图表中,却只有坐标轴,没有任何数据显示。 以我的VUE项目开发可视化面板为例,下面将详细分析可…...

spacy安装失败报错
报错 使用命令pip install spacy安装spacy时总是报错(python -m pip install spacy方式安装同样报错) 解决办法 使用conda安装,conda能够避免很多不必要的依赖包。 命令:conda install spacy 安装成功列表展示...
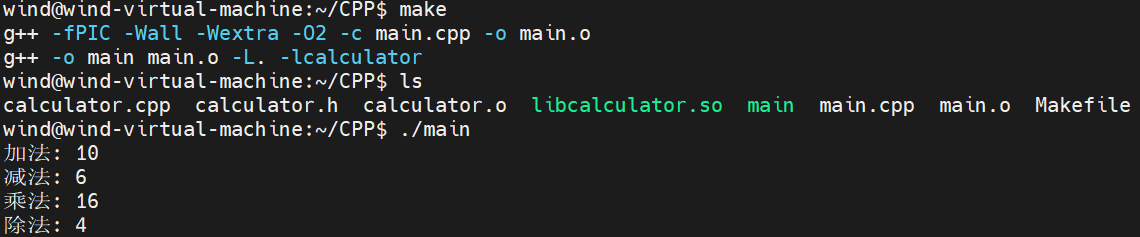
C++在Linux上生成动态库并调用接口测试
加减乘除demo代码 项目结构 CPP/ ├── calculator.cpp ├── calculator.h ├── main.cpp 头文件 #ifndef CALCULATOR_H #define CALCULATOR_H#ifdef __cplusplus extern "C" {#endifdouble add(double a, double b);double subtract(double a, double b…...

第三篇:Python数据结构深度解析与工程实践
第一章:列表与字典 1.1 列表的工程级应用 1.1.1 动态数组实现机制 Python列表底层采用动态数组结构,初始分配8个元素空间,当空间不足时按0,4,8,16,25,35...的公式扩容,每次扩容增加约12.5%的容量 通过sys模块可验证扩容过程: import sys lst = [] prev_size = 0 for …...
前端性能测试工具 —— WebPageTest
测试工具介绍 WebPageTest 是一个用于测量和分析网页性能的工具。它提供了详细的诊断信息,帮助用户了解网页在不同条件下的表现。用户可以选择全球不同的测试地点,使用真实的浏览器,并自定义网络条件进行测试。WebPageTest 还支持核心网络指…...

北邮LLMs在导航中的应用与挑战!大模型在具身导航中的应用进展综述
作者:Jinzhou Lin, Han Gao, Xuxiang Feng, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, Shibiao Xu 单位:北京邮电大学人工智能学院,中国科学院自动化研究所多模态人工智能系统国家重点实验室,中科院空间信息研究所…...

Windows下ElasticSearch8.x的安装步骤
下载ElasticSearch:https://www.elastic.co/downloads/elasticsearch (我下载的是目前最新版8.17.4)解压ElasticSearch 进入到ElasticSearch的bin目录下双击elasticsearch.bat 弹出控制台并开始执行,在这一步会输出初始账号和密码…...

【高性能缓存Redis_中间件】一、快速上手redis缓存中间件
一、铺垫 在当今的软件开发领域,消息队列扮演着至关重要的角色。它能够帮助我们实现系统的异步处理、流量削峰以及系统解耦等功能,从而提升系统的性能和可维护性。Redis 作为一款高性能的键值对数据库,不仅提供了丰富的数据结构,…...

AI Agent入门指南
图片来源网络 一、开箱暴击:你以为的"智障音箱",其实是赛博世界的007 1.1 从人工智障到智能叛逃:Agent进化史堪比《甄嬛传》 青铜时代(2006-2015) “小娜同学,关灯” “抱歉&…...

React 第三十节 使用 useState 和 useEffect Hook实现购物车
不使用 redux 实现 购物车案例 使用 React 自带的 useState 和 useEffect Hook 即可实现购物车 export default function ShoppingCar() {// 要结算的商品 总数 以及总价const [totalNum, setTotalNum] useState(0)const [totalPerice, setTotalPerice] useState(0)// 商品…...