北邮LLMs在导航中的应用与挑战!大模型在具身导航中的应用进展综述

-
作者:Jinzhou Lin, Han Gao, Xuxiang Feng, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, Shibiao Xu
-
单位:北京邮电大学人工智能学院,中国科学院自动化研究所多模态人工智能系统国家重点实验室,中科院空间信息研究所,齐鲁工业大学教育部计算力网络与信息安全重点实验室,山东计算机科学基础研究中心山东省计算机网络重点实验室
-
论文标题:Advances in Embodied Navigation Using Large Language Models: A Survey
-
论文链接:https://arxiv.org/pdf/2311.00530
-
项目主页:https://github.com/Rongtao-Xu/Awesome-LLM-EN
主要贡献
-
论文对LLMs在导航任务中的应用进行了全面综述,比较了基于LLM的导航模型与非LLM模型的优缺点,帮助读者了解当前的研究进展。
-
深入分析了常用的导航数据集,讨论了它们的适用性、问题和局限性,为研究人员选择和应用数据集提供了实用建议。
-
探讨了LLMs在导航应用中面临的技术和理论挑战,并指出了未来的研究方向,包括动态路径优化和算法优化等。
介绍
- 背景与发展:
-
介绍了LLMs在导航领域的快速发展及其在自然语言处理和机器学习中的重要性。
-
特别提到LLMs在少样本规划方面的成功,能够在几乎没有或没有样本数据的情况下有效地进行规划和决策。
-
- 技术挑战:
-
尽管取得了显著成就,但在将LLMs应用于导航时仍存在许多技术和理论挑战。
-
包括如何同时整合文本、图像和其他传感器数据,减少实时应用的延迟,以及在不牺牲性能的情况下提高训练效率。
-
- 研究方法:
-
为了应对这些挑战,研究者采用了多种方法,如机器学习、深度学习和进化算法,以及其他视觉-语言模型来增强LLMs的多模态数据融合能力。
-
- 应用优势:
-
论文指出,LLMs在导航任务中表现出色,特别是在路径规划、环境理解和动态调整任务中。
-
LLMs的强大语言和图像处理能力使其成为导航系统的宝贵工具。
-
- 研究目标:
-
论文的主要目标是探索LLMs在导航模型中的应用,提供全面的知识和资源给研究人员和从业者。
-
与其他相关综述相比,本文专注于LLMs在导航领域的应用,分析现有LLM导航模型的优缺点,并与传统的非LLM模型进行比较。
-
背景
大语言模型
-
发展历程:LLMs代表了自然语言处理(NLP)和机器学习领域的重要里程碑。它们被设计用于处理和生成自然语言,通常在大规模文本数据上进行预训练,以捕捉语言的语法结构、词间关系和上下文细微差别。
-
关键技术:LLMs采用Transformer架构,利用自注意力机制有效处理长距离依赖。它们通过预训练和微调的方式适应各种任务,展现出在自然语言生成、翻译、摘要和问答等方面的强大能力。
-
演变:从早期的Bag-of-Words(BoW)到N-grams和决策树,再到Word2Vec和GloVe的词嵌入模型,LLMs的演变展示了自然语言处理技术的进步。
-
应用:LLMs已广泛应用于聊天机器人、自动写作、问答系统和多模态学习等领域,展示了其在人工智能中的巨大潜力。
具身智能
-
定义:具身智能关注于开发与环境紧密互动的智能智能体,强调智能从根本上是从智能体与其环境的互动中产生的。
-
多学科融合:该领域融合了神经科学、心理学、机器人学和人工智能等多个学科,旨在模拟智能行为。
-
LLMs的应用:LLMs与具身智能的结合成为一个热点话题,利用LLMs的丰富知识和强大的NLP能力,将人类指令转化为物理智能体可理解的格式。
-
多模态融合:通过整合图像、点云和语音提示等多模态信息,具身智能体能够更全面地理解其环境,实现更复杂的任务。
LLMs在具身智能中的应用
-
具身语言理解:LLMs用于将抽象的语言符号与物理世界中的实体、动作或状态相结合,适用于需要真实世界交互的应用,如机器人控制和人机交互。
-
少样本规划:LLMs在少样本规划中表现出色,能够在新的任务中进行有效的规划和决策,而无需大量样本数据。
-
具身导航:LLMs在具身导航中的应用通过多模态融合、深度学习算法和强化学习方法,提高了导航任务的效率和适应性。
基于大模型的具身智能体

基于大模型的具身语言理解
具身语言理解是指将语言模型处理的抽象符号与物理世界中的具体实体、动作或状态相结合的过程。这一领域对于需要与现实世界互动的应用至关重要,例如机器人控制和人机交互。
-
目标:LLMs在这一领域的应用旨在实现语言与现实世界的对接,使模型能够理解和执行具体的物理操作。
-
技术挑战:LLMs通常在文本生成或分类方面表现出色,但在处理具体实体或现实世界情况时存在局限。它们缺乏基础知识和在交互式环境中处理相关概念的能力。
-
研究策略:为了克服这些挑战,研究者采用了多种策略,包括微调预训练模型、使用强化学习算法进行复杂环境中的决策,以及设计专门的多模态学习架构。
-
应用前景:尽管面临技术挑战,LLMs在具身语言理解中的应用具有巨大的潜力,特别是在机器人操作和人机交互等需要高度交互性的场景中。
基于大模型的少样本规划
-
少样本规划是一种机器学习技术,旨在通过少量样本数据进行有效的规划和决策。LLMs在这一领域的应用展示了其在新任务中的快速适应能力。
-
优势:LLMs在零样本和少样本学习中表现出色,能够在没有大量样本数据的情况下进行泛化。这使得它们在需要快速适应新任务的场景中非常有用。
-
应用场景:LLMs在导航任务中特别有用,能够处理自然语言查询并生成可执行的行动计划。这对于在视觉丰富的环境中执行复杂任务至关重要。
-
研究进展:研究者通过引入方法如Llama-Planner、CoT(Chain-of-Thought)和LLM-DP等,进一步提升了LLMs在少样本规划中的表现。
-
未来方向:随着技术的进步,LLMs在少样本规划中的应用将继续扩展,特别是在需要快速适应和决策的场景中。
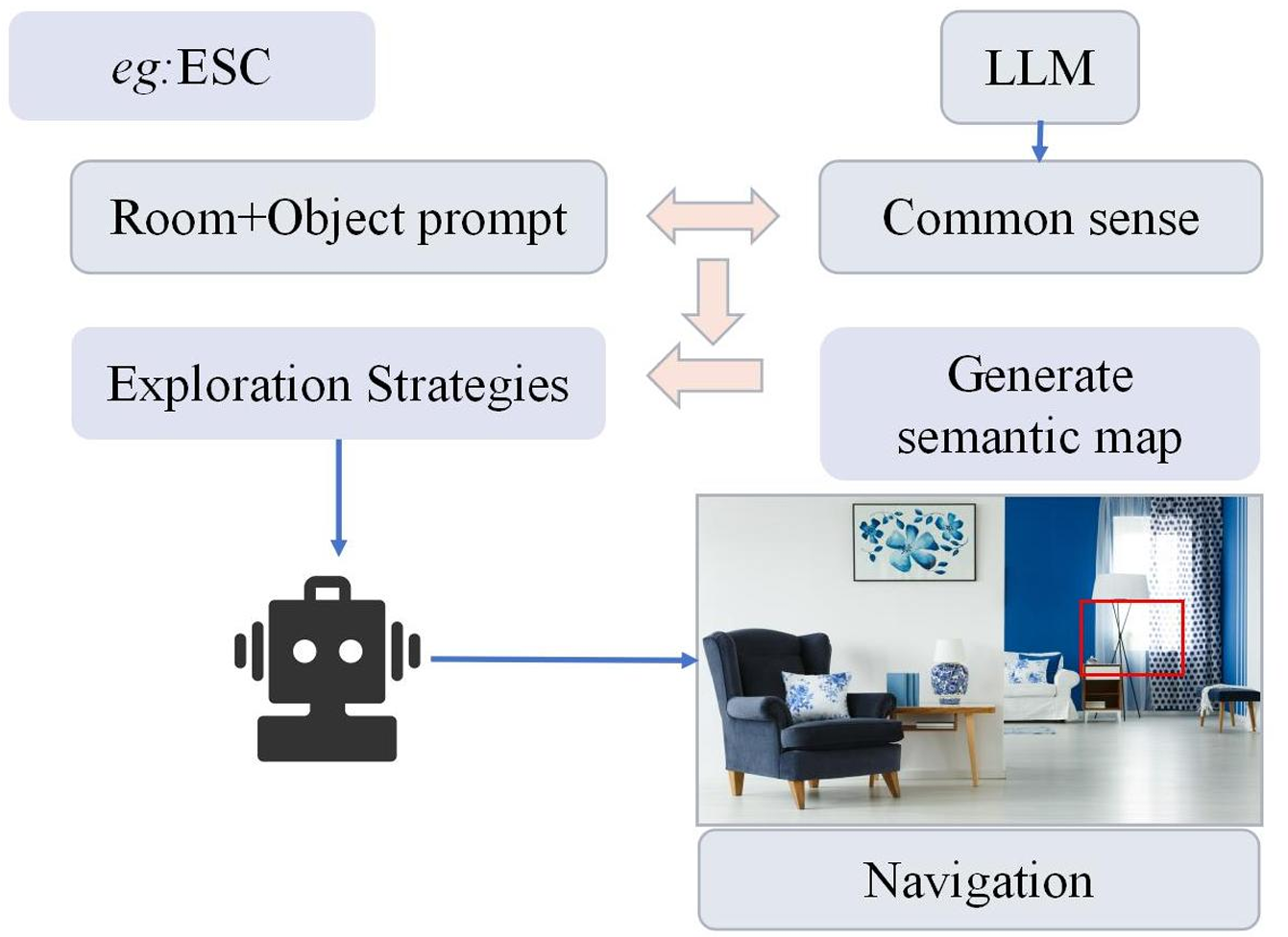
具身导航
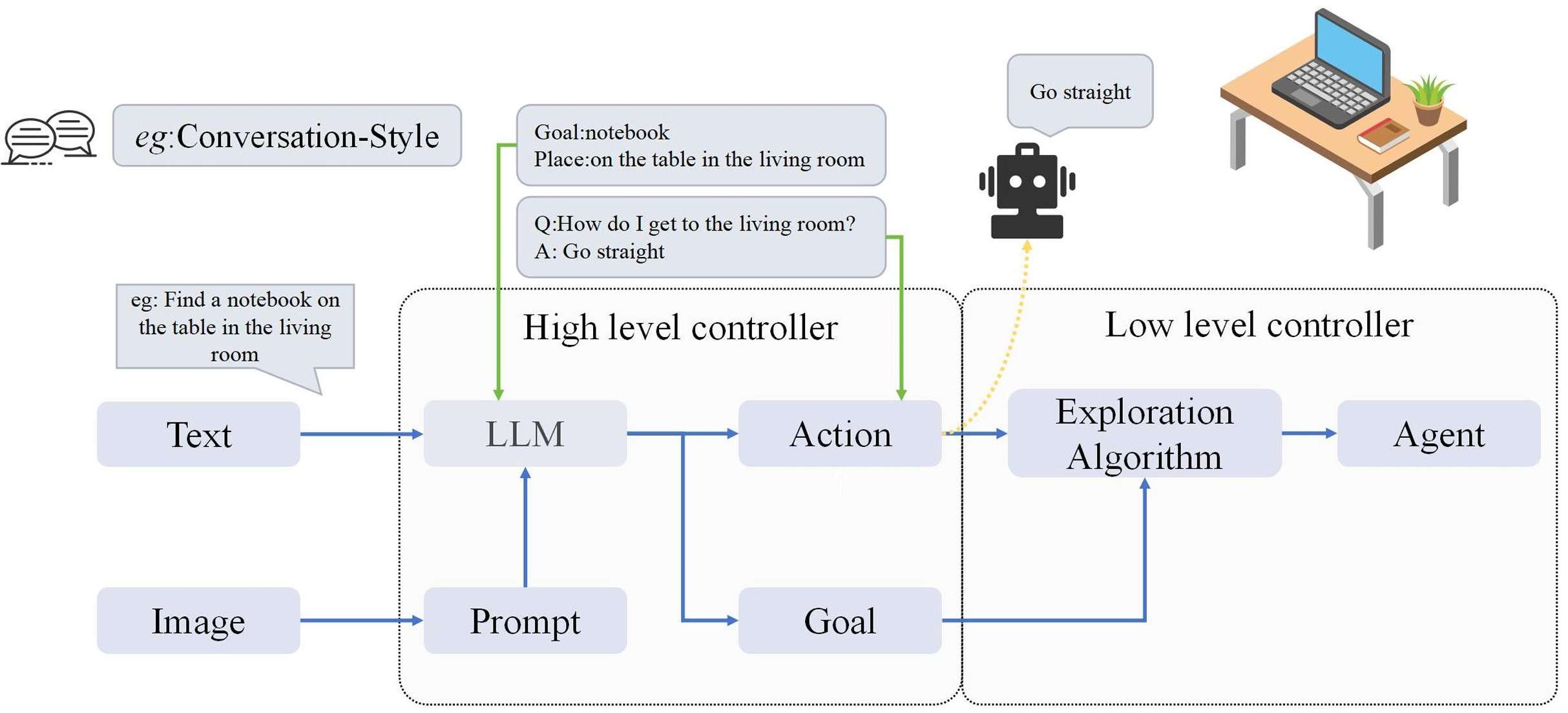
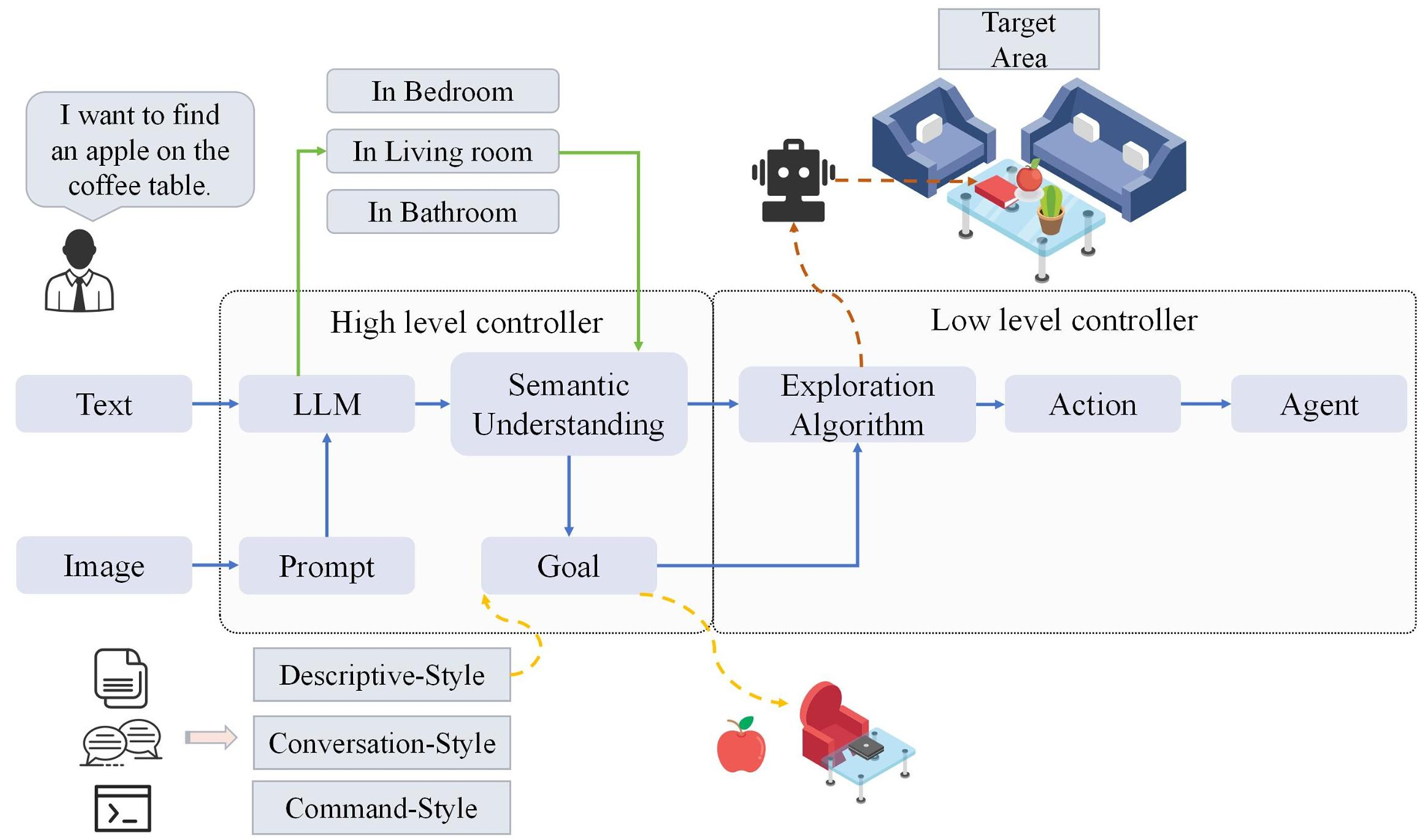
LLM发挥的作用
-
多模态融合:
-
导航模型通过结合视觉、语言和听觉数据来提高其性能。具体来说,这些模型使用LLMs来处理复杂的语言指令,并结合视觉系统来准确解释和响应环境。
-
通过多模态融合,模型能够更好地理解和适应复杂的环境,提供更准确的导航结果。
-
-
环境上下文理解与决策:
-
导航模型通过深度学习算法来增强对环境上下文的理解和决策能力。LLMs的高级语言理解能力帮助模型更好地把握任务要求,并在导航过程中避开障碍物。
-
这些模型能够根据环境的变化做出调整,以提高导航的效率和准确性。
-
-
长期记忆机制:
-
模型采用长期记忆机制来记住过去的导航经验和环境特征,这有助于在复杂或变化的环境中进行有效的路径规划。
-
这种机制使得模型能够在多次导航任务中保持一致性和连贯性,提高其适应性和可靠性。
-
-
用户交互:
-
导航模型具备有效与用户互动的能力,能够处理自然语言输入,并以更自然和人性化的方式沟通。
-
这种交互能力提高了用户体验,并使模型在人机交互场景中更具适应性。
-
-
强化学习:
-
引入强化学习方法,使模型能够通过与环境的持续互动进行自我优化和学习。
-
这种方法允许模型不断调整行为以适应新任务或环境变化,从而提高其在复杂环境中的导航能力。
-
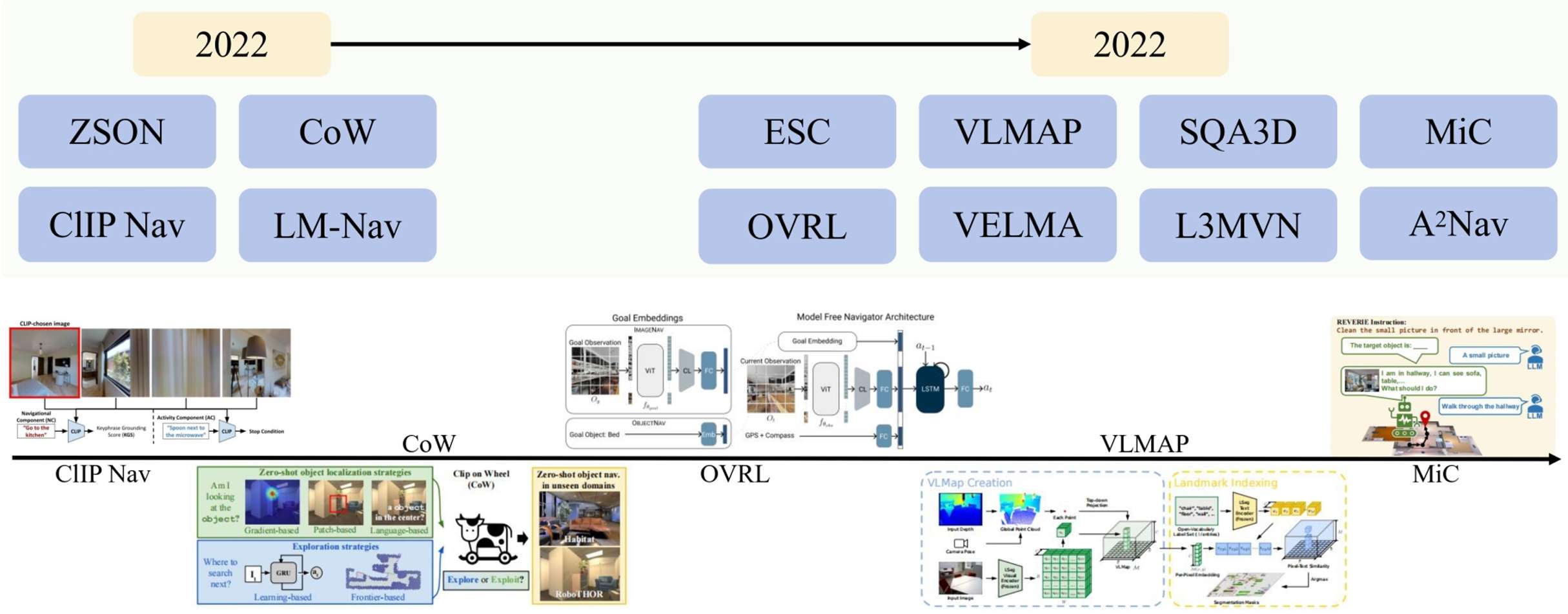
- 基于LLM的模型分类:
-
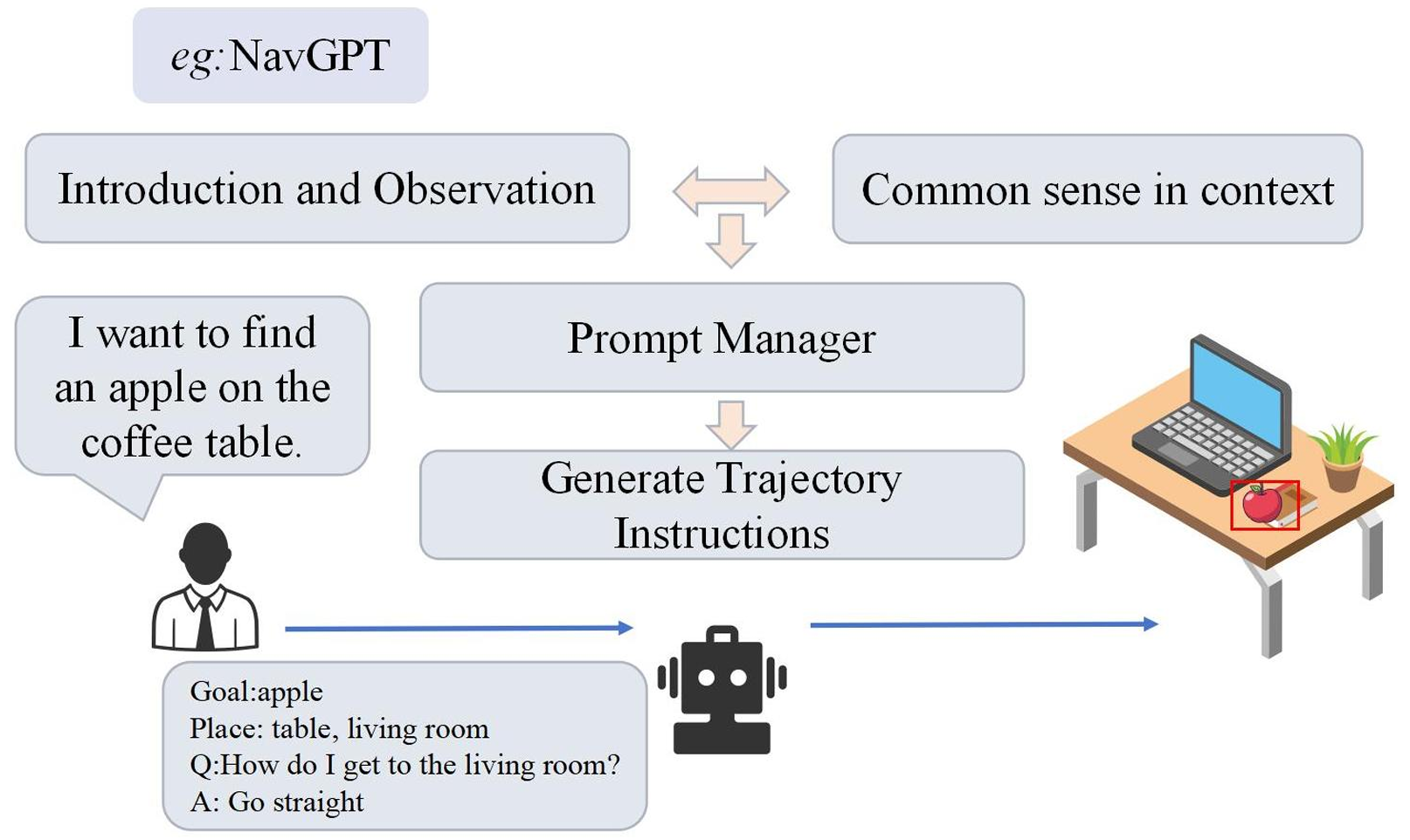
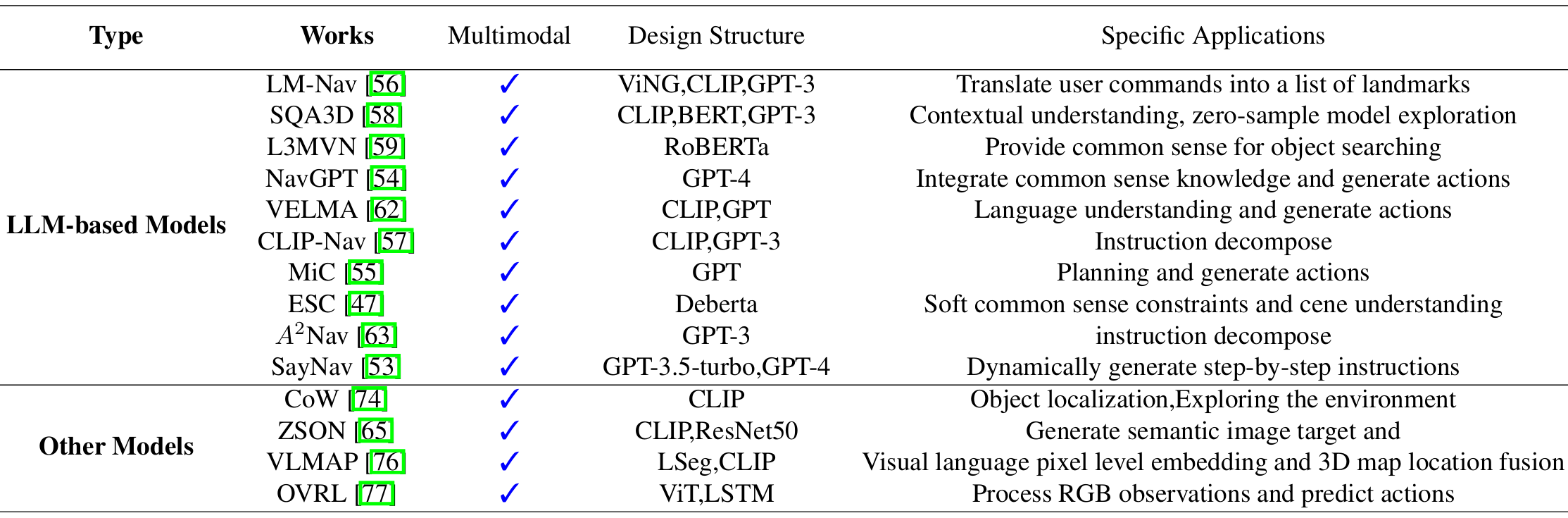
LLM作为规划器:这类模型直接使用LLMs生成动作,通过探索策略引导智能体。例如,CLIP-Nav和NavGPT等模型。
-
LLM用于分析数据:这类模型使用LLMs来分析视觉或文本数据,识别目标相关信息,并据此生成适当的动作。例如,LM-Nav和SQA3D等模型。
-
基于LLM的模型
-
LM-Nav:利用预训练的语言、视觉和动作模型,通过自然语言命令实现复杂的机器人交互。
-
CLIP-Nav:通过视觉锚定和序列到序列模型,实现零样本导航框架。
-
SQA3D:评估智能体在3D场景中的场景理解能力,要求智能体从第一人称视角进行逻辑推理。
-
L3MVN:利用LLMs增强视觉目标导航,解决在陌生环境中自主探索的挑战。
-
ESC:利用常识知识进行零样本对象导航,通过GLIP模型进行开放世界导航。
-
NavGPT:基于LLMs的视觉导航智能体,探索GPT模型的推理能力。
-
VELMA:基于LLMs的具身智能智能体,用于城市街景设置中的导航。
-
A2Nav:关注动作感知的视觉-语言导航方法,分解复杂的导航指令为一系列动作特定的子任务。
-
MiC:用于动态对话的环境感知指令规划器,特别适用于REVERIE数据集。
-
SayNav:利用LLMs的常识知识,实现复杂环境中的导航任务。
非LLM模型
-
论文还介绍了几种非LLM的导航模型,这些模型通过不同的方法实现了导航任务的自动化。
-
例如,CoW(CLIP on Wheels)通过将CLIP应用于具身AI任务,实现了对象定位和探索。
-
ZSON(Zero-shot Object Navigation)通过语义相似性进行目标导航,适用于无标注的3D环境。
-
VLMAP(Visual Language Map)通过结合视觉-语言特征进行自然语言导航。
-
OVRL(Object-Viewpoint Reinforcement Learning)通过任务无关的神经网络架构进行视觉导航。
大模型在具身智能中的其他应用
-
VoxPoser:
-
背景:VoxPoser是一种新颖的方法,利用LLMs指导机器人执行各种任务,而无需预定义的运动原语。
-
方法:通过LLMs,VoxPoser能够从自然语言指令中提取关键线索和约束,生成机器人的运动轨迹。例如,当接收到指令“打开最上面的抽屉,但要小心花瓶”时,VoxPoser能够理解需要抓住抽屉把手并向外拉,同时避免花瓶。
-
应用:这种方法不仅解决了指令执行的问题,还在动态环境中生成了鲁棒的机器人轨迹。通过组装3D值图,机器人可以在真实环境中执行这些动作,而无需额外的训练。
-
特点:VoxPoser的独特之处在于其能够根据自然语言指令在未知场景中进行零样本泛化。
-
-
ALFRED:
-
背景:ALFRED是一个基准和数据集,用于训练和评估模型在具身智能任务中的表现。
-
数据集:该数据集包含25,743个英语指令,对应8,055个专家演示。每个演示大约有50步,总计428,322个图像-动作序列。
-
任务:ALFRED的任务非常复杂,通常需要智能体执行一系列不可逆的状态更改任务,如打破物体或将食物从一个容器转移到另一个容器。
-
特点:ALFRED超越了现有的视觉-语言任务数据集,提供了更丰富的专家演示,适用于模拟环境中更复杂的序列长度、动作空间和语言复杂性。
-
-
PaLM-E:
-
背景:PaLM-E是一个多模态语言模型,擅长整合视觉、语言和传感器模态,以促进复杂现实世界挑战的更接地气的推理。
-
训练:通过在多样化机器人任务和数据集上并行训练,PaLM-E表现出强大的迁移学习能力。
-
应用:PaLM-E在机器人规划、视觉问答、图像描述和语言任务中表现出色。它能够在多智能体决策和迁移学习中表现出色。
-
特点:PaLM-E通过直接整合连续传感器模态,增强了语言模型的能力,使其能够进行更接地气的推理。
-
-
RT-2:
-
背景:RT-2是一个前沿模型,旨在将网络视觉和语言洞察力转化为机器人控制功能。
-
组成:由预训练的视觉-语言模型和基于强化学习的机器人控制策略组成。
-
应用:RT-2在模拟和真实环境中表现出色,能够执行复杂的操作,如物体操作和开门任务。
-
特点:RT-2通过将大型视觉语言模型直接整合到微观控制器中,增强了其泛化和语义推理能力。
-
具身智能数据集

-
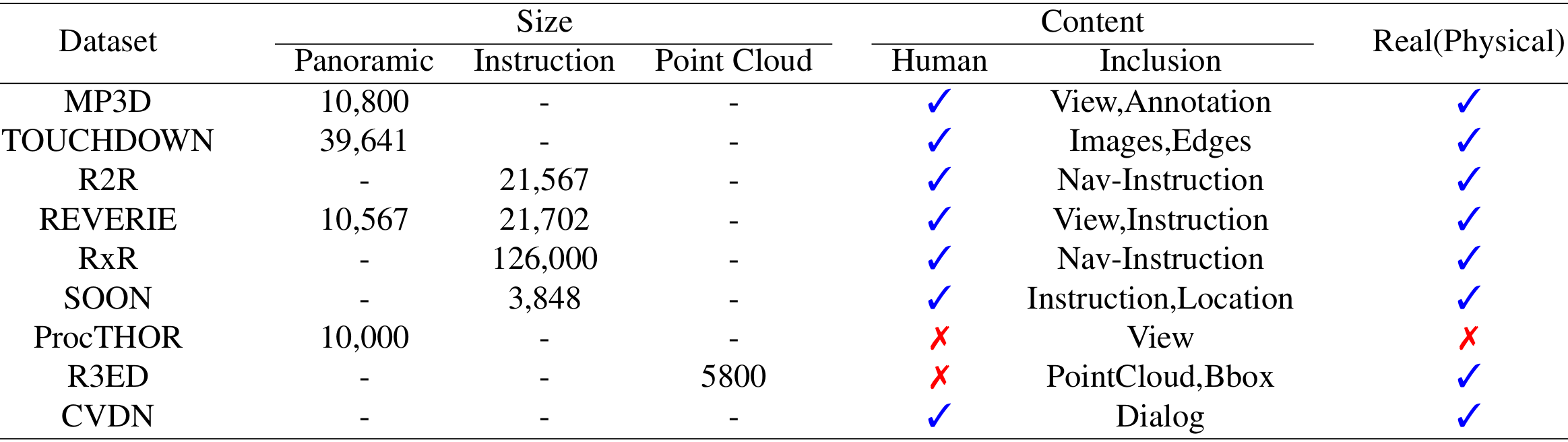
MatterPort3D:
-
背景:MP3D是一个综合性的数据集,主要由RGB-D场景组成,涵盖了10,800个全景视图,来自194,400个RGB-D图像。
-
内容:数据集包含90个广泛的建筑环境,主要用于3D室内环境。它提供了多种数据模态,如RGB图像、深度图像和语义注释。
-
应用:MP3D适用于需要自监督或替代方法的视觉任务,如对象检测、场景分割和3D重建。由于其高分辨率和多样性,它成为了一个重要的基准数据集。
-
-
TOUCHDOWN:
-
背景:TOUCHDOWN是一个专门为导航和空间推理设计的数据集,利用Google Street View构建了一个广阔的户外环境。
-
内容:数据集包含39,641个全景图像和61,319条边,均来自纽约市。每个视点都有一个360度的RGB全景。
-
应用:TOUCHDOWN适用于需要户外导航和空间理解的场景。它通过“寻宝”方法收集数据,适合训练和评估在复杂城市环境中导航的模型。
-
-
Room-to-Room:
-
背景:R2R是一个专为视觉-语言导航(VLN)设计的数据集,扩展了MP3D的数据,增加了大量的自然语言数据。
-
内容:数据集包含一系列在3D室内环境中导航的路径,每个路径都有一系列具体的位置和方向(视点),并配有自然语言指令。
-
应用:R2R适用于需要理解自然语言和复杂决策的导航任务。它提供了一个详细的导航指令集,适合训练和评估在室内环境中导航的模型。
-
-
CVDN:
-
背景:CVDN是一个扩展自R2R的数据集,专注于在模拟的逼真家庭环境中训练导航智能体。
-
内容:数据集包含超过2,000个“人-人”对话,平均每个对话包含约50步,总计428,322个图像-动作序列。
-
应用:CVDN适用于需要理解和生成自然语言的导航任务。它提供了丰富的对话数据,适合训练在人类中心环境中导航的模型。
-
-
REVERIE:
-
背景:REVERIE是一个综合数据集,包含10,567个全景图像和4,140个目标对象,配有多达21,702个众包指令。
-
内容:数据集提供了增强的语义细节,如目标对象的颜色,并包含自然语言指令。
-
应用:REVERIE适用于需要语义理解和复杂指令处理的导航任务。它提供了丰富的目标对象和自然语言指令,适合训练在复杂环境中导航的模型。
-
-
Room-Across-Room:
-
背景:RxR是一个扩展自R2R的多语言数据集,支持多种语言的导航指令。
-
内容:数据集包含多种语言的自然语言导航指令,适用于多语言的视觉-语言导航任务。
-
应用:RxR适用于需要多语言理解和导航的模型,适合训练在多语言环境中导航的模型。
-
-
SOON:
-
背景:SOON是一个基于3D住房环境的语言导航数据集,强调真实图像全景。
-
内容:数据集包含90个住宅设置,每个设置配有一个自然语言指令,详细描述了目标位置。
-
应用:SOON适用于需要高语言复杂性和生态多样性的导航任务。它提供了丰富的语义数据和长指令,适合训练在复杂环境中导航的模型。
-
-
ProcTHOR:
-
背景:ProcTHOR是一个由算法生成的3D住宅场景数据集,用于训练和评估具身AI智能体。
-
内容:数据集包含10,000个算法生成的3D场景,每个场景都有多个对象、纹理变化和光照条件。
-
应用:ProcTHOR适用于需要大规模生成和交互的虚拟环境中的导航任务。它提供了多样化的场景和对象,适合训练在复杂环境中导航的模型。
-
-
R3ED:
-
背景:R3ED是一个包含真实世界室内环境的3D数据集,用于机器人主动视觉学习。
-
内容:数据集包含超过5,800个点云和约22,400个3D边界框,来自七个不同的真实室内环境。
-
应用:R3ED适用于需要长时记忆和真实世界适应性的导航任务。它提供了真实的点云数据,适合训练在复杂环境中导航的模型。
-
-
X-Embodiment:
-
背景:X-Embodiment是一个机器人操作数据集,包含来自22个不同机器人实例的一百万个机器人轨迹。
-
内容:数据集整合了来自34个国际机器人研究实验室的60个预存机器人数据集。
-
应用:X-Embodiment适用于需要跨机器人平台泛化的任务。它提供了多样化的机器人操作数据,适合训练在多机器人环境中操作的模型。
-
挑战与未来发展方向
数据集的挑战:
-
多样性与适用性:不同的数据集具有独特的优势和局限性,适用于不同类型的导航和语言指导任务。例如,MatterPort3D、R2R、RXR和REVERIE适用于室内导航任务,而TOUCHDOWN适用于城市环境。每个数据集在复杂性和多样性方面各有侧重,选择合适的数据集对于特定任务至关重要。
-
数据质量和复杂性:数据集的质量和复杂性会影响模型的训练效果。例如,MP3D提供了高质量的RGB-D图像和3D重建数据,但其复杂性也增加了模型训练和推理的难度。
建模的挑战:
-
数据需求:LLM导航模型需要大量高质量的数据进行训练,不足或错误的数据会影响导航效果。大多数LLM模型依赖于预训练或直接调用的模型,而不是针对特定任务进行训练,这可能影响最终的导航结果。
-
能力限制:LLMs在处理细粒度导航指令和空间方向推断方面存在局限,尤其在需要长期规划和空间推理的任务中表现不佳。此外,LLMs在交互式导航和包含可通行障碍物的环境中适应性较差。
未来发展方向:
-
动态路径优化:未来的研究可能会向动态空间发展,实时调整路径以适应动态目标。这将使导航模型能够更好地应对变化的环境。
-
算法和模型优化:通过使用特定任务的LLM训练和优化算法及模型架构,可以减少资源消耗并提高效率。
-
多模态融合:未来的研究将重点放在多模态数据的融合上,以增强模型的环境感知和决策能力。例如,结合视觉、听觉和触觉信息,使模型能够更好地理解和适应复杂环境。
-
自动驾驶技术的融合:通过融合多模态数据(如GPS和雷达),提供高精度的导航支持,同时改善用户体验。
-
隐私和安全:在数据收集、传输、存储和处理过程中,确保数据安全和用户隐私保护是未来的重要研究方向。需要采取严格的加密、访问控制和认证机制,以防止数据滥用或泄露。
应用前景:
-
多任务学习:未来的研究可能会集中在多任务学习上,开发能够处理多种任务的通用模型。这将提高模型的适应性和泛化能力。
-
创新算法:开发新的算法以优化机器人的行为策略,使其能够适应不断变化的环境。
-
交互适应性:增强模型在复杂环境中的交互适应能力,使其能够更好地理解和响应用户的意图。
总结
-
论文全面回顾了LLMs在具身导航中的应用,分析了现有模型的优缺点,并比较了LLMs基模型与非LLMs模型。
-
论文指出了LLMs在导航任务中的巨大潜力,但也强调了需要解决数据多样性、细粒度导航和空间推理能力等挑战。
-
未来的研究方向包括动态路径优化、算法和模型架构的优化、与自动驾驶技术的融合以及多模态融合和优化算法的开发。
-
总体而言,LLMs在具身导航中具有广阔的应用前景,但仍需克服现有的技术难题。

相关文章:
北邮LLMs在导航中的应用与挑战!大模型在具身导航中的应用进展综述
作者:Jinzhou Lin, Han Gao, Xuxiang Feng, Rongtao Xu, Changwei Wang, Man Zhang, Li Guo, Shibiao Xu 单位:北京邮电大学人工智能学院,中国科学院自动化研究所多模态人工智能系统国家重点实验室,中科院空间信息研究所…...

Windows下ElasticSearch8.x的安装步骤
下载ElasticSearch:https://www.elastic.co/downloads/elasticsearch (我下载的是目前最新版8.17.4)解压ElasticSearch 进入到ElasticSearch的bin目录下双击elasticsearch.bat 弹出控制台并开始执行,在这一步会输出初始账号和密码…...

【高性能缓存Redis_中间件】一、快速上手redis缓存中间件
一、铺垫 在当今的软件开发领域,消息队列扮演着至关重要的角色。它能够帮助我们实现系统的异步处理、流量削峰以及系统解耦等功能,从而提升系统的性能和可维护性。Redis 作为一款高性能的键值对数据库,不仅提供了丰富的数据结构,…...

AI Agent入门指南
图片来源网络 一、开箱暴击:你以为的"智障音箱",其实是赛博世界的007 1.1 从人工智障到智能叛逃:Agent进化史堪比《甄嬛传》 青铜时代(2006-2015) “小娜同学,关灯” “抱歉&…...

React 第三十节 使用 useState 和 useEffect Hook实现购物车
不使用 redux 实现 购物车案例 使用 React 自带的 useState 和 useEffect Hook 即可实现购物车 export default function ShoppingCar() {// 要结算的商品 总数 以及总价const [totalNum, setTotalNum] useState(0)const [totalPerice, setTotalPerice] useState(0)// 商品…...

Git的简介和简单的命令使用介绍
Git 是一种分布式版本控制系统,常用于跟踪文件的变化,协作开发和管理代码版本。以下是 Git 的基本概念和使用方式: 仓库(Repository):Git 仓库是用来存储项目文件和版本历史的地方。可以通过在本地或远程创…...

概念辨析:Redis 多路 I/O 复用和多线程
Redis 多路 I/O 复用是在 Redis 2.0 引入的,而 Redis 多线程是在 Redis 6.0 引入的,两者不是同一个概念。 多路复用的本质还是同步 I/O,因为最终都需要主线程调用 read() 方法把数据拷贝到用户态。 在并发量非常大的情况下,Redi…...
海洋大地测量基准与水下导航系列之八我国海洋水下定位装备发展现状
中国国家综合PNT体系建设重点可概括为“51N”,“5”指5大基础设施,包括重点推进下一代北斗卫星导航系统、积极发展低轨导航增强系统、按需发展水下导航系统、大力发展惯性导航系统、积极探索脉冲星导航系统;“1”是实现1个融合发展࿰…...

计算机系统设计中的一些常用方法
面试中经常被问到: 有一个亿qq号,找出重复的 给你512m内存,找出5g文件中最大的数字 订单超时实现精准关单 … 当然,还有经常遇到的问题: 接口业务逻辑复杂或查数据库慢,相应耗时高 网络因为丢包导致服…...

【征程 6】工具链 VP 示例中 Cmakelists 解读
1. 引言 在文章【征程 6】VP 简介与单算子实操中,介绍了 VP 是什么,并以单算子 rotate 为例,介绍了 VP API 使用方法。在【征程 6】工具链 VP 示例中日志打印解读 中介绍了 VP 单算子示例中用到的日志打印的头文件应该怎么写。接下来和大家一…...

深入解析 Jenkins Agent 的 .jnlp 启动文件
🧩 深入解析 Jenkins Agent 的 .jnlp 启动文件 在 Jenkins 中,通过 JNLP(Java Network Launch Protocol)方式连接 Agent 是一种常见且灵活的方式。你可能曾见过类似这样的命令: java -jar agent.jar -jnlpUrl file:/…...

谷歌开源代理开发工具包(Agent Development Kit,ADK):让多智能体应用的构建变得更简
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

0x01、Redis 主从复制的实现原理是什么?
Redis 主从复制概述 Redis 的主从复制是一种机制,允许一个主节点(主实例)将数据复制到一个或多个从节点(从实例)。通过这一机制,从节点可以获取主节点的数据并与之保持同步。 复制流程 开始同步…...

noscript 标签是干什么的
vue public目录下的 index.html 会有 <noscript> 标签不知道是干吗的。 其实 noscript 标签在不支持或是禁用JavaScript 的浏览器中显示替代的内容。这个元素可以包含任何 HTML 元素。这个标签的用法也非常简单: <noscript><strong>Were sorry …...
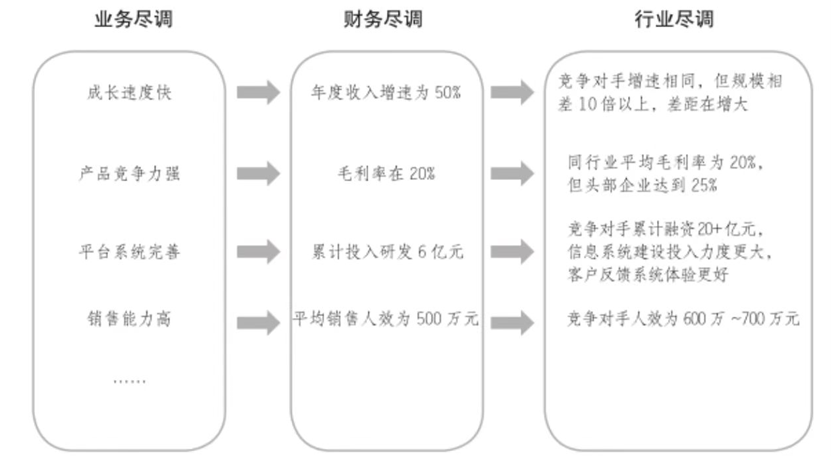
[创业之路-366]:投资尽职调查 - 尽调核心逻辑与核心影响因素:价值、估值、退出、风险、策略
目录 一、VC投资的本质是冒着不确定性风险进行买卖、生意,为了赚取高额回报 1、VC投资的核心本质 2、VC投资的运作机制 3、VC投资的风险与挑战 4、VC投资的底层逻辑 5、总结:VC投资的本质再定义 二、尽调核心逻辑 1、尽调的含义 2、尽调的逻辑方…...

MOP数据库中的EXPLAIN用法
EXPLAIN 是 SQL 中的一个非常有用的工具,主要用于分析查询语句的执行计划。执行计划能展示数据库在执行查询时的具体操作步骤,像表的读取顺序、使用的索引情况、数据的访问方式等,这有助于我们对查询性能进行优化。 语法 不同的数据库系统&…...

Hyprnote开源程序是一款记录和转录您会议的 AI 记事本。 本地优先且可扩展 。
一、软件介绍 文末提供源码下载学习 Hyprnote开源程序是一款记录和转录您会议的 AI 记事本。 从您的原始会议记录中生成强大的摘要,本地优先且可扩展 。使用开源模型 (Whisper & Llama) 离线工作,高度可扩展 ,由插…...

MSCKF及可观性总结
可观性 参考链接 真实VIO系统不能观的维度是4(位置和yaw角),由于EKF的转移和观测Jacobian矩阵的线性化点不同、不可观方向噪声的存在,实际MSCKF不能观的维度变成了3,绕重力轴的旋转(yaw角)被错…...
上篇:新能源轻卡城配物流经济/动力模式量化定义(理论篇)——数学暴力破解工程困局
副标题:用微分方程撕开模式切换本质,用传感器数据重构载重真相 引言:为什么轻卡模式定义比乘用车难10倍? 行业现状痛点: 中国新能源轻卡日均载重波动高达300%(空载0kg→满载4.5吨)某头部车企实…...
Ubuntu22环境下,Docker部署阿里FunASR的gpu版本
番外: 随着deepseek的爆火,人工智能相关的开发变得异常火爆,相关的大模型开发很常见的agent智能体需要ASR语音识别的功能,阿里开源的FunASR几乎是把一个商业的项目放给我们使用了。那么我们项目中的生产环境怎么部署gpu版本的语音识别服务呢?经过跟deepseek的一上午的极限…...

Python 实现最小插件框架
文章目录 Python 实现最小插件框架1. 基础实现项目结构plugin_base.py - 插件基类plugins/hello.py - 示例插件1plugins/goodbye.py - 示例插件2main.py - 主程序 2. 更高级的特性扩展2.1 插件配置支持2.2 插件依赖管理2.3 插件热加载 3. 使用 setuptools 的入口点发现插件3.1 …...
内网邮箱服务器搭建-详解
目录 一、背景 二、搭建邮箱需要具备的基础知识 1、smtp(Simple Mail Transfer Protocol) SMTP工作原理 SMTP 命令 SMTP 协议端口 2、pop3(Post Office Protocol) POP3特点 POP3工作原理 3、imap4(Internet M…...

21 天 Python 计划:使用SQLAlchemy 中的ORM查询
文章目录 准备工作图书表 books分类表 categoriesORM 对象定义 一、根据主键获取记录二、AND 查询三、 常用方法四、OR 查询五、 5. AND 和 OR 并存的查询六、巧用列表或者字典的解包给查询方法传参七、其它常用运算符八、查询指定列九、内连接、外连接9.1 内连接9.2 外连接9.3…...

使用 LLaMA-Factory 微调 llama3 模型(二)
使用 LLaMA-Factory 微调 llama3 模型 1. LLaMA-Factory模型介绍 https://github.com/hiyouga/LLaMA-FactoryLLaMA-Factory 是一个用于大型语言模型(LLM)微调的工具,它旨在简化大型语言模型的微调过程, 使得用户可以快速地对模型…...

并发编程--条件量与死锁及其解决方案
并发编程–条件量与死锁及其解决方案 文章目录 并发编程--条件量与死锁及其解决方案1.条件量1.1条件量基本概念1.2条件量的使用 2. 死锁 1.条件量 1.1条件量基本概念 在许多场合中,程序的执行通常需要满足一定的条件,条件不成熟的时候,任务…...
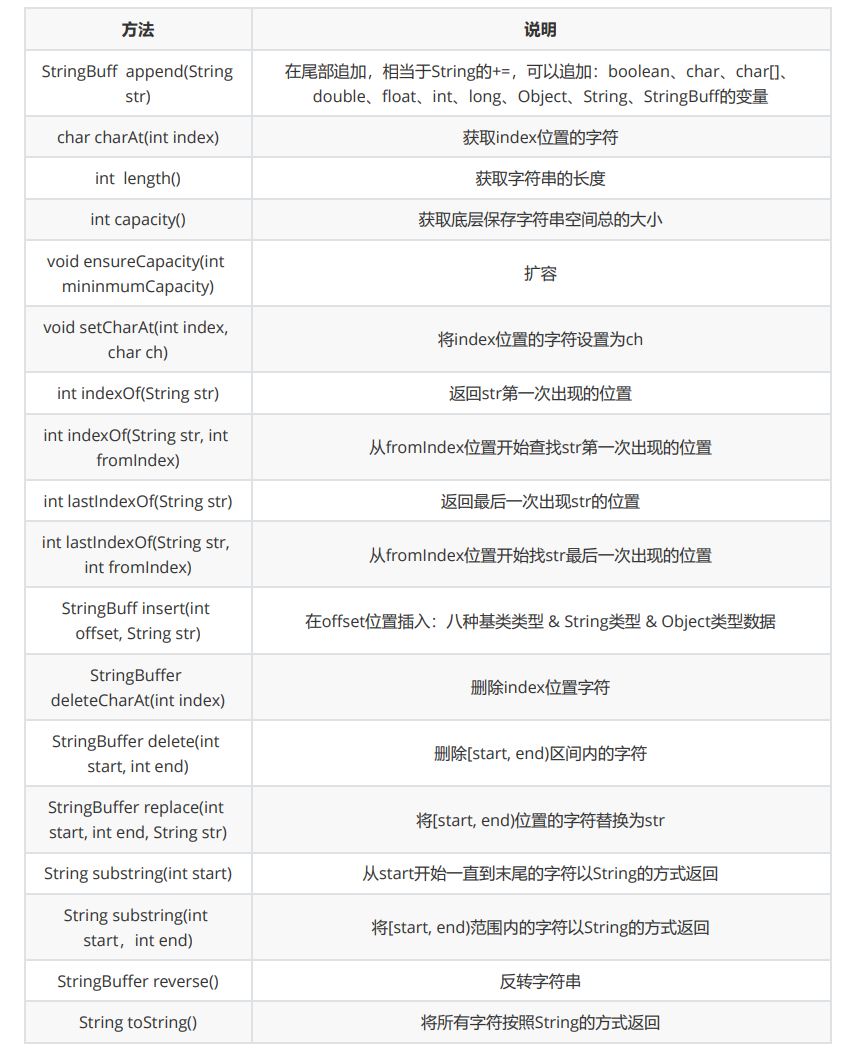
JAVA SE 自我总结
目录 1. 字面常量 2. 数据类型 3. 变量 4. 类型转换 5. 实参和形参的关系 6. 数组 6.1 数组的概念 6.2 动态初始化 6.3 静态初始化 7. 数据区 编辑 8. 数组的拷贝 8.1 赋值拷贝 8.2 方法拷贝 9. 代码块 10. 内部类 10.1 实例内部类 10.2 静态内部类 10.3 …...
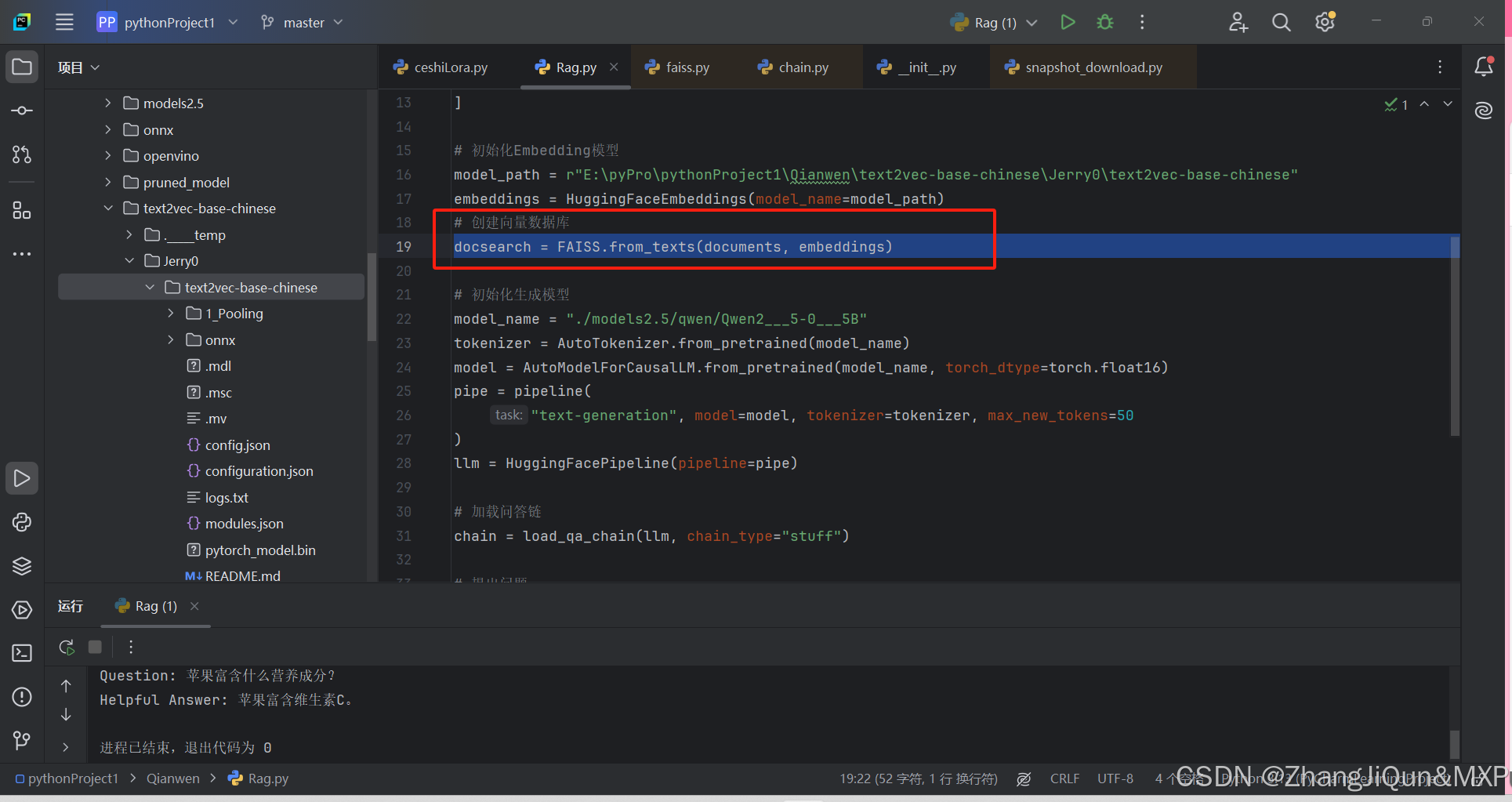
RAG创建向量数据库:docsearch = FAISS.from_texts(documents, embeddings)
RAG创建向量数据库:docsearch = FAISS.from_texts(documents, embeddings) 代码解释 docsearch = FAISS.from_texts(documents, embeddings) 这行代码主要作用是基于给定的文本集合创建一个向量数据库(这里使用 FAISS 作为向量数据库工具 )。具体说明如下: FAISS :FAISS …...

虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?
虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解? code review! 文章目录 虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?理解这句话的关键点1.类(…...

鸢尾花分类的6种机器学习方法综合分析与实现
鸢尾花分类的6种机器学习方法综合分析与实现 首先我们来看一下对应的实验结果。 数据准备与环境配置 在开始机器学习项目前,首先需要准备编程环境和加载数据。以下代码导入必要的库并加载鸢尾花数据集: import numpy as np import pandas as pd impo…...
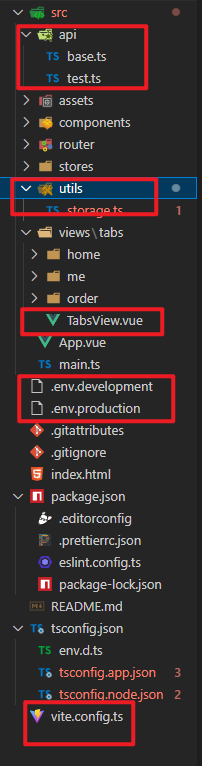
vite,Vue3,ts项目关于axios配置
一、安装依赖包 npm install axios -S npm install qs -S npm install js-cookie 文件目录 二、配置线上、本地环境 与src文件同级,分别创建本地环境文件 .env.development 和线上环境文件 .env.production # 本地环境 ENV = development # 本地环境接口地址 VITE_API_URL =…...