21 天 Python 计划:使用SQLAlchemy 中的ORM查询
文章目录
- 准备工作
- 图书表 books
- 分类表 categories
- ORM 对象定义
- 一、根据主键获取记录
- 二、AND 查询
- 三、 常用方法
- 四、OR 查询
- 五、 5. AND 和 OR 并存的查询
- 六、巧用列表或者字典的解包给查询方法传参
- 七、其它常用运算符
- 八、查询指定列
- 九、内连接、外连接
- 9.1 内连接
- 9.2 外连接
- 9.3 代码解释
- 9.4 结果
- 十、打印 SQL
- 10.1 代码解释
- 10.2结果
- 结语
Python是一种强大且易于学习的编程语言。通过这个21天的计划,我们将逐步深入灵活使用SQLAlchemy 中的ORM查询。无论你是初学者还是有一定基础的开发者,这个计划都将帮助你巩固和扩展你的Python知识。
在学习本篇之前,我们先复习一下前面的内容:
day1:Python下载和开发工具介绍
day2:数据类型、字符编码、文件处理
day3:基础语法与课外练习
day4:函数简单介绍
day5:模块与包
day6:常用模块介绍
day7:面向对象
day8:面向对象高级
day9:异常处理
day10:网络编程
day11:并发编程
day12:MySQL数据库初识
day13:MySQL库相关操作
day14:MySQL表相关操作
day15:MySQL中DML与权限管理
day16:MySQL数据备份与Python操作实战指南
day17:MySQL视图、触发器、存储过程、函数与流程控制
准备工作
为方便说明,我们初始化如下数据:
图书表 books
| id | cat_id | name | price |
|---|---|---|---|
| 1 | 1 | 生死疲劳 | 40.40 |
| 2 | 1 | 皮囊 | 31.80 |
| 3 | 2 | 半小时漫画中国史 | 33.60 |
| 4 | 2 | 耶路撒冷三千年 | 55.60 |
| 5 | 2 | 国家宝藏 | 52.80 |
| 6 | 3 | 时间简史 | 31.10 |
| 7 | 3 | 宇宙简史 | 22.10 |
| 8 | 3 | 自然史 | 26.10 |
| 9 | 3 | 人类简史 | 40.80 |
| 10 | 3 | 万物简史 | 33.20 |
分类表 categories
| id | name |
|---|---|
| 1 | 文学 |
| 2 | 人文社科 |
| 3 | 科技 |
ORM 对象定义
注意:本文 Python 代码在以下环境测试通过
- Python 3.6.0
- PyMySQL 0.8.1
- SQLAlchemy 1.2.8
# coding=utf-8
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy.orm import sessionmaker# 创建基类
Base = declarative_base()
# 创建数据库引擎,需要替换为实际的用户名、密码和数据库名
engine = create_engine('mysql+pymysql://username:password@127.0.0.1:3306/db_name?charset=utf8')
# 创建会话工厂
Session = sessionmaker(bind=engine)
# 创建会话对象
session = Session()# 定义一个方法,将对象属性转换为字典
def to_dict(self):return {c.name: getattr(self, c.name, None) for c in self.__table__.columns}# 将 to_dict 方法绑定到基类
Base.to_dict = to_dict# 定义图书类
class Book(Base):__tablename__ = 'books'id = Column(Integer, primary_key=True)cat_id = Column(Integer)name = Column('name', String(120))price = Column('price', Numeric)# 定义分类类
class Category(Base):__tablename__ = 'categories'id = Column(Integer, primary_key=True)name = Column('name', String(30))
具体查询方式如下所示:
一、根据主键获取记录
当我们获取图书的详情时,很容易用到。
# 方式一:使用 get 方法
book_id = 1
book = session.query(Book).get(book_id)
print(book and book.to_dict())
# 直接 get(primary_key) 就得到结果 {'id': 1, 'cat_id': 1, 'name': '生死疲劳', 'price': Decimal('40.40')}# 方式二:使用 filter 和 first 方法
book_id = 1
book = session.query(Book) \.filter(Book.id == book_id) \.first()
print(book and book.to_dict())
# 不过,还是前一种方式简洁一些。
二、AND 查询
我们最常用到的就是这种查询,比如我要获取 cat_id为 1 且价格大于 35 的书。
# 方式一:直接在 filter 中传入多个条件
books = session.query(Book) \.filter(Book.cat_id == 1, Book.price > 35) \.all()
print([v.to_dict() for v in books])
# 执行后,得到结果 [{'id': 1, 'cat_id': 1, 'name': '生死疲劳', 'price': Decimal('40.40')}]# 方式二:使用 and_ 函数
from sqlalchemy import and_
books = session.query(Book) \.filter(and_(Book.cat_id == 1, Book.price > 35)) \.all()
print([v.to_dict() for v in books])
# 通常来说,如果条件全是用 AND 连接的话,没必要显式的去用 and_。# 方式三:使用 filter_by 方法(适用于等值比较)
books = session.query(Book) \.filter_by(cat_id=1, price=31.8) \.all()
print([v.to_dict() for v in books])
# 结果 [{'id': 2, 'cat_id': 1, 'name': '皮囊', 'price': Decimal('31.80')}]
# 这种方式相对于 filter() 来说,书写要简洁一些,不过条件都限制在了等值比较。不同情况选择合适的就好。
三、 常用方法
除了上面使用的 get()、first()、all() 外,还有下面的一些方法比较常用。
# one() 只获取一条记录,如果找不到记录或者找到多条都会报错
# 找不到记录会抛如下错误
# sqlalchemy.orm.exc.NoResultFound: No row was found for one()
try:book = session \.query(Book).filter(Book.id > 10) \.one()print(book and book.to_dict())
except Exception as e:print(e)# 找到多条记录会抛如下错误
# sqlalchemy.orm.exc.MultipleResultsFound: Multiple rows were found for one()
try:book = session \.query(Book).filter(Book.id < 10) \.one()print(book and book.to_dict())
except Exception as e:print(e)# 正常,得到如下结果
# {'id': 10, 'cat_id': 3, 'name': '万物简史', 'price': Decimal('33.20')}
book = session \.query(Book).filter(Book.id == 10) \.one()
print(book and book.to_dict())# count() 返回记录条数
count = session \.query(Book) \.filter(Book.cat_id == 3) \.count()
print(count)
# 结果 5# limit() 限制返回的记录条数
books = session \.query(Book) \.filter(Book.cat_id == 3) \.limit(3) \.all()
print([v.to_dict() for v in books])
# 结果 [{'id': 6, 'cat_id': 3, 'name': '时间简史', 'price': Decimal('31.10')}, {'id': 7, 'cat_id': 3, 'name': '宇宙简史', 'price': Decimal('22.10')}, {'id': 8, 'cat_id': 3, 'name': '自然史', 'price': Decimal('26.10')}]# distinct() 与 SQL 的 distinct 语句行为一致
books = session \.query(Book.cat_id) \.distinct(Book.cat_id) \.all()
print([dict(zip(v.keys(), v)) for v in books])
# 结果 [{'cat_id': 1}, {'cat_id': 2}, {'cat_id': 3}]# order_by() 将记录按照某个字段进行排序
# 图书按 ID 降序排列
# 如果要升序排列,去掉 .desc() 即可
books = session \.query(Book.id, Book.name) \.filter(Book.id > 8) \.order_by(Book.id.desc()) \.all()
print([dict(zip(v.keys(), v)) for v in books])
# 结果 [{'id': 10, 'name': '万物简史'}, {'id': 9, 'name': '人类简史'}]# scalar() 返回调用 one() 后得到的结果的第一列值
book_name = session \.query(Book.name) \.filter(Book.id == 10)\.scalar()
print(book_name)
# 结果 万物简史# exist() 查看记录是否存在
# 查看 ID 大于 10 的图书是否存在
from sqlalchemy.sql import exists
is_exist = session \.query(exists().where(Book.id > 10)) \.scalar()
print(is_exist)
# 结果 False
四、OR 查询
通过 OR 连接条件的情况也多,比如我要获取 cat_id等于 1 或者价格大于 35 的书。
from sqlalchemy import or_
books = session.query(Book) \.filter(or_(Book.cat_id == 1, Book.price > 35)) \.all()
print([v.to_dict() for v in books])
# 执行,得到结果 [{'id': 1, 'cat_id': 1, 'name': '生死疲劳', 'price': Decimal('40.40')}, {'id': 2, 'cat_id': 1, 'name': '皮囊', 'price': Decimal('31.80')}, {'id': 4, 'cat_id': 2, 'name': '耶路撒冷三千年', 'price': Decimal('55.60')}, {'id': 5, 'cat_id': 2, 'name': '国家宝藏', 'price': Decimal('52.80')}, {'id': 9, 'cat_id': 3, 'name': '人类简史', 'price': Decimal('40.80')}]
# 使用方式和 AND 查询类似,从 sqlalchemy 引入 or_,然后将条件放入就 OK 了。
五、 5. AND 和 OR 并存的查询
现实情况下,我们很容易碰到 AND 和 OR 并存的查询。
# 示例一:查询价格大于 55 或者小于 25,同时 cat_id 不等于 1 的图书
from sqlalchemy import or_
books = session.query(Book) \.filter(or_(Book.price > 55, Book.price < 25), Book.cat_id != 1) \.all()
print([v.to_dict() for v in books])
# 结果 [{'id': 4, 'cat_id': 2, 'name': '耶路撒冷三千年', 'price': Decimal('55.60')}, {'id': 7, 'cat_id': 3, 'name': '宇宙简史', 'price': Decimal('22.10')}]# 示例二:查询图书的数量,图书满足两个要求中的一个即可:一是 cat_id 大于 5;二是 cat_id 小于 2 且价格大于 40。
from sqlalchemy import or_, and_
count = session.query(Book) \.filter(or_(Book.cat_id > 5, and_(Book.cat_id < 2, Book.price > 40))) \.count()
print(count)
# 结果 1
六、巧用列表或者字典的解包给查询方法传参
开发中,我们经常会碰到根据传入的参数构造查询条件进行查询。
# 列表解包示例
# 请求参数,这里只是占位,实际由用户提交的请求决定
params = {'cat_id': 1}
conditions = []
if params.get('cat_id', 0):conditions.append(Book.cat_id == params['cat_id'])
if params.get('price', 0):conditions.append(Book.price == params['price'])
if params.get('min_price', 0):conditions.append(Book.price >= params['min_price'])
if params.get('max_price', 0):conditions.append(Book.price <= params['max_price'])
books = session.query(Book).filter(*conditions).all()
print([v.to_dict() for v in books])
# 结果 [{'id': 1, 'cat_id': 1, 'name': '生死疲劳', 'price': Decimal('40.40')}, {'id': 2, 'cat_id': 1, 'name': '皮囊', 'price': Decimal('31.80')}]
# OR 查询类似,将列表解包传给 or_() 即可。如果需求更复杂,AND 和 OR 都可能出现,这个时候根据情况多建几个列表实现。这里只向大家说明大致的思路,就不举具体的例子了。# 字典解包示例
# 请求参数,这里只是占位,实际由用户提交的请求决定
params = {'price': 31.1}
condition_dict = {}
if params.get('cat_id', 0):condition_dict['cat_id'] = params['cat_id']
if params.get('price', 0):condition_dict['price'] = params['price']
books = session.query(Book) \.filter_by(**condition_dict) \.all()
print([v.to_dict() for v in books])
# 结果 [{'id': 6, 'cat_id': 3, 'name': '时间简史', 'price': Decimal('31.10')}]
七、其它常用运算符
除了上面看到的 ==、>、>=、<、<=、!= 之外,还有几个比较常用。
# IN 查询 ID 在 1、3、5 中的记录
books = session.query(Book) \.filter(Book.id.in_([1, 3, 5])) \.all()# INSTR() 查询名称包含「时间简史」的图书
books = session.query(Book) \.filter(Book.name.contains('时间简史')) \.all()# FIND_IN_SET() 查询名称包含「时间简史」的图书
# 这里显然应该用 INSTR() 的用法
# FIND_IN_SET() 一般用于逗号分隔的 ID 串查找
# 这里使用 FIND_IN_SET(),旨在说明用法
from sqlalchemy import func
books = session.query(Book) \.filter(func.find_in_set('时间简史', Book.name)) \.all()# LIKE 查询名称以「简史」结尾的图书
books = session.query(Book) \.filter(Book.name.like('%简史')) \.all()# NOT 上面的 IN、INSTR、FIN_IN_SET、LIKE 都可以使用 ~ 符号取反。
# 查询 ID 不在 1 到 9 之间的记录
books = session.query(Book) \.filter(~Book.id.in_(range(1, 10))) \.all()
八、查询指定列
查询名称包含「简史」的图书的 ID 和名称。
books = session.query(Book.id, Book.name) \.filter(Book.name.contains('简史')) \.all()
print([dict(zip(v.keys(), v)) for v in books])
# 结果 [{'id': 6, 'name': '时间简史'}, {'id': 7, 'name': '宇宙简史'}, {'id': 9, 'name': '人类简史'}, {'id': 10, 'name': '万物简史'}]
九、内连接、外连接
9.1 内连接
# 获取分类为「科技」,且价格大于 40 的图书
# 如果 ORM 对象中定义有外键关系
# 那么 join() 中可以不指定关联关系
# 否则,必须要
books = session \.query(Book.id, Book.name.label('book_name'), Category.name.label('cat_name')) \.join(Category, Book.cat_id == Category.id) \.filter(Category.name == '科技', Book.price > 40) \.all()
print([dict(zip(v.keys(), v)) for v in books])
# 结果 [{'id': 9, 'book_name': '人类简史', 'cat_name': '科技'}]# 统计各个分类的图书的数量
from sqlalchemy import func
books = session \.query(Category.name.label('cat_name'), func.count(Book.id).label('book_num')) \.join(Book, Category.id == Book.cat_id) \.group_by(Category.id) \.all()
print([dict(zip(v.keys(), v)) for v in books])
# 结果 [{'cat_name': '文学', 'book_num': 2}, {'cat_name': '人文社科', 'book_num': 3}, {'cat_name': '科技', 'book_num': 5}]
9.2 外连接
为了更清晰地说明外连接的使用,我们仅在这一小节中向 books表中加入如下数据:
| id | cat_id | name | price |
|---|---|---|---|
| 11 | 5 | 人性的弱点 | 54.40 |
现在,我们要查看 ID 大于等于 9 的图书的分类信息。在 SQLAlchemy 中,outerjoin默认是左连接。如果 ORM 对象中定义有外键关系,那么 outerjoin()中可以不指定关联关系;否则,必须要指定。
# outerjoin 默认是左连接
# 如果 ORM 对象中定义有外键关系
# 那么 outerjoin() 中可以不指定关联关系
# 否则,必须要
books = session \.query(Book.id.label('book_id'),Book.name.label('book_name'),Category.id.label('cat_id'),Category.name.label('cat_name')) \.outerjoin(Category, Book.cat_id == Category.id) \.filter(Book.id >= 9) \.all()
print([dict(zip(v.keys(), v)) for v in books])
9.3 代码解释
- session.query():用于指定要查询的字段,这里我们使用 label()方法为字段指定别名,方便后续处理。
- outerjoin():执行外连接操作,将Book表和 Category表通过 cat_id进行关联。
- filter():添加过滤条件,只查询Book.id大于等于 9 的记录。
- all():执行查询并返回所有结果。
9.4 结果
[{'book_id': 9, 'book_name': '人类简史','cat_id': 3, 'cat_name': '科技'},{'book_id': 10, 'book_name': '万物简史','cat_id': 3, 'cat_name': '科技'},{'book_id': 11, 'book_name': '人性的弱点','cat_id': None, 'cat_name': None}]
注意最后一条记录,由于cat_id为 5 在categories表中没有对应的记录,所以cat_id和 cat_name的值为 None。
十、打印 SQL
当碰到复杂的查询,比如有 AND、有 OR、还有连接查询时,有时可能得不到预期的结果,这时我们可以打出最终的 SQL 帮助我们来查找错误。
以上一节的外连接为例,说明怎么打印最终 SQL:
q = session \.query(Book.id.label('book_id'),Book.name.label('book_name'),Category.id.label('cat_id'),Category.name.label('cat_name')) \.outerjoin(Category, Book.cat_id == Category.id) \.filter(Book.id >= 9)raw_sql = q.statement \.compile(compile_kwargs={"literal_binds": True})
print(raw_sql)
10.1 代码解释
- q.statement:获取查询语句的 SQLAlchemy 内部表示。
- compile(compile_kwargs={“literal_binds”: True}):将查询语句编译为实际的 SQL 语句,并将绑定参数替换为实际的值。
10.2结果
SELECT books.id AS book_id, books.name AS book_name, categories.id AS cat_id, categories.name AS cat_name
FROM books LEFT OUTER JOIN categories ON books.cat_id = categories.id
WHERE books.id >= 9
结语
通过这个21天的Python计划,我们涵盖了灵活使用 SQLAlchemy 中的ORM查询。希望这些内容能帮助你更好地理解和使用Python。继续学习和实践,你将成为一名优秀的Python开发者!
📢 注意啦!文末有彩蛋!参与评论就有机会把这本好书抱回家~动动手指,说不定下个锦鲤就是你!赠书福利
相关文章:

21 天 Python 计划:使用SQLAlchemy 中的ORM查询
文章目录 准备工作图书表 books分类表 categoriesORM 对象定义 一、根据主键获取记录二、AND 查询三、 常用方法四、OR 查询五、 5. AND 和 OR 并存的查询六、巧用列表或者字典的解包给查询方法传参七、其它常用运算符八、查询指定列九、内连接、外连接9.1 内连接9.2 外连接9.3…...

使用 LLaMA-Factory 微调 llama3 模型(二)
使用 LLaMA-Factory 微调 llama3 模型 1. LLaMA-Factory模型介绍 https://github.com/hiyouga/LLaMA-FactoryLLaMA-Factory 是一个用于大型语言模型(LLM)微调的工具,它旨在简化大型语言模型的微调过程, 使得用户可以快速地对模型…...

并发编程--条件量与死锁及其解决方案
并发编程–条件量与死锁及其解决方案 文章目录 并发编程--条件量与死锁及其解决方案1.条件量1.1条件量基本概念1.2条件量的使用 2. 死锁 1.条件量 1.1条件量基本概念 在许多场合中,程序的执行通常需要满足一定的条件,条件不成熟的时候,任务…...
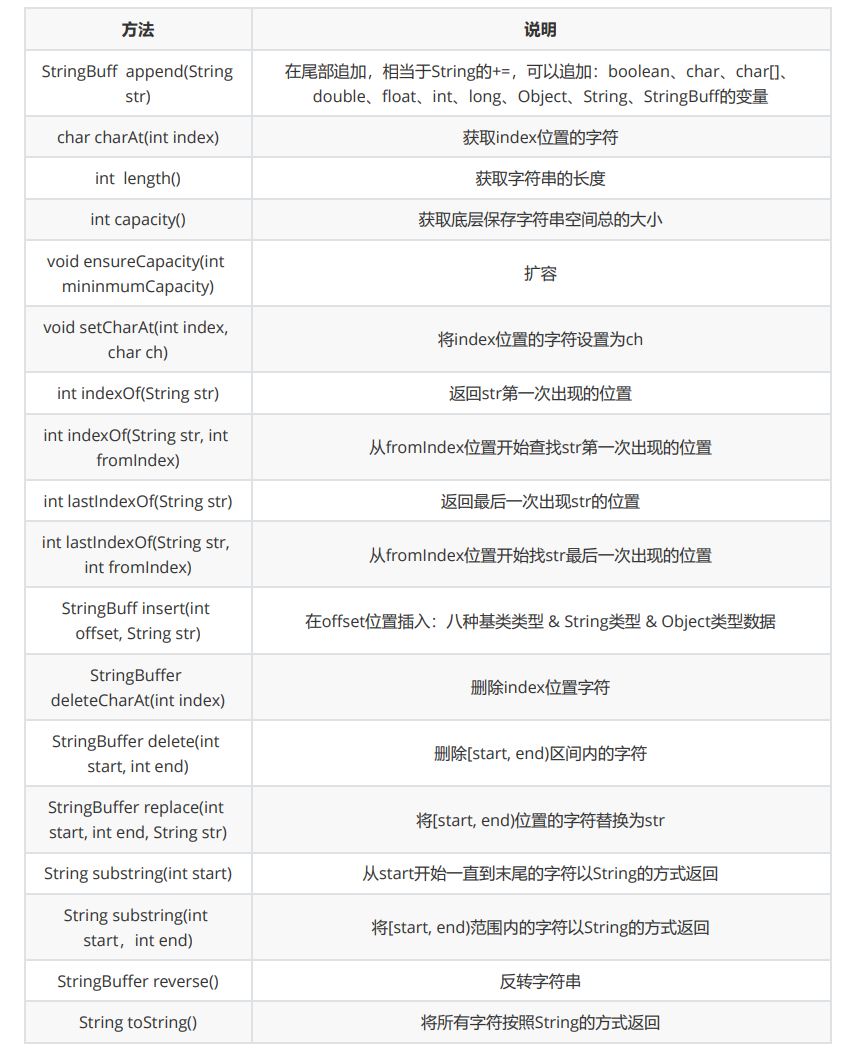
JAVA SE 自我总结
目录 1. 字面常量 2. 数据类型 3. 变量 4. 类型转换 5. 实参和形参的关系 6. 数组 6.1 数组的概念 6.2 动态初始化 6.3 静态初始化 7. 数据区 编辑 8. 数组的拷贝 8.1 赋值拷贝 8.2 方法拷贝 9. 代码块 10. 内部类 10.1 实例内部类 10.2 静态内部类 10.3 …...
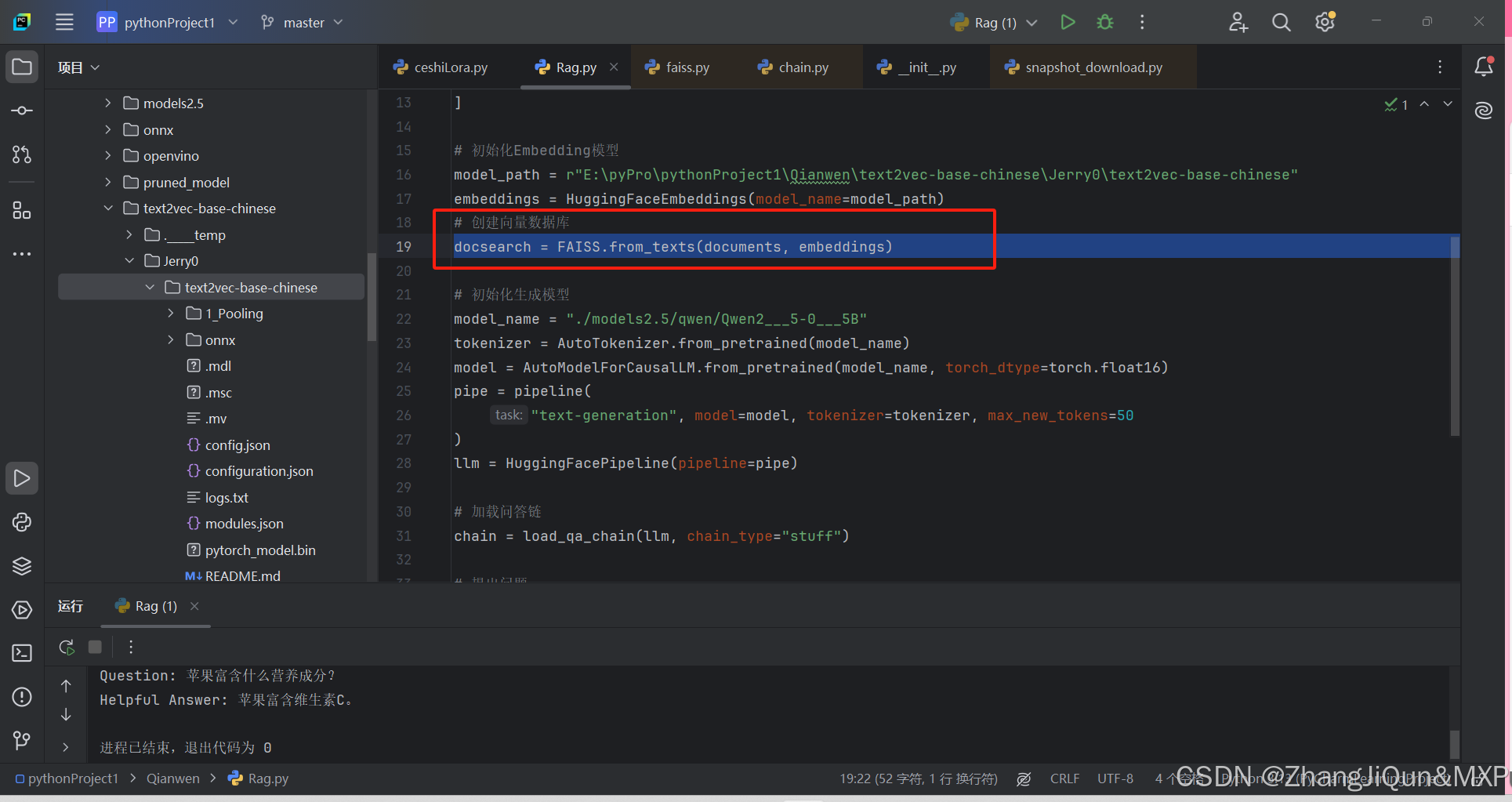
RAG创建向量数据库:docsearch = FAISS.from_texts(documents, embeddings)
RAG创建向量数据库:docsearch = FAISS.from_texts(documents, embeddings) 代码解释 docsearch = FAISS.from_texts(documents, embeddings) 这行代码主要作用是基于给定的文本集合创建一个向量数据库(这里使用 FAISS 作为向量数据库工具 )。具体说明如下: FAISS :FAISS …...

虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?
虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解? code review! 文章目录 虚幻引擎5-Unreal Engine笔记之“将MyStudent变量设置为一个BP_Student的实例”这句话如何理解?理解这句话的关键点1.类(…...

鸢尾花分类的6种机器学习方法综合分析与实现
鸢尾花分类的6种机器学习方法综合分析与实现 首先我们来看一下对应的实验结果。 数据准备与环境配置 在开始机器学习项目前,首先需要准备编程环境和加载数据。以下代码导入必要的库并加载鸢尾花数据集: import numpy as np import pandas as pd impo…...
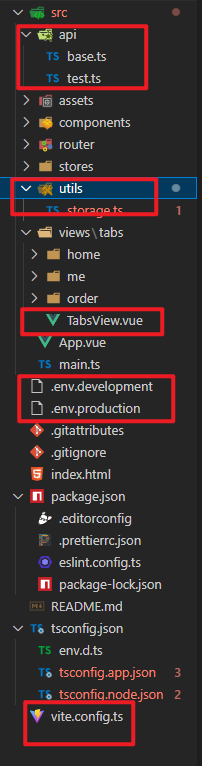
vite,Vue3,ts项目关于axios配置
一、安装依赖包 npm install axios -S npm install qs -S npm install js-cookie 文件目录 二、配置线上、本地环境 与src文件同级,分别创建本地环境文件 .env.development 和线上环境文件 .env.production # 本地环境 ENV = development # 本地环境接口地址 VITE_API_URL =…...

mysql:重置表自增字段序号
情况一:清空表数据后重置自增 ID 如果你希望清空表中的所有数据,并将自增 ID 重置为初始值(通常为 1) 1、truncate truncate table tb_dict; 2、delete 配合 alter 语句 delete from tb_dict; alter table tb_dict AUTO_INCR…...

STM32 模块化开发指南 · 第 4 篇 用状态机管理 BLE 应用逻辑:分层解耦的实践方式
本文是《STM32 模块化开发实战指南》第 4 篇,聚焦于 BLE 模块中的状态管理问题。我们将介绍如何通过有限状态机(Finite State Machine, FSM)架构,实现 BLE 广播、扫描、连接等行为的解耦与可控,并配合事件队列驱动完成主从共存、低功耗友好、状态清晰的 BLE 应用。 一、为…...

HTML — 浮动
浮动 HTML浮动(Float)是一种CSS布局技术,通过float: left或float: right使元素脱离常规文档流并向左/右对齐,常用于图文混排或横向排列内容。浮动元素会紧贴父容器或相邻浮动元素的边缘,但脱离文档流后可能导致父容器高…...

IP节点详解及国内IP节点获取指南
获取国内IP节点通常涉及网络技术或数据资源的使用,IP地址作为网络设备的唯一标识,对于网络连接和通信至关重要。详细介绍几种修改网络IP地址的常用方法,无论是对于家庭用户还是企业用户,希望能找到适合自己的解决方案。以下是方法…...
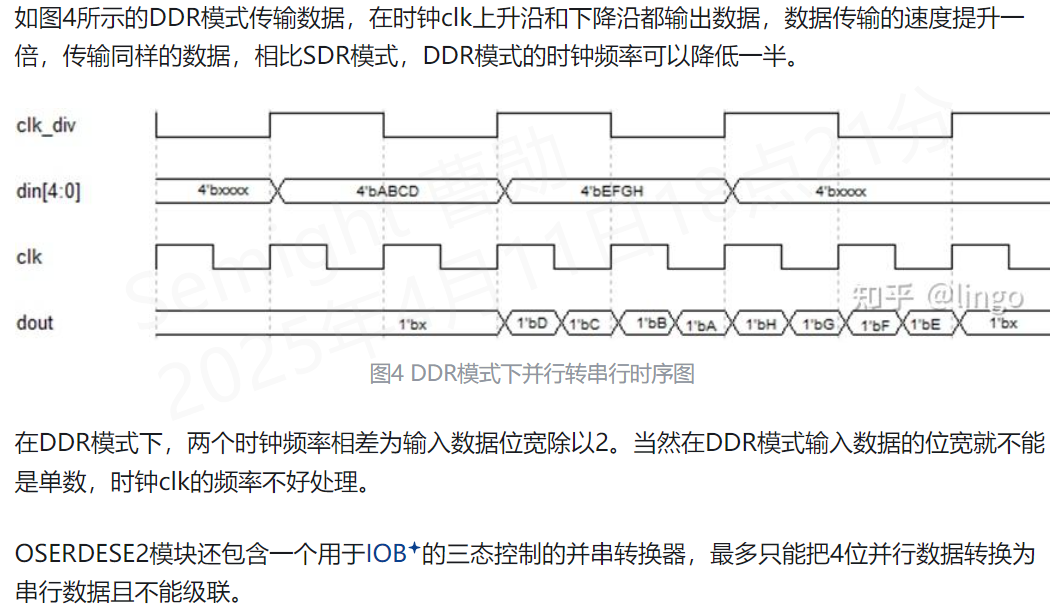
AD9253 LVDS 高速ADC驱动开发
1、查阅AD9253器件手册 2、查阅Xilinx xapp524手册 3、该款ADC工作在125Msps下,14bit - 2Lane - 1frame 模式。 对应:data clock时钟为500M DDR mode。data line rate:1Gbps。frame clock:1/4 data clock 具体内容:…...
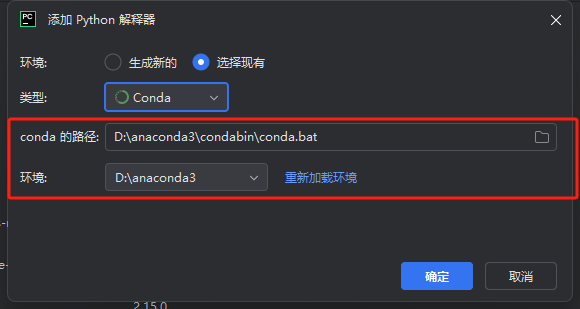
pycharm2024.3.5版本配置conda踩坑
配置解释器是conda时,死活选不到自己的环境 看了很多,都是说要选scripts下的conda.exe 都没用 主要坑在于这是新版的pycharm 是配置condabin 下的 conda.bat 参考:PyCharm配置PyTorch环境(完美解决找不到Conda可执行文件python.exe问题) …...

【异常处理】Clion IDE中cmake时头文件找不到 头文件飘红
如图所示是我的clion项目目录 我自定义的data_structure.h和func_declaration.h在unit_test.c中无法检索到 cmakelists.txt配置文件如下所示: cmake_minimum_required(VERSION 3.30) project(noc C) #设置头文件的目录 include_directories(${CMAKE_SOURCE_DIR}/…...
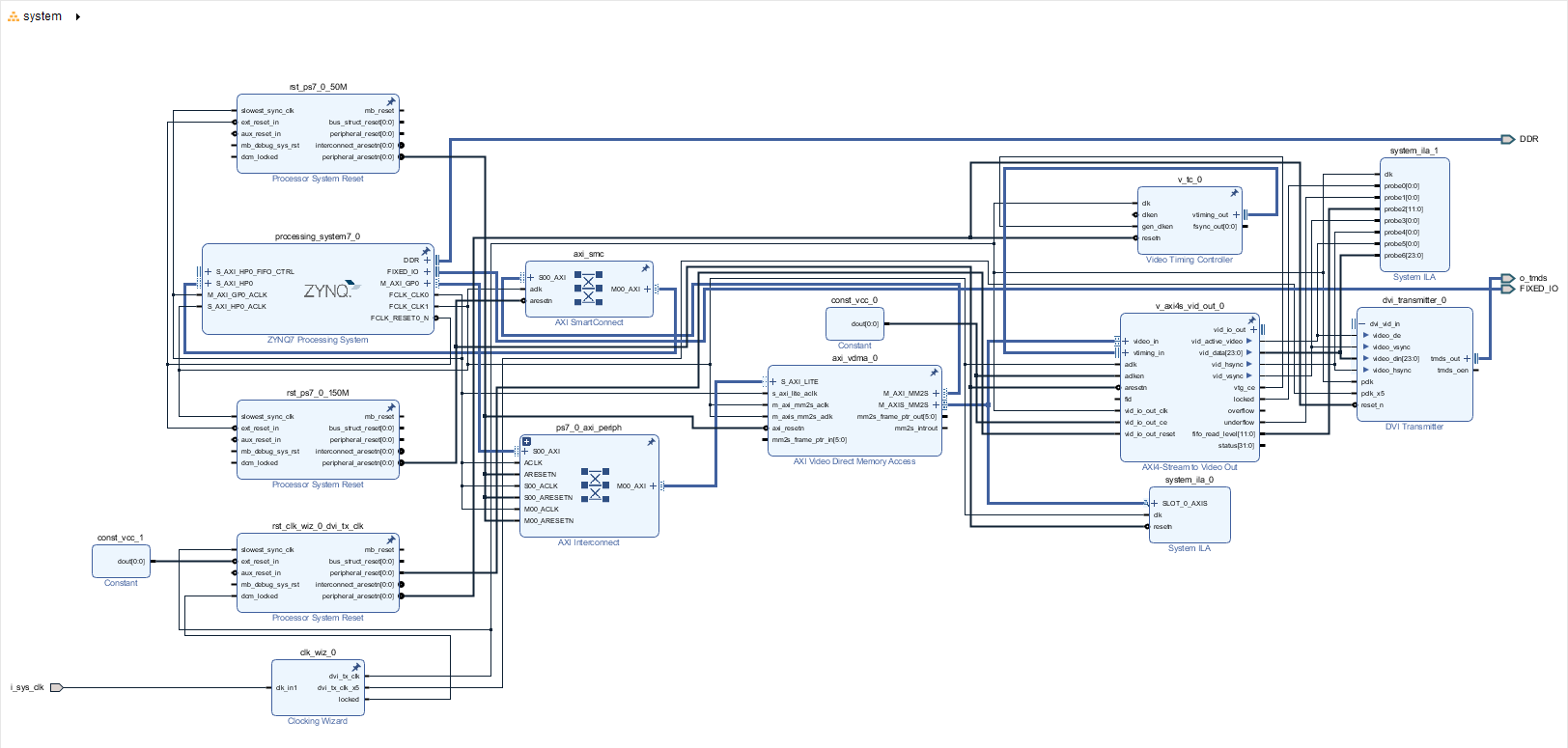
14 - VDMA彩条显示实验
文章目录 1 实验任务2 系统框图3 硬件设计4 软件设计 1 实验任务 本实验任务是PS端写彩条数据至DDR3内存中,然后通过PL端的VDMA IP核将彩条数据通过HDMI接口输出显示。 2 系统框图 本实验是用HDMI接口固定输出1080P的彩条图,所以: rgb2lc…...
:touch)
每天学一个 Linux 命令(13):touch
Linux 文件管理命令:touch touch 是 Linux 中一个简单但高频使用的命令,主要用于创建空文件或修改文件的时间戳(访问时间、修改时间)。它是文件管理和脚本操作的实用工具。 1. 命令作用 创建空文件:快速生成一个或多个空白文件。更新时间戳:修改文件的访问时间(Access …...
PromptUp 网站介绍:AI助力,轻松创作
1. 网站定位与核心功能 promptup.net 可能是一个面向 创作者、设计师、营销人员及艺术爱好者 的AI辅助创作平台,主打 零门槛、智能化的内容生成与优化。其核心功能可能包括: AI艺术创作:通过输入关键词、选择主题或拖放模板,快速生成风格多样的数字艺术作品(如插画、海报…...

高级java每日一道面试题-2025年3月26日-微服务篇[Nacos篇]-在Spring Cloud项目中如何集成Nacos?
如果有遗漏,评论区告诉我进行补充 面试官: 在Spring Cloud项目中如何集成Nacos? 我回答: 在Spring Cloud项目中集成Nacos,可以充分利用Nacos作为服务注册与发现中心以及配置管理中心的功能。以下是详细的步骤和说明,帮助你完成这一集成过程…...
 平台的整体概览与未来发展)
AI 大语言模型 (LLM) 平台的整体概览与未来发展
📋 分析报告:AI 大语言模型 (LLM) 平台的整体概览与未来发展 自动生成的结构化分析报告 💻 整体概述:AI LLM 平台的市场现状与发展动力 随着人工智能技术的飞速发展,大语言模型(Large Language Models, L…...

Java中的Map vs Python字典:核心对比与使用指南
一、核心概念 1. 基本定义 Python字典(dict) :动态类型键值对集合,语法简洁,支持快速查找。Java Map:接口,常用实现类如 HashMap、LinkedHashMap,需声明键值类型(泛型&…...

人工智能100问☞第3问:深度学习的核心原理是什么?
目录 一、通俗解释 二、专业解析 三、权威参考 深度学习的核心原理是通过构建多层神经网络结构,逐层自动提取并组合数据特征,利用反向传播算法优化参数,从而实现对复杂数据的高层次抽象和精准预测。 一、通俗解释 深度学习的核心原理,就像是教计算机像婴儿…...

金能电力:配电房为什么离不开绝缘胶板
在当今电力系统日益复杂、对供电稳定性与安全性要求极高的时代,每一个细节都关乎着电力供应的顺畅以及工作人员的生命安全。而配电房里常常被大家忽视的绝缘垫,实则起着至关重要的 “守护” 作用。今天,金能电力就来给大家详细讲讲配电房为什…...

Python 深度学习实战 第1章 什么是深度学习代码示例
第1章:什么是深度学习 内容概要 第1章介绍了深度学习的背景、发展历史及其在人工智能(AI)和机器学习(ML)中的地位。本章探讨了深度学习的定义、其与其他机器学习方法的关系,以及深度学习在近年来取得的成…...

【模块化拆解与多视角信息1】基础信息:隐藏的筛选规则——那些简历上没说出口的暗号
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...
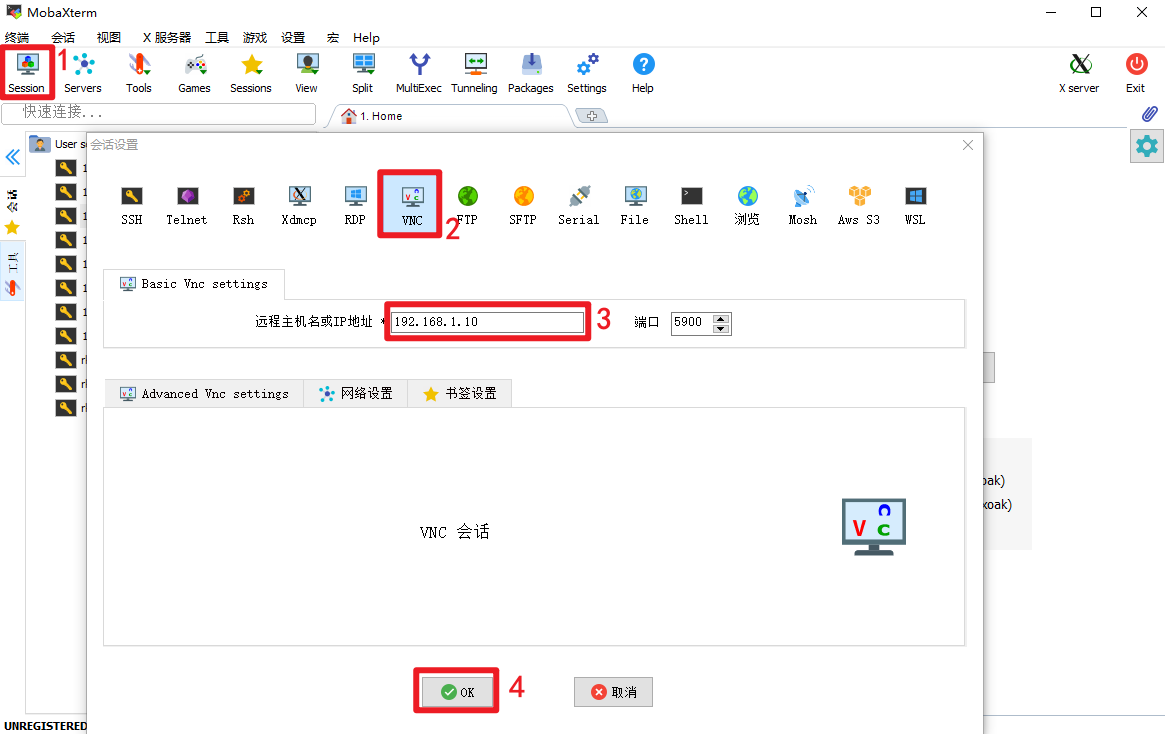
【HD-RK3576-PI】VNC 远程桌面连接
在当今数字化时代,高效便捷的操作方式是技术爱好者与专业人士的共同追求。对于使用 HD-RK3576-PI微型单板计算机的用户而言,当面临没有显示屏的场景时,如何实现远程操作桌面系统呢?别担心,VNC 远程桌面连接将为你解决这…...

Vue.js 中 v-if 的使用及其原理
在 Vue.js 的开发过程中,条件渲染是一项极为常见的需求。v-if指令作为 Vue.js 实现条件渲染的关键手段,能够根据表达式的真假来决定是否渲染某一块 DOM 元素。它在优化页面展示逻辑、提升用户体验等方面发挥着重要作用。接下来,我们就深入探讨…...

电梯广告江湖的终局:分众 “吃掉” 新潮,是救赎还是迷途?
文 / 大力财经 作者 / 魏力 导言:商业世界的底层运行法则,从来都是能量流动的自然映射。宇宙第一性原理和运行法则是,能量大的吸引能量小的。电梯里的战争与和平,从对抗到合并,成为中国商业竞争史中关于博弈与进化的…...

第十六届蓝桥杯大赛软件赛省赛 C/C++ 大学B组
由于官方没有公布题目的数据, 所以代码仅供参考 1. 移动距离 题目链接:P12130 [蓝桥杯 2025 省 B] 移动距离 - 洛谷 【问题描述】 小明初始在二维平面的原点,他想前往坐标 (233, 666)。在移动过程中,他 只能采用以下两种移动方式…...
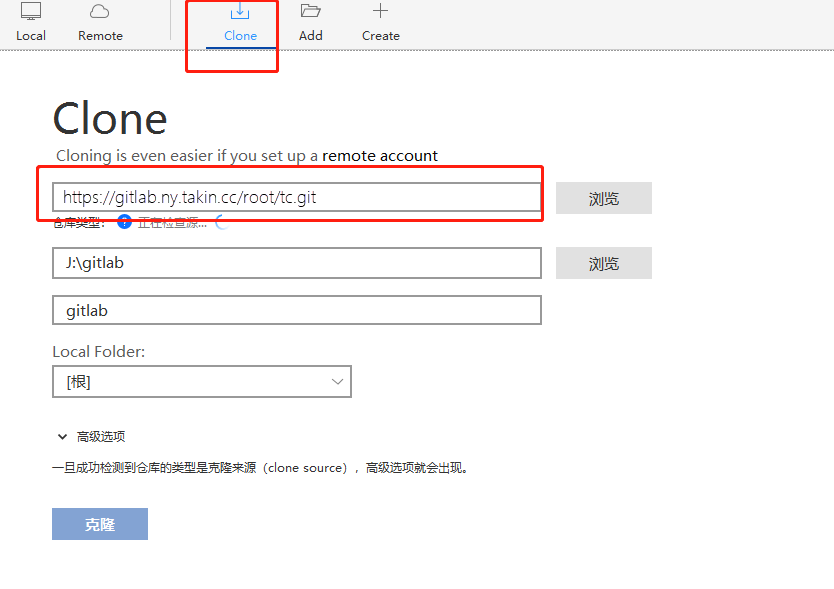
如何在 CentOS 7 系统上以容器方式部署 GitLab,使用 ZeroNews 通过互联网访问 GitLab 私有仓库,进行代码版本发布与更新
第 1 步: 部署 GitLab 容器 在开始部署 GitLab 容器之前,您需要创建本地目录来存储 GitLab 数据、配置和日志: #创建本地目录 mkdir -p /opt/docker/gitlab/data mkdir -p /opt/docker/gitlab/config mkdir -p /opt/docker/gitlab/log#gi…...